题目
187. 重复的DNA序列
所有 DNA 都由一系列缩写为 ‘A’,‘C’,‘G’ 和 ‘T’ 的核苷酸组成,例如:“ACGAATTCCG”。在研究 DNA 时,识别 DNA 中的重复序列有时会对研究非常有帮助。
编写一个函数来找出所有目标子串,目标子串的长度为 10,且在 DNA 字符串 s 中出现次数超过一次。
示例 1:
输入:s = "AAAAACCCCCAAAAACCCCCCAAAAAGGGTTT"
输出:["AAAAACCCCC","CCCCCAAAAA"]
示例 2:
输入:s = "AAAAAAAAAAAAA"
输出:["AAAAAAAAAA"]
提示:
0 <= s.length <= 105
s[i] 为 'A'、'C'、'G' 或 'T'
解题思路
首先要知道一个字串的概念。
字串:串中任意个连续的字符组成的子序列称为该串的子串。
所以我们可以用哈希表的方法,一边计算字符串的长度,一边计算字符出现过的次数。
Code
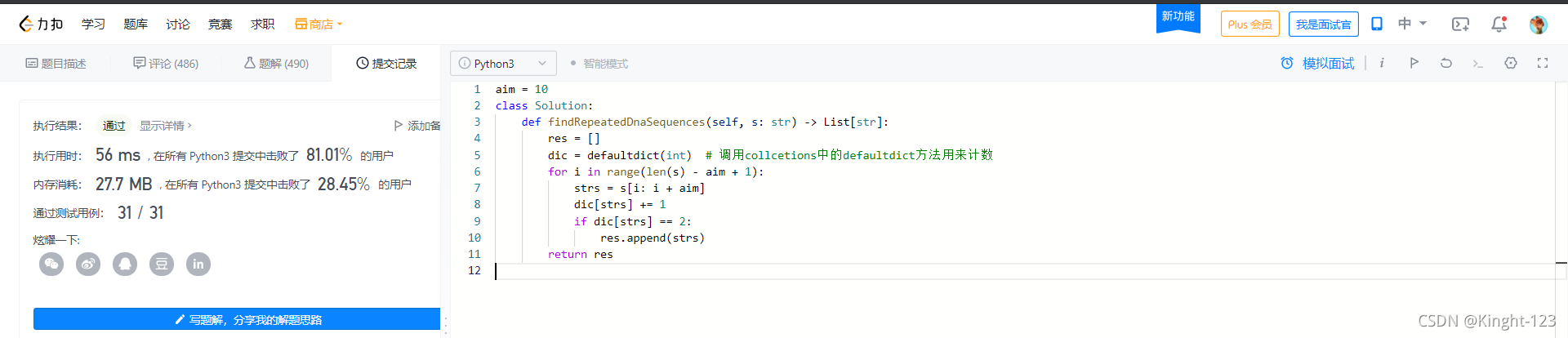
aim = 10
class Solution:
def findRepeatedDnaSequences(self, s: str) -> List[str]:
res = []
dic = defaultdict(int) # 调用collcetions中的defaultdict方法用来计数
for i in range(len(s) - aim + 1):
strs = s[i: i + aim]
dic[strs] += 1
if dic[strs] == 2:
res.append(strs)
return res
运行结果