Python ����ѧϰʵս:��˺��������ԭ�������졢��֦�����ӻ�
0 🌲д��ǰ��
Python ����ѧϰʵսר��ּ�ڻ���Pythonʵ�ֻ���ѧϰ�ľ����㷨,�������Իع�LR��������DT�������硢֧��������SVM��,����Դ�������ĩ,������Ҫ��������,���а���,ϣ����github�ϸ���??star~,🔥��ӭ��ע����!
Reference: ��־����ʦ�ġ�����ѧϰ��������📖
1 🌲ʲô�Ǿ�����?
������(decision tree, DT)ģ�����������پ�������ʱ��ϵ���жϴ�������,�������ṹ�������ֶ���֮(divide-and-conquer)ѧϰ��
һ���,�������������ɷ�֧�ڵ��Ҷ�ڵ�,���ķ�֧�ڵ��Ϊ���ڵ㡣��֧�ڵ�������Ի���,Ҷ�ڵ��������Ԥ�������������㷨�Ļ�����ʽ�����ʾ��

�����㷨�еļ����ؼ���:
�������㷨�еݹ鷵������(2)������ֲ���Ϊ��ǰҶ�ڵ�ķֲ�����;����(3)���ø��ڵ������ֲ���Ϊ��ǰҶ�ڵ�ķֲ����ɡ�
���� a ? = g e t B e s t ( A ) a_*=getBest\left( \boldsymbol{A} \right) a??=getBest(A)���ԵĹ����Ϊ��ͬ���㷨������ָ��,����ǰ�ڵ㻮������Ϊ��������,��������Կ���Ϊ�ӽڵ㻮�����ԡ�
��ʱ��������Ҳû��ϵ,�������ʵս��ʱ���ָ��ÿ���Ĺ��̡�
2 🌲�����������㷨
ע:���������㷨�Ĺ�ʽ��������һ���Ա���ο���ͬ������ɵ������ԺͲ����ԡ�
2.1 👉 ID3�㷨
ID3�������㷨����ԭ���ǻ�����Ϣ����(information gain)ɸѡ���Ż�������:
a
?
=
a
r
g
max
?
a
��
A
??
G
a
i
n
(
X
,
a
)
{a_*=\underset{a\in A}{\mathrm{arg}\max}\,\,Gain\left( \boldsymbol{X}, a \right) }
a??=a��Aargmax?Gain(X,a)
��Ϣ���涨��Ϊ������
a
a
a��ѵ����
X
X
X���л��ֺ���Ϣ�صļ���,���
X
X
X������ϴ��ȵ�����:
G
a
i
n
(
X
,
a
)
=
E
n
t
(
X
)
?
��
v
=
1
V
�O
X
v
�O
�O
X
�O
E
n
t
(
X
v
)
Gain\left( \boldsymbol{X}, a \right) =Ent\left( \boldsymbol{X} \right) -\sum_{v=1}^V{\frac{\left| \boldsymbol{X}^v \right|}{\left| \boldsymbol{X} \right|}Ent\left( \boldsymbol{X}^v \right)}
Gain(X,a)=Ent(X)?v=1��V?�OX�O�OXv�O?Ent(Xv)
������Ϣ�������������ϵ����:
E
n
t
(
X
)
=
?
��
k
=
1
�O
Y
�O
p
k
log
?
2
p
k
Ent\left( \boldsymbol{X} \right) =-\sum_{k=1}^{\left| \mathcal{Y} \right|}{p_k\log _2p_k}
Ent(X)=?k=1���OY�O?pk?log2?pk?
���������㷨ʵս���ǻ���ID3�㷨
2.2 👉 C4.5�㷨
C4.5�������㷨�ĺ���ԭ���ǻ���������(gain ratio)ɸѡ���Ż�������,�൱�ڶ���Ϣ������й�������
a
a
a���ȡ�������ȡֵ��Ŀ������ʽ��Ȩ,�Ա�����Ϣ����ƫ�ÿ��ܴ����IJ���Ӱ��:
a
?
=
a
r
g
max
?
a
��
A
??
G
a
i
n
_
r
a
t
i
o
(
X
,
a
)
{a_*=\underset{a\in A}{\mathrm{arg}\max}\,\,Gain\_ratio\left( \boldsymbol{X}, a \right) }
a??=a��Aargmax?Gain_ratio(X,a)
��Ϣ�����ʶ���Ϊ:
G
a
i
n
_
r
a
t
i
o
(
X
,
a
)
=
G
a
i
n
(
X
,
a
)
I
V
(
a
)
Gain\_ratio\left( \boldsymbol{X}, a \right) =\frac{Gain\left( \boldsymbol{X}, a \right)}{IV\left( a \right)}
Gain_ratio(X,a)=IV(a)Gain(X,a)?
�������Թ���ֵ(intrinsic value)
I
V
(
a
)
=
?
��
v
=
1
V
�O
X
v
�O
�O
X
�O
log
?
2
�O
X
v
�O
�O
X
�O
IV\left( a \right) =-\sum_{v=1}^V{\frac{\left| \boldsymbol{X}^v \right|}{\left| \boldsymbol{X} \right|}\log _2\frac{\left| \boldsymbol{X}^v \right|}{\left| \boldsymbol{X} \right|}}
IV(a)=?v=1��V?�OX�O�OXv�O?log2?�OX�O�OXv�O?
2.3 👉 CART�㷨
CART�������㷨�ĺ���ԭ���ǻ�������ϵ��(Gini index)ɸѡ���Ż�������
a
?
=
a
r
g
max
?
a
��
A
??
G
i
n
i
_
i
n
d
e
x
(
X
,
a
)
{a_*=\underset{a\in A}{\mathrm{arg}\max}\,\,Gini\_index\left( \boldsymbol{X}, a \right) }
a??=a��Aargmax?Gini_index(X,a)
����ϵ������Ϊ
G
i
n
i
_
i
n
d
e
x
(
X
,
a
)
=
��
v
=
1
V
�O
X
v
�O
�O
X
�O
G
i
n
i
(
X
v
)
Gini\_index\left( \boldsymbol{X}, a \right) =\sum_{v=1}^V{\frac{\left| \boldsymbol{X}^v \right|}{\left| \boldsymbol{X} \right|}Gini\left( \boldsymbol{X}^v \right)}
Gini_index(X,a)=v=1��V?�OX�O�OXv�O?Gini(Xv)
���л���ֵ
G
i
n
i
(
X
v
)
=
��
k
=
1
�O
Y
�O
��
k
��
��
k
p
k
p
k
��
=
1
?
��
k
=
1
�O
Y
�O
p
k
2
Gini\left( \boldsymbol{X}^v \right) =\sum_{k=1}^{\left| \mathcal{Y} \right|}{\sum_{k'\ne k}{p_kp_{k'}}}=1-\sum_{k=1}^{\left| \mathcal{Y} \right|}{p_{k}^{2}}
Gini(Xv)=k=1���OY�O?k����?=k��?pk?pk��?=1?k=1���OY�O?pk2?
3 🌲Pythonʵ��ID3�������㷨
3.1 🍉�ܹ����
��Ҫ��Ϊ����ģ��:����������ģ��������������ģ��,���ڽ�����ѧϰ�㷨���ͻ��Ʒ���,����ά����
Ϊʵ�־���������ģ��,����Ԥ����һ����ģ������ƽӿ�,��������һ��������,ʵ������ӿڱ�̡�
���еĽڵ��ٶ���һ��������װ��
# ���ڵ�
class TreeNode:...
# ��
class Tree(ABC):...
# ������
class PlotTree(ABC):...
# �������ڵ�
class DTreeNode(TreeNode):...
# ������
class DT(Tree):...
# ���ƾ�����
class PlotDT(PlotTree):...
3.2 🍉��Ϣ������Ϣ�������
������Ϣ��
'''
* @breif: �������������Ϣ��
* @param[in]: data -> ������, required: ���һ��Ϊ��ǩ��
* @retval: ��Ϣ��
'''
def __getEntory(self, data: DataFrame) -> float:
ent, label = 0, data.iloc[:, -1]
for i in list(label.value_counts().index):
pk = label.value_counts()[i] / label.index.size
ent = ent - pk * np.log2(pk)
return ent
������Ϣ����
'''
* @breif: ID3��������������Ϣ����
* @param[in]: data -> ������, required: ���һ��Ϊ��ǩ��
* @param[in]: A -> �����������ȡ����ֵ�ֵ�
* @retval: ���Ż�������, �������������ɢ��λ��(�������������������)
'''
def getAttrByInfoGain(self, data: DataFrame, A: dict):
# ��Ϣ����, ���Ż�������, �������������ɢ��λ��
gainInfo, bestA, bestIndex = -9999, None, None
for attr, attrValDict in A.items():
tempGainInfo = self.__getEntory(data)
# ������ɢ����
if not attrValDict['isContinuous']:
for attrVal in attrValDict['val']:
subSet = self.__getSubsetByAttr(attr, attrVal, data)
tempGainInfo = tempGainInfo - self.__getEntory(
subSet) * subSet.index.size / data.index.size
# ������������
else:...
if tempGainInfo > gainInfo:
gainInfo = tempGainInfo
bestA = attr
bestIndex = tempBestIndex if attrValDict[
'isContinuous'] else None
return bestA, bestIndex
Ϊ����չʾ������,δ�����������Ե������
3.3 🍉���ɾ�����
�������ݼ�:
���,ɫ��,����,����,����,�겿,����,�ܶ�,������,�ù�
1,����,����,����,����,����,Ӳ��,0.697,0.46,��
2,�ں�,����,����,����,����,Ӳ��,0.774,0.376,��
3,�ں�,����,����,����,����,Ӳ��,0.634,0.264,��
4,����,����,����,����,����,Ӳ��,0.608,0.318,��
5,dz��,����,����,����,����,Ӳ��,0.556,0.215,��
6,����,����,����,����,��,��ճ,0.403,0.237,��
7,�ں�,����,����,�Ժ�,��,��ճ,0.481,0.149,��
8,�ں�,����,����,����,��,Ӳ��,0.437,0.211,��
9,�ں�,����,����,�Ժ�,��,Ӳ��,0.666,0.091,��
10,����,Ӳͦ,���,����,ƽ̹,��ճ,0.243,0.267,��
11,dz��,Ӳͦ,���,ģ��,ƽ̹,Ӳ��,0.245,0.057,��
12,dz��,����,����,ģ��,ƽ̹,��ճ,0.343,0.099,��
13,����,����,����,�Ժ�,����,Ӳ��,0.639,0.161,��
14,dz��,����,����,�Ժ�,����,Ӳ��,0.657,0.198,��
15,�ں�,����,����,����,��,��ճ,0.36,0.37,��
16,dz��,����,����,ģ��,ƽ̹,Ӳ��,0.593,0.042,��
17,����,����,����,�Ժ�,��,Ӳ��,0.719,0.103,��
�涨�������ݼ���dataFrame��ʽ��ȡ,�������ɾ������Ľӿ�:
'''
* @breif: ���ɾ�����
* @param[in]: data -> �������ݼ�����, required: ���һ��Ϊ��ǩ��
* @param[in]: A -> �����������ȡ����ֵ�ֵ�
* @param[in]: depth -> ���ɽڵ�����
* @param[in]: func -> �������Ի��ֺ���
* @param[in]: parent -> ���ڵ����
* @retval: ����������
'''
def generateTree(self, data: DataFrame, A: dict,
depth: int, func, parent=None):
����func�Ǻ���ָ��,��ʱ������Ϣ������㺯�����ɡ�
���յ�һ�ڵ��㷨����һ����ʵ��:
���ɽڵ�:
# ���ɽڵ�
root = DTreeNode()
root.parent = parent
root.depth = depth
�ݹ鷵������
# ����ȫ����ͬһ���C,��ǰ�ڵ���ΪC��Ҷ�ڵ�
if data.iloc[:, -1].nunique() == 1:
return root
# A = ?,��ǰ�ڵ���Ϊ������������Ҷ�ڵ�
if len(A) == 0:
return root
������Ż������Բ��ݹ�����
# ������Ż�������
root.a, root.isContinuous = func(data, A)
# �������Ż������ԵĿ�ȡ����ֵ
if not root.isContinuous:
for a in A[root.a]['val']:
# ���ȡֵΪa�������Ӽ�
subData = self.__getSubsetByAttr(root.a, a, data)
if subData.empty:
child = self.__setChildLeafNode(root, root.label, a)
else:
_A = A.copy()
_A.pop(root.a) # �Ƴ�������
child = self.generateTree(subData, _A, root.depth + 1, func, parent=root)
child.aVal = a
root.child.append(child)
����Ϊ�˲����ڻ���,��û���������ԵĴ���ճ������,��ʵ������Ҫ�ֿ�������
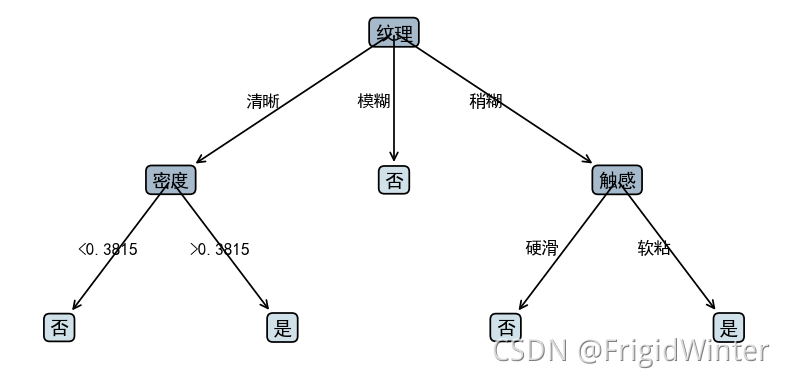
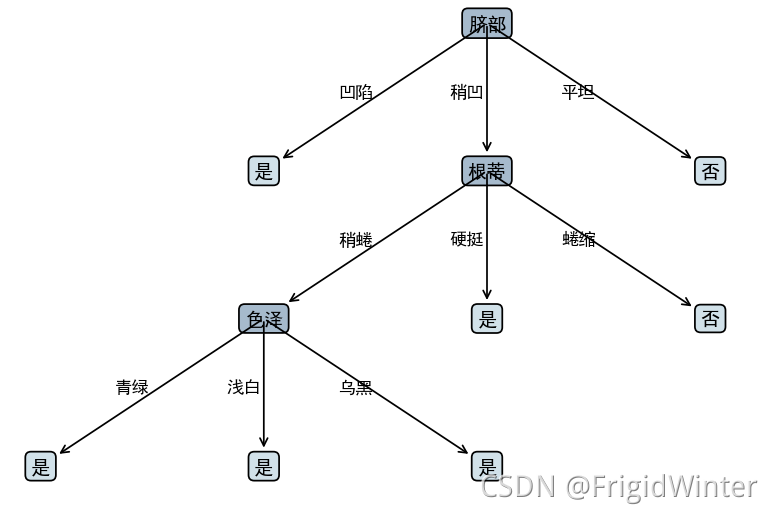
3.4 🍉���������ӻ�
���������ӻ������ܼ�,���ﲻ��,ֱ�ӿ�����,��������ע�͡�
class PlotDT(PlotTree):
def __init__(self, hide=False, graphSize=10) -> None:
super().__init__(hide=hide, graphSize=graphSize)
'''
* @breif: ���ƾ�����
* @param[in]: tree -> ���������ڵ�
* @retval: None
'''
def plotTree(self, tree):
tree.pos = (0, self.graphSize - 1) # ָ�����ڵ�λ��
self.creatPlot(tree)
plt.show()
'''
* @breif: ������������ͼ
* @param[in]: tree -> ���������ڵ�
* @retval: None
'''
def creatPlot(self, tree):
deltaX, deltaY = 3, 4 # ��ͼʱ�ڵ��X, Yƫ����
if tree.child:
num = len(tree.child)
# ָ���ӽڵ���ʼλ��
startPos = (tree.pos[0] - num // 2 * deltaX,
tree.pos[1] - deltaY) if num % 2 == 1 else (
tree.pos[0] - (num // 2 - 0.5) * deltaX,
tree.pos[1] - deltaY)
self.__poltNode(tree, tree.a, self.branchNodeStyle)
for i in range(num):
tree.child[i].pos = (startPos[0] + i * deltaX, startPos[1])
self.creatPlot(tree.child[i])
else:
self.__poltNode(tree, tree.label, self.leafNodeStyle)
'''
* @breif: ���ƾ������ڵ�
* @param[in]: node -> �ڵ����
* @param[in]: nodeText -> �ڵ��ı�
* @param[in]: nodeType -> �ڵ�����
* @retval: None
'''
def __poltNode(self, node, nodeText, nodeType) -> None:
if node.parent:
self.plotNode(nodeText, node.pos, node.parent.pos, nodeType)
midPos = ((node.parent.pos[0] + node.pos[0]) / 2 - 0.5,
(node.parent.pos[1] + node.pos[1]) / 2)
self.plotText(midPos, node.aVal)
else:
self.plotNode(nodeText, node.pos, node.pos, nodeType)
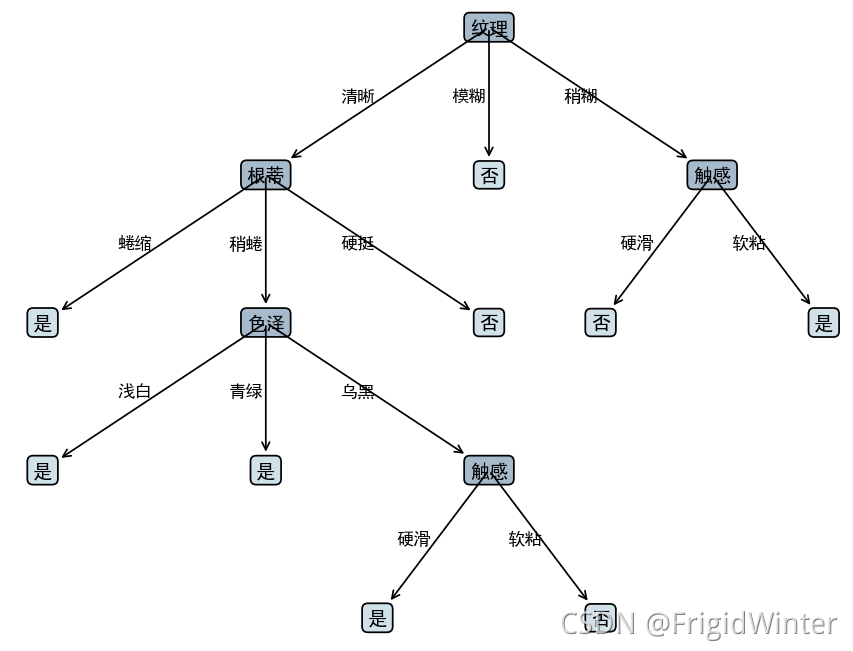
3.5 🍉��������֦
������ѧϰ�㷨�����ײ������������,����Ϊ���ijߴ�����ҷ�֧���ࡣ��ͬ�������Ի�����Ծ������������ܵ�Ӱ��ʮ������,����֦(pruning)�IJ��Ժͳ̶ȶԷ�ֹ����ϡ����Ʒ������ܵ������൱������
��������֦�㷨��Ҫ��ΪԤ��֦(prepruning)�����֦(postpruning)��ǰ�����ھ��������ɹ�����,����ÿ�����ǰ�ȹ��Ƶ�ǰ���Ļ����ܷ�������������,��������ֹͣ���ֲ�����ǰ�����ΪҶ���;�������ȴ�ѵ��������һ�������ľ�����,Ȼ���Ե����ϱ�����֧�ڵ�,�о��ܷ�������������,�������÷�֧�ڵ���ΪҶ�ڵ㡣
���㷨ʵ������Ҫ��Ϊ����:��֧�ڵ��������жϼ�֦��������֧�ڵ㰴�������,��dz���ΪԤ��֦,��֮Ϊ���֦���жϼ�֦���ܼ�������֤�����жϾ���,��֦�������ͱ�����֦���,������
'''
* @breif: ��������֦
* @param[in]: validData -> ��֤��, required: ���һ��Ϊ��ǩ��
* @param[in]: ptype -> ��֦���� post:���֦ pre:Ԥ��֦
* @retval: None
'''
def pruning(self, validData: DataFrame, ptype="post") -> None:
assert ptype in ('post', 'pre')
_tree = copy.deepcopy(self.tree)
branchNodeDict = {i: i.depth for i in self.getBranchNode(_tree)}
if ptype == "post":
branchNodeDict = sorted(branchNodeDict.items(), key=lambda x: x[1], reverse=True)
elif ptype == "pre":
branchNodeDict = sorted(branchNodeDict.items(), key=lambda x: x[1], reverse=False)
for _node, depth in branchNodeDict:
# ��֦ǰ��Ԥ��ȷ��
acc = self.calPredictAcc(validData, self.tree)
# ����ڵ���Ӵ�����֦
temp = _node.child
_node.child = []
# ��֦���Ԥ��ȷ��
postacc = self.calPredictAcc(validData, _tree)
if postacc > acc:
del self.tree
self.tree = copy.deepcopy(_tree)
else:
_node.child = temp
��֦ǰ
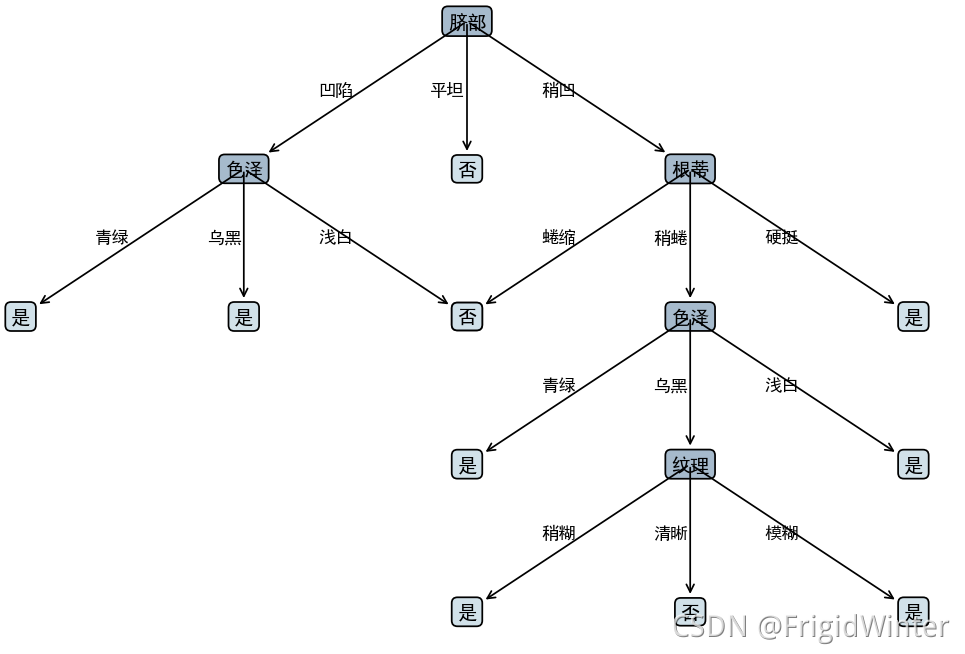
��֦��