1.���ݽṹ���㷨�Ĺ�ϵ
- ����data�ṹ��һ���о���֯���ݷ�ʽ��ѧ��,
- ����=���ݽṹ+�㷨
- ���ݽṹ���㷨�Ļ���
2.���Խṹ�ͷ����Խṹ
2.1���Խṹ
- ���Խṹ��Ϊ��õ����ݽṹ,���ص�������Ԫ��֮�����һ��һ�����Թ�ϵ��
- ���Խṹ�����ֲ�ͬ�Ĵ洢�ṹ,��˳��洢�ṹ(����)����ʽ�洢�ṹ(����)��˳��洢�����Ա���Ϊ˳���,˳����еĴ洢Ԫ���������ġ�
- ��ʽ�洢�����Թ�ϵ��Ϊ����,�����еĴ洢Ԫ�ز�һ������,
- ���Խṹ��������:����,����,������ջ��
2.2����������
��������������:��ά����,��ά����,�����,���ṹ,ͼ�ṹ��
3,ϡ������Ͷ���
��Ϊ��ά����ĺܶ�ֵ��Ĭ��ֵ0,����һ��ֵ������ʱ,����ʹ��ϡ�����顣
ϡ������Ĵ���������:
- ��¼����һ���м��м���,�ж��ٲ�ͬ��ֵ
- �Ѿ��в�֮ͬ��Ԫ�ص����м�ֵ��¼��һ��С��ģ��������,�Ӷ���С����Ĺ�ģ
ϡ������ľ���˵��:
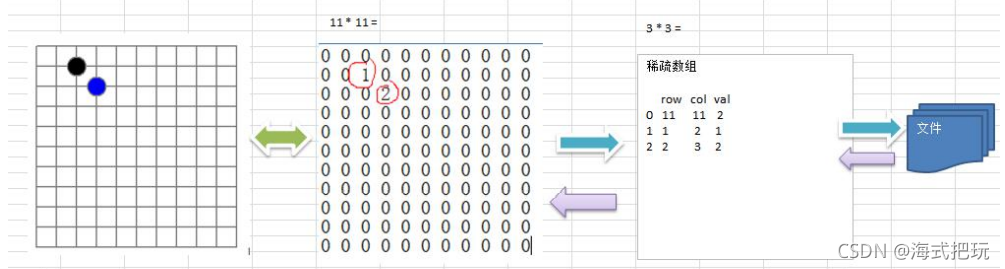
��ά����ת�� ϡ������˼·:
- ����ԭʼ�Ķ�ά����,�õ���Ч���ݵĸ���sum
- ����sum�Ϳ��Դ���ϡ������
- ����ά�����е�ֵ����ϡ������
����:
1.�ȱ�����ά����,��ȡ��ά�����з�0���ݵĸ���
int sum=0;
//��������Ϊa[][]
//X��ʾ����,Y��ʶ����
for(int i=0;i<X;i++){
for(int j=0;j<Y;j++){
if (a[i][j]!=0){
sum++;
}
}
}
2.������Ӧ��ϡ������
//int[sum+1][3]-->[3]��һ�б�ʾ��ά���������,�ڶ��б�ʾ��ά���������,�����б�ʾ���������
int sparseArr[][]=new int[sum+1][3];
sparseArr[0][0]=X;
sparseArr[0][1]=Y;
sparseArr[0][3]=sum;
//������ά����,����0��ֵ����spareArr��
int count=0;
//��¼�ǵڼ�����0����
for(int i=0;i<X;i++){
for(int j=0;j<Y;j++){
if(a[i][j]!=0){
count++;
sparseArr[count][0]=i;
sparseArr[count][1]=j;
sparseArr[count][3]=a[i][j];
}
}
}
ϡ������ת�� ��ά����˼·:
- �ȶ�ȡϡ�������һ��,���ݵ�һ�е����ݴ�����ά���顣
- �ٶ�ȡϡ��������е�����,����ֵ����ά���顣
����:
//1.��������b��Ŷ�ά����
int b[][]=new int[sparseArr[0][0]][sparse[0][1]];
//2.�ڶ�ȡϡ�������ļ�������(�ӵڶ��п�ʼ),����ֵ��ԭ��ά���鼴��
for(int i=1;i<sparseArr.length;i++){
b[sparseArr[i][0]][sparseArr[i][1]]=sparseArr[i][2];
}
4.����
4.1�����
- ������һ�������б�,�������������������ʵ�֡�
- ��ѭ�����ȳ���ԭ��:�ȴ�����е�����,Ҫ��ȡ��������������Ҫ��ȡ����
4.2.1����ģ��Զ���˼·
- ���б����������б�,��ʹ������Ľṹ���洢���е�����,�������maxSize�Ǹö��е����������
- ��Ϊ���е����,�����Ƿֱ��ǰ���������,�����Ҫ��������front ��rear�ֱ��¼����ǰ��˵��±�,front����������������ı�,��rear������������������ı�,
- �����ǽ����ݴ������ʱ��Ϊ��addQueue��,addQueue�Ĵ�����Ҫ����������:˼·����
- ��βָ��������:rear+1,��front==rear ��
- ��βָ��rearС�ڶ��е�����±�maxSize-1,�����ݴ���rear��ָ������Ԫ����,�������������ݡ���rear==maxSize-1 ������
����:
(������ģ��)
class ArrayQueue{
private int maxSize;//��ʾ������������
private int front;//����ͷ
private int rear;//����β
private int[] arr;//���������ڴ������,ģ�����
//�������еĹ�����
public ArrayQueue(int arrMaxSize){
maxSize=arrMaxSize;
arr=new int[maxSize];
front=-1;//ָ�����ͷ��,������front��ָ�����ͷ��ǰһ��λ��
rear=-1;//ָ�����β,ָ�����β,ָ�����β������(���һ������)
}
//�ж϶����Ƿ���
public boolean isFull(){
return rear==maxSize-1;
}
//�ж϶����Ƿ�Ϊ��
public boolean isEmpty(){
return rear==front;
}
//�������ݵ�����
public void addQueue(int n){
//�ж϶����Ƿ���
if(isFull()){
System.out.println("������,���ܼ�������");
return;
}
rear++;//��rear����
arr[rear]=n;
}
//��ȡ���е�����,������
public int getQueue(){
if(isEmpty()){
//ͨ���׳��쳣
throw new RuntimeException("���п�,����ȡ����");
}
front++;//front����
return arr[front];
}
//��ʾ���е���������
public void showQueue(){
//����
if(isEmpty()){
System.out.println("���пյ�,û������!!");
return;
}
//���
for(int i=0;i<arr.length;i++){
System.out.printf("arr[%d]=%d\n",i,arr[i]);
}
}
//��ʾ���е�ͷ����,ע�ⲻ��ȡ������
public int headQueue(){
//�ж�
if(isEmpty()){
throw new RuntimeException("���пյ�,û������!!");
}
return arr[front+1];
}
}
#ȱ��:
������ֻ��ʹ��һ��,û�дﵽ����Ч����
4.2.2����ģ��Ի��ζ���˼·
��4.2.1�е�����ģ����е��Ż�,�����������,��˽����鿴����һ�����εġ�(ͨ��ȡģ�ķ�����ʵ��)
����˵��:
- β��������һ��Ϊͷ����ʱ��ʾ������,�������������ճ�һ����ΪԼ��,��������ж϶�������ʱ����Ҫע��(rear+1)%maxSize==front ������
- rear=front ��ա�
˼·:
- front�����ĺ�����һ������:front��ָ����еĵ�һ��Ԫ��,Ҳ����˵arr[front]���Ƕ��еĵ�һ��Ԫ��front�ij�ʼֵ=0;
- rear�����ĺ�����һ������:rearָ����е����һ��Ԫ�صĺ�һ��λ��,��Ϊϣ���ճ�һ���ռ���ΪԼ��,rear�ij�ʼֵ=0;
- ��������ʱ,������(rear+1)%maxSize=front ��
- �Զ���Ϊ�յ�����,rear==front ��
- ��������������,��������Ч�����ݵĸ��� (rear+maxSize-front)%maxSize //rear=1;front=0
����:
(������ģ��)
class CircleArray{
private int maxSize;//��ʾ������������
private int front;//ָ����еĵ�һ��Ԫ��,Ҳ����˵arr[front]���Ƕ��еĵ�һ��Ԫ��,
//front�ij�ʼֵ=0
private int rear;//����β
//rear�����ĺ���:rearָ����е����һ��Ԫ�صĺ�һ��λ��,��Ϊϣ���ճ�һ���ռ���ΪԼ����
//rear�ij�ʼֵ=0
private int[] arr;//���������ڴ������,ģ�����
//�������еĹ�����
public CircleArray(int arrMaxSize){
maxSize=arrMaxSize;
arr=new int[maxSize];
}
//�ж϶����Ƿ���
public boolean isFull(){
return (rear+1)%maxSize==front;
}
//�ж϶����Ƿ�Ϊ��
public boolean isEmpty(){
return rear==front;
}
//�������ݵ�����
public void addQueue(int n){
//�ж϶����Ƿ���
if(isFull()){
System.out.println("������,���ܼ�������");
return;
}
//ֱ�ӽ����ݼ���
arr[rear]=n;
//��rear����,(����ȡģ)
rear=(rear+1)%maxSize;
}
//��ȡ���е�����,������
public int getQueue(){
if(isEmpty()){
//ͨ���׳��쳣
throw new RuntimeException("���п�,����ȡ����");
}
//1.�Ȱ�front��Ӧ��ֵ������һ����ʱ����
//2.��front����,����ȡģ
//3.����ʱ��������
int value=arr[front];
front=(front+1)%maxSize;
return value;
}
//��ʾ���е���������
public void showQueue(){
//����
if(isEmpty()){
System.out.println("���пյ�,û������!!");
return;
}
//���
for(int i=0;i<front+size();i++){
System.out.printf("arr[%d]=%d\n",i%maxSize,arr[i%maxSize]);
}
}
//�����ǰ������Ч���ݵĸ���
public int size(){
return (rear-front+maxSize)%maxSize;
}
//��ʾ���е�ͷ����,ע�ⲻ��ȡ������
public int headQueue(){
//�ж�
if(isEmpty()){
throw new RuntimeException("���пյ�,û������!!");
}
return arr[front];
}
}
5.����
5.1��������
������������б�,�����ڴ��еĴ洢��ͼ:
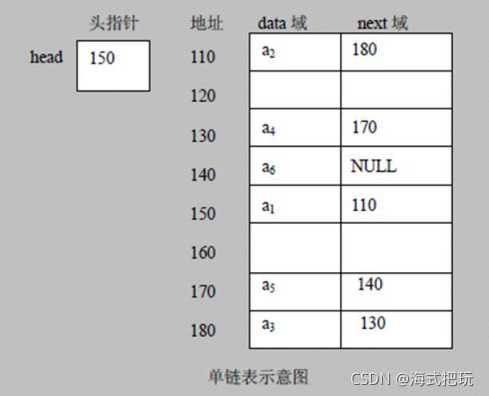
- �������Խڵ�ķ�ʽ���洢
- ÿ���ڵ����data��,next��:ָ����һ���ڵ�
- �����ĸ����ڵ㲻һ���������洢
- ������Ϊ��ͷ����������û�д�ͷ��������
5.2��������Ӧ��
ʹ�ô�headͷ���ĵ����������(ˮ�Ӣ��)����ɾ�IJ����
5.2.1����ڵ�
//����HeroNode,ÿ��HeroNode�������һ���ڵ�
class HreoNode{
public int no;
public String name;
public String nickname;
public HeroNode next;//ָ����һ�ڵ�
//������
public HreoNode(int no,String name,String nickname){
this.no=no;
this.name=name;
this.nickname=nickname;
}
//��дtoString����
public String toString(){
return "HeroNode[no="+no+",name="+name+",nickname="+nickname+]";
}
}
5.2.2����ͷ�ڵ�
//����SingleLinkedList����Ӣ��
calss SingleLinkedList{
//�ȳ�ʼ��һ��ͷ���,ͷ�ڵ㲻Ҫ��,����ž��������
private HeroNode head=new HreoNode(0,"","");
}
5.2.3���ӽڵ�
5.2.3.1�����������
//����SingleLinkedList����Ӣ��
calss SingleLinkedList{
//�ȳ�ʼ��һ��ͷ���,ͷ�ڵ㲻Ҫ��,����ž��������
private HeroNode head=new HreoNode(0,"","");
//5.2.3.1�����������
//˼·:1,�ҵ���ǰ���������һ���ڵ㡣2,�����һ���ڵ��nextָ���µĽڵ�
public void add(HeroNode heronode){
//��Ϊhead�ڵ㲻�ܶ�,���������Ҫһ����������temp
HeroNode temp=head;
//��������,
while(true){
//�ҵ����������
if(temp.next==null){
break;
}
//���û���ҵ�
temp=temp.next;
}
//���Ƴ�whileѭ��ʱ,temp��ָ�������������
//���������ڵ��nextָ���µĽڵ�
temp.next=hreroNode;
}
}
5.2.3.2���뵽ָ��λ��
//����SingleLinkedList����Ӣ��
calss SingleLinkedList{
//�ȳ�ʼ��һ��ͷ���,ͷ�ڵ㲻Ҫ��,����ž��������
private HeroNode head=new HreoNode(0,"","");
//5.2.3.2���뵽ָ��λ��
//˼·:1,�ҵ���ǰ���������һ���ڵ㡣2,�����һ���ڵ��nextָ���µĽڵ�
public void add(HeroNode heronode){
//��Ϊhead�ڵ㲻�ܶ�,���������Ҫһ����������temp
HeroNode temp=head;
boolean flag=false;//flag��־��ʾ���ӵı���Ƿ����,Ĭ��Ϊfalse
//��������,
while(true){
//�ҵ����������
if(temp.next==null){
break;
}
if(temp.next.no>heroNode.no){
//λ���ҵ�,����temp�ĺ������
break;
}else if(temp.next.no==hreoNode.no){
//˵��ϣ�����ӵı���Ѿ�����
flag=true;//˵����Ŵ���
break;
}
//���û���ҵ�
temp=temp.next;
}
//�ж�flag��ֵ
if(flag){
System.out.printf("��������");
}else{
//���뵽������temp�ڵ�ĺ���
heroNode.next=temp.next;
temp.next=heroNode;
}
}
}
5.2.3�Ľڵ�
//����SingleLinkedList����Ӣ��calss SingleLinkedList{ //�ȳ�ʼ��һ��ͷ���,ͷ�ڵ㲻Ҫ��,����ž�������� private HeroNode head=new HreoNode(0,"",""); //�Ľڵ����Ϣ,����no�������, 1.����newHeroNode��no���ļ��� public void update(HeroNode newHeroNode){ //�ж��Ƿ�Ϊ�� if(head.next==null){ System.out.println("����Ϊ��"); return; } //���帨������temp�ҵ���Ҫ�ĵĽڵ� HeroNode temp=head.next; boolean flag=false; while(true){ if(temp==null){ break;//�Ѿ����������� } if(temp.no==newHeroNode.no){ flag=true; break; } temp=temp.next; } //����flag�ж��Ƿ��ҵ�Ҫ�ĵĽڵ� if(flag){ temp.name=newHeroNode.name; temp.nickname=newHeroNode.nickname; }else{ System.out.println("û���ҵ�"); } }}
5.2.5ɾ���ڵ�
//����SingleLinkedList����Ӣ��calss SingleLinkedList{ //�ȳ�ʼ��һ��ͷ���,ͷ�ڵ㲻Ҫ��,����ž�������� private HeroNode head=new HreoNode(0,"",""); //ɾ���ڵ� //˼· /* 1.head���ܶ�,�����Ҫһ��temp�����ڵ��ҵ���ɾ������ǰһ����� 2.��temp.next.no��Ҫɾ���ڵ��no�Ƚ� */ public void del(int no){ HeroNode temp=head; boolean flag=false; while(true){ if(temp.next==null){ break; } if(temp.next.no=no){ flag=true; break; } temp=temp.next; } if(flag){ temp.next=temp.next.next; }else{ System.out.println("û���ҵ�"); } }}
5.2.6��ʾ����
//����SingleLinkedList����Ӣ��calss SingleLinkedList{ //�ȳ�ʼ��һ��ͷ���,ͷ�ڵ㲻Ҫ��,����ž�������� private HeroNode head=new HreoNode(0,"",""); //5.2.6��ʾ���� public void list(){ //�ж������Ƿ�Ϊ�� if(head.next==null){ return; } //��Ϊͷ�ڵ㲻�ܶ�,���������Ҫһ�������ڵ���� HeroNode temp=head.next; while(true){ if(temp==null){ break; } System.out.println(temp); temp=temp.next; } }}
5.3������Ӧ�ð���
5.3.1����������Ч�ڵ����
public static int getLength(HeroNode head){ if(head.next==null){ return 0; } int length=0; HeroNode temp=head.next; while(temp!=null){ length++; temp=temp.next; } return length;}
5.3.2���ҵ������е�����k��Ԫ��
˼·:
- ��д����,����head�ڵ�,ͬʱ����һ��index
- index��ʾ���ǵ����ڼ����ڵ�
- �Ȱ�������ͷ��β����,�õ������ij��� getLength()
- �õ�size��,��������һ���ڵ����(size-index)
public static HeroNode findLastIndexNode(HeroNode head,int index){ if(head.next==null){ return null; } //�����õ��������� int size=getLength(head); //�õ�size��,��������һ���ڵ����(size-index) if(index<=0||index>size){ return null; } //xunhuan HeroNode temp=head.next; for(int i=0;i<size-index;i++){ temp=temp.next; } return temp;}
5.3.3�������ķ�ת
˼·:
- �ȶ���һ���ڵ� reverseHead=new HeroNode();
- ��ͷ��β����,ȥ�����һ���ڵ���뵽��ǰ��
- ԭ��������head.next=rexerseHead.next
//�������ķ�תpublic static void reverseList(HeroNode head){ //�����ǰ����Ϊ�ջ�ֻ��һ���ڵ�,ֱ�ӷ��� if(head.next==null||head.next.next==null){ return; } //���� HeroNode temp=head.next; HeroNode next=null;//ָ��ǰ�ڵ����һ�ڵ� HeroNode reverseHead=new HeroNode(0,"",""); //��ͷ��β����,ȥ�����һ���ڵ���뵽��ǰ�� while(temp!=null){ next=temp.next;//���ڵ����һ�ڵ� temp.next=reverseHead.next;//��temp����һ�ڵ�ָ������������ǰ�� reverseHead.next==temp;//���ӵ������� temp=next;//���� }}
ȱ��:
- ��������,���ҵķ���ֻ����һ������,
- ��������������ɾ��,��Ҫ����������
5.4˫������Ӧ�ð���
5.4.1����һ��˫����������
//����HeroNode,ÿ��HeroNode�������һ���ڵ�class HreoNode{ public int no; public String name; public String nickname; public HeroNode next;//ָ����һ�ڵ� public HreoNode pre; //������ public HreoNode(int no,String name,String nickname){ this.no=no; this.name=name; this.nickname=nickname; } //��дtoString���� public String toString(){ return "HeroNode[no="+no+",name="+name+",nickname="+nickname+]"; }}
5.4.2�����������
//����SingleLinkedList����Ӣ��calss SingleLinkedList{ //�ȳ�ʼ��һ��ͷ���,ͷ�ڵ㲻Ҫ��,����ž�������� private HeroNode head=new HreoNode(0,"",""); //5.4.2����������β�� //˼·:1,�ҵ���ǰ���������һ���ڵ㡣2,temp.next=newHeroNode;newHeroNode.pre=temp. public void add(HeroNode heronode){ //��Ϊhead�ڵ㲻�ܶ�,���������Ҫһ����������temp HeroNode temp=head; //��������, while(true){ //�ҵ���������� if(temp.next==null){ break; } //���û���ҵ� temp=temp.next; } //���Ƴ�whileѭ��ʱ,temp��ָ������������� //���������ڵ��nextָ���µĽڵ� temp.next=hreroNode; heroNode.pre=temp; }}
5.4.3�Ľڵ�
//����SingleLinkedList����Ӣ��calss SingleLinkedList{ //�ȳ�ʼ��һ��ͷ���,ͷ�ڵ㲻Ҫ��,����ž�������� private HeroNode head=new HreoNode(0,"",""); //�Ľڵ����Ϣ,����no�������, 1.����newHeroNode��no���ļ��� public void update(HeroNode newHeroNode){ //�ж��Ƿ�Ϊ�� if(head.next==null){ System.out.println("����Ϊ��"); return; } //���帨������temp�ҵ���Ҫ�ĵĽڵ� HeroNode temp=head.next; boolean flag=false; while(true){ if(temp==null){ break;//�Ѿ����������� } if(temp.no==newHeroNode.no){ flag=true; break; } temp=temp.next; } //����flag�ж��Ƿ��ҵ�Ҫ�ĵĽڵ� if(flag){ temp.name=newHeroNode.name; temp.nickname=newHeroNode.nickname; }else{ System.out.println("û���ҵ�"); } }}
5.4.4ɾ���ڵ�
//����SingleLinkedList����Ӣ��calss SingleLinkedList{ //�ȳ�ʼ��һ��ͷ���,ͷ�ڵ㲻Ҫ��,����ž�������� private HeroNode head=new HreoNode(0,"",""); //ɾ���ڵ� //˼· /* 1.ֱ���ҵ�Ҫɾ���ڵ� 2.����ɾ�� */ public void del(int no){ if(head.next==null){ return; } HeroNode temp=head.next; boolean flag=false; while(true){ if(temp==null){ break; } if(temp.no=no){ flag=true; break; } temp=temp.next; } if(flag){ temp.pre.next=temp.next; //��ֹ��ָ���쳣 if(temp.next!=null){ temp.next.pre=temp.pre; } }else{ System.out.println("û���ҵ�"); } }}
5.4.5��ʾ����
//����SingleLinkedList����Ӣ��calss SingleLinkedList{ //�ȳ�ʼ��һ��ͷ���,ͷ�ڵ㲻Ҫ��,����ž�������� private HeroNode head=new HreoNode(0,"",""); //5.2.6��ʾ���� public void list(){ //�ж������Ƿ�Ϊ�� if(head.next==null){ return; } //��Ϊͷ�ڵ㲻�ܶ�,���������Ҫһ�������ڵ���� HeroNode temp=head.next; while(true){ if(temp==null){ break; } System.out.println(temp); temp=temp.next; } }}
5.5����������
5.5.1���
? ���ε���������ͨ����������һ��,Ψһ��ͬ�ľ�����ͨ�����������һ���ڵ��nextΪ��,�����ε����������һ���ڵ��nextΪͷ�ڵ�,�γ�һ���ջ���
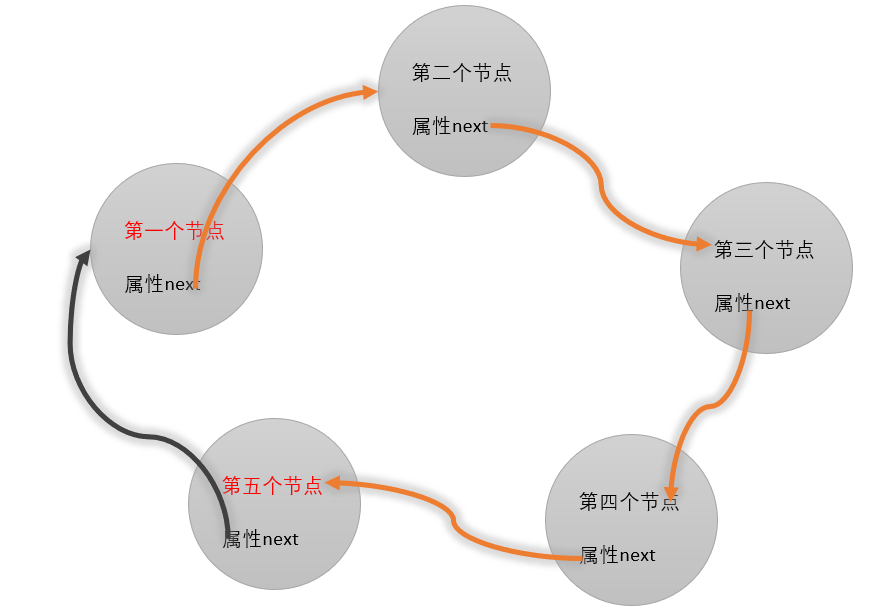
5.5.2�����ڵ����
/*�ڵ����*/ class Node { private int no; private Node next; public Node(int no) { this.no = no; } public int getNo() { return no; } public void setNo(int no) { this.no = no; } public Node getNext() { return next; } public void setNext(Node next) { this.next = next; } @Override public String toString() { return "Node{" + "no=" + no + '}'; } }
5.5.3������������
/*����������*/ class CircleSingleLinkedList { private Node first = null; }
5.4.4�ж��Ƿ�Ϊ��
/*�Ƿ�Ϊ�յķ���*/ public boolean isEmpty() { return first == null; }
5.4.5���ӽڵ㵽β��
/*����һ���ڵ㵽β���ķ���*/ public boolean addNode(Node node) { /*���ͷΪ��,��ô�ͽ�ͷ��ֵ,���ҽ�ͷ��nextָ���Լ�,�ﵽ���ε�Ч��*/ if (isEmpty()) { first = node; first.setNext(first); return true; } /*�����ڵ�*/ Node tmp = first; while (true) { /*�����ǰ�ڵ��nextΪͷ�ڵ�,��ô˵��������β���ڵ��ˡ�*/ if (tmp.getNext() == first) { /*��ô��ǰ�ڵ��next�͵������������ӵĽڵ�*/ tmp.setNext(node); /*��Ȼ�����ӵĽڵ����������,��ô�����ӵĽڵ��next����ͷ�ڵ�*/ node.setNext(first); return true; } /**/ tmp = tmp.getNext(); } }
- �����ǰ����Ϊ��,��ôֱ�Ӱ�node��ֵ������������ͷ�ڵ㡣
- ����ͱ���,Ȼ����������һ�������������ǵ�ǰ�ڵ����һ���ڵ����ͷ�ڵ�,��ô��˵����ǰ�ڵ�������һ���ڵ��ˡ�
- Ȼ���ҵ����һ���ڵ��,���һ���ڵ��next�������ǵ�ǰ����Ľڵ�,��Ҫע����ǵ�ǰ����Ľڵ��nextҪΪͷ�ڵ㡣
ע��:
? ���������β���������ͼ���ڵ��β���ڵ��next��������ͨ��������һ�¡���ΪҪ�γɱջ�,��ôβ���ڵ��nextһ��ҪΪfirst,����ͱղ��ˡ�
6.ջ
6.1ջ�Ľ���
- ջ��һ���������������б���
- ջ���������Ա���Ԫ�صIJ����ɾ��ֻ�������Ա���ͬһ�˽��е�һ���������Ա������������ɾ����һ��,Ϊ�仯��һ��,��Ϊջ��(Top ),��һ��Ϊ�̶���һ��,��Ϊջ��(Bottom ).
6.2ջ��Ӧ�ó���
- �ӳ���ĵ���:�������ӳ���ǰ,���Ƚ��¸�ָ��ĵ�ַ��ŵ���ջ��,ֱ���ӳ���ִ������ٽ���ַȡ��,�Իص�ԭ���ij����С�
- �����ݹ����:���ӳ���ĵ�������,ֻ�dz��˴洢��һ��ָ��ĵ�ַ��,Ҳ������,������������ݴ����ջ�С�
- ����ʽ��ת��
- �������ı���
- ͼ�ε���������㷨
6.3ջ�Ŀ�������
6.3.1������ģ��ջ
˼·:
- ʹ������ģ��ջ
- ����һ��top����ʾջ��,��ʼ��Ϊ-1
- ��ջ�IJ���:�������ݼ��뵽ջʱ,top++;stack[top]=data;
- ��ջ�IJ���,int value=stack[top];top�C;return value;
6.3.1.1����ջ����
//����һ��ArrayStack��ʾջclass ArrayStack{ private int maxSize;//ջ�Ĵ�С private int[] stack;// ģ��ջ private int top =-1;//��ʾջ��,��ʼ��Ϊ-1 //������ public ArrayStack(int maxSize){ this.maxSize=maxSize; stack=new int[this.maxSize]; } //ջ�� public boolean isFull(){ return top==maxSize-1; } //ջ�� public boolean isEmpy(){ return top=-1; } // ��ջ public void push(int value){ if(isFull()){ System.out.println("ջ��"); return; } top++; stack[top]=value; } //��ջ public void pop(){ if(isEmpty()){ throw new RuntimeException("ջ��"); } int value=stack[top]; top--; return value; } //��ʾջ����� public void list(){ if(isEmpty()){ System.out.println("ջ��"); return; } //��ջ����ʾ for(int i=top;i>=0;i--){ System.out.printf("stack[%d]=%d\n",i,stack[i]); } }}
6.3 ջʵ���ۺϼ�����(������ʽ)
��ջ��ʵ���ۺϼ�����-
? 7x2x2-5+1-5+3-4=?
˼·:
- ͨ��һ��indexֵ(����),����������ʽ
- ���������һ������,��ֱ����ջ
- �������ɨ�赽����һ������,�ͷ����
- ������ֵ�ǰ�ķ���ջΪ��,��ֱ����ջ
- �����ǰ����ջ�з���,�ͽ��бȽ�,�����ǰ�����������ȼ�С�ڻ����ջ�еIJ�����,����Ҫ����ջ��pop��������,�ӷ���ջ��popһ��������,��������,���ѹ����ջ,Ȼ��ǰ������push����ջ,�����ǰ�IJ����������ȼ�����ջ�еIJ�����,��ֱ�������ջ��
- ������ʽɨ�����,��˳��Ĵ���ջ�ͷ���ջpop���ݽ�������
- �������ջ��ֻ��һ������,���DZ���ʽ�Ľ��
public calss Calculator{ public static void main(String[] args){ //����ǰ����ʦ˼·,��ɱ���ʽ String exception="7x2x2-5+1-5+3-4"; //��������ջ,��ջ,����ջ ArrayStack numStack=new ArrayStack(10); ArrayStack operStack=new ArrayStack(10); //������ر��� int index=0;//����ɨ�� int num1=0; int num2=0; int oper=0; int res=0; char ch='';//��ÿ��ɨ�赽��char���浽ch String keepNum="";//����ƴ�Ӷ�λ�� //��ʼѭ��ɨ��expression while(rrue){ //���εõ�expression��ÿ���ַ� ch=expression.substring(index,index+1).charAt(0); // �ж�ch��ʲĪ,����Ӧ���� if(operStack.isOper(ch)){ //����� //�жϵ�ǰ�ķ���ջ�Ƿ�Ϊ�� if(!operStack.isEmpty()){ //�����ǰ�����������ȼ�С�ڻ����ջ�еIJ�����,����Ҫ����ջ��pop��������,�ӷ���ջ��popһ��������,��������, if(operStack.priority(ch)<=operStack.priority(operStack.peek())){ num1=numStack.pop(); num2=numStack.pop(); oper=operStack.pop(); res=numStack.cal(num1,num2,oper); //�����ջ numStack.push(res); //ѹ�뵱ǰ����� operStack.push(ch); }else{ //�����ǰ�IJ����������ȼ�����ջ�еIJ�����,��ֱ�������ջ�� operStack.push(ch); } }else{ //���Ϊ��ֱ�������ջ operStack.push(ch); } }else{ //�������,��ֱ������ջ /* ����˼·: 1��������λ��ʱ,���ܷ�����һ����������ջ,�����Ƕ�λ�� 2.��Ҫ��expression�ı���ʽindex��һλ��,��������ͽ���ɨ��,����ֱ����ջ 3.����keepNum ����ƴ���ַ��� */ keepNum+=ch; //���ch�Ѿ���expression�����һλ,��ֱ����ջ if(index==expression.length()-1){ numStack.push(Integer.parseInt(keepNum)); }else{ //�ж���һ�ַ��Dz�������,���������,�ͼ���ɨ��,����������,��ֱ����վ if(operStack.isOper(expression.substring(index+1,index+2).charAt(0))){ //�����һλ������� numStack.push(Integer.parseInt(keepNum)); //ÿ�����keepNum keepNum=""; } } } //��index+1,���ж��Ƿ�ɨ�赽expression��� index++; if(index>=expression.length()){ break; } } //��ɨ�����,��˳�����ջ�ͷ���ջpop����Ӧ����ͷ��� while(true){ //�������ջΪ��,��ջֻ��һ����� if(operStack.isEmpty()){ break; } num1=numStack.pop(); num3=numStack.pop(); oper=operStack.pop(); res=numStack.cal(num1,num2,oper); //�����ջ numStack.push(res); } int res2=numStack.pop(); System.out.printf("%s=%d",expression,res2); }}//����ջ(�ο�6.3.1.1����ջ����)//��������������ȼ�public int priority(int oper){ if(oper=='x'||oper=='/'){ return 1; }else if(oper=='+'||oper=='-'){ return 0; }else{ return -1; }}//�ж��Dz��ǿ�һ�������public boolean iaOper(char val){ return val=='+'||val=='-'||val=='x'||val=='/';} //���㷽��public int cal(int num1,int num2,int oper){ int res=0;//������� switch(oper){ case '+': res=num1+num2; break; case '-': res=num2-num1; break; case 'x': res=num1xnum2; break; case '-': res=num2/num1; break; default: break; } return res;}
6.4�沨��������
�������һ���沨��������,Ҫ�������������:
- ����һ���沨������ʽ(������ʽ),ʹ��ջ,��������
- ֧�����źͶ�λ������
˼·:
����:(30+4)x5-6��Ӧ�ĺ�����ʽ����30 4 +5 x 6 -,��ְ��������:
- ��������ɨ��,��30,4 ѹ���ջ
- ����+�����,��˵���30,4,���������,�����ѹ����ջ
- ��5��ջ
- ��������x�����,����5,7,���������,�����ѹ����ջ
- ��6��ջ
- �����-�����,���������,�����ѹ����ջ
����:
������->������ʽ����ArrayList��
public class PolandNotation{ public static void main(String[] args){ //�ȶ����沨������ʽ //(30+4)x5-6��Ӧ�ĺ�����ʽ����30 4 +5 x 6 -, String suffixExpression="30 4 +5 x 6 -"; //������ʽ����ArrayList�� List<String> list=getListString(suffixExpression); System.out.println("renList="+list); int res=calcuate(list); System.out.println("���"+res); }
�ָ��ַ���
//�ָ��ַ��� //��һ���沨������ʽ���ν����ݺ����������ArrayList�� public static List<String> getListString(String suffixExpression){ //��suffixExpression�ֿ� String[] split=suffixExpression.split(" "); List<String> list=new ArrayList<String>(); for(String ele:split){ list.add(ele); } return list; }
�沨������ʽ������
public static int calculate(List<String> ls){ //����ջ Stack<String> stack=new Stack<String>(); //����ls for(String item:ls){ if(item.matches("\\d+")){ stack.push(item); }else{ int num2=Integer.parseInt(stack.pop()); int num1=Integer.parseInt(stack.pop()); int res=0; if(item.equals("+")){ res=num1+num2; }else if(item.equals("-")){ res=num1-num2; }else if(item.equals("x")){ res=num1xnum2; }else if(item.equals("/")){ res=num1/num2; }else{ throw new RuntimeException("���������"); } stack.push(""+res); } return Integer.parseInt(stack.pop()); }}
}
6.5������ʽת��Ϊ������ʽ
? ��ҿ���,������ʽ�ʺϼ���ʽ��������,������ȴ��̫����д����,�����DZ���ʽ�ܳ��������,����ڿ��� ��,������Ҫ�� ������ʽת�ɺ�����ʽ��
���岽������:
-
��ʼ������ջ:�����ջ s1 �ʹ����м�����ջ s2;
-
��������ɨ��������ʽ;
-
����������ʱ,����ѹ s2;
-
���������ʱ,�Ƚ����� s1 ջ������������ȼ�:
1.��� s1 Ϊ��,��ջ�������Ϊ�����š�(��,��ֱ�ӽ����������ջ;
2.����,�����ȼ���ջ��������ĸ�,Ҳ�������ѹ�� s1;
3.����,�� s1 ջ���������������ѹ�뵽 s2 ��,�ٴ�ת��(4-1)�� s1 ���µ�ջ���������Ƚ�;
-
��������ʱ:
-
����������š�(��,��ֱ��ѹ�� s1
2.����������š�)��,�����ε��� s1 ջ���������,��ѹ�� s2,ֱ���� ��������Ϊֹ,��ʱ����һ�����Ŷ���
-
-
�ظ����� 2 �� 5,ֱ������ʽ�����ұ�
-
�� s1 ��ʣ�����������ε�����ѹ�� s2
-
���ε��� s2 �е�Ԫ�ز����,���������Ϊ������ʽ��Ӧ�ĺ�����ʽ
����:
//��������ʽת��Ϊ������ʽ public static List<String> parseSuffixExpressionList(List<String> ls){ //����ջ Stack<String> s1=new Stack<String>();//����ջ //������� List<String> s2=new ArrayList<String>();//���� //����ls for(String item:ls){ if(item.matches("\\d+")){ s2.add(item); }else if(item.equals("(")){ s1.push(item); }else if(item.equals(")")){ //����������š�)��,�����ε���s1ջ���������,��ѹ��s2,��ѹ�� s2,ֱ���� ��������Ϊֹ,��ʱ����һ�����Ŷ��� while(!s1.peek().equals("(")){ s2.add(s1.pop()); } s1.pop();//���������� }else{ //��item�����ȼ�С�ڵ���s1ջ�������,�� s1 ջ���������������ѹ�뵽 s2 ��,�ٴ�ת��(4-1)�� s1 ���µ�ջ���������Ƚ�; while(s1.size()!=0&&Operation.getValue(s1.peek())>=Operation.getValue(item)){ s2.add(s1.pop()); } s1.push(item); } } //��s1��ʣ�����������μ���s2 while(s1.size()!=0){ s2.add(s1.pop()); } return s2;}
���ض�Ӧ�����ȼ�����
class Operation{ private static int ADD=1; private static int SUB=1; private static int MUL=2; private static int DIV=2; public static int getValue(String operation){ int result=0; switch(operation){ case "+": result=ADD; break; case "-": result=SUB; break; case "*": result=MUL; break; case "/": result=DIV; break; default: break; } return result; }}
�沨��������������
package com.atguigu.reversepolishcal;import java.util.ArrayList;import java.util.Collections;import java.util.List;import java.util.Stack;import java.util.regex.Pattern;public class ReversePolishMultiCalc { /** * ƥ�� + - * / ( ) ����� */ static final String SYMBOL = "\\+|-|\\*|/|\\(|\\)"; static final String LEFT = "("; static final String RIGHT = ")"; static final String ADD = "+"; static final String MINUS= "-"; static final String TIMES = "*"; static final String DIVISION = "/"; /** * �Ӝp + - */ static final int LEVEL_01 = 1; /** * �˳� * / */ static final int LEVEL_02 = 2; /** * ���� */ static final int LEVEL_HIGH = Integer.MAX_VALUE; static Stack<String> stack = new Stack<>(); static List<String> data = Collections.synchronizedList(new ArrayList<String>()); /** * ȥ�����пհ� * @param s * @return */ public static String replaceAllBlank(String s ){ // \\s+ ƥ���κοհ��ַ�,�����ո��Ʊ�������ҳ���ȵ�, �ȼ���[ \f\n\r\t\v] return s.replaceAll("\\s+",""); } /** * �ж��Dz������� int double long float * @param s * @return */ public static boolean isNumber(String s){ Pattern pattern = Pattern.compile("^[-\\+]?[.\\d]*$"); return pattern.matcher(s).matches(); } /** * �ж��Dz�������� * @param s * @return */ public static boolean isSymbol(String s){ return s.matches(SYMBOL); } /** * ƥ������ȼ� * @param s * @return */ public static int calcLevel(String s){ if("+".equals(s) || "-".equals(s)){ return LEVEL_01; } else if("*".equals(s) || "/".equals(s)){ return LEVEL_02; } return LEVEL_HIGH; } /** * ƥ�� * @param s * @throws Exception */ public static List<String> doMatch (String s) throws Exception{ if(s == null || "".equals(s.trim())) throw new RuntimeException("data is empty"); if(!isNumber(s.charAt(0)+"")) throw new RuntimeException("data illeagle,start not with a number"); s = replaceAllBlank(s); String each; int start = 0; for (int i = 0; i < s.length(); i++) { if(isSymbol(s.charAt(i)+"")){ each = s.charAt(i)+""; //ջΪ��,(������,���� ���������ȼ�����ջ�����ȼ� && ���������ȼ�����( )�����ȼ� ���� ) ����ֱ����ջ if(stack.isEmpty() || LEFT.equals(each) || ((calcLevel(each) > calcLevel(stack.peek())) && calcLevel(each) < LEVEL_HIGH)){ stack.push(each); }else if( !stack.isEmpty() && calcLevel(each) <= calcLevel(stack.peek())){ //ջ�ǿ�,���������ȼ�С�ڵ���ջ�����ȼ�ʱ��ջ����,ֱ��ջΪ��,����������(,����������ջ while (!stack.isEmpty() && calcLevel(each) <= calcLevel(stack.peek()) ){ if(calcLevel(stack.peek()) == LEVEL_HIGH){ break; } data.add(stack.pop()); } stack.push(each); }else if(RIGHT.equals(each)){ // ) ������,���γ�ջ����ֱ����ջ���������˵�һ��)������,��ʱ)��ջ while (!stack.isEmpty() && LEVEL_HIGH >= calcLevel(stack.peek())){ if(LEVEL_HIGH == calcLevel(stack.peek())){ stack.pop(); break; } data.add(stack.pop()); } } start = i ; //ǰһ���������λ�� }else if( i == s.length()-1 || isSymbol(s.charAt(i+1)+"") ){ each = start == 0 ? s.substring(start,i+1) : s.substring(start+1,i+1); if(isNumber(each)) { data.add(each); continue; } throw new RuntimeException("data not match number"); } } //���ջ�ﻹ��Ԫ��,��ʱԪ����Ҫ���γ�ջ����,��������ջ��ʣ��ջ��Ϊ/,ջ��Ϊ+,Ӧ�����γ�ջ����,����ֱ�ӷ�ת����stack ���ӵ����� Collections.reverse(stack); data.addAll(new ArrayList<>(stack)); System.out.println(data); return data; } /** * ������ * @param list * @return */ public static Double doCalc(List<String> list){ Double d = 0d; if(list == null || list.isEmpty()){ return null; } if (list.size() == 1){ System.out.println(list); d = Double.valueOf(list.get(0)); return d; } ArrayList<String> list1 = new ArrayList<>(); for (int i = 0; i < list.size(); i++) { list1.add(list.get(i)); if(isSymbol(list.get(i))){ Double d1 = doTheMath(list.get(i - 2), list.get(i - 1), list.get(i)); list1.remove(i); list1.remove(i-1); list1.set(i-2,d1+""); list1.addAll(list.subList(i+1,list.size())); break; } } doCalc(list1); return d; } /** * ���� * @param s1 * @param s2 * @param symbol * @return */ public static Double doTheMath(String s1,String s2,String symbol){ Double result ; switch (symbol){ case ADD : result = Double.valueOf(s1) + Double.valueOf(s2); break; case MINUS : result = Double.valueOf(s1) - Double.valueOf(s2); break; case TIMES : result = Double.valueOf(s1) * Double.valueOf(s2); break; case DIVISION : result = Double.valueOf(s1) / Double.valueOf(s2); break; default : result = null; } return result; } public static void main(String[] args) { //String math = "9+(3-1)*3+10/2"; String math = "12.8 + (2 - 3.55)*4+10/5.0"; try { doCalc(doMatch(math)); } catch (Exception e) { e.printStackTrace(); } }}
7.�ݹ�
7.1�ݹ�ĸ���
? �ݹ���Ƿ����Լ������Լ�,ÿ�ε���ʱ���벻ͬ��ֵ,�ݹ������ڱ���߽�����ӵ�����,ͬʱ�����ô�������
7.2�ݹ������ѭ����
- ִ��һ������ʱ,�ʹ���һ���µ��ܱ����Ķ����ռ�(ջ�ռ�)��
- �����ľֲ������Ƕ�����,�����Ӱ�졣
- ���������ʹ�õ����������ͱ���(��������),�ͻṲ�����������͵����ݡ�
- �ݹ�������Ƴ��ݹ�������ƽ�,����ͻ����ݹ顣
- ��һ������ִ�����,��������return,�ͻ᷵��,����˭����,�ͽ�������ظ�˭,ͬʱ������ִ����ϻ��߷���ʱ,�÷���Ҳ��ִ�����
����:
�׳�����
//�׳�����public static int factorial(int){ if(n==1){ return 1; }else{ return facrorial(n-1)*n; }}
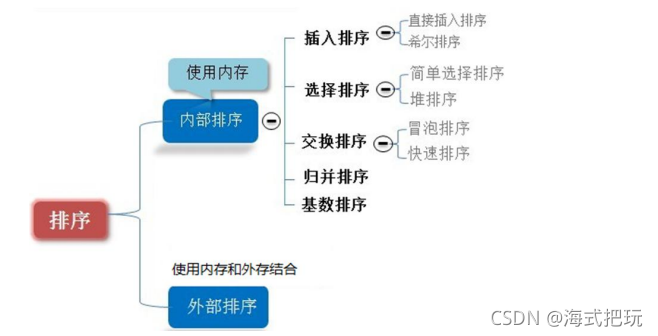
8.�����㷨
8.1�����㷨�Ľ���
����Ҳ�������㷨,�����ǽ�һ������,��ָ����˳��������еĹ��̡�
8.2����ķ���
? 1.�ڲ�����
? ָ����Ҫ�������������ݶ����ص��ڲ��洢��(�ڴ�)�н�������
? 2.�ⲿ����
? ����������,��ȫ�����ص��ڴ��� ,��Ҫ�����ⲿ�洢(�ļ���)��������
? 3.�����������㷨����:
? 
8.3�㷨ʱ�临�Ӷ�
8.3.1����һ������ִ��ʱ��ķ���
? 1.�º�ͳ��
? ���ַ�������,������������:һ��Ҫ�����Ƶ��㷨���������ܽ�������,��Ҫʵ�����иó���;��������ʱ���ͳ���������ڼ������Ӳ��,�����Ȼ�������,���ַ�ʽ,Ҫ��ͬһ̨���������ͬ��״̬������,���ܱȽ��Ǹ����еĿ졣(����ʵ)
? 2.��ǰ����ķ���
? ͨ������ij���㷨��ʱ�临�Ӷ����ж��ĸ��㷨���š�
8.3.2ʱ��Ƶ��
��������:
? ʱ��Ƶ��:һ���㷨���ѵ�ʱ�����㷨������ִ�д�����������,�Ǹ��㷨�����ִ�еĴ�����,������ʱ��Ͷࡣһ���㷨�е����ִ�еĴ�����Ϊ���Ƶ�Ȼ�ʱ��Ƶ����
8.3.3ʱ�临�Ӷ�
? 1.һ�������,�㷨�еĻ������������ظ�ִ�д����������ģn��ij������,��T(n)��ʾ,����ij������ָ��f(n),ʹ�õ�n���������ʱ,T(n)/f(n)�ļ���ֵΪ��������ij���,���f(n)��T(n)��ͬ����������������T(n)=O(f(n)),��O(f(n))Ϊ�㷨�Ľ���ʱ�临�Ӷ�,���ʱ�临�Ӷȡ�
? 2.T(n)��ͬ,��ʱ�临�Ӷȿ�����ͬ����:T(n)=n2+7n+1��T(n)=3*n2+9n ���ǵ�ʱ�临�Ӷȶ�ΪO(n^2)��
? 3.����ʱ�临�Ӷȵķ���
- �ó���1��������ʱ�������мӷ�����
- �ĺ�����д���������,ֻ������߽���
- ȥ����߽����ϵ��
8.3.4ƽ��ʱ�临�ӶȺ����ʱ�临�Ӷ�
-
ƽ��ʱ�临�Ӷ���ָ���п��ܵ�����ʵ�����Եȸ��ʳ��ֵ������,���㷨������ʱ�䡣
-
�����µ�ʱ�临�Ӷȳ�Ϊ�ʱ�临�Ӷȡ�һ�����۵�ʱ�临�ӶȾ�Ϊ�ʱ�临�Ӷ�����������ԭ����:�����µ�ʱ�临�Ӷ����㷨���κ�����ʵ��������ʱ��Ľ���,��֤����ȴ�ʱ�������
-
ƽ��ʱ�临�ӶȺ��ʱ�临�Ӷ��Ƿ�һ��:
| �Ƿ�ԭ������ | �Ƿ��ȶ� | ���,�,ƽ��ʱ�临�Ӷ� | �ռ临�Ӷ� | �Ƿ���ڱȽ� | |
|---|---|---|---|---|---|
| ���� | �� | �� | O(n)�� O(n^2)�� O(n^2) | O(1) | �� |
| �������� | �� | �� | O(n)�� O(n^2)�� O(n^2) | O(1) | �� |
| ѡ������ | �� | �� | O(n^2)�� O(n2)��O(n2) | O(1) | �� |
| ϣ������ | �� | �� | O(n)��O(n2)��O(n1.3) | O(1) | �� |
| �������� | �� | �� | O(nlogn)��O(n^2)��O(nlogn) | O(logn)~O(n) | �� |
| �鲢���� | �� | �� | O(nlogn)��O(nlogn)��O(nlogn) | O(n) | �� |
| �������� | �� | �� | O(n+k)��O(n+k)��O(n+k),k �����ݷ�Χ | O(n+k) | �� |
| Ͱ���� | �� | �� | O(n)��O(n)��O(n) | O(N+M),N��ʾ�������ݸ���,M��ʾͰ���� | �� |
| �������� | �� | �� | O(nk)��O(nk)��O(n*k),k ���� | O(n+k) | �� |
| ������ | �� | �� | O(nlogn)��O(nlogn)��O(nlogn) | O(1) | �� |
8.4�㷨�Ŀռ临�Ӷ�
8.4.1��������
- ������ʱ�临�Ӷȵ�����,һ���㷨�Ŀռ临�Ӷȶ���Ϊ���㷨�����ĵĴ洢�ռ�,��Ҳ�������ģn�ĺ���
- �ռ临�Ӷ��Ƕ�һ���㷨�����й�������ʱռ�ݴ洢�ռ�Ĵ�С������
- �����㷨����ʱ,��Ҫ���۵���ʱ�临�Ӷȡ����û������Ͽ�,�������е��dz���ִ�е��ٶȡ�һЩ�����Ʒ���㷨���ʾ����ÿռ任ʱ����
8.5����
8.5.1��������
? ð������Ļ���˼����:ͨ���Դ��������д�ǰ���(���±��С��Ԫ�ؿ�ʼ),���αȽ����ڵ�Ԫ�ص�ֵ,������������,ʹֵ�ϴ��Ԫ����ǰ�����
�Ż�:
? ��Ϊ����Ĺ�����,��Ԫ�ز��Ͻӽ��Լ���λ��,**���һ�˱Ƚ�����û�н��н���,��˵����������,**���Ҫ���������������һ����־flag�ж�Ԫ���Ƿ���й��������Ӷ����ٲ���Ҫ�ıȽϡ�
����:

����:
public static void bubbleSort(int[] arr){ int temp=0;//����������н��� boolean flag=false;//��ʾ����,�ж��Ƿ���н��� for(int i=0;i<arr.length()-1;i++){ for(int j=0;j<arr.length()-1-i;j++){//���iλ������õ�,�����ٴ����� if(arr[j]>arr[j+1]){ flag=true; temp=arr[j]; arr[j]=arr[j+1]; arr[j+1]=temp; } } if(!flag){//�����������,һ�ν�����û�� break; }else{//����,�����´��ж� flag=false; } }}
8.6ѡ������
8.6.1��������
? ѡ������Ҳ�����ڲ�����,�Ǵ��������������,��ָ���Ĺ���ѡ��ijһ��Ԫ��,�����ݽ���λ�ú�ﵽ�����Ŀ�ġ�
8.6.2ѡ������˼·
? ѡ������Ҳ��һ�ּ����������Ļ���˼·��:��һ�δ�arr[0]arr[n-1]��ѡ����Сֵ,��arr[0]����,�ڶ��δ�arr[1]arr[n-1]��ѡ����Сֵ,��arr[1]����,���ܹ�ͨ��n-1�˽���,�õ�һ������С��������������������С�
8.6.3ѡ������˼·����ͼ
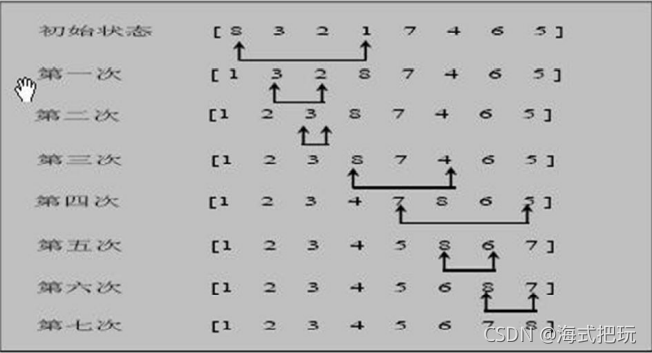
����:
public static void SelectSort(int[] arr){ for(int i=0;i<arr.length()-1;i++){ int minIndex=i; int min=arr[0]; for(int j=i+1;j<arr.length();j++){ if(min>arr[j]){ min=arr[j]; minIndex=j; } } //int min=arr[0];����Сֵ,����arr[i]��λ�� if(minIndex!=i){ arr[minIndex]=arr[i]; arr[i]=min; } }}
8.7��������
8.7.1�����������
? �������������ڲ�����,�Ƕ����������Ԫ���Բ���ķ�ʽѰ��Ԫ�ص��ʵ�λ��,�Դﵽ�����Ŀ�ġ�
8.7.2���������˼·
? ��������Ļ���˼��:��n���������Ԫ�ؿ���Ϊһ���������һ�������,��ʼʱ�����ֻ��һ��Ԫ��,���������,���������ȥһ������,�������Ԫ�ؽ��бȽ�,���������ʵ�λ��,ʹ֮��Ϊ�µ��������
8.7.3��������˼·ͼ
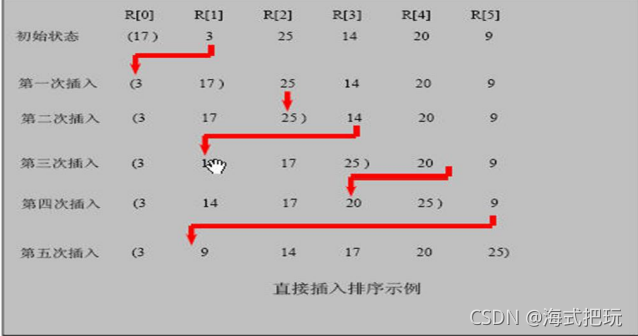
����:
public static void InsterSort(inr[] arr){ int insterVal=0;//Ԫ������ int insterIndex=0;//Ԫ�ش������±� for(int i=1;i<arr.length();i++){ //������������ insterVal=arr[i]; insterIndex=i-1;//��arr[i]��ǰ���Ԫ�ص����� //��insterVal�Ҳ���λ�� //insterIndex>=0��֤��Խ��; //insterVal<arr[insterIndex],��û���ҵ�λ�� while(insterIndex>=0&&insterVal<arr[insterIndex]){ arr[insterIndex+1]=arr[insterIndex]; //���� insterIndex--; } //���Ƴ�whileѭ��,˵�������λ���Ѿ��ҵ�,insterIndex+1; if(insterIndex+1!=i){ arr[insterIndex+1]=insterVal; } }}
8.8ϣ������
����Ҫ��������ǽ�С����ʱ,���ƵĴ�����������,��Ч����Ӱ��
8.8.1ϣ���������
? ϣ������Ҳ��һ�ֲ����㷨,���Ǽ��������㷨�����Ľ��İ汾,Ҳ��Ϊ��С��������
8.8.2ϣ������Ļ���˼��
? ϣ�������ǰѼ�¼���±��һ����������,��ÿ��ʹ��ֱ�Ӳ�������;������������,ÿ������Ĺؼ���Խ��Խ��,����������1ʱ,�����ļ�ǡ����Ϊ1��,�㷨����ֹ
8.8.3ϣ������ʾ��ͼ
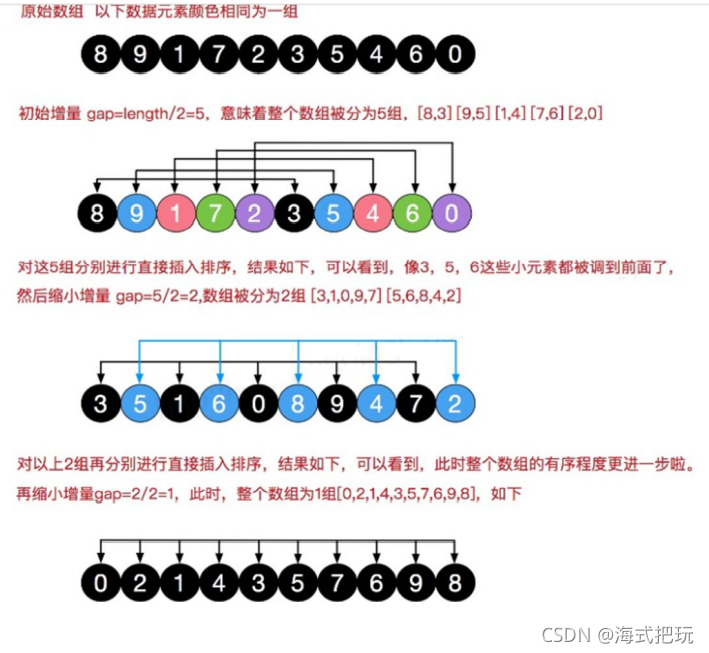
����:
//������public static void shellSort(int[] arr){ int temp=0; for(int gap=arr.length()/2;gap>0;gap/=2){ for(int i=gap;i<arr.length();i++){ //��������������Ԫ��(��gap��),����Ϊgap for(int j=i-gap;j>=0;j-=gap){ //�����ǰԪ�ش��ڼ��ϲ�����Ԫ��,˵������ if(arr[j]>arr[j+gap]){ temp=arr[j]; arr[j]=arr[j+gap]; arr[j+gap]=temp; } } } }}
//��λ��public static void shellSort(int[] arr){ //����gap,������С���� for(int gap=arr.length()/2;gap>0;gap/=2){ for(int i=gap;i<arr.length();i++){ int j=i; int temp=arr[j]; if(arr[j]<arr[j-gap]){ while(j-gap>=0&&temp<arr[j-gap]){ //�ƶ� arr[j]=arr[j-gap]; j-=gap; } arr[j]=temp; } } }}
8.9��������
8.9.1�����������
? ���������Ƕ�ð�������һ�ָĽ�������˼·:ͨ��һ������Ҫ��������ݷָ�ɶ�����������,����һ���ֵ��������ݶ�����һ���ֵ�����ҪС,Ȼ���ٰ��˷��������������ݷֱ���п�������,����������Եݹ����,�Դ˴ﵽ�������ݱ����������
8.9.2��������ʾ��ͼ
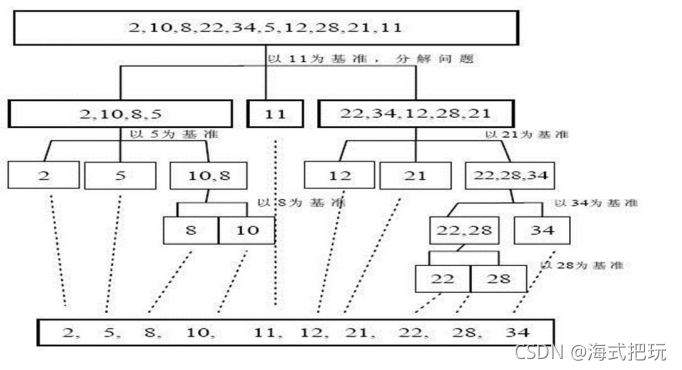
����:
public static void QuickSort(int[] arr,int left,int right){ int l=left;//���±� int r=right;//���±� int pivot=arr[(right+left)/2]; int temp=0;//��ʱ����,��Ϊ����ʹ�� //whileѭ����Ŀ�����ñ�pivotֵС�ķŵ���� while(l<r){ while(arr[l]<pivot){ l+=1; } while(arr[r]>pivot){ r-=1; } //���l=r;˵������֮��� if(l>=r){ break; } //���� temp=arr[l]; arr[l]=arr[j]; arr[j]=temp; //������������arr[l]=pivot. if(arr[l]==pivot){ r-=1; } //������������arr[r]=pivot. if(arr[r]==pivot){ l+=1; } //���l=r;����l++;r-- if(l==r){ l+=1; r-=1; } //����ݹ� if(left<r){ QuickSort(arr,left,r); } //���ҵݹ� if(right>l){ QuickSort(arr,l,right); } }}
8.10�鲢����
8.10.1�鲢�������
? �鲢���������ù鲢��˼��ʵ�ֵ�����,���㷨���þ�������β���
8.10.2�鲢����˼·ͼ
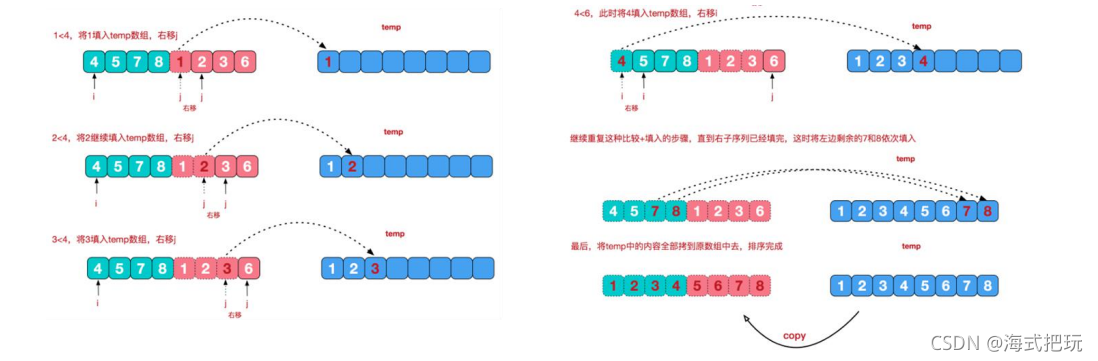
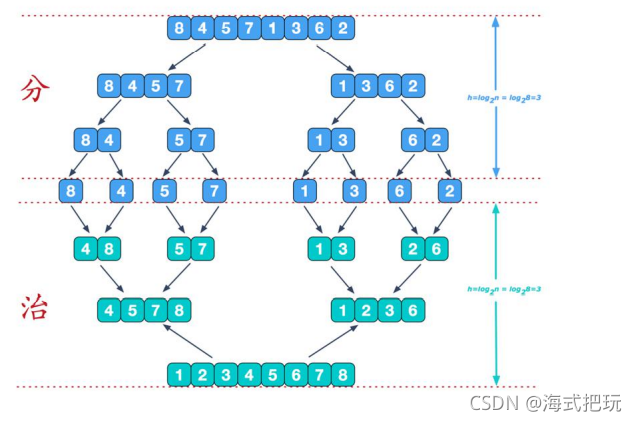
����:
//��+��public static void mergetSort(int[] arr,int left,int right,int[] temp){ if(left<right){ int mid=(left+right)/2; mergetSort(arr,left,mid,temp); mergetSort(arr,mid+1,right,temp); merge(arr,left,mid,right,temp) }}//�ϲ�����public atatic void merge(int[] arr,int left,int mid,int right,int[] temp){ int i=left;//����������г�ʼ���� int j=mid+1;//�Ҳ��������г�ʼ���� int t=0;//ָ��temp����ĵ�ǰ���� /* һ�� �Ȱ��������ߵ���������д��temp ֪����һ�ߴ������ */ while(i<=mid&&j<=right){ // if(arr[i]<=arr[j]){//��С���� temp[t]=arr[i]; t+=1; i+=1; }else{ temp[t]=arr[j]; t+=1; j+=1; } } /* �� ��ʣ��һ��ȫ������ */ while(i<=mid){//���ʣ�� temp[t]=arr[i]; t+=1; i+=1; } while(j<=right){//�Ҳ�ʣ�� temp[t]=arr[j]; t+=1; j+=1; } /* �� ��temp���鵼��arr���� */ t=0; int tempLeft=left; while(tempLeft<=right){ arr[tempLeft]=temp[t]; t+=1; tempLeft+=1; }}
8.11��������
8.11.1�����������
- �����������ڡ�����ʱ����,�ֳơ�Ͱ�ӷ�����ͨ����ֵ�ĸ���λ��ֵ,��Ҫ�����Ԫ�ط�����ij��Ͱ
- �������������ȶ�������,����������Ч�ʸ���ȶ�������
- ����������Ͱ�������չ
8.11.2�����������˼·
? �����д��������ֵͳһΪͬ�����ȵij���,����ǰ������,�ӵ�λ��ʼ,��������
����:
public static void radixSort(int[] arr){ int max=arr[0]; //����Ѱ�����ֵ for(int i=1;i<arr.length();i++){ if(arr[i]>max){ max=arr[i]; } } //�ж�������м�λ int maxLength=(max+"").length(); //����һ�ݶ�ά����,��ʾ10��Ͱ //Ϊ��ֹ��ֵʱ�������,ÿ��һά�����С��Ϊarr.length int[][] bucket=new int[10][arr.length]; //����һ��һά�����ʾÿ��Ͱ�д������ݵĸ��� int[] bucketElementCounts=new int[10]; for(int i=0,n=1;i<maxLength;i++,n*=10){ for(int j=0;j<arr.length;j++){ //ȡ��ÿλ���Ķ�Ӧλ��ֵ int digitOfElement=arr[j]/n%10; //���뵽��Ӧ��Ͱ�� bucket[digitOfElement][bucketElementCounts[digitOfElement]]=arr[j]; bucketElementCounts[digitOfElement]++;//��ֹijλ����γ��� } //�������ͨ��˳��(һά������±�����ȡ��,����ԭ����) int index=0; //����ÿ��Ͱ, for(int k=0;k<bucketElementCounts.length;k++){ //�ж�Ͳ��Ϊ�� if(bucketElementCounts[k]!=0){ for(int l=0;l<bucketElementCounts[k];l++){ arr[index++]=bucket[k][l]; } } //����,�����´����� bucketElementCounts[k]=0; } }}
8.12������
8.12.1������Ļ�������
- �����������ö��������ݽṹ����Ƶ�һ�������㷨,��������һ��ѡ������,�����,���,ƽ��ʱ�临�ӶȾ�ΪO(nlogn),��Ҳ�Dz��ȶ�����
- ���Ǿ����������ʵ���ȫ������:ÿ������ֵ�����ڻ���������Һ��ӵ�ֵ,��Ϊ��,ע��:û��Ҫ��ڵ��������к��ӵĹ�ϵ
- ÿ������ֵ��С�������Һ��ӵ�ֵ,��ΪС���ѡ�
8.12.2�������˼��
- ������������й����һ����
- ��ʱ,��������ֵ���Ǹ��ڵ�
- ������ĩβԪ�ؽ���
- Ȼ��n-1��Ԫ�����¹����һ������,����ִ��
����:
//��һ������תΪ��public void adjustHeap(int[] arr,int i,int length){ int temp=arr[i];//ȡ����ǰԪ��,������ʱ���� //2*i+1��ʾ��ǰ�ڵ�����ӽڵ� for(int k=i*2+1;k<length;k=k*2+1){ if(k+1<length&&arr[k]<arr[k+1]){//���ӽڵ�ֵС�����ӽڵ� k++;//kָ�����ӽڵ� } if(arr[k]>temp){ arr[i]=arr[k];//��ǰ�ϴ�ֵ������ǰ�ڵ� i=k;//����ѭ�� }else{ break; } } arr[i]=temp;}public void heapSort(int[] arr){ //������ for(int i=arr.length/2-1;i>=0;i--){ adjustHeap(arr,i,arr.length); } //������ĩβԪ�ؽ��� int temp=0; for(int j=arr.length-1;j>0;j--){ temp=arr[j]; arr[j]=arr[0]; arr[0]=temp; adjustHeap(arr,0,j); }}
9.�����㷨
9.1�����㷨����
��Java��,���dz��õIJ��ҷ���������:
- ˳�����
- ���ֲ��ҷ�/�۰����
- ��ֵ����
- 쳲���������
9.2˳�����
˼·����:
? ����˳�����α�������,���бȶԡ�
����:
public static void seqSearch(int[] arr,int value){ //�����Ա� for(int i=0;i<arr.length;i++){ if(arr[i]==value){ return i; } } return -1;}
9.3���ֲ��ҷ�
˼·����:
- ����ȷ��������м�λ��,mid=(left+right)/2;
- Ȼ����findVal��arr[mid]�Ƚ�
- findVal>arr[mid],���ҵݹ����
- indVal<arr[mid],����ݹ����
- indVal=arr[mid],����
- �����ݹ�
- �ҵ��ͽ����ݹ�
- �ݹ������,��δ�ҵ�,����left>right,���˳��ݹ�
����:
public static void binarySearch(int[] arr,int left,int right,int findVal){ //��left>right��δ�ҵ� if(left>right){ return -1; } //Ѱ�������м�ֵ int mid=(left+right)/2; int midVal=arr[mid]; if(findVal>midVal){ //���ҵݹ� return binarySearch(arr,mid+1,right,findVal); }else if(findVal<mindVal){ //����ݹ� return binarySearch(arr,left,mid,findVal); }else{ return mid; }}
9.4��ֵ����
˼·����:
-
��ֵ����ԭ��
? ��ֵ���������ڶ��ַ�����,��ͬ���Dz�ֵ����ÿ�δ�����Ӧ��mid�����Dz���
-
�۰�����е�����mid=(left+right)/2;
-
��ֵ���ҵ�����mid=(right-left)/(arr[right]-arr[left])*(findVal-arr[left])+left
����:
public static void insterSearch(int[] arr,int left,int right,int findVal){ //ȷ��mid����Խ�� if(left>right||findVal<arr[0]||findVal>arr[arr.length-1]){ return -1; } //��mid int mid=left+(right-left)/(arr[right]-arr[left])*(findVal-arr[left]); if(findVal>midVal){ //���ҵݹ� return binarySearch(arr,mid+1,right,findVal); }else if(findVal<mindVal){ //����ݹ� return binarySearch(arr,left,mid,findVal); }else{ return mid; }}
ע������:
- �����������ϴ�,�ؼ��ֲַ��ȽϾ��ȵIJ��ұ���˵,���ò�ֵ����,�ٶȽϿ졣
- �ؼ��ֲַ������ȵ������,�÷�����һ�����۰���Һ�
9.5쳲���������
쳲���������(Fibonacci sequence),�ֳƻƽ�ָ�����,����ѧ�������ɶࡤ쳲�����(Leonardoda Fibonacci)�����ӷ�ֳΪ���Ӷ�����,���ֳ�Ϊ���������С���
쳲���������ָ��������һ������: 0,1,1,2,3,5,8,13,21,34,55,89,144,233,377,610,987,1597,2584,4181,6765,10946,17711���� ���Ĺ�����:������дӵ� 3 �ʼ,ÿһ�����ǰ����֮�͡� ����ѧ��,쳲��������������±��Ե��Ƶķ�������:F(0)=0,F(1)=1, F(n)=F(n - 1)+F(n - 2)(n �� 2,n �� N*),��Ȼ,쳲�����������һ�����Ե������С�
˼·����:
- ����������ij������䵽 nums. length = F[k] - 1,k ��������������Сֵ,�������鳤��Ϊ15,��ô�Ͱ����������䵽 F[6] - 1 = 20,������ĩβ���ӵ�����Ԫ�ض���ԭ�������һ��Ԫ�صĸ��ơ�
- �ҵ� mid Ԫ��,���Ͻ��ж��ֱȽ�,ֱ���ҵ�Ŀ��Ԫ��Ϊֹ,��һ�����������۰���Һ�����,�����Ǽ��� mid �Ĺ�ʽ�� (low + high) / 2��Ϊ low + ( F[k-1] - 1)��
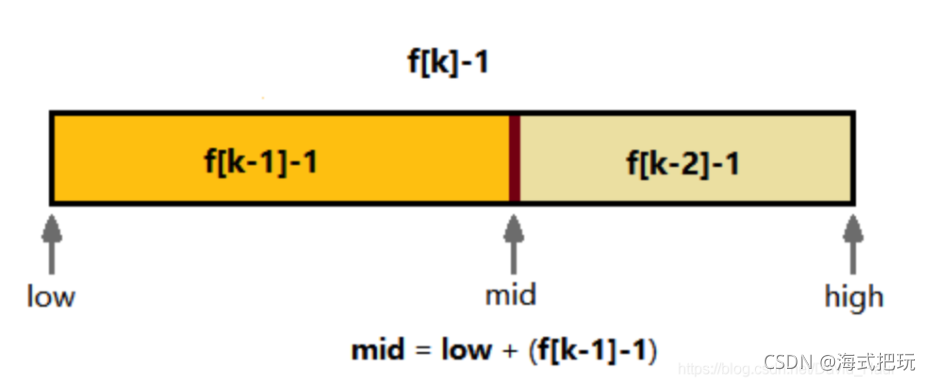
��f(k-1)-1������
Ϊʲô��Ҫ�����鳤�����䵽 F[k] - 1 ������ F[k] ���� F[k+1]?
��ʵ����Ϊ������ȷ�ݹ����midֵ,����ͼ�ɷ��� F[k]-1 = (F[k-1] + F[k-2]) - 1 = (F[k-1]-1) + 1 + (F[k-2]-1),�м��1�������Ƕ��ֵ�ê��mid,���Ŀ��������,���鳤�Ⱦ�����(F[k-1]-1),���������,���鳤�Ⱦ�����(F[k-2]-1),����͵���mid��ɲ��ҡ���(F[k-1]-1)���ܲ��(F[k-2]-1)+1+(F[k-3]-1),�����ݹ�ָ���ȥ���ܲ��ϵ���С����ֱ���ҵ�Ŀ�ꡣ
����:
//��д쳲���������public static int[] fib(){ int[] f=new int[maxsize]; f[0]=1; f[1]=1; for(int i=2;i<maxsize;i++){ f[i]=f[i-1]+f[i-2]; } return f;}//��д쳲������㷨public static void fibonacciSearch(int[] arr,int findVal){ int low=0; int high=a.length-1; int k=0;//��ʾ쳲�������ֵ�±� int mid=0; int f[]=fib();//��ȡ쳲��������� while(high>f[k]-1){//��ȡ쳲��������зָ�ֵ���±� k++; } int[] temp=Arrays.copyOf(arr,f[k]); //ʹ��arr��������������temp����λ�� for(int i=high+1;i<temp.length;i++){ temp[i]=arr[high]; } while(low <= high) { mid = low + f[k-1]-1; if(findVal < tempr[mid]) { high = mid - 1; k -= 1; }else if(findVal > tempr[mid]) { low = mid + 1; k -= 2; }else { if(mid < temp.length) { return mid; }else { return temp.length - 1; } } } return -1;}
10.���ṹ�Ļ���֪ʶ
10.1������
10.1.1Ϊʲô��Ҫ���������ݽṹ
1.����洢��ʽ�ķ���
�ŵ�:
ͨ���±귽ʽ����Ԫ��,�ٶȿ졣������������,������ʹ�ö��ֲ���������ٶ�
ȱ��:
���Ҫ��������ij��ֵ,���߲���(��һ��˳��)�������ƶ�,Ч�ʽϵ�
2.��ʽ�洢��ʽ�ķ���
�ŵ�:
��һ���̶��϶�����洢��ʽ���Ż�(����:����һ����ֵ�ڵ�,ֻ��Ҫ������ڵ�,�����������м���,ɾ��Ч��Ҳ�ܺ�)��
ȱ��:
�ڽ��м���ʱ,Ч����Ȼ�ϵ�,����Ҫ��ͷ��ʼ������
3.���洢��ʽ�ķ���
��������ݴ洢,��ȡ��Ч�ʡ�
10.1.2��ʾ��ͼ
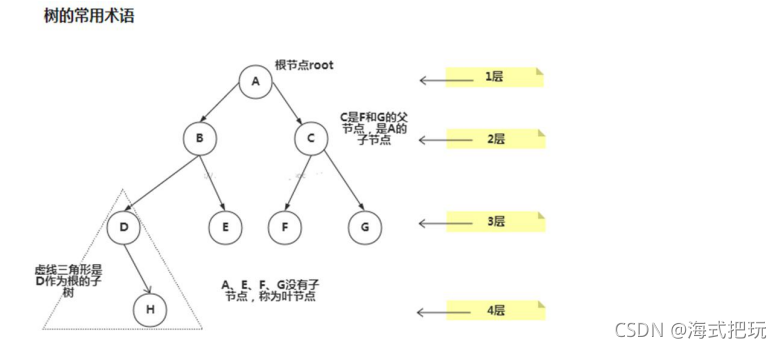
���Ķ�:һ�����������ĸ�����Ϊ�ý��Ķ�;��A���Ķ�Ϊ4,B���Ķ�Ϊ3
���Ķ�:������Ķ�������ֵΪ���Ķ�,����ͼ�����Ķ�Ϊ3,��ΪB���Ķ�Ϊ3,����������Ľ���
Ҷ�ӽ��:û����һ��������Ľ��ΪҶ�ӽ��,��E,F,C,G
��֧���:��Ҷ�ӽ��Ϊ��֧���,���������
�ڲ����:���������,��֧���Ϊ�ڲ����
10.1.3�������ĸ���
1.���кܶ���,ÿ���ӽ�����ֻ���������ڵ���һ����ʽ�Ķ�����
2.�������е��ӽڵ��Ϊ��ڵ���ҽڵ�

3.����ö�����������Ҷ�ӽڵ㶼�����һ��,���ҽڵ�����=2^n-1,nΪ����,�����dz�Ϊ����������

4.����ö�����������Ҷ�ӽڵ㶼�����һ����ߵ����ڶ���,�������һ���Ҷ�ӽڵ����������,�����ڶ����Ҷ�ӽڵ����ұ�����,���dz�Ϊ��ȫ������
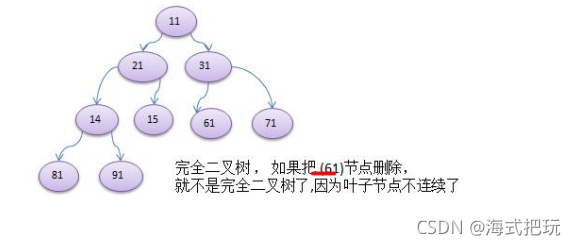
10.1.4����������˵��
? ʹ��ǰ��,����,�����Զ��������б���
- ǰ�����:��������ڵ�,�ڱ�����������������
- �������:�ȱ���������,��������ڵ�,�ڱ���������
- �������:�ȱ�����������������,��������ڵ�
����ڵ�:
class HeroNode { private int no; private String name; private HeroNode left; //Ĭ��null private HeroNode right; //Ĭ��null public HeroNode(int no, String name) { this.no = no; this.name = name; } public int getNo() { return no; } public void setNo(int no) { this.no = no; } public String getName() { return name; } public void setName(String name) { this.name = name; } public HeroNode getLeft() { return left; } public void setLeft(HeroNode left) { this.left = left; } public HeroNode getRight() { return right; } public void setRight(HeroNode right) { this.right = right; } @Override public String toString() { return "HeroNode [no=" + no + ", name=" + name + "]"; }
ǰ���������:
public static void preOrder(){ System.out.println(this); if(this.left!=null){ this.left.preOrder(); } if(this.right!=null){ this.right.preOrder(); }}
�����������:
public static void infixOrder(){ if(this.left!=null){ this.left.infixOrder(); } System.out.println(this); if(this.right!=null){ this.right.infixOrder(); }}
�����������:
public static void postOrder(){ if(this.left!=null){ this.left.postOrder(); } if(this.right!=null){ this.right.postOrder(); } System.out.println(this);}
10.1.5������-����ָ���ڵ�
? ʹ��ǰ��,����,��������ѯָ���Ľڵ�
ǰ�����˼·:
- ���жϵ�ǰ�ڵ��Dz���Ҫ��ѯ��
- ��������
- �������,���жϵ�ǰ�ڵ�����ӽڵ��Ƿ�Ϊ��,�����Ϊ��,��ݹ��ѯ
- �����ݹ��ѯ�ҵ��ڵ�ͷ���,��������ж�,��ǰ�ڵ�����ӽڵ��Ƿ�Ϊ��,�����Ϊ��,������ݹ����
�������˼·:
- �жϵ�ǰ�ڵ�����ӽڵ��Ƿ�Ϊ��,�����Ϊ��,��ݹ��������
- ����ҵ�,��,���û���ҵ�,�ͺ͵�ǰ�ڵ�Ƚ�,����Ǿͷ���,����������ӽڵ�ݹ�
- ����ҵݹ��������,�ҵ��ͷ���,����null
�������˼·:
-
�жϵ�ǰ�ڵ�����ӽڵ��Ƿ�Ϊ��,�����Ϊ��,��ݹ��������
-
����ҵ�,��,���û���ҵ�,�ͺ͵�ǰ�ڵ�����ӽڵ���бȽ�,�����Ϊ����δ�ҵ��͵ݹ�
-
�͵�ǰ�ڵ���бȽ�,�ҵ��ͷ���,����null
ǰ��������Ҵ���
public HeroNode preOrderSearch(int no){ System.out.println("ǰ�����"); if(this.no==no){//�Ƚϵ�ǰ�ڵ� return this; } //�жϵ�ǰ�ڵ�����ӽڵ��Ƿ�Ϊ��,��Ϊ�վͼ����ݹ� HeroNode resNode=null; if(this.left!=null){ resNode=this.left.preOrderSearch(no); } //�����Ϊ��,��˵���ҵ��� if(resNode!=null){ return resNode; } //���ҵݹ� if(this.right!=null){ resNode=this.right.preOrderSearch(no); } return resNode;}
����������Ҵ���
public HeroNode infixOrderSearch(int no){ System.out.println("�������"); //�жϵ�ǰ�ڵ�����ӽڵ��Ƿ�Ϊ��,��Ϊ�վͼ����ݹ� HeroNode resNode=null; if(this.left!=null){ resNode=this.left.infixOrderSearch(no); } //�����Ϊ��,��˵���ҵ��� if(resNode!=null){ return resNode; } if(this.no==no){//�Ƚϵ�ǰ�ڵ� return this; } //���ҵݹ� if(this.right!=null){ resNode=this.right.infixOrderSearch(no); } return resNode; }
����������Ҵ���
public HeroNode postOrderSearch(int no){ System.out.println("�������"); //�жϵ�ǰ�ڵ�����ӽڵ��Ƿ�Ϊ��,��Ϊ�վͼ����ݹ� HeroNode resNode=null; if(this.left!=null){ resNode=this.left.postOrderSearch(no); } //�����Ϊ��,��˵���ҵ��� if(resNode!=null){ return resNode; } //���ҵݹ� if(this.right!=null){ resNode=this.right.postOrderSearch(no); } if(resNode!=null){ return resNode; } if(this.no==no){//�Ƚϵ�ǰ�ڵ� return this; } return resNode;}
10.1.6������-ɾ���ڵ�
Ҫ��:
- ���ɾ���Ľڵ���Ҷ�ӽڵ�,��ɾ���ýڵ�
- ���Ҫɾ���Ľڵ��Ƿ�Ҷ�ӽڵ�,��ɾ��������
˼·:
- �������ֻ��һ��root�ڵ�,�ͽ��������ÿ�
- ��Ϊ�������ǵ����,������Ҫ�жϵ�ǰ�ڵ���ӽڵ��Dz�����Ҫɾ���Ľڵ�
- �����ǰ�ڵ�����ӽڵ㲻Ϊ��,�������ӽڵ������Ҫɾ���Ľڵ�,��this.left=null;
- �����ǰ�ڵ�����ӽڵ㲻Ϊ��,�������ӽڵ������Ҫɾ���Ľڵ�,��this.right=null;
- ���2&3��û��ɾ���ڵ�,����Ҫ���������ݹ�ɾ��
- �����4��Ҳû��ɾ���ڵ�,��Ӧ�����ҵݹ�ɾ��
����:
public void delNode(int no){ if(this.left!=null&&this.left.no==no){ this.left=null; return; } if(this.right!=null&&this.right.no==no){ this.right=null; return; } //ɾ�� if(this.left!=null){ this.left.delNode(no); } if(this.right!=null){ this.right.delNode(no); } }
10.2˳��洢������
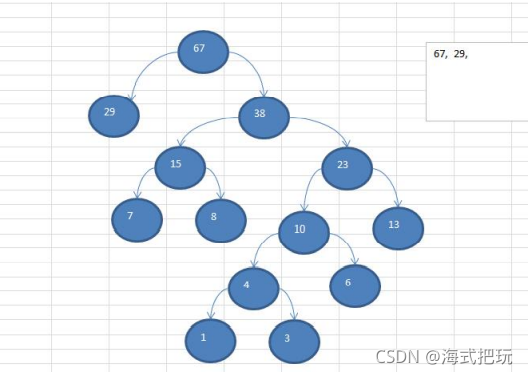
10.2.21˳��洢�������ĸ���
����˵��:
�����ݴ洢����,���ݴ洢��ʽ�����Ĵ洢��ʽ�����ת��,���������ת������,��Ҳ����ת�������顣
˳��洢�������ĵõ�:
- ˳�������ͨ��ֻ�ῼ����ȫ������
- ��n��Ԫ�ص����ӽڵ�Ϊ2*n+1
- ��n��Ԫ�ص����ӽڵ�Ϊ2*n+2
- ��n��Ԫ�صĸ��ڵ�Ϊ(n+1)/2
����:
int[] arr;public void preOrder(int index){ if(arr==null||arr.length==0){ System.out.println("������") } System.out.println(arr[index]); if((index*2+1)<arr.length){ preOrder(index*2+1); } if((index*2+2)<arr.length){ preOrder(index*2+2); }}
10.3������������
10.3.1������������������
- n���ڵ�Ķ��������к���n+1����ʽ2n-(n-1)=n+1������ָ�������ö��������Ŀ�ָ����,���ָ��ýڵ���ij�ֱ��������µ�ǰ���ͺ�ǽڵ��ָ��(���ָ��ӵ�ָ���Ϊ����)
- ���ּ��������Ķ����������ֳ�Ϊ��������,��Ӧ�Ķ�������Ϊ�����������������������ʵIJ�ͬ,�����������ɷ�Ϊǰ������������,����,����
- һ���ڵ��ǰһ���ڵ�,��Ϊǰ���ڵ�
- һ�����ĺ�һ���ڵ�,��Ϊ��̽ڵ�
˼·����:
- leftָ��������,Ҳ����ָ��ǰ���ڵ�
- rightָ��������,Ҳ����ָ���̽ڵ�
����:
����ڵ�:
class HeroNode { private int no; private String name; private HeroNode left; //Ĭ��null private HeroNode right; //Ĭ��null //���Ϊ0,��ʾ��������;���Ϊ1,��ʾǰ����̽ڵ� private int leftType; private int rightType; public HeroNode(int no, String name) { this.no = no; this.name = name; } public int getNo() { return no; } public void setNo(int no) { this.no = no; } public String getName() { return name; } public void setName(String name) { this.name = name; } public HeroNode getLeft() { return left; } public void setLeft(HeroNode left) { this.left = left; } public HeroNode getRight() { return right; } public void setRight(HeroNode right) { this.right = right; } @Override public String toString() { return "HeroNode [no=" + no + ", name=" + name + "]"; }
ʵ��������������
class ThreadedBinaryTree{ private HeroNode root; //Ϊʵ��������,��Ҫ����һ��ָ��ǰ�ڵ��ǰ���ڵ��ָ�� //�ڵݹ����������ʱ,pre���DZ�����ǰһ���ڵ� private HeroNode pre=null; public void setRoot(HeroNode root){ this.root=root; } //ʵ�������������� public void threadedNodes(HeroNode node){//node���ǵ�ǰ��Ҫ�������Ľڵ� if(node==null){ return; } //�������������� threadedNodes(node.getLeft()); //��������ǰ�ڵ� //����ǰ���ڵ� if(node.getLeft()==null){ //�õ�ǰ�ڵ����ָ��ָ��ǰ���ڵ� node.setLeft(pre); //������ node.setLeftType(1); } //������̽ڵ� if(pre!=null&&pre.getRight()==null){ pre.setRight(node); pre.setRightType(1); } pre=node; //������������ threadedNodes(node.getRight()); }}
��������������
//�������������������� public void threadeList(){ //����һ������,�洢��ǰ�ڵ�,��root��ʼ HeroNode node=root; while(node!=null){ //ѭ���ҵ�leftType==1�ڵ� while(node.getLeftType()==0){ node=node.getLeft(); } //��ӡ��ǰ�ڵ� System.out.println(node); while(node.getRightType()==1){ //�����ǰ�ڵ����ָ��ָ���̽ڵ�,��һֱ��� node=node.getRight(); System.out.println(node); } //�滻�����ڵ� node=node.getRight(); } }
ɾ���ڵ�˼·:
- ��Ϊ�������ǵ����,�����������жϵ�ǰ�ڵ���ӽڵ��Ƿ���Ҫɾ���ڵ�,������ȥ�ж�����ڵ��Dz�����Ҫɾ���ڵ�
- �����ǰ�ڵ�����ӽڵ㲻Ϊ��,�������ӽڵ����Ҫɾ���Ľڵ�,�ͽ�this.left=null;���Ҿͷ���(�����۶�ɾ��)
- �����ǰ�ڵ�����ӽڵ㲻Ϊ��,�������ӽڵ����Ҫɾ���Ľڵ�,�ͽ�this.right=null;���Ҿͷ���(�����۶�ɾ��)
- ����ݹ�ɾ��
����:
public void delNode(int no){ if(this.left!=null&&this.left.no==no){ this.left=null; return; } if(this.right!=null&&this.right.no==no){ this.right=null; return; } //�ݹ�ɾ�� if(this.left!=null){ this.left.delNode(no); } if(this.right!=null){ this.right.delNode(no); }}
10.4�շ�����
10.4.1��������
- ����n��Ȩֵ��Ϊn��Ҷ�ӽ��,����һ�Ŷ�����,�������Ĵ�Ȩ·�����ȴﵽ��С(wpl),�������Ķ�����Ϊ���Ŷ�����,Ҳ��Ϊ��������
- �շ������Ǵ�Ȩ·����̵���,Ȩֵ�ϴ�Ľڵ�����ڵ��
10.4.2�շ�����������Ҫ����;���˵��
- ·����·������: ��һ������,��һ���ڵ�����һ���ڵ���Դﵽ�ĺ��ӻ����ӽڵ�֮���ͨ·,��Ϊ·����ͨ·�з�֧����Ŀ��Ϊ·�������� ���涨�����IJ���Ϊ1,��Ӹ��ڵ㵽��L��ڵ��·������Ϊ(L-1)
- �ڵ��Ȩ�ʹ�Ȩ·������: �������нڵ㸶��һ������ij�ֺ������ֵ,�������ֵ��Ϊ�õ��Ȩ���ڵ�Ĵ�Ȩ·������Ϊ: �Ӹ��ڵ㵽�ýڵ�֮���·��������ýڵ��Ȩ�ij˻�
- ���Ĵ�Ȩ·������: ���Ĵ�Ȩ·�����ȹ涨Ϊ����Ҷ�ӽ��Ĵ�Ȩ·������֮��,
10.4.3���ɺշ������IJ���
����һ������{13,7,8,3,29,6,1},Ҫ��ת��һ�źշ�����
- ��С����������� ,��ÿһ������,ÿ�����ݶ���һ���ڵ�,ÿ���ڵ���Կ�����һ����Ķ�����
- ȡ�����ڵ�Ȩֵ��С�����ö�����
- ���һ���µĶ�����,�ö������ĸ��ڵ��Ȩֵ��ǰ���������������ڵ�Ȩֵ�ĺ�
- �ٽ�����µĶ�����,�Ը��ڵ�Ȩֵ��Ȩֵ��С�ٴ�����,�����ظ�,
��java�нӿ�comparableʹ���Ǿ���Ҫ�Ӵ�����,����Լ��ϻ��������������,���Ǿ���ʹ�õ�Arrays.sort()����Collections.sort().�������еĶ������Զ���Ķ���ʱ,���������ַ����ܹ�ʹ����Ӧ�õ��Զ������ļ���(����)�С�
����:
//�����ڵ��� //Ϊ����Node�����������Collection�������� //��Nodeʵ��Comparable�ӿ� class Node implements Comparable<Node>{ int value;//�ڵ�Ȩֵ Node left;//ֻ�����ӽڵ� Node right;//ָ�����ӽڵ� public Node(int value){ this.value=value; } @Override public String toString(){ return "NOde[value="+value+"]"; } @Override public int compareTo(Node o){ //��ʾ��С�������� return this.value-o.value; } }
//��дʵ�ֺշ������ķ��� public static Node creaHuffmanTree(int[] arr){ /* 1.����arr���� 2.��arr������ÿ��Ԫ�ع���һ��Node 3.��Node���뵽ArrayList�� */ List<Node> nodes=new ArrayList<Node>(); for(int value: arr){ node.add(new Node(value)); } //ѭ�� while(nodes.size()>1){ //���� Collection.sort(nodes); System.out.println("nodes="+nodes); /* ȥ������Ȩֵ��С�Ķ����� ��arr[0]��arr[1]; */ Node leftNode=nodes.get(0); Node rightNode=nodes.get(1); //�����µĶ����� Node parent=new Node(leftNode.value+rightNode.value); parent.left=leftNode; parent.right=rightNode; //��Array List������ɾ���������� nodes.remove(leftNode); nodes.remove(rightNode); //��parent���ӵ�Array List�� nodes.add(parent); } //���غշ������root�ڵ� return nodes.get(0); }
//ǰ����� public void preOrder(){ System.out.println(this); if(this.left!=null){ thix.left.preOrser(); } if(this.right!=null){ this.right.preOrder(); } }
10.5����������(BST)
��������:
����һ������{7,3,10,12,5,1,9},Ҫ���ܹ���Ч����ɶ����ݵIJ�ѯ������
��������:
- ʹ������
- ����δ����:,�ŵ�:ֱ��������β������,�ٶȿ졣ȱ��:��ѯ�ٶ���
- ��������:,�ŵ�:����ʹ�ö��ֲ��ҷ�,�����ٶȿ졣ȱ��:Ϊ�˱�֤��������,������������ʱ,�ҵ�����λ�ú�,�����������Ҫ�����ƶ�,�ٶ�����
- ʹ����ʽ�洢-����
- ���������Ƿ�����,��ѯ�ٶȶ���,�����ٶȱ������,����Ҫ�����ƶ���
- ʹ�ö���������
10.5.1��������������
����������:BST,���ڶ������������κ�һ����Ҷ�ӽڵ�,Ҫ�����ӽڵ��ֵ�ȵ�ǰ�ڵ��ֵС,�ҽڵ��ֵ�ȵ�ǰ�ڵ��ֵ��
**�ر�˵��:**�������ͬ��ֵ,���Խ��ýڵ�������ӽڵ�����ӽڵ�

10.5.2�����������Ĵ���
һ�����鴴���ɶ�Ӧ�Ķ���������,��ʹ���������������,����:����ΪArray{7,3,10,13,5,1,9},�����ɶ�Ӧ�Ķ���������Ϊ:

����:
public void add(Node node){ if(node==null){ return; } //���������Ϊ��,��ֱ�Ӹ�root��ֵ if(root==null){ roor=node; }else{ root.add(node); } if(node.value<this.value){ //������ڵ�Ϊ�� if(this.left==null){ this.left=node; }else{ //�����Ϊ��,��ݹ����� this.left.add(node); } }else{ if(this.right==null){ this.right=node; }else{ this.right.add(node); } }}
10.5.3������������ɾ��
������������ɾ������Ƚϸ���,���������:
- ɾ��Ҷ�ӽڵ�
- ɾ��ֻ��һ�������Ľڵ�
- ɾ�������������Ľڵ�
˼·����:
��һ�������ɾ��Ҷ�ӽڵ�:
- ��Ҫ���ҵ�Ҫɾ���Ľڵ�targetNode
- �ҵ�targetNode�ĸ��ڵ�parent
- ȷ��targetNode�����ӻ����Һ���
- ���ӽڵ�:parent.left=null;���ӽڵ�:parent.right=null;
�ڶ��������ɾ��ֻ��һ�������Ľڵ�
- ��Ҫ���ҵ�Ҫɾ���Ľڵ�targetNode
- �ҵ�targetNode�ĸ��ڵ�parent
- ȷ��targetNode���ӽڵ������ӽڵ㻹�����ӽڵ�
- ȷ��targetNode��parent�����ӻ����Һ���
- ���targetNode�����ӽڵ�
- ���targetNode��parent�����ӽڵ�:parent.left=targetNode.left
- ���targetNode��parent�����ӽڵ�:parent.right=targetNode.left
- ���targetNode�����ӽڵ�
- ���targetNode��parent�����ӽڵ�:parent.left=targetNode.right
- ���targetNode��parent�����ӽڵ�:parent.right=targetNode.right
�����������ɾ�������������Ľڵ�
- ��Ҫ���ҵ�Ҫɾ���Ľڵ�targetNode
- �ҵ�targetNode�ĸ��ڵ�parent
- ��targetNode�����������ҵ���С�Ľڵ�
- ��һ����ʱ����,����С����ֵ���浽temp
- ɾ������С�ڵ�
- targetNode.value=temp;
����:
//��ѯҪɾ���Ľڵ�public Node search(int value){ if(root==null){ return null; }else{ return root.search(value); }}
//���Ҹ��ڵ�public Node searchParent(int value){ if(root==null){ return null; }else{ return root.searchParent(value); }}
//ɾ��nodeΪ���ڵ�Ķ�������������С�ڵ�public int delRightTreeMin(Node node){ Node target=node; //ѭ���IJ��� while(target.left!=null){ target=target.left; } delNode(target.value); return target.value;}
//ɾ���ڵ�public void delNode(int value){ if(root==null){ return; }else{ //�ҵ�Ҫɾ���Ľڵ�targetNode�ڵ� Node targetNode=search(value); //���û���ҵ� if(targetNode==null){ return; } //��targetNode�ĸ��ڵ� Node parent=searchParent(value); //���Ҫɾ���Ľڵ���Ҷ�ӽڵ� if(targetNode.left==null&&targetNode.right==null){ //�ж�targetNode��parent�����ҽڵ� if(parent.left!=null&&parent.left.value==value){ //����ڵ� parent.left=null; }else if(parent.right!=null&&parent.right.value==value){ parent.right=null; } }else if(targetNode.left!=null&&targetNode.right!=null){ //ɾ�������������Ľڵ� //Ѱ��targetNodeΪ���ڵ�����������Сֵ int minval=delRightTreeMin(targetNode.right); targetNode.value=mnval; }else{ //ɾ��ֻ��һ�������Ľڵ� if(targetNode.left!=null){//ɾ���Ľڵ������ӽڵ� if(parent!=null){ if(parent.left.value==value){//���targetNode��parent�����ӽڵ� parent.left=targetNode.left; }else{ parent.right=targetNode.left; }else{ root=targetNode.left;//�ݹ� } } }else{//ɾ���Ľڵ������ӽڵ� if(parent!=null){ if(parent.right.value==value){ parent.right=targetNode.right; }else{ parent.left=targetNode.right; }else{ root=targetNode.right; } } } } }}
10.6ƽ�������(AVL)
����һ������{1,2,3,4,5,6},Ҫ��һ�Ŷ���������,��������������
���BST���ڵ��������:
- ������ȫ��Ϊ��,����ʽ�Ͽ�,����һ��������
- �����ٶ�û��Ӱ��
- ��ѯ�ٶ������½�(��ΪҪһ�αȽ�),���ܷ���BST������,��Ϊÿ��Ҫ�Ƚ�������,���ѯ�ٶȱȵ���������
- �������-ƽ�������(AVL)
10.6.1��������
- ƽ�������Ҳ������������,���Ա�֤��ѯЧ�����
- ���������ص�:����һ�������������������������ĸ߶Ȳ�ľ���ֵ������1,����������������һ��ƽ���������
�����Ըýڵ�Ϊ���ڵ�����ĸ߶�
public int height(){ return Math.max(left==null?0:left.height(),right==null?0:right.height())+1;}
10.6.2����ת(����)
˼·����:
- ����һ���½ڵ�newNode,ֵ���ڵ�ǰ����ֵ
- ���½ڵ����������ɵ�ǰ�ڵ��������
- ���½�����������ɵ�ǰ�ڵ����������������
- �ѵ�ǰ�ڵ��ֵ�������ӽڵ��ֵ
- �ѵ�ǰ�ڵ�����������ó�Ϊ��������������
- �ѵ�ǰ�ڵ������������Ϊ�½ڵ�
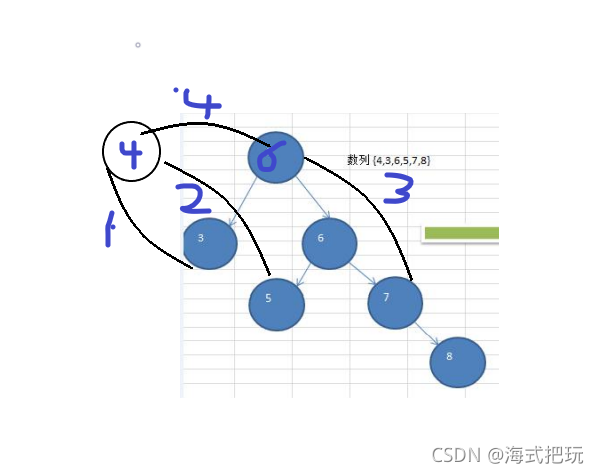
����:
private void leftRotate(){ //����һ���½��,�Ե�ǰ������ֵ Node newNode=new Node(value); //���½ڵ����������ɵ�ǰ�ڵ�������� newNode.left=left; ���½�����������ɵ�ǰ�ڵ���������������� newNode.right=right.left; //�ѵ�ǰ�ڵ��ֵ�������ӽڵ��ֵ value=right.value; //�ѵ�ǰ�ڵ�����������ó�Ϊ�������������� right=right.right; // left=newNode;}
10.6.3����ת(����ת)
˼·����:
- ����һ���½ڵ�newNode,ֵ���ڵ�ǰ����ֵ
- ���½ڵ�����ӽڵ�ָ��ǰ�ڵ��������
- �ѵ�ǰ�ڵ�����ӽڵ�ָ��ǰ�ڵ���������������
- �ѵ�ǰ����ֵ����Ϊ���ӽ���ֵ
- �ѵ�ǰ�ڵ�����������ó�Ϊ��������������
- �ѵ�ǰ��������������Ϊ�½ڵ�
����:
private void rightrotate(){ Node newNode=new Node(value); newNode.right=right; newNode.left=left.right; value=left.value; left=left.left; right=newNode;}
10.6.4˫��ת
˼·����:
- ����������ת������ʱ
- ����������������������߶ȴ��������������ĸ߶�
- �ȶԵ�ǰ�ڵ����ڵ��������ת
- �ڶԵ�ǰ�ڵ��������ת
����:
// ���ӽ��ķ��� // �ݹ����ʽ���ӽ��,ע����Ҫ���������������Ҫ�� public void add(Node node) { if (node == null) { return; } // �жϴ���Ľ���ֵ,�͵�ǰ�����ĸ�����ֵ��ϵ if (node.value < this.value) { // �����ǰ������ӽ��Ϊnull if (this.left == null) { this.left = node; } else { // �ݹ�������������� this.left.add(node); } } else { // ���ӵĽ���ֵ���� ��ǰ����ֵ if (this.right == null) { this.right = node; } else { // �ݹ�������������� this.right.add(node); } } //��������һ������,���: (�������ĸ߶�-�������ĸ߶�) > 1 , ����ת if(rightHeight() - leftHeight() > 1) { //����������������������ĸ߶ȴ����������������������ĸ߶� if(right != null && right.leftHeight() > right.rightHeight()) { //�ȶ����ӽ���������ת right.rightRotate(); //Ȼ���ڶԵ�ǰ����������ת leftRotate(); //����ת.. } else { //ֱ�ӽ�������ת���� leftRotate(); } return ; //����Ҫ!!! } //��������һ������,��� (�������ĸ߶� - �������ĸ߶�) > 1, ����ת if(leftHeight() - rightHeight() > 1) { //����������������������߶ȴ��������������ĸ߶� if(left != null && left.rightHeight() > left.leftHeight()) { //�ȶԵ�ǰ��������(������)->����ת left.leftRotate(); //�ٶԵ�ǰ����������ת rightRotate(); } else { //ֱ�ӽ�������ת���� rightRotate(); } } }
11.��·������
11.1��������B��
11.1.1���������������
�������IJ���Ч�ʸ�,��Ҳ��������:
��������Ҫ���ص��ڴ�,����������Ľڵ���,û������,����������Ľڵ��,�ͻ����:
- ����1:�ڹ���������ʱ,��Ҫ���i/o����,�ٶ���Ӱ��
- ����2:�ڵ��,����ɶ������ĸ߶Ⱥܴ�,�ή�Ͳ����ٶ�
11.1.2�����
- �ڶ�������,ÿ���ڵ���������,����������ӽڵ㡣�������ÿ���ڵ�����и���������������ӽڵ�,���Ƕ����
- �����ͨ��������֯�ڵ�,�������ĸ߶�,�ܶԶ����������Ż���

11.1.3B���Ļ�������
B��ͨ��������֯�ڵ�,�������ĸ߶�,������i/o��д����������Ч��

- ��ͼB��ͨ��������֯�ڵ�,�������ĸ߶�
- �ļ�ϵͳ�����ݿ�ϵͳ����������ô���Ԥ��ԭ��,��ÿ�����Ĵ�С���ó�һҳ,����ÿ���ڵ�ֻ��Ҫһ��I/O�Ϳ�����ȫ����
11.2 2-3��
11.2.1 2-3�������B���ṹ,���������ص�:
- 2-3��������Ҷ�ӽڵ㶼��ͬһ��(ֻҪ��B��������)
- �������ڵ�Ľڵ㽹���ڵ�,���ڵ�Ҫôû�нڵ�,Ҫô�������ڵ�
11.2.2 2-3����Ӧ�ð���
������{16,24.12,32,14,26,34,10,8,28,38,20}������2-3��,����֤���ݲ����˳���С��
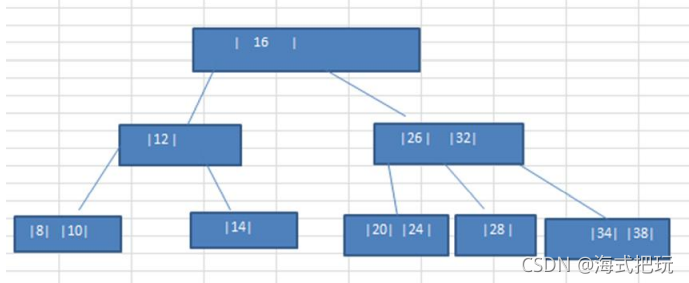
11.3 B��,B+��,B*��
11.3.1B���Ľ���
B-tree����B��,�ֳ�B-��
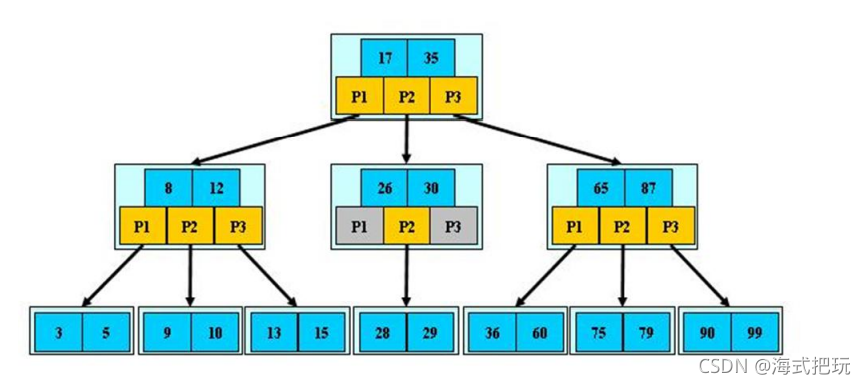
����ͼ��˵��:
- B���Ľ�:�ڵ������ӽ��ĸ�����
- B-���������Ӹ��ڵ㿪ʼ,�Խڵ��ڵĹؼ��ֽ��ж��ֲ���,������������,�������ؼ���������Χ�Ķ��ӽڵ�
- �ؼ��ּ��Ϸֲ�����Ƭ����
- �����п����ڷ�Ҷ�ӽڵ����
11.3.2B+���Ľ���
B+����B���ı���,Ҳ��һ�ֶ�·������
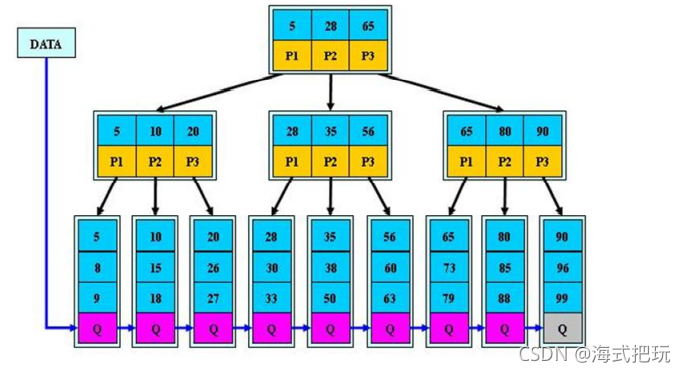
����ͼ��˵��:
- B+����������B��Ҳ������ͬ,������B+��ֻ�дﵽҶ�ӽڵ������
- ���йؼ��ֶ�������Ҷ�ӽڵ��������(������ֻ����Ҷ�ӽڵ㡾Ҳ�г���������),�������еĹؼ���ǡ���������
- �����ڷ�Ҷ�ӽڵ�����
- ��Ҷ�ӽڵ��൱����Ҷ�ӽڵ������(ϡ������),Ҷ�ӽڵ��൱���Ǵ洢���ݵ����ݲ�
- ���ʺ��ļ�����ϵͳ
- B����B+�������Լ���Ӧ�ó���
11.3.3B*���Ľ���
B*����B+���ı���,��B+�����Ǹ��ͷ�Ҷ�ӽڵ�������ָ���ֵܵ�ָ��
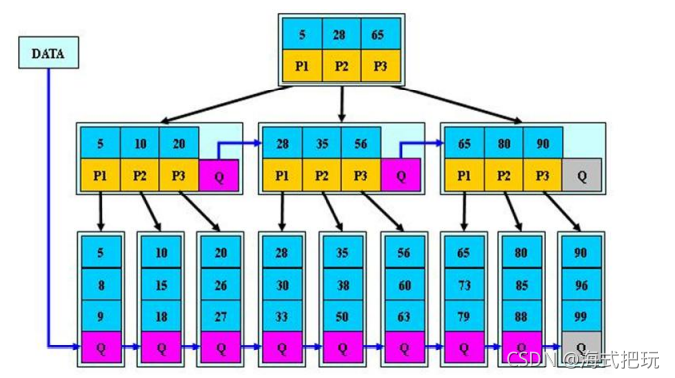
����ͼ��˵��:
- B*�������˷�Ҷ�ӽڵ�ؼ��ָ�������Ϊ(2/3)*M,��������ʹ����Ϊ2/3.��B+���Ŀ�����ʹ����Ϊ1/2
- B*�������½ڵ�ĸ��ʱ�B+��Ҫ��,�ռ�ʹ���ʸ���
12. ͼ
12.1ͼ��������
12.1.1ΪʲôҪ��ͼ
- ���Ա�������һ��ֱ��ǰ����һ��ֱ�Ӻ�̵Ĺ�ϵ
- ��Ҳֻ����һ��ֱ��ǰ��Ҳ���Ǹ��ڵ�
- ��������Ҫ��ʾ��Զ�Ĺ�ϵʱ,�������Ǿ��õ���ͼ
12.1.2ͼ�ľ���˵��
ͼ��һ�����ݽṹ,���нڵ���Ծ��������������Ԫ�ء��������ڽڵ�֮������ӳ�Ϊ��
12.1.3ͼ�ij��ø���
-
����
-
��
-
·��
-
����ͼ
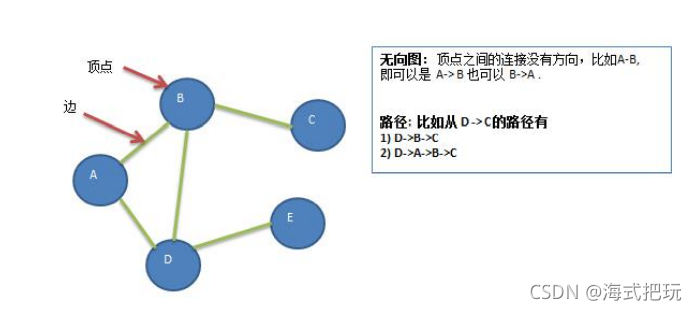
-
����ͼ
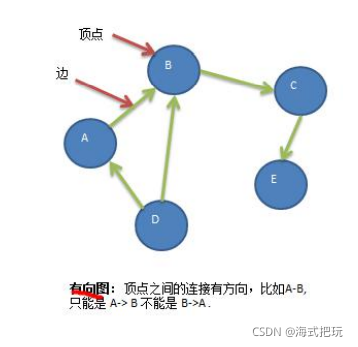
-
��Ȩͼ
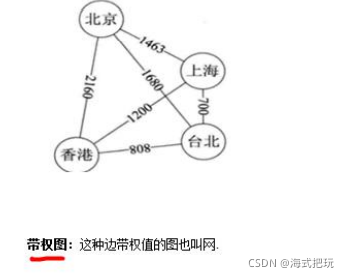
12.2ͼ�ı��﷽ʽ
ͼ�ı��﷽ʽ������:��ά�����ʾ(�ڽӾ���);������ʾ(�ڽӱ�)
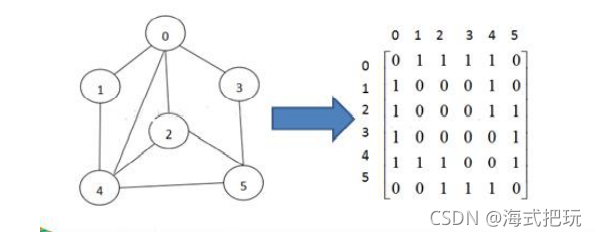
12.2.1�ڽӾ���
�ڽӾ����DZ�ʾͼ���ж�����֮�����ڹ�ϵ�ľ���
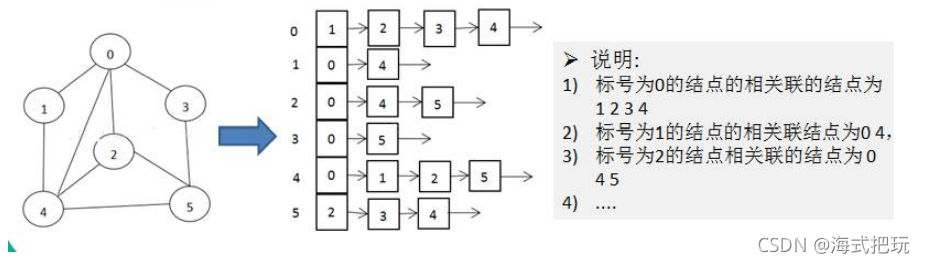
12.2.2�ڽӱ�
- �ڽӾ�����ҪΪÿ�����㶼����n���ߵĿռ�,��ʵ�кܶ���Dz����ڵ�,����ɿռ��һ����ʧ
- �ڽӱ���ʵ��ֻ���Ĵ��ڵı�,�����IJ����ڵıߡ�û�пռ��˷�,�ڽӱ�������+�������
12.3ͼ�Ŀ�������
-
Ҫ��:

-
˼·����:
- �洢���� String ʹ��ArrayList
- ������� int[][] edges
����:
//����ڵ�public void insertVertex(String vertex){ vertexList.add(vertex);}//���ӱ� public void insertEdge(int v1,int v2,int weight){ edges[v1][v2]=weight; edges[v2][v1]=weight; numOfEdges++;//�ߵ���Ŀ }
12.4ͼ��������ȱ��������㷨
12.4.1ͼ��������
����ÿ�����ķ��ʡ�һ�������ַ��ʲ���:
- ��������㷨
- ��������㷨
ͼ�Ķ������:
public class Graph{ private ArrayList<String> vertexList;//�洢���㼯�� private int[][] edges;//�洢ͼ��Ӧ���ڽӾ��� private int numOfEdges;//��ʾ�ߵ���Ŀ private boolean[] isVisited;// ��������boolean[]����¼ij���ڵ��Ƿ��� }
12.4.2������ȱ���˼��
ͼ����������㷨:
- ͼ��������ȱ���,�ӳ�ʼ���ʽڵ����,��ʼ���ʽڵ�����ж���ڽӽڵ�,������ȱ����IJ��Ծ������ȷ��ʵ�һ���ڽӽڵ�,Ȼ��������������ʵ��ٽ�ڵ���Ϊ��ʼ�ڵ�,�������ĵ�һ���ڽӽڵ�,
- �����ķ��ʲ����������������ھ�����,,�����Ƕ�һ�����������ڽӽڵ���к������
- �������������һ���ݹ�Ĺ���
12.4.3������ȱ����㷨����
-
���ʳ�ʼ�ڵ�v,����ǽڵ�vΪ�ѷ��ʡ�
-
���ҽڵ�v�ĵ�һ���ڽӽڵ�w
-
��w����,�����ִ��4,���ص���һ��,����v����һ���ڵ����
-
��wδ������,��w����������ȱ����ݹ�(����w������һ��v,Ȼ����в���123)
-
���ҽڵ�v��w�ڽӽڵ�,ת������3
-
����ͼ
12.5ͼ�Ĺ�����ȱ����㷨
12.5.1������ȱ����㷨����˼��
������һ���ֲ������Ĺ���,������ȱ����㷨��Ҫʹ��һ�������Ա�֤���ʹ��Ľ���˳��,�Ա㰴���˳�����������Щ�ڵ���ڽӽڵ�
12.5.2������ȱ����㷨����
- ���ʳ�ʼ�ڵ�v����ǽڵ�v�ѷ���
- �ڵ�v�����
- ������Ϊ�ǿ�ʱ,����ִ��,�����㷨����
- ������,ȡ�ö���ͷ�ڵ�u
- ���ҽ��u�ĵ�һ���ڽӽڵ�w
- ���ڵ�u���ڽӽڵ�w������,��ת������3;����ѭ�����²���:
- ���ڵ�w��δ������,��ڵ�w���Ϊ�ѷ���
- �ڵ�w�����
- ���ҽڵ�u�ļ�w�ڽӽڵ�֮�����һ���ڽӽڵ�w,ת������6
12.6ͼ�ı���
����:
public class Graph {
private ArrayList<String> vertexList; //�洢���㼯��
private int[][] edges; //�洢ͼ��Ӧ���ڽ����
private int numOfEdges; //��ʾ�ߵ���Ŀ
//���������boolean[], ��¼ij������Ƿ���
private boolean[] isVisited;
public static void main(String[] args) {
//����һ��ͼ�Ƿ�ok
int n = 8; //���ĸ���
String Vertexs[] = {"1", "2", "3", "4", "5", "6", "7", "8"};
//����ͼ����
Graph graph = new Graph(n);
//ѭ�������Ӷ���
for(String vertex: Vertexs) {
graph.insertVertex(vertex);
}
//���±ߵĹ�ϵ
graph.insertEdge(0, 1, 1);
graph.insertEdge(0, 2, 1);
graph.insertEdge(1, 3, 1);
graph.insertEdge(1, 4, 1);
graph.insertEdge(3, 7, 1);
graph.insertEdge(4, 7, 1);
graph.insertEdge(2, 5, 1);
graph.insertEdge(2, 6, 1);
graph.insertEdge(5, 6, 1);
//��ʾһ���ڽ����
graph.showGraph();
//����һ��,���ǵ�dfs�����Ƿ�ok
System.out.println("��ȱ���");
graph.dfs();
System.out.println();
System.out.println("�������!");
graph.bfs();
}
//������
public Graph(int n) {
//��ʼ�������vertexList
edges = new int[n][n];
vertexList = new ArrayList<String>(n);
numOfEdges = 0;
}
//�õ���һ���ڽӽ����±� w
/**
*
* @param index
* @return ������ھͷ��ض�Ӧ���±�,����-1
*/
public int getFirstNeighbor(int index) {
for(int j = 0; j < vertexList.size(); j++) {
if(edges[index][j] > 0) {
return j;
}
}
return -1;
}
//����ǰһ���ڽӽ����±�����ȡ��һ���ڽӽ��
public int getNextNeighbor(int v1, int v2) {
for(int j = v2 + 1; j < vertexList.size(); j++) {
if(edges[v1][j] > 0) {
return j;
}
}
return -1;
}
//������ȱ����㷨
//i ��һ�ξ��� 0
private void dfs(boolean[] isVisited, int i) {
//�������Ƿ��ʸý��,���
System.out.print(getValueByIndex(i) + "->");
//���������Ϊ�Ѿ�����
isVisited[i] = true;
//���ҽ��i�ĵ�һ���ڽӽ��w
int w = getFirstNeighbor(i);
while(w != -1) {//˵����
if(!isVisited[w]) {
dfs(isVisited, w);
}
//���w����Ѿ������ʹ�
w = getNextNeighbor(i, w);
}
}
//��dfs ����һ������, �����������еĽ��,������ dfs
public void dfs() {
isVisited = new boolean[vertexList.size()];
//�������еĽ��,����dfs[����]
for(int i = 0; i < getNumOfVertex(); i++) {
if(!isVisited[i]) {
dfs(isVisited, i);
}
}
}
//��һ�������й�����ȱ����ķ���
private void bfs(boolean[] isVisited, int i) {
int u ; // ��ʾ���е�ͷ����Ӧ�±�
int w ; // �ڽӽ��w
//����,��¼�����ʵ�˳��
LinkedList queue = new LinkedList();
//���ʽ��,��������Ϣ
System.out.print(getValueByIndex(i) + "=>");
//���Ϊ�ѷ���
isVisited[i] = true;
//�����������
queue.addLast(i);
while( !queue.isEmpty()) {
//ȡ�����е�ͷ����±�
u = (Integer)queue.removeFirst();
//�õ���һ���ڽӽ����±� w
w = getFirstNeighbor(u);
while(w != -1) {//�ҵ�
//�Ƿ���ʹ�
if(!isVisited[w]) {
System.out.print(getValueByIndex(w) + "=>");
//����Ѿ�����
isVisited[w] = true;
//���
queue.addLast(w);
}
//��uΪǰ����,��w�������һ���ڽ��
w = getNextNeighbor(u, w); //���ֳ����ǵĹ������
}
}
}
//�������еĽ��,�����й����������
public void bfs() {
isVisited = new boolean[vertexList.size()];
for(int i = 0; i < getNumOfVertex(); i++) {
if(!isVisited[i]) {
bfs(isVisited, i);
}
}
}
//ͼ�г��õķ���
//���ؽ��ĸ���
public int getNumOfVertex() {
return vertexList.size();
}
//��ʾͼ��Ӧ�ľ���
public void showGraph() {
for(int[] link : edges) {
System.err.println(Arrays.toString(link));
}
}
//�õ��ߵ���Ŀ
public int getNumOfEdges() {
return numOfEdges;
}
//���ؽ��i(�±�)��Ӧ������ 0->"A" 1->"B" 2->"C"
public String getValueByIndex(int i) {
return vertexList.get(i);
}
//����v1��v2��Ȩֵ
public int getWeight(int v1, int v2) {
return edges[v1][v2];
}
//������
public void insertVertex(String vertex) {
vertexList.add(vertex);
}
//���ӱ�
/*
*
* @param v1 ��ʾ����±꼴ʹ�ڼ������� "A"-"B" "A"->0 "B"->1
* @param v2 �ڶ��������Ӧ���±�
* @param weight ��ʾ
*/
public void insertEdge(int v1, int v2, int weight) {
edges[v1][v2] = weight;
edges[v2][v1] = weight;
numOfEdges++;
}
}