机器学习基础数学理论
文章目录
矩阵论
范数
欧几里德(L2范数):
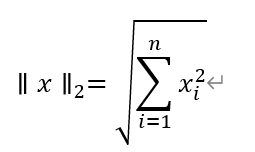
即向量的长度
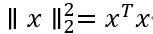
Frobenius范数:
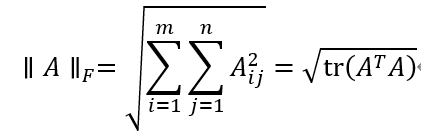
我们有范数族Lp:
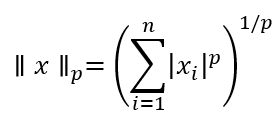 其中,P
≥
\geq
≥ 1
其中,P
≥
\geq
≥ 1
矩阵的值域和零空间
一组向量{x1,…xn}是可以表示为{x1,…xn}的线性组合的所有向量的集合。
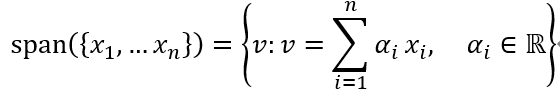
任何向量v
∈
\in
∈Rn都可以写成𝑥1到𝑥𝑛的线性组合。
向量y∈Rm投影到{x1,…xn}(这里我们假设xi∈Rm)得到向量v∈span({x1,…,xn}),由欧几里德范数∥v-y∥2可以得知,这样v尽可能接近y。
我们将投影表示为Proj(y;{x1,…xn }),并且可以将其正式定义为: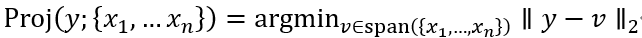
矩阵A∈R(m×n)的值域(有时也称为列空间),表示为R(A),是A列的跨度。换句话说:
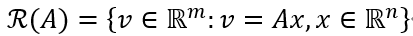
那么,向量y∈Rm到A的范围的投影由下式给出:
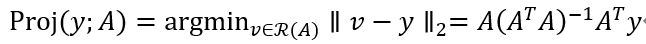
看一下投影的定义,显而易见,这实际上是我们在最小二乘问题中最小化的目标(除了范数的平方这里有点不一样,这不会影响找到最优解),所以这些问题自然是非常相关的。
一个矩阵A∈R(m×n)的零空间 N(A) 是所有乘以A时等于0向量的集合,即:N(A)={x∈Rn :Ax=0}
梯度
假设f:R(m×n)→R是将维度为m×n的矩阵A∈R(m×n)作为输入并返回实数值的函数。 然后f的梯度(相对于A∈R(m×n))是偏导数矩阵,定义如下:

即,m×n矩阵:
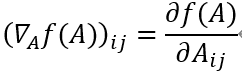
特殊情况,当A为向量A∈Rn时,我们有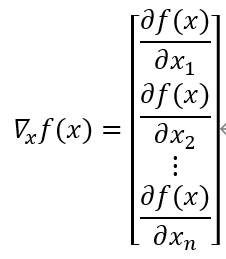
黑塞矩阵(海森矩阵)

话句话说,即:
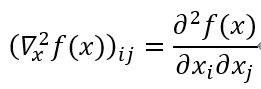
很自然地认为梯度与向量函数的一阶导数的相似,而黑塞矩阵与二阶导数的相似(我们使用的符号也暗示了这种关系)。
最小二乘法
假设我们得到矩阵A∈R(m×n)(为了简单起见,我们假设A是满秩)和向量b∈Rm,从而使b?R(A)。在这种情况下,我们将无法找到向量x∈Rn,由于Ax=b,因此我们想要找到一个向量x,使得Ax尽可能接近 b,用欧几里德范数的平方∥Ax-b∥22来衡量。
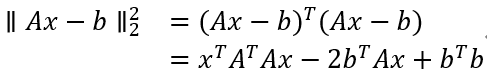
根据x的梯度:
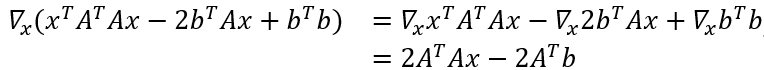
将最后一个表达式设置为零,然后解出x,得到了正规方程:
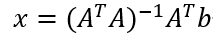
概率论
条件概率
假设B是一个概率非0的事件,我们定义在给定B的条件下A 的条件概率为:
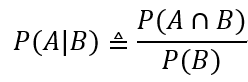
换句话说,P(A|B)是度量已经观测到B事件发生的情况下A事件发生的概率,两个事件被称为独立事件当且仅当P(A∩B)=P(A)P(B)(或等价地,P(A|B)=P(A))。因此,独立性相当于是说观察到事件B对于事件A的概率没有任何影响。
累积分布函数
累积分布函数(CDF)是函数FX: R→[0,1],它将概率度量指定为:
FX (x)?P(X≤x)
概率质量函数
对于一些离散随机变量,当随机变量X取有限种可能值时,表示与随机变量相关联的概率度量的更简单的方法是直接指定随机变量可以假设的每个值的概率。特别地,==概率质量函数(PMF)==是函数 pX: Ω→R,这样:
p~X~ (x)?P(X=x)
概率密度函数
对于一些连续随机变量,累积分布函数FX (x)处可微。在这些情况下,我们将==概率密度函数(PDF)==定义为累积分布函数的导数,即:
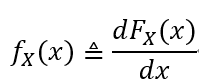
期望
假设X是一个离散随机变量,其PMF为 pX (x),g: R→R是一个任意函数。在这种情况下,g(X)可以被视为随机变量,我们将g(X)的期望值定义为:
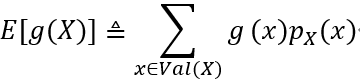
如果X是一个连续的随机变量,其PDF 为fX (x),那么g(X)的期望值被定义为:
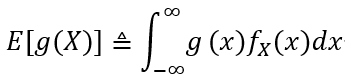
直觉上,g(X)的期望值可以被认为是g(x)对于不同的x值可以取的值的==“加权平均值”==,其中权重由pX (x)或fX (x)给出。
方差
随机变量X的方差是随机变量X的分布围绕其平均值集中程度的度量。形式上,随机变量X的方差定义为:
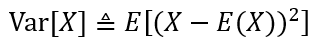
其替代公式:
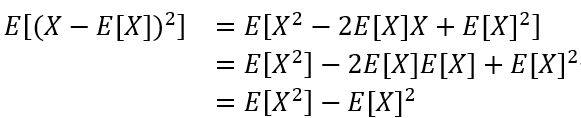
标准差:
方差结果开根号。
举例:
计算均匀随机变量X的平均值和方差,任意x∈[0,1],其PDF为 pX (x)=1,其他地方为0。

注意上述第二个公式X2对应仍为的fx(x)而不是fx(x2),因为其变量仍为x,概率密度函数不变。
一些常见的随机变量

一些随机变量的概率密度函数和累积分布函数的形状如图所示。

重要公式和结论

两个随机变量
假设我们有两个随机变量,一个方法是分别考虑它们。如果我们这样做,我们只需要FX (x)和FY (y)。但是如果我们想知道在随机实验的结果中,X和Y同时假设的值,我们需要一个更复杂的结构,称为X和Y的联合累积分布函数,定义如下:
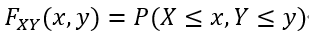
可以证明,通过了解联合累积分布函数,可以计算出任何涉及到X和Y的事件的概率。
联合CDF: FXY (x,y)和每个变量的联合分布函数FX (x)和FY (y)分别由下式关联:
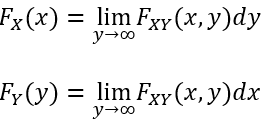
这里我们称FX (x)和FY (y)为 FXY (x,y)的边缘累积概率分布函数。
联合概率和边缘概率质量函数
如果X和Y是离散随机变量,那么联合概率质量函数 pXY: R×R→[0,1]由下式定义:
pXY (x,y)=P(X=x,Y=y)
这里, 对于任意x,y,0≤PXY (x,y)≤1, 并且 ∑x∈Val(X)∑y∈Val(Y)PXY (x,y)=1
两个变量上的联合PMF分别与每个变量的概率质量函数有什么关系?
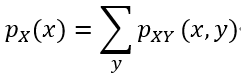
对于pY (y)类似。在这种情况下,我们称pX (x)为X的边际概率质量函数。
联合概率和边缘概率密度函数
假设X和Y是两个连续的随机变量,具有联合分布函数FXY。在FXY (x,y)在x和y中处处可微的情况下,我们可以定义联合概率密度函数:
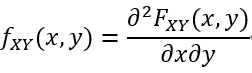
请注意,概率密度函数fXY (x,y)的值总是非负的,但它们可能大于1。尽管如此,可以肯定的是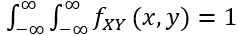
与离散情况相似,我们定义:
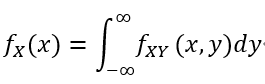
作为X的边际概率密度函数(或边际密度),对于fY (y)也类似。
条件概率分布
条件分布试图回答这样一个问题,当我们知道X必须取某个值x时,Y上的概率分布是什么?在离散情况下,给定Y的条件概率质量函数是简单的:
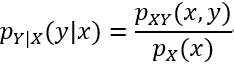
简单地定义给定X=x的条件概率密度为:
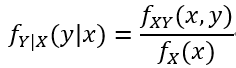
贝叶斯定理
对于离散随机变量X和Y:
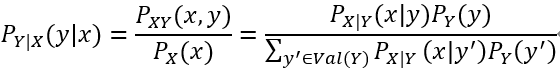
对于连续随机变量X和Y:
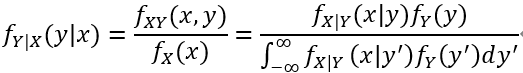
期望和协方差
假设我们有两个离散的随机变量X,Y并且g: R2→R是这两个随机变量的函数。那么g的期望值以如下方式定义:
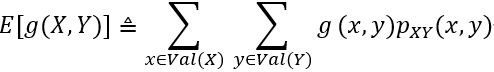
对于连续随机变量X,Y,类似的表达式是:
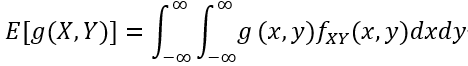
我们可以用期望的概念来研究两个随机变量之间的关系。特别地,两个随机变量的协方差定义为:
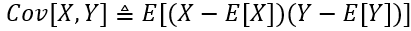
使用类似于方差的推导,我们可以将它重写为:
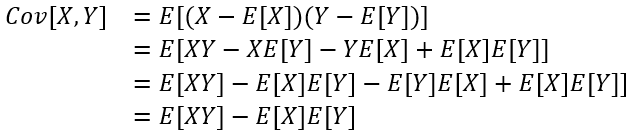
在这里,说明两种协方差形式相等的关键步骤是第三个等号,在这里我们使用了这样一个事实,即E[X]和E[Y]实际上是常数,可以被提出来。当cov[X,Y]=0时,我们说X和Y不相关。

常见二维随机变量联合分布

多个随机变量
我们可以定义X1,X2,?,Xn的联合累积分布函数、联合概率密度函数,以及给定X2,?,Xn时X1的边缘概率密度函数为:
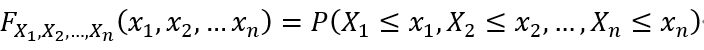

为了计算事件A?Rn的概率,我们有:
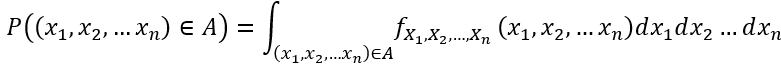
链式法则:
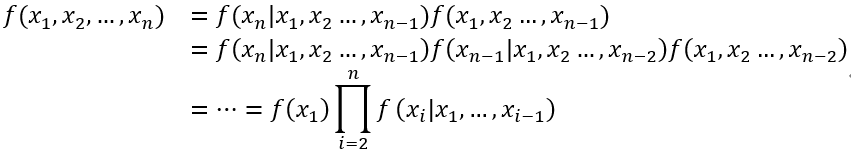
随机变量X_1,X_2,?,X_n是独立的:
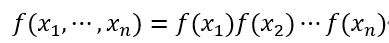
独立随机变量经常出现在机器学习算法中,其中我们假设属于训练集的训练样本代表来自某个未知概率分布的独立样本。为了明确独立性的重要性,考虑一个“坏的”训练集,我们首先从某个未知分布中抽取一个训练样本(x(1),y(1)),然后将完全相同的训练样本的m-1个副本添加到训练集中。在这种情况下,我们有:
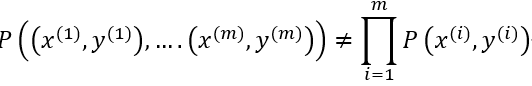
这些例子并不独立。在实践中,样本的不独立性经常出现,并且它具有减小训练集的“有效大小”的效果。
随机向量
假设我们有n个随机变量。当把所有这些随机变量放在一起工作时,我们经常会发现把它们放在一个向量中是很方便。.我们称结果向量为随机向量(更正式地说,随机向量是从Ω到R^n的映射)。应该清楚的是,随机向量只是处理n个随机变量的一种替代符号,因此联合概率密度函数和综合密度函数的概念也将适用于随机向量。
如果g是:
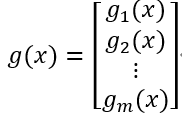
那么有期望:
考虑g: Rn→R中的任意函数。
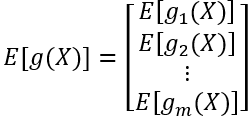
其中,
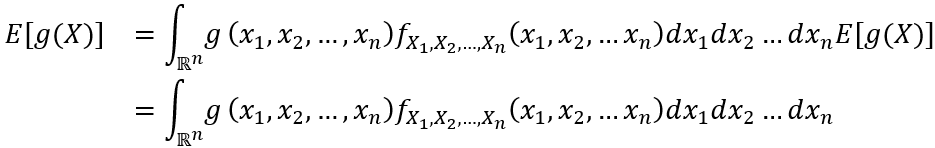
协方差矩阵:

多元高斯分布
随机向量上概率分布的一个特别重要的例子叫做多元高斯或多元正态分布。随机向量X∈Rn被认为具有多元正态(或高斯)分布,当其具有均值μ∈Rn和协方差矩阵Σ∈S++n(其中S++n指对称正定n×n矩阵的空间)
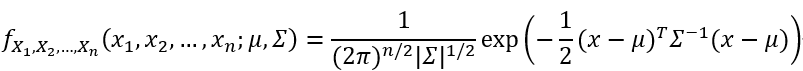
我们把它写成X~N(μ,Σ)。请注意,在n=1的情况下,它降维成普通正态分布,其中均值参数为μ1,方差为Σ11。
一般来说,高斯随机变量在机器学习和统计中非常有用,主要有两个原因:
首先,在统计算法中对“噪声”建模时,它们非常常见。通常,噪声可以被认为是影响测量过程的大量小的独立随机扰动的累积;根据中心极限定理,独立随机变量的总和将趋向于“看起来像高斯”。
其次,高斯随机变量便于许多分析操作,因为实际中出现的许多涉及高斯分布的积分都有简单的封闭形式解。
数理统计
基本概念
总体:研究对象的全体,它是一个随机变量,用X表示。
个体:组成总体的每个基本元素。
简单随机样本:来自总体X的n个相互独立且与总体同分布的随机变量X1,X2,…,Xn,称为容量为n的简单随机样本,简称样本。
统计量:设X1,X2,?,Xn,是来自总体X的一个样本,g(X1,X2,?,Xn)是样本的连续函数,且g(?)中不含任何未知参数,则称g(X1,X2,?,Xn)为统计量 。

分布

其中,

正态总体的常用样本分布
设X1,X2,?,Xn为来自正态总体N(μ,σ2)的样本:

以上参考来自 http://www.ai-start.com/ml2014/.