文章目录
前言
LightGBM是由微软公司开发的,属于Boosting算法的一种,官方文档地址是: https://lightgbm.readthedocs.io.
LightGBM是XGBoost升级版本,用于许多商业实战中,例如客户违约预测模型,广告收益回归预测模型等。
一、LightGBM算法的设计理念
LightGBM采用分布式的GBDT,选择了基本直方图的决策树算法
| 项目 | XGBoost | LightGBM |
|---|---|---|
| 训练速度 | 慢 | 快 |
| 内存消耗 | 大 | 小 |
| 预测精度 | 相当 | 相当 |
| 分类特征 | 不支持类别特征,需要OneHot编码处理 | 直接支持类别特征 |
相比于XGBoost的优势:
- 降低计算每次拆分增益的成本
- 使用减法直方图进一步加速
- 降低内存使用
- 降低并行学习的通信成本
二、LightGBM算法的数学原理概述
LightGBM = XGBoost + Histogram + GOSS + EFB
- Histogram算法:直方图算法(减少候选分类点数量)
- GOSS算法:基于梯度的单边采样算法(作用是减少样本的数量)
- EFB算法:互斥特征捆绑算法(作用是减少特征数量)
通过以上3个算法的引入,LightGBM生成一片叶子需要的复杂度大大降低了,从而极大的节约了计算成本,同时Histogram算法还将特征由浮点数转换成0~255位的整数进行存储。从而极大的节约了内存存储。
(一)基于leaf-wise决策树生长策略
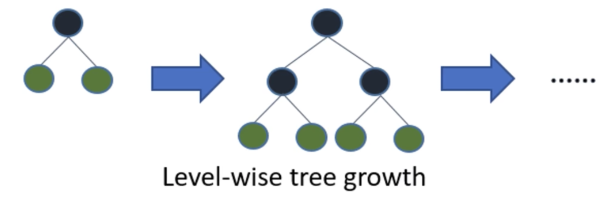
对于大部分决策树算法使用的是level-wise生长策略,即同一层的叶子节点每次都一起分裂,但实际上一些叶子节点的分裂增益较低,这样分裂会增加不少开销,如图所示:
LightGBM是使用leaf-wise策略,每一次在当前叶子节点中,找出分列增益最大的叶子节点进行分裂,而不是所有节点都进行分裂,这样可以提高精度,如下图所示:

(二)直方图算法
直方图算法是代替XGBoost的预排序(pre-sorted)算法的。
首先需要了解直方图的基本概念:直方图分为频数直方图和频率直方图,横坐标为相关数据,纵坐标是该数据出现的频数或频率,通过 hist() 函数绘制直方图。
直方图算法,也叫作histogram算法,简单来说,就是先对特征值进行装箱处理,把连续的浮点特征值离散化成k个整数,形成一个一个的箱体(bins),同时构造一个宽度为k的直方图,在遍历数据的时候,根据离散化后的值作为索引在直方图中累积统计量(因此这里是频数直方图),当遍历一次数据后,直方图累积了需要的统计量,然后根据直方图的离散值,遍历寻找最优的分割点。
对于连续特征来说,装箱处理就是特征工程中的离散化:如[0,10)区间的值都可以赋值为0,[10,20)区间的值都可以赋值为1等,这样就可以把众多的数值划分到有限的分箱中,在Lightgbm中默认的分箱数(bins)为256(该数也可以设置)。
例子:
现在有10000个客户,也就有10000个身高,将身高分箱为256份后(例如180cm-180.2cm的所有客户都分箱为数字200),就变为256个数字,这时再统计每个数值对应的频数(例如180cm-180.2cm的客户为100人,那数字200对应的频数就是100)。这样在节点分裂的时候,对于每个特征都计算10000遍(所有的样本数量)了,而是只需要计算256遍(分箱数),这样就大大加快了训练速度。
(三)GOSS算法
单边梯度采样GOSS算法(Gradient-based One-Side Sampling):通过对样本采样的方法来减少计算目标函数增益时候的复杂度。
GOSS算法中,梯度更大的样本点在计算信息增益时会占有更重要的作用,当我们对样本进行下采样的时候保留这些梯度较大的样本点,并随机去掉梯度小的样本。
怎样保证信息损失降到最低:
首先把样本按照梯度排序,选出梯度最大的a%个样本,然后在剩下小梯度数据中随机选取b%个样本,在计算信息增益的时候,将选出来的b%小梯度样本的信息增益扩大1-a/b的倍数。
(四)EFB算法
EFB算法(Exclusive Feature Bundling),即互斥特征绑定算法。
- EFB算法则将互斥特征绑在一起以减少特征维度
- EFB算法可以有效减少用于构建直方图的特征数量,从而降低计算复杂度,尤其是特征中包含大量稀疏特征的时候
LightGBM可以直接将每个类别取值和一个bin关联,从而自动地处理它们,而无需预处理成onehot编码
(五)并行学习
LightGBM支持特征并行和数据并行两种。传统的特征并行主要思想是在并行化决策树中寻找最佳切分点,在数据量大时难以加速,同时需要对切分结果进行通信整合。
LightGBM则是使用分散规约(Reduce scatter),它将直方图合并的任务分给不同的机器,降低通信和计算的开销,并利用直方图做加速训练,进一步成少开销。
三、LightGBM算法的简单代码实现
(一)安装LightGBM
LightGBM模型的安装办法可以采取PIP安装法,以Windows操作系统为例,Win+R快捷键调出运行框,输入cmd后,在弹出界面中输入代码后Enter键回车运行即可:pip install lightgbm
如在Jupyter Notebook编辑器中,运行下列代码!pip install lightgbm
(二)演示LightGBM分类模型和回归模型
X = [[1,2],[3,4],[5,6],[7,8],[9,10]]
y = [1,2,3,4,5]
from lightgbm import LGBMClassifier
model = LGBMClassifier() #分类模型
from lightgbm import LGBMRegressor
model = LGBMRegressor() #回归模型
model.fit(X,y)
(三)案例
案例背景:智能风控、大数据风控
银行等金融机构经常会根据客户的个人资料、财产等情况,来预测借款客户是否会违约,从而进行贷前审核,贷中管理,贷后违约处理等工作。金融处理的就是风险,需要在风险和收益间寻求到一个平衡点,现代金融某种程度上便是一个风险定价的过程,通过个人的海量数据,从而对其进行风险评估并进行合适的借款利率定价,这便是一个典型的风险定价过程,这也被称之为大数据风控。
1、模型搭建
- 读取数据
- 提取特征变量和目标变量
- 划分训练集和测试集
- 模型训练和搭建
- 模型预测及评估
#1、读取数据
import pandas as pd
df = pd.read_excel('客户信息及违约表现.xlsx')
#2、提取特征变量和目标变量
X = df.drop(columns='是否违约')
Y = df['是否违约']
#3、划分训练集和测试集
from sklearn.model_selection import train_test_split
X_train,X_test,y_train,y_test = train_test_split(X,Y,test_size=0.2,random_state=123)
#4、模型训练和搭建
from lightgbm import LGBMClassifier
model = LGBMClassifier() #分类模型
model.fit(X_train,y_train)
#5、模型预测及评估
y_pred = model.predict(X_test)
a = pd.DataFrame()#创建一个空的DataFrame
a['预测值'] = list(y_pred)
a['实际值'] = list(y_test)
from sklean.metrics import accuracy_score
score = accuracy_score(y_pred,y_test)
model.score(X_test,y_test)#模型准确度评分
#绘制ROC曲线来评估模型预测效果
y_pred_proba = model.predict_proba(X_test)
from sklean.metrics import roc_curve
fpr,tpr,thres = roc_curve(y_test,y_pred_proba[:,1])
import matplotlib.pyplot as plt
plt.plot(fpr,tpr)
plt.show()
#求AUC值
from sklean.metrics import roc_auc_score
score = roc_auc_score(y_test.values,y_pred_proba[:,1])
features = X.columns#获取特征名称
importances = model.feature_importances_#获取特征重要性
#通过二维表格显示
importances_df = pd,DataFrame()
importances_df['特征名称'] = features
importances_df['特征重要性'] = importances
importances_df.sort_values('特征重要性',ascending=False)
2、参数调优
了解了基本的参数后,我们需要对参数进行调优,使用网格搜索交叉验证的方法进行参数调优
from sklearn.model_selection import GridSearchCV
parameters = ['num_leaves':[10,15,31],'n_estimators':[10,20,30],'learning_rate':[0.05,0.1,0.2]}
model = LGBMCLassifier()
grid_search = GridSearchCV(model,parameters,scoring='roc_auc',cv=5)
grid_search.fit(X_train,y_train)#传入数据
grid_search.best_params_#输出参数的最优值
#结果{'Learning-rate':0.1,'n-estimators':20,'num-leaves':15]