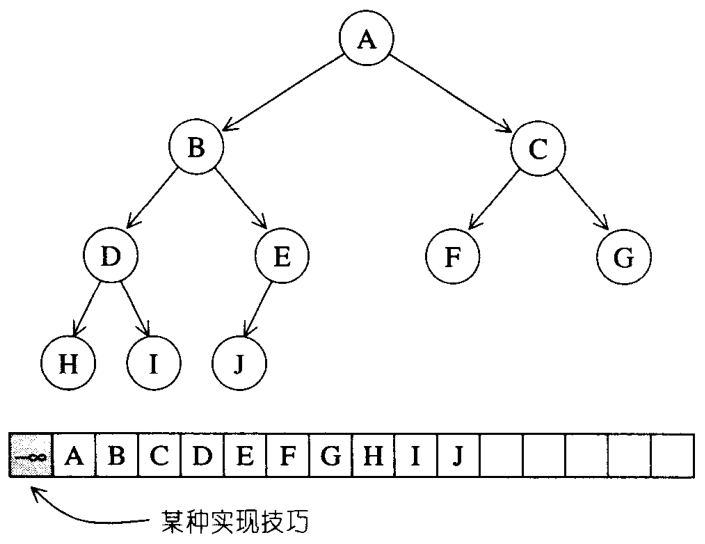
����Ŀ¼
- 1��ʲô��STL?
- 2������һ��ʲô��trivial destructor
- 3��ʹ������ָ������ڴ���Դ,RAII����ô����?
- 4��������:++it��it++�ĸ���,Ϊʲô
- 5��˵һ��C++��ֵ���ú���ֵ����
- 6��STL��hashtable��ʵ��?
- 7����˵һ��traits����
- 8��STL�������ռ�������
- 9�� vector��list��������Ӧ��?��ô��ijvector����list�ĵ����ڶ���Ԫ��
- 10��STL ��vectorɾ�����е�Ԫ��,��������α仯?Ϊʲô����������?�ͷſռ�?
- 11��Vector����ͷſռ�?
- 12�������ڲ�ɾ��һ��Ԫ��
- 13��STL���������ʵ��
- 14��map��set����ôʵ�ֵ�,���������ô�ܹ�ͬʱʵ������������? Ϊʲôʹ�ú����?
- 15������ڹ����ڴ���ʹ��STL����?
- 16��map���뷽ʽ���ļ���?
- 17��STL��unordered_map(hash_map)��map������,hash_map��ν����ͻ�Լ�����
- 18��vectorԽ������±�,mapԽ������±�?vectorɾ��Ԫ��ʱ����ͷſռ�?
- 19��map��[]��find������?
- 20�� STL��list��queue֮�������
- 21��STL�е�allocator��deallocator
- 22��STL��hash_map���ݷ���ʲô?
- 23���������������ܽ�?
- 24��vector������ɾ��������ô����?Ϊʲô��1.5������2��?
- 25��˵һ��STLÿ��������Ӧ�ĵ�����
- 26��STL�е�����ʧЧ���������Щ?
- 27��STL��vector��ʵ��
- 28��STL��slist��ʵ��
- 29��STL��list��ʵ��
- 30��STL�е�deque��ʵ��
- 31��STL��stack��queue��ʵ��
- 32��STL�е�heap��ʵ��
- 33��STL�е�priority_queue��ʵ��
- 34��STL��set��ʵ��?
- 35��STL��map��ʵ��
- 36��set��map������,multimap��multiset������
- 37��STL��unordered_map��map�������Ӧ�ó���**
- 38��hashtable�н����ͻ����Щ����?**
- 39��������Ĵ������
- 39C++�ĺ�������Ͱ���
- 40 string��ʹ�÷���
1��ʲô��STL?
C++ STL�ӹ�����������������:�㷨,�����͵�������
- �㷨��������,���Ƶȳ����㷨,�Լ���ͬ�����ض����㷨��
- �����������ݵĴ����ʽ,��������ʽ��������ʽ����,����ʽ��������list,vector��,����ʽ��������set,map�ȡ�
- �����������ڲ���¶�����ڲ��ṹ������¶������ı�����
2������һ��ʲô��trivial destructor
��trivial destructor��һ����ָ�û�û���Զ�����������,����ϵͳ���ɵ�,�������������ڡ�STLԴ��������г�Ϊ����ʹ����������������
��֮,�û��Զ�������������,���֮Ϊ��non-trivial destructor��,����������������������µĿռ�һ��Ҫ��ʽ���ͷ�,���������ڴ�й¶
����trivial destructor,���ÿ�ζ����е���,��Ȼ��Ч����һ���˺�,��ν����ж���?
��STLԴ��������и�����˵����:
��������value_type()��ȡ��ָ������ͱ�,������__type_traits�жϸ��ͱ�����������Ƿ�trivial,����(__true_type),��ʲôҲ����,��Ϊ(__false_type),��ȥ����destory()����
Ҳ����˵,��ʵ�ʵ�Ӧ�õ���,STL���ṩ����ص��жϷ���**__type_traits**,����Ȥ�Ķ��߿������в���ʹ�÷�ʽ������trivial destructor,����trivial construct��trivial copy construct��,����ܹ����Ƿ�trivial��������,���Բ����ڴ洦������memcpy()��malloc()�ȸ��Ӹ�Ч�������ز���,����Ч�ʡ�
3��ʹ������ָ������ڴ���Դ,RAII����ô����?
- RAIIȫ���ǡ�Resource Acquisition is Initialization��,ֱ������ǡ���Դ��ȡ����ʼ����,Ҳ����˵�ڹ��캯�������������Դ,�������������ͷ���Դ��
��ΪC++�����Ի��Ʊ�֤��,��һ��������ʱ��,�Զ����ù��캯��,�������������ʱ����Զ�������������������,��RAII��ָ����,����Ӧ��ʹ������������Դ,����Դ�Ͷ�����������ڰ�
- ����ָ��(std::shared_ptr��std::unique_ptr)��RAII��ߴ�����ʵ��,ʹ������ָ��,����ʵ���Զ����ڴ����,��Ҳ����Ҫ��������delete��ɵ��ڴ�й©��
�������ŵ�����,��������ָ��,�����м�������Ҫ�ٳ���delete�ˡ�
4��������:++it��it++�ĸ���,Ϊʲô
- ǰ�÷���һ������,���÷���һ������
// ++iʵ�ִ���Ϊ:
int& operator++()
{
*this += 1;
return *this;
}
- ǰ�ò��������ʱ����,���ñ��������ʱ����,��ʱ����ᵼ��Ч�ʽ���
//i++ʵ�ִ���Ϊ:
int operator++(int)
{
int temp = *this;
++*this;
return temp;
}
5��˵һ��C++��ֵ���ú���ֵ����
C++11����ͨ��������ֵ�������Ż�����,������˵��ͨ���ƶ�������������ν����������,ͨ��move����������ʱ���ɵ���ֵ�е���Դ���۵�ת�Ƶ�����һ��������ȥ,ͨ������ת����������ܰ��ղ���ʵ��������ת��������(ͬʱ,����ת����õ�һ���ô��ǿ���ʵ���ƶ�����)��
-
��C++11�����е�ֵ��������ֵ����ֵ����֮һ,��ֵ�ֿ���ϸ��Ϊ����ֵ������ֵ����C++11�п���ȡ��ַ�ġ������ֵľ�����ֵ,��֮,����ȡ��ַ�ġ�û�����ֵľ�����ֵ(����ֵ����ֵ)���ٸ�����,int a = b+c, a ������ֵ,���б�����Ϊa,ͨ��&a���Ի�ȡ�ñ����ĵ�ַ;����ʽb+c������int func()�ķ���ֵ����ֵ,���䱻��ֵ��ijһ����ǰ,���Dz���ͨ���������ҵ���,&(b+c)�����IJ�����ͨ�����롣
-
C++11��C++98�е���ֵ���������䡣��C++11����ֵ�ַ�Ϊ����ֵ(prvalue,Pure Rvalue)�ͽ���ֵ(xvalue,eXpiring Value)�����д���ֵ�ĸ����ͬ��������C++98������ֵ�ĸ���,ָ������ʱ�����Ͳ������������������ֵ;����ֵ����C++11�����ĸ���ֵ������صı���ʽ,��������ʽͨ���ǽ�Ҫ���ƶ��Ķ���(��Ϊ����),���緵����ֵ����T&&�ĺ�������ֵ��std::move�ķ���ֵ,����ת��ΪT&&������ת�������ķ���ֵ������ֵ��������Ϊͨ������ȡ�����������ڴ�ռ�ķ�ʽ��ȡ����ֵ����ȷ�������������ٱ�ʹ�á���������ʱ,ͨ������ȡ���ķ�ʽ���Ա����ڴ�ռ���ͷźͷ���,�ܹ��ӳ�����ֵ�������ڡ�
-
��ֵ���þ��Ƕ�һ����ֵ�������õ����͡���ֵ���þ��Ƕ�һ����ֵ�������õ�����,��ʵ��,������ֵͨ������������,����Ҳֻ��ͨ�����õķ�ʽ�ҵ����Ĵ��ڡ���ֵ���ú���ֵ���ö��������������͡�����������һ����ֵ���û�����ֵ����,�������������г�ʼ��������ԭ���������Ϊ���������ͱ����Լ�����ӵ����������ڴ�,ֻ�Ǹö����һ����������ֵ�����Ǿ�������ֵ�ı���,����ֵ�������Dz�����(����)�����ı�������ֵ����ͨ��Ҳ���ܰ���ֵ,��������ֵ�����Ǹ������ܡ����������͡������Խ��ܷdz�����ֵ��������ֵ����ֵ������г�ʼ��������������ֵ�����õ���ֵ�����ġ���������ֻ����ֻ���ġ���Ե�,�dz�����ֵֻ�ܽ��ܷdz�����ֵ������г�ʼ����
-
��ֵֵ����ͨ�����ܰ��κε���ֵ,Ҫ���һ����ֵ����ֵ����,ͨ����Ҫstd::move()����ֵǿ��ת��Ϊ��ֵ��
��ֵ����ֵ
��ֵ:��ʾ���ǿ��Ի�ȡ��ַ�ı���ʽ,���ܳ����ڸ�ֵ�������,�Ըñ���ʽ���и�ֵ���������η�const�ij���ʹ�ÿ����������µı�ʶ��,������ȡ�õ�ַ,����û�취������и�ֵ
const int& a = 10;
��ֵ:��ʾ����ȡ��ַ�Ķ���,�г���ֵ����������ֵ��lambda����ʽ�ȡ�����ȡ��ַ,������ʾ�䲻�ɸı�,����������ֵ����ֵ����ʱ�Ϳ��Ը�����ֵ��
��ֵ���ú���ֵ����
��ֵ����:��ͳ��C++�����ñ���Ϊ��ֵ����
��ֵ����:C++11����������ֵ����,��ֵ���ù�������ֵʱ,��ֵ���洢���ض�λ��,��ֵ����ָ����ض�λ��,Ҳ����˵,��ֵ��Ȼ����ȡ��ַ,������ֵ�����ǿ��Ի�ȡ��ַ��,�õ�ַ��ʾ��ʱ����Ĵ洢λ��
������Ҫ˵һ����ֵ���õ��ص�:
- �ص�1:ͨ����ֵ���õ�����,��ֵ�֡��ػ�������,��������������ֵ�������ͱ�������������һ����,ֻҪ�ñ���������,����ֵ��ʱ������һֱ�����ȥ
- �ص�2:��ֵ���ö�������ֵ����ֵ����˼����ֵ�������͵ı�����������ֵҲ��������ֵ
- �ص�3:T&& t�ڷ����Զ������ƶϵ�ʱ��,������ֵ������ֵȡ�������ij�ʼ����
�ٸ�����:
#include <bits/stdc++.h>
using namespace std;
template<typename T>
void fun(T&& t)
{
cout << t << endl;
}
int getInt()
{
return 5;
}
int main() {
int a = 10;
int& b = a; //b����ֵ����
int& c = 10; //����,c����ֵ����ʹ����ֵ��ʼ��
int&& d = 10; //��ȷ,��ֵ��������ֵ��ʼ��
int&& e = a; //����,e����ֵ���ò���ʹ����ֵ��ʼ��
const int& f = a; //��ȷ,��ֵ�������൱����������,��������ֵ������ֵ��ʼ��
const int& g = 10;//��ȷ,��ֵ�������൱����������,��������ֵ������ֵ��ʼ��
const int&& h = 10; //��ȷ,��ֵ������
const int& aa = h;//��ȷ
int& i = getInt(); //����,i����ֵ���ò���ʹ����ʱ����(��ֵ)��ʼ��
int&& j = getInt(); //��ȷ,��������ֵ����ֵ
fun(10); //��ʱfun�����IJ���t����ֵ
fun(a); //��ʱfun�����IJ���t����ֵ
return 0;
}
6��STL��hashtable��ʵ��?
STL�е�hashtableʹ�õ������������hash��ͻ����,����ͼ��ʾ��
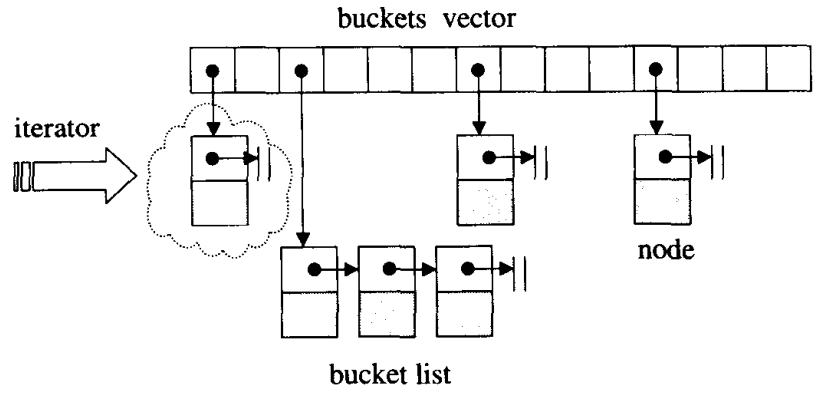
hashtable�е�bucket��ά����list�Ȳ���listҲ����slist,�������Լ��������hashtable_node���ݽṹ��ɵ�linked-list,��bucket�ۺ��屾��ʹ��vector���д洢��hashtable�ĵ�����ֻ�ṩǰ������,���ṩ���˲���
��hashtable���bucket��������,��������28������[53, 97, 193,��,429496729],�ڴ���hashtableʱ,����ݴ����Ԫ�ظ���ѡ����ڵ���Ԫ�ظ�����������Ϊhashtable������(vector�ij���),����ÿ��bucket��ά����linked-list����Ҳ����hashtable���������������hashtable��Ԫ�ظ���������bucket������,��Ҫ�����ؽ�table����,���ҳ���һ������,�����µ�buckets vector,���¼���Ԫ������hashtable��λ�á�
7����˵һ��traits����
traits�������á���Ƕ�ͱ𡰵ı�̼�������������template�����Ƶ�����,��ǿC++δ���ṩ�Ĺ����ͱ���֤��������������õ���iterator_traits��type_traits��
iterator_traits
����Ϊ������ȡ��,�ܹ������������ȡ����5���ͱ�:
- value_type:��������ָ������ͱ�
- difference_type:����������֮��ľ���
- pointer:��������ָ����ͱ�
- reference:�����������õ��ͱ�
- iterator_category:������˵�����,���鿴��
type_traits
��ע�����ͱ������,��������ͱ��Ƿ�߱�non-trivial defalt ctor(Ĭ�Ϲ��캯��)��non-trivial copy ctor(�������캯��)��non-trivial assignment operator(��ֵ�����) ��non-trivial dtor(��������),������Ƿ�,���Բ�ȡֱ�Ӳ����ڴ�ķ�ʽ���Ч��,һ����˵,type_traits֧������5�����͵��ж�:
__type_traits<T>::has_trivial_default_constructor
__type_traits<T>::has_trivial_copy_constructor
__type_traits<T>::has_trivial_assignment_operator
__type_traits<T>::has_trivial_destructor
__type_traits<T>::is_POD_type
���ڱ�����ֻ���class object��ʽ�IJ������в����Ƶ�,�����ʽ�ķ��ؽ����Ӧ���Ǹ�boolֵ,ʵ����ʹ�õ���һ�ֿյĽṹ��:
struct __true_type{};struct __false_type{};
�������ṹ��û���κγ�Ա,������������ĸ���,������������,��νһ������
��Ȼ,����������ж�����һ��Shape����,Ҳ����������Shape���type_traits���ػ��汾
template<> struct __type_traits<Shape>{
typedef __true_type has_trivial_default_constructor;
typedef __false_type has_trivial_copy_constructor;
typedef __false_type has_trivial_assignment_operator;
typedef __false_type has_trivial_destructor;
typedef __false_type is_POD_type;
};
��л�ź��ѡ�������硱����:��������ȡ������ ����->���� , ��->��-2021.06.28
8��STL�������ռ�������
1����������Ϊʲô��Ҫ�����ռ�������?
����֪����̬�����ڴ�ʱ,Ҫ�ڶ�������,������������Ҫ
Ƶ�����ڶѿ����ͷ��ڴ�,��ͻ��ڶ�����ɺܶ��ⲿ��Ƭ,�˷����ڴ�ռ�;
ÿ�ζ�Ҫ���е���malloc��free�����Ȳ���,ʹ�ռ�ͻ�����һЩ������Ϣ,�����˿ռ�������;
�����ⲿ��Ƭ����,�ڴ���������Ҳ��������ڴ��������Ҫ�ϲ����п�,�˷���ʱ��,�����Ч�ʡ�
���Ǿ������˶����ռ�������,�������ڴ�<=128bytesʱ,����Ϊ����С���ڴ�,����ö����ռ���������
����STL��һ���ռ��������Ͷ����ռ���������ѡ����,һ��Ĭ��ѡ���Ϊ�����ռ��������� �������128�ֽ���תȥһ������������
һ��������
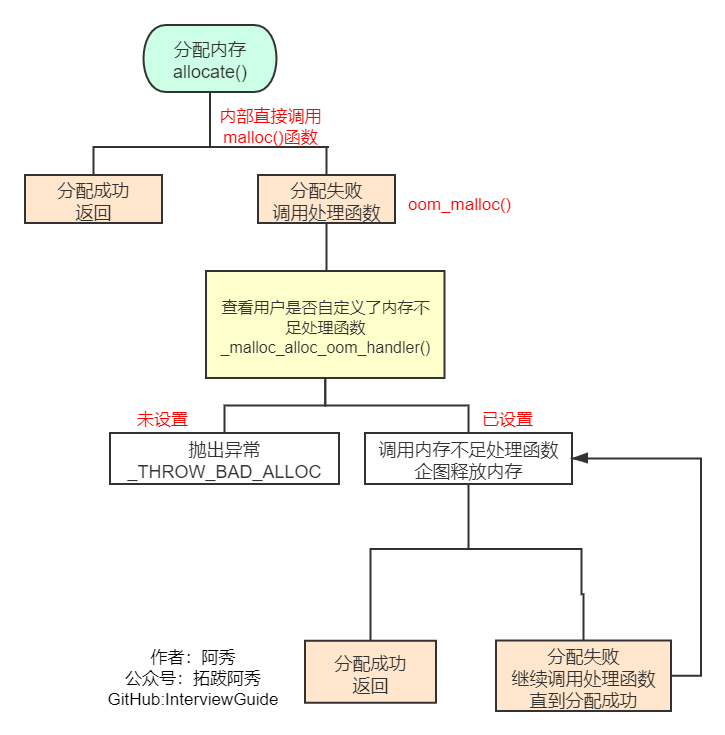
һ���ռ�����������Ҫ�ĺ�������allocate��deallocate��reallocate �� һ���ռ�����������malloc(),free(),realloc()��C����ִ��ʵ�ʵ��ڴ����� �����¹�����:
1��ֱ��allocate�����ڴ�,��ʵ����malloc�������ڴ�,�ɹ���ֱ�ӷ���,ʧ�ܾ͵��ô�������
2������û��Զ������ڴ����ʧ�ܵĴ��������͵���,û�еĻ��ͷ����쳣
3������Զ����˴��������ͽ��д���,�����ټ�����������
����������
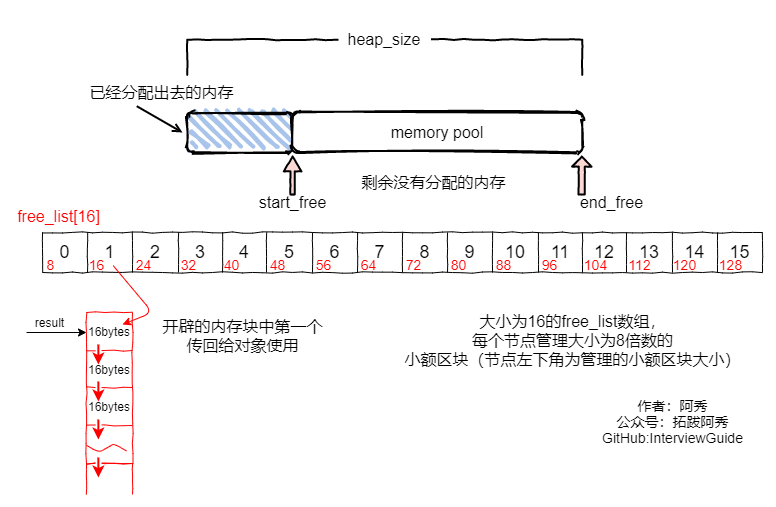
1��ά��16������,�ֱ���0-15������,��С8�ֽ�,��8�ֽ�����,���128�ֽ�,�㴫��һ���ֽڲ���,��ʾ����Ҫ�����ڴ�,���Զ�����У�Ե��ڼ�������(����Ҫ13bytes�ռ�,���ǻ��������16bytes��С),���ҵ���n��������鿴�����Ƿ�Ϊ��,�����Ϊ��ֱ�ӴӶ�Ӧ��free_list�аγ�,���Ѿ�������ָ������ƶ�һλ��
2����Ӧ��free_listΪ��,�ȿ����ڴ���Dz��ǿ�ʱ,����ڴ�ز�Ϊ��:
(1)�ȼ�����ʣ��ռ��Ƿ�20���ڵ��С(�������ڴ��С(������) * 20),���㹻��ֱ�Ӵ��ڴ�����ó�20���ڵ��С�ռ�,������һ��������û�ʹ��,����19���������������е����������Ӧ��free_list��,�����´�������ͬ��С���ڴ�����ʱ,��ֱ�Ӳ�����
(2)�������20���ڵ��С,�����Ƿ�������1���ڵ��С,������Ļ���ֱ���ó�һ��������û�,Ȼ���ʣ��Ŀռ��з��価���ܶ�Ľڵ������Ӧ��free_list�С�
(3)�����һ���ڵ��ڴ涼��������Ļ�,���ڴ����ʣ��Ŀռ������Ӧ��free_list��(�ҵ���Ӧ��free_list),Ȼ���ٸ��ڴ�������ڴ�,ת��3��
3���ڴ��Ϊ��,�����ڴ�
��ʱ�����ռ���������ʹ��malloc()��heap�������ڴ�,(һ����������ڴ��СΪ2 * ����ڵ��ڴ��С(������)* 20 + һ�ζ���ռ�),����40��,һ��������,һ����ڴ���С�
4��mallocû�гɹ�
�ڵ����������,���malloc()ʧ����,˵��heap��û���㹻�ռ�����������,��ʱ,�����ռ���������ӱ�����ڵ�ռ���free_list��һһ����,�ӱ�������ڵ�ռ���free_list�аγ�һ���ڵ���ʹ�á������Ҳû�ҵ�,˵��������free_list�ж�û������������,�Ǿ�Ҫ����һ���������ˡ�
�ͷ�ʱ����deallocate()����,���ͷŵ�n>128,�����һ���ռ�������,�����ֱ�ӽ��ڴ��������������ĺ���λ�á�
STL�����ռ���������Ȼ������ⲿ��Ƭ�������Ч��,����ͬʱ������һЩȱ��:
1.��Ϊ���������Ĺ�������,���������������ڴ���Զ�����Ϊ8�ı���,��ʱ������Ҫ1���ֽ�,�������8���ֽ�,���˷���7���ֽ�,���������������ڲ���Ƭ������,������������ֺܶ��,�ͻ���ɺܶ��ڲ���Ƭ;
2.�����ռ����������ڶ���������������ڴ��,Ȼ����������������,������ʹ��,�ڳ���ִ�й�����,����������ڴ�һ��һ�鶼��������������,�����ỹ������ϵͳ,��������ʵ�������г�Աȫ�Ǿ�̬��,����������������ڴ�ֻ���ڽ��̽����Ż��ͷ��ڴ�,��������ϵͳ,�ɴ˴�����������:1.���Ҳ��ϵĿ���С���ڴ�,����������ϵĿռ䶼����������������,�����뿪�ٴ���ڴ�ͻ�ʧ��;2.�����������ϹҺܶ��ڴ��û�б�ʹ��,��ǰ������ռ���ڴ治�ͷ�,��ʱ��Ľ����ڶ������벻���ռ�,Ҳ������ʹ�õ�ǰ���̵Ŀ����ڴ�,�ɴ˾ͻ������������⡣
һ��������
GC4.9֮���û�е�һ����,ֻ�еڶ���
����������
����default_alloc_template ����
�и��Զ������ĺ���:�㴫��һ���ֽڲ���,��ʾ����Ҫ�����ڴ�,���Զ�����У�Ե��ڼ�������(0-15������,��С8�ֽ� ���128�ֽ�)
allocate����:���Ҫ������ڴ����128�ֽ�,��ת�õ�һ��������,����Ҳ����С��128�ֽڡ���ô�����ж����ڵڼ�������,��λ����,���ж������Dz��ǿ�,����ǿվ���Ҫ��ֵ,(���ڵ�8�ı���,Ĭ��һ������20������,��Ȼ��ҲҪ�ж�20���Dz����ܹ����뵽,���ֻ���뵽һ���Ǿ�ֱ�ӷ��غ���,��ֹһ���Ļ�,�ѵ�2����n�������ҵ���ǰ������,��һ�����ػ�ȥ��������,n�Dz�����20��,��Ȼ���������1-20֮��,�Ǿ����ڴ���Ƭ��,�Ǿ��Ȱ���Ƭ�ҵ�ijһ��������,Ȼ��������malloc��,malloc 2*20����)ȥ�ڴ��ȥ�û������·��䡣��Ϊ�յĻ�
9�� vector��list��������Ӧ��?��ô��ijvector����list�ĵ����ڶ���Ԫ��
-
vector���ݽṹ
vector����������,ӵ��һ���������ڴ�ռ�,������ʼ��ַ���䡣����ܸ�Ч�Ľ��������ȡ,ʱ�临�Ӷ�Ϊo(1);����Ϊ�ڴ�ռ���������,�����ڽ��в����ɾ������ʱ,������ڴ��Ŀ���,ʱ�临�Ӷ�Ϊo(n)������,���������ڴ�ռ䲻��ʱ,����������һ���ڴ�ռ䲢�����ڴ濽���������洢�ṹ:vector�ǿ���ʵ�ֶ�̬�����Ķ�������,֧�ֶ������Ч�ʵķ��ʺ�������β�˵�ɾ���Ͳ������,���м��ͷ��ɾ���Ͳ�����Բ���,��ҪŲ�����������ݡ��������������������vector�������Ա�Լ�ȥ������������,�����汾���Ѿ�ʵ���������Ķ�̬����,��������Ҫ����Ա�ֶ�д�����ݺ����������ݡ� -
list���ݽṹ
list����˫������ʵ�ֵ�,����ڴ�ռ��Dz������ġ�ֻ��ͨ��ָ���������,����list�������ȡ�dz�û��Ч��,ʱ�临�Ӷ�Ϊo(n);�������������ص�,�ܸ�Ч�ؽ��в����ɾ�����������洢�ṹ:list��һ��˫�����ṹ,֧�ֶ�������˫�������ÿ���ڵ����������Ϣ:Ԫ�ر���,ָ��ǰһ��Ԫ�صĽڵ�(prev)��ָ����һ��Ԫ�صĽڵ�(next)�����list���Ը�Ч�ʵĶ�����Ԫ������λ�ý��з��ʺͲ���ɾ���Ȳ����������漰�Զ���ָ���ά��,���Կ����Ƚϴ�
����:vector���������Ч�ʸ�,���ڲ����ɾ��ʱ(������β��)��ҪŲ������,���ײ�����list�ķ���Ҫ������������,�����������Ч�ʵ͡��������ݵIJ����ɾ�������ȶ��ȽϷ���,�ı�ָ���ָ�ɡ�list�ǵ����,vector��˫��ġ�vector�еĵ�������ʹ�ú��ʧЧ��,��list�ĵ�������ʹ��֮���Լ���ʹ�á�
int mySize = vec.size();vec.at(mySize -2);
list���ṩ�������,���Բ������±�ֱ�ӷ��ʵ�ij��λ�õ�Ԫ��,Ҫ����list���Ԫ��ֻ�ܱ���,������Ҫ��ֻ��Ҫ����list�����N��Ԫ�صĻ�,�����÷��������������:
10��STL ��vectorɾ�����е�Ԫ��,��������α仯?Ϊʲô����������?�ͷſռ�?
size()�������ص������ÿռ��С,capacity()���ص����ܿռ��С,capacity()-size()����ʣ��Ŀ��ÿռ��С����size()��capacity()���,˵��vectorĿǰ�Ŀռ��ѱ�����,�����������Ԫ��,�������vector�ռ�Ķ�̬������
���ڶ�̬�������������·����ڴ�ռ䡢����ԭ�ռ䡢�ͷ�ԭ�ռ�,��Щ���̻ή�ͳ���Ч�ʡ����,����ʹ��reserve(n)Ԥ�ȷ���һ��ϴ��ָ����С���ڴ�ռ�,������ָ����С���ڴ�ռ�δʹ����ʱ,�Dz������·����ڴ�ռ��,������������Ч�ʡ�ֻ�е�n>capacity()ʱ,����reserve(n)�Ż�ı�vector������
resize()��Ա����ֻ�ı�Ԫ�ص���Ŀ,���ı�vector��������
1���յ�vector����,size()��capacity()��Ϊ0
2�����ռ��С����ʱ,�·���Ŀռ��СΪԭ�ռ��С��2����
3��ʹ��reserve()Ԥ�ȷ���һ���ڴ��,�ڿռ�δ���������,�����������·���,�Ӷ�������Ч�ʡ�
4����reserve()����Ŀռ��ԭ�ռ�Сʱ,�Dz����������·���ġ�
5��resize()����ֻ�ı�������Ԫ����Ŀ,δ�ı�������С��
6����reserve(size_type)ֻ������capacityֵ,��Щ�ڴ�ռ���ܻ��ǡ�Ұ����,�����ʱʹ�á�[ ]��������,����ܻ�Խ�硣��resize(size_type new_size)������ʹ��������new_size������
��ͬ�ı�����,vector�в�ͬ�����ݴ�С����vs����1.5��,��GCC����2��;
�ռ��ʱ���Ȩ�⡣����˵, �ռ����Ķ�,ƽ̯ʱ�临�Ӷȵ�,���˷ѿռ�Ҳ�ࡣ
ʹ��k=2�������ӵ���������,ÿ����չ���³ߴ��Ȼ�պô���֮ǰ������ܺ�,Ҳ����˵,֮ǰ������ڴ�ռ䲻���ܱ�ʹ�á��������ڴ治�Ѻá���ð�����������Ϊ(1,2)
�Աȿ��Է��ֲ��ò��óɱ���ʽ����,���Ա�֤������ʱ�临�Ӷ�,������ָ����С������ֻ�ܴﵽO(n)��ʱ�临�Ӷ�,���,ʹ�óɱ��ķ�ʽ���ݡ�
11��Vector����ͷſռ�?
����vector���ڴ�ռ�ÿռ�ֻ������,���������ȷ�����10,000���ֽ�,Ȼ��erase������9,999��,����һ����ЧԪ��,�����ڴ�ռ����Ϊ10,000���������ڴ�ռ�����vector����ʱ����ܱ�ϵͳ���ա�empty()������������Ƿ�Ϊ�յ�,clear()�����������Ԫ�ء����Ǽ�ʹclear(),vector��ռ�õ��ڴ�ռ���Ȼ���,����֤�ڴ�Ļ��ա�
�����Ҫ�ռ䶯̬��С,���Կ���ʹ��deque�����vector,������swap()���������ͷ��ڴ档
vector(Vec).swap(Vec); //��Vec���ڴ����;
vector().swap(Vec); //���Vec���ڴ�;
vector�Ĵ���ʵ��
#include <iostream>
using namespace std;
/*
��ģ�� =�� ʵ��һ��C++ STL�����һ��˳������ vector ��������
SeqStack
Queue
����:
�ռ�������allocator
template<class _Ty,
class _Alloc = allocator<_Ty>>
class vector
�����Ŀռ�������allocator ���ļ����� �ڴ濪��/�ڴ��ͷ� ������/��������
*/
// ���������Ŀռ�������,��C++�����allocatorʵ��һ��
template<typename T>
struct Allocator
{
T* allocate(size_t size) // �����ڴ濪��
{
return (T*)malloc(sizeof(T) * size);
}
void deallocate(void *p) // �����ڴ��ͷ�
{
free(p);
}
void construct(T *p, const T &val) // ���������
{
new (p) T(val); // ��λnew
}
void destroy(T *p) // �����������
{
p->~T(); // ~T()������T���͵���������
}
};
/*
�����ײ��ڴ濪��,�ڴ��ͷ�,�����������,��ͨ��allocator�ռ���������ʵ��
*/
template<typename T, typename Alloc = Allocator<T>>
class vector
{
public:
vector(int size = 10)
{
// ��Ҫ���ڴ濪�ٺͶ�����ֿ�����
//_first = new T[size];
_first = _allocator.allocate(size);
_last = _first;
_end = _first + size;
}
~vector()
{
// ����������Ч��Ԫ��,Ȼ���ͷ�_firstָ��ָ��Ķ��ڴ�
// delete[]_first;
for (T *p = _first; p != _last; ++p)
{
_allocator.destroy(p); // ��_firstָ��ָ����������ЧԪ�ؽ�����������
}
_allocator.deallocate(_first); // �ͷŶ��ϵ������ڴ�
_first = _last = _end = nullptr;
}
vector(const vector<T> &rhs)
{
int size = rhs._end - rhs._first;
//_first = new T[size];
_first = _allocator.allocate(size);
int len = rhs._last - rhs._first;
for (int i = 0; i < len; ++i)
{
//_first[i] = rhs._first[i];
_allocator.construct(_first+i, rhs._first[i]);
}
_last = _first + len;
_end = _first + size;
}
vector<T>& operator=(const vector<T> &rhs)
{
if (this == &rhs)
return *this;
//delete[]_first;
for (T *p = _first; p != _last; ++p)
{
_allocator.destroy(p); // ��_firstָ��ָ����������ЧԪ�ؽ�����������
}
_allocator.deallocate(_first);
int size = rhs._end - rhs._first;
//_first = new T[size];
_first = _allocator.allocate(size);
int len = rhs._last - rhs._first;
for (int i = 0; i < len; ++i)
{
//_first[i] = rhs._first[i];
_allocator.construct(_first + i, rhs._first[i]);
}
_last = _first + len;
_end = _first + size;
return *this;
}
void push_back(const T &val) // ������ĩβ����Ԫ��
{
if (full())
expand();
//*_last++ = val; _lastָ��ָ����ڴ湹��һ��ֵΪval�Ķ���
_allocator.construct(_last, val);
_last++;
}
void pop_back() // ������ĩβɾ��Ԫ��
{
if (empty())
return;
//--_last; // ����Ҫ��_lastָ��--,����Ҫ����ɾ����Ԫ��
--_last;
_allocator.destroy(_last);
}
T back()const // ��������ĩβ��Ԫ�ص�ֵ
{
return *(_last - 1);
}
bool full()const { return _last == _end; }
bool empty()const { return _first == _last; }
int size()const { return _last - _first; }
private:
T *_first; // ָ��������ʼ��λ��
T *_last; // ָ����������ЧԪ�صĺ��λ��
T *_end; // ָ������ռ�ĺ��λ��
Alloc _allocator; // ���������Ŀռ�����������
void expand() // �����Ķ�������
{
int size = _end - _first;
//T *ptmp = new T[2 * size];
T *ptmp = _allocator.allocate(2*size);
for (int i = 0; i < size; ++i)
{
//ptmp[i] = _first[i];
_allocator.construct(ptmp+i, _first[i]);
}
//delete[]_first;
for (T *p = _first; p != _last; ++p)
{
_allocator.destroy(p);
}
_allocator.deallocate(_first);
_first = ptmp;
_last = _first + size;
_end = _first + 2 * size;
}
};
class Test
{
public:
Test() { cout << "Test()" << endl; }
~Test() { cout << "~Test()" << endl; }
Test(const Test&) { cout << "Test(const Test&)" << endl; }
};
int main()
{
Test t1, t2, t3;
cout << "-------------------" << endl;
vector<Test> vec;
vec.push_back(t1);
vec.push_back(t2);
vec.push_back(t3);
cout << "-------------------" << endl;
vec.pop_back(); // ֻ��Ҫ�������� Ҫ�Ѷ�����������ڴ��ͷŷ��뿪 delete
cout << "-------------------" << endl;
return 0;
}
#include<iostream>
using namespace std;
#include<memory.h>
// alloc��SGI STL�Ŀռ�������
template <class T, class Alloc = alloc>
class vector
{
public:
// vector��Ƕ�����Ͷ���,typedef�����ṩiterator_traits<I>֧��
typedef T value_type;
typedef value_type* pointer;
typedef value_type* iterator;
typedef value_type& reference;
typedef size_t size_type;
typedef ptrdiff_t difference_type;
protected:
// ����ṩSTL����allocator�ӿ�
typedef simple_alloc <value_type, Alloc> data_allocator;
iterator start; // ��ʾĿǰʹ�ÿռ��ͷ
iterator finish; // ��ʾĿǰʹ�ÿռ��β
iterator end_of_storage; // ��ʾʵ�ʷ����ڴ�ռ��β
void insert_aux(iterator position, const T& x);
// �ͷŷ�����ڴ�ռ�
void deallocate()
{
// ����ʹ�õ���data_allocator�����ڴ�ռ�ķ���,
// ������Ҫͬ��ʹ��data_allocator::deallocate()�����ͷ�
// ���ֱ���ͷ�, ����data_allocator�ڲ�ʹ���ڴ�صİ汾
// �ͻᷢ������
if (start)
data_allocator::deallocate(start, end_of_storage - start);
}
void fill_initialize(size_type n, const T& value)
{
start = allocate_and_fill(n, value);
finish = start + n; // ���õ�ǰʹ���ڴ�ռ�Ľ�����
// �����, ��ʵ����������ڴ�,
// ����Ҫ�����ڴ�ռ�������, �Ѿ�ʹ�õ��ڴ�ռ��������ͬ
end_of_storage = finish;
}
public:
// ��ȡ���ֵ�����
iterator begin() { return start; }
iterator end() { return finish; }
// ���ص�ǰ�������
size_type size() const { return size_type(end() - begin()); } //����,�����size()���ѵ�Ӧ���dz���ʱ���
size_type max_size() const { return size_type(-1) / sizeof(T); }
// �������·����ڴ�ǰ����ܴ洢�Ķ������
size_type capacity() const { return size_type(end_of_storage - begin()); }
bool empty() const { return begin() == end(); } //��ʵ�����empty��size��������ܴ��
reference operator[](size_type n) { return *(begin() + n); }
// ��ʵ����Ĭ�Ϲ������vector�������ڴ�ռ�
vector() : start(0), finish(0), end_of_storage(0) {}
vector(size_type n, const T& value) { fill_initialize(n, value); }
vector(int n, const T& value) { fill_initialize(n, value); }
vector(long n, const T& value) { fill_initialize(n, value); }
// ��Ҫ�����ṩĬ�Ϲ��캯��
explicit vector(size_type n) { fill_initialize(n, T()); }
vector(const vector<T, Alloc>& x)
{
start = allocate_and_copy(x.end() - x.begin(), x.begin(), x.end());
finish = start + (x.end() - x.begin());
end_of_storage = finish;
}
//û�д�����������Ŷ
~vector()
{
// ��������
destroy(start, finish);
// �ͷ��ڴ�
deallocate();
}
vector<T, Alloc>& operator=(const vector<T, Alloc>& x);
// �ṩ���ʺ���
reference front() { return *begin(); }
reference back() { return *(end() - 1); }
// ������β��һ��Ԫ��, ���ܵ����ڴ����·���
// push_back(const T& x)
// |
// |---------------- ��������?
// |
// ----------------------------
// No | | Yes
// | |
// �� ��
// construct(finish, x); insert_aux(end(), x);
// ++finish; |
// |------ �ڴ治��, ���·���
// | ��СΪԭ����2��
// new_finish = data_allocator::allocate(len); <stl_alloc.h>
// uninitialized_copy(start, position, new_start); <stl_uninitialized.h>
// construct(new_finish, x); <stl_construct.h>
// ++new_finish;
// uninitialized_copy(position, finish, new_finish); <stl_uninitialized.h>
void push_back(const T& x)
{
// �ڴ�����������ֱ����Ԫ��, ������Ҫ���·����ڴ�ռ�
if (finish != end_of_storage)
{
construct(finish, x);
++finish;
}
else
insert_aux(end(), x);
}
// ��ָ��λ�ò���Ԫ��
// insert(iterator position, const T& x)
// |
// |------------ �����Ƿ��㹻 && �Ƿ���end()?
// |
// -------------------------------------------
// No | | Yes
// | |
// �� ��
// insert_aux(position, x); construct(finish, x);
// | ++finish;
// |-------- �����Ƿ���?
// |
// --------------------------------------------------
// Yes | | No
// | |
// �� |
// construct(finish, *(finish - 1)); |
// ++finish; |
// T x_copy = x; |
// copy_backward(position, finish - 2, finish - 1); |
// *position = x_copy; |
// ��
// data_allocator::allocate(len); <stl_alloc.h>
// uninitialized_copy(start, position, new_start); <stl_uninitialized.h>
// construct(new_finish, x); <stl_construct.h>
// ++new_finish;
// uninitialized_copy(position, finish, new_finish); <stl_uninitialized.h>
// destroy(begin(), end()); <stl_construct.h>
// deallocate();
iterator insert(iterator position, const T& x)
{
size_type n = position - begin();
if (finish != end_of_storage && position == end())
{
construct(finish, x);
++finish;
}
else
insert_aux(position, x);
return begin() + n;
}
iterator insert(iterator position) { return insert(position, T()); }
void pop_back()
{
--finish;
destroy(finish);
}
iterator erase(iterator position)
{
if (position + 1 != end())
copy(position + 1, finish, position);
--finish;
destroy(finish);
return position;
}
iterator erase(iterator first, iterator last)
{
iterator i = copy(last, finish, first);
// ��������Ҫ������Ԫ��
destroy(i, finish);
finish = finish - (last - first);
return first;
}
// ����size, ���Dz��������·����ڴ�ռ�
void resize(size_type new_size, const T& x)
{
if (new_size < size())
erase(begin() + new_size, end());
else
insert(end(), new_size - size(), x);
}
void resize(size_type new_size) { resize(new_size, T()); }
void clear() { erase(begin(), end()); }
protected:
// ����ռ�, ���Ҹ��ƶ�����Ŀռ䴦
iterator allocate_and_fill(size_type n, const T& x)
{
iterator result = data_allocator::allocate(n);
uninitialized_fill_n(result, n, x);
return result;
}
// �ṩ�������
// insert_aux(iterator position, const T& x)
// |
// |---------------- �����Ƿ��㹻?
// ��
// -----------------------------------------
// Yes | | No
// | |
// �� |
// ��opsition��ʼ, ��������ƶ�һ��λ�� |
// construct(finish, *(finish - 1)); |
// ++finish; |
// T x_copy = x; |
// copy_backward(position, finish - 2, finish - 1); |
// *position = x_copy; |
// ��
// data_allocator::allocate(len);
// uninitialized_copy(start, position, new_start);
// construct(new_finish, x);
// ++new_finish;
// uninitialized_copy(position, finish, new_finish);
// destroy(begin(), end());
// deallocate();
template <class T, class Alloc>
void insert_aux(iterator position, const T& x)
{
if (finish != end_of_storage) // ���б��ÿռ�
{
// �ڱ��ÿռ���ʼ������һ��Ԫ��,����vector���һ��Ԫ��ֵΪ���ֵ
construct(finish, *(finish - 1));
++finish;
T x_copy = x;
copy_backward(position, finish - 2, finish - 1);
*position = x_copy;
}
else // ���ޱ��ÿռ�
{
const size_type old_size = size();
const size_type len = old_size != 0 ? 2 * old_size : 1;
// ��������Ԫ��:�����СΪ0,������1(��Ԫ�ش�С)
// �����С��Ϊ0,������ԭ����С������
// ǰ�����������ԭ����,��������������������
iterator new_start = data_allocator::allocate(len); // ʵ������
iterator new_finish = new_start;
// ���ڴ���������
try
{
// ��ԭvector�İ������ǰ�����ݿ�������vector
new_finish = uninitialized_copy(start, position, new_start);
// Ϊ��Ԫ���趨��ֵ x
construct(new_finish, x);
// ����ˮλ
++new_finish;
// ��������Ժ��ԭ����Ҳ��������
new_finish = uninitialized_copy(position, finish, new_finish);
}
catch(...)
{
// �ع�����
destroy(new_start, new_finish);
data_allocator::deallocate(new_start, len);
throw;
}
// �������ͷ�ԭvector
destroy(begin(), end());
deallocate();
// ����������,ָ����vector
start = new_start;
finish = new_finish;
end_of_storage = new_start + len;
}
}
// ��ָ��λ�ò���n��Ԫ��
// insert(iterator position, size_type n, const T& x)
// |
// |---------------- ����Ԫ�ظ����Ƿ�Ϊ0?
// ��
// -----------------------------------------
// No | | Yes
// | |
// | ��
// | return;
// |----------- �ڴ��Ƿ��㹻?
// |
// -------------------------------------------------
// Yes | | No
// | |
// |------ (finish - position) > n? |
// | �ֱ����ָ�� |
// �� |
// ---------------------------- |
// No | | Yes |
// | | |
// �� �� |
// �������, ����ָ�� �������, ����ָ�� |
// ��
// data_allocator::allocate(len);
// new_finish = uninitialized_copy(start, position, new_start);
// new_finish = uninitialized_fill_n(new_finish, n, x);
// new_finish = uninitialized_copy(position, finish, new_finish);
// destroy(start, finish);
// deallocate();
template <class T, class Alloc>
void insert(iterator position, size_type n, const T& x) //ע�⿴,���ﴫ�������ǿ���
{
// ���nΪ0�����κβ���
if (n != 0)
{
if (size_type(end_of_storage - finish) >= n)
{ // ʣ�µı��ÿռ���ڵ��ڡ�����Ԫ�صĸ�����
T x_copy = x;
// ���¼�������֮�������Ԫ�ظ���
const size_type elems_after = finish - position;
iterator old_finish = finish;
if (elems_after > n)
{
// �����֮�������Ԫ�ظ��� ���� ����Ԫ�ظ���
uninitialized_copy(finish - n, finish, finish);
finish += n; // ��vector β�˱�Ǻ���
copy_backward(position, old_finish - n, old_finish);
fill(position, position + n, x_copy); // �Ӳ���㿪ʼ������ֵ
}
else
{
// �����֮�������Ԫ�ظ��� С�ڵ��� ����Ԫ�ظ���
uninitialized_fill_n(finish, n - elems_after, x_copy);
finish += n - elems_after;
uninitialized_copy(position, old_finish, finish);
finish += elems_after;
fill(position, old_finish, x_copy);
}
}
else
{ // ʣ�µı��ÿռ�С�ڡ�����Ԫ�ظ�����(�Ǿͱ������ö�����ڴ�)
// ���Ⱦ����³���:�ͳ��ȵ����� , ��ɳ���+����Ԫ�ظ���
const size_type old_size = size();
const size_type len = old_size + max(old_size, n);
// ���������µ�vector�ռ�
iterator new_start = data_allocator::allocate(len);
iterator new_finish = new_start;
__STL_TRY
{
// �������Ƚ��ɵ�vector�IJ����֮ǰ��Ԫ�ظ��Ƶ��¿ռ�
new_finish = uninitialized_copy(start, position, new_start);
// �����ٽ�����Ԫ��(��ֵ��Ϊn)�����¿ռ�
new_finish = uninitialized_fill_n(new_finish, n, x);
// �����ٽ���vector�IJ����֮���Ԫ�ظ��Ƶ��¿ռ�
new_finish = uninitialized_copy(position, finish, new_finish);
}
# ifdef __STL_USE_EXCEPTIONS
catch(...)
{
destroy(new_start, new_finish);
data_allocator::deallocate(new_start, len);
throw;
}
# endif /* __STL_USE_EXCEPTIONS */
destroy(start, finish);
deallocate();
start = new_start;
finish = new_finish;
end_of_storage = new_start + len;
}
}
}
};
12�������ڲ�ɾ��һ��Ԫ��
- ˳������(����ʽ����,����vector��deque)
erase����������ʹ��ָ��ɾ���ĵ�����ʧЧ,����ʹ��ɾԪ��֮������е�����ʧЧ(list����),���Բ���ʹ��erase(it++)�ķ�ʽ,����erase�ķ���ֵ����һ����Ч������;
It = c.erase(it);
- ��������(����ʽ����,����map��set��multimap��multiset��)
erase������ֻ�DZ�ɾ��Ԫ�صĵ�����ʧЧ,���Ƿ���ֵ��void,����Ҫ����erase(it++)�ķ�ʽɾ��������;
c.erase(it++)
13��STL���������ʵ��
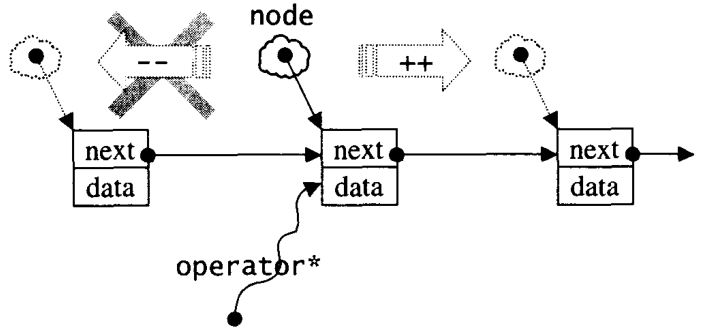
1�� ��������һ�ֳ�����������,ͨ�������������ڲ��˽������ڲ�ԭ��������±�������,����֮��,STL�е�����һ������Ҫ�����þ�����Ϊ������STL�㷨��ճ�ϼ���
2�� �����������þ����ṩһ�����������ڲ�����Ԫ�صĽӿ�,��˵������ڲ����뱣��һ���������������ָ��,Ȼ�����ظ����������������,��������Ҫ����*�������->�����,�Լ�++���C�ȿ�����Ҫ���ص���������ء����C++�е�����ָ�����,����ָ��Ҳ�ǽ�һ��ָ���װ,Ȼ��ͨ�����ü�������������������Զ��ͷ��ڴ�Ĺ��ܡ�
3����õĵ���������Ӧ�ͱ�������:value type��difference type��pointer��reference��iterator catagoly;
14��map��set����ôʵ�ֵ�,���������ô�ܹ�ͬʱʵ������������? Ϊʲôʹ�ú����?
-
���ǵĵײ㶼���Ժ�����Ľṹʵ��,��˲���ɾ���Ȳ�������O(lognʱ�������,��˿�����ɸ�Ч�IJ���ɾ��;
-
���������Ƕ�����һ��ģ�����,�������key��ô������set,�������map,��ô������map;�ײ��Ǻ����,ʵ��map�ĺ�����Ľڵ�����������key+value,��ʵ��set�Ľڵ�����������value
-
��Ϊmap��setҪ�����Զ������,������ܹ�ʵ����һ����,����ʱ�临�ӶȱȽϵ͡�
15������ڹ����ڴ���ʹ��STL����?
- ����һ�°�STL����,����map, vector, list�ȵ�,���빲���ڴ���,IPCһ��������Щǿ���ͨ�����ݽṹ������,���ɽ��̼�ͨ�ŵ�����һ����ǿ���˺ܶࡣ
����û��Ҫ��Ϊ�����ڴ����������������ݽṹ,����,STL�ĸ߶ȿ���չ�Խ�ΪIPC����ʹ��STL���������õķ�װ,Ĭ��������������Լ����ڴ����������
��һ��Ԫ�ر����뵽һ��STL�б�(list)��ʱ,�б������Զ�Ϊ������ڴ�,�������ݡ����ǵ�Ҫ��STL�����ŵ������ڴ���,������ȴ�Լ��ڶ��Ϸ����ڴ档
һ����İ취���ڶ��Ϲ���STL����,Ȼ����������Ƶ������ڴ�,����ȷ�������������ڲ�������ڴ�ָ�����ڴ��е���Ӧ����,������Ǹ���������ɵ�����
- �������A�ڹ����ڴ��з�������������,����B����ҵ���Щ������?
һ���������ǽ���A���������ڹ����ڴ��е�ȷ����ַ��(fixed offsets),�����B���ԴӸ���֪��ַ�ϻ�ȡ����������һ���Ľ���İ취��,����A���ڹ����ڴ�ij��ȷ����ַ�Ϸ���һ��map����,Ȼ�����A�ٴ�����������,Ȼ�����ȡ�����ֺ͵�ַһ�����浽���map�����
����B֪����λ�ȡ�ñ����˵�ַӳ���map����,Ȼ��ͬ���ٸ�������ȡ�����������ĵ�ַ��
16��map���뷽ʽ���ļ���?
- ��insert��������pair����,
mapStudent.insert(pair<int, string>(1, "student_one"));
- ��insert��������value_type����
mapStudent.insert(map<int, string>::value_type (1, "student_one"));
- ��insert������ʹ��make_pair()����
mapStudent.insert(make_pair(1, "student_one"));
- �����鷽ʽ��������
mapStudent[1] = "student_one";
17��STL��unordered_map(hash_map)��map������,hash_map��ν����ͻ�Լ�����
-
unordered_map��map����,���Ǵ洢��key-value��ֵ,����ͨ��key����������value����ͬ����unordered_map�������key�Ĵ�С��������,
-
�洢ʱ�Ǹ���key��hashֵ�ж�Ԫ���Ƿ���ͬ,��unordered_map�ڲ�Ԫ���������,��map�е�Ԫ���ǰ��ն����������洢,�������������õ����������
-
����ʹ��ʱmap��key��Ҫ����operator<����unordered_map��Ҫ����hash_value������������operator==�����Ǻܶ�ϵͳ���õ��������Ͷ��Դ���Щ,
-
��ô������Զ�������,��ô����Ҫ�Լ�����operator<����hash_value()�ˡ�
-
�����Ҫ�ڲ�Ԫ���Զ�����,ʹ��map,����Ҫ����ʹ��unordered_map
-
unordered_map�ĵײ�ʵ����hash_table;
-
hash_map�ײ�ʹ�õ���hash_table,��hash_tableʹ�õĿ��������г�ͻ����,����hash_map���ÿ��������г�ͻ�����
-
**ʲôʱ������:**������������Ԫ�ص�ʱ��,���жϵ�ǰ������Ԫ�ظ���,������ڵ�����ֵ������ǰ����ij��ȳ��Լ������ӵ�ֵ��ʱ��,��Ҫ�Զ���������
-
**����(resize)**�������¼�������,��HashMap�����ﲻͣ������Ԫ��,��HashMap�����ڲ���������װ�ظ����Ԫ��ʱ,�������Ҫ��������ij���,�Ա���װ������Ԫ�ء�
18��vectorԽ������±�,mapԽ������±�?vectorɾ��Ԫ��ʱ����ͷſռ�?
-
ͨ���±����vector�е�Ԫ��ʱ�����߽���,���ô���ʵ�ַ�ʽҪ������IDE,��ͬIDE��ʵ�ַ�ʽ��һ��,ȷ�����ɷ���Խ���ַ��
-
map���±������[]��������:��key��Ϊ�±�ȥִ�в���,��������Ӧ��ֵ;������������key,�ͽ�һ�����и�key��value��ij��ֵ�������map��
-
erase()����,ֻ��ɾ������,���ܸı�������С;
erase��Ա����,��ɾ����itVect������ָ���Ԫ��,���ҷ���Ҫ��ɾ����itVect֮��ĵ�����,�������൱��һ������ָ��;clear()����,ֻ���������,���ܸı�������С;���Ҫ����ɾ�����ݵ�ͬʱ�ͷ��ڴ�,��ô�����ѡ��deque������
update1:��л�ź��ѡ�Գ��ѧ�㷨��ָ������,������!
update2:��л�ź��ѡ�������硱����:��vector�߽��顱-> ���忴IDE��ʵ�ַ�ʽ,���Dz���ȡԽ���ַ-2021.06.28
19��map��[]��find������?
-
map���±������[]��������:���ؼ�����Ϊ�±�ȥִ�в���,�����ض�Ӧ��ֵ;�������������ؼ���,�ͽ�һ�����иùؼ����ֵ���͵�Ĭ��ֵ����������map��
-
map��find����:�ùؼ���ִ�в���,�ҵ��˷��ظ�λ�õĵ�����;�������������ؼ���,�ͷ���β��������
20�� STL��list��queue֮�������
-
list�����ܹ���vectorһ������ָͨ����Ϊ������,��Ϊ��ڵ㲻��֤�ڴ洢�ռ�����������;
-
list��������ͽ�ϲ������������ԭ�е�list������ʧЧ;
-
list������һ��˫������,���һ���һ����״˫������,������ֻ��Ҫһ��ָ��;
-
list����vector�����п����ڿռ䲻��ʱ���������á������ƶ��IJ���,���Բ���ǰ�����е������ڲ������֮����Ȼ��Ч;
-
deque��һ��˫�ڵ��������Կռ�,��ν˫��,��˼�ǿ�����ͷβ���˷ֱ���Ԫ�صIJ����ɾ������;������ͷβ���˷ֱ���Ԫ�صIJ����ɾ������;
-
deque��vector���IJ���,һ����deque��������ʱ���ڶ���ͷ�˽���Ԫ�صIJ�����Ƴ�����,������dequeû����ν��������,��Ϊ���Ƕ�̬���Էֶ������ռ���϶���,��ʱ��������һ���µĿռ䲢��������,dequeû����ν�Ŀռ䱣�����ܡ�
21��STL�е�allocator��deallocator
-
��һ��������ֱ��ʹ��malloc()��free()��relloc(),�ڶ�����������������ò�ͬ�IJ���:���������鳬��128bytesʱ,��֮Ϊ�㹻��,����õ�һ��������;������������С��128bytesʱ,Ϊ�˽��Ͷ��⸺��,ʹ�ø��ӵ��ڴ��������ʽ,��������һ��������;
-
�ڶ����������������κ�С��������ڴ��������ϵ���8�ı���,��ά��16��free-list,���Թ�����СΪ8~128bytes��С������;
-
�ռ����ú���allocate(),�����ж������С,����128��ֱ�ӵ��õ�һ��������,С��128ʱ�ͼ���Ӧ��free-list�����free-list֮���п�������,��ֱ��������,���û�п�������,�ͽ������С������8�ı���,Ȼ�����refill(),Ϊfree-list���·���ռ�;
-
�ռ��ͷź���deallocate(),�ú��������ж������С,����128bytesʱ,ֱ�ӵ���һ��������,С��128bytes���ҵ���Ӧ��free-listȻ���ͷ��ڴ档
22��STL��hash_map���ݷ���ʲô?
-
hash table�����ڵ�Ԫ�س�ΪͰ(bucket),����Ͱ�����ӵ�Ԫ�س�Ϊ�ڵ�(node),���д���ͰԪ�ص�����Ϊstl��������Ҫ��һ������ʽ��������vector������֮����ѡ��vectorΪ���ͰԪ�صĻ�������,��Ҫ����Ϊvector�����������ж�̬��������,�����˹���Ԥ��
-
��ǰ����:���ȳ��Դ�Ŀǰ��ָ�Ľڵ����,ǰ��һ��λ��(�ڵ�),���ڽڵ㱻������list��,�������ýڵ��nextָ�뼴���������ǰ������,���Ŀǰ������list��β��,��������һ��bucket����,������ָ����һ��list��ͷ���ڵ㡣
23���������������ܽ�?
1.vector �ײ����ݽṹΪ���� ,֧�ֿ����������
2.list �ײ����ݽṹΪ˫������,֧�ֿ�����ɾ
3.deque �ײ����ݽṹΪһ������������Ͷ��������,��ϸ��STLԴ������P146,֧����β(�м䲻��)������ɾ,Ҳ֧���������
deque��һ��˫�˶���(double-ended queue),Ҳ���ڶ��б������ݵ�.���ı�����ʽ����:
[��1] --> [��2] -->[��3] --> ��
ÿ���ѱ���ü���Ԫ��,Ȼ��ѺͶ�֮����ָ��ָ��,����������list��vector�Ľ��Ʒ.
4.stack �ײ�һ����list��dequeʵ��,���ͷ������,����vector��ԭ��Ӧ����������С������,���ݺ�ʱ
5.queue �ײ�һ����list��dequeʵ��,���ͷ������,����vector��ԭ��Ӧ����������С������,���ݺ�ʱ(stack��queue��ʵ��������,����������,��Ϊ�Ƕ��������ٷ�װ)
6.priority_queue �ĵײ����ݽṹһ��ΪvectorΪ�ײ�����,��heapΪ���������������ײ�����ʵ��
7.set �ײ����ݽṹΪ�����,����,���ظ�
8.multiset �ײ����ݽṹΪ�����,����,���ظ�
9.map �ײ����ݽṹΪ�����,����,���ظ�
10.multimap �ײ����ݽṹΪ�����,����,���ظ�
11.unordered_set �ײ����ݽṹΪhash��,����,���ظ�
12.unordered_multiset �ײ����ݽṹΪhash��,����,���ظ�
13.unordered_map �ײ����ݽṹΪhash��,����,���ظ�
14.unordered_multimap �ײ����ݽṹΪhash��,����,���ظ�
24��vector������ɾ��������ô����?Ϊʲô��1.5������2��?
-
����Ԫ��:vectorͨ��һ��������������Ԫ��,�����������,���������ݵ�ʱ��,��Ҫ����һ�������ڴ�,��ԭ�������ݸ��ƹ���,�ͷ�֮ǰ���ڴ�,�ڲ���������Ԫ��;
-
��vector���κβ���,һ������ռ���������,ָ��ԭvector�����е������Ͷ�ʧЧ�� ;
-
��ʼʱ��vector��capacityΪ0,�����һ��Ԫ�غ�capacity����Ϊ1;
-
��ͬ�ı�����ʵ�ֵ����ݷ�ʽ��һ��,VS2015����1.5������,GCC��2�����ݡ�
�Աȿ��Է��ֲ��ò��óɱ���ʽ����,���Ա�֤������ʱ�临�Ӷ�,������ָ����С������ֻ�ܴﵽO(n)��ʱ�临�Ӷ�,���,ʹ�óɱ��ķ�ʽ���ݡ�
-
���ǿ��ܲ����Ķѿռ��˷�,�ɱ�������������̫��,ʹ�ý�Ϊ�㷺�����ݷ�ʽ������,��2�����ķ�ʽ����,������1.5���ķ�ʽ���ݡ�
-
��2���ķ�ʽ����,������һ��������ڴ��Ȼ����֮ǰ�����ڴ���ܺ�,����֮ǰ������ڴ治���ٱ�ʹ��,������ñ�������������Ϊ(1,2)֮��:
-
��������vector�ij�Ա����pop_back()����ɾ�����һ��Ԫ��.
-
������erase()����ɾ����һ��iteratorָ����Ԫ��,Ҳ����ɾ��һ��ָ����Χ��Ԫ�ء�
-
�����Բ���ͨ���㷨remove()��ɾ��vector�����е�Ԫ��.
-
��ͬ����:����removeһ������²���ı������Ĵ�С,��pop_back()��erase()�ȳ�Ա������ı������Ĵ�С��
25��˵һ��STLÿ��������Ӧ�ĵ�����
| ���� | ������ |
|---|---|
| vector��deque | ������ʵ����� |
| stack��queue��priority_queue | �� |
| list��(multi)set/map | ˫������� |
| unordered_(multi)set/map��forward_list | ǰ������� |
26��STL�е�����ʧЧ���������Щ?
��vector��:
����Ԫ��:
1��β�����:size < capacityʱ,��������ʧЧβ����ʧЧ(δ���·���ռ�),size == capacityʱ,���е�������ʧЧ(��Ҫ���·���ռ�)��
2���м����:�м����:size < capacityʱ,��������ʧЧ������Ԫ��֮�����е�����ʧЧ,size == capacityʱ,���е�������ʧЧ��
ɾ��Ԫ��:
β��ɾ��:ֻ��β����ʧЧ��
�м�ɾ��:ɾ��λ��֮�����е���ʧЧ��
deque �� vector ���������,
��list˫������ÿһ���ڵ��ڴ治����, ɾ���ڵ����ǰ������ʧЧ,erase������һ����Ч������;
map/set�ȹ��������ײ��Ǻ����ɾ���ڵ㲻��Ӱ�������ڵ�ĵ�����, ʹ�õ���������ȡ��һ�������� mmp.erase(iter++);
unordered_(hash) ���������岻��, rehash֮��, ������Ӧ��Ҳ��ȫ��ʧЧ.
27��STL��vector��ʵ��
vector��һ������ʽ����,�����ݰ����Լ�������ʽ��array�dz�����,���ߵ�Ψһ�����Ƕ��ڿռ����õ������,������֪,arrayռ�õ��Ǿ�̬�ռ�,һ�������˾Ͳ����Ըı��С,��������ռ䲻��������Ҫ���д�������Ŀռ�,���ֶ������ݿ������µĿռ���,�ٰ�ԭ���Ŀռ��ͷš�vector��ʹ�����Ķ�̬�ռ�����,ά��һ�����������Կռ�,�ڿռ䲻��ʱ,�����Զ���չ�ռ�������Ԫ��,�������蹩������������ռ�Ĺ�������Ȼ��Ҫ����:�������ÿռ�,�ƶ�����,�ͷ�ԭ�ռ��Ȳ�����������Ҫ˵��һ�¶�̬���ݵĹ���:��ԭ��С��������������һ��ϴ�Ŀռ�(���߾ɳ���+����Ԫ�صĸ���),Դ��:
const size_type len = old_size + max(old_size, n);
Vector���ݱ�����ƽ̨�й�,��Win + VS ���� 1.5��,�� Linux + GCC ���� 2 ��
���Դ���:
#include <iostream>
#include <vector>
using namespace std;
int main()
{
//��Linux + GCC��
vector<int> res(2,0);
cout << res.capacity() <<endl; //2
res.push_back(1);
cout << res.capacity() <<endl;//4
res.push_back(2);
res.push_back(3);
cout << res.capacity() <<endl;//8
return 0;
//�� win 10 + VS2019��
vector<int> res(2,0);
cout << res.capacity() <<endl; //2
res.push_back(1);
cout << res.capacity() <<endl;//3
res.push_back(2);
res.push_back(3);
cout << res.capacity() <<endl;//6
}
������������,һ��ʼ������һ�鳤��Ϊ2�Ŀռ�,����������һ������,���ȱ�Ϊԭ��������,Ϊ4,��ʱ��ռ�õij���Ϊ3,�ټ�����������,��ʱ���ȱ�Ϊ8,���������Ŀ����ռ�ı仯����
��Ҫע�����,Ƶ����vector����push_back()����������Ӱ���,������Ϊÿ����һ��Ԫ��,����ռ乻�õĻ�����ֱ�Ӳ���,���ռ䲻����,����Ҫ�������ÿռ�,�ƶ�����,�ͷ�ԭ�ռ�Ȳ���,�Գ������ܻ����һ����Ӱ��
28��STL��slist��ʵ��
list��˫������,��slist(single linked list)�ǵ�������,���ǵ���Ҫ��������:ǰ�ߵĵ�������˫���Bidirectional iterator,���ߵĵ��������ڵ����Forward iterator����Ȼslist�ĺܶ�ܲ���list���,�����������õĿռ��С,�������졣
����STL��ϰ��,��������Ὣ��Ԫ�ز��뵽ָ��λ��֮ǰ,����֮��,Ȼ��slist�Dz��ܻ�ͷ��,ֻ��������,�����slist������λ�ò�������Ƴ�Ԫ����ʮ�ֲ����ǵ�,������slist��ͷȴ�ǿ�ȡ��,slist�ر��ṩ��insert_after()��erase_after�����Ӧ�á����ǵ�Ч������,slistֻ�ṩpush_front()����,Ԫ�ز��뵽slist��,�洢�Ĵ��������Ĵ������෴��
slist�ĵ������������ͼ��ʾ:
slistĬ�ϲ���alloc�ռ����������ýڵ�Ŀռ�,�����ݽṹ��Ҫ��������
template <class T, class Allco = alloc>
class slist
{
...
private:
...
static list_node* create_node(const value_type& x){}//���ÿռ䡢����Ԫ��
static void destroy_node(list_node* node){}//�����������ͷſռ�
private:
list_node_base head; //ͷ��
public:
iterator begin(){}
iterator end(){}
size_type size(){}
bool empty(){}
void swap(slist& L){}//��������slist,ֻ��Ҫ��head����
reference front(){} //ȡͷ��Ԫ��
void push_front(const value& x){}//ͷ������Ԫ��
void pop_front(){}//��ͷ��ȡ��Ԫ��
...
}
�ٸ�����:
#include <forward_list>
#include <algorithm>
#include <iostream>
using namespace std;
int main()
{
forward_list<int> fl;
fl.push_front(1);
fl.push_front(3);
fl.push_front(2);
fl.push_front(6);
fl.push_front(5);
forward_list<int>::iterator ite1 = fl.begin();
forward_list<int>::iterator ite2 = fl.end();
for(;ite1 != ite2; ++ite1)
{
cout << *ite1 <<" "; // 5 6 2 3 1
}
cout << endl;
ite1 = find(fl.begin(), fl.end(), 2); //Ѱ��2��λ��
if (ite1 != ite2)
fl.insert_after(ite1, 99);
for (auto it : fl)
{
cout << it << " "; //5 6 2 99 3 1
}
cout << endl;
ite1 = find(fl.begin(), fl.end(), 6); //Ѱ��6��λ��
if (ite1 != ite2)
fl.erase_after(ite1);
for (auto it : fl)
{
cout << it << " "; //5 6 99 3 1
}
cout << endl;
return 0;
}
��Ҫע�����C++��ίԱ��û�в���slist������,forward_list��C++ 11�г���,����slist��������û��size()������
29��STL��list��ʵ��
�����vector���������Ϳռ�,list�Եø�������,�������ĺô����ڲ����ɾ����ֻ������һ��Ԫ�ؿռ�,���list�Կռ��������ʮ�־���,���κ�λ��Ԫ�صIJ����ɾ�����dz���ʱ�䡣list���ܱ�֤�ڵ��ڴ洢�ռ��������洢,Ҳӵ�е�����,�������ġ�++�������C���������ڵ���ָ��IJ���,list�ṩ�ĵ�����������˫�������:Bidirectional iterators��
list�ڵ�Ľṹ������Դ��:
template <class T>
struct __list_node{
typedef void* void_pointer;
void_pointer prev;
void_pointer next;
T data;
}
��Դ��ɿ���list��Ȼ��һ��˫��������list��vector����һ��������,�ڲ���ͽӺϲ���֮��,���������ԭ������ʧЧ,��vector������Ϊ�ռ��������õ��µ�����ʧЧ��
����listҲ��һ����������,���ֻҪһ��ָ�����������������������list��node�ڵ�ָ��ʼ��ָ��β�˵�һ���հڵ�,�����һ�֡�ǰ�պ�������ṹ
list�Ŀռ����Ĭ�ϲ���alloc��Ϊ�ռ�������,Ϊ�˷�����Խڵ��СΪ���õ�λ,������һ��list_node_allocator������һ�������ö���ڵ�ռ�
����list��˫������,��֧����ͷ��(front)��β��(back)�����������push��pop����,��Ȼ��֧��erase,splice,sort,merge,reverse,sort�Ȳ���,���ﲻ����ϸ������
30��STL�е�deque��ʵ��
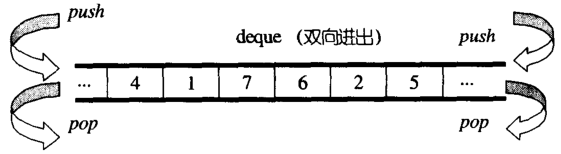
vector�ǵ���(β��)���������Կռ�,deque����һ��˫�ڵ��������Կռ�,��ȻvectorҲ������ͷβ����Ԫ�ز���,������ͷ��������Ч��ʮ�ֵ���(��Ҫ���漰��������ƶ�)
deque��vector��������һ����deque�����ڳ���ʱ���ڶ�ͷ�˽���Ԫ�ز���,����dequeû�������ĸ���,���Ƕ�̬���Էֶ������ռ���϶���,������ʱ����һ���µĿռ䲢��������
deque��ȻҲ�ṩ������ʵĵ�����,�������������������ͨ��ָ��,�临�ӳ̶ȱ�vector�ߺܶ�,��˳��DZ�Ҫ,����һ��ʹ��vector����deque�������Ҫ��deque����,�����Ƚ�deque�е�Ԫ�ظ��Ƶ�vector��,����sort��vector����,�ٽ�������ƻ�deque
deque��һ��һ�εĶ��������ռ����,һ����Ҫ�����µĿռ�,ֻҪ����һ�ζ��������ռ�ƴ����ͷ����β������,���deque��������������ά����������������
deque�����ݽṹ����:
class deque
{
...
protected:
typedef pointer* map_pointer;//ָ��mapָ���ָ��
map_pointer map;//ָ��map
size_type map_size;//map�Ĵ�С
public:
...
iterator begin();
itertator end();
...
}
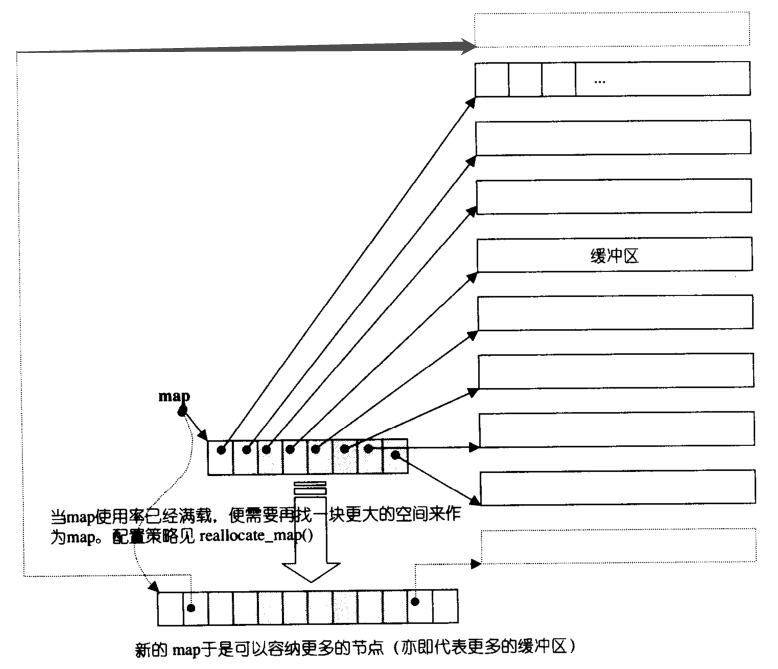
deque�ڲ���һ��ָ��ָ��map,map��һС�������ռ�,���е�ÿ��Ԫ�س�Ϊһ���ڵ�,node,ÿ��node����һ��ָ��,ָ����һ�νϴ�������ռ�,��Ϊ������,�������deque��ʵ�ʴ�����ݵ�����,Ĭ�ϴ�С512bytes������ṹ����ͼ��ʾ��
deque�ĵ��������ݽṹ����:
struct __deque_iterator
{
...
T* cur;//��������ָ��������ǰ��Ԫ��
T* first;//��������ָ��������һ��Ԫ��
T* last;//��������ָ���������һ��Ԫ��
map_pointer node;//ָ��map�е�node
...
}
��deque�ĵ��������ݽṹ���Կ���,Ϊ�˱�������������,��������Ҫ��������4��Ԫ��
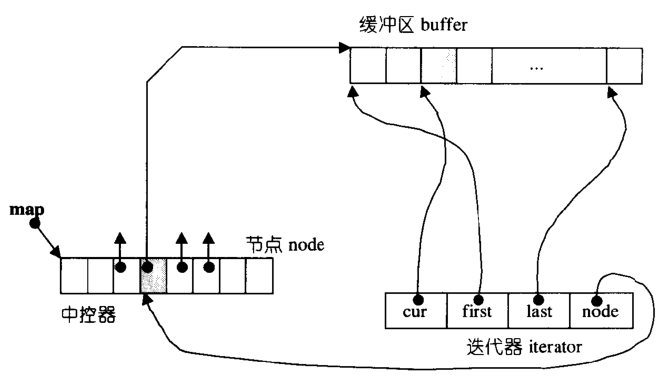
deque�������ġ�++�������C��������Զ��vector����������,����Ҫ�������ڻ������߽�,��δӵ�ǰ������������һ��������,��Ȼdeque�ڲ��ڲ���Ԫ��ʱ,���map��node����ȫ��ʹ����,��nodeָ��Ļ�����Ҳû�ж���Ŀռ�,��ʱ�������µ�map(2���ڵ�ǰ+2������)�����ɸ����node,Ҳ���ǿ���ָ�����Ļ���������dequeɾ��Ԫ��ʱ,Ҳ�ṩ��Ԫ�ص������Ϳ��л������ռ���ͷŵȻ��ơ�
31��STL��stack��queue��ʵ��
stack
stack(ջ)��һ���Ƚ����(First In Last Out)�����ݽṹ,ֻ��һ����ںͳ���,�Ǿ���ջ��,���˻�ȡջ��Ԫ����,û�������������Ի�ȡ���ڲ�������Ԫ��,��ṹͼ����:

stack���ֵ��ڵ����ݽṹ��������˫�ڵ�deque��list�γ�,ֻ��Ҫ����stack�����ʶ�Ӧ�Ƴ�ijЩ�ӿڼ���ʵ��,stack��Դ������:
template <class T, class Sequence = deque<T> >
class stack
{
...
protected:
Sequence c;
public:
bool empty(){return c.empty();}
size_type size() const{return c.size();}
reference top() const {return c.back();}
const_reference top() const{return c.back();}
void push(const value_type& x){c.push_back(x);}
void pop(){c.pop_back();}
};
��stack�����ݽṹ���Կ���,�����в�������Χ��Sequence���,��SequenceĬ����deque���ݽṹ��stack���֡���ij�ֽӿ�,�γ���һ�ַ�ò������Ϊ,��Ϊadapter(�����)�����������Ϊcontainer adapter����container
stack����Ĭ��ʹ��deque��Ϊ��ײ�����֮��,Ҳ����ʹ��˫�ڵ�list,ֻ��Ҫ�ڳ�ʼ��stackʱ,��list��Ϊ�ڶ����������ɡ�����stackֻ�ܲ������˵�Ԫ��,������ڲ�Ԫ����������,Ҳ���ṩ��������
queue
queue(����)��һ���Ƚ��ȳ�(First In First Out)�����ݽṹ,ֻ��һ����ں�һ������,�ֱ�λ����˺����,����Ԫ����,û�������������Ի�ȡ���ڲ�������Ԫ��,��ṹͼ����:
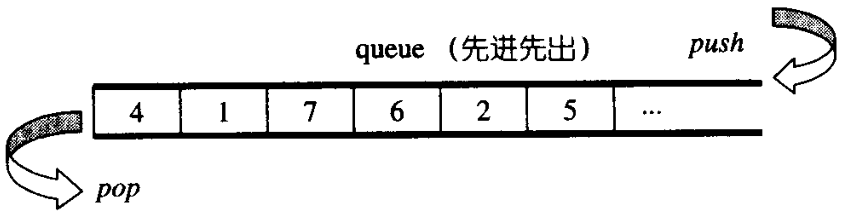
���Ƶ�,queue���֡��Ƚ��ȳ��������ݽṹ��������˫�ڵ�deque��list�γ�,ֻ��Ҫ����queue�����ʶ�Ӧ�Ƴ�ijЩ�ӿڼ���ʵ��,queue��Դ������:
template <class T, class Sequence = deque<T> >
class queue
{
...
protected:
Sequence c;
public:
bool empty(){return c.empty();}
size_type size() const{return c.size();}
reference front() const {return c.front();}
const_reference front() const{return c.front();}
void push(const value_type& x){c.push_back(x);}
void pop(){c.pop_front();}
};
��queue�����ݽṹ���Կ���,�����в�����Ҳ������Χ��Sequence���,SequenceĬ��Ҳ��deque���ݽṹ��queueҲ��һ��container adapter��
ͬ��,queueҲ����ʹ��list��Ϊ�ײ�����,�����б�������,û�е�������
32��STL�е�heap��ʵ��
heap(��)������STL���������,��priority queue(���ȶ���)�ĵײ�ʵ�ֻ���,��Ϊbinary max heap(�����)�������ֵλ�ڶѵĸ���,���ȼ���ߡ�
binary heap������һ��complete binary tree(��ȫ������),����binary tree������ײ��Ҷ�ڵ�֮��,����������,����Ҷ�ڵ�����Ҳ�����ֿ�϶,����ͼ��ʾ����һ����ȫ������
��ȫ��������û���κνڵ�©��,�Ƿdz����յ�,������һ���ô��ǿ���ʹ��array���洢���еĽڵ�,��Ϊ������ij���ڵ�λ�� i i i��,����ڵ�ض�λ�� 2 i 2i 2i��,�ҽڵ�λ�� 2 i + 1 2i+1 2i+1��,���ڵ�λ�� i / 2 i/2 i/2(����ȡ��)����������array��ʾtree�ķ�ʽ��Ϊ��ʽ��������
������ǿ���ʹ��һ��array��һ��heap�㷨��ʵ��max heap(ÿ���ڵ��ֵ���ڵ������ӽڵ��ֵ)��min heap(ÿ���ڵ��ֵС�ڵ������ӽڵ��ֵ)������array���ܶ�̬�ĸı�ռ��С,��vector����array��һ��������ѡ��
��heap�㷨����Щ?�����еIJ��롢��������������㷨,����һһ����������
push_heap�����㷨
������ȫ������������,�²����Ԫ��һ����λ��������ײ���ΪҶ�ӽڵ�,����������ҵĵ�һ���ո���ʵ��,�ڸ�ִ�в������ʱ,��Ԫ��λ�ڵײ�vector��end()��,֮����һ����Ϊpercolate up(����)�Ĺ���,�ٸ���������ͼ:
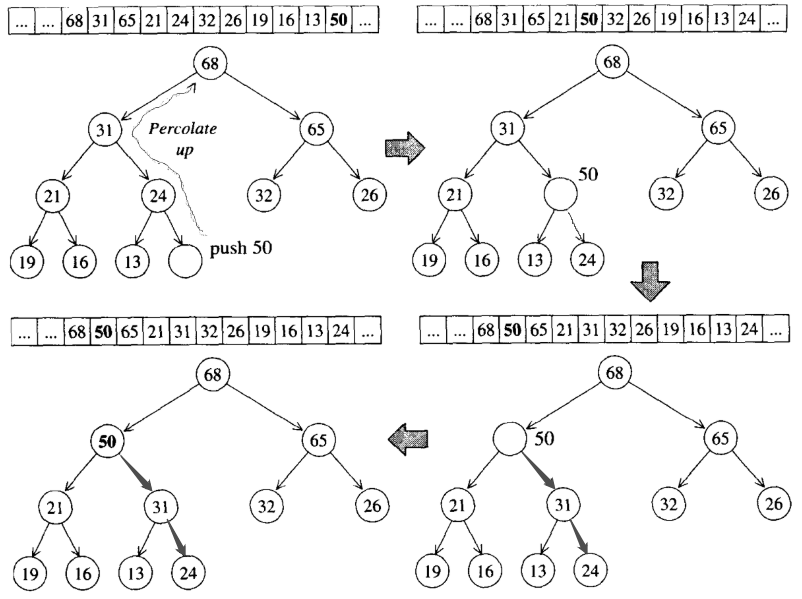
��Ԫ��50�ڲ�����к�,�ȷ���vector��end()����,֮��ִ�����ݹ���,�����������λ��,�Ա�����max heap������,����˽����ѵĻ�,���ԭ��������ѵĵ���������һ���ġ�
pop_heap�㷨
heap��pop����ʵ�ʵ������Ǹ��ڵ���,����heap�ڲ�ִ��pop_heapʱ,ֻ�ǽ����ƶ���vector�����λ��,Ȼ����Ϊ��������ߵ�Ԫ���ҵ�һ�����ʵİ���λ��,ʹ������������ȫ�������������������������Ԫ�����Ȼ�������������ӽڵ�Ƚ�,����ϴ���ӽڵ����λ��,���һֱ����,ֱ�������������Ԫ�ش������������ӽڵ�,�����·ŵ�Ҷ�ڵ�Ϊֹ,������̳�Ϊpercolate down(����)���ٸ�����:
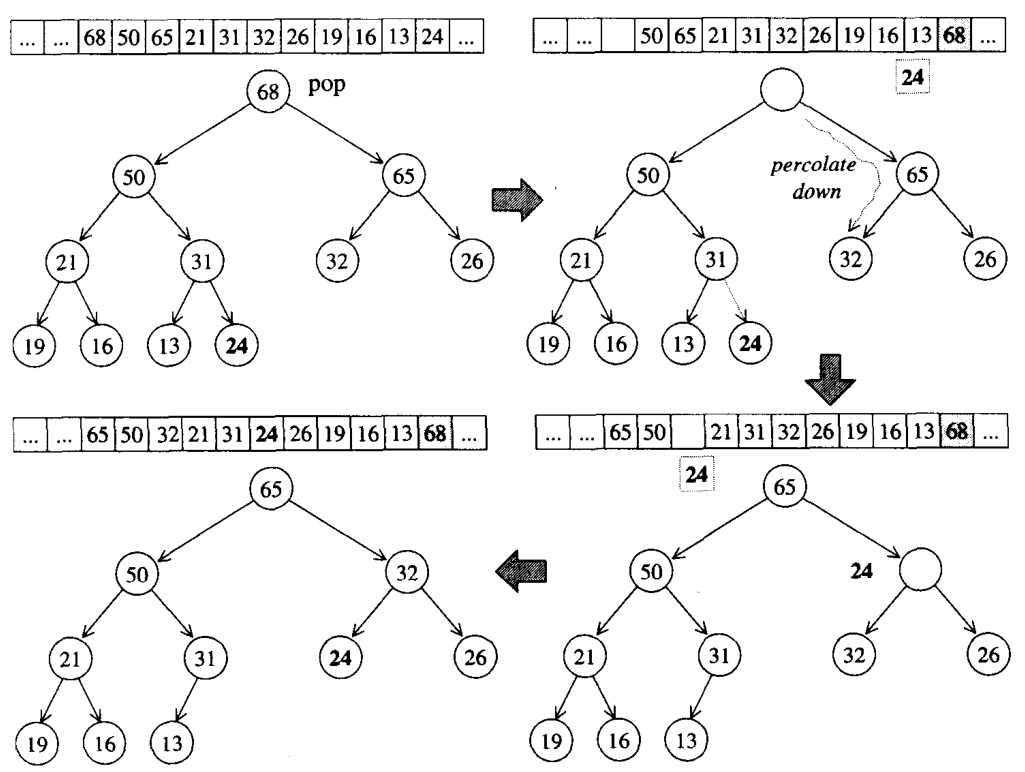
���ڵ�68��pop֮��,�Ƶ���vector����ײ�,��24����,24���ȴӸ��ڵ㿪ʼ�����ӽڵ���бȽ�,ֱ���ҵ����ʵ�λ�ð���,��Ҫע�����pop֮��Ԫ�ز�û�б�����,���Ҫ��������,����ʹ��pop_back()��
sort�㷨
һ���Ա�֮,��Ϊpop_heap���Խ���ǰheap�е����ֵ���ڵײ�����vector��ĩβ,heap��Χ��1,��ô���ϵ�ִ��pop_heapֱ����Ϊ��,���ɵõ�һ���������С�
make_heap�㷨
��һ������ת��Ϊheap,һ��һ�����ݲ���,��������˵������percolate�㷨���ɡ�
����ʵ��:
#include <iostream>
#include <algorithm>
#include <vector>
using namespace std;
int main()
{
vector<int> v = { 0,1,2,3,4,5,6 };
make_heap(v.begin(), v.end()); //��vectorΪ�ײ�����
for (auto i : v)
{
cout << i << " "; // 6 4 5 3 1 0 2
}
cout << endl;
v.push_back(7);
push_heap(v.begin(), v.end());
for (auto i : v)
{
cout << i << " "; // 7 6 5 4 1 0 2 3
}
cout << endl;
pop_heap(v.begin(), v.end());
cout << v.back() << endl; // 7
v.pop_back();
for (auto i : v)
{
cout << i << " "; // 6 4 5 3 1 0 2
}
cout << endl;
sort_heap(v.begin(), v.end());
for (auto i : v)
{
cout << i << " "; // 0 1 2 3 4 5 6
}
return 0;
}
33��STL�е�priority_queue��ʵ��
priority_queue,���ȶ���,��һ��ӵ��Ȩֵ�����queue,����queueһ���Ƕ������,�ײ�����,�ڲ���Ԫ��ʱ,Ԫ�ز��ǰ��ղ����������,�����Զ�����Ȩֵ(ͨ����Ԫ�ص�ʵֵ)����,Ȩֵ���,������ǰ��,����ͼ��ʾ��
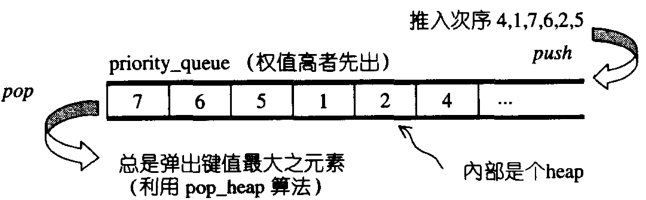
Ĭ�������,priority_queueʹ��һ��max-heap���,�ײ�����ʹ�õ���һ��ΪvectorΪ�ײ�����,��heapΪ���������������ײ�����ʵ�� ��priority_queue������ʵ�ֻ��Ƶ����䲻����Ϊ����,����һ��������������ؼ���Դ������:
template <class T, class Squence = vector<T>,
class Compare = less<typename Sequence::value_tyoe> >
class priority_queue{
...
protected:
Sequence c; // �ײ�����
Compare comp; // Ԫ�ش�С�Ƚϱ�
public:
bool empty() const {return c.empty();}
size_type size() const {return c.size();}
const_reference top() const {return c.front()}
void push(const value_type& x)
{
c.push_heap(x);
push_heap(c.begin(), c.end(),comp);
}
void pop()
{
pop_heap(c.begin(), c.end(),comp);
c.pop_back();
}
};
priority_queue������Ԫ��,��������һ���Ĺ���,ֻ��queue���˵�Ԫ��(Ȩֵ�����),���л��ᱻ���ȡ��,��û�б�������,Ҳ���ṩ������
�ٸ�����:
#include <queue>
#include <iostream>
using namespace std;
int main()
{
int ia[9] = {0,4,1,2,3,6,5,8,7 };
priority_queue<int> pq(ia, ia + 9);
cout << pq.size() <<endl; // 9
for(int i = 0; i < pq.size(); i++)
{
cout << pq.top() << " "; // 8 8 8 8 8 8 8 8 8
}
cout << endl;
while (!pq.empty())
{
cout << pq.top() << ' ';// 8 7 6 5 4 3 2 1 0
pq.pop();
}
return 0;
}
34��STL��set��ʵ��?
STL�е������ɷ�Ϊ����ʽ����(sequence)����ʽ����(associative),set���ڹ���ʽ������
set��������,����Ԫ�ض������Ԫ�ص�ֵ�Զ�������(Ĭ������),setԪ�صļ�ֵ����ʵֵ,ʵֵ���Ǽ�ֵ,set��������������ͬ�ļ�ֵ
set��������������Ԫ�ص�ֵ,���������һ��constance iterators
����STL set��RB-tree(�����)��Ϊ�ײ����,�������е�set������Ϊ����ת����RB-tree�IJ�����Ϊ,���ﲹ��һ�º����������:
- ÿ���ڵ㲻�Ǻ�ɫ���Ǻ�ɫ
- �����Ϊ��ɫ
- ����ڵ�Ϊ��ɫ,���ӽڵ��Ϊ��
- ��һ�ڵ���(NULL)��β�˵��κ�·��,�����ĺڽڵ���������ͬ
���ں�����ľ����������,�Ƚϸ��Ӷ��߿��Է��ġ��㷨���ۡ���ϸ�˽⡣
�ٸ�����:
#include <set>
#include <iostream>
using namespace std;
int main()
{
int i;
int ia[5] = { 1,2,3,4,5 };
set<int> s(ia, ia + 5);
cout << s.size() << endl; // 5
cout << s.count(3) << endl; // 1
cout << s.count(10) << endl; // 0
s.insert(3); //�ٲ���һ��3
cout << s.size() << endl; // 5
cout << s.count(3) << endl; // 1
s.erase(1);
cout << s.size() << endl; // 4
set<int>::iterator b = s.begin();
set<int>::iterator e = s.end();
for (; b != e; ++b)
cout << *b << " "; // 2 3 4 5
cout << endl;
b = find(s.begin(), s.end(), 5);
if (b != s.end())
cout << "5 found" << endl; // 5 found
b = s.find(2);
if (b != s.end())
cout << "2 found" << endl; // 2 found
b = s.find(1);
if (b == s.end())
cout << "1 not found" << endl; // 1 not found
return 0;
}
����ʽ��������ʹ���������ṩ��find()��������ָ����Ԫ��,Ч�ʸ���,��ΪSTL�ṩ��find()������һ��˳�������㷨��
35��STL��map��ʵ��
map������������Ԫ�ػ���ݼ�ֵ�����Զ�����map�����е�Ԫ�ض���pair,ӵ�м�ֵ(key)��ʵֵ(value)��������,���Ҳ�����Ԫ������ͬ��key
һ��map��keyȷ����,��ô�����ĵ�,���ǿ��������key��Ӧ��value,���map�ĵ������Ȳ���constant iterator,Ҳ����mutable iterator
��STL map�ĵײ������RB-tree(�����),��һ����hash tableΪ�ײ����ʵ�ֵij�Ϊhash_map��map�ļܹ�����ͼ��ʾ
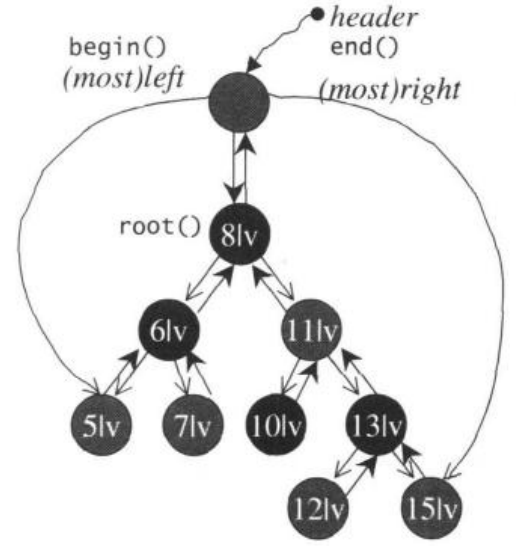
map���ڹ���ʱȱʡ���õ�������key,Ҳʹ��alloc���������ÿռ��С,��Ҫע������ڲ���Ԫ��ʱ,���õ��Ǻ�����е�insert_unique()����,����insert_euqal()(multimapʹ��)
�ٸ�����:
#include <map>
#include <iostream>
#include <string>
using namespace std;
int main()
{
map<string, int> maps;
//��������Ԫ��
maps["jack"] = 1;
maps["jane"] = 2;
maps["july"] = 3;
//��pair��ʽ����
pair<string, int> p("david", 4);
maps.insert(p);
//�������Ԫ��
map<string, int>::iterator iter = maps.begin();
for (; iter != maps.end(); ++iter)
{
cout << iter->first << " ";
cout << iter->second << "--"; //david 4--jack 1--jane 2--july 3--
}
cout << endl;
//ʹ��subscipt����ȡʵֵ
int num = maps["july"];
cout << num << endl; // 3
//����ijkey
iter = maps.find("jane");
if(iter != maps.end())
cout << iter->second << endl; // 2
//��ʵֵ
iter->second = 100;
int num2 = maps["jane"]; // 100
cout << num2 << endl;
return 0;
}
��Ҫע�����subscript(�±�)�����ȿ�����Ϊ��ֵ����(������)Ҳ������Ϊ��ֵ����(��ȡʵֵ)������:
maps["abc"] = 1; //��ֵ����int num = masp["abd"]; //��ֵ����
�������,subscript�����������ȸ��ݼ�ֵ�ҳ�ʵֵ,Դ������:
...T& operator[](const key_type& k){
return (*((insert(value_type(k, T()))).first)).second;
}...
�������й�����:���ȸ��ݼ�ֵ��ʵֵ����һ��Ԫ��,���Ԫ�ص�ʵֵδ֪,��˲���һ����ʵֵ�ͱ���ͬ����ʱ�������:
value_type(k, T());
�ٽ����������뵽map��,������һ��pair:
pair<iterator,bool> insert(value_type(k, T()));
pair��һ��Ԫ���ǵ�����,ָ��ǰ�������Ԫ��,�������ɹ�����true,��ʱ��Ӧ��ֵ����,���ݼ�ֵ����ʵֵ������ʧ��(�ظ�����)����false,��ʱ���ص����Ѿ����ڵ�Ԫ��,�����ȡ������ʵֵ
(insert(value_type(k, T()))).first; //������
*((insert(value_type(k, T()))).first); //������
(*((insert(value_type(k, T()))).first)).second; //ȡ��ʵֵ
�������ʵֵ�������÷�ʽ����,�����Ϊ��ֵ������ֵ������
36��set��map������,multimap��multiset������
setֻ�ṩһ���������͵Ľӿ�,���ǻὫ��һ��Ԫ�ط��䵽key��value��,��������compare_function�õ��� identity()����,�������������ʲô���ʲô,������ʵ����set����,set��key��value��ʵ��һ�����ˡ���ʵ�������������Ԫ��,������ֻ����һ��Ԫ��
map���ṩ�����������͵Ľӿ�,�ֱ����key��value��λ����,���ıȽ�function���õ��Ǻ������comparefunction(),�����ȷʵ������Ԫ�ء�
����������insert���Dz��ú������insert_unique() ��һ���IJ��� ��
multimap��map��Ψһ�������:multimap���õ��Ǻ������insert_equal(),�����ظ������map���õ����Ƕ�һ���IJ���insert_unique(),multiset��setҲһ��,�ײ�ʵ�ֶ���һ����,ֻ���ڲ����ʱ����õķ�����һ����
���������
����ʱ���ֳ�д���������ĸ��ʼ���Ϊ0,���Ǻ����һЩ�����������Ҫ���յġ�
1�����Ƕ���������(�̳ж�������������):
-
������������,�������������н���ֵ��С�ڻ�������ĸ�����ֵ��
-
������������,�������������н���ֵ�����ڻ�������ĸ�����ֵ��
- ��������Ҳ�ֱ�Ϊ������������
2�����������¼���Ҫ��:
-
�������нڵ�Ǻ켴�ڡ�
-
���ڵ��Ϊ�ڽڵ㡣
-
��ڵ���ӽڵ��Ϊ��(�ڽڵ��ӽڵ��Ϊ��)��
-
�Ӹ���NULL���κ�·���Ϻڽ������ͬ��
3������ʱ��һ�����Կ�����O(logn)��
37��STL��unordered_map��map�������Ӧ�ó���**
map֧�ּ�ֵ���Զ�����,�ײ�����Ǻ����,������IJ�ѯ��ά��ʱ�临�ӶȾ�Ϊ O ( l o g n ) O(logn) O(logn),���ǿռ�ռ�ñȽϴ�,��Ϊÿ���ڵ�Ҫ���ָ��ڵ㡢���ӽڵ㼰��ɫ����Ϣ
unordered_map��C++ 11�����ӵ�����,�ײ�����ǹ�ϣ��,ͨ��hash��������Ԫ��λ��,���ѯʱ�临�Ӷ�ΪO(1),ά��ʱ����bucketͰ��ά����list�����й�,���ǽ���hash����ʱ�ϴ�
�����ߵĵײ���ƺ��ص���Կ���:map�������������ݵ�Ӧ�ó���,unordered_map�����ڸ�Ч��ѯ��Ӧ�ó���
38��hashtable�н����ͻ����Щ����?**
��סǰ����:
����̽��
ʹ��hash�����������λ������Ѿ���Ԫ��ռ����,���������Ѱ��,�ҵ���β��ص���ͷ,ֱ���ҵ�һ����λ
����
ÿ������ά��һ��list,���hash����������ĸ�����ͬ,��˳��������list��
��ɢ��
������ͻʱʹ����һ��hash�����ټ���һ����ַ,ֱ������ͻ
����̽��
ʹ��hash�����������λ������Ѿ���Ԫ��ռ����,���� 1 2 1^2 12�� 2 2 2^2 22�� 3 2 3^2 32���IJ�������Ѱ��,������������������,���֮Ϊα���̽��
���������
һ��hash��������Ľ����ͬ,�ͷ��빫�������
39��������Ĵ������
#include <iostream>
#include <queue>
#include <vector>
#include <set>
using namespace std;
int main()
{
set<int, greater<int>> set1;
for (int i = 0; i < 10; ++i)
{
set1.insert(rand() % 100);
}
for (int v : set1)
{
cout << v << " ";
}
cout << endl;
return 0;
}
int main()
{
priority_queue<int> que1; // vector
for (int i = 0; i < 10; ++i)
{
que1.push(rand() % 100);
}
while (!que1.empty())
{
cout << que1.top() << " ";
que1.pop();
}
cout << endl;
using MinHeap = priority_queue<int, vector<int>, greater<int>>;
MinHeap que2; // vector
for (int i = 0; i < 10; ++i)
{
que2.push(rand() % 100);
}
while (!que2.empty())
{
cout << que2.top() << " ";
que2.pop();
}
cout << endl;
return 0;
}
/*
�������� => C��������ĺ���ָ��
*/
// ʹ��C�ĺ���ָ��������
/*
template<typename T>
inline bool mygreater(T a, T b)
{
return a > b;
}
template<typename T>
inline bool myless(T a, T b)
{
return a < b;
}
*/
/*
1.ͨ�������������operator(),����ʡ�Ժ����ĵ��ÿ���,��ͨ������ָ��
���ú���(���ܹ�inline��������)Ч�ʸ�
2.��Ϊ�����������������ɵ�,���Կ���������صij�Ա����,������¼��������ʹ��
ʱ�������Ϣ
*/
// C++��������İ汾ʵ��
template<typename T>
class mygreater
{
public:
bool operator()(T a, T b) // ��Ԫ��������
{
return a > b;
}
};
template<typename T>
class myless
{
public:
bool operator()(T a, T b) // ��Ԫ��������
{
return a < b;
}
};
// compare��C++�Ŀ⺯��ģ��
template<typename T, typename Compare>
bool compare(T a, T b, Compare comp)
{
// ͨ������ָ����ú���,��û�а취������,Ч�ʺܵ�,��Ϊ�к������ÿ���
return comp(a, b); // operator()(a, b);
}
int main()
{
cout << compare(10, 20, mygreater<int>()) << endl;
cout << compare(10, 20, myless<int>()) << endl;
//cout << compare('b', 'y') << endl;
return 0;
}
39C++�ĺ�������Ͱ���
#include <iostream>
#include <vector>
#include <map>
#include <functional> // ʹ��function������������
#include <algorithm>
#include <ctime>
#include <string>
using namespace std;
/*
C++11�ṩ�İ����ͺ�������
bind function
C++ STL bind1st��bind2nd =�� ��������һ����������
function : ����,��������,lambda����ʽ ����ֻ��ʹ����һ�������
*/
void doShowAllBooks() { cout << "�鿴�����鼮��Ϣ" << endl; }
void doBorrow() { cout << "����" << endl; }
void doBack() { cout << "����" << endl; }
void doQueryBooks() { cout << "��ѯ�鼮" << endl; }
void doLoginOut() { cout << "ע��" << endl; }
int main()
{
int choice = 0;
// C�ĺ���ָ��
map<int, function<void()>> actionMap;
actionMap.insert({ 1, doShowAllBooks }); // insert(make_pair(xx,xx));
actionMap.insert({ 2, doBorrow });
actionMap.insert({ 3, doBack });
actionMap.insert({ 4, doQueryBooks });
actionMap.insert({ 5, doLoginOut });
for (;;)
{
cout << "-----------------" << endl;
cout << "1.�鿴�����鼮��Ϣ" << endl;
cout << "2.����" << endl;
cout << "3.����" << endl;
cout << "4.��ѯ�鼮" << endl;
cout << "5.ע��" << endl;
cout << "-----------------" << endl;
cout << "��ѡ��:";
cin >> choice;
auto it = actionMap.find(choice); // map pair first second
if (it == actionMap.end())
{
cout << "����������Ч,����ѡ��!" << endl;
}
else
{
it->second();
}
// ����,��Ϊ���������պ� ����������-��ԭ��
/*switch (choice)
{
case 1:
break;
case 2:
break;
case 3:
break;
case 4:
break;
case 5:
break;
default:
break;
}*/
}
return 0;
}
#include <iostream>
#include <vector>
#include <map>
#include <functional> // ʹ��function������������
#include <algorithm>
#include <ctime>
#include <string>
void hello1()
{
cout << "hello world!" << endl;
}
void hello2(string str) // void (*pfunc)(string)
{
cout << str << endl;
}
int sum(int a, int b)
{
return a + b;
}
class Test
{
public: // ��������һ������void (Test::*pfunc)(string)
void hello(string str) { cout << str << endl; }
};
int main()
{
/*
1.�ú�������ʵ����function
2.ͨ��function����operator()������ʱ��,��Ҫ���ݺ������ʹ�����Ӧ�IJ���
*/
// ��function����ģ�嶨�崦,����ϣ����һ����������ʵ����function
function<void()> func1 = hello1;
func1(); // func1.operator()() => hello1()
function<void(string)> func2 = hello2;
func2("hello hello2!"); // func2.operator()(string str) => hello2(str)
function<int(int, int)> func3 = sum;
cout<<func3(20, 30)<<endl;
// operator()
function<int(int, int)> func4 = [](int a, int b)->int {return a + b; };
cout << func4(100, 200) << endl;
function<void(Test*, string)> func5 = &Test::hello;
func5(&Test(), "call Test::hello!");
return 0;
}
40 string��ʹ�÷���
string��STL���ַ�������,ͨ��������ʾ�ַ���������ʹ��string֮ǰ,�ַ���ͨ������char��ʾ��,string��char������������ʾ�ַ�����
˵��string������,�Ͳ��ò���char*���͵��ַ����Ա�:
1��char*��һ��ָ��,string��һ����
string��װ��char*,��������ַ���,��һ��char*�͵�������
2��string��װ�˺ܶ�ʵ�õij�Ա����
����find,����copy,ɾ��delete,�滻replace,����insert
3�����ÿ����ڴ��ͷź�Խ��
string����char*��������ڴ�,ÿһ��string�ĸ���,ȡֵ����string�ฺ��ά��,���õ��ĸ���Խ���ȡֵԽ��ȡ�
4��string��char�����ת��,stringתcharͨ��string�ṩ��c_str()������
C++ �����е�string��ʾ�ɱ䳤���ַ���,����ͷ�ļ�string���档
#include < string >
using std::string;
ֱ�ӳ�ʼ���Ϳ�����ʼ��
string s1;//��ʼ���ַ���,���ַ���
string s2 = s1; //������ʼ��,����ַ���
string s3 = ��I am b��; //ֱ�ӳ�ʼ��,s3�����ַ���
string s4(10, ��a��); //s4����ַ�����aaaaaaaaaa
string s5(s4); //������ʼ��,����ַ���
string s6(��I am d��); //ֱ�ӳ�ʼ��
string s7 = string(6, ��c��); //������ʼ��,cccccc
string��IO����


ʹ��cin�����ַ���ʱ,�����հ�ֹͣ��ȡ
" Hello World"
��ô���ǵõ����ַ�������"Hello",ǰ��Ŀհ�û��,�����worldҲ����������
��������������hello world��������ô��?�Ǿ�������
cin>>s1>>s2;
hello����s1��,world����s2���ˡ�
��ʱ�������һ�����Ӵ�����,�ֲ��������������������string���洢����,��ô��?
�Ǿ�����getline����ȡһ�������ݡ�
string str;
getline(cin, str);
cout << str << endl;