💖�����:��Һ�,���������,��ѧ·18�ŵij���🥇
📝������ҳ:Ӧ����ס�������ĵIJ���_��ѧ·18�ų���_CSDN����
🎉����?����?�ղ� == ����ϰ��(һ������)😋?ϣ����Ҷ��֧��🤗~һ����� 😁
����ר��:
���ݽ�ά������Pythonʵ��
ǰ��
11�·���,Ŀǰ��������, ���ɸ�������,�ڹ�ҵ�����еĹ��̼����״����Ǵ����������ĽǶȽ��м�غ����,Ȼ��,���������ĺܶ������ȷʵ�����Ե�,��ʵ��������,�ֶ��Ƿ����Ե�����,��Ҳ��һЩ���Ե�,�ɴ����ǿ��Դ�ȫ�ֺ;ֲ�����,�������ݽ����ھ�ͷ���,�Դ�,���������˺ܶ�������ݽ�ά��һЩ�������ڱ�ҵ����,���������潲���ҵ�һЩ�����Python����ĸ��֡�
Python��������ĩӴ!~
���
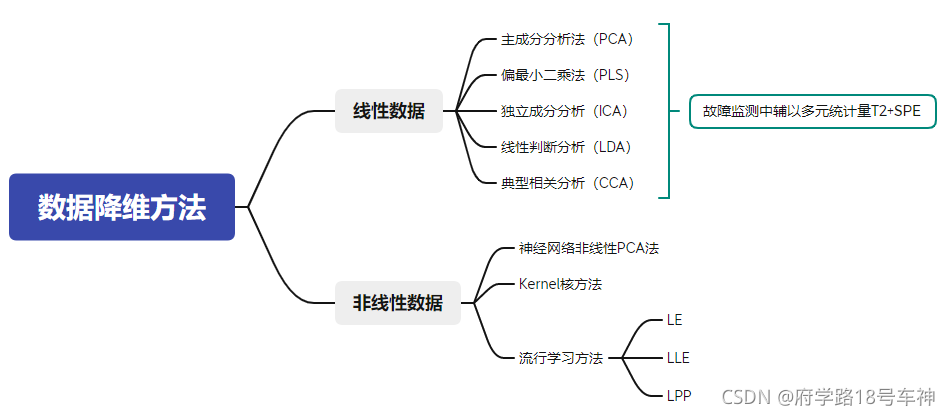
�������ݽ�ά
���Խ�ά����,����Ԫ����(PCA)"��������С���˻�(PLS)������Ԫ����(ICA),���Ա�����(LDA)�ȡ�
��Ԫ����(PCA)
֮ǰ�й�һƪblog���ܹ���һ����,-> ������
���̼���е�Ӧ�ÿɿ� -> ����
�����ڽ���һ���~
PCA��һ��ͳ�Ʒ���,�㷺Ӧ���ڹ��̺Ϳ�ѧӦ����,�븵��Ҷ�������,����������������⡣
�� x �� R m \boldsymbol{x} \in \mathfrak{R}^{m} x��Rm��ʾ m m m��������ʸ������������ֵ��
����ÿ���������� N N N������,���ݾ��� X = [ x 1 x 2 ? x N ] T �� R N �� m \mathbf{X}=\left[\begin{array}{llll} \boldsymbol{x}_{1} & \boldsymbol{x}_{2} & \cdots & \boldsymbol{x}_{N} \end{array}\right]^{T} \in \mathfrak{R}^{N \times m} X=[x1??x2????xN??]T��RN��m,�ɴ������� x i T x^T_i xiT?��ÿһ����ɡ�
�������ݾ���
X
X
X��һ����ҪҪ����,��Ӧ���зḻ�������仯,�Դ������̵Ĺ�ͬԭ��仯������
X
X
X������Ϊ���ֵ,ͨ��ΪPCA��ģ����λ����������
X
X
Xͨ������ֵ�ֽ�(SVD)�ֽ�Ϊ�÷־���
T
T
T�����ؾ���
P
P
P,
X
=
T
P
T
+
X
~
(1)
\mathbf{X}=\mathbf{T P}^{T}+\tilde{\mathbf{X}}\tag{1}
X=TPT+X~(1)
����
T
=
X
P
T=XP
T=XP����
l
l
l ����ǰ����������������ֵ,P ����
l
l
l����ǰ����������,
X
~
\tilde{\mathbf{X}}
X~ �Dzв�������,T ������������,P �����������ġ�������Э��������ʾΪ
S
=
1
N
?
1
X
T
X
(2)
\mathbf{S}=\frac{1}{N-1} \mathbf{X}^{T} \mathbf{X}\tag{2}
S=N?11?XTX(2)
��ΪSVD���������,���Զ� S ���������ֽ�,�Ի�� P ��Ϊ S �� l l l ��ǰ����������,����ֵ��ʾΪ
��
=
diag
?
{
��
1
,
��
2
,
��
,
��
l
}
(3)
\mathbf{\Lambda}=\operatorname{diag}\left\{\lambda_{1}, \lambda_{2}, \ldots, \lambda_{l}\right\}\tag{3}
��=diag{��1?,��2?,��,��l?}(3)
��
i
i
i ������ֵ����÷־��� T �ĵ�
i
i
i �����,������ʾ:
��
i
=
1
N
?
1
t
i
T
t
i
��
var
?
{
t
i
}
(4)
\lambda_{i}=\frac{1}{N-1} \mathbf{t}_{i}^{T} \mathbf{t}_{i} \approx \operatorname{var}\left\{\mathbf{t}_{i}\right\}\tag{4}
��i?=N?11?tiT?ti?��var{ti?}(4)
���ǵ� i i i���÷����� t i �� R N \mathbf{t}_{i} \in \mathfrak{R}^{N} ti?��RN������������ɷ��ӿռ�(PCS)�� S p = span ? { P } \mathcal{S}_{p}=\operatorname{span}\{\mathbf{P}\} Sp?=span{P},ʣ���ӿռ�(RS) S r S_r Sr?�� S p S_p Sp?�����������������ռ仮��ΪPCS��RS,ʹ��RS������С������ֵ,��Щ����ֵ��Ӧ��ͨ�����н�С�仯���ӿռ�,������Ҫ���������ӿռ䡣���,�в������ڸ�������ƽ�������ƽ�⽨������ѧģ���еķ��������
�������� x �� R m \mathbf{x} \in \mathfrak{R}^{m} x��Rm���Էֱ�ͶӰ��PCS��RS��,
x ^ = P t = P P T x �� S p (5) \hat{\boldsymbol{x}}=\mathbf{P} \boldsymbol{t}=\mathbf{P P}^{T} \boldsymbol{x} \in \mathcal{S}_{p}\tag{5} x^=Pt=PPTx��Sp?(5)
����,
t = P T x �� R l (6) \boldsymbol{t}=\mathbf{P}^{T} \boldsymbol{x} \in \mathfrak{R}^{l}\tag{6} t=PTx��Rl(6)
Ϊ l l l ��DZ�ڱ����÷ֵ�������
�����:
x ~ = x ? x ^ = ( I ? P P T ) x �� S r (7) \tilde{\boldsymbol{x}}=\boldsymbol{x}-\hat{\boldsymbol{x}}=\left(\mathbf{I}-\mathbf{P P}^{T}\right) \boldsymbol{x} \in \mathcal{S}_{r}\tag{7} x~=x?x^=(I?PPT)x��Sr?(7)
��Ϊ S p S_p Sp? �� S r S_r Sr? ��������,
x ^ T x ~ = 0 (8) \hat{\boldsymbol{x}}^{T} \tilde{\boldsymbol{x}}=0\tag{8} x^Tx~=0(8)
��
x = x ^ + x ~ (9) \boldsymbol{x}=\hat{\boldsymbol{x}}+\tilde{\boldsymbol{x}}\tag{9} x=x^+x~(9)
����,һ����Ҫ�ĸ�����,���ݵ�PCAģ��, x ^ \hat{\boldsymbol{x}} x^��DZ���� t �� R m \mathbf{t} \in \mathfrak{R}^{m} t��Rm ��������
ƫ��С���˷�(PLS)
PLS�����㷨��������:
- ��X��Y��������(��������ֵ����������)(�˲����ɲο� ���� ��CCA�㷨)��
- ��X�ĵ�һ�����ɷ�Ϊ p 1 p_1 p1?,Y�ĵ�һ�����ɷ�Ϊ q 1 q_1 q1?,���߶�������λ����(ע��:��������ɷֲ�����ͨ��PCA�õ������ɷ�)(~~�˼�����:~~�������ɷֿɼĿ���CCAϵ�������еĵ�һϵ���ɷ�,�� a 1 a_1 a1?)��
- u 1 = X p 1 , v 1 = Y q 1 u_1=Xp_1,v_1=Yq_1 u1?=Xp1?,v1?=Yq1?,���CCA����һ��,�ɵ������������Լ��������
-
V
a
r
(
u
1
)
��
M
a
x
,
V
a
r
(
v
1
)
��
M
a
x
Var(u_1)\rightarrow Max,Var(v_1)\rightarrow Max
Var(u1?)��Max,Var(v1?)��Max,���������ɷַ����ϵ�ͶӰ,�õ��������ķ������ֵ(
ò�����������е����)�� - R ( u 1 , v 1 ) �� M a x R_(u_1,v_1)\rightarrow Max R(?u1?,v1?)��Max,��CCAһ����
- �ۺ���������,�ɵ� C o v ( u 1 , v 1 ) = V a r ( u 1 ) V a r ( v 1 ) R ( u 1 , v 1 ) �� M a x Cov(u_1,v_1)=\sqrt{Var(u_1)Var(v_1)}R_(u_1,v_1) \rightarrow Max Cov(u1?,v1?)=Var(u1?)Var(v1?)?R(?u1?,v1?)��Max��
�����֮,Ϊ��ʵ��ƫ��С���˻ع�Ļ���˼��,Ҫ��p1��q1��Э�������,����������Ż����Ŀ�꺯��:
M a x : < X p 1 , Y q 1 > S . t . : �O �O p 1 �O �O = 1 , �O �O q 1 �O �O = 1 Max:<Xp_1,Yq_1> \\ S.t.:||p_1||=1,||q_1||=1 Max:<Xp1?,Yq1?>S.t.:�O�Op1?�O�O=1,�O�Oq1?�O�O=1
���Ʊ�CCA�ļ�,���︽��CCA��Ŀ�꺯��:
M a x : R ( U , V ) = Cov ? ( U , V ) Var ? [ U ] Var ? [ V ] = C o v ( U , V ) = t k T C o v ( A , B ) h k = t k T �� 12 h k S . t . : V a r ( U k ) = V a r ( t k T A ) = t k T �� 11 t k = 1 , V a r ( V k ) = V a r ( h k T A ) = h k T �� 22 h k = 1 Max:R_{(U,V)}=\frac{\operatorname{Cov}(U, V)}{\sqrt{\operatorname{Var}[U] \operatorname{Var}[V]}}=Cov(U,V)={t_k}^TCov(A,B)h_k={t_k}^T\Sigma_{12} h_k\\ S.t.:Var(U_k)=Var({t_k^T}{A})={t_k^T}\Sigma_{11}t_k=1, Var(V_k)=Var({h_k^T}{A})={h_k^T}\Sigma_{22}h_k=1 Max:R(U,V)?=Var[U]Var[V]?Cov(U,V)?=Cov(U,V)=tk?TCov(A,B)hk?=tk?T��12?hk?S.t.:Var(Uk?)=Var(tkT?A)=tkT?��11?tk?=1,Var(Vk?)=Var(hkT?A)=hkT?��22?hk?=1
����CCA��һ�����Ĺ���,�����ǵ�PLS�ع�ֻ�Ƕ�Ŀǰ�ĵ�һ���ɷ������Ż�����,ʣ�µ����ɷֻ����ټ��㡣
�����Ż���Ŀ�����İ취,��CCAһ��,Ҳ���������������ճ���������⡣(���������ϸ���㲽��)
����,�����������ճ���:
L
=
p
1
T
X
T
Y
q
1
?
��
2
(
p
1
T
p
1
?
1
)
?
��
2
(
q
1
T
q
1
?
1
)
\mathcal{L}=p_{1}^{T} X^{T} Y q_{1}-\frac{\lambda}{2}\left(p_{1}^{T} p_{1}-1\right)-\frac{\theta}{2}\left(q_{1}^{T} q_{1}-1\right)
L=p1T?XTYq1??2��?(p1T?p1??1)?2��?(q1T?q1??1)
�ֱ��
p
1
p_1
p1?��
q
1
q_1
q1?��ƫ��,
?
L
?
p
1
=
X
��
Y
q
1
?
��
p
1
=
0
?
L
?
q
1
=
Y
��
X
p
1
?
��
q
1
=
0
\begin{array}{l} \frac{\partial \mathcal{L}}{\partial p_{1}}=X^{\tau} Y q_{1}-\lambda p_{1}=0 \\\\ \frac{\partial \mathcal{L}}{\partial q_{1}}=Y^{\tau} X p_{1}-\theta q_{1}=0 \end{array}
?p1??L?=X��Yq1??��p1?=0?q1??L?=Y��Xp1??��q1?=0?
��CCAһ��,�����
��
\lambda
����
��
\theta
����ȡ�
��
��
?
1
X
��
Y
q
1
=
p
1
\lambda^{-1}X^{\tau} Y q_{1}= p_{1}
��?1X��Yq1?=p1?��������ڶ�ʽ��,�ɵ�
Y
��
X
X
��
Y
q
1
=
��
2
q
1
Y^{\tau}XX^{\tau} Y q_{1}= \lambda^{2} q_{1}
Y��XX��Yq1?=��2q1?
���߾�����
p
1
p_1
p1?��
q
1
q_1
q1?,������Լ������
�O
�O
p
1
�O
�O
=
1
,
�O
�O
q
1
�O
�O
=
1
||p_1||=1,||q_1||=1
�O�Op1?�O�O=1,�O�Oq1?�O�O=1,�ɵ�:
X
��
Y
Y
��
X
p
1
=
��
2
p
1
X^{\tau}YY^{\tau} X p_{1}= \lambda^{2} p_{1}
X��YY��Xp1?=��2p1?
����ʽ
��
2
\lambda^{2}
��2��Ϊ
X
��
Y
Y
��
X
p
1
X^{\tau}YY^{\tau} X p_{1}
X��YY��Xp1?������ֵ,
p
1
p_1
p1?Ϊ��Ӧ�ĵ�λ��������,
q
1
q_1
q1?һ����
��� p 1 p_1 p1?�� q 1 q_1 q1?���� ? X p 1 , Y q 1 ? �� p 1 �� X �� Y q 1 �� p 1 �� ( �� p 1 ) �� �� \left\langle X p_{1}, Y q_{1}\right\rangle \rightarrow p_{1}^{\tau} X^{\tau} Y q_{1} \rightarrow p_{1}^{\tau}\left(\lambda p_{1}\right) \rightarrow \lambda ?Xp1?,Yq1??��p1��?X��Yq1?��p1��?(��p1?)�����ɵõ����Ž⡣
�ɼ� p 1 p_1 p1?�� q 1 q_1 q1?��ͶӰ���������������������ϵ�Ȩ��,��CCAֻ������������
����,���ǿ��Եõ� u 1 �� v 1 u_1��v_1 u1?��v1?ֵ,����� u 1 �� v 1 u_1��v_1 u1?��v1?��ͼ����ֻ�DZ�ʾΪ��ɫ��,���������������,�Ǻ�CCA�Ĺ���һ��,�ò���X��Y��ӳ�䡣
���������㷨����ϸԭ��(ģ��+�ع�)�ɿ� -> ����
�����ɷַ���(ICA)
�����ɷַ��� ICA(Independent Component Correlation Algorithm)��һ�ֺ���,XΪnά�۲��ź�ʸ��,SΪ������m(m<=n)άδ֪Դ�ź�ʸ��,����A����Ϊ��Ͼ���ICA��Ŀ�ľ���Ѱ�ҽ�����W(A�������),Ȼ���X�������Ա任,�õ��������U��
����ʹ�������Ȼ�����������㷨,���Ǽٶ�ÿ��
s
i
s_i
si?�и����ܶ�
p
s
p_s
ps?,��ô����ʱ��ԭ�źŵ����Ϸֲ�����
p
(
s
)
=
��
i
=
1
n
p
s
(
s
i
)
\mathrm{p}(\mathrm{s})=\prod_{i=1}^{n} p_{s}\left(s_{i}\right)
p(s)=i=1��n?ps?(si?)
�˹�ʽ����һ������ǰ��:ÿ���˷����������źŸ��Զ�����
����
p
(
s
)
p(s)
p(s),���ǿ������
p
(
x
)
p(x)
p(x)
p
(
x
)
=
p
s
(
H
x
)
�O
H
�O
=
�O
H
�O
��
i
=
1
n
p
s
(
h
i
T
x
)
\mathrm{p}(\mathrm{x})=\mathrm{p}_{s}(H x)|\mathrm{H}|=|\mathrm{H}| \prod_{i=1}^{n} p_{s}\left(h_{i}{ }^{T} x\right)
p(x)=ps?(Hx)�OH�O=�OH�Oi=1��n?ps?(hi?Tx)
�����ÿ�������ź�
x
x
x�ĸ���,�ұ���ÿ��ԭ�źŸ��ʵij˻���
�O
H
�O
|H|
�OH�O����
��û������֪ʶ,��������� H H H�� s s s��
���������Ҫ֪��
p
s
(
s
i
)
p_s(s_i)
ps?(si?),���Ǵ���ѡȡһ�������ܶȺ�������
s
s
s,�������Dz���ѡȡ��˹�ֲ����ܶȺ������ڸ�����������֪���ܶȺ���p(x)���ۼƷֲ�����(cdf)F(x)�õ���F(x)Ҫ��������������:������������[0,1]�����Ƿ���sigmoid�������ʺ�,���������������,ֵ��0��1,�������������Ǽٶ�
s
s
s���ۻ��ֲ���������sigmoid����
g
(
s
)
=
1
1
+
e
?
s
g(s)=\frac{1}{1+e^{-s}}
g(s)=1+e?s1?
�ɵ�,
p
s
(
s
)
=
g
��
(
s
)
=
e
s
(
1
+
e
s
)
2
p_{s}(s)=g^{\prime}(s)=\frac{e^{s}}{\left(1+e^{s}\right)^{2}}
ps?(s)=g��(s)=(1+es)2es?
�����
s
s
s���ܶȺ�������ʱ��
s
s
s��ʵ����
Ҫ������Ԥ��֪�� s s s�ķֲ�����,�ǾͲ��ü�����,����δ֪�������,sigmoid�����ܹ��ڴ����������ȡ�ò�����Ч����
������ʽ�� p s ( s ) p_s(s) ps?(s)�Ǹ��Գƺ���,���E[s]=0(s�ľ�ֵΪ0),��ôE[x]=E[As]=0,x�ľ�ֵҲ��0��
��������֪���� p s ( s ) p_s(s) ps?(s),���濪ʼ�� H H H��
�������ѵ������Ϊ
X
(
i
)
=
(
x
1
(
i
)
,
x
2
(
i
)
,
��
,
x
n
(
i
)
)
;
(
i
=
1
,
��
,
m
)
\mathrm{X}^{(i)}=\left(x_{1}^{(i)}, x_{2}^{(i)}, \ldots, x_{n}^{(i)}\right) ;( i=1, \ldots, m)
X(i)=(x1(i)?,x2(i)?,��,xn(i)?);(i=1,��,m),ʹ��ǰ��õ���
x
x
x�ĸ����ܶȺ���,��������������Ȼ����:
?
(
H
)
=
��
i
=
1
m
(
��
j
=
1
n
log
?
g
��
(
h
j
T
x
(
i
)
)
+
log
?
�O
H
�O
)
\ell(H)=\sum_{i=1}^{m}\left(\sum_{j=1}^{n} \log g^{\prime}\left(h_{j}^{T} x^{(i)}\right)+\log |H|\right)
?(H)=i=1��m?(j=1��n?logg��(hjT?x(i))+log�OH�O)
����,�������һ���Ϊ
p
(
x
(
i
)
)
p(x^{(i)})
p(x(i)),Ȼ���ٶ�
H
H
H��������������ʽ�а���������ʽ,������ʽ|W|�����ķ����ɲο�������
���յõ��������ʽ(�ܸ��Ӻܷ����C����):
H
:
=
H
+
��
(
[
1
?
2
g
(
h
1
T
x
(
i
)
)
1
?
2
g
(
h
2
T
x
(
i
)
)
?
1
?
2
g
(
h
n
T
x
(
i
)
)
]
x
(
i
)
T
+
(
H
T
)
?
1
)
H:=H+\alpha\left(\left[\begin{array}{c} 1-2 g\left(h_{1}^{T} x^{(i)}\right) \\ 1-2 g\left(h_{2}^{T} x^{(i)}\right) \\ \vdots \\ 1-2 g\left(h_{n}^{T} x^{(i)}\right) \end{array}\right] x^{(i)^{T}}+\left(H^{T}\right)^{-1}\right)
H:=H+��????????????1?2g(h1T?x(i))1?2g(h2T?x(i))?1?2g(hnT?x(i))???????x(i)T+(HT)?1??????
����
��
\alpha
����ʾ�����ݶ���������,���Զ��塣
��ͨ�����������,����� H H H,��ɵõ� s ( i ) = H x ( i ) s^{(i)}=Hx^{(i)} s(i)=Hx(i)����ԭ��ԭʼ�źš�
��������ɷַ���ICAԭ����Ӧ�ÿɿ� ��> ����
��������(LDA)
LDA��˼��:�������������ݼ�,�跨����������ͶӰ��һ��ֱ����,ʹ��ͬ�����ݵ�ͶӰ�㾡���ܵĽӽ������������ݵ�ͶӰ��֮�佫���ܼ����Զ�������������������ݵķ���ʱ,����ͶӰ��ͬ����ֱ����,�ٸ���ͶӰ���λ����ȷ�����������������ͼ(Դ����־��������ѧϰ��)��ʾ:
�����ͶӰֱ��Ҳ�õ�����С���˵�˼��,��������������ֱͶӰ��ֱ����,ֻ�����ǵ�Լ��������Ϊ�˲�ͬ��������֮���ͶӰ��ֱ���ϵľ��������
������ҪѰ�ҵ���ͶӰ���� w w w��,ʹ����������������������:1) ��ͬ����֮��ͶӰ������С;2)��ͬ����֮��ͶӰ��λ�����(��ͨ�����䲻ͬ���ݵ�ͶӰ���ĵ����б�)

ͼ��,��+���͡�-�������������ֲ�ͬ�����ݴ�,����Բ��ʾ���ݴص���������,���߱�ʾ��ͶӰ,��ɫʵ��Բ���ͺ�ɫʵ�����������ֱ�������������ݴ�ͶӰ�� w w w�����ϵ����ĵ㡣
��������ͶӰ���� y = w T x y=\mathbf{w^Tx} y=wTx,�в�����Ϊ�����IJ���ȷ,���в�δ�ἰ���� y y y�Ľ���,���Ƕ��� y y y��ʵ�������ἰ�ġ�
������Ϊ,�����
y
y
y,������Ϊ������ͶӰ��һ������,������
x
x
xͶӰ�ڷ���Ϊ
w
w
w��ֱ����,�����Ǵ��������ͶӰֱ��Ϊ
y
=
w
T
x
y=\mathbf{w^Tx}
y=wTx,�����ᱻ������Ϊ��ͶӰ���ֵ0��
���˼�����(���в���,������ָ��)
��֪���������ݼ�Ϊ
D
=
{
(
x
i
,
y
i
)
}
i
=
1
m
,
y
i
��
{
0
,
1
}
D=\{(x_i,y_i)\}_{i=1}^{m},y_i\in \{0,1\}
D={(xi?,yi?)}i=1m?,yi?��{0,1}
����
X
i
��
��
i
��
��
i
X_i��\mu_i��\Sigma_i
Xi?����i?����i?�ֱ��ʾ��
i
��
{
0
,
1
}
i\in\{0,1\}
i��{0,1}��(ע��:�����
i
i
i ָ���ж��ٸ���ͬ��������ݼ�,ͼ��ֻ������,��Ϊ0��1)ʾ���ļ��ϡ���ֵ������Э�������
���罫���е��������ݵ㶼ͶӰ��ֱ�� w w w����,��ô���ͬ���������ݵ����ĵ���ֱ���ϵ�ͶӰ�ɱ�ʾΪ w T �� 0 �� w T �� 1 w^{T}\mu_0��w^{T}\mu_1 wT��0?��wT��1?;ͬ��,��������ͶӰ��ֱ���Ϻ�,���ǵõ�������������Э����ֱ�Ϊ w T �� 0 w w^{T}\Sigma_0w wT��0?w�� w T �� 1 w w^{T}\Sigma_1w wT��1?w.
��������ֻ����һάƽ���ϵ�ֱ��,��Ϊһά�ռ�,�ɴ� w T �� 0 �� w T �� 1 �� w T �� 0 w �� w T �� 1 w w^{T}\mu_0��w^{T}\mu_1��w^{T}\Sigma_0w��w^{T}\Sigma_1w wT��0?��wT��1?��wT��0?w��wT��1?w����ʵ����
Ϊʲô˵������һά�ռ���?���Կ���ͼ,����ÿ����������dά����(��ͼΪ��ά x 1 �� x 2 x_1��x_2 x1?��x2?����ϵ)�����ھͼ�һ��,����һ��ֱ�� w w w��ʾ��Щ����,��֮Ϊ�������ϵ�һά�����������˵��һά������ͶӰ��һ��ֱ�����Ժ������,��ֱ����������һά�ռ����ġ�
����˼����һ������,�����ͬ�����������ͶӰ�㾡���ܵĿ���,��ʹ�ò�ͬ����ͶӰ����ø�Զ��?
������Ҫ����Э����ĸ���,СС��ϰһ��Э����������������֪ʶ(��Ϊ���˼���ѧ������)
Э����(Covariance)�ڸ����ۺ�ͳ��ѧ�����ں���������������������������Э�����һ���������,����������������ͬ�������
����� �� 0 �� �� 1 \Sigma_0��\Sigma_1 ��0?����1?��Ϊ����Э����Ҳ���Ǵ�������(Ҳ��Ϊ��������)������:�����ݷֲ��ȽϷ�ɢ(��������ƽ�������������ϴ�)ʱ,����������ƽ�����IJ��ƽ���ͽϴ�,����ͽϴ�;�����ݷֲ��Ƚϼ���ʱ,����������ƽ�����IJ��ƽ���ͽ�С��
�ܵ�˵��:����Խ��,���ݵIJ���Խ��;����ԽС,���ݵIJ�����ԽС��
Э�����ʾ����������������������,����ֻ��ʾһ���������ķ��ͬ�� ������������ı仯����һ��,Ҳ����˵�������һ����������������ֵ,����һ��Ҳ��������������ֵ,��ô��������֮���Э���������ֵ�� ������������ı仯�����෴,������һ����������������ֵ,����һ��ȴС������������ֵ,��ô��������֮���Э������Ǹ�ֵ��
�����֮:��������֮����Խ��,Э�����ԽС;�෴,��������Խ���Ʊ仯����һ��,��Э����Խ����
��ϰ��Э������������֪ʶ��,������������Ӧ�ò��ѡ�
�������ǵ�����,��ͬ�������ͶӰ�㾡���ܵ�����,���仰˵������ͬ������ͶӰ��Э���������ܵ�С(ע��:������������Э����==��������,Ҳ����������������һ��),�� w T �� 0 w + w T �� 1 w w^{T}\Sigma_0 w+w^{T}\Sigma_1 w wT��0?w+wT��1?w�����ܵ�С,�������ݵIJ�����С,֮��ľ����С��������
���ڲ�ͬ��������ͶӰ��֮��IJ���,ʹ����ӵ�Զ�롣���ǿ���ͨ����ͬ���ݼ�ͶӰ�����ĵ����б�,��ͬ���ĵ�֮��ľ���Խ��,��ô��ʾ����֮����ø�Զ,�� �O �O w T �� 0 + w T �� 1 �O �O 2 2 ||w^{T}\mu_0+w^{T}\mu_1||_2^2 �O�OwT��0?+wT��1?�O�O22?(ŷʽ����)����
��!��������ͬʱ�������ߵ����,�����ʹ�õõ����Ŀ��,�������ǵ�ģ��:
J
=
��
w
T
��
0
?
w
T
��
1
��
2
2
w
T
��
0
w
+
w
T
��
1
w
=
w
T
(
��
0
?
��
1
)
(
��
0
?
��
1
)
T
w
w
T
(
��
0
+
��
1
)
w
\begin{aligned} J &=\frac{\left\|\boldsymbol{w}^{\mathrm{T}} \boldsymbol{\mu}_{0}-\boldsymbol{w}^{\mathrm{T}} \boldsymbol{\mu}_{1}\right\|_{2}^{2}}{\boldsymbol{w}^{\mathrm{T}} \boldsymbol{\Sigma}_{0} \boldsymbol{w}+\boldsymbol{w}^{\mathrm{T}} \boldsymbol{\Sigma}_{1} \boldsymbol{w}} \\ &=\frac{\boldsymbol{w}^{\mathrm{T}}\left(\boldsymbol{\mu}_{0}-\boldsymbol{\mu}_{1}\right)\left(\boldsymbol{\mu}_{0}-\boldsymbol{\mu}_{1}\right)^{\mathrm{T}} \boldsymbol{w}}{\boldsymbol{w}^{\mathrm{T}}\left(\boldsymbol{\Sigma}_{0}+\boldsymbol{\Sigma}_{1}\right) \boldsymbol{w}} \end{aligned}
J?=wT��0?w+wT��1?w����?wT��0??wT��1?����?22??=wT(��0?+��1?)wwT(��0??��1?)(��0??��1?)Tw??
�۲���ʽĿ�꺯��,�����ǵ�
J
��
M
a
x
J\rightarrow Max
J��Max����������Ҫ�Ľ����ʽ��̫����,���������Ż�һ�°ɡ�
����һ�����ںͼ�ɢ�Ⱦ����֪ʶ:
����,���������塰����ɢ�Ⱦ���(within-class scatter matrix)
S
w
=
��
0
+
��
1
=
��
x
��
X
0
(
x
?
��
0
)
(
x
?
��
0
)
T
+
��
x
��
X
1
(
x
?
��
1
)
(
x
?
��
1
)
T
\begin{aligned} \mathbf{S}_{w} &=\boldsymbol{\Sigma}_{0}+\boldsymbol{\Sigma}_{1} \\ &=\sum_{\boldsymbol{x} \in X_{0}}\left(\boldsymbol{x}-\boldsymbol{\mu}_{0}\right)\left(\boldsymbol{x}-\boldsymbol{\mu}_{0}\right)^{\mathrm{T}}+\sum_{\boldsymbol{x} \in X_{1}}\left(\boldsymbol{x}-\boldsymbol{\mu}_{1}\right)\left(\boldsymbol{x}-\boldsymbol{\mu}_{1}\right)^{\mathrm{T}} \end{aligned}
Sw??=��0?+��1?=x��X0?��?(x?��0?)(x?��0?)T+x��X1?��?(x?��1?)(x?��1?)T?
�����ɢ�Ⱦ���(between-class scatter matrix):
S
b
=
(
��
0
?
��
1
)
(
��
0
?
��
1
)
T
\mathbf{S}_{b}=\left(\boldsymbol{\mu}_{0}-\boldsymbol{\mu}_{1}\right)\left(\boldsymbol{\mu}_{0}-\boldsymbol{\mu}_{1}\right)^{\mathrm{T}}
Sb?=(��0??��1?)(��0??��1?)T
Ȼ�����ǵ�
J
J
J���Ա�ʾΪ
J
=
w
T
S
b
w
w
T
S
w
w
J=\frac{\boldsymbol{w}^{\mathrm{T}} \mathbf{S}_{b} \boldsymbol{w}}{\boldsymbol{w}^{\mathrm{T}} \mathbf{S}_{w} \boldsymbol{w}}
J=wTSw?wwTSb?w?
��������������,��������ǵ�LDA��Ҫ���Ŀ�꺯��,�Ƚ�רҵ��˵��Ϊ,
S
b
S_b
Sb?��
S
w
S_w
Sw?�ġ����������̡�(generalizad Rayleigh quotient)��
���ڡ����������̡�(generalizad Rayleigh quotient)�Ľ���,���Բο�������������
�����̾��������ڽ�ά�;���������,��Ϊ��ά�������������ܵ��������С�������ص�ʽ��,����ͨ������ֵ�ֽ�ķ�ʽ�ҵ���ά�ռ���
������������:
���濪ʼ�������ǵĺ�����Լ��������

���ȵ�ȷ�����ǵ�
w
w
w,����
J
J
J�ķ�ĸ���Ӷ��ǹ���
w
w
w�Ķ���ʽ��,����
w
w
w�ij�����,��ֻ�뷽���йء���������
w
T
S
w
w
=
1
\boldsymbol{w}^{\mathrm{T}} \mathbf{S}_{w} \boldsymbol{w}=1
wTSw?w=1,��:
min
?
w
?
w
T
S
b
w
?s.t.?
w
T
S
w
w
=
1
\begin{array}{ll} \min _{\boldsymbol{w}} & -\boldsymbol{w}^{\mathrm{T}} \mathbf{S}_{b} \boldsymbol{w} \\ \text { s.t. } & \boldsymbol{w}^{\mathrm{T}} \mathbf{S}_{w} \boldsymbol{w}=1 \end{array}
minw??s.t.???wTSb?wwTSw?w=1?
���������ճ�����(����ɲο�CCA��Lagrange��Ӧ��)�ɵ�,
S
b
w
=
��
S
w
w
(*)
\boldsymbol{S_bw=\lambda S_w w}\tag{*}
Sb?w=��Sw?w(*)
����, �� \lambda ��Ϊ�������ճ��ӡ�
���ϡ����ɢ�Ⱦ���֪,
S
b
w
\boldsymbol{S_bw}
Sb?wΪ
��
0
?
��
1
\mu_0-\mu_1
��0??��1?��ƽ��,��
S
b
w
\boldsymbol{S_bw}
Sb?w�ķ������Ϊ
��
0
?
��
1
\mu_0-\mu_1
��0??��1?,�����ķ������ȷ����,��������
S
b
w
=
��
(
��
0
?
��
1
)
\boldsymbol{S_bw=\lambda (\mu_0-\mu_1)}
Sb?w=��(��0??��1?)
��������ȷ��, �� \lambda ��ֻ�Ǵ������������ij���,���� S b w \boldsymbol{S_bw} Sb?w������ʽ������ܻ������ɻ���,����� �� \lambda ����(*)ʽ�� �� \lambda ����һ�� �� \lambda ����?
���ǿ϶��ġ�
����ʽ����(*)ʽ,�ɵù���
S
w
\boldsymbol{S_w}
Sw?��ʽ��:
w
=
S
w
?
1
(
��
0
?
��
1
)
\boldsymbol{w=S_w^{-1}(\mu_0-\mu_1)}
w=Sw?1?(��0??��1?)
������Ҫ��
S
w
\boldsymbol{S_w}
Sw?����,���ǵ���ֵ����ȶ���,����ʵ��������,��Ҫ��
S
w
\boldsymbol{S_w}
Sw?��������ֵ�ֽ�(Ҳ���������ھ���������ѧ����SVD����),ԭ���ܼ�,�˴�,��Ϊ
S
w
=
U
��
V
T
\boldsymbol{S_w=U\Sigma V^{T}}
Sw?=U��VT,����
��
\Sigma
����һ��ʵ�ԽǾ���,�Խ����ϵ�Ԫ��Ҳ������ν�ġ�������
S
w
\boldsymbol{S_w}
Sw?������ֵ��������Ҫ������
S
w
\boldsymbol{S_w}
Sw?����,��ʽ�ӱ�Ϊ������,
S
w
?
1
=
V
��
?
1
U
T
\boldsymbol{S_w^{-1}=V\Sigma^{-1} U^{T}}
Sw?1?=V��?1UT
����,���ǵõ���
S
w
?
1
\boldsymbol{S_w^{-1}}
Sw?1?,�Ӷ������ֱ������
w
w
w,�ҵ�ʹ��
J
J
J ����
w
w
w.
LDA���ɴӱ�Ҷ˹�������۵ĽǶ�������(���ڱ�Ҷ˹�ɲο�����),��֤��,����������ͬ���顢�����˹�ֲ�(��̬�ֲ�)��Э�������ʱ,LDA���Դﵽ���ŵķ���Ч����
����������ô��Ƕ���������,��ô���ڶ��������
���������б����LDA��Fisher�б����ԭ�����ƹ�ɿ� ��> ����
������ط���(CCA)
����������������CCA,���ǿ���֪��,��˵�����ǶԲ�ͬ����֮������ط�������Ϊרҵ��˵����,һ�ֶ����������֮����س̶ȵ���Ԫͳ�Ʒ�����
���������Զ�����������,��������һƪBlog���Բο��ο���
����,�ӻ��������֡�
��������Ҫ���������� X , Y X,Y X,Y������ع�ϵ����ʱ,�����õ����ϵ������ӳ��ѧ������ͳ�Ƶ�С���Ӧ�ö�֪���İɡ����ǽ���һ�¡�
���ϵ��:��һ�����Է�ӳ����֮����ع�ϵ���г̶ȵ�ͳ��ָ�ꡣ���ϵ���ǰ����������,ͬ���������������ƽ��ֵ�����Ϊ����,ͨ����������������ӳ������֮����س̶�;�����о����Եĵ����ϵ����
R ( X , Y ) = Cov ? ( X , Y ) Var ? [ X ] Var ? [ Y ] R(X, Y)=\frac{\operatorname{Cov}(X, Y)}{\sqrt{\operatorname{Var}[X] \operatorname{Var}[Y]}} R(X,Y)=Var[X]Var[Y]?Cov(X,Y)?
����, C o v ( X , Y ) Cov(X,Y) Cov(X,Y)��ʾ X , Y X,Y X,Y��Э�������, V a r [ X ] Var[X] Var[X]Ϊ X X X�ķ���, V a r [ Y ] Var[Y] Var[Y]Ϊ Y Y Y�ķ���.
��ϰ��һ�´�ѧ���Ƹ���ͳ��֪ʶ,��ô,���������Ҫ�����Ķ�����������߶�������,�ָ���ô����?
CCA����ѧ����:
��������������
A
(
a
1
,
a
2
,
.
.
.
,
a
n
)
,
B
(
b
1
,
b
2
,
.
.
.
,
b
m
)
A(a_1,a_2,...,a_n),B(b_1,b_2,...,b_m)
A(a1?,a2?,...,an?),B(b1?,b2?,...,bm?),��ô���ǵĹ�ʽ��������:
R
(
X
i
,
Y
j
)
=
��
i
=
1
,
j
=
1
n
,
m
C
o
v
(
X
i
,
Y
j
)
V
a
r
[
X
i
]
V
a
r
[
Y
j
]
R(X_i,Y_j)=\sum_{i=1,j=1}^{n,m} \frac{Cov(X_i,Y_j)}{\sqrt{Var[X_i]Var[Y_j]}}
R(Xi?,Yj?)=i=1,j=1��n,m?Var[Xi?]Var[Yj?]?Cov(Xi?,Yj?)?
���ǻ�õ�һ�������ľ���:
[
R
(
X
1
,
Y
1
)
.
.
.
R
(
X
1
,
Y
m
?
1
)
R
(
X
1
,
Y
m
)
R
(
X
2
,
Y
1
)
.
.
.
R
(
X
2
,
Y
m
?
1
)
R
(
X
2
,
Y
m
)
.
.
.
.
.
.
.
.
.
.
.
.
R
(
X
n
,
Y
1
)
.
.
.
.
.
.
R
(
X
n
,
Y
m
)
]
\begin{bmatrix} R(X_1,Y_1) &... & R(X_1,Y_{m-1}) & R(X_1,Y_m)\\R(X_2,Y_1) & ...& R(X_2,Y_{m-1})& R(X_2,Y_m)\\ ...& ...& ...&... \\ R(X_n,Y_1) & ...& ...&R(X_n,Y_m) \end{bmatrix}
?????R(X1?,Y1?)R(X2?,Y1?)...R(Xn?,Y1?)?............?R(X1?,Ym?1?)R(X2?,Ym?1?)......?R(X1?,Ym?)R(X2?,Ym?)...R(Xn?,Ym?)??????
�����Ļ�,���ǰ�ÿ�����������ϵ�������˳���,��֪��������һ�����������ܷ����ء�����������ҵ��������֮��ĸ��Ե��������,��ô���Ǿ�ֻ���������������֮�����ط�����
�������ϵ��:���ȶ�ԭ����������������ɷַ���,�õ��µ����Թ�ϵ���ۺ�ָ��,��ͨ���ۺ�ָ��֮����������ϵ�����о�ԭ�����������ع�ϵ��
���������������ɷַ���(PCA)��˼��,���Ѷ��������������֮������ת������������֮�����ء�
�ȵõ��������
(
A
T
,
B
T
)
(A^T,B^T)
(AT,BT)���������
��
=
[
��
11
?
��
12
��
21
?
��
22
]
\Sigma=\left[\begin{array}{l} \Sigma_{11} \ \Sigma_{12} \\ \Sigma_{21} \ \Sigma_{22} \end{array}\right]
��=[��11??��12?��21??��22??]
����,
��
11
=
C
o
v
(
A
)
,
��
22
=
C
o
v
(
B
)
,
��
12
=
��
12
T
=
C
o
v
(
A
,
B
)
\Sigma_{11} = Cov(A),\Sigma_{22} = Cov(B),\Sigma_{12}=\Sigma_{12}^T = Cov(A,B)
��11?=Cov(A),��22?=Cov(B),��12?=��12T?=Cov(A,B).
�������������
A
(
a
1
,
a
2
,
.
.
.
,
a
n
)
,
B
(
b
1
,
b
2
,
.
.
.
,
b
m
)
A(a_1,a_2,...,a_n),B(b_1,b_2,...,b_m)
A(a1?,a2?,...,an?),B(b1?,b2?,...,bm?)�ֱ���ϳ���������U��V,�������Ա�ʾ
U
=
t
1
a
1
+
t
2
a
2
+
.
.
.
+
t
n
a
n
,
V
=
h
1
b
1
+
h
2
b
2
+
.
.
.
+
h
m
b
m
\begin{matrix} U=t_1a_1+t_2a_2+...+t_na_n,\\ \\V=h_1b_1+h_2b_2+...+h_mb_m \end{matrix}
U=t1?a1?+t2?a2?+...+tn?an?,V=h1?b1?+h2?b2?+...+hm?bm??
Ȼ��,�ҳ������ܵ����ϵ�� t k = ( t 1 , t 2 , . . . , t n ) T , h k = ( h 1 , h 2 , . . . , h m ) T {t_k}=(t_1,t_2,...,t_n)^T,{h_k}=(h_1,h_2,...,h_m)^T tk?=(t1?,t2?,...,tn?)T,hk?=(h1?,h2?,...,hm?)T,
ʹ��, R ( U , V ) ? M a x R(U,V)\longrightarrow Max R(U,V)?Max,����,�͵õ����������ϵ��;�����е� U , V U,V U,V Ϊ������ر�����
������ط��������ص�˼��:���ȷֱ���ÿ��������ҳ���һ�Ե��ͱ���,ʹ�������������,Ȼ����ÿ��������ҳ��ڶ��Ե��ͱ���,ʹ��ֱ��뱾���ڵĵ�һ�Ե��ͱ��������,�ڶ��Ա������дδ������ԡ������ȥ,ֱ�����е�K��,������������ϵ����ȡ��Ϊֹ,���Եõ�K�������
So,
ע��:��ʱ�� ( U , V ) (U,V) (U,V)�����ܷ�ӳ�������֮�����ع�ϵ,������Ҫ����������һ���ϵ��������ʾ,����ɹ��� K K K�������Ĺ�ϵ
ֱ��
R
(
U
,
V
)
?
M
a
x
R(U,V)\longrightarrow Max
R(U,V)?MaxΪֹ
U
k
=
t
k
T
A
=
t
1
k
a
1
+
t
2
k
a
2
+
.
.
.
+
t
n
k
a
n
V
k
=
h
k
T
B
=
h
1
k
b
1
+
h
2
k
b
2
+
.
.
.
+
h
m
k
b
m
\begin{matrix} U_k={t_k^T}{A}=t_{1k}a_1+t_{2k}a_2+...+t_{nk}a_n\\ \\ V_k={h_k^T}{B}=h_{1k}b_1+h_{2k}b_2+...+h_{mk}b_m \end{matrix}
Uk?=tkT?A=t1k?a1?+t2k?a2?+...+tnk?an?Vk?=hkT?B=h1k?b1?+h2k?b2?+...+hmk?bm??
����,������Ҫһ��Լ����������,ʹ�� R ( U , V ) ? M a x R(U,V)\longrightarrow Max R(U,V)?Max
V
a
r
(
U
k
)
=
V
a
r
(
t
k
T
A
)
=
t
k
T
��
11
t
k
=
1
V
a
r
(
V
k
)
=
V
a
r
(
h
k
T
A
)
=
h
k
T
��
22
h
k
=
1
C
o
v
(
U
k
,
U
i
)
=
C
o
v
(
U
k
,
V
i
)
=
C
o
v
(
V
i
,
U
k
)
=
C
o
v
(
V
k
,
V
i
)
=
0
(
1
<
=
i
<
k
)
\begin{matrix} Var(U_k)=Var({t_k^T}{A})={t_k^T}\Sigma_{11}t_k=1\\ \\ Var(V_k)=Var({h_k^T}{A})={h_k^T}\Sigma_{22}h_k=1\\ \\ Cov(U_k,U_i)=Cov(U_k,V_i)=Cov(V_i,U_k)=Cov(V_k,V_i)=0(1<=i<k) \end{matrix}
Var(Uk?)=Var(tkT?A)=tkT?��11?tk?=1Var(Vk?)=Var(hkT?A)=hkT?��22?hk?=1Cov(Uk?,Ui?)=Cov(Uk?,Vi?)=Cov(Vi?,Uk?)=Cov(Vk?,Vi?)=0(1<=i<k)?
�������ϵ����ʽ
R
(
U
,
V
)
R_{(U,V)}
R(U,V)?
R
(
U
,
V
)
=
Cov
?
(
U
,
V
)
Var
?
[
U
]
Var
?
[
V
]
=
C
o
v
(
U
,
V
)
=
t
k
T
C
o
v
(
A
,
B
)
h
k
=
t
k
T
��
12
h
k
R_{(U,V)}=\frac{\operatorname{Cov}(U, V)}{\sqrt{\operatorname{Var}[U] \operatorname{Var}[V]}}=Cov(U,V)={t_k}^TCov(A,B)h_k={t_k}^T\Sigma_{12} h_k
R(U,V)?=Var[U]Var[V]?Cov(U,V)?=Cov(U,V)=tk?TCov(A,B)hk?=tk?T��12?hk?
�ڴ�Լ��������, t k , h k t_k,h_k tk?,hk?ϵ���õ����,��ʹ�� R ( U , V ) R_{(U,V)} R(U,V)?�����
���������ط���CCA�㷨���������Ӧ�ÿɿ� ��> ����
����������(SFA)
����һ�� i ά�����ź� x ( t ) = [ x 1 ( t ) , �� , x I ( t ) ] T \mathbf{x}(t)=\left[x_{1}(t), \ldots, x_{I}(t)\right]^{T} x(t)=[x1?(t),��,xI?(t)]T,����һ������-������� g ( x ) = [ g 1 ( x ) , �� , g J ( x ) ] T \mathbf{g}(\mathbf{x})=\left[g_{1}(\mathbf{x}), \ldots, g_{J}(\mathbf{x})\right]^{T} g(x)=[g1?(x),��,gJ?(x)]T,ÿ����������һ��K�������Ժ����ļ�Ȩ�� h k ( x ) : g j ( x ) : = �� k = 1 K w j k h k ( x ) h_{k}(\mathbf{x}): g_{j}(\mathbf{x}):=\sum_{k=1}^{K}w_{j k} h_{k}(\mathbf{x}) hk?(x):gj?(x):=��k=1K?wjk?hk?(x)��ͨ��K > max(I, J)��Ӧ�� h = [ h 1 , �� , h K ] T \mathbf{h}=\left[h_{1}, \ldots, h_{K}\right]^{T} h=[h1?,��,hK?]T�������źŲ�����������չ�ź� z ( t ) : = h ( x ( t ) ) \mathbf{z}(t):=\mathbf{h}(\mathbf{x}(t)) z(t):=h(x(t))���������ַ�����չ����,���Խ�����������չ���źŷ��� z k ( t ) z_k(t) zk?(t)����Ϊ�������⡣���ǽ�����������ת��Ϊ��������ij��÷�����һ��������֪��������֧��������(Vapnik, 1995)��Ȩ���� w j = [ w j 1 , �� , w j K ] T \mathbf{w}_{j}=\left[w_{j 1}, \ldots, w_{j K}\right]^{T} wj?=[wj1?,��,wjK?]T����ѧϰ,��j������źŷ����� y j ( t ) = g j ( x ( t ) ) = w j T h ( x ( t ) ) = w j T z ( t ) y_{j}(t)=g_{j}(\mathbf{x}(t))=\mathbf{w}_{j}^{T} \mathbf{h}(\mathbf{x}(t))=\mathbf{w}_{j}^{T} \mathbf{z}(t) yj?(t)=gj?(x(t))=wjT?h(x(t))=wjT?z(t)������
Ŀ��(������1)���Ż�����-�������,�Ӷ�ʹȨֵ�ﵽ
��
(
y
j
)
=
?
y
�B
j
2
?
=
w
j
T
?
z
�B
z
�B
T
?
w
j
\Delta\left(y_{j}\right)=\left\langle\dot{y}_{j}^{2}\right\rangle=\mathbf{w}_{j}^{T}\left\langle\dot{\mathbf{z}} \dot{\mathbf{z}}^{T}\right\rangle \mathbf{w}_{j}
��(yj?)=?y�B?j2??=wjT??z�Bz�BT?wj? (3.1)
����С�ġ�
������ѡ��ķ����Ժ���hkareʹ��չ�ź�z(t)�������ֵ�͵�λЭ�����������һ������Ժ��� h k h_k hk?���Ժ�����ͨ��һ����״����⼯�� h k �� h_{k}^{\prime} hk��?�е���,����������Ȼ�����Ƿ���Լ������(����ʽ2-4)
? y j ? = w j T ? z ? ? = 0 = 0 , ( 3.2 ) ? y j 2 ? = w j T ? z z T ? ? = I w j = w j T w j = 1 ( 3.3 ) , ? j �� < j : ? y j �� y j ? = w j �� T ? z z T ? ? = I w j = w j �� T w j = 0 , ( 3.4 ) \begin{array}{r} \left\langle y_{j}\right\rangle = \mathbf{w}_{j}^{T} \underbrace{\langle\mathbf{z}\rangle}_{ = 0} = 0, (3.2)\\ \left\langle y_{j}^{2}\right\rangle = \mathbf{w}_{j}^{T} \underbrace{\left\langle\mathbf{z z}^{T}\right\rangle}_{ = \mathbf{I}} \mathbf{w}_{j} = \mathbf{w}_{j}^{T} \mathbf{w}_{j} = 1 (3.3), \\ \forall j^{\prime}<j: \quad\left\langle y_{j^{\prime}} y_{j}\right\rangle = \mathbf{w}_{j^{\prime}}^{T} \underbrace{\left\langle\mathbf{z z}^{T}\right\rangle}_{ = \mathbf{I}} \mathbf{w}_{j} = \mathbf{w}_{j^{\prime}}^{T} \mathbf{w}_{j} = 0, (3.4) \end{array} ?yj??=wjT?=0 ?z???=0,(3.2)?yj2??=wjT?=I ?zzT???wj?=wjT?wj?=1(3.3),?j��<j:?yj��?yj??=wj��T?=I ?zzT???wj?=wj��T?wj?=0,(3.4)?
���ҽ�������Լ��Ȩ������Ϊ�����ı�������ʱ,�Զ����㡣
���,����������������ĵ�һ������,�Ż������ΪѰ��ʹ����(3.1)�е� �� ( y 1 ) \Delta\left(y_{1}\right) ��(y1?)��С�ĸ���Ȩ���������Ǿ��� ? z �B z �B T ? \left\langle\dot{\mathbf{z}} \dot{\mathbf{z}}^{T}\right\rangle ?z�Bz�BT?�ĸ�����������,����Ӧ����С������ֵ(cf. Mitchison, 1991)����һ�����ߵ�����ֵ������������������-�����������һ����������һ�����ߵ�1��ֵ����������˽�������Ż�������㷨��
��ȷ����ԭʼ�źš�����ѵ�����ݵľ�ȷ��һ���źź����Բ������ݵĽ��ƹ�һ���ź������õġ��� x ~ ( t ) \tilde{\mathbf{x}}(t) x~(t)��һ�������������ֵ�ͷ����ԭʼ�����źš�Ϊ�˼��㷽�����ʾ��Ŀ��,�źű���һ��Ϊ���ƽ��ֵ�͵�λ������ֹ�һ����ѵ������x(t)�Ǿ�ȷ�ġ�����ͬ��ƫ������������У����������,ͨ����õ�һ�����ƹ�һ���������ź� x �� ( t ) \mathbf{x}^{\prime}(t) x��(t),��Ϊÿ�����������ľ�ֵ�ͷ������в�ͬ,����һ������ʹ�ô�ѵ��������ȷ����ƫ��������������ɡ�������,ԭʼ�ź���һ��������,����������һ�����ۺ�;û�в��������ۺŵķ���ͨ��(��������)ָ���ǹ淶��ѵ�����ݡ�
���㷨������������ʽ(�μ���ͼ):
- �����ź�������ѵ��,iά�����ź�Ϊ x ~ ( t ) \tilde{\mathbf{x}}(t) x~(t)��
- �����źŹ�һ�����������źŽ��й�һ���õ�
x ( t ) : = [ x 1 ( t ) , �� , x I ( t ) ] T ( 3.5 ) ?with? x i ( t ) : = x ~ i ( t ) ? ? x ~ i ? ? ( x ~ i ? ? x ~ i ? ) 2 ? , ( 3.6 ) ?so?that? ? x i ? = 0 ( 3.7 ) ?and? ? x i 2 ? = 1 ( 3.8 ) \begin{aligned} \mathbf{x}(t) &:=\left[x_{1}(t), \ldots, x_{I}(t)\right]^{T} (3.5)\\ \text { with } \quad x_{i}(t) &:=\frac{\tilde{x}_{i}(t)-\left\langle\tilde{x}_{i}\right\rangle}{\sqrt{\left\langle\left(\tilde{x}_{i}-\left\langle\tilde{x}_{i}\right\rangle\right)^{2}\right\rangle}}, (3.6) \\ \text { so that } \quad\left\langle x_{i}\right\rangle &=0 (3.7)\\ \text { and } \quad\left\langle x_{i}^{2}\right\rangle &=1 (3.8) \end{aligned} x(t)?with?xi?(t)?so?that??xi???and??xi2???:=[x1?(t),��,xI?(t)]T(3.5):=?(x~i???x~i??)2??x~i?(t)??x~i???,(3.6)=0(3.7)=1(3.8)?
- ������������Ӧ��һ������Ժ��� h ~ ( x ) \tilde{\mathbf{h}}(\mathbf{x}) h~(x),������չ�ź� z ~ ( t ) \tilde{\mathbf{z}}(t) z~(t)������ʹ����һ�ε����е���ʽ(�������� S F A SFA SFA��ʱ�� S F A 1 SFA_1 SFA1?��ʾ)��һ�κ����εĵ���ʽ,���������,�� x 1 x 2 x_1x_2 x1?x2?(���¶���SFA��ʱ�� S F A 2 SFA_2 SFA2?��ʾ),��Ҳ����ʹ���κ������ĺ���������˶��ڶ��� S F A SFA SFA,
h ~ ( x ) : = [ x 1 , �� , x I , x 1 x 1 , x 1 x 2 , �� , x I x I ] T ( 3.9 ) z ~ ( t ) : = h ~ ( x ( t ) ) = [ x 1 ( t ) , �� , x I ( t ) , x 1 ( t ) x 1 ( t ) , x 1 ( t ) x 2 ( t ) , �� , x I ( t ) x I ( t ) ] T ( 3.10 ) \begin{aligned} \tilde{\mathbf{h}}(\mathbf{x}):=&\left[x_{1}, \ldots, x_{I}, x_{1} x_{1}, x_{1} x_{2}, \ldots, x_{I} x_{I}\right]^{T} (3.9) \\ \tilde{\mathbf{z}}(t):=\tilde{\mathbf{h}}(\mathbf{x}(t))=&\left[x_{1}(t), \ldots, x_{I}(t), x_{1}(t) x_{1}(t),\right.\\ &\left.x_{1}(t) x_{2}(t), \ldots, x_{I}(t) x_{I}(t)\right]^{T} (3.10) \end{aligned} h~(x):=z~(t):=h~(x(t))=?[x1?,��,xI?,x1?x1?,x1?x2?,��,xI?xI?]T(3.9)[x1?(t),��,xI?(t),x1?(t)x1?(t),x1?(t)x2?(t),��,xI?(t)xI?(t)]T(3.10)?
���� h ~ ( x ) \tilde{\mathbf{h}}(\mathbf{x}) h~(x)������ z ~ ( t ) \tilde{\mathbf{z}}(\mathbf{t}) z~(t)��һ�����ȷ����ʵ�ά��Ϊ K = I + I ( I + 1 ) / 2 K = I + I(I + 1)/2 K=I+I(I+1)/2��
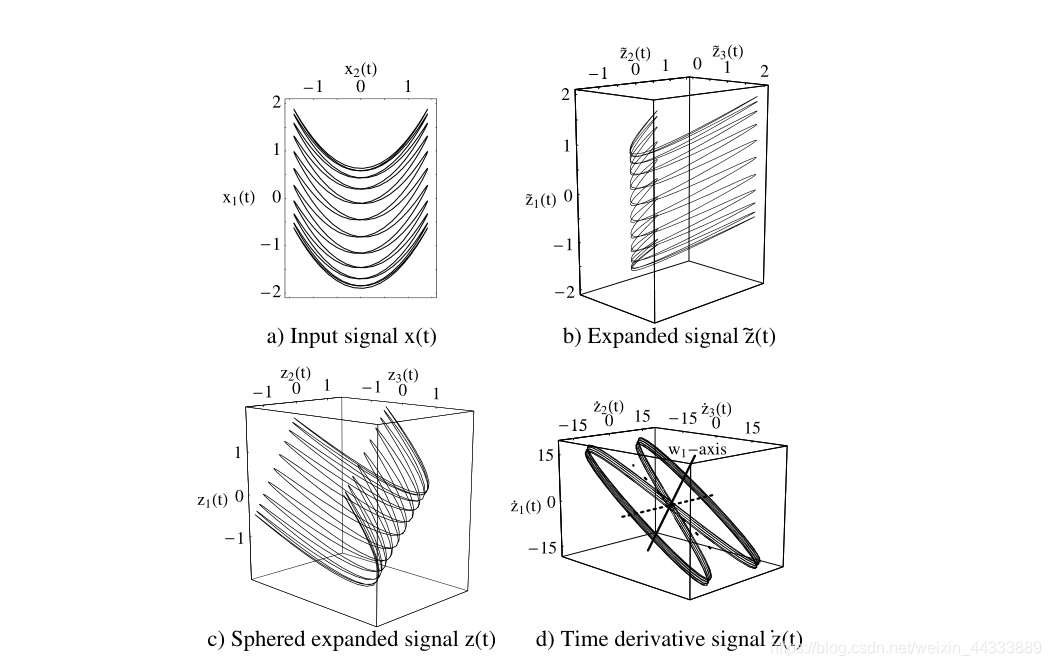
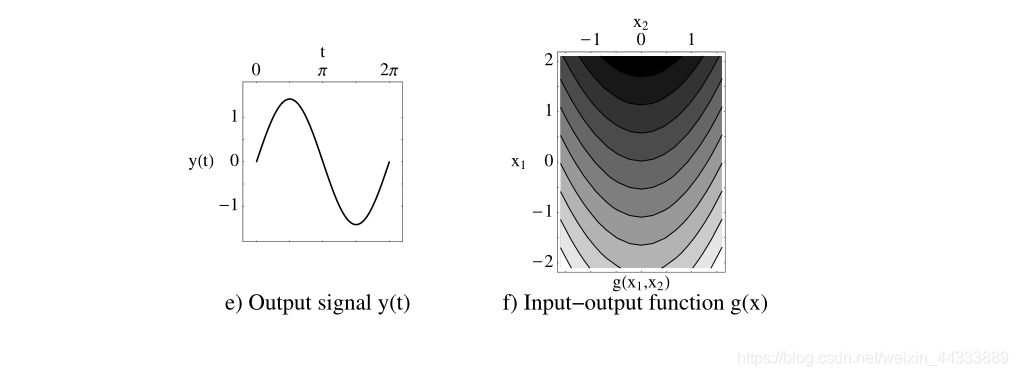
- ����������չ���ź����� z ~ ( t ) \tilde{\mathbf{z}}(\mathbf{t}) z~(t)ͨ������任��һ��,�����ɾ������ֵ�͵�λЭ������� I I I�� z ( t ) z(t) z(t),
z ( t ) : = S ( z ~ ( t ) ? ? z ~ ? ) , ( 3.11 ) ?with? ? z ? = 0 ( 3.12 ) ?and? ? z z T ? = I ( 3.13 ) \begin{aligned} \mathbf{z}(t) &:=\mathbf{S}(\tilde{\mathbf{z}}(t)-\langle\tilde{\mathbf{z}}\rangle), (3.11) \\ \text { with } \quad\langle\mathbf{z}\rangle &=\mathbf{0} (3.12) \\ \text { and }\left\langle\mathbf{z} \mathbf{z}^{T}\right\rangle &=\mathbf{I} (3.13) \end{aligned} z(t)?with??z??and??zzT??:=S(z~(t)??z~?),(3.11)=0(3.12)=I(3.13)?
���ֹ�һ����Ϊ���滯(���)������ S S S���������,����ͨ���Ծ�������ɷַ���(PCA)ȷ�� ( Z ~ ( t ) ? ? z ~ ? ) (\tilde{\mathbf{Z}}(t)-\langle\tilde{\mathbf{z}}\rangle) (Z~(t)??z~?)�����,���������ض���ѵ�����ݼ�����Ҳ������
h ( x ) : = S ( h ~ ( x ) ? ? z ~ ? ) \mathbf{h}(\mathbf{x}):=\mathbf{S}(\tilde{\mathbf{h}}(\mathbf{x})-\langle\tilde{\mathbf{z}}\rangle) h(x):=S(h~(x)??z~?) (3.14)
����һ����������,�� z ( t ) z(t) z(t)�������ݡ�
- ���ɷַ����������ɷַ�����Ӧ���ھ��� ? z �B z �B T ? \left\langle\dot{\mathbf{z}} \dot{\mathbf{z}}^{T}\right\rangle ?z�Bz�BT?��������С����ֵ�� J J J���������� �� j ��_j ��j?�õ���һ��Ȩ����
w j : ? z �B z �B T ? w j = �� j w j ( 3.15 ) ?with? �� 1 �� �� 2 �� ? �� �� J ( 3.16 ) \begin{array}{ll} \mathbf{w}_{j}: & \left\langle\dot{\mathbf{z}} \dot{\mathbf{z}}^{T}\right\rangle \mathbf{w}_{j}=\lambda_{j} \mathbf{w}_{j} (3.15) \\ \text { with } & \lambda_{1} \leq \lambda_{2} \leq \cdots \leq \lambda_{J} (3.16) \end{array} wj?:?with???z�Bz�BT?wj?=��j?wj?(3.15)��1?����2?��?����J?(3.16)?
�ṩ����-�������
g ( x ) : = [ g 1 ( x ) , �� , g J ( x ) ] T ( 3.17 ) ?with? g j ( x ) : = w j T h ( x ) ( 3.18 ) \begin{aligned} \mathbf{g}(\mathbf{x}) &:=\left[g_{1}(\mathbf{x}), \ldots, g_{J}(\mathbf{x})\right]^{T} (3.17)\\ \text { with } \quad g_{j}(\mathbf{x}) &:=\mathbf{w}_{j}^{T} \mathbf{h}(\mathbf{x}) (3.18) \end{aligned} g(x)?with?gj?(x)?:=[g1?(x),��,gJ?(x)]T(3.17):=wjT?h(x)(3.18)?
����ź�
y ( t ) : = g ( x ( t ) ) ( 3.19 ) ?with? ? y ? = 0 ( 3.20 ) ? y y T ? = I ( 3.21 ) ?and? �� ( y j ) = ? y �B j 2 ? = �� j . ( 3.22 ) \begin{aligned} \mathbf{y}(t) &:=\mathbf{g}(\mathbf{x}(t)) (3.19)\\ \text { with } &\langle\mathbf{y}\rangle &=\mathbf{0} (3.20)\\ \left\langle\mathbf{y} \mathbf{y}^{T}\right\rangle &=\mathbf{I} (3.21)\\ \text { and } \Delta\left(y_{j}\right)=\left\langle\dot{y}_{j}^{2}\right\rangle &=\lambda_{j} . (3.22) \end{aligned} y(t)?with??yyT??and?��(yj?)=?y�B?j2???:=g(x(t))(3.19)?y?=I(3.21)=��j?.(3.22)?=0(3.20)
����źŵĸ������ľ�ֵ�͵�λ���Ϊ��,�����Dz���صġ�
-
�ظ��������Ҫ,������ź� y ( t ) y(t) y(t)(������ǰ����������ͬ����źŵ����)��Ϊ�����ź� x ( t ) x(t) x(t),����ѧϰ�㷨����һ��Ӧ�á���������3��
-
������Ϊ�˶Բ����źŽ���ϵͳ����,������2��6���Ƶ��Ĺ�һ��������-�������Ӧ�����µ������ź�(����x0(T))��ע��,��������ź���Ҫʹ����ѵ���ź���ͬ��ƫ���������ӽ��й�һ��,��ȷ������ѧϰ������-�����ϵ�����,ѵ���ź�ֻ�ǽ��Ƶع�һ������
x �� ( t ) : = [ x 1 �� ( t ) , �� , x I �� ( t ) ] T ( 3.23 ) ?with? x i �� ( t ) : = x ~ i �� ( t ) ? ? x ~ i ? ? ( x ~ i ? ? x ~ i ? ) 2 ? ( 3.24 ) ?so?that? ? x i �� ? �� 0 ( 3.25 ) ?and? ? x i �� 2 ? �� 1 ( 3.26 ) \begin{aligned} & \mathbf{x}^{\prime}(t):=\left[x_{1}^{\prime}(t), \ldots, x_{I}^{\prime}(t)\right]^{T} (3.23)\\ \text { with } \quad x_{i}^{\prime}(t) &:=\frac{\tilde{x}_{i}^{\prime}(t)-\left\langle\tilde{x}_{i}\right\rangle}{\sqrt{\left\langle\left(\tilde{x}_{i}-\left\langle\tilde{x}_{i}\right\rangle\right)^{2}\right\rangle}}(3.24) \\ \text { so that } \quad\left\langle x_{i}^{\prime}\right\rangle & \approx 0 (3.25)\\ \text { and }\left\langle x_{i}^{\prime 2}\right\rangle & \approx 1 (3.26) \end{aligned} ?with?xi��?(t)?so?that??xi��???and??xi��2???x��(t):=[x1��?(t),��,xI��?(t)]T(3.23):=?(x~i???x~i??)2??x~i��?(t)??x~i???(3.24)��0(3.25)��1(3.26)?
ֻ���ڲ����źŶ�ѵ���źž��д����Ե������,��һ������ȷ�ġ�����ź�Ҳ�����
y �� ( t ) : = g ( x �� ( t ) ) ( 3.27 ) ?with? ? y �� ? �� 0 , ( 3.28 ) ?and? ? y �� y �� T ? �� I . ( 3.29 ) \begin{aligned} \mathbf{y}^{\prime}(t) &:=\mathbf{g}\left(\mathbf{x}^{\prime}(t)\right)(3.27) \\ \text { with } \quad\left\langle\mathbf{y}^{\prime}\right\rangle & \approx \mathbf{0}, (3.28)\\ \text { and }\left\langle\mathbf{y}^{\prime} \mathbf{y}^{\prime T}\right\rangle & \approx \mathbf{I} . (3.29) \end{aligned} y��(t)?with??y��??and??y��y��T??:=g(x��(t))(3.27)��0,(3.28)��I.(3.29)?
����ʵ��ԭ��,�ڲ���4�Ͳ���5��ʹ��������ֵ�ֽ������PCA������һЩ����ֵ�dz��ӽ�������˻�����,����ֵ�ֽ���һ�ֽϺõķ�������,Ȼ���ڲ���4�ж�����Щ����ֵ��������չ����ʱ�ᵼ���˻�����,��Ϊ�������߶�����ı�ʾ,����һЩ�ɷֿ��ܾ������Թ�ϵ��һ����˵,����ֵ�ӽ�������źŷ���ͨ����������,���������,�ڹ�һ�����dz�Ѹ�ٵز��������κ������,SFA�������ڲ���5��ѡ�����,������ЩС���Ӧ�ñ�����������Ҫ��
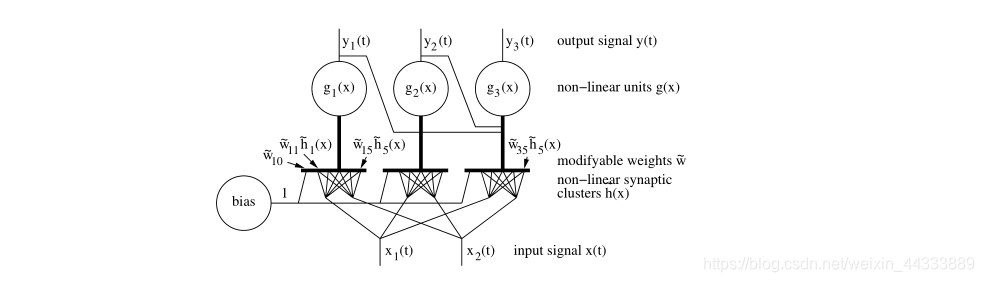
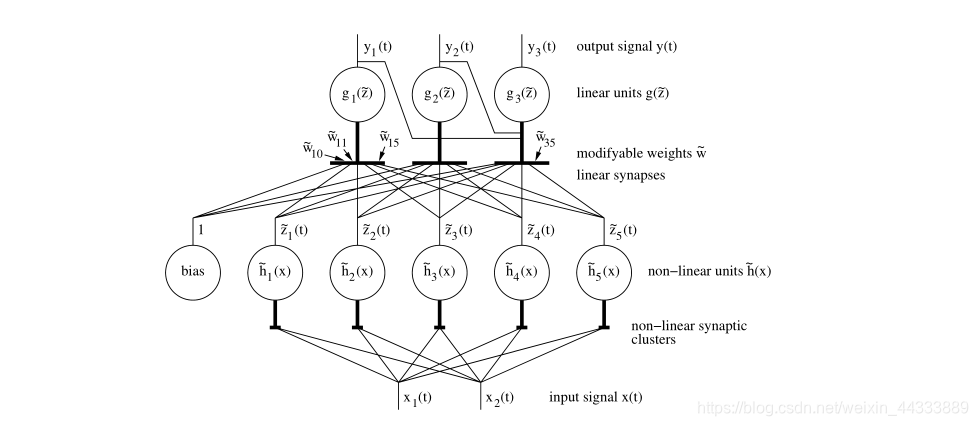
��ͼ3��ִ��SFA�����ֿ��ܵ�����ṹ��(��)��һ�鵥λ������,����(����)�Ͻ��и��ӵļ���,��sigma-pi��λ��(��)����Ϊ��Ԫ���������й̶��ķ����Ե�Ԫ�ķֲ�����,�羶�������������в�����Ӧ��������Ԫ���������������,����-������������� g j ( x ) = w j T h ( x ) = w ~ j 0 + w ~ j T h ~ ( x ) g_{j}(\mathbf{x})=\mathbf{w}_{j}^{T} \mathbf{h}(\mathbf{x})=\tilde{w}_{j 0}+\tilde{\mathbf{w}}_{j}^{T} \tilde{\mathbf{h}}(\mathbf{x}) gj?(x)=wjT?h(x)=w~j0?+w~jT?h~(x)����,�������ʵ���ԭʼ w ~ ( J ) \tilde{\mathbf{w}}(\mathbf{J}) w~(J)Ȩ��������������������źŷ����DZ����ġ�
����ֱ���� �� \Delta ����ֵ,������һ�ָ�ֱ�۵Ľ����������źŵIJ����������õġ�
�����Ƕ���Ϊ��ָ���
g j ( x ) = w j T h ( x ) = w ~ j 0 + w ~ j T h ~ ( x ) �� ( y ) : = T 2 �� �� ( y ) g_{j}(\mathbf{x})=\mathbf{w}_{j}^{T} \mathbf{h}(\mathbf{x})=\tilde{w}_{j 0}+\tilde{\mathbf{w}}_{j}^{T} \tilde{\mathbf{h}}(\mathbf{x})\eta(y):=\frac{T}{2 \pi} \sqrt{\Delta(y)} gj?(x)=wjT?h(x)=w~j0?+w~jT?h~(x)��(y):=2��T?��(y)? (3.30)
�� t �� [ t 0 , t 0 + T ] t �� [t_0,t_0+T] t��[t0?,t0?+T], ����һ�������Ҳ� y ( t ) : = 2 sin ? ( n 2 �� t / T ) y(t):=\sqrt{2} \sin (n 2 \pi t / T) y(t):=2?sin(n2��t/T)������Ŀ����,��(y)��������Ŀ,����(y) = n�����,�����źŵ�ָ���DZ�ʾ��ֵͬ�Ĵ����Ҳ�������,���ٶԦǵ�����ֵ�������ġ��ͦ�ֵ��ʾ�ź��������ڴӲ������ݵ���������ź�ֻ�ǽ��ƹ�һ��, �� ( y 0 ) ��(y_0) ��(y0?)��ζ�Ű��� y 0 y_0 y0?�����ƽ��ֵ�͵�λ����ľ�ȷ��һ��,��ʹ �� \eta �� ָ�������һ��żȻ�ı������ӡ�
��������������SFAԭ����Ӧ�ÿɿ� ��> ����
���������ݽ�ά
ʵ�ʹ�ҵ�����������ֳ����ӵ�����,���̵ķ�����������Ϊͻ��,��˷��������ݽ�ά�����ڹ����������õ��˹㷺�Ĺ�ע��Ӧ�á���Թ�ҵ�����д��ڵĴ��������Թ���,�����ǵ������ȡֵ��Χ�ϴ�ʱ,�ܶ������Ϣ�����ַ����Թ�ϵ���ٱ�PCA��������Է����������Ĺ�������о��Ӿ�ʮ�����չ����,��Ҫ��������¼����:����������Է���;(Kernel)����;����ѧϰ(Maniford Learning)������
����������Է���
�����������PCA������������Kramer�����,��ģ����һ�����������,������������ͬһ�����ݡ������м����Ԫ����С�������ĸ���,ʵ���˽�ά��Ч����������ָ��������ṹ����������²����ܱ�֤������PCA�ȼ�,�����һ�ָĽ��ķ���,���ȼ����ÿ��ѵ�����ݵ�ľ�����������������ߵĵ�ά��ʾ��,��ʹ����������������ֱ�ʵ�ֽ�ά���ط���ӳ��;��ѧ������˸����ܶȺ����о��˷�����PCA����Ԫ��������̬�ֲ�������;��ѧ���о��˷����Թ������ݺ��еĶ�̬�����⡣
���������绹�ɽ��LDA��ICA��SFA��CCA���������Է���,����Ͳ���չ����!~~
����ֻ�����������PCA����Ϊ�����������������(NN)����PCA�ķ���,��ʵ��������Ŀǰ��Ȼ���ںܶ������,�����ľ��������������ѵ�����Ӷ�,��ܸ�,��߳ɱ�,��ʵ�ʹ�ҵ�����е����ݲ�����������,����������IJ��������������ȱʧ������������,����,����ģ�͵ķ����������Ǻܺû���˵�����Ա�֤������ȷ������������ģ�͵Ľṹ����Ӧ�����������ݵĹ�ģ,�Ż��㷨,Ч�ʼ����߹���ʵ��,��֤ѧϰ�����������Ժͼ�ֵ������δ�õ����,�ʶ��ڴ������������Ľ�ά����,���Ǻܿ���,����˵���ǡ���̫����!
��(Kernel)����
�˷����ǽ����ݵ�ԭʼ����ռ�����Եر任��һ����ά�ĺ������ռ����ʹ�����Լ�����һ�ּ�Ӵ���������
�ʼ�������ƹ��������Ե�Ϊ֧��������(SVM),����������Kernel PCA��������ʶ�������ʶ��,ͬʱ�ڹ��̼������Ҳ���˺ܴ���о���չ,�ƶ��˹��̼�ع�����ϵĽ���,��Ȼ�кܶ�ѧ�߽���kernelӦ�õ��˷����Խ�ά��������,����������һ������Ҫ������,���Ǻ˺�����������ôѡȡ������,���ڼ���˺����ķ���,���������ڷ�ӳ�����еķ�����,���併ά�õ�Ŀ�꺯����û�п��ǵ����������ݽṹ��������,�������ڽ�����ǿ�б�Ϊ�����Խṹ��ȱ��,�ɴ�,���ַ��������Ǻܺ�,����Ҫ��һ�����о����ơ�
���Ժ˺���
��ת������
?
(
x
)
=
x
\phi (x)=x
?(x)=x,��õ����Ժ˺���,�����������ĵ��Ϊ:
k
(
x
,
x
��
)
=
x
T
x
��
k(x,x^{'})=x^{T}x^{'}
k(x,x��)=xTx��
���Ժ˺����������ռ�F��ά��������ռ�
��
\chi
����ά��һ��,ÿ��������������Ҳһ��,����
x
=
(
x
1
,
x
2
,
.
.
.
,
x
n
)
x=(x_{1},x_{2},...,x_{n})
x=(x1?,x2?,...,xn?)��������,
x
x
x����һ��������
������Ҫ�������ռ��������ʱ,����ʹ�����Ժ˺�����
���ԭʼ�����Ѿ��Ǹ�ά�ҿɽ��бȽ�,������ռ������Կɷ֡�
�����ں��������ɴ����̶����ȵ��������ݱ�ʾ�Ķ���
��˹�˺���
��˹�˺������ֳ�������Square exponential kernel(SE Kernel )or radial basis function(RBF,���������),������:
k
(
x
,
x
��
)
=
e
?
1
2
(
x
?
x
��
)
T
��
?
1
(
x
?
x
��
)
k(x,x^{'})=e^{-\frac{1}{2}(x-x^{'})^{T}\Sigma^{-1} (x-x^{'})}
k(x,x��)=e?21?(x?x��)T��?1(x?x��)
����,
��
\Sigma
����ʾ��������������ÿ��������������Ӧ��Э����,Pά���ݾ���
��
��
\Sigma
���ǶԽǾ���ʱ,Ϊ
k
(
x
,
x
��
)
=
e
?
1
2
��
j
=
1
p
(
x
j
?
x
j
��
)
2
��
j
2
k(x,x^{'})=e^{-\frac{1}{2}\sum_{j=1}^{p} \frac{(x_{j}-x^{'}_{j})^2}{\sigma^{2}_{j}}}
k(x,x��)=e?21?��j=1p?��j2?(xj??xj��?)2?
����,
��
j
\sigma_j
��j?����������
j
j
j �������߶ȡ�
��
��
\Sigma
�������ε�ʱ��,��Ϊ
k
(
x
,
x
��
)
=
e
?
��
x
?
x
��
��
2
2
��
2
,
��
j
=
��
,
?
j
k(x,x^{'})=e^{-\frac{\left \| x-x^{'} \right \|^{2}}{2\sigma^{2}}},\sigma_j=\sigma,\forall j
k(x,x��)=e?2��2����?x?x������?2?,��j?=��,?j
�ú˺����������ռ��ά�������ġ��˺�������ת�������ļ���,�ʿ���������Ͼ�������ѡn��Gram����,��ʹ�Ѿ�����ʽ�Ľ�����ͶӰ������ά�ȵ������ռ���ȥ,������Ч��
����ѧϰ����
����ѧϰ�Ƿ����Խ�ά����Ҫ�о�����,Ҳ�ǽ�Щ����,��������ѧϰ��������������ȡ������ϵ�һ���µ�̽��,���ܵ��˹㷺�Ĺ�ע��
����(manifold)��һ�㼸�ζ�����ܳ�,��������ά�ȵ������������,��һ��Ľ�ά����һ��,����ѧϰ�ǰ�һ���ڸ�ά�ռ��е������ڵ�ά�ռ������±�ʾ����֮ͬ����,������ѧϰ�м���:�����������ݲ�����һ��DZ�ڵ�������,����˵�����������ݴ���һ��DZ�ڵ����Ρ�
�����ϵĵ㱾����û�������,����Ϊ�˱�ʾ��Щ���ݵ�,���ǰ����η��뵽��Χ�ռ�(ambient space),����Χ�ռ��ϵ���������ʾ�����ϵĵ�,������ά�ռ� R 3 R^3 R3 ��������һ��2ά����,��������ֻ���������ɶ�,������һ�������Χ�ռ�R^3 �ռ��е���������ʾ������档
����ѧϰ = ������ + ��������
����ѧϰ���Ը���Ϊ:�ڱ��������ϵ��ijЩ�������������������,�ҳ�һ���Ӧ����������(intrinsic coordinate),�����ξ����õ�չ���ڵ�άƽ����,���ֵ�ά��ʾҲ����������(intrinsic feature),��Χ�ռ��ά���й۲�ά��,���ʾ����Ȼ����,��ͳ���ϳ�Ϊobservation��(��������Blog)
LLE(Locally Linear Embedding) �ֲ�����Ƕ��
LLE�㷨����2000�걻S.T.Roweis��L.K.Saul������ķ����Խ�ά����,���Ļ���˼���ǽ�ȫ�ַ�����ת��Ϊ�ֲ�����,�������ص��ľֲ������ܹ��ṩȫ�ֽṹ����Ϣ,������ÿ���ֲ��������Խ�ά��,�ڰ���ij�ֹ���������һ��,���ܹ��õ���ά��ȫ�������ʾ��
LLE�㷨��һ��ǰ�����:�����������ڵĵ�ά�����ھֲ������Ե�,��ÿ����������������Ľ��ڵ����Ա�ʾ�����������������ս������Ч���ϵõ�֤�������㷨��ѧϰĿ����:�ڵ�ά�ռ��б���ÿ�������е�Ȩֵ����,������Ƕ��ӳ���ھֲ������Ե�������,��С���ع���
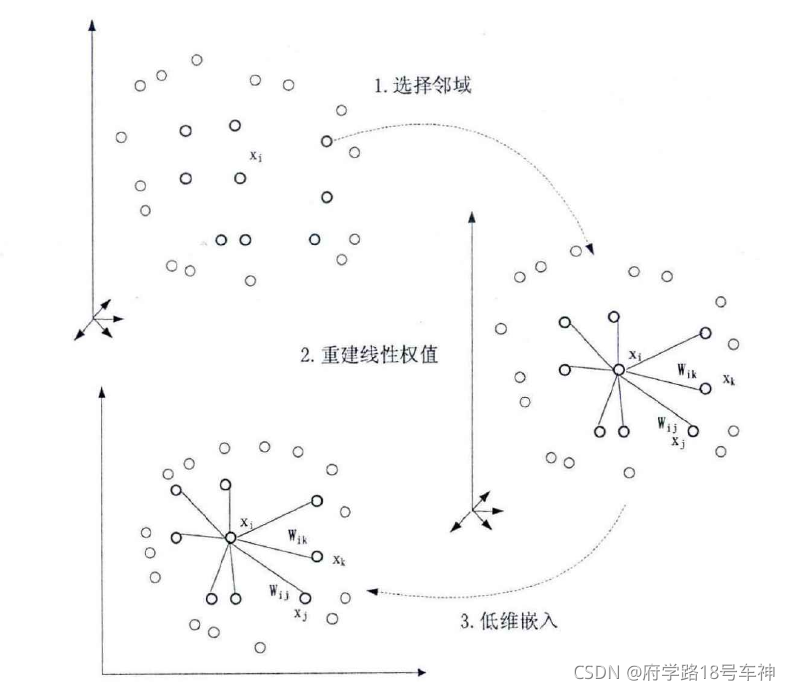
��ͼΪLLE�㷨�����в���
���и�ά�ռ� R D R^D RD�е�N����ά������� { x i } = ( x 1 , x 2 , . . . , x N ) , i �� [ 1 , N ] \{x_{i}\}=(x_{1},x_{2},...,x_{N}),i\in [1,N] {xi?}=(x1?,x2?,...,xN?),i��[1,N],Ҫͨ����ά������ӳ�䵽��ά�ռ� R d R^{d} Rd��,��Ҫ���ӳ����N��dά����̨ { y i } , i �� [ 1 , N ] \{y_{i}\},i\in [1,N] {yi?},i��[1,N]�����ǵ�Ȼϣ���ܹ�����ʾ��ӳ�� F F F����ʾ,��{ x i x_i xi?}���Ƿ����Խṹʱ,�����ʾӳ�� F F F�൱����,��������ѧϰ��ԭ��,��W�������Խṹ�ľֲ������Խṹ������,����W�������Խṹ�Ľ�ά�ֽ�Ϊ�ֲ������Խ�ά�������LLE�㷨�Ļ���ԭ����
��Ҫ����:
- Ѱ��ÿ��������� k k k�����ڵ�;
- ��ÿ��������Ľ��ڵ�������������ľֲ��ؽ�Ȩֵ����
- �ɸ�������ľֲ��ؽ�Ȩֵ���������ڵ���������������������
�������ϸ���㲽��Ͳ���������,��һ�����е�д�IJ���,����ת����
LE (Laplacian Eigenmaps) ������˹����ӳ��
������˹����ӳ��(Laplacian Eigenmaps,LE)Ҳ��һ�־ֲ�������ѧϰ����,��LE�ķ����е�����,LE�㷨Ҳ����ֱ�۽�ά��Ŀ�꺯��,Ҳ����˵,ͨ�������˸�ά����֮��Ľ��ڹ�ϵ���õ���ά���������нṹ��
LE�㷨����Ҫ�������IJ�:
- ��������ͼ:����ÿ����ά�������ݵ� { x i } = ( x 1 , x 2 , . . . , x N ) , i �� [ 1 , N ] \{x_{i}\}=(x_{1},x_{2},...,x_{N}),i\in [1,N] {xi?}=(x1?,x2?,...,xN?),i��[1,N],Ѱ����������ݵ�(ȥŷ�Ͼ������СK���ڵ����ݵ�),�ɴ˽��������ϵͼ(����ͼ)
- ����ÿ���������ݵ�ִ���Ȩֵ,(�������ı�ȨֵΪ0),����Ȩֵ����
W
=
{
w
i
j
}
W=\{w_{ij} \}
W={wij?}.
�������ݵ���Ȩֵ�ļ��㷽��������:
(���xi��xj�������ϵͼ��Ϊ���ڵ�,������֮���Ȩֵ��ֵΪ w i j = 1 w_{ij}=1 wij?=1;�෴,��Ϊ0.��˵������,�ڵ�����ȡ1,������ȡ0��)
(�Ⱥ�Ȩֵ:���xi��xj��������Ϊ���ڵ�,���Ⱥ˺���Ϊ�丳ֵΪ: w i , j = e x p ( �� x i ? x j �� 2 �� 2 ) w_{i,j}=exp(\frac{\left \| x_{i}-x_{j} \right \|^{2}}{\sigma^2}) wi,j?=exp(��2��xi??xj?��2?)),���� w i , j w_{i,j} wi,j?���뵽������˹�����еõ���ʽ����L;�෴,��Ȩֵ��ֵΪ0.) - ���������������(ӳ����):Ŀ�꺯����> m i n �� i j ( y i ? y j ) 2 w i j min \Sigma_{ij}(y_i-y_j)^2w_{ij} min��ij?(yi??yj?)2wij? ,�����Ƶ�,�Ե�ά���ݵļ���ת��Ϊ����ֵ�ֽ�ķ�ʽ,Ҳ��ʹ�� L y = �� D y Ly=\lambda Dy Ly=��Dy,���� x i x_i xi?ӳ�䵽 y i y_i yi?�С�
- ʹ����С��n�ͷ�������ֵ��Ӧ������������Ϊ��ά��Ľ�������
LPP(Locality Preserving Projection) �ֲ�����ͶӰ
�ֲ�����ͶӰLPP�㷨�����Ŀ����Ϊ��ʵ�ַ��������ε�ѧϰ�ͷ���,LPP������ȡ������б��Ե����������н�ά,��һ�ֱ����˾ֲ���Ϣ,����Ӱ��ͼ��ʶ���������صĽ�ά����,�����㷨��������һ�����Խ�ά����,����������Ľ����������˹����ӳ���㷨(LE)��˼��,�Ӷ������ڶԸ�ά���ݽ��н�ά����Ч�ر��������ڲ��ķ����Խṹ��
�����������Խ�ά�������,LPP�������Խ������IJ������ݵ�,ͨ��ӳ���ڽ�ά����ӿռ��ҵ���Ӧ��λ��,�����������Է���ֻ�ܶ���ѵ�����ݵ�,�������µIJ������ݡ�LPP�������Ժ����ؽ��µIJ������ݵ��������ӳ���ϵ(����),ͶӰӳ���ڵ�ά�ռ��С�
�� n άԭ����ӳ��Ϊ l ά����,l<< n ;ʵ�����ݽ�ά,��������Ϊm ��(���ô�����)


ת������
�����������Ѿ�������,ȷʵ,д��ô��Ҳ����,���涼ֱ��ת������(�˼�),���Ǹ�ʲô�ֲ�����,�ǰ�,һ�������ˢ����~
����!~
����,�����Ĵ�����������ˡ�> ���ݽ�ά�㷨���뼯��
����:https://pan.baidu.com/s/1yusgn7VtgSADEu7tiBF3nA (��ֱ�ӵ�����������ת��Ӵ~)
��ȡ��:yyds
?��ֶ�Paper,������ʼ�,���ѧϰ,���ˢ����LeetCode?!!!
���ˢ��!!!������!!!
?To Be No.1??��������
?��������?,��·��?��ע���ղ��������?��������ò�����
?( ��・?・` )
?
��
���ʾ�����ʶ,��ʶ�����������ʡ�
��