MySQL������
һ����������
��������:���ٲ�ѯ����MySQL�б���Ϊ������,�Ǵ洢�������ڿ����ҵ���¼��һ�����ݽṹ�����Խ���ѯ������ߺü�����������
����ѯ������С��һ����С������Χ,(MyISAM�������γ��ڴ�������)ͨ����ѯ����������ӳ���ȡ��Ҫ�����ݡ�
����IO:��һ��IOʱ,����ѵ�ǰ���̵�ַ�����ݶ�ȡ���ڴ滺����,Ҳ������ڵ�����Ҳ����ȡ���ڴ滺������,��Ϊ�ֲ�Ԥ����ԭ����������,�����������һ����ַ�����ݵ�ʱ��,�������ڵ�����Ҳ��ܿ챻���ʵ���ÿһ��IO��ȡ���������dz�֮Ϊһҳ(page)������һҳ�ж�����ݸ�����ϵͳ�й�,һ��Ϊ4k��8k��
1��B+��
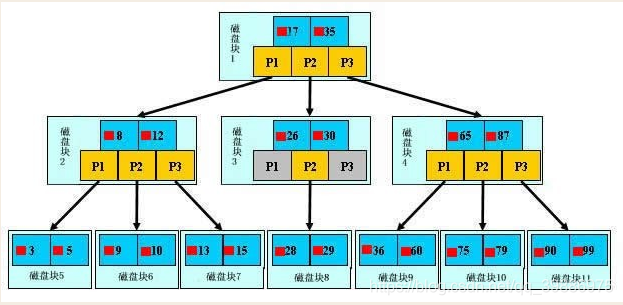
dz��ɫ�Ŀ����dz�֮Ϊһ�����̿�,���̿��������������(����ɫ��ʾ)��ָ��(��ɫ��ʾ)������̿�1����������17��35,����ָ��P1��P2��P3,P1��ʾС��17�Ĵ��̿�,P2��ʾ��17��35֮��Ĵ��̿�,P3��ʾ����35�Ĵ��̿顣��ʵ�����ݴ�����Ҷ�ӽڵ㼴3��5��9��10��13��15��28��29��36��60��75��79��90��99����Ҷ�ӽڵ�ֻ���洢��ʵ������,ֻ�洢ָ�����������������,��17��35������ʵ���������ݱ��С�
b+�������ݲ��ҹ���:
�������������29,��ô���Ȼ�Ѵ��̿�1�ɴ��̼��ص��ڴ�,��ʱ����һ��IO,���ڴ����ö��ֲ���ȷ��29��17��35֮��,�������̿�1��P2ָ��,�ڴ�ʱ����Ϊ�dz���(��ȴ��̵�IO)���Ժ��Բ���,ͨ�����̿�1��P2ָ��Ĵ��̵�ַ�Ѵ��̿�3�ɴ��̼��ص��ڴ�,�����ڶ���IO,29��26��30֮��,�������̿�3��P2ָ��,ͨ��ָ����ش��̿�8���ڴ�,����������IO,ͬʱ�ڴ��������ֲ����ҵ�29,������ѯ,�ܼ�����IO����ʵ�������,3���b+�����Ա�ʾ�ϰ��������,����ϰ�������ݲ���ֻ��Ҫ����IO,������߽��Ǿ��,���û������,ÿ�������Ҫ����һ��IO,��ô�ܹ���Ҫ����ε�IO,��Ȼ�ɱ��dz��dz��ߡ�
�����ֶ�:
ͨ������ķ���,IO����ȡ����b+���ĸ߶�h,���赱ǰ���ݱ�������ΪN,ÿ�����̿���������������m,����h=�S(m+1)N,��������Nһ���������,mԽ��,hԽС;��m = ���̿�Ĵ�С / ������Ĵ�С,���̿�Ĵ�СҲ����һ������ҳ�Ĵ�С,�ǹ̶���,���������ռ�Ŀռ�ԽС,�����������Խ��,���ĸ߶�Խ�͡������Ϊʲôÿ��������,�������ֶ�Ҫ������С,����intռ4�ֽ�,Ҫ��bigint8�ֽ���һ������Ҳ��Ϊʲôb+��Ҫ�����ʵ�����ݷŵ�Ҷ�ӽڵ�������ڲ�ڵ�,һ���ŵ��ڲ�ڵ�,���̿��������������½�,���������ߡ������������1ʱ�����˻������Ա���
����ʵ���ݷ����ڲ�ڵ�,���ݿ�����������,������b+������ʹ��ԭ���ı��ṹ�˻�Ϊ���Խṹ��Ҳ�ͽ��Ͳ�ѯ�ٶȡ�
����������ƥ������(����������ƥ��):
��b+�����������Ǹ��ϵ����ݽṹ,����(name,age,sex)��ʱ��,b+���ǰ��մ����ҵ�˳����������������,���統(����,20,F)������������������ʱ��,b+�������ȱȽ�name��ȷ����һ�������ѷ���,���name��ͬ�����αȽ�age��sex,���õ�����������;����(20,F)������û��name����������ʱ��,b+���Ͳ�֪����һ���ò��ĸ��ڵ�,��Ϊ������������ʱ��name���ǵ�һ���Ƚ�����,����Ҫ�ȸ���name����������֪����һ��ȥ�����ѯ�����統(����,F)����������������ʱ,b+��������name��ָ����������,����һ���ֶ�age��ȱʧ,����ֻ�ܰ����ֵ������������ݶ��ҵ�,Ȼ����ƥ���Ա���F��������, ����Ƿdz���Ҫ������,������������ƥ�����ԡ�
�ֶ�ȱʧ�������,ֻ���ѯ��ȱʧ�ֶ�֮ǰ�����ݽ�����ʾ����ǰ������ƥ���ֶε����ݶ��������ʾ��
2����������
��������Ҫ�����Ǽ��ٲ�ѯ,����ijЩ���������ṩԼ��������(����������Ψһ����)
a����������
1.��ͨ����index :���ٲ���
2.Ψһ����
��������:primary key :���ٲ���+Լ��(��Ϊ����Ψһ)
Ψһ����:unique:���ٲ���+Լ�� (Ψһ)
3.��������
-primary key(id,name):������������
-unique(id,name):����Ψһ����
-index(id,name):������ͨ����
4.ȫ������fulltext :���������ܳ�һƪ���µ�ʱ��,Ч����á�
5.�ռ�����spatial :�˽�ͺ�,��������
�����������:hash��btree
hash���͵�����:��ѯ������,��Χ��ѯ��
btree���͵�����:b+��,����Խ��,������ָ��������(���Ǿ�����,��ΪinnodbĬ��֧����)
#��ͬ�Ĵ洢����֧�ֵ���������Ҳ��һ��
InnoDB ֧������,֧���м�������,֧�� B-tree��Full-text ������,��֧�� Hash ����;
MyISAM ��֧������,֧�ֱ���������,֧�� B-tree��Full-text ������,��֧�� Hash ����;
Memory ��֧������,֧�ֱ���������,֧�� B-tree��Hash ������,��֧�� Full-text ����;
NDB ֧������,֧���м�������,֧�� Hash ����,��֧�� B-tree��Full-text ������;
Archive ��֧������,֧�ֱ���������,��֧�� B-tree��Hash��Full-text ������;
b�����������ļ��ַ���
1. ����/ɾ���������
#����һ:������ʱ
����CREATE TABLE ���� (
�ֶ���1 �������� [������Լ��������],
�ֶ���2 �������� [������Լ��������],
[UNIQUE | FULLTEXT | SPATIAL ] INDEX | KEY
[������] (�ֶ���[(����)] [ASC |DESC])
);
#������:CREATE���Ѵ��ڵı��ϴ�������
CREATE [UNIQUE | FULLTEXT | SPATIAL ] INDEX ������
ON ���� (�ֶ���[(����)] [ASC |DESC]) ;
#������:ALTER TABLE���Ѵ��ڵı��ϴ�������
ALTER TABLE ���� ADD [UNIQUE | FULLTEXT | SPATIAL ] INDEX
������ (�ֶ���[(����)] [ASC |DESC]) ;
#ɾ������:DROP INDEX ������ ON ������;
### �鿴�����ĵ�
help create
help create index
==================
1.��������
-�ڴ�����ʱ�ʹ���(��Ҫע��ļ���)
create table s1(
id int ,#���������primary key
#id int index #����������������,��Ϊindexֻ������,û��Լ��һ˵,
#����������,����ΨһԼ��һ��,�ڶ����ֶε�ʱ�������
name char(20),
age int,
email varchar(30)
#primary key(id) #Ҳ���������
index(id) #����������
);
-�ڴ��������ڴ���
create index name on s1(name); #������ͨ����
create unique age on s1(age);����Ψһ����
alter table s1 add primary key(id); #����ס������,Ҳ���Ǹ�id�ֶ�����һ������Լ��
create index name on s1(id,name); #������ͨ��������
2.ɾ������
drop index id on s1;
drop index name on s1; #ɾ����ͨ����
drop index age on s1; #ɾ��Ψһ����,�ͺ���ͨ����һ��,������indexǰ��unique��ɾ,ֱ�ӾͿ���ɾ��
alter table s1 drop primary key; #ɾ������(��Ϊ�����ӵ�ʱ���ǰ���alter�����ӵ�,��ô����Ҳ��alter��ɾ)
# a������,�Ҳ�������
#1. ����
create table s1(
id int,
name varchar(20),
gender char(6),
email varchar(50)
);
#2. �����洢����,ʵ�����������¼
delimiter $$ #�����洢���̵Ľ�������Ϊ$$
create procedure auto_insert1()
BEGIN
declare i int default 1;
while(i<3000000)do
insert into s1 values(i,concat('egon',i),'male',concat('egon',i,'@oldboy'));
set i=i+1;
end while;
END$$ #$$����
delimiter ; #���������ֺ�Ϊ��������
# 3.�鿴�洢����
show create procedure auto_insert1\G
# 4.���ô洢����
call auto_insert1();
��û��������ǰ���²��Բ�ѯ�ٶ�
#������:��ͷ��βɨ��һ��,���Բ�ѯ�ٶȺ���
mysql> select * from s1 where id=333;
+------+---------+--------+----------------+
| id | name | gender | email |
+------+---------+--------+----------------+
| 333 | egon333 | male | 333@oldboy.com |
| 333 | egon333 | f | alex333@oldboy |
| 333 | egon333 | f | alex333@oldboy |
+------+---------+--------+----------------+
rows in set (0.32 sec)
mysql> select * from s1 where email='egon333@oldboy';
rows in set (0.36 sec)
�������ѯ
#1. һ����Ϊ�����������ֶδ�������,����select * from t1 where age > 5;����ҪΪage��������
#2. �ڱ����Ѿ��д������ݵ������,�����������,��ռ��Ӳ�̿ռ�,����ɾ�����¶�����,ֻ�в�ѯ��
����create index idx on s1(id);��ɨ��������е�����,Ȼ����idΪ������,���������ṹ,�����Ӳ�̵ı��С�
�����Ժ�,�ٲ�ѯ�ͻ�ܿ���
#3. ��Ҫע�����:innodb��������������s1.ibd�ļ���,��myisam������������е����������ļ�table1.MYI
3�������ķ�ʽ
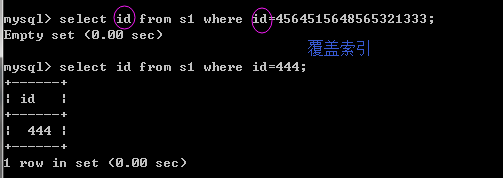
a����������
select * from s1 where id=123;
��sql����������,�����������
����id=123�����������ݽṹ�ж�λ����id��Ӳ���е�λ��,����˵�����ݱ��е�λ�á�
��������select���ֶ�Ϊ*,����id�����Ҫ�����ֶ�,�����ζ��,����ͨ�������ṹȡ��id������,
����Ҫ���ø�id��ȥ�ҵ���id�����е������ֶ�ֵ,������Ҫʱ���,������,�������ֻselect id,
�ͼ�ȥ����ݿ���,����
select id from s1 where id=123;
�������Ǹ���������,��������,�Ҵ����������ݽṹֱ�Ӿ�ȡ����id��Ӳ�̵ĵ�ַ,�ٶȺܿ�
c����������
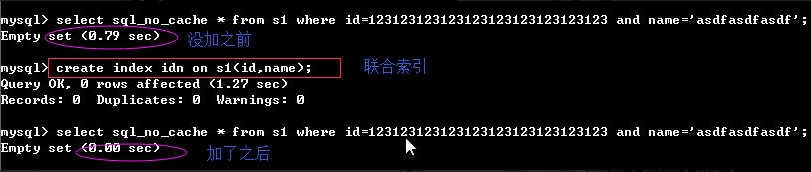
d�������ϲ�
#�����ϲ�:�Ѷ�����������ϲ�ʹ��
#����:
�������������������,���Ƕ������������ϲ�ȥ���,����
create index ne on s1(name,email);
#�������
������ȫ���Ե���Ϊname��email��������
���������������:
select * from s1 where name='egon' ;
select * from s1 where name='egon' and email='adf';
�����ϲ���������:
select * from s1 where name='egon' ;
select * from s1 where email='adf';
select * from s1 where name='egon' and email='adf';
էһ�����������ϲ�������:�������и�������,����ʵҪ�����ȥ��,�����name='egon' and email='adf',
��ô���������Ч��Ҫ���������ϲ�,����ǵ�������,��ô�����������ϲ��ȽϺ���
����ǰ
#1.����ǰƥ��ԭ��,�dz���Ҫ��ԭ��,
create index ix_name_email on s1(name,email,)
- ����ǰƥ��:���밴�մ����ҵ�˳��ƥ��
select * from s1 where name='egon'; #����
select * from s1 where name='egon' and email='asdf'; #����
select * from s1 where email='alex@oldboy.com'; #������
mysql��һֱ����ƥ��ֱ��������Χ��ѯ(>��<��between��like)��ֹͣƥ��,
����a = 1 and b = 2 and c > 3 and d = 4 �������(a,b,c,d)˳�������,
d���ò���������,�������(a,b,d,c)�����������õ�,a,b,d��˳��������������
#2.=��in��������,����a = 1 and b = 2 and c = 3 ����(a,b,c)������������˳��,mysql�IJ�ѯ�Ż���
������Ż�����������ʶ�����ʽ
#3.����ѡ�����ֶȸߵ�����Ϊ����,���ֶȵĹ�ʽ��count(distinct col)/count(*),
��ʾ�ֶβ��ظ��ı���,����Խ������ɨ��ļ�¼��Խ��,Ψһ�������ֶ���1,��һЩ״̬��
�Ա��ֶο����ڴ�������ǰ���ֶȾ���0,�ǿ������˻���,���������ʲô����ֵ��?ʹ�ó�����ͬ,
���ֵҲ����ȷ��,һ����Ҫjoin���ֶ����Ƕ�Ҫ����0.1����,��ƽ��1��ɨ��10����¼
#4.�����в��ܲ������,�����С��ɾ���,����from_unixtime(create_time) = ��2014-05-29��
�Ͳ���ʹ�õ�����,ԭ��ܼ�,b+���д�Ķ������ݱ��е��ֶ�ֵ,
�����м���ʱ,��Ҫ������Ԫ�ض�Ӧ�ú������ܱȽ�,��Ȼ�ɱ�̫��
�������Ӧ��д��create_time = unix_timestamp(��2014-05-29��);