8.1 ���ҵ���ظ���
����:�����ݼ�����Ѱ������ij������������Ԫ�صĹ��̳�Ϊ����
���ұ�(���ҽṹ):���ڲ��ҵ����ݼ��ϳ�Ϊ���ұ�,����ͬһ���͵�����Ԫ��(���¼)���
�ؼ���:����Ԫ����Ψһ��ʶ��Ԫ�ص�ij���������ֵ,ʹ�û��ڹؼ��ֵIJ���,���ҽ��Ӧ����Ψһ�ġ�
��̬���ұ�:ֻ��Ҫ��������Ԫ�صIJ��Ҳ���,����ע�����ٶȼ���
��̬���ұ�:������Ҫ��������Ԫ�صIJ���,Ҳ��Ҫ������Ԫ�ؽ�����ɾ����,���˲����ٶ�,ҲҪ��ע��/ɾ�����Ƿ�ʵ�֡�
8.2 ˳����IJ���
8.2.1 ���ҷ�ʽ
��ͷ����(���ߴӽŵ�ͷ)������
������˳���������,����Ԫ������������
8.2.2 ʵ�ִ���
typedef struct{//���ұ������ݽṹ(˳���)
ElemType *elem;//��̬�����ַ
int TableLen;//���ij���
}SSTable;
//˳�����
int Search_Seq(sSTable ST,ElemType key){
int i;
for( i=0; i<ST.TableLen && ST.elem[i] !=key; ++i);
//���ҳɹ�,��Ԫ���±�;����ʧ��,��-1
return i==ST.TableLen? -1 : i;
}
Ҳ����0��λ�ô桰�ڱ���,��β����ͷ�����������ŵ�:ѭ��ʱ�����ж��±��Ƿ�Խ�硣
//˳�����
int Search_Seq(sSTable ST,ElemType key){
ST.elem[0]=key;//���ڱ���
int i;
for(i=ST.TableLen;ST.elem[i] !=key;--i);
//�Ӻ���ǰ��
return i;
//���ҳɹ�,��Ԫ���±�;����ʧ��,��0
}
8.2.3 �㷨�Ż�
��һ��
���������ҵı��Ľ��������
�ŵ�:����ʧ��ʱASL����
�ɹ����Ĺؼ��ֶԱȴ���=������ڲ���
ʧ�ܽ��Ĺؼ��ֶԱȴ���=�丸�ڵ����ڲ���
Ĭ�������,����ʧ�������ɹ�������ȸ��ʷ���
�ڶ���
�������ؼ��ֱ����ҵĸ��ʲ�ͬ,�ɰ�������ʽ�������
�ŵ�:���ҳɹ�ʱASL����
8.2.4 ʱ�临�Ӷ�:O(n)
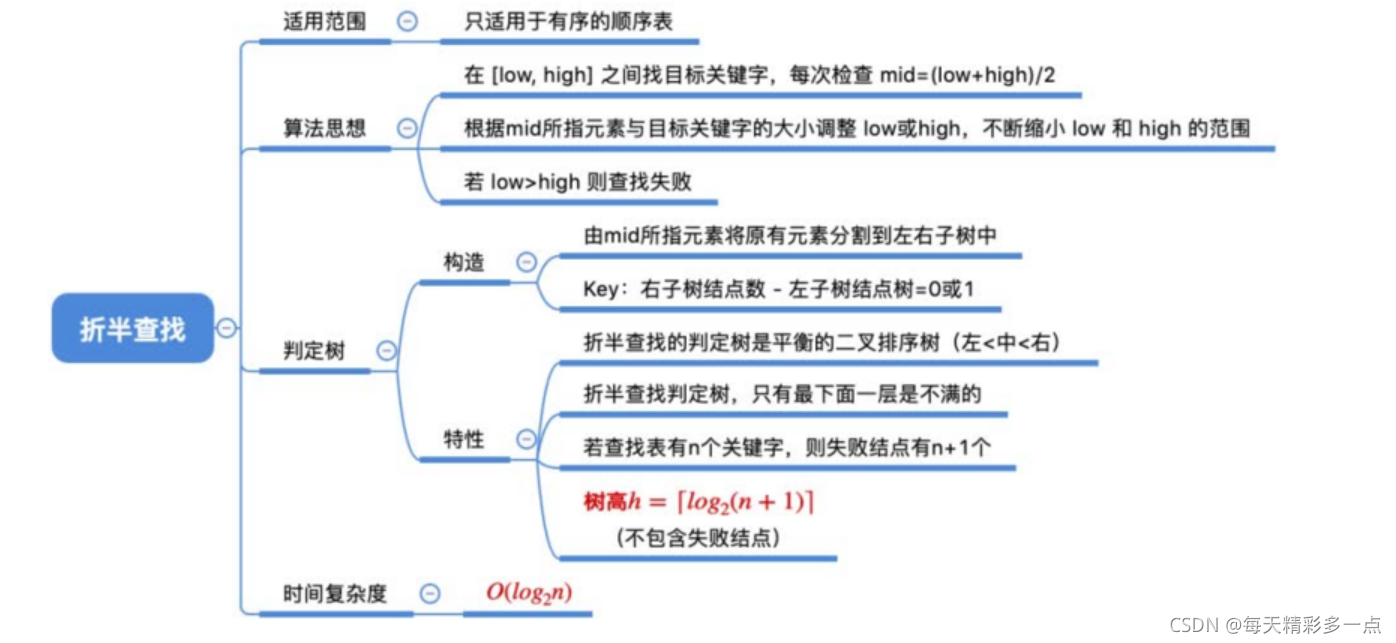
8.3 �۰���ҷ�
8.3.1 ����ʵ��
//�۰����
typedef struct{//���ұ������ݽṹ(˳���)
ElemType *elem;//��̬�����ַ
int TableLen;//���ij���
}SSTable;
int Binary_Search(SSTable L,ElemType key){
int low=0,high=L.TableLen-1,mid;
while(low<=high){
mid=(low+high)/2;//ȡ�м�λ��
if(L.elem [mid]==key)
return mid;//���ҳɹ�������λ��
else if(L.elem[mid]>key)
high=mid-1;//��ǰ�벿�ּ�������
else
low=mid+1;//�Ӻ�벿�ּ�������
}
return -1;//����ʧ��,����-1
}
8.3.2 �ܽ�
8.4 �ֿ����
8.4.1 ����ʵ��
�ֿ������Ҫ������������",���б���ÿ���ֿ�����ؼ��ֺͷֿ�Ĵ洢���䡣
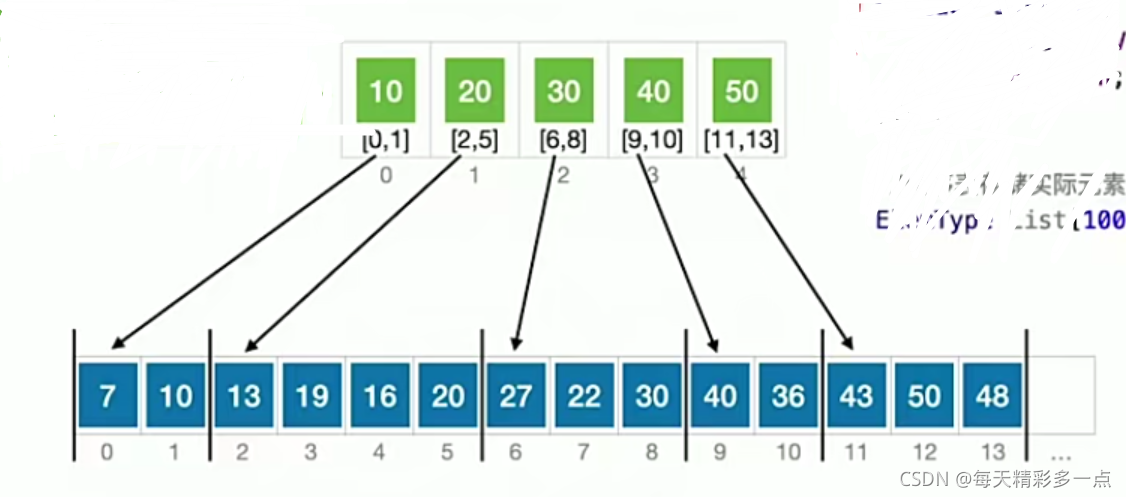
�ص�:��������,�������
�ֿ����,�ֳ�����˳�����,�㷨��������:
������������ȷ�������¼�����ķֿ�(��˳���۰�)
���ڿ���˳�����
���������в�����Ŀ��ؼ���,���۰��������������ͣ��(low>high)Ҫ��low��ָ�ֿ��в���
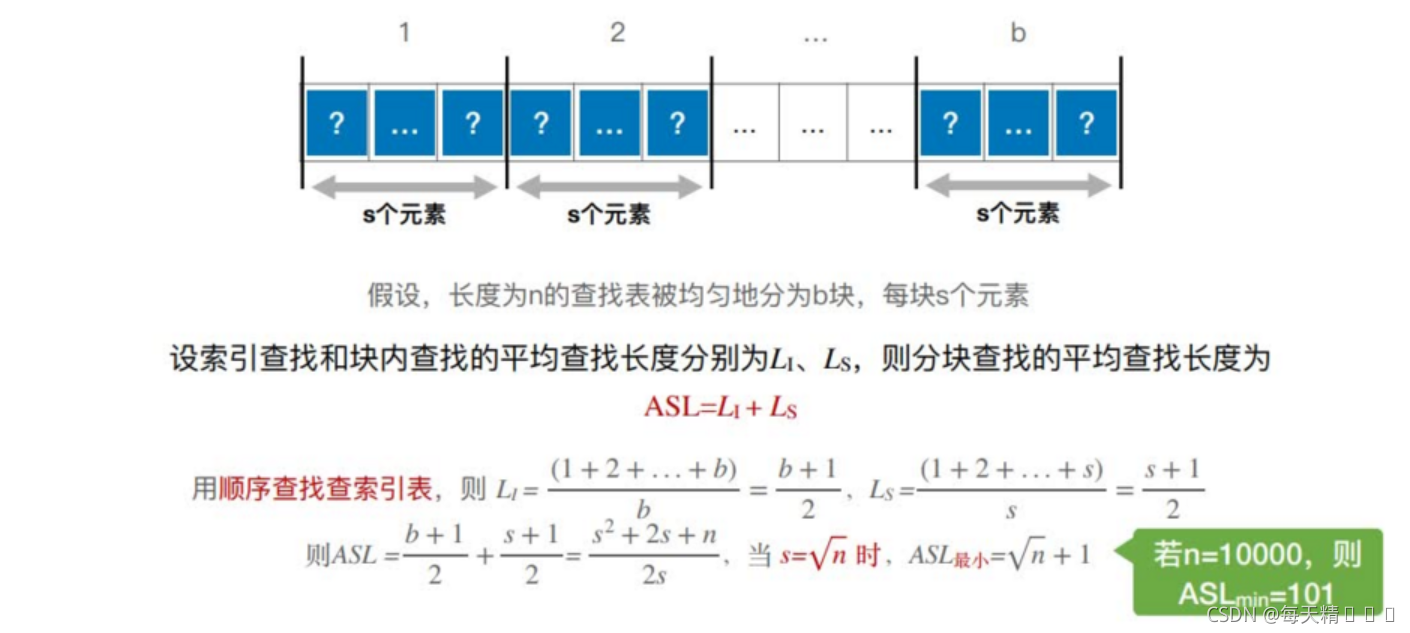
8.4.2 Ч�ʷ���
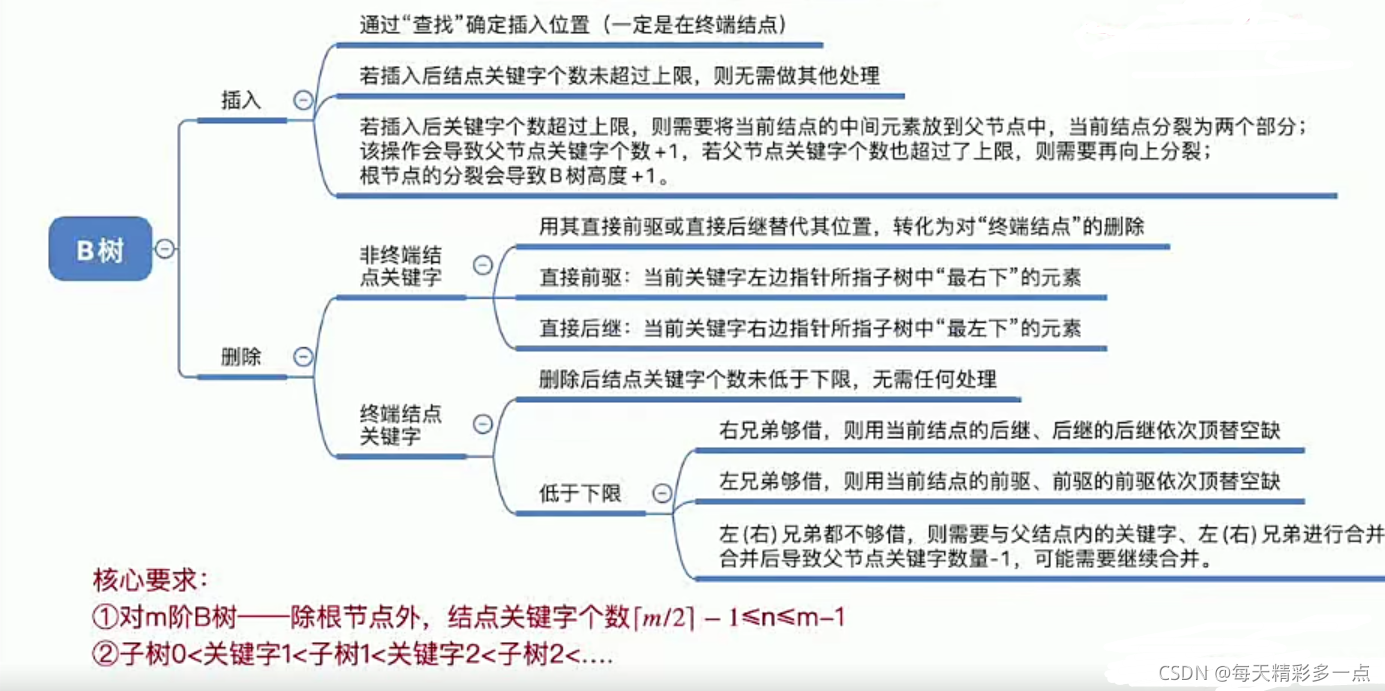
8.5 B��
8.6 ɢ�в���
8.6.1 ��������
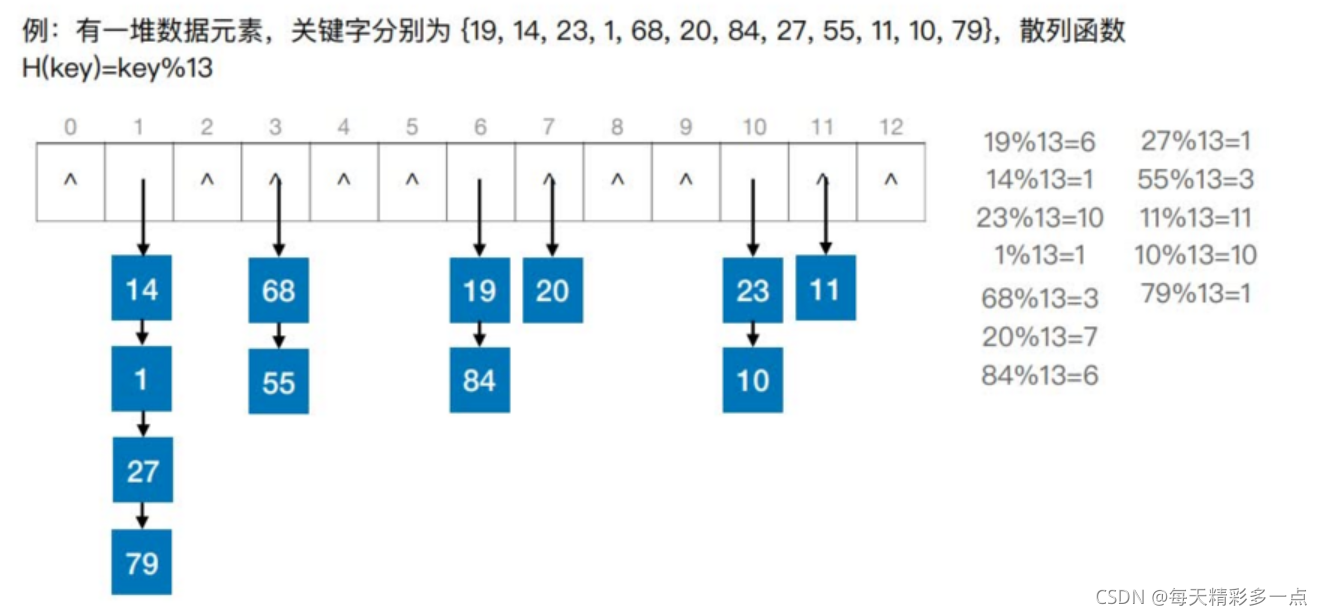
ɢ�б�(Hash Table),�ֳƹ�ϣ������һ�����ݽṹ,�ص���,����Ԫ�صĹؼ�������洢��ֱַ�����
ͨ����ɢ�к���(��ϣ����)��: Addr=H(key)�������ؼ��ֺ���洢��ַ����ϵ��
ͬ���:����ͬ�Ĺؼ���ͨ��ɢ�к���ӳ�䵽ͬһ��ֵ
����ͻ":ͨ��ɢ�к���ȷ����λ���Ѿ����������Ԫ��
���ҳ���:�ڲ���������,��Ҫ�Աȹؼ��ֵĴ�����Ϊ���ҳ���
8.6.2 ������ͻ�ķ���
1.������
������ͬ��ʷ���һ�������д洢
��ͼ��ƽ�����ҳ���:
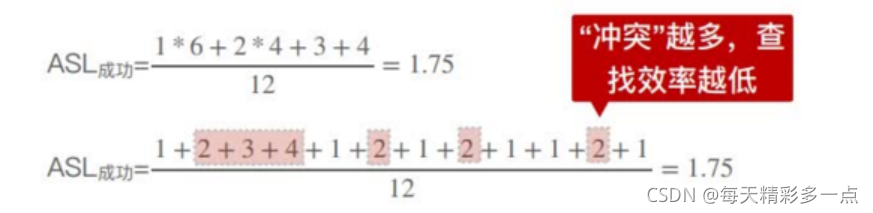

2. ���Ŷ�ַ��
��ָ�ɴ���±���Ŀ��е�ַ��������ͬ��ʱ����,�������ķ�ͬ��ʱ���š�
����ѧ���ƹ�ʽΪ:
Hi= (H(key) + di) %m
i = 0, 1, 2,��, k(k �� m-1),m��ʾɢ�б�����;diΪ��������;i������Ϊ����i�η�����ͻ��
������̽�ⷨ
di= 0, 1, 2, 3, ��, m-1;
��������ͻʱ,ÿ������̽�����ڵ���?����Ԫ�Ƿ�Ϊ��
H(key)=1%13=1
H0=(1+d0)%16=1����ͻ�C>H1=(1+d1)%16=2
ע��:
���á����Ŷ�ַ����ʱ,ɾ����㲻�ܼؽ���ɾ���Ŀռ���Ϊ��,���ض�����֮����?ɢ�б���ͬ��ʽ��IJ���·��,������?����ɾ����ǡ�,������ɾ��
����̽�ⷨ���������ͬ��ʡ���ͬ��ʵġ��ۼ�(�ѻ�)������,����Ӱ�����Ч��
����ԭ��:��ͻ����̽��?���Ƿ���ij��������λ��
��ƽ��̽�ⷨ��
��di= 02, 12, -12, 22, -22, ��, k2, -k2ʱ,��Ϊƽ��̽�ⷨ,�ֳƶ���̽�ⷨ,����k��m/2��
ƽ��̽�ⷨ:��������̽�ⷨ�����ײ�?���ۼ�(�ѻ�)�����⡣
��α������з���
di��?��������,��di= 0, 5, 24, 11, ��
3. ��ɢ�з�
8.6.3 �����Ĺ�ϣ����
���Ŀ��:�ò�ͬ�ؼ��ֵij�ͻ�����ܵ���
1. ����������
H(key) = key % p
ɢ�б�����Ϊm,ȡһ��������m����ӽ������m������p
2.ֱ�Ӷ�ַ��
H(key) = key �� H(key) = a*key + b
����,a��b�dz��������ַ����������,�Ҳ��������ͻ�����ʺϹؼ��ֵķֲ��������������,���ؼ��ֲַ�������,��λ�϶�,�����ɴ洢�ռ���˷ѡ�
3.���ַ�����
ѡȡ����ֲ���Ϊ���ȵ�����λ��Ϊɢ�е�ַ
��ؼ�����r������(��ʮ������),��r�������ڸ�λ�ϳ��ֵ�Ƶ�ʲ�?����ͬ,������ijЩλ�Ϸֲ�����?Щ,ÿ��������ֵĻ������;����ijЩλ�Ϸֲ�������,ֻ��ij�������뾭������,��ʱ��ѡȡ����ֲ���Ϊ���ȵ�����λ��Ϊɢ�е�ַ�����ַ����ʺ�����֪�Ĺؼ��ּ���,�������˹ؼ���,����Ҫ���¹����µ�ɢ�к�����
4.ƽ��ȡ�з�
ȡ�ؼ��ֵ�ƽ��ֵ���м伸λ��Ϊɢ�е�ַ��
����ȡ����λҪ��ʵ��������������ַ����õ���ɢ�е�ַ��ؼ��ֵ�ÿλ���й�ϵ,���ʹ��ɢ�е�ַ�ֲ��ȽϾ���,�����ڹؼ��ֵ�ÿλȡֵ���������Ȼ��С��ɢ�е�ַ�����λ����