Ŀ¼
---------------------------------------------------------------------------------------------------------------------------------
ǰ��
��ʾ:ͨ���Խ����ݼ�,����������������������״̬�Ƿ��ʺ�ȥ�˶�����Ԥ�⡣
��ʾ:�����DZ�ƪ������������,���永���ɹ��ο�
һ��������ԭ��
????????��������һ��Ԥ���б�ģ�͡����������Ƕ������������ֵ֮���һ��ӳ���ϵ������ÿ���ڵ��ʾij������,ÿ����֧·������ij�����ܵ�����ֵ,ÿ��Ҷ������Ӧ�Ӹ��ڵ㵽��Ҷ�ڵ���������·������ʾ�Ķ����ֵ��.�������Ǵ�ѵ��������ѧϰ�ó�һ����״ģ��,ͨ������һϵ�о���(ѡ��)�������ݽ��л���,�����������һϵ���������ѡ�������ľ��߹��̾��ǴӸ��ڵ㿪ʼ,���Դ��������ж�Ӧ����������,��������ֵѡ�������֧,ֱ��Ҷ�ӽ��,��Ҷ�ӽ���ŵ������Ϊ���߽�������ڼලѧϰ�㷨,����ѡ��Ķ����Ǿ������Ĺؼ���
��������������������ɡ��������������:�ڲ������Ҷ�ڵ����ڲ�����ʾһ������������,Ҷ�ڵ��ʾһ����������
����:����������ͷ���ж�һ���˵��Ա�
����ԱA:�ȸ���ͷ���ж�,�ٸ��������ж�,ͷ������������Ϊ����,ͷ����������ϸΪŮ��;ͷ���̡�������Ϊ����,ͷ���̡�����ϸΪŮ��;���ǵõ����¾�������
 ?
?
����ԱB:�����ж�����,����ϸ��Ů��,�����֡�ͷ����������,�����֡�ͷ������Ů�����õ����¾�����:
 ?
?
?��ʱ���Ƿ������־����������������ж�,��������������?���Ҫ�����Ǹ�������õ��������,�ͽ�����Ϊ��ѻ���������
����ʵ�����
2.1.���ž������Ե�ѡ��
2.1.1��Ϣ��
�������ݼ��Ĵ�ԭ����:����������ݱ��������������ܲ������ݵĸ��Ӷ�,�ԱȰ�
?����Ϣ�����������������ϴ�����õ�һ��ָ��,�ٶ� ��ǰ��������D�е�k��������ռ�ı���Ϊpk (K=1, 2, ..., |y|)
,��D����Ϣ�ض���Ϊ:?
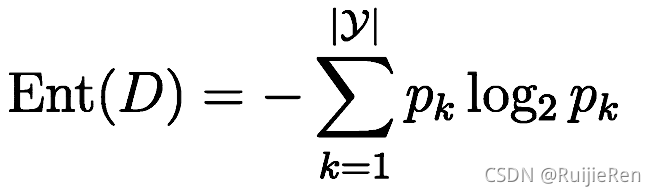 ?
?
Ent(D)��ֵԽС,��D�Ĵ���Խ��
? ������Ϣ��ʱԼ��:��p = 0,��plog2p=0
? Ent(D)����СֵΪ0,���ֵΪlog2|y|
����:
 ?
?
 ??������Ϣ�صĴ�������:
??������Ϣ�صĴ�������:
#����������ݼ�����ũ��
def calcShannonEnt(dataSet):
'''
����������ݼ�����ũ��
:param dataSet: ���ݼ�
:return: ��ũ��
'''
# �������ݼ�������,��������
numEntries = len(dataSet)
# ����ÿ����ǩ���ֳ��ִ������ֵ�
labelCounts = {}
#��ÿ��������������ͳ��
for featVec in dataSet:
#��ȡ��ǩ(label)��Ϣ
currentLabel = featVec[-1]
#������ڱ�ǩû�з���ͳ�ƴ������ֵ�,��������
if currentLabel not in labelCounts.keys():
labelCounts[currentLabel] = 0
#label����
labelCounts[currentLabel] += 1
#��ũ�ظ���ֵ
shannonEnt = 0.0
for key in labelCounts:
#ѡ��ñ�ǩ�ĸ���
prob = float(labelCounts[key])/numEntries
shannonEnt -=prob * log(prob,2)
return shannonEnt
2.1.2��Ϣ����(�����㷨:ID3)
��Ϣ�����ʾ������Ϣ�صIJ�ֵ����Ϣ�����������:
 ?
?
��������,����A1��������D���л������õ���Ϣ����Ϊ:
Gain(D,A1) = H(D) -?[H(D|A1=����)*5/15+H(D|A1=����)*5/15+H(D|A1=����)*5/15]?
=0.971-(0.971*0.33+0.971*0.33+0.7219*0.33)= 0.093
ͨ����Ϣ�����������������ԵĴ���:
#���ո��������������ݼ�
def splitDataSet(dataSet,axis,value):
'''
����˵��:���ո��������������ݼ�
:param dataSet: �����ֵ����ݼ�
:param axis:�������ݼ�������
:param value:�����ķ���ֵ
:return:�������õ����ݼ�
'''
retDataSet = [] #�������ص����ݼ��б�
for featVec in dataSet: #�������ݼ�
if featVec[axis] == value:
reducedFeatVec = featVec[:axis] #ȥ��axis����
reducedFeatVec.extend(featVec[axis+1:]) #���������������ӵ������б�
retDataSet.append(reducedFeatVec)
return retDataSet #���ػ��ֺ�����ݼ�
#ѡ����õ����ݼ����ַ�ʽ
def chooseBestFeatureToSplit(dataSet):
'''
����˵��:ѡ����������
:return: ��Ϣ�������(����)����������ֵ
'''
#��������,-1����Ϊ���һ��������ǩ
numFeatures = len(dataSet[0]) - 1
#�������ݼ���ԭʼ��ũ��
baseEntropy = calcShannonEnt(dataSet)
bestInfoGain = 0.0 #��Ϣ���渳��ֵ0
bestFeature = -1 #��������������ֵ
for i in range(numFeatures):
#��ȡdataSet�ĵ�i�����������浽featList��
featList = [example[i] for example in dataSet]
#print(featList) #ÿ��������15������ֵ�б�
#����set����{},Ԫ�ز����ظ�
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
#subDataSet���ֺ���Ӽ�
subDataSet = splitDataSet(dataSet,i,value)
#�����Ӽ��ĸ���=�Ӽ�����/����ѵ��������
prob = len(subDataSet)/float(len(dataSet))
#������ũ��
newEntropy += prob * calcShannonEnt(subDataSet)
#������Ϣ����
infoGain = baseEntropy - newEntropy
#print("��%d������������Ϊ%.3f" %(i,infoGain))
#C4.5�㷨:���������(��Ϣ������)
#infoGain2 = (baseEntropy - newEntropy)/baseEntropy
if (infoGain >bestInfoGain):
bestInfoGain = infoGain #������Ϣ����,�ҵ�������Ϣ����
bestFeature = i #��¼��Ϣ������������������ֵ
return bestFeature #������Ϣ������������������ֵ?2.1.3��Ϣ������(�����㷨:C4.5)
��Ϣ����Կ�ȡֵ��Ŀ�϶����������ƫ��,��ʮ��ƫ����ӵ�и���ѡ��ľ�������(������ǽ����ݱ������Ҳ��Ϊ�������Ժ�������������Ϊ��һ���ȼ��ľ�������)��Ҳ�����˲�������¾�������ȷ���ܵ���Ӱ��,��ôѧ���������һ���µ����ݻ��ַ����C��Ϣ������(Gain?ratio)��Ҳ��������ԭ����Ϣ�������������Ƕ��һ�����������ڲ�Ҳ����һ����Ϣ�ء�
��������������:
 ?
?
?����a�Ŀ���ȡֵ�� ĿԽ��(��VԽ��),��IV(a)��ֵͨ����Խ��
?��������,����(����,����,����)
?IV(����,v=3) =? -(5/15*log5/15+5/15*log5/15+5/15*log5/15)
Gain_ratio(D,����) = Gain(D,����) / IV(����,v=3)
�����������ȡֵ��Ŀ��������������ƫ��,ȡ��Ϣ��������ߵ�������Ϊ��������
def calcShannonEnt1(dataSet, method = 'none'):
numEntries = len(dataSet)
labelCount = {}
for feature in dataSet:
if method =='prob': #������Ϊprobʱת��������Ϣ������
label = feature
else:
label = feature[-1]
if label not in labelCount.keys():
labelCount[label]=1
else:
labelCount[label]+=1
shannonEnt = 0.0
for key in labelCount:
numLabels = labelCount[key]
prob = numLabels/numEntries
shannonEnt -= prob*(log(prob,2))
return shannonEnt
#��Ϣ������
def chooseBestFeatureToSplit2(dataSet): #ʹ����Ϣ�����ʽ��л������ݼ�
numFeatures = len(dataSet[0]) -1 #���һ��λ�õ���������
baseEntropy = calcShannonEnt(dataSet) #�������ݼ�������Ϣ��
bestInfoGain = 0.0
bestFeature = -1
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
newEntropyProb = calcShannonEnt1(featList, method='prob') #�����ڲ���Ϣ������
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
# ͨ����ͬ������ֵ���������Ӽ�
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob *calcGini(subDataSet)
newEntropy = newEntropy*newEntropyProb
infoGain = baseEntropy - newEntropy #����ÿ����Ϣֵ����Ϣ����
if(infoGain > bestInfoGain):
bestInfoGain = infoGain
bestFeature = i
return bestFeature #������Ϣ������������
?2.1.4����ָ��(�����㷨:C4.5)
����������,����D��K����,���������ڵ�k��ĸ���ΪPk, ����� �ֲ��Ļ���ֵ����Ϊ:
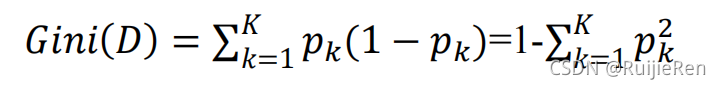 ?
?
?��ӳ�������ȡ��������,������Dz�һ�µĸ��ʡ�
?Gini(D)ԽС,���ݼ�D�Ĵ���Խ��;
?�������ݼ�D,����a�Ļ���ָ������Ϊ:
 ?
?
����ָ����ӳ���Ƿ�֧�����������������һ�µ����,���Ի���ָ��ԽС,����Խ��,��������ѡ������ָ����С��������Ϊ���Ż�������
?��������,��������Ļ���ָ��:��������D=15,
?����=����ʱ,������Ϊ5,false:3,? agree:2? ? ------>?gini1= 1-[(3/5)^2+(2/5)^2]?
?����=����ʱ,������Ϊ5,false:2,? agree:3? ? ------>?gini2= 1-[(2/5)^2+(3/5)^2]?
?����=����ʱ,������Ϊ5,false:1,? agree:4? ? ------>?gini3= 1-[(1/5)^2+(4/5)^2]?
? gini(����) = 5/15 *gini1 + 5/15* gini2 +5/15*gini3
#����ָ��
def calcGini(dataset):
feature = [example[-1] for example in dataset]
uniqueFeat = set(feature)
sumProb =0.0
for feat in uniqueFeat:
prob = feature.count(feat)/len(uniqueFeat)
sumProb += prob*prob
sumProb = 1-sumProb
return sumProb
def chooseBestFeatureToSplit3(dataSet): #ʹ�û���ϵ�����л������ݼ�
numFeatures = len(dataSet[0]) -1 #���һ��λ�õ���������
bestInfoGain = np.Inf
bestFeature = 0.0
for i in range(numFeatures):
featList = [example[i] for example in dataSet]
uniqueVals = set(featList)
newEntropy = 0.0
for value in uniqueVals:
# ͨ����ͬ������ֵ���������Ӽ�
subDataSet = splitDataSet(dataSet, i, value)
prob = len(subDataSet)/float(len(dataSet))
newEntropy += prob *calcGini(subDataSet)
infoGain = newEntropy
if(infoGain < bestInfoGain): # ѡ����С�Ļ���ϵ����Ϊ��������
bestInfoGain = infoGain
bestFeature = i
return bestFeature #���ؾ������Ե��������
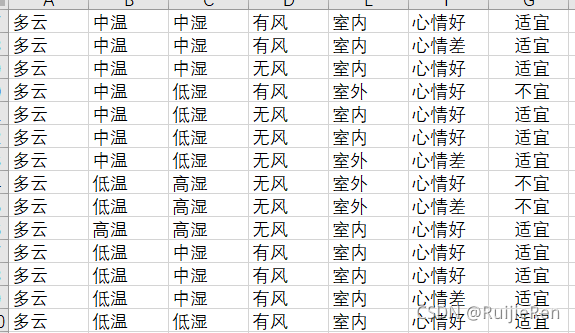
2.2 �����ݼ�
 ?
?
������֤��������Ԥ������:
 ?
?
�Զ������ݽ��д����Ĵ���:
import pandas as pd
myData = pd.read_excel('D:\python\RRJ\pycharm��Ŀ\pythonProject1\digits\TestData2.xlsx',header = None)
print(myData.head())
myData = np.array(myData).tolist()
for d in myData:
for i in range(len(d)):
d[i] = d[i].strip()
print(myData)
Labels = ['����', '�¶�', 'ʪ��', '���', '����','����û�']2.3 ����������?
#����������
def createTree(dataSet,labels):
'''
����˵��:����������
:param dataSet: ѵ�����ݼ�
:param labels: �������Ա�ǩ
:return:
'''
#ȡ�����ǩ
classList = [example[-1] for example in dataSet]
#�������ܴ��ڶ������,��Ҫ�ж�һ��,��������ȫ��ͬ��ֹͣ��������
if classList.count(classList[0]) == len(classList):
return classList[0]
if len(dataSet[0]) == 1:
return majorityCnt(classList) #��������������ʱ���س��ִ����������ǩ
bestFeat = chooseBestFeatureToSplit(dataSet) #ѡ����������
bestFeatLabel = labels[bestFeat] #�������������ǩ
myTree = {bestFeatLabel:{}} #�������������ı�ǩ������
#del(labels[bestFeat]) #ɾ���Ѿ�ʹ��������ǩ
#�õ�ѵ������������������������ֵ
featValues = [example[bestFeat] for example in dataSet]
#ȥ���ظ�������ֵ
uniqueVals = set(featValues)
#��������,����������
for value in uniqueVals:
subLabels = labels[:]
myTree[bestFeatLabel][value] = createTree(splitDataSet(dataSet, bestFeat, value),subLabels)
return myTree2.4 ����Ͷ�ȡ������
����������Ǻܺ�ʱ������,���������ݼ��ܴ��ʱ��,����ķѴ����ļ���ʱ��,���Ϊ�˽�ʡʱ��,��ÿ��ִ�з���ʱ�����Ѵ���������,�����´��뱣��:
#�洢������
'''
:param inputTree:�Ѿ����ɵľ�����
:param filename: �������Ĵ洢�ļ���
'''
def storeTree(inputTree, filename):
import pickle
fw = open(filename, 'wb')
pickle.dump(inputTree, fw)
fw.close()
#��ȡ������
def grabTree(filename):
import pickle
fr = open(filename)
return pickle.load(fr) #�������ֵ�2.5 ���ƾ�����
#���ƾ�����
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
decisionNode = dict(boxstyle="sawtooth", fc="0.8") #���ý���ʽ
leafNode = dict(boxstyle="round4", fc="0.8") #����Ҷ�ڵ��ʽ
arrow_args = dict(arrowstyle="<-") #���ü�ͷ��ʽ
#��ȡ������Ҷ�ӽ����Ŀ
def getNumLeafs(myTree):
'''
����˵��:��ȡҶ�ӽ����Ŀ
:param myTree: ������
:return: ������Ҷ�ӽ����Ŀ
'''
numLeafs = 0 #��ʼ��Ҷ�ӽ��
#firstStr = myTree.keys()[0]
firstStr = next(iter(myTree)) #��ȡ�������
secondDict = myTree[firstStr] #��ȡ��һ���ֵ�
for key in secondDict.keys():
#���Ըý���Ƿ�Ϊ�ֵ�,��������ֵ�,�����˽��ΪҶ�ӽ��
if type(secondDict[key]).__name__=='dict':
numLeafs += getNumLeafs(secondDict[key])
else: numLeafs +=1
return numLeafs
#��ȡ�����������
def getTreeDepth(myTree):
'''
����˵��:��ȡ�����������
:param myTree:������
:return:����������
'''
maxDepth = 0 #��ʼ������������
firstStr = next(iter(myTree))
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__=='dict':
thisDepth = 1 + getTreeDepth(secondDict[key])
else: thisDepth = 1
if thisDepth > maxDepth:
maxDepth = thisDepth #�������IJ���
return maxDepth
#���ƽ��
'''
����˵��:���ƽ��
:param nodeTxt: �����
:param centerPt: �ı�λ��
:param parentPt: ��ע�ļ�ͷλ��
:param nodeType: ����ʽ
'''
def plotNode(nodeTxt, centerPt, parentPt, nodeType):
createPlot.ax1.annotate(nodeTxt, xy=parentPt, xycoords='axes fraction',
xytext=centerPt, textcoords='axes fraction',
va="center", ha="center", bbox=nodeType, arrowprops=arrow_args)
#��ע���������ֵ
'''
����˵��:��ע���������ֵ
:param cntrPt,parentPt: ���ڼ����עλ��
:param txtString: ��ע������
'''
def plotMidText(cntrPt, parentPt, txtString):
xMid = (parentPt[0]-cntrPt[0])/2.0 + cntrPt[0]
yMid = (parentPt[1]-cntrPt[1])/2.0 + cntrPt[1]
createPlot.ax1.text(xMid, yMid, txtString, va="center", ha="center", rotation=30)
#
'''
����˵��:���ƾ�����
:param myTree: ������(�ֵ�)
:param parentPt: ��ע������
:param nodeTxt: �����
'''
def plotTree(myTree, parentPt, nodeTxt):
#��ȡ������Ҷ�����Ŀ,���������Ŀ���
numLeafs = getNumLeafs(myTree)
#��ȡ����������
depth = getTreeDepth(myTree)
#��ȡ��һ���ֵ�
firstStr = next(iter(myTree))
#�����
cntrPt = (plotTree.xOff + (1.0 + float(numLeafs))/2.0/plotTree.totalW, plotTree.yOff)
#��ע���������ֵ
plotMidText(cntrPt, parentPt, nodeTxt)
#���ƽ��
plotNode(firstStr, cntrPt, parentPt, decisionNode)
#��һ���ֵ�,���������ӽ��
secondDict = myTree[firstStr]
plotTree.yOff = plotTree.yOff - 1.0/plotTree.totalD
for key in secondDict.keys():
# ���Ըý���Ƿ�Ϊ�ֵ�,��������ֵ�,�����˽��ΪҶ�ӽ��
if type(secondDict[key]).__name__=='dict':
#����Ҷ�ӽ��,�ݹ���ü�������
plotTree(secondDict[key],cntrPt,str(key))
else: #��Ҷ�ӽ������л���,��ע�����
plotTree.xOff = plotTree.xOff + 1.0/plotTree.totalW
plotNode(secondDict[key], (plotTree.xOff, plotTree.yOff), cntrPt, leafNode)
plotMidText((plotTree.xOff, plotTree.yOff), cntrPt, str(key))
plotTree.yOff = plotTree.yOff + 1.0/plotTree.totalD
#�����������
def createPlot(inTree):
'''
����˵��:�����������
:param inTree: ������(�ֵ�)
'''
fig = plt.figure(1, facecolor='white') #����fig
fig.clf() #���fig
axprops = dict(xticks=[], yticks=[])
createPlot.ax1 = plt.subplot(111, frameon=False, **axprops) #ȥ��x,y��
plotTree.totalW = float(getNumLeafs(inTree)) #������Ҷ�ӽ����Ŀ
plotTree.totalD = float(getTreeDepth(inTree)) #����������
plotTree.xOff = -0.5/plotTree.totalW; plotTree.yOff = 1.0; #xƫ��
plotTree(inTree, (0.5,1.0), '') #���ƾ�����
plt.show()
2.6 ʹ�þ��������з���
���ຯ��:
#ʹ�þ������ķ��ຯ��
'''
����˵��:ʹ�þ���������
:param inputTree: �Ѿ����ɵľ�����
:param featLabels: �洢ѡ�����������
:param testVec: ���������б�,˳���Ӧ����������ǩ
:return: ������
'''
def classify(inputTree,featLabels,testVec):
#firstStr = next(iter(inputTree)) #��ȡ���������
firstStr = list(inputTree.keys())[0]
#print(firstStr)
secondDict = inputTree[firstStr] #��һ���ֵ�
featIndex = featLabels.index(firstStr) #��ȡ�洢ѡ�������������ǩ������
classLabel = -1
for key in secondDict.keys():
if testVec[featIndex] == key:
# ���Ըý���Ƿ�Ϊ�ֵ�,��������ֵ�,�����˽��ΪҶ�ӽ��
if type(secondDict[key]).__name__=='dict':
classLabel = classify(secondDict[key],featLabels,testVec)
else:
classLabel = secondDict[key]
# ���classLabelΪ-1��ѭ����������ȻΪ-1,��ʾδ�ҵ������ݶ�Ӧ�Ľڵ������Ƿ������ֵܽڵ���ִ����������
if classLabel == -1:
return getLeafBestCls(inputTree)
else:
return classLabel
#��ýڵ�������Ҷ�ӽڵ���б�
def getLeafscls(myTree, clsList):
numLeafs = 0
firstStr = list(myTree.keys())[0]
secondDict = myTree[firstStr]
for key in secondDict.keys():
if type(secondDict[key]).__name__ == 'dict':
clsList =getLeafscls(secondDict[key],clsList)
else:
clsList.append(secondDict[key])
return clsList
#���س��ִ����������
def getLeafBestCls(myTree):
clsList = []
resultList = getLeafscls(myTree,clsList)
return max(resultList,key = resultList.count)2.7 �����ľ��������
������:
if __name__ == '__main__':
'''
myDat,labels = createDataSet()
print(myDat)
print(labels)
print("ԭʼ������Ϣ��ũ��Ϊ:",end=' ')
print(calcShannonEnt(myDat))
print("��õ����ݻ��ֵ���������ֵ:",end=' ')
print(chooseBestFeatureToSplit(myDat))
#myTree = treesPlotter.retrieveTree(0)
myTree = createTree(myDat,labels)
treesPlotter.createPlot(myTree) #û���������ǩ
#myTree['no surfacing'][3] = 'maybe'
print(myTree)
treesPlotter.createPlot(myTree)
print('���Է�����Ϊ:',end='')
#print(classify(myTree,labels,['����','����','��ʪ','��']))
'''
import pandas as pd
myData = pd.read_excel('D:\python\RRJ\pycharm��Ŀ\pythonProject1\digits\TestData2.xlsx',header = None)
print(myData.head())
myData = np.array(myData).tolist()
for d in myData:
for i in range(len(d)):
d[i] = d[i].strip()
print(myData)
Labels = ['����', '�¶�', 'ʪ��', '���', '����','����û�']
myTree = createTree(myData, Labels)
storeTree(storeTree, 'saveTree.txt') #���������洢����txt�ļ�
treesPlotter.createPlot(myTree)
print("Ԥ����:")
print(classify(myTree, Labels, ['����', '����', '��ʪ', '��', '����','�����']))
dataSet2 = [['����', '����', '��ʪ', '��', '����', '�����'],
['����', '����', '��ʪ', '�з�', '����', '�����'],
['����', '����', '��ʪ', '��', '����', '�����'],
['����', '����', '��ʪ', '��', '����', '�����'],
['����', '����', '��ʪ', '�з�', '����', '�����'],
['����', '����', '��ʪ', '�з�', '����', '�����'],
['����', '����', '��ʪ', '�з�', '����', '�����'],
['����', '����', '��ʪ', '�з�', '����', '�����'],
['����', '����', '��ʪ', '�з�', '����', '�����'],
['����', '����', '��ʪ', '��', '����', '�����']]
for dataVet in dataSet2:
print(classify(myTree,Labels,dataSet2))����Ϣ���洴���ľ�����
 ?
?
Ԥ����:
 ?
?
�Ա�Ԥ�����ݵ���ȷ��:40%
����Ϣ�����ʴ����ľ�����
? ?
?
�û���ָ�������ľ�����
 ?
?
Ԥ������ȷ�ʶ���40%,�ɼ�������������������,ͨ���������ṩ�����ݲ��Է����������ݼ�������,���ݼ��������Լ���Ĵ���̫��������,һ�¾��߽��һ��false��?
�����������ص�ݺβ�����ݽ��в���:
 ?
?
��Ϣ����Ԥ����:
 ?
?
��ȷ��:4/15*100%=28.6%
��Ϣ������,����ָ��Ԥ������ͬ:�����Ǵ����д��������,��Ҫ��һ���Ľ���
�ô�ʹ�õ�url������������ݡ�
�ܽ�
�����ʵ�����������Լ�������ݼ�����ʹʵ����������,���Ƚ���Ϣ����,��Ϣ������,����ָ�����ֻ��ַ�ʽ�Ķ����ݻ��ֵ�����,�Լ��Ƚϵó����ַ�ʽ���ʺ���������������
��Ϣ�����ȱ��:
��Ϣ������Կ�ȡֵ��Ŀ�϶����������ƫ��,����"��š�����������Ϣ����ӽ���1;
ֻ�����ڴ�����ɢ�ֲ�������;,û�п���ȱʧֵ��