
[���ݽṹ]�����˴�����
ǰ��
������ѧϰ���ݽṹ��,���Ǿ����Ӵ��������������,��������ѧϰʱ,ֱ����Դ���ʱ����һ��ãȻ,Ϊʲô����ӿ�Ҫ����Щ����,ΪʲôҪǰ������������Щ�������Dz�֪��������ʵ����Щ�ӿ�ʱ���ǵ�˼������ô����,��ƪ�����ҽ�ͨ��������ĸ������ķ���������ķ�����������ÿһ�������˼����ʽ��ʵ�ֹ���,��������������������ʵ��,��������Դ���ʱ����ãȻ
����
������ĸ���
����:��ν����,����ʹһ����¼,�������е�ij����ijЩ�ؼ��ֵĴ�С,������ݼ������������IJ�����
�ȶ���: �ٶ��ڴ�����ļ�¼������,���ڶ��������ͬ�Ĺؼ��ֵļ�¼,����������,��Щ��¼����Դ��ֲ���,����ԭ������,r[i]=r[j],��r[i]��r[j]֮ǰ,����������������,r[i]����r[j]֮ǰ,������������㷨���ȶ���;�����Ϊ���ȶ��ġ�
�ڲ�����: ����Ԫ��ȫ�������ڴ��е�����
�ⲿ����:����Ԫ��̫���ͬʱ�����ڴ���,����������̵�Ҫ�����������֮���ƶ����ݵ�����
����������
�����������Ǿ���ʹ�õ�����,����ʱ�ıȼ�,������ʱ�ĺ����Ƚ�,�����ߵ͵�
1.�ֻ�����ʱ������ʹ��

2.�����е�����ʹ��

��������
�ٸ���
�Ѵ�����ļ�¼����ؼ���ֵ�Ĵ�С������뵽һ���Ѿ��ź��������������,ֱ�����еļ�¼������Ϊֹ,�õ�һ���µ��������� ��
�ڷ���
�����ڿ������ʱ����ܻ��Dz�������ʲô��˼,�������Ǿ��������е�����:
�������ڴ��˿˵�ʱ��,���ǻ�ϵ�ץ��,�����ץ�ƵĹ��̾������ǵIJ�������,�������ǻ�ץ�����ǵĵ�һ����,����Ĭ���������ڵ�������;������ץ���µ���ʱ,���Ǿ��ж�֮ǰ�Ѿ���������в�����һ������,ʹ���ǵ�������Ȼ����,�Դ�����,ֱ���������ƽ���,������ͬʱ,�����������Ҳ���ɰ��մ�С�����˳������

�۴������
ͨ������ķ�������֪���˴���Ҫʵ�ֵĽ��,��������Ҫ����һ������,��������������������,һ���������Ѿ��ź��������,��һ������һ��Ҫ�������ǵ�ǰ�������е�Ԫ����������������Ƿ�����֪,��ʵ���Ǵ������еĵ�һ��Ԫ����Ϊ�������ݿ�ʼ,����ͨ�����ǵIJ����������ʵ�ֽ�������,Ȼ���ٽ�ǰ����Ԫ����Ϊ��������,���ε���,ǰ����Ԫ��,ǰ�ĸ�Ԫ�ء�������ֱ������Ԫ�ض���Ϊ�������ݡ�
Ȼ��������һ����Щ��������ִ�����ǵ�����������,ʵ�������ڲ���Ԫ��֮��,����������Ȼ����,��ô����Ӧ�����ʵ�����ǵ�����������?
������ͨ�������ͼ����й��̷���:

���ʱ������֪����������������ʵ�ֵ�,��ô��������Ӧ����ô��д��?������������ȴ�һ�˿�ʼд��,Ȼ��������ȥ����ѭ���Ĺ���
����������д����һ�˲�������Ĵ���:
void InsertSort(int*a, int n)
{
int end = ? ;//��Ϊ���ʱ�����Dz�֪�����ǵ�end�����λ��,������������?����,��ѭ������������
int tmp = a[end + 1];//�������ǽ�Ҫ�����Ԫ���Ƚ��б���,��Ϊ���Ǻ����Ĵ���Ὣ���λ�õ�Ԫ�ؽ��и���
while (end >= 0)
{
if (tmp < a[end])
{
a[end + 1] = a[end];
end--;
}
else
{
//a[end+1] = tmp;
break;
}
}
a[end + 1] = tmp;//�����ǿ����˶������:�ٵ�����Ҫ�������һֱ�����ǵ��������е����ֶ�ҪС��ʱ��,���ǽ���ŵ�end+1��λ��;���������,����ҲҪ����ŵ�end +1��λ��
}
��������ֻҪ�ٽ�end�Ĵ�С�����������ʵ�����ǵIJ����������,������������end�Ĵ�Сȡֵ���з���

ͨ������ķ���,���ǾͿ��Եó������Ĵ���
void InsertSort(int*a, int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tmp = a[end + 1];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + 1] = a[end];
end--;
}
else
{
break;
}
}
a[end + 1] = tmp;
}
}
�ܴ������
Sort.h
#include<stdio.h>
#include<stdlib.h>
void InsertSort(int* a, int n);
void PrintArray(int*a, int n);
void InsertTest();
Sort.c
#include"Sort.h"
void InsertSort(int*a, int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tmp = a[end + 1];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + 1] = a[end];
end--;
}
else
{
break;
}
}
a[end + 1] = tmp;
}
}
void PrintArray(int*a, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ",a[i]);
}
printf("\n");
}
void InsertTest()
{
int a[] = { 54, 38, 96, 23, 15, 72, 60, 45, 83 };
int size = sizeof(a) / sizeof(int);
PrintArray(a, size);
InsertSort(a, size);
PrintArray(a, size);
}
test.c
#include"Sort.h"
int main()
{
InsertTest();
return 0;
}
������ִ�д����,����ִ�еĽ��Ϊ
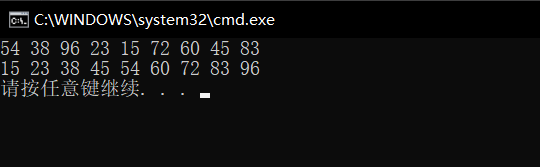
����˵�����ǵķ���˼·������д����ȷ��
�ݲ������������
�������ǶԲ��������ʱ�临�ӶȽ��з���,���ǿ��Եó����������ʱ�临�ӶȵĴ�С,ȡ�������ǵĴ�������,�����ǵĴ�������Ϊ����ʱ,���ǵ�ʱ�临�ӶȾ���O(N^2);�������ǵĴ�������Ϊ˳����߽ӽ�˳��ʱ,���ǵ�ʱ�临�ӶȾ���O(N)
ע��,���ǵó����������������:ʱ�临�ӶȵĴ�Сȡ���ڴ������ݵ�����̶�,��ô������Ǵ����������ڿ�ʼʱ���ȽϽӽ���������,���ʱ�������ٽ��в�������ʱ���ǵ�ʱ�临�ӶȾͿ��Դ���½�,��ô���ǿɲ�����ʵ���ڽ��в�������ǰ�Ƚ���һ������,ʹ�������ݽӽ�����������?
ϣ������

�ٸ���
ϣ�������ֳ���С��������ϣ�����Ļ���˼����:��ѡ��һ������,�Ѵ������ļ������м�¼�ֳɸ���,���о���Ϊ�ļ�¼����ͬһ����,����ÿһ���ڵļ�¼��������Ȼ��,ȡ,�ظ��������������Ĺ�����������=1ʱ,���м�¼��ͳһ�����ź���
�ڷ���
�����ڵ�һ�ζ��������ʱ��,���ܲ������ڽ���ʲô,����ͨ�������ͼ���Ƚ��м���,������ϣ������IJ�������
 ͨ�������ͼ�����,����֪�������ǶԴ������ݽ���һ��ϣ������ʱ,���ǵĴ������ݴ�һ��ʼ�������Ϊ��Ϊ����,���ʱ��������,���������һ�ν���ϣ������,����ô������ݽ���һ�θ���������? �����ʱ�����Ƿ���, ������ǵ�gap����ֵ�������ı�Ļ�,��ô������һ�ν���ϣ�������,���ݲ��ᷢ���ı�,����������Ҫ�ı����ǵ�gap����ֵ��С, ��ô���ʱ�����Ǻ����ǵIJ�����������,���ǿ���˼����,������ǵ�gapֵ�ϴ�,��ô���������ƶ��ĵ�λ����Ҳ��Խ��,��ô���ǵĴ������ݵ������Ծ�Խ��,�෴,��������ǵIJ�������,ÿһ�ε�Ԫ���ƶ�����Ϊһ����λ����,���ʱ�����ǵó��ľ�����������
ͨ�������ͼ�����,����֪�������ǶԴ������ݽ���һ��ϣ������ʱ,���ǵĴ������ݴ�һ��ʼ�������Ϊ��Ϊ����,���ʱ��������,���������һ�ν���ϣ������,����ô������ݽ���һ�θ���������? �����ʱ�����Ƿ���, ������ǵ�gap����ֵ�������ı�Ļ�,��ô������һ�ν���ϣ�������,���ݲ��ᷢ���ı�,����������Ҫ�ı����ǵ�gap����ֵ��С, ��ô���ʱ�����Ǻ����ǵIJ�����������,���ǿ���˼����,������ǵ�gapֵ�ϴ�,��ô���������ƶ��ĵ�λ����Ҳ��Խ��,��ô���ǵĴ������ݵ������Ծ�Խ��,�෴,��������ǵIJ�������,ÿһ�ε�Ԫ���ƶ�����Ϊһ����λ����,���ʱ�����ǵó��ľ�����������

�۴������
ͨ������ķ���,���ǵ�֪����ϣ������ķ�ʽΪ��ν����ƶ���λ����Ϊgap�IJ�������,�������ǵ�gap��ÿִ��һ��ϣ������֮��,���ǵ�gap�����С,���֮�����ǵĴ������ݾʹ������Ϊ��������
���ʱ������֪����������������ʵ�ֵ�,��ô��������Ӧ����ô��д��?������������ȴ�һ�˿�ʼд��,Ȼ��������ȥ����ѭ��������ʹ���ǵ�gap��μ�С������
void ShellSort(int* a, int n)
{
int gap = 3;//�������Ǽ������ǵ�gapΪ3
for (int i = 0; i < n - gap; i++)
{
int end = i ;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
�Դ���������

�������ǵó���һ��ִ�еĴ���,��ʵ�������ǵIJ�������,ֻ��������ÿһ���ƶ��ľ��벻���ǵ�λ����,���Ǵ�СΪgap�ľ���,��ô���ʱ�����Ǿ�Ӧ�ÿ���,���ǵ�gap�Ĵ�СӦ��Ϊ����?
�������ϣ��������gap�Ĵ�С,�ٷ������Ľ�����ÿһ�ν�gap������ / 3,��Ϊ������������ʱЧ�ʸ��� ������֪����� ������ִ��ϣ������ʱ����������ǵ�ϣ��������gap��Ϊ1�Ļ�,Ҳ�������ղ�ִ�в�������Ļ�,���ǵĴ���������Զ�����ܱ�Ϊ��������,��Զֻ�����ӽ���������,��������������
�ڽ�����Щ����֮�����ǿ��Եó����ǵĴ���
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;//������Ա�֤�������һ��gap����ֵΪ1,ʹ�������һ��ִ�в�������
for (int i = 0; i < n - gap; i++)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}
�ܴ������
sort.h
#include<stdio.h>
#include<stdlib.h>
void PrintArray(int* a, int n);
void ShellSort(int* a, int n);
void ShellTest();
sort.c
#include"Sort.h"
void PrintArray(int*a, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ",a[i]);
}
printf("\n");
}
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
gap = gap / 3 + 1;
for (int i = 0; i < n - gap; i++)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
}
a[end + gap] = tmp;
}
}
}
void ShellTest()
{
int a[] = { 54, 38, 96, 23, 15, 72, 60, 45, 83 };
int size = sizeof(a) / sizeof(int);
PrintArray(a, size);
ShellSort(a, size);
PrintArray(a, size);
}
test.c
#include"Sort.h"
int main()
{
ShellTest();
return 0;
}
������ִ�д����,����ִ�еĽ��Ϊ
����˵�����ǵķ���˼·������д����ȷ��
��������(ѡ������)
�ٸ���
ÿһ�δӴ����������Ԫ����ѡ����С(�����)��һ��Ԫ��,��������е���ʼλ��,ֱ��ȫ�������������Ԫ������ ��
�ڷ���
���������ǰ��������Ƚ�����������,�������Ƕ����潲���Ĺ��̽���һ���Ľ���,���������ȶ����潲���ĸ������һ������:
��������н������ÿһ����ѡ����ǰ���������е����ֵ����Сֵ,Ȼ������ͨ������,������������,����ʵ����������,��ô���ǿ��Զ���һ���̽���һ������,����ÿһ���ҵ���ǰ���������е����ֵ����Сֵ,Ȼ�����ǽ���ֱ������һ��Ԫ�غ͵�һ��Ԫ�ؽ���,Ȼ����С���ǵIJ��ҷ�Χ,���ظ������IJ���,����ʵ�����ǵ���������,�������ǵ�Ч�ʿ��Ը���һЩ
�۴������
���������������Ǵ����ʵ�ֽ��з���
������������������,������Ҫ����������־,�ֱ��¼���Ǵ������ݵ�ͷԪ�غ�βԪ��,����������begin��end���;Ȼ������ÿ���������һ��֮��,���Ǿͽ���������һ����Ѱ�ҵ������ֵ��βԪ�ؽ���,��Сֵ��ͷԪ�ؽ���,֮������Ҫ��С������һ�εIJ��ҷ�Χ,��ô���ǵľ�Ҫִ��:begin++;end�C;Ȼ���ظ����������IJ���,����ʵ�ֽ��������ݱ�Ϊ��������
void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
void SelectSort(int* a, int n)
{
int begin = 0;
int end = n - 1;
while (begin <= end)
{
int mini = begin;
int maxi = begin;
for (int i = begin; i <= end; i++)
{
if (a[i] < a[mini])
{
mini = i;//��¼������Сֵ���±�
}
if (a[i] > a[maxi])
{
maxi = i;//��¼�������ֵ���±�
}
}
Swap(&a[mini], &a[begin]);
Swap(&a[maxi], &a[end]);
begin++;
end--;
}
}
�ܴ������
sort.h
#include<stdio.h>
#include<stdlib.h>
void PrintArray(int* a, int n);
void SelectSort(int* a, int n);
void SelectTest();
sort.c
#include"Sort.h"
void PrintArray(int*a, int n)
{
for (int i = 0; i < n; i++)
{
printf("%d ",a[i]);
}
printf("\n");
}
void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
void SelectSort(int* a, int n)
{
int begin = 0;
int end = n - 1;
while (begin <= end)
{
int mini = begin;
int maxi = begin;
for (int i = begin; i <= end; i++)
{
if (a[i] < a[mini])
{
mini = i;
}
if (a[i] > a[maxi])
{
maxi = i;
}
}
Swap(&a[mini], &a[begin]);
Swap(&a[maxi], &a[end]);
begin++;
end--;
}
}
void SelectTest()
{
int a[] = { 54, 38, 96, 23, 15, 72, 60, 45, 83 };
int size = sizeof(a) / sizeof(int);
PrintArray(a, size);
SelectSort(a, size);
PrintArray(a, size);
}
test.c
#include"Sort.h"
int main()
{
SelectTest();
return 0;
}
������ִ�д����,����ִ�еĽ��Ϊ
���ڵ�ִ�н����ʾ���ǵķ���˼·������д����ȷ��;
�������ȷ��?
�������ǻ�һ�鴦�����ݽ��м���
int a[] = { 154, 38, 96, 23, 15, 72, 60, 45, 83 };
������ִ�д����,����ִ�еĽ��Ϊ
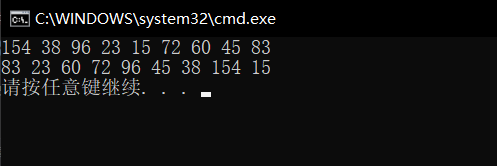
�������Ƿ���,���ǵ�ִ�н����û��ʵ��������Ҫ����������,���ʱ�����ǻ�ͼ��������:
 ��ô������Ҫ�Դ��������,��ô���Ƕ��±�����жϼ���:
��ô������Ҫ�Դ��������,��ô���Ƕ��±�����жϼ���:
void SelectSort(int* a, int n)
{
int begin = 0;
int end = n - 1;
while (begin <= end)
{
int mini = begin;
int maxi = begin;
for (int i = begin; i <= end; i++)
{
if (a[i] < a[mini])
{
mini = i;
}
if (a[i] > a[maxi])
{
maxi = i;
}
}
Swap(&a[mini], &a[begin]);
if (begin == maxi)
{
maxi = mini;
}
Swap(&a[maxi], &a[end]);
begin++;
end--;
}
}
�������ǾͿ��Ա��⽻��ʧ�ܵ����
������
���ڶ����������������ǰ��IJ����н����
���͵�ַ:https://blog.csdn.net/weixin_52664715/article/details/120463777?spm=1001.2014.3001.5501
�����������ٽ���һ�μĽ���:
�ٸ���
������(Heapsort)��ָ���öѻ���(��)�������ݽṹ����Ƶ�һ�������㷨,����ѡ�������һ�֡�����ͨ����������ѡ�����ݡ�
�ڷ���
�����ǽ��ж�����ʱ,���ǵĴ���������һ���������,��ô����������Ҫ�Ƚ�������鴦��Ϊ���(�������ǽ������������Ĭ��Ϊ����)
��ô�������ʵ�ֽ�һ��������鴦��Ϊ�����?�����������ҵ����ǵ����һ������,Ҳ�����������������һ��Ԫ�����ڵ�����,���Ƕ�����������жѵ����µ���,ʹ���������Ϊ���,Ȼ����������ĸ��ڵ���Ϊ���ǵı�����־,��������ڵ���ν��м�һ����,ֱ�����ǵĸ��ڵ㳬�����ǵ����鷶Χ(���ڵ� < 0);
�ѵ����µ�����ʵ��,�������Ǽ���:������Ĭ�ϲ����и��ڵ����ڵ�Ϊ���������нϴ��Ԫ��,Ȼ�������ж��������ڵ��Ƿ����,�������ͬʱ�ж����������ڵ�����������ڵ��,���ͬʱ��������,���ǽ�child��ǵ�������;���ʱ���������жϸ��ڵ��뺢�ӽڵ�Ĵ�С,�����ǵĺ��ӽڵ�����ǵĸ��ڵ��ʱ,���ǽ����ӽڵ��븸�ڵ���н���,ͬʱ�ı亢�ӽڵ���ڵ���±�;Ȼ���ظ���������,ֱ���������µ���ʱ,���ӽڵ�Խ�����ǵ����鷶Χ,��ʱ�������µ�������,������������ṹ��Ϊ���;
����������IJ���֮��,���ǵ��������������ṹ�о���һ�����,��ô����������Ҫ�������ѱ�Ϊ��������(����),���ʱ�����ǽ�����ѵĶ���,Ҳ�������ǵĸ��ڵ����������������һ���ڵ���н���(���е����һ��Ҷ�ڵ���н���),���ʱ�����ǵ�����,��ȥ�������Ԫ��,����ʣ�µ����ݾ��������ڽ���ѵ����µ����е��������,���ڵ�������������Ǵ��,��ô���ʱ�����Ƕ�����������ݽ��жѵ���������,ʹ���ǵ������ֱ�Ϊ���,���ʱ�����ǽ�����ij��ȼ�һ,���ظ�����IJ���,���������ǵ�ѭ������ʱ���Ǿ�ʵ���˽����������漴�����Ϊ��������;
�۴������
����ͼ��˵�����ֽӿ�ʵ�ֵ����:
1.�ѵ����µ���:

2.�ѵĽ���




3.�ѵ�����:

void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
void AdjustDown(int* a, int n, int parent)//a�����ǵ�����;n�����������Ԫ�ظ���;parent�����Ǹ��ڵ������
{
int child = parent * 2 + 1;
while (child < n)
{
//if (a[child + 1] < n && a[child + 1] > a[child])//�ж����ǵ������Ƿ���������;��Ϊ������ǰĬ��������Ϊ���������д����;
if (child + 1< n && a[child + 1] > a[child])//�ж����ǵ������Ƿ���������;��Ϊ������ǰĬ��������Ϊ���������д����;
{
child++;//���ʱ������ȷ�����������Ĵ���,ͬʱ���ǽ����������еĽϴ�����ʵȷ��Ϊ������
}
if (a[child] > a[parent])//���ʱ��������ǵĺ��Ӵ������ǵĸ��ڵ�,��ô���ǽ��н���
{
Swap(&a[child], &a[parent]);//�����ǽ�������֮��,��ô��ǰ��������,��Ϊ����е�һ����,�����������������ƻ�,���ʱ��������Ҫ�������������ظ���������,���½�����
parent = child;
child = parent * 2 + 1;
}
else
{
break;//�����Ǻ��ӱ����ǵĸ��ڵ�Сʱ,˵���ǵĶ�û������
}
}
}
//��������Ҫ��̶�����Ĵ���,���ǽ��з���:
void HeapSort(int* a, int n)//�����n�����ǵ��������
{
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
//���ʱ�����ǽ�һ����������Ƚ�����һ�����;
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
end--;
}
}
�ܴ������
sort.h
#include<stdio.h>
#include<stdlib.h>
void HeapSort(int* a, int n);
void AdjustDown(int* a, int n, int parent);
void HeapTest();
sort.c
void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
void AdjustDown(int* a, int n, int parent)//a�����ǵ�����;n�����������Ԫ�ظ���;parent�����Ǹ��ڵ������
{
int child = parent * 2 + 1;
while (child < n)
{
//if (a[child + 1] < n && a[child + 1] > a[child])//�ж����ǵ������Ƿ���������;��Ϊ������ǰĬ��������Ϊ���������д����;
if (child + 1< n && a[child + 1] > a[child])//�ж����ǵ������Ƿ���������;��Ϊ������ǰĬ��������Ϊ���������д����;
{
child++;//���ʱ������ȷ�����������Ĵ���,ͬʱ���ǽ����������еĽϴ�����ʵȷ��Ϊ������
}
if (a[child] > a[parent])//���ʱ��������ǵĺ��Ӵ������ǵĸ��ڵ�,��ô���ǽ��н���
{
Swap(&a[child], &a[parent]);//�����ǽ�������֮��,��ô��ǰ��������,��Ϊ����е�һ����,�����������������ƻ�,���ʱ��������Ҫ�������������ظ���������,���½�����
parent = child;
child = parent * 2 + 1;
}
else
{
break;//�����Ǻ��ӱ����ǵĸ��ڵ�Сʱ,˵���ǵĶ�û������
}
}
}
//��������Ҫ��̶�����Ĵ���,���ǽ��з���:
void HeapSort(int* a, int n)//�����n�����ǵ��������
{
for (int i = (n - 1 - 1) / 2; i >= 0; i--)
{
AdjustDown(a, n, i);
}
//���ʱ�����ǽ�һ����������Ƚ�����һ�����;
int end = n - 1;
while (end > 0)
{
Swap(&a[0], &a[end]);
AdjustDown(a, end, 0);
end--;
}
}
void HeapTest()
{
int a[] = { 54, 38, 96, 23, 15, 72, 60, 45, 83 };
int size = sizeof(a) / sizeof(int);
PrintArray(a, size);
HeapSort(a, size);//�����n�����ǵ���ֵ����
PrintArray(a, size);
}
test.c
#include"Sort.h"
int main()
{
HeapTest();
return 0;
}
������ִ�д����,����ִ�еĽ��Ϊ
����˵�����ǵķ���˼·������д����ȷ��
����
����ð�����������������ѧϰC���Գ��ڽ��н�����ѧϰ�뽲��,�������ǾͲ�����
void BubbleSort(int* a, int n)
{
for (int j = 0; j < n; j--)//����һ��ѭ�������ǿ������ǽ��������ֵ��ŵ�λ��
{
for (int i = 1; i < n - j; i++)
{
if (a[i - 1] > a[i])
{
Swap(&a[i - 1], &a[i]);
}
}
}
}
���Ƕ�ð���������һ�����Ż�
void BubbleSort(int* a, int n)//��ð��������Ż�:
{
for (int j = 0; j < n; j++)
{
int exchange = 0;
for (int i = 1; i < n - j; i++)
{
if (a[i - 1] > a[i])
{
Swap(&a[i - 1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
{
break;
}
}
}
��������
�ٸ���
����������Hoare��1962�������һ�ֶ������ṹ�Ľ�������,�����˼��Ϊ:��ȡ������Ԫ�������е�ijԪ����Ϊ��ֵ,���ո������뽫�����Ϸָ����������,��������������Ԫ�ؾ�С�ڻ�ֵ,��������������Ԫ�ؾ����ڻ�ֵ,Ȼ���������������ظ��ù���,ֱ������Ԫ�ض���������Ӧλ����Ϊֹ��
�ڷ���
��������ֱ�ӿ���������Ķ�����ܲ���������,�����Ҷ����������Ƚ���һ���Ľ���,�����ڽ��п�������ʱ,�����Ƚ�һ��������Ϊ����Ҫ���������Ԫ��,�����ǽ���һ�ο�������֮��,���Ԫ�ػ��ƶ�����������������������Ϊ������������ȷλ��,ͬʱ,���ﵽ��ȷλ��֮��,Ԫ�ص���ߵ�Ԫ�ض�����ҪС,Ԫ���ұߵ�Ԫ�ض�����Ҫ��
��������ͨ��ͼ������һ�˿��������ִ�й��̽��з���:

�۴������
��������֪���˿��������ִ�й���,��ô�������ڶԴ����ִ�н��з���:
��������֪��������Ҫ��ȷ������ÿһ���е�keyֵ,��ô���Ǿ���Ҫ���䶨���ڳ�����,������Ǵ�������ָ��,�ֱ�ָ�������������Ԫ�غ�βԪ��,Ȼ�����ǿ�ʼ�������ǵ����鷶Χ
�����ǵ�ȷ����keyԪ�������ǵ���Ԫ��ʱ,���Ǵ���ָ�뿪ʼ�ƶ�,Ȼ��ʼ�жϵ�ǰԪ����keyԪ�صĴ�С��ϵ,��ָ��ָ���Ԫ�ش������ǵ�keyԪ��ʱ,ָ��ǰ��,��С���ǵ����鷶Χ,��ָ��ָ���Ԫ��С�����ǵ�keyԪ��ʱ,ָ��ֹͣ�ƶ�;���ǿ�ʼ�ƶ����ǵ���ָ��,��ָ��ָ���Ԫ��С�����ǵ�keyԪ��ʱ,ָ�����,��С���ǵ����鷶Χ,��ָ��ָ���Ԫ�ش������ǵ�keyԪ��ʱ,ָ��ֹͣ�ƶ�;��ʱ���ǽ�����������ָ��ָ���Ԫ��
����֮��,���Ǽ����ظ�����������,ֱ����ָ�����ָ������,�����ǵ�����ָ������ʱ,���ǽ����ǵ�key��ǵ�Ԫ�����ʱ������Ԫ�ؽ��н���,��ʱkeyԪ�ؾ͵�������ȷ������λ��
void PartSort(int* a, int left, int right)//�������DZ�д����һ�������ִ�з�ʽ
{
int keyi = left;
while (left < right)
{
while (left < right && a[right] >= a[keyi])
{
right--;
}
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[keyi], &a[left]);//��ʱ���Ǻ�left��������right�����Ѿ�û������,��Ϊ��������ָ��ָ���Ԫ����ͬ
}
��������ʵ����һ����ʵ�ֽ�keyԪ���ƶ���������֮�����ȷλ��,��ô����������Ӧ����ôȥ�ƶ�ʣ�µ�Ԫ����?
���ʱ�������ڿ�һ�����Ǣ��еķ���,��һ��������:
 ������ִ��һ�˿�������֮��,keyԪ����ߵ�Ԫ�ص�С��keyԪ��,�ұߵ���������keyԪ��
������ִ��һ�˿�������֮��,keyԪ����ߵ�Ԫ�ص�С��keyԪ��,�ұߵ���������keyԪ��
���ʱ�����ǿ��ܻ����뵽����������������ʱ��˼�롪���ֶ���֮,����Ҳ����ͬ��,�����ڵ�һ����ʵ���˽�keyԪ���ƶ���������֮�����ȷλ��,����ʱkeyԪ�ص������������������,����ЩԪ����ִ�п�������֮���λ�÷ֱ���keyԪ�����Ԫ����ɵ������С��ұ�Ԫ����ɵ�������,��������ƶ�֮����Ԫ���ƶ�ʱ��������Խ������⡣ ��������ֻ����ÿִ��һ�ο�������֮��,��������л���,ͨ���ݹ�Ϳ���ʵ�ֽ�������������Ϊ��������,�ﵽ�����Ŀ�ġ�

int PartSort(int* a, int left, int right)//�������DZ�д����һ�������ִ�з�ʽ
{
int keyi = left;
while (left < right)
{
while (left < right && a[right] >= a[keyi])
{
right--;
}
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[keyi], &a[left]);//��ʱ���Ǻ�left��������right�����Ѿ�û������,��Ϊ��������ָ��ָ���Ԫ����ͬ
return left;//��ʱ�±�Ϊleft����right��λ���д�ŵ�������һ��ʼ��keyi�±��ֵ,�������Ƿ������ǽ���֮��keyi������,Ҳ����keyi
}
void QuickSort(int* a, int left, int right)
{
if (left >= right)
{
return;
}
int keyi = PartSort(a, left, right);
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1, right);
}
�ܴ������
sort.h
#include<stdio.h>
#include<stdlib.h>
void QuickSortTest();
void QuickSort(int* a, int left, int right);
int PartSort(int* a, int left, int right);
sort.c
#include"Sort.h"
int PartSort(int* a, int left, int right)//�������DZ�д����һ�������ִ�з�ʽ
{
int keyi = left;
while (left < right)
{
while (left < right && a[right] >= a[keyi])
{
right--;
}
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[keyi], &a[left]);//��ʱ���Ǻ�left��������right�����Ѿ�û������,��Ϊ��������ָ��ָ���Ԫ����ͬ
return left;//��ʱ�±�Ϊleft����right��λ���д�ŵ�������һ��ʼ��keyi�±��ֵ,�������Ƿ������ǽ���֮��keyi������,Ҳ����keyi
}
void QuickSort(int* a, int left, int right)
{
if (left >= right)
{
return;
}
int keyi = PartSort(a, left, right);
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1, right);
}
void QuickSortTest()
{
int a[] = { 6, 1, 2, 7, 9, 3, 4, 5, 10, 8 };
PrintArray(a, sizeof(a) / sizeof(int));
QuickSort(a, 0, sizeof(a) / sizeof(int)-1);
PrintArray(a, sizeof(a) / sizeof(int));
}
void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
test.c
#include"Sort.h"
int main()
{
QuickSortTest();
return 0;
}
������ִ�д����,����ִ�еĽ��Ϊ
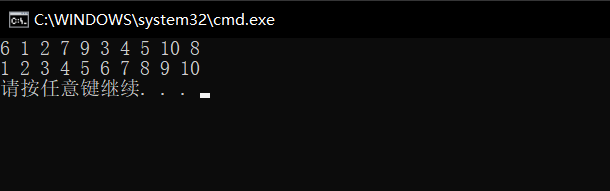
����˵�����ǵķ���˼·������д����ȷ��
�ݴ���ĸĽ�1
��������ʵ���˿��������ִ��,������˼��һ���������,�������Ҫ�����������Ѿ�����������,��ô������ִ�п��������ʱ��ÿһ�ζ�����˲�������,�����Ļ�ʱ�临�Ӷ�̫��,��ô������û��ʲô�취���ԸĽ�һ�����ǵĿ�������ȥ�������������?

�������Dz��� "����ȡ�з�"
���ǵ�����ȡ�з�����Ϊ�˱�������Ҫ������������������,���������ʵ�ַ�����,���DZȽϵ�ǰ���е�left��right��mid����ǵ�Ԫ��,Ȼ������ѡ��������Ԫ�����м��С��Ԫ����key��ǵ�Ԫ�ؽ��н���,,���������ǵĴ�����������������ʱ�Ϳ��Ա������ǵĿ��������Ϊ��������
��������֪�������Ƿ�����ִ�з�ʽ,������������ʵ�ִ���
int GetMidIndex(int* a, int left, int right)
{
int mid = (left + right) / 2;
if (a[left] < a[mid])
{
if (a[mid] < a[right])
{
return mid;
}
else if (a[left] > a[right])
{
return left;
}
else if (a[right] > a[left])
{
return right;
}
}
else//(a[left] > a[mid])
{
if (a[right] > a[left])
{
return left;
}
else if (a[right] > a[mid])
{
return right;
}
else if (a[mid] > a[right])
{
return mid;
}
}
}
ͨ������Ĵ���,���ǿ��ԱȽϳ����������м��С����,ͬʱ���������±�,���ʱ�������ٶԿ�������Ĵ����Լ��ļ���
int PartSort(int* a, int left, int right)//�������DZ�д����һ�������ִ�з�ʽ
{
int midi = GetMidIndex(a, left, right);
Swap(&a[left], &a[midi]);//�����ݽ��н���,�±���Ȼ����
int keyi = left;
while (left < right)
{
while (left < right && a[right] >= a[keyi])
{
right--;
}
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[keyi], &a[left]);//��ʱ���Ǻ�left��������right�����Ѿ�û������,��Ϊ��������ָ��ָ���Ԫ����ͬ
return left;//��ʱ�±�Ϊleft����right��λ���д�ŵ�������һ��ʼ��keyi�±��ֵ,�������Ƿ������ǽ���֮��keyi������,Ҳ����keyi
}
�������
sort.h
#include<stdio.h>
#include<stdlib.h>
void QuickSortTest();
void QuickSort(int* a, int left, int right);
int PartSort(int* a, int left, int right);
int GetMidIndex(int* a, int left, int right);
sort.c
#include"Sort.h"
void QuickSort(int* a, int left, int right)
{
if (left >= right)
{
return;
}
int keyi = PartSort(a, left, right);
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1, right);
}
//Ϊ�˱������������Ѿ�����,���ǽ�������ȡ���㷨��:
int GetMidIndex(int* a, int left, int right)
{
int mid = (left + right) / 2;
if (a[left] < a[mid])
{
if (a[mid] < a[right])
{
return mid;
}
else if (a[left] > a[right])
{
return left;
}
else if (a[right] > a[left])
{
return right;
}
}
else//(a[left] > a[mid])
{
if (a[right] > a[left])
{
return left;
}
else if (a[right] > a[mid])
{
return right;
}
else if (a[mid] > a[right])
{
return mid;
}
}
}
int PartSort(int* a, int left, int right)//�������DZ�д����һ�������ִ�з�ʽ
{
int midi = GetMidIndex(a, left, right);
Swap(&a[left], &a[midi]);//�����ݽ��н���,�±���Ȼ����
int keyi = left;
while (left < right)
{
while (left < right && a[right] >= a[keyi])
{
right--;
}
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[keyi], &a[left]);//��ʱ���Ǻ�left��������right�����Ѿ�û������,��Ϊ��������ָ��ָ���Ԫ����ͬ
return left;//��ʱ�±�Ϊleft����right��λ���д�ŵ�������һ��ʼ��keyi�±��ֵ,�������Ƿ������ǽ���֮��keyi������,Ҳ����keyi
}
void QuickSortTest()
{
int a[] = { 6, 1, 2, 7, 9, 3, 4, 5, 10, 8 };
PrintArray(a, sizeof(a) / sizeof(int));
QuickSort(a, 0, sizeof(a) / sizeof(int)-1);
PrintArray(a, sizeof(a) / sizeof(int));
}
void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
test.c
#include"Sort.h"
int main()
{
QuickSortTest();
return 0;
}
������ִ�д����,����ִ�еĽ��Ϊ
����˵�����ǵķ���˼·������д����ȷ��
�ߴ���ĸĽ�2
�������ǶԿ��������ʵ���ṩ��һ�ַ���,�ڿӷ�
��������ͨ��ͼ������ַ������н���

���Ǻ�������ͬ,��ʵ�ֵ�������Ĵ���
int PartSort(int* a, int left, int right)
{
int key = a[left];
int hole = left;
while (left < right)
{
while (left < right && a[right] >= key)//�ұ���С,���ߵĿ���
{
right--;
}
a[hole] = a[right];//�ҵ���,��������,ͬʱ����ӵ��±�
hole = right;
while (left < right && a[left] <= key)//����Ҵ�,��ұߵĿ���
{
left++;
}
a[hole] = a[left];
hole = left;
}
//���ʱ�������ҵ���keyֵ������λ��,Ȼ��ֵ
a[hole] = key;
return hole;
}
��������
sort.h
#include<stdio.h>
#include<stdlib.h>
void PrintArray(int* a, int n);
void QuickSortTest();
void QuickSort(int* a, int left, int right);
int PartSort(int* a, int left, int right);
sort.c
int PartSort(int* a, int left, int right)
{
int key = a[left];
int hole = left;
while (left < right)
{
while (left < right && a[right] >= key)//�ұ���С,���ߵĿ���
{
right--;
}
a[hole] = a[right];//�ҵ���,��������,ͬʱ����ӵ��±�
hole = right;
while (left < right && a[left] <= key)//����Ҵ�,��ұߵĿ���
{
left++;
}
a[hole] = a[left];
hole = left;
}
//���ʱ�������ҵ���keyֵ������λ��,Ȼ��ֵ
a[hole] = key;
return hole;
}
void QuickSort(int* a, int left, int right)
{
if (left >= right)
{
return;
}
int keyi = PartSort(a, left, right);
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1, right);
}
void QuickSortTest()
{
int a[] = { 6, 1, 2, 7, 9, 3, 4, 5, 10, 8 };
PrintArray(a, sizeof(a) / sizeof(int));
QuickSort(a, 0, sizeof(a) / sizeof(int)-1);
PrintArray(a, sizeof(a) / sizeof(int));
}
void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
test.c
#include"Sort.h"
int main()
{
QuickSortTest();
return 0;
}
������ִ�д����,����ִ�еĽ��Ϊ
����˵�����ǵķ���˼·������д����ȷ��
�����ĸĽ�3
����ѧϰ���������ַ���֮��,�����ٽ�����һ�ֿ��������ִ�з�ʽ, ˫ָ�뷽��
��������ͨ��ͼ��,ֱ��˵����һ�ַ������ִ����ʵ�ֿ�������

��������֪�������ַ�����ʵ�ֹ���,��ô���Ǻ�����Ĺ�����ͬ,�Ƚ���������Ĵ������ʵ��
int PartSort(int* a, int left, int right)
{
int keyi = left;
int prv = left;
int cur = prv + 1;
while (cur <= right)
{
if (a[cur] < a[keyi])
{
Swap(&a[++prv], &a[cur]);
}
cur++;
}
Swap(&a[keyi], &a[prv]);
return prv;
}
��ʱ������ǻ�ͼ���з�����֪,����������ʵ�ֹ�����,���ǻ�����Լ����Լ����������,�������ܻ���Ч�������½�,�������ǿ��Զ�������������Ż�
int PartSort(int* a, int left, int right)//�������Ƕ�������־��һ���ж�,�������±�ָ���λ����ͬʱ,���Dz����н���,�����ͱ������Լ����Լ����������
{
int keyi = left;
int prv = left;
int cur = prv + 1;
while (cur <= right)
{
if (a[cur] < a[keyi] && ++prv != cur)
{
Swap(&a[prv], &a[cur]);
}
cur++;
}
Swap(&a[prv], &a[keyi]);
return prv;
}
�������Ҹ��Ƽ�ʹ�õ�һ�ַ���ȥʵ�����ǿ��������е��˴���,��Ϊ����������,�����ַ��������ⷽ����ܻ���������
��������
sort.h
#include<stdio.h>
#include<stdlib.h>
void PrintArray(int* a, int n);
void QuickSortTest();
void QuickSort(int* a, int left, int right);
int PartSort(int* a, int left, int right);
sort.c
int PartSort(int* a, int left, int right)
{
int keyi = left;
int prv = left;
int cur = prv + 1;
while (cur <= right)
{
if (a[cur] < a[keyi])
{
Swap(&a[++prv], &a[cur]);
}
cur++;
}
Swap(&a[keyi], &a[prv]);
return prv;
}
void QuickSort(int* a, int left, int right)
{
if (left >= right)
{
return;
}
int keyi = PartSort(a, left, right);
QuickSort(a, left, keyi - 1);
QuickSort(a, keyi + 1, right);
}
void QuickSortTest()
{
int a[] = { 6, 1, 2, 7, 9, 3, 4, 5, 10, 8 };
PrintArray(a, sizeof(a) / sizeof(int));
QuickSort(a, 0, sizeof(a) / sizeof(int)-1);
PrintArray(a, sizeof(a) / sizeof(int));
}
void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
test.c
#include"Sort.h"
int main()
{
QuickSortTest();
return 0;
}
������ִ�д����,����ִ�еĽ��Ϊ
����˵�����ǵķ���˼·������д����ȷ��
�ϲ�����
�ٸ���
�鲢����(MERGE-SORT)�ǽ����ڹ鲢�����ϵ�һ����Ч�������㷨,���㷨�Dz��÷��η�(Divide and Conquer)��һ���dz����͵�Ӧ�á���������������кϲ�,�õ���ȫ���������;����ʹÿ������������,��ʹ�����жμ�������������������ϲ���һ�������,��Ϊ��·�鲢��
�ڷ���
�����ڿ��˺ϲ�����ĸ���֮��,�ٽ��֮ǰ��������ѧϰ,��ʵ���ǶԺϲ������ʵ������һЩ��Ϥ�ĸо�,��������ͨ��ͼ����з���

���ǽ�����������зָ�,Ȼ���շֶ���֮��˼��,�����ָ�,�����Ƿָ����������ֻ����һ��Ԫ��ʱ,������Ϊ��ǰ��������,Ȼ�����ǿ�ʼ�ϲ�,���������������,ʹ�úϲ����������Ȼ����,������,����ͨ���ݹ�ʵ�ֽ�������зָ�,Ȼ��������ͨ���ݹ�ʵ�ֽ���������кϲ�,��ʹ�ϲ�����������α�������,���������ǵݹ����ʱ,���ǵ�����ʹ����������Ϊ��������
�۴������
void _MergeSort(int* a, int left, int right, int* tmp)//�ӿڵIJ���:ԭ���顢�������߽硢������ұ߽硢��ʱ����(�����洢ԭ���������)
{
if (left >= right)//���ʱ��˵����Χ��ֻ��һ������,��ô����Ĭ��������
return;
int mid = (right + left) / 2;
//[left,mid][mid+1,right];
_MergeSort(a, left, mid, tmp);
_MergeSort(a, mid + 1, right, tmp);
//�鲢
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
int index = left;//��ʱ�����е�λ�ñ��
while (begin1 <= end1 && begin2 <= end2)//�ָ���������Ȼ��Ԫ��
{
if (a[begin1] < a[begin2])//�����ָ������е�Ԫ�رȽ�,ȡС����
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
//��һ�����,ȫ������ʱ,��һ���ָ���������Ȼ����Ԫ��,�����ƶ�����ʱ������
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
//�鲢��,���ǽ����ݿ�����ԭ������
for (int i = left; i <= right; i++)
{
a[i] = tmp[i];
}
}
void MergeSort(int* a, int n)//����ԭ������ͨ���ݹ���ʵ�ֺϲ�,���������ÿһ�ζ��Լ����õݹ�Ļ�,����Ҫmalloc,��������ÿһ�δ����ķ�Χ���ڱ仯
//�������Ǿ��ڵ�ǰ�ӿ�����дһ���ӿ�,ȥʵ�ֵݹ�
{
int* tmp = (int*)malloc(sizeof(int)* n);//����һ������,���С������Ҫ��������������С���
_MergeSort(a, 0, n - 1, tmp);//����ͨ���ڲ��ӿڵݹ�ʵ������,��ʹ�ñ��ӿ�,ÿһ�ζ�Ҫmalloc,ջ֡�Ŀ���̫��
free(tmp);
}
�ܴ������
sort.h
#include<stdio.h>
#include<stdlib.h>
void PrintArray(int* a, int n);
void MergeSort(int* a, int n);
void _MergeSort(int* a, int left, int right, int* tmp);
void TestMergeSort();
sort.c
void _MergeSort(int* a, int left, int right, int* tmp)//�ӿڵIJ���:ԭ���顢�������߽硢������ұ߽硢��ʱ����(�����洢ԭ���������)
{
if (left >= right)//���ʱ��˵����Χ��ֻ��һ������,��ô����Ĭ��������
return;
int mid = (right + left) / 2;
//[left,mid][mid+1,right];
_MergeSort(a, left, mid, tmp);
_MergeSort(a, mid + 1, right, tmp);
//�鲢
int begin1 = left, end1 = mid;
int begin2 = mid + 1, end2 = right;
int index = left;//��ʱ�����е�λ�ñ��
while (begin1 <= end1 && begin2 <= end2)//�ָ���������Ȼ��Ԫ��
{
if (a[begin1] < a[begin2])//�����ָ������е�Ԫ�رȽ�,ȡС����
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
//��һ�����,ȫ������ʱ,��һ���ָ���������Ȼ����Ԫ��,�����ƶ�����ʱ������
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
//�鲢��,���ǽ����ݿ�����ԭ������
for (int i = left; i <= right; i++)
{
a[i] = tmp[i];
}
}
void MergeSort(int* a, int n)//����ԭ������ͨ���ݹ���ʵ�ֺϲ�,���������ÿһ�ζ��Լ����õݹ�Ļ�,����Ҫmalloc,��������ÿһ�δ����ķ�Χ���ڱ仯
//�������Ǿ��ڵ�ǰ�ӿ�����дһ���ӿ�,ȥʵ�ֵݹ�
{
int* tmp = (int*)malloc(sizeof(int)* n);//����һ������,���С������Ҫ��������������С���
_MergeSort(a, 0, n - 1, tmp);//����ͨ���ڲ��ӿڵݹ�ʵ������,��ʹ�ñ��ӿ�,ÿһ�ζ�Ҫmalloc,ջ֡�Ŀ���̫��
free(tmp);
}
void TestMergeSort()
{
//int a[] = { 6, 1, 2, 7, 9, 3, 4, 5, 10, 8 };
int a[] = { 10, 6, 7, 1, 3, 9, 4, 2 };
PrintArray(a, sizeof(a) / sizeof(int));
MergeSort(a, sizeof(a) / sizeof(int));
PrintArray(a, sizeof(a) / sizeof(int));
}
void Swap(int* px, int* py)
{
int tmp = *px;
*px = *py;
*py = tmp;
}
test.c
#include"Sort.h"
int main()
{
TestMergeSort();
return 0;
}
������ִ�д����,����ִ�еĽ��Ϊ
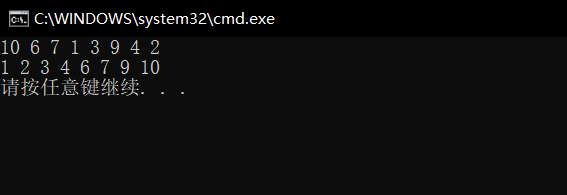
����˵�����ǵķ���˼·������д����ȷ��
��������
�ٸ���
˼��:���������ֳ�Ϊ�볲ԭ��,�ǶԹ�ϣֱ�Ӷ�ַ���ı���Ӧ�á�
�ڷ���
�����и���������̫�����,û��ѧ����Ӧ֪ʶ������������,��������ͨ��ͼ����з���

�۴������
����������Ҫע��,����ͼ���е��������Ǹ����ķ�Χ��С,������ǵ����������Ԫ�صĽϴ�,��Ԫ��֮�����Ծ�ϴ�,��ô����Ӧ����ô������?������ͨ��ͼ������ͽ�����취

ͨ��ͼ��,����֪�������Dz���������ķ���������ǵ�ǰ������ʱ,��������,����ɿռ���˷�,�������Dz������ӳ��İ취,�������ǵ��������ݵĿ���,��������ռ���˷�
void CountSort(int* a, int n)
{
int min = a[0], max = a[0];//��ѡ����ǰ�����е����ֵ����Сֵ
for (int i = 1; i < n; ++i)
{
if (a[i] < min)
{
min = a[i];
}
if (a[i] > max)
{
max = a[i];
}
}
int range = max - min + 1;//Count���鳤��
int* count = (int*)calloc(range, sizeof(int));//����Count����
// ͳ�ƴ���
for (int i = 0; i < n; ++i)
{
count[a[i] - min]++;//����������Ҫ���л�ͼ����,���ӱ�������
}
// ����count��������
int i = 0;
for (int j = 0; j < range; ++j)
{
while (count[j]--)
{
a[i++] = j + min;
}
}
}
����������Ҫ�Դ��е�һ��������з���,����ͨ��ͼ��ķ�ʽ���н���

�ܴ������
sort.h
#include<stdio.h>
#include<stdlib.h>
void PrintArray(int* a, int n);
void TestCountSort();
void CountSort(int* a, int n);
sort.c
void CountSort(int* a, int n)
{
int min = a[0], max = a[0];//��ѡ����ǰ�����е����ֵ����Сֵ
for (int i = 1; i < n; ++i)
{
if (a[i] < min)
{
min = a[i];
}
if (a[i] > max)
{
max = a[i];
}
}
int range = max - min + 1;//Count���鳤��
int* count = (int*)calloc(range, sizeof(int));//����Count����
// ͳ�ƴ���
for (int i = 0; i < n; ++i)
{
count[a[i] - min]++;//����������Ҫ���л�ͼ����,���ӱ�������
}
// ����count��������
int i = 0;
for (int j = 0; j < range; ++j)
{
while (count[j]--)
{
a[i++] = j + min;
}
}
}
void TestCountSort()
{
int a[] = { 10, 6, 7, 1, 3, 9, 4, 2, 2, 3, 6, 7, 4, 10 };
PrintArray(a, sizeof(a) / sizeof(int));
CountSort(a, sizeof(a) / sizeof(int));
PrintArray(a, sizeof(a) / sizeof(int));
}
test.c
#include <time.h>
#include <stdlib.h>
#include "Sort.h"
int main()
{
TestHeapSort();
return 0;
}
������ִ�д����,����ִ�еĽ��Ϊ
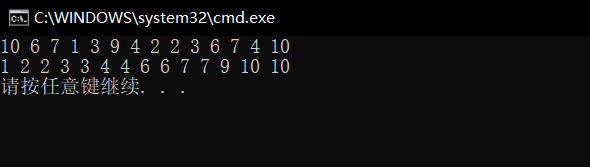
����˵�����ǵķ���˼·������д����ȷ��
�ܽ�
���Ͼ����Ҷ����������а˴�����ĸ��������뽲��,�����һ���������е��ȶ��ԡ�ʱ�临�Ӷȡ��������÷ǵݹ�ʵ�ֽ��н���
������������д���ĵط�,���鷳��λ����ָ�̡�Ĥ�ݸ�λ�ˡ���Ĥ�ݸ�λ�ˡ�
