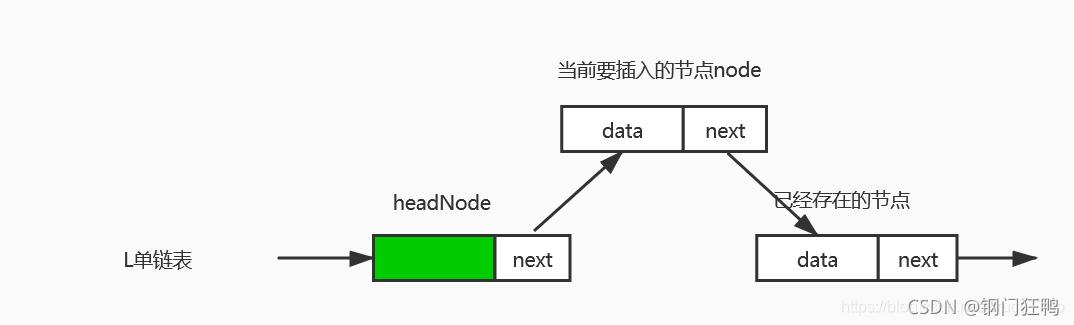
数据结构的存储方式只有两种:数组(顺序存储)和链表(链式存储)
这句话怎么理解,不是还有散列表、栈、队列、堆、树、图等等各种数据结构吗?
我们分析问题,一定要有递归的思想,自顶向下,从抽象到具体。你上来就列出这么多,那些都属于「上层建筑」,而数组和链表才是「结构基础」。因为那些多样化的数据结构,究其源头,都是在链表或者数组上的特殊操作,API 不同而已。
数组(原文链接:https://blog.csdn.net/ws9029/article/details/109405549)
这就像你与朋友(假如3人)去看电影,找到地方就坐后又来了一位朋友,但原来坐的地方没有空位置(你们4人想坐一起),只得再找一个可坐下所有人的地方。在这种情况下,你需要请求计算机重新分配一块可容纳4个位置的内存。如果又来了一位朋友,而当前坐的地方也没有空位,你们就得再次转移!真是太麻烦了。同样,在数组中添加新元素也可能很麻烦。如果没有了空间,就得移到内存的其他地方,因此添加新元素的速度会很慢。
链表
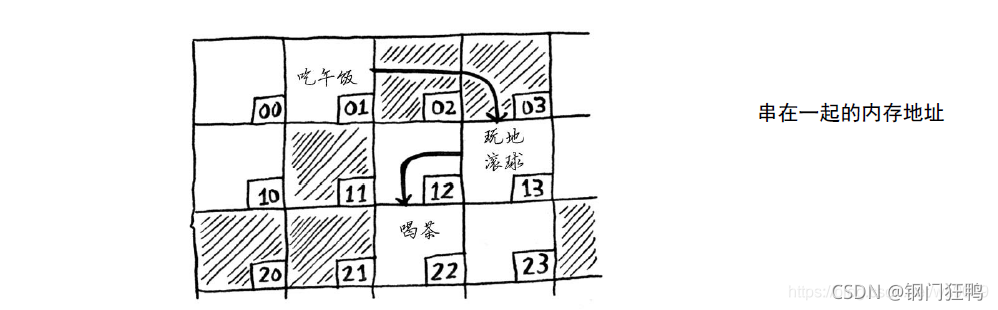
链表中的元素可存储在内存的任何地方。链表的每个元素都存储了下一个元素的地址,从而使一系列随机的内存地址串在一起。
这犹如寻宝游戏。你前往第一个地址,那里有一张纸条写着“下一个元素的地址为123”。因此,你前往地址123,那里又有一张纸条,写着“下一个元素的地址为847”,以此类推。在链表中添加元素很容易:只需将其放入内存,并将其地址存储到前一个元素中。使用链表时,根本就不需要移动元素。这还可避免另一个问题。假设你与五位朋友去看一部很火的电影。你们六人想坐在一起,但看电影的人较多,没有六个在一起的座位。使用数组时有时就会遇到这样的情况。假设你要为数组分配10 000个位置,内存中有10 000个位置,但不都靠在一起。在这种情况下,你将无法为该数组分配内存!链表相当于说“我们分开来坐”,因此,只要有足够的内存空间,就能为链表分配内存。
那么链表有没有缺点?
当读取链的最后一个元素时,你不能直接读取,因为你不知道它所处的地址,必须先访问元素#1,从中获取元素#2的地址,再访问元素#2并从中获取元素#3的地址,以此类推,直到访问最后一个元素。需要同时读取所有元素时,链表的效率很高:你读取第一个元素,根据其中的地址再读取第二个元素,以此类推。但如果你需要跳跃,链表的效率真的很低。
使用链表时,插入元素很简单,只需修改它前面的那个元素指向的地址。而使用数组时,则必须将后面的元素都向后移。因此,当需要在中间插入元素时,链表是更好的选择。假如在链表中删除某个元素,只需修改前一个元素指向的地址即可。而使用数组时,删除元素后,必须将后面的元素都向前移。
总结
下面是数组和链表操作的运行时间:
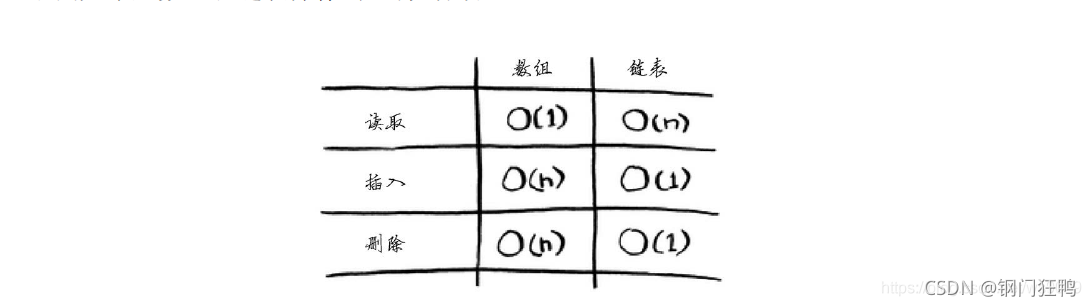
数组和链表哪个用得更多呢?显然要看情况。但数组用得很多,因为它支持随机访问。有两种访问方式:随机访问和顺序访问。顺序访问意味着从第一个元素开始逐个地读取元素。链表只能顺序访问:要读取链表的第十个元素,得先读取前九个元素,并沿链接找到第十个元素。随机访问意味着可直接跳到第十个元素。经常说数组的读取速度更快,这是因为它们支持随机访问。很多情况都要求能够随机访问,因此数组用得很多!
数组遍历框架,典型的线性迭代结构:
void traverse(int[] arr) {
for (int i = 0; i < arr.length; i++) {
// 迭代访问 arr[i]
}
}
链表遍历框架,兼具迭代和递归结构:
/* 基本的单链表节点 */
class ListNode {
int val;
ListNode next;
}
void traverse(ListNode head) {
for (ListNode p = head; p != null; p = p.next) {
// 迭代访问 p.val
}
}
void traverse(ListNode head) {
// 递归访问 head.val
traverse(head.next)
二叉树遍历框架,典型的非线性递归遍历结构:
class TreeNode {
int val;
TreeNode left, right;
}
void traverse(TreeNode root) {
traverse(root.left)
traverse(root.right)
}
头