����Ŀ¼
һ��ʲô��KMP�㷨?
KMP�㷨��һ�ָĽ����ַ���ƥ���㷨,��D.E.Knuth,J.H.Morris��V.R.Pratt�����,������dz���Ϊ��Ŭ�ء�Ī��˹�������ز���(���KMP�㷨)��KMP�㷨���� BF �㷨�����ϸĽ��õ����㷨��ѧϰ BF �㷨����֪��,���㷨��ʵ�ֹ��̾��� ��ɵ��ʽ�� ����ģʽ��(�ٶ�Ϊ�Ӵ��Ĵ�)�������е��ַ�һһƥ��,ƥ�䲻�ɹ��ص���һ��������ƥ�����һλ�ַ�����ƥ��,�㷨ִ��Ч�ʲ��ߡ�
����KMP�㷨�Ľ������
KMP�㷨�������ݽṹ�������ַ����ƥ�������������㷨��KMP�㷨����������һ����֪�ַ����в����Ӵ���λ��,Ҳ��������ģʽƥ�䡣����,������ A(��ABCABCE��)��ģʽ�� B(��ABCE��)����ģʽƥ��,�����Ϊȥ�ж�,����ƥ�����Ρ���Ȼ�������ַ����ٵĴ�����Ϊƥ�������,�����ü������ƥ��������һЩ,���ǵ��ַ����е��ַ��dz����ʱ��,�Ͳ�������Ϊȥƥ�䡣���Դ�����������Ӳ,���ǰ����ֿ��������һ�����㷨���������������
ͼ1:
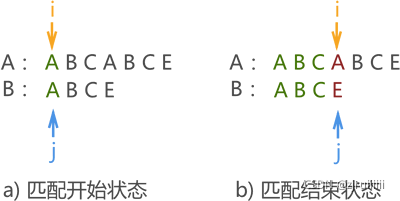
��һ����ͼ 1 ��ʾ,����ƥ��ʧ�ܡ����ڱ���ƥ�������,���ǿ��Ի��һЩ��Ϣ,ģʽ���� ��ABC�� ����������Ӧ���ַ���ͬ,��ģʽ�����ַ� ��A�� �� ��B�� �� ��C�� ��ͬ��
��˽����´�ģʽƥ��ʱ,û�б�Ҫ�ô� B �е� ��A�� �������е�һ��ƥ����ַ� ��B�� �� ��C�� һһƥ��(���Ǿ���������ͬ),����ֱ��ȥƥ��ʧ��λ�ô����ַ� ��A�� ,��ͼ����ʾ��
ͼ2:
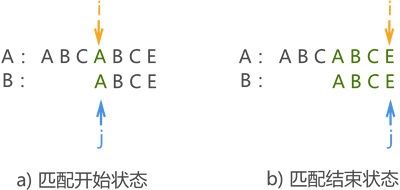
����,ƥ��ɹ�����ʹ�� BF �㷨,���ģʽƥ�������Ҫ���� 4 �Ρ�
�ɴ˿��Կ���,ÿ��ƥ��ʧ�ܺ�ģʽ���ƶ��ľ��벻һ���� 1,ijЩ�����һ�ο��ƶ����λ��,���λ���Dz�ȷ����,��������ȷ�����ƶ�λ�þ���KMP�㷨���ѵ����ص�,����� KMP ģʽƥ���㷨��
����ģʽ���ƶ�������ж�(next����)
ÿ��ģʽƥ��ʧ�ܺ�,����ģʽ������ƶ��ľ����� KMP �㷨�еĺ��IJ��֡�
��ʵ,ƥ��ʧ�ܺ�ģʽ���ƶ��ľ��������û�й�ϵ,ֻ��ģʽ�������й�ϵ��
����,���ǽ�ǰ���ģʽ�� B ��Ϊ ��ABCAE��,���ڵ�һ��ģʽƥ��ʧ��,����ƥ��ʧ��λ��ģʽ�����ַ� ��E�� ǰ���������ַ� ��A��,���,�ڶ���ģʽƥ��Ӧ��Ϊͼ����ʾ��λ��:
ͼ��:
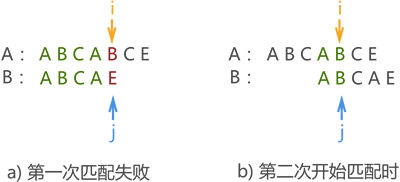
���ͼ 1��ͼ 2 ��ͼ 3 ���ѿ���,ģʽ���ƶ��ľ���ֻ�������й�ϵ,�������ء����仰˵,����������α任,ֻҪ����ģʽ��,��ƥ��ʧ�ܺ��ƶ��ľ�����Ѿ�ȷ���ˡ�
�������,ģʽ�����κ�һ���ַ������ܵ���ƥ��ʧ��,��˴���ÿ���ַ���Ӧ�ö�Ӧһ������,������ʾƥ��ʧ�ܺ�ģʽ���ƶ��ľ��롣
���,���ǿ��Ը�ÿ��ģʽ���䱸һ������(���� next[]),���ڴ洢ģʽ����ÿ���ַ���Ӧָ�� j �ض����λ��(Ҳ���Ǵ洢ģʽ���������±�)��
ģʽ���и��ַ���Ӧ next ֵ�ļ��㷽ʽ��,ȡ���ַ�ǰ����ַ���(�������Լ�),��ǰ�ַ����ͺ��ַ�����ͬ�ַ������������Ǹ��ַ���Ӧ�� next ֵ��
ǰ�ַ���ָ����λ��ģʽ����ʼλ�õ��ַ���,����ģʽ�� ��ABCD��,�� ��A������AB������ABC�� �Լ� ��ABCD�� ������ǰ�ַ���;���ַ���ָ����λ�ڴ���β�����ַ���,����ģʽ�� ��ABCD�� ��˵,��D������CD������BCD�� �� ��ABCD�� Ϊ���ַ���������˵,next����ļ��㷽ʽ����ָ��������Ҫ����ƥ����ַ���ǰһ���ַ�Ϊ��,��ȡģʽ���е�һ���ַ�Ϊ���ַ�����Ϊǰ,������ģʽ���е�һ���ַ���Ϊǰ����Ҫ�Ƚϵ��ַ�����һ���ַ���Ϊ����������ͬ�Ĵ����Ⱦ��ǽ�Ҫ����ƥ����ַ���next[�±�]ֵ,û����ͬ����nextֵΪ0��next��ֵ��Ϊƥ�䲻�ɹ�����һ��ƥ�佫Ҫ���ݵ�ģʽ�����±ꡣ
ע��,ģʽ���е�һ���ַ���Ӧ��ֵΪ -1,�ڶ����ַ���Ӧ 0 ,���ǹ̶�����ġ����,ͼ 3 ��ģʽ�� ��ABCAE�� ��,���ַ���Ӧ�� next ֵ��ͼ4��ʾ:
ͼ��:
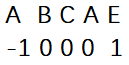
��Ϊ��ǰ�����һ���ַ���A�����ַ���B����nextֵ�Ѿ�ȷ��,���ַ���C����ǰ��ֻ���ַ���A�����ַ���B��,û����ͬ�Ĵ���Ϊ0;�����,��Ҫ����ƥ����ַ���A����ǰ�����ַ���A�����ַ���B�����ַ���C��,û����ǰΪA,��ΪC�������ַ���,��˸��ַ���A����nextֵΪ0;�����,��Ҫƥ����ǡ�E���ַ�,����E���ַ�ǰ�������ַ���A��Ϊǰ,���ַ���A��Ϊ�����ַ���,�����ַ�����A��,�䳤��Ϊ1(һ���ַ��ڴ˴���һ��������ʾ),���ַ���E���ĵ�nextֵΪ1��
�������� next �����ʵ�ַ�ʽ��Ϊ���ô�ҶԴ�����Ĺ�����һ����������ʶ��������ѧϰ����ñ�̵�˼��ʵ�� next ���顣���ʵ�� next ����Ҫ�������Ҫ������Ȼ�� ����μ���ÿ���ַ�ǰ��ǰ�ַ����ͺ��ַ�����ͬ�ĸ�������
�������������next���������
����һ:
ͼ��:
���ǹ۲�ͼ��,ǰ��������next[i]=k��p[i]=p[k],����ģʽ��Ϊp,���Թ۲쵽�������Ĺ���:ʽ��һ:p[0]...p[k-1]=p[x]...p[i-1] (��һ�����ֵĴ�abc��i�±�ǰ���һ����abc�������) ,���x��ģʽ��p�е�ijһ���±ꡣ�д˹��ɺ�,��������Ϊk-1-0==i-1-x,������x=i-k ����x=i-k���ص�ʽ��һ����,��ʽ�Ӷ�:p[0]...p[k-1]=p[i-k]...p[i-1]����Ϊ��ǰ��p[i]=p[k],��p[i-1]��Ϊp[i],p[k-1]��Ϊp[k],�����������õ�ʽ����:p[0]...p[k]=p[i-k]...p[i]����Ϊ��ʽ������ǰ������next[i]=k,�����Ƴ�next[i+1]=k+1 (next�������κ�����¶�Ҫ����������)��
ͼ��:

���ζ�:
ͼ��:

��ʱ������p[i]=p[k](�κ�ʱ����next[i]=k),��ô����������������next������±���?���������һ������,�������ζ��ͻ�ܶࡣ���p[i]!=p[k],����ͼ�߾���,��һ��ƥ�䲻�ɹ�,ģʽ��p���˵��±�Ϊ2��λ��,�����±�Ϊ2��λ�õ��ַ���ʼ�Ͳ�һ����Ҫ�ҵ��ַ�����ʱ����Ҫ��������,���˵����±�0,����һ���ַ���a��,��ʱ���Ƿ��־�Ȼ�ٴ�������next[i+1]=k+1��
��Ȼ����һ���������,ֻ�ǵ����������next����,Ҳ���ǵ�����������ݵ���һ���ַ�ʱ��Ȼ����ͬ,��ʱ��������±�Ϊ-1���ַ���,�������ǵ��������Dz������±�Ϊ-1�ġ���˻��ݵ��±�Ϊ0�ľ����ٻ�����,ֻ�ܴ�ģʽ��p�ĵ�һ���ַ���ʼ����ƥ�䡣
ע��:
- next�����ֵÿ��ֻ�ܼ�1,�������ż�,����һ���Ǵ��ġ�
- ��ȷ����Ҫȷ��ij���ַ���Ӧ��next��ֵ�����������±�Ϊk���ַ�����ͬʱ,��Ҫȷ��ij���ַ���nextֵ��һ��Ҫ��0��ʼ��
- �ñ����ʵ��next������Ҫע��������Dz�֪����i��nextֵΪ����,��������֪��ֻҪ��p[i]=p[k],��ض���next[i+1]=k���������Ҫ��ǰ�����ơ�ֻ��next������±�Ϊ0��ֵ����-1,������nextֵ�����С�֪ǰ�����Ƶ���
�������ʹ������˼��ʵ�� next ����� C ���Դ���:
#include <stdio.h>
#include <string.h>
#include <assert.h>
#include <stdlib.h>
void GetNext(char* arr2, int* next)//arr2Ϊ�ִ�
{
int i = 0;
int k = -1;
int len2 = strlen(arr2);
next[0] = -1;
while (i < len2)
{
if (k == -1 || arr2[i] == arr2[k])//k==-1ʱ���������:��һ����һ��ʼk��Ϊ-1,�ڶ�����k=-1�Dz����ٻ��ݡ�
{
k++;//�������kһ��ֻ��1
i++;//�Ӵ�������һλ���next��ֵ
next[i] = k;//����next��ֵ
}
else
{
k = next[k];//�ַ���ͬ�����
}
}
}
int KMP(char* arr1, char* arr2) //arr1Ϊ����,arr2Ϊ�ִ�
{
assert(arr1 && arr2); //��֤�����ָ�벻�ǿ�ָ��
int len1 = strlen(arr1);
int len2 = strlen(arr2);
if (len2<0 || len2>len1)
{
return -1;
}
if (len1 == 0 || len2 == 0) //���ֲ����ܵ����
{
return -1;
}
int* next = (int*)malloc(sizeof(int) * len2);//Ϊnext���鶯̬���ٿռ�
GetNext(arr2, next);
int i = 0;
int j = 0;
while (j == -1 || i < len1 && j < len2)
{
if (arr1[i] == arr2[j])//�Ƚ���Ⱦ�����һλ
{
i++;
j++;
}
else
{
j = next[j];//�����������Ӵ�,��������
}
}
if (j >= len2)
{
return i - j;//�����������ִ���ʼƥ�䵽�ɹ��Ŀ�ʼλ��
}
return -1;//�Ӵ�������û�п�ƥ����ַ���
}
int main()
{
char arr1[] = "abababcabc";
char arr2[] = "abcabc";
printf("%d", KMP(arr1, arr2));
return 0;
}
�ġ�KMP�㷨�ľ���ʵ��
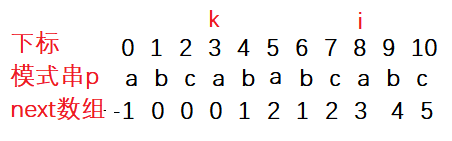
�������� A Ϊ ��ababcabcacbab��,ģʽ�� B Ϊ ��abcac��,�� KMP �㷨ִ�й���Ϊ:
- ��һ��ƥ����ͼ����ʾ,ƥ����ʧ��,ָ�� j �ƶ��� next[j] ��λ��:
ͼ��:
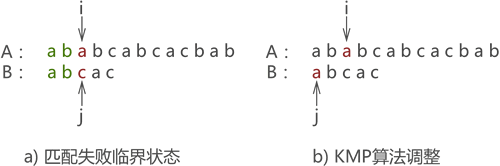
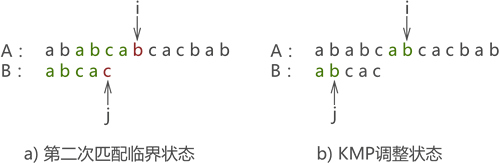
- �ڶ���ƥ����ͼ����ʾ,ƥ����ʧ��,����ִ�� j=next[j] ����:
ͼ��:
- ������ƥ��ɹ�,��ͼʮ��ʾ:
ͼʮ:
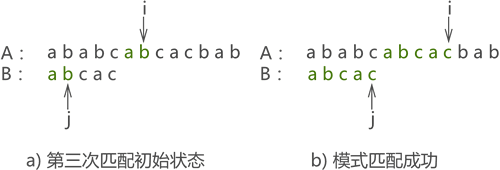
������,ʹ�� KMP �㷨ֻ��ƥ�� 3 ��,��ͬ��������ʹ�� BF �㷨����ƥ�� 6 �β�����ɡ�
�塢KMP�㷨��ʱ�临�Ӷ�
�������Ƿ���һ��KMP�㷨��ʱ�临�Ӷ�:
KMP�㷨�ж���һ��������Ĺ���,��������һ���ռ䡣����������s����Ϊn,�Ӵ�t�ij���Ϊm����next����ʱʱ�临�Ӷ�ΪO(m),�����ƥ��������������,�Ƚϴ����ɼ�Ϊn,����KMP�㷨����ʱ�临�Ӷ�ΪO(m+n),�ռ临�Ӷȼ�ΪO(m),ֻΪnext���鿪����m��int�ֽڴ�С�Ŀռ䡣��������ص�ģʽƥ��ʱ�临�Ӷ�O(m*n),KMP�㷨�����Ƿdz���ġ�
����next����ĸĽ��Cnextval���鼰�������
ͼʮһ:
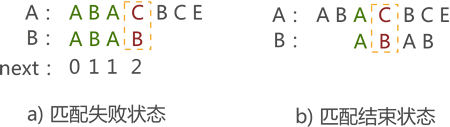
����,��ͼʮһ�е�a),��ƥ��ʧ��ʱ,Next ��������ͼʮһ�� b) ��ʼ��������ģʽƥ��,���Ǵ�ͼ�п��Կ���,��������û�б�Ҫ��,�����˷�ʱ�䡣Ӧ��ֱ�Ӵӵ�һ���ַ���A�����¿�ʼƥ�䡣��ô��θĽ�next������?
ͼʮ��:

ʹ�þ������� next �����ڽ������ģʽ��Ϊ ��aaaaaaab�� �����������,�������Ч��,��ͼʮ����ʾ,����ǰΪ next1,�����Ϊ next2����Ȼ�����Ϊ����,����Ҫ�����next�������������nextval���顣
����:���aλ�ַ�����nextֵָ���bλ�ַ����,���aλ��nextval��ָ��bλ��nextvalֵ,�������,���aλ��nextvalֵ�������Լ�aλ��nextֵ��
next����Ľ���Ĵ���:
#include <stdio.h>
#include <string.h>
#include <assert.h>
#include <stdlib.h>
void GetNext(char* arr2, int* next)
{
int i = 0;
int k = -1;
int len2 = strlen(arr2);
next[0] = -1;
while (i < len2)
{
if (k == -1 || arr2[i] == arr2[k])
{
k++;
i++;
if (arr2[i] == arr2[k])//�����һ��if�������һλ���ַ���arr2[i]��arr2[k]��Ȼ�����ֱ��һ���Ի��ݵ�λ
{
next[i] = next[k];
}
else //arr2[i] != arr2[k]
{
next[i] = k; //���ö�λ���,��next����һ��
}
}
else
{
k = next[k];
}
}
}
int KMP(char* arr1, char* arr2)
{
assert(arr1 && arr2);
int len1 = strlen(arr1);
int len2 = strlen(arr2);
if (len2<0 || len2>len1)
{
return -1;
}
if (len1 == 0 || len2 == 0)
{
return -1;
}
int* next = (int*)malloc(sizeof(int) * len2);
GetNext(arr2, next);
int i = 0;
int j = 0;
while (j == -1 || i < len1 && j < len2)
{
if (arr1[i] == arr2[j])
{
i++;
j++;
}
else
{
j = next[j];
}
}
if (j >= len2)
{
return i - j;
}
return -1;
}
int main()
{
char arr1[] = "abababcabc";
char arr2[] = "abcabc";
printf("%d", KMP(arr1, arr2));
return 0;
}
�ߡ����Ļ�
ʵ������,���߶�KMP�㷨���˽�һ��ʼ�dz���,ֻ�в����ظ�˼������ϰ�������ô������ϰ���Ŷ�KMP�㷨�dz��˽�,��������ƪ���͵���չ�ָ���ҡ���Ȼ�����KMP�㷨����ʲô�������ƪ������Ҫ�Ľ��ĵط���˽�����ۡ�