Ŀ¼
1. ���νṹ
1.1 ����(�˽�)
��������˳���, ����, ջ, ��������һ��һ�����Խṹ. ��������һ��һ�Զ�����ݽṹ, ��n(n>=0)�������ཻ���ڵ�����в�ι�ϵ�ļ���.
�ص�����:
- ��һ������Ľڵ�, ��Ϊ���ڵ�, ���ڵ�û��ǰ���ڵ�
- �����ڵ���, ����ڵ㱻�ֳ�M(M > 0)�������ཻ�ļ���T1, T2, ��, Tm,����ÿһ������ <= m) ����һ���������Ƶ�������ÿ�������ĸ��ڵ�����ֻ��һ��ǰ��,������0���������
- ���ǵݹ鶨���[���Ķ������õ������ĸ���]
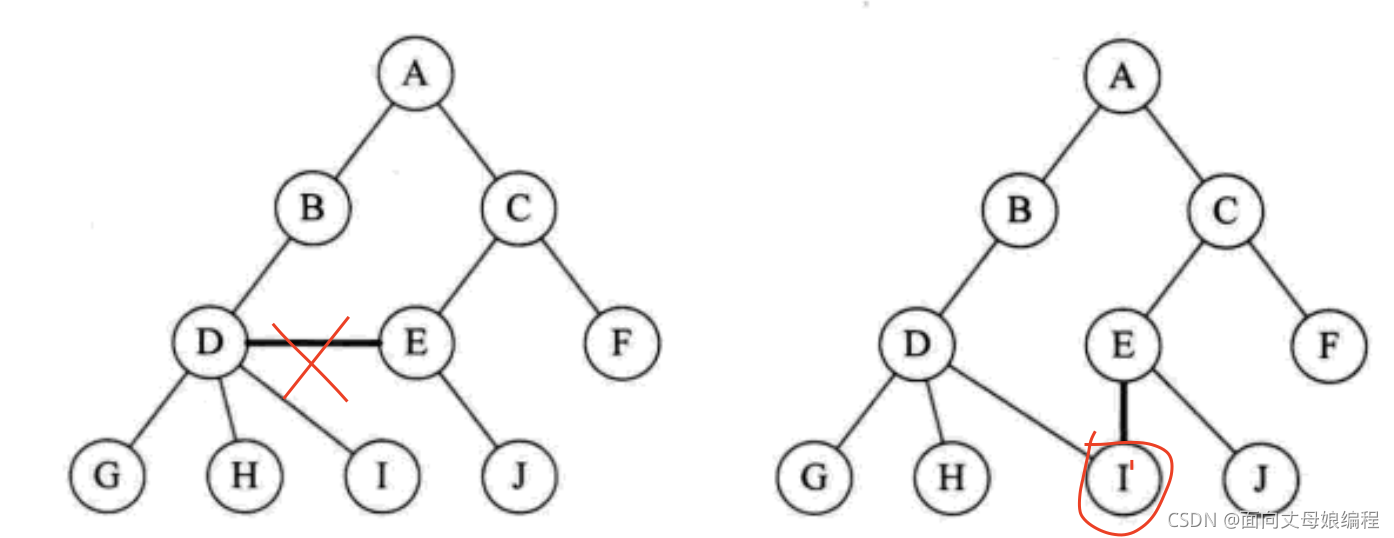
��ȷ����:
1.2 ����(��Ҫ)
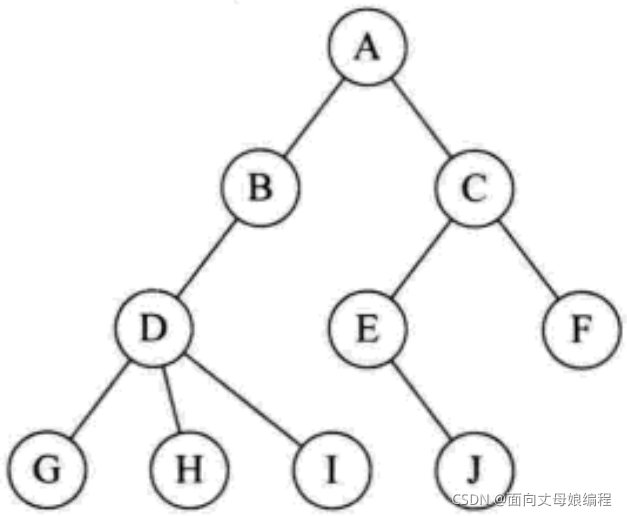
�õ�����ͼ����ȷ�Ķ�������������
-
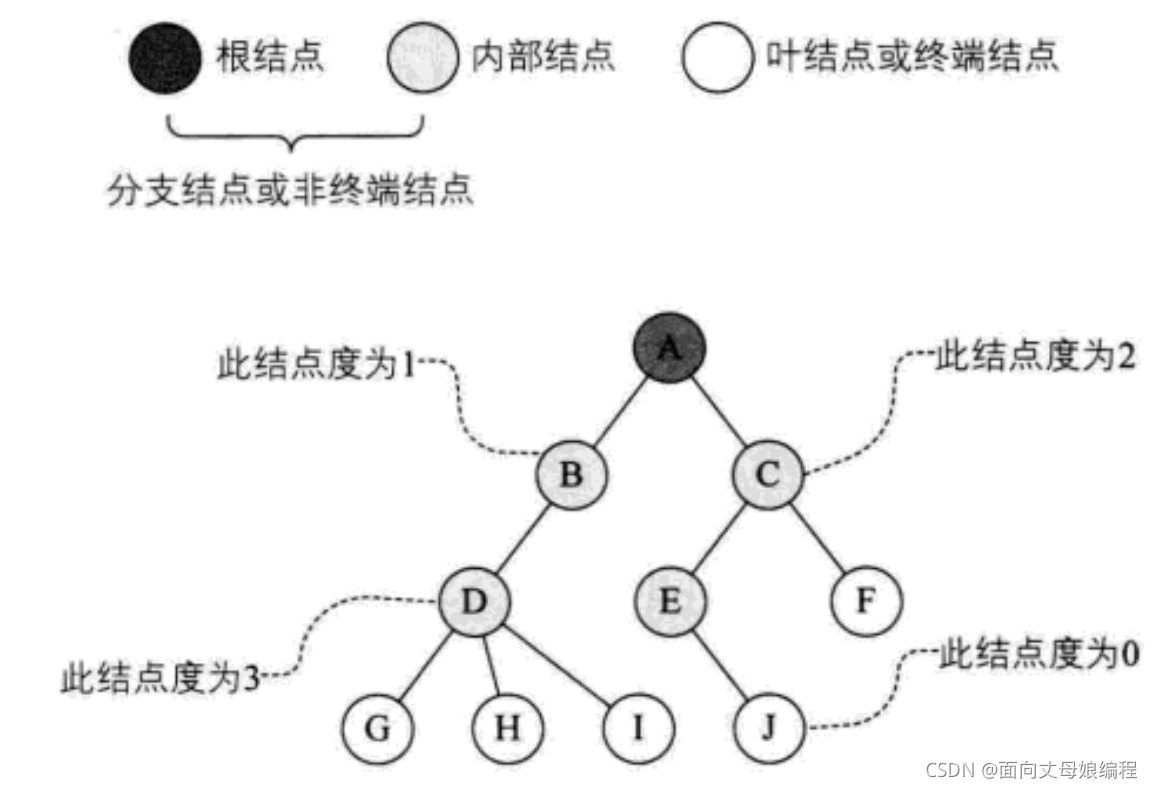
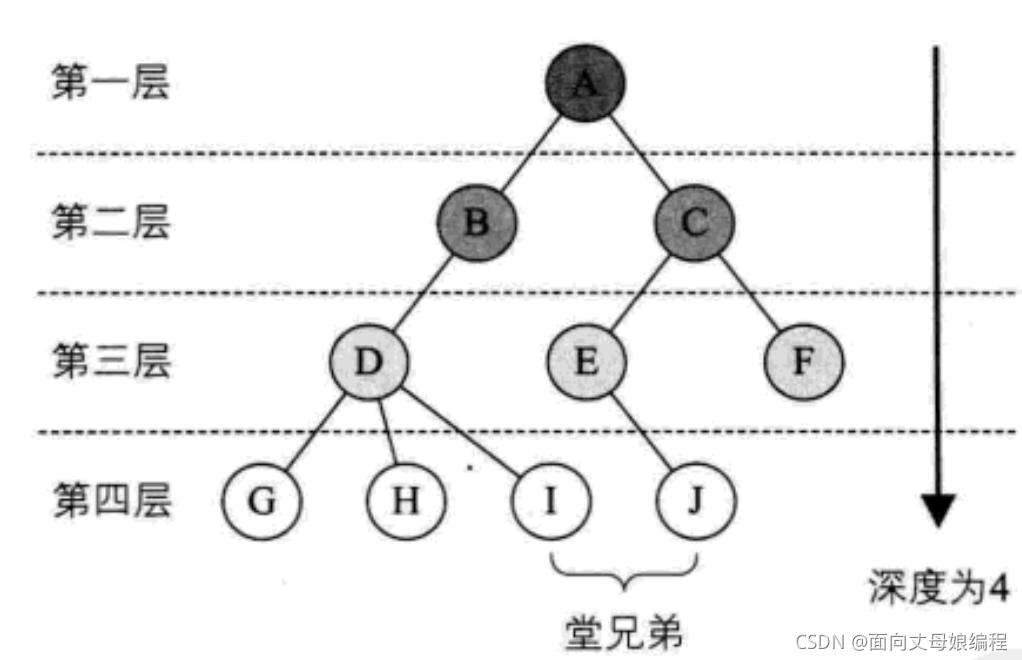
�ڵ�Ķ�: һ���ڵ㺬�е������ĸ�����Ϊ�ýڵ�Ķ�[A�ĶȾ���2]
-
���ն˽ڵ���֧�ڵ�:�Ȳ�Ϊ0�Ľڵ�[A, B, C, D, E]
-
���Ķ�: һ������,���Ľڵ�Ķȳ�Ϊ���Ķ�; ����ͼ:���Ķ�Ϊ3
-
Ҷ�ӽڵ���ն˽ڵ�: ��Ϊ0�Ľڵ��ΪҶ�ڵ�; ����ͼ:G��H��I��J�ڵ�ΪҶ�ڵ�
-
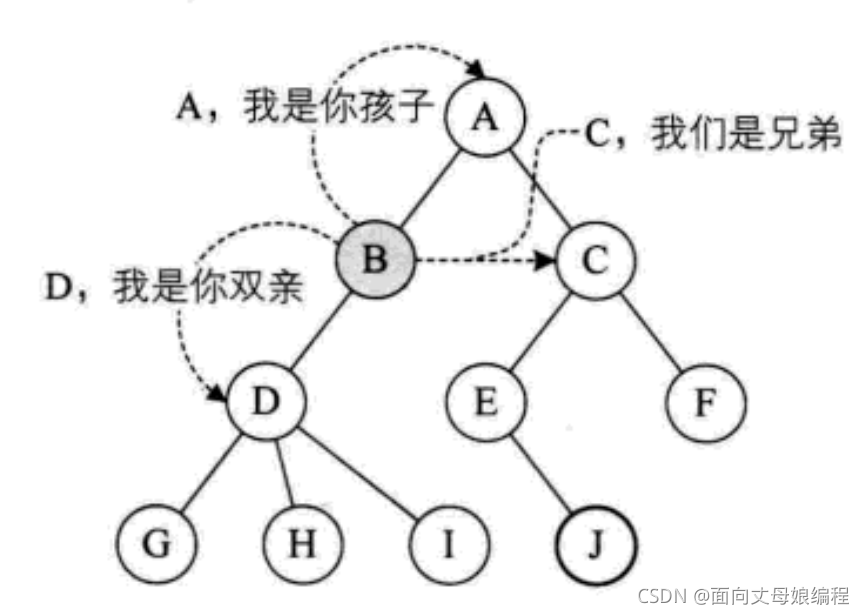
˫�ڵ�ڵ�: ��һ���ڵ㺬���ӽڵ�,������ڵ��Ϊ���ӽڵ�ĸ��ڵ�; ����ͼ:A��B�ĸ��ڵ�
-
���ӽڵ���ӽڵ�: һ���ڵ㺬�е������ĸ��ڵ��Ϊ�ýڵ���ӽڵ�; ����ͼ:B��A�ĺ��ӽڵ�
-
�ֵܽڵ�: ������ͬ���ڵ�Ľڵ㻥��Ϊ�ֵܽڵ�[B��C, E��F, G, H��I]
-
���ֵܽڵ�: ˫����ͬһ��Ľڵ㻥��Ϊ���ֵܽڵ�[D��E, D��F]
-
�ڵ������: �Ӹ����ýڵ�����з�֧�������нڵ�[A]
-
�����: һ������,û��˫���Ľ��;����ͼ:A
-
ɭ��: ��m(m>=0)�û����ཻ�����ļ��ϳ�Ϊɭ��
-
�ڵ�IJ��: �Ӹ���ʼ������,��Ϊ��1��,�����ӽڵ�Ϊ��2��,�Դ�����
-
���ĸ߶Ȼ����: ���нڵ�������; ����ͼ:���ĸ߶�Ϊ4
| ���Խṹ | ���ṹ |
|---|---|
| ��һ��Ԫ��: ��ǰ�� | ���ڵ�: ��˫�� |
| ���һ��Ԫ��: ��� | Ҷ�ڵ�: ���, �ɶ�� |
| �м�Ԫ��: һ��ǰ��һ����� | �м�ڵ�: һ��˫��, ������� |
1.3 ���ı�ʾ��ʽ
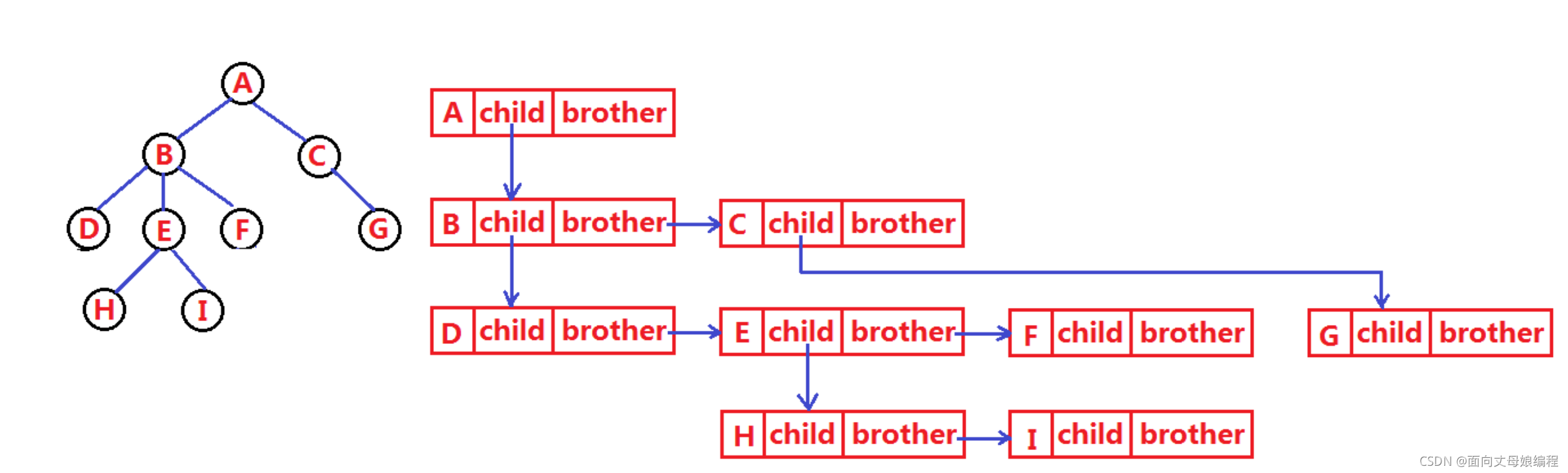
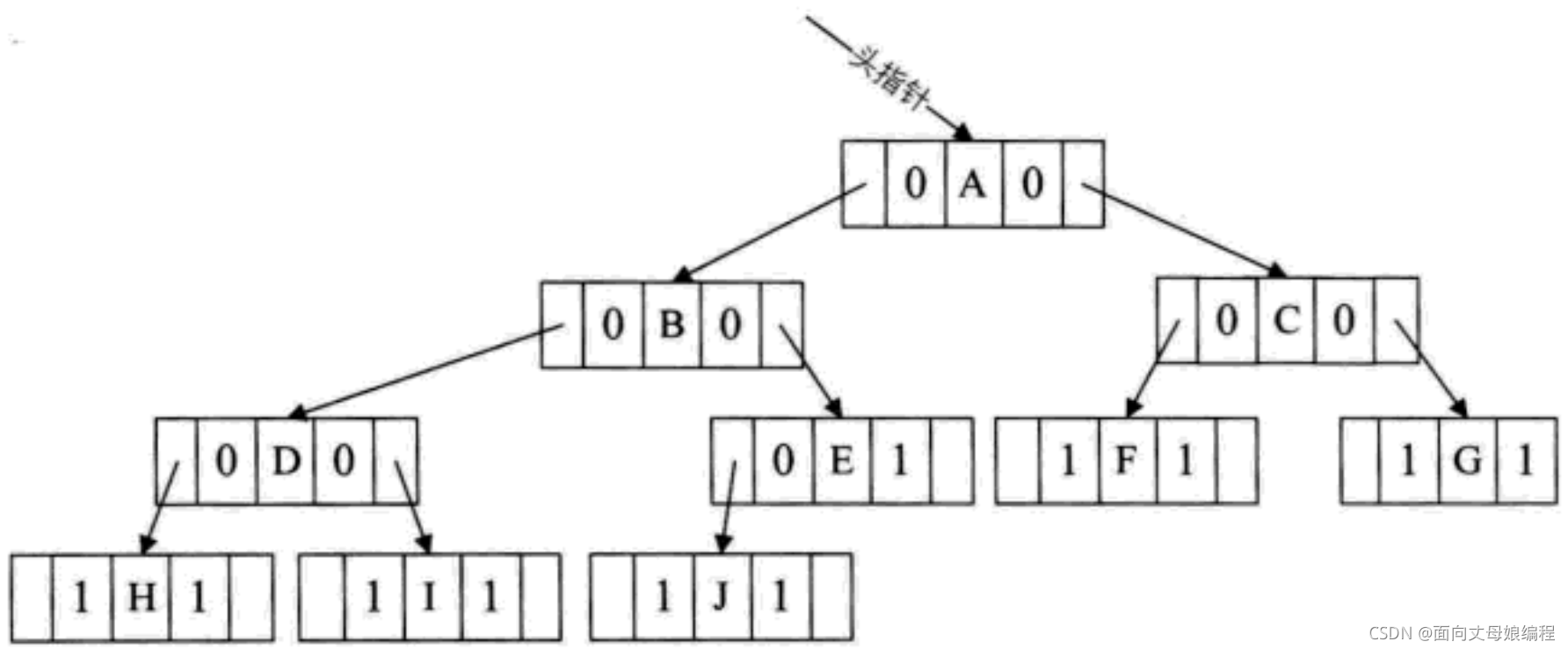
���ṹ������Ա��ͱȽϸ�����,Ҫ�洢��ʾ�����ͱȽ��鷳��,ʵ�������кܶ��ֱ�ʾ��ʽ,��:˫�ױ�ʾ�������ӱ�ʾ���������ֵܱ�ʾ���ȵȡ���������ͼ��˽�������õ������ֵܱ�ʾ��������OJ�����ľ������ֱ�ʾ��ʽ��
class Node {
int value;// ���д洢������
Node child;// ��һ����������
Node brother;// ��һ���ֵ�����
}
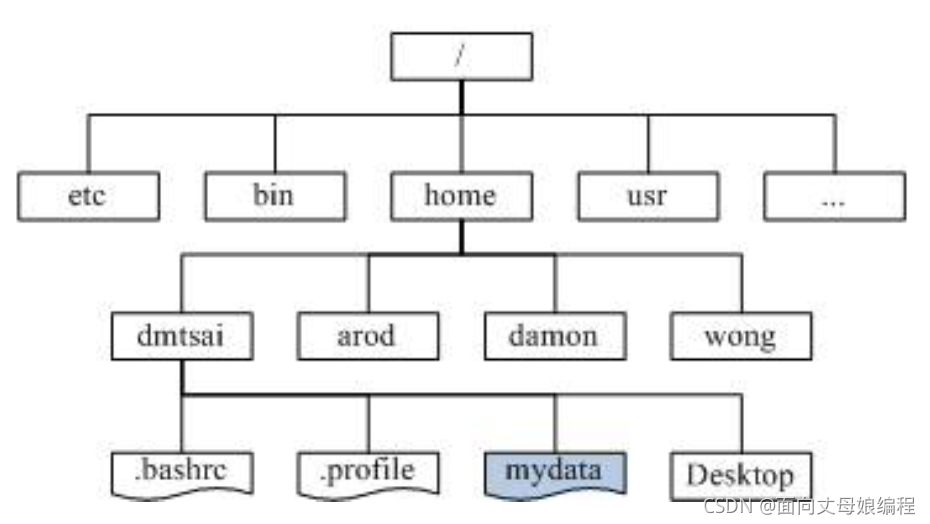
1.4 ����Ӧ��
�ļ�ϵͳ����(Ŀ¼���ļ�)
2. ������(BinaryTree�ص�)
2.1 ����
���ǴӾ���IJ�������Ϸ��ʼ, ��dz������ܶ�����.
��100���ڲ�����, ��༸�ο��Բ¶���?����:7
�����Ǹ���ÿ�βµĴ�С������������

���Ƿ������������С��ϵ������ָ����Χ��ij������, Ч�ʲ��Ǹߵ�һ�����. ��˶������־��ж�����ϵ�����: 0��1, �����, ������, ���뷴, ��������ʺ���������ģ. �����������״�ṹ��Ϊ������
һ�ö������ǽ���һ��������,�ü��ϻ���Ϊ��,��������һ�����ڵ�������ñ��Ϊ���������������Ķ�������ɡ�
�ص�:
- ÿ���ڵ������2������, �������ڶȴ���2�Ľڵ�
- ����������������֮��, �����ܵߵ�, ��˶�����Ҳ��һ��������
2.2 ��������5��������̬
- �ն�����
- ֻ��һ�����ڵ�
- ���ڵ�ֻ��������
- ���ڵ�ֻ��������
- ���ڵ㼴������������������
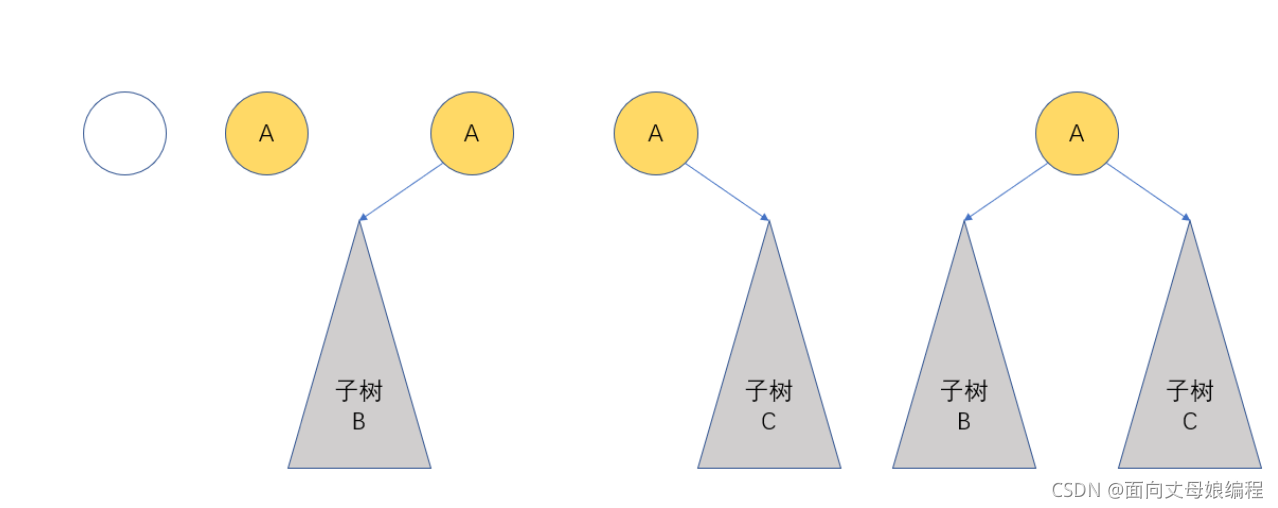
2.3 ��������Ķ�����
2.3.1 �
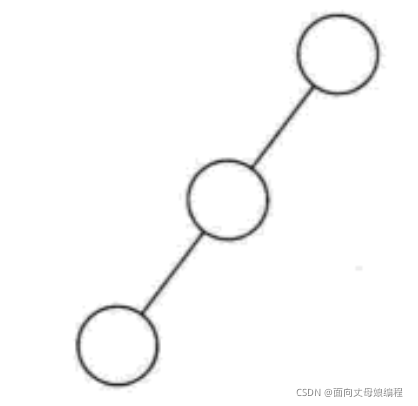
����˼��, б��һ��Ҫ��б��, ���Ķ�бҲ���н�����.���еĽڵ㶼ֻ��������������б��; ���еĽڵ㶼ֻ��������������б��
���:
���:
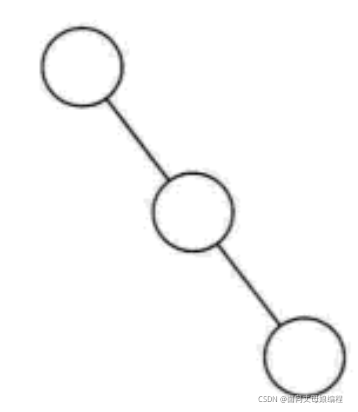
б���������ص�: ÿһ�㶼ֻ��һ���ڵ�, �����������������ͬ.
��Щͬѧ�������: ��Ҳ�ܽ�����, �ⲻ��������Ϥ�����Ա���?
����: �Ե�, ���Ա��ṹ��������Ϊ����һ�ּ�������ı�����ʽ
2.3.2 ��������
��һ�ö�������, ������з�֧��㶼������������������, ��������Ҷ�ӽڵ㶼��ͬһ����, �����Ķ�������Ϊ��������
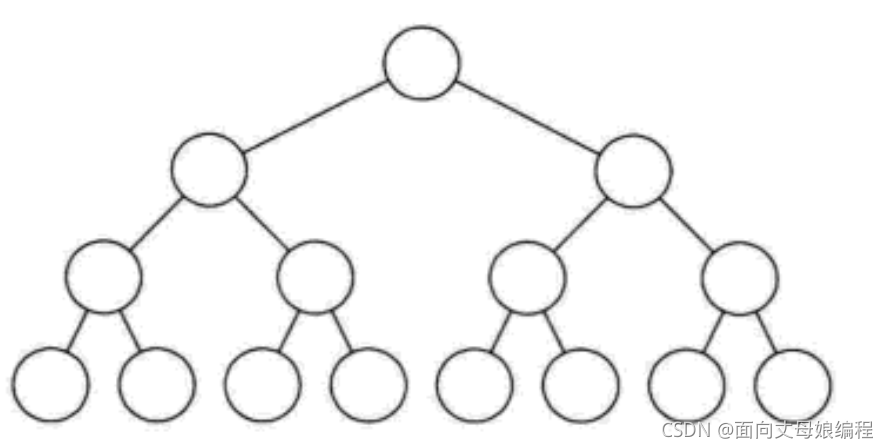
�������ӿ��ú���, ���ȳ�
���������ص�:
- Ҷ�ӽ��ֻ�ܳ���������һ��, ������������Ͳ����ܴﵽƽ��
- ��Ҷ�ӽ��Ķ�һ����2, ��������"ȱ�첲����"
- ��ͬ����ȵĶ�������, �����������������, Ҷ�ӽ�����
2.3.3 ��ȫ������
��һ�ž��� n ���ڵ�Ķ�������������, ���i(<1=i<=n)�Ľڵ���ͬ����ȵ����������б��Ϊi�Ľڵ��ڶ�����������λ����ȫ��ͬ
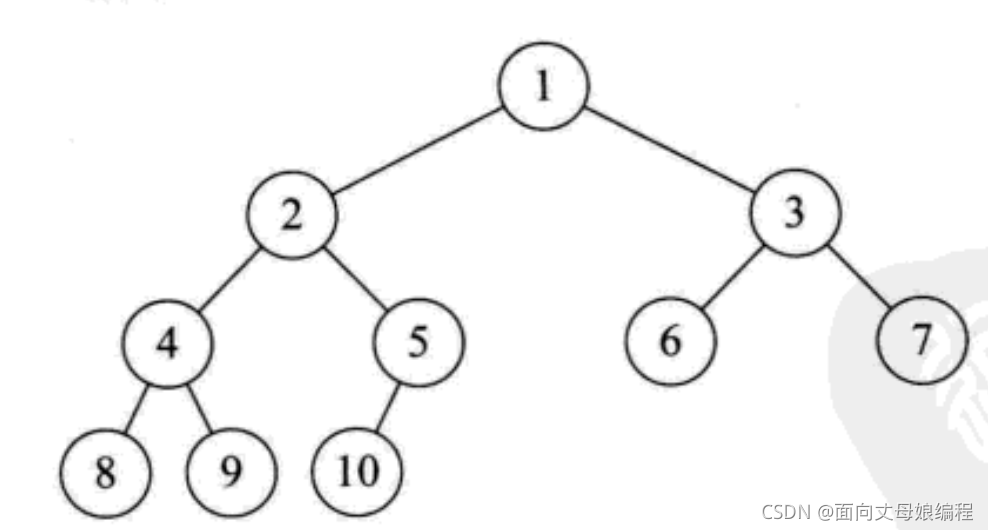
����һ����Щ������������������
���ȴ���������������, "��"��"��ȫ"�IJ���: ��������һ����һ����ȫ������, ������ȫ��������һ����һ����������
ʲô�ǰ�������?
��ͼ�о��ǰ��մ��ϵ���, ������һ�ΰ���1, 2, 3, ��, n�����
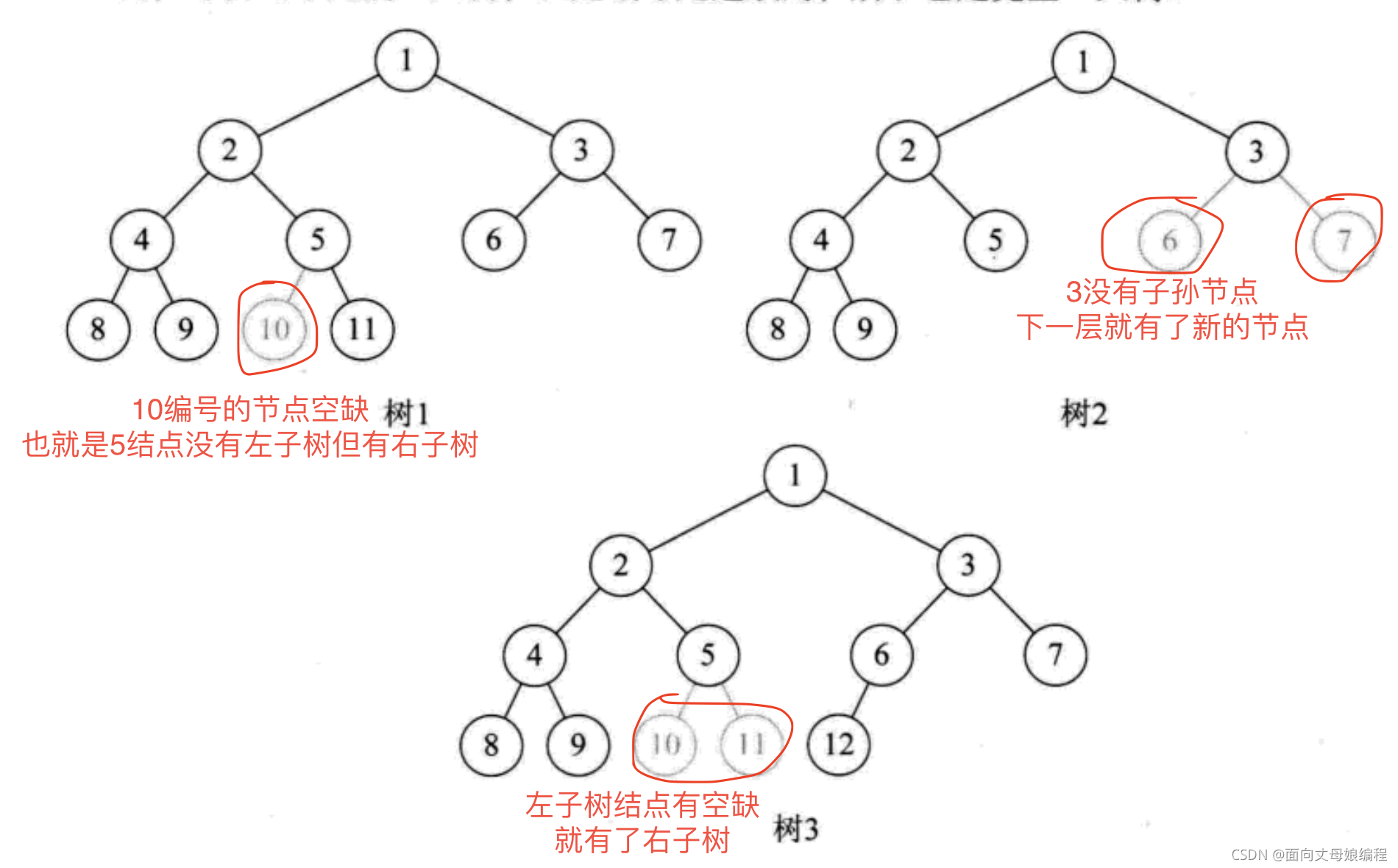
��ȫ�������ص�:
- Ҷ�ӽ��ֻ�ܳ�������������
- ���²��Ҷ�ӽ��һ��������������λ��
- �����ڶ���, �����Ҷ�ӽ��, һ�������Ҳ�����λ��
- ������Ķ�Ϊ1, ��ýڵ�ֻ������, ��������ֻ�������������
- ͬ��������Ķ�����, ��ȫ�������������С
�������������, Ҳ��������һ���ж�ij�������Ƿ�Ϊ��ȫ�������İ취: ���Ŷ�������ʾ��ͼ, ����ĬĬ��ÿ���ڵ㰴�����������Ľṹ���˳����, �����ų����˿յ�, ��˵��������ȫ���������������ȫ������
2.4 ������������
2.4.1 ��i�������
���涨���ڵ�IJ���Ϊ1,��һ�÷ǿն������ĵ�i��������� 2^(i-1)(i>0)�����
2.4.2 ���������������
���涨���ڵ�IJ���Ϊ1,�����ΪK�Ķ��������ڵ����� 2^k-1(k>0)�����
2.4.3 Ҷ�ӽ��ͷ�Ҷ�ӽ��������ϵ
���κ�һ�ö�����, �����Ҷ������Ϊ n0, ��Ϊ2�ķ�Ҷ������Ϊ n2,����n0=n2+1[����һ���Ҷ�ӽ�����=��������з�Ҷ�ӽ�����+1]
2.4.4 ���ݽ���������
����n���ڵ�Ķ����������KΪlog2^(n+1)����ȡ��
2.4.5 ���ӽ���Ź�ϵ
���ھ���n��������ȫ������,������մ������´������ҵ�˳������нڵ��0��ʼ���,��������Ϊi �Ľ����:
- ��i>0,˫�����:(i-1)/2;
- ��i=0,iΪ���ڵ���,��˫�ڵ�
- ��2i+1<n,�������:2i+1,����������
- ��2i+2<n,�Һ������:2i+2,�������Һ���
������ɺ���Ҫ, �漰������, ������������Ҫ�õ��������
2.4.6 ����
��һ����ȫ���������ܹ���1000���ڵ�, ��ö������� 500 ��Ҷ�ӽڵ�, 500����Ҷ�ӽڵ�, 1���ڵ�ֻ������, 0��ֻ���Һ���.
500��Ҷ�ӽ����㲽��
- Ҷ�ӽ���ܸ���=��10��Ҷ�ӽ�����+��9��Ҷ�ӽ�����
��ͬѧ����: Ϊ�ε�9�����Ҷ�ӽ����?
����: ��Ϊ���Ƿ��ִ������� 1000 �����, �����������Ļ����� 2^10-1 �����, ����˵�� ��10��û��, ��9��һ����Ҷ�ӽ��
������������������һ���ļ���
- ��10��ȫ��Ҷ�ӽ�����: �����ܽ����� - 9�㼰�������н�����
��Ϊ��һ����ȫ������, ���Կ��Ա�֤��9��һ������������
��ʽ: 1000-(2^9-1)�C>1000-511=489
�������ǻ����9���Ҷ�ӽ�����
- ��9��Ҷ�ӽ�����: ��9������� - ��10�㸸�ڵ����
��ʽ: 2^(9-1)-��10�㸸�ڵ����
��������������10�㸸�ڵ����
- ��10�㸸�ڵ������
���������n��ż��, ���丸������Ϊ n/2
���������n������, ���丸������n/2+1
�ڵ�һ������������˵�10�㸸�ڵ����, ���10�㸸�ڵ��������: 489/2 + 1�C>245 - ���ڿ��Լ���� 3 ���ó���9��Ҷ�ӽ�����:
2^(9-1)-245�C>256-245=11 - ���ڿ��Լ���� 1 ���е�������������Ҷ�ӽ��;
�� 10 ������ + �� 9 Ҷ�ӽ����: 489+11 = 500 - ����Ҷ�ӽ�����, ������֪����Ҷ�ӽڵ�
�ܽ�����-Ҷ�ӽ�����: 1000-500 - ������ȫ��������10�������Ϊ489, Ϊ����, ����һ����1���ڵ�ֻ������, �� 0 ���ڵ�ֻ��������
��һ���� 100 ��������ȫ�������Ӹ���һ�㿪ʼ,ÿһ����������ζԽ����б��,���ڵ���Ϊ 1 ,����Ϊ 98 �Ľڵ�ĸ��ڵ���Ϊ: (98-1)/2 = 48
��ǿն�����������������,���������ϵĽ��ֵ��С�ڸ����ֵ,���������ϵĽ��ֵ����С�ڸ����ֵ,��Ƹö�����Ϊ�����������������������ı������Ϊ�������е���: �������
��һ�ö������ĸ����������,Ȼ��ݹ��ִ�����²���,�����ӽ�������ӽ�����ӡ����ϲ�������ʵ���������.
n���ڵ����ȫ������,�������ж��ٲ�: log(n+1)��ȡ��
2.5 �������Ĵ洢
2.5.1 ˳��洢
��������˳��洢��ʹ��һά����洢�������еĽڵ㲢�Ҵ洢��λ��Ӧ��Ҫ�����ֽڵ�֮�������ϵ, ���红��˫��, �����ֵܽڵ�
2.5.1.1 ��ȫ����������ʽ�洢
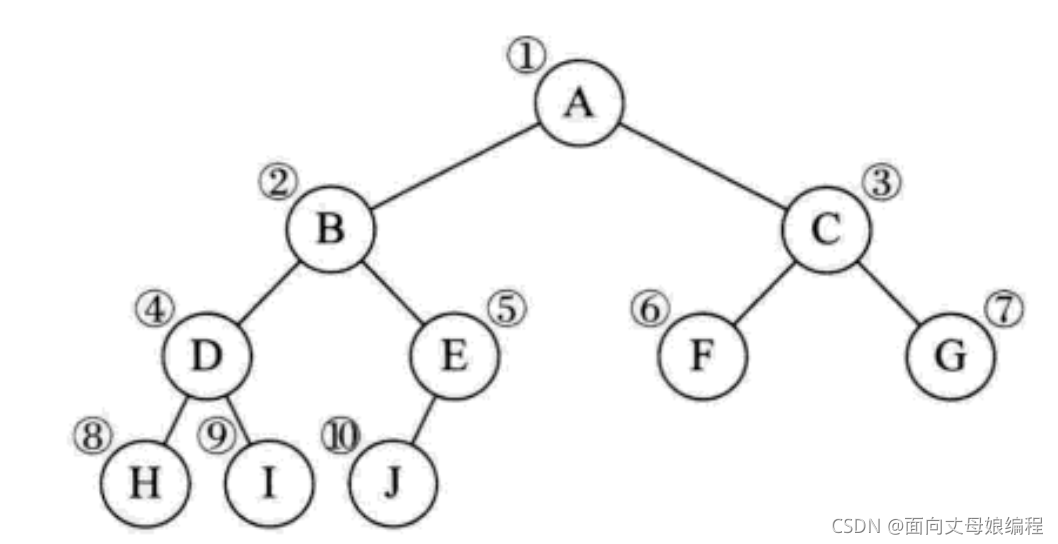
����Ŷ������洢������, ��Ӧ���±��Ӧ����ȵ�λ��

���¿�����ȫ����������Խ���˰�, ������������ϸ�, ����˳��ṹҲ�ܱ��ֳ��������Ľṹ��
2.5.1.2 һ��������ʽ�洢
����һ�����������, �����Ų��ܷ�ӳ����ϵ, ���ǿ�������ȫ���������, ֻ�����Ѳ����ڵĽ����ʩΪ ��^�� ����.dzɫ�ڵ����������
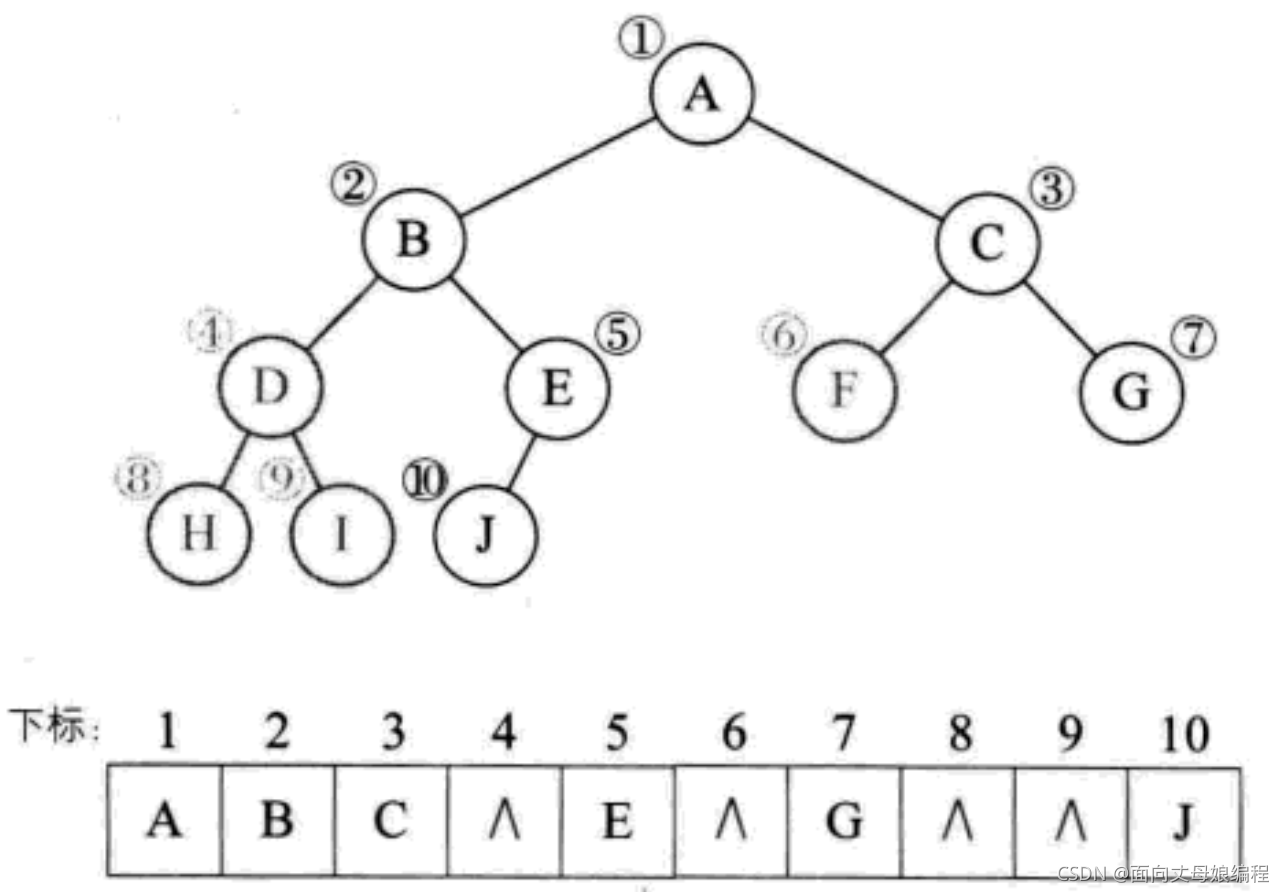
����һ�¼������: ��б������б����
һ�����Ϊ k ����б��, ֻ�� k ���ڵ�, ȴ��Ҫ���� 2^k-1 ���洢��Ԫ, ����Ȼ�ǶԴ洢�ռ���˷�. ����˳��洢ֻ��������ȫ������
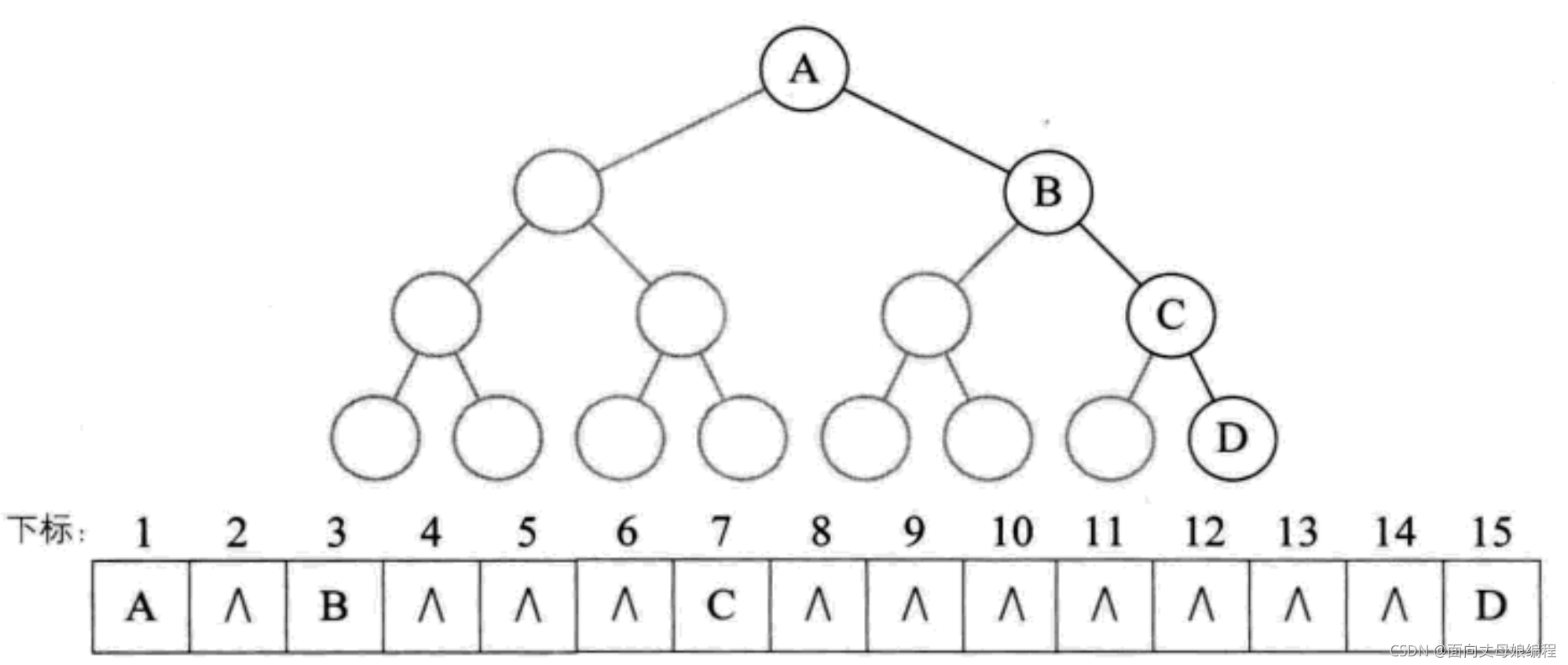
2.5.2 ��ʽ�洢
��Ȼ˳��洢��Ӧ�Բ�ǿ, ���Ǿ�Ҫ������ʽ�洢�ṹ. ������ÿ���ڵ��������������, �������һ�������������ָ����Ƚ�����. ����Ƕ�������
���ӱ�ʾ��

class Node {
int val;// ������
Node left;// ���ӵ�����,������������Ϊ��������������
Node right;// �Һ��ӵ�����,���������Һ���Ϊ��������������
}
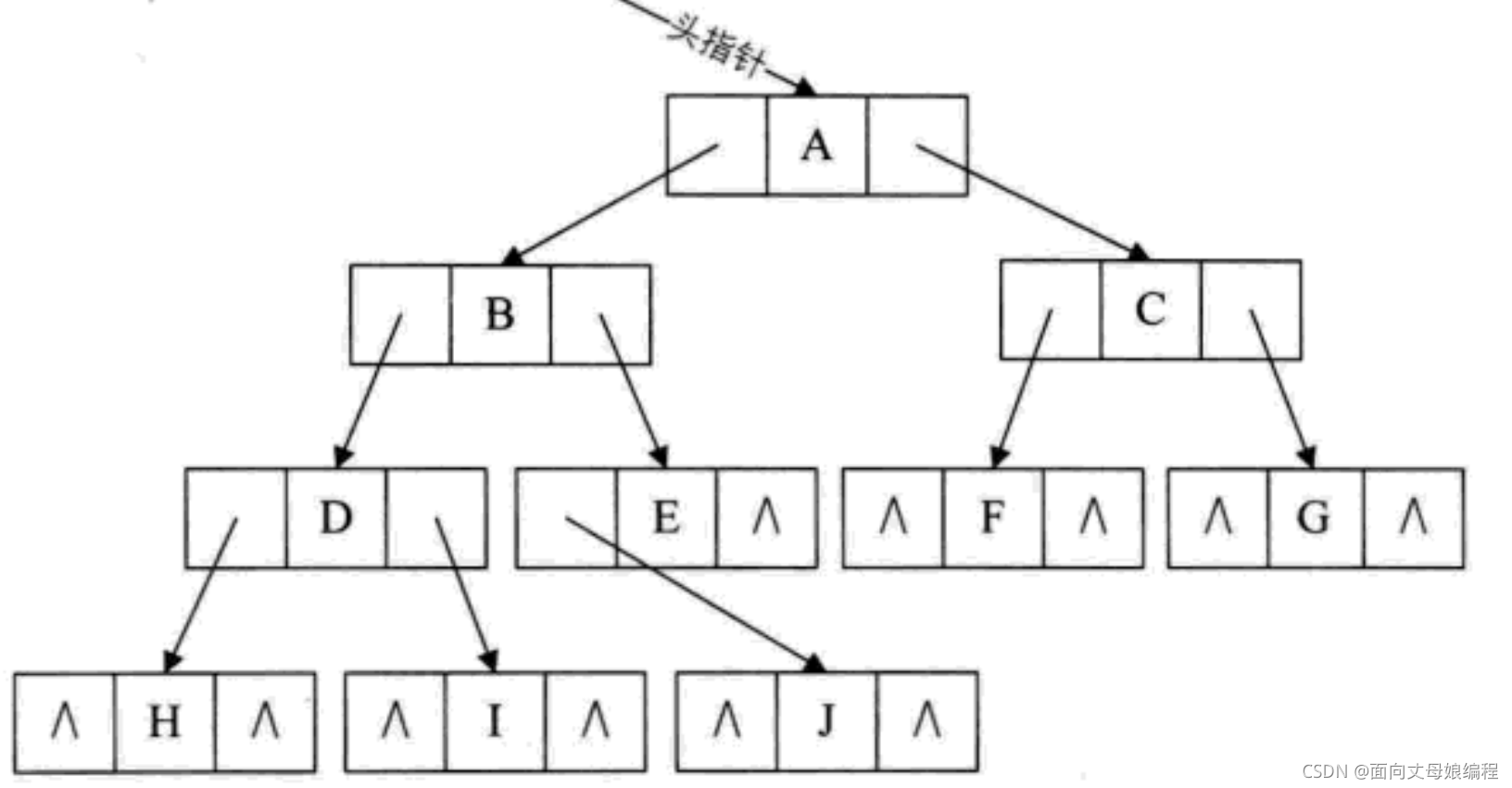
����˫�ױ�ʾ����Ҫ������ƽ����,���IJ������ӱ�ʾ��������������, �����������OJ��ĿҲ�����õ����ַ���������������.
3. ��������dz�������
3.1 ����������
3.1.1 ����������ԭ��
����: ������20��100Ԫ�ĺ�2000��1Ԫ�Ľ�ȯ, ͬʱ�����˿���, ��ұ�����˭���м�����.
����ͬѧ����˵: �ȼ�100Ԫ��. �����dz���, ��Ϊ��1��100Ԫ�ĵ��ڼ�100��1Ԫ��, Ч�ʺõIJ���һ���🤏.
���Եó������Ľ���: ͬ���Ǽ�ȯ, ������ʱ����, Ҫ�ﵽ���Ч��, ����dz���Ҫ. ���ڶ������ı�������, ����ͬ���Ե�Ҳ����Ҫ.
�������ı���(traversing binary tree): ��ָ�Ӹ�������, ����ij�ִ������������������е����нڵ�, ʹ��ÿһ���ڵ㱻����һ���ҽ���������һ��
�����������ؼ���: ���κͷ���. ��ͬ�����Խṹ, ���Ҳ���Ǵ�ͷ��β, ѭ��, ˫��ȼı�����ʽ. ���Ľڵ�֮�䲻����Ψһ��ǰ���ͺ�̹�ϵ, �ڷ���һ���ڵ��, ��һ�������ʵĽڵ������Ų�ͬ��ѡ��. �����������ĵ�·��, �߿��־ԸҪ�����ĸ�����, ������ѧ, ����רҵ��. ѡ��ʽ��ͬ, �����Ĵ������ȫ��ͬ
3.1.2 ��������������
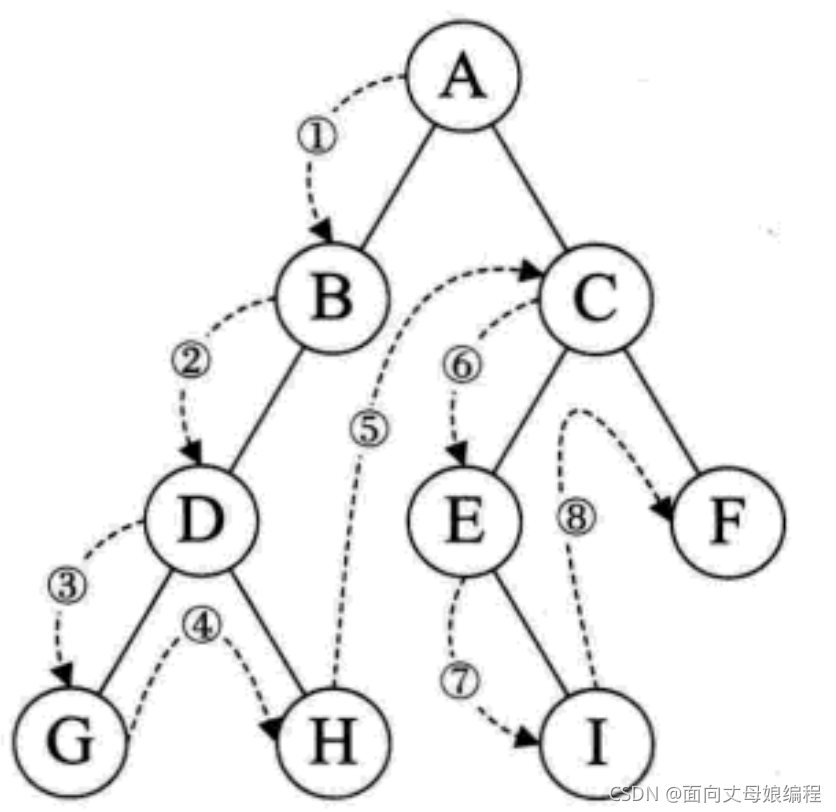
3.1.2.1 ǰ�����
- ��������Ϊ��, �ؿղ���
- �����ȷ��ʸ��ڵ�, Ȼ��ǰ�������������ǰ�����������
- ���շ��ʵĽ������: ABDGHCEIF
����ͼ���� ������ ��˳����ʶ�����ʾ��ͼ
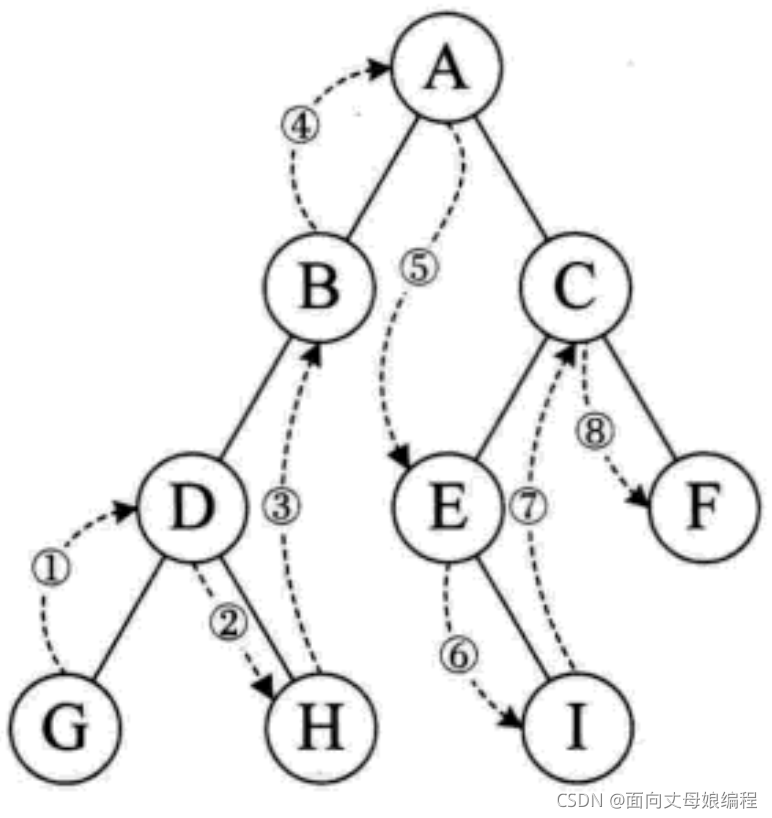
3.1.2.2 �������
- ����, �ؿղ���
- ����ʹӸ���㿪ʼ(ע�Ⲣ�����ȷ��ʸ��ڵ�)
- ����������ڵ��������
- Ȼ����ʸ��ڵ�
- ����������������
- ���շ��ʽ������: GDHBAEICF
����ͼ���� ����� ��˳����ʶ�����ʾ��ͼ
3.1.2.3 �������
- ����, �ؿղ���
- ���ȴ�������Ҷ�ӽ���ڵ�ķ�ʽ����������������, �����ʸ��ڵ�
- ���շ��ʽ����: GHDBIEFCA
����ͼ���� ���Ҹ� ��˳����ʶ�����ʾ��ͼ
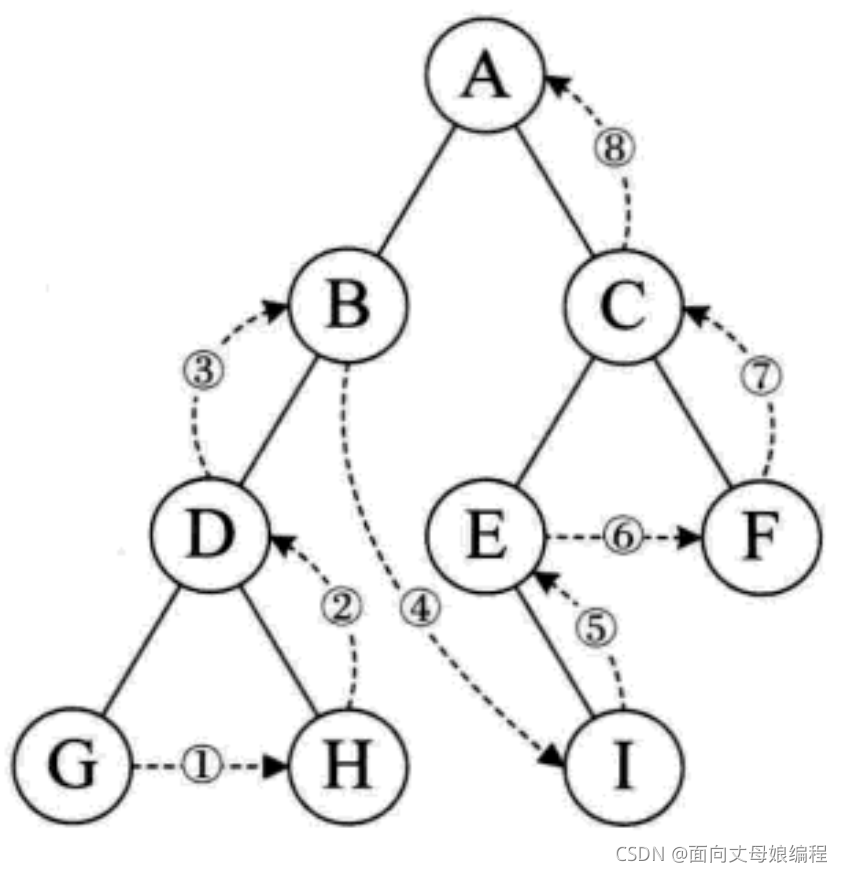
3.1.2.4 �������
- ����Ϊ��, ���ؿղ���
- ��������ĵ�һ��, Ҳ���Ǹ��ڵ㿪ʼ����
- ���϶���������
- ��ͬһ����, �����ҵ�˳��Խڵ��������
- ���շ��ʽ������: ABCDEFGHI
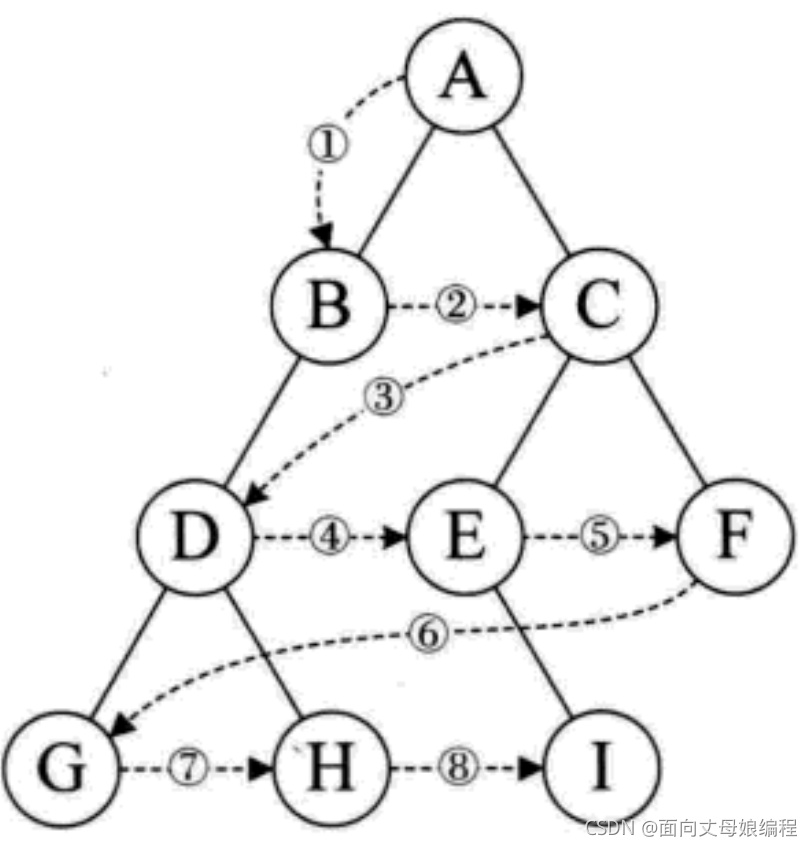
3.1.3 �����������㷨
��������������һ�Ŷ�����T, �������ṹ�洢
3.1.3.1 ǰ������㷨������
OJ��Ŀ����
�ݹ�ǰ�����
private static void preOrderTraversal(BinaryTreeNode root) {
if (root == null) {
return;
} else {
System.out.print(root.val + " ");
preOrder(root.left);
preOrder(root.right);
}
}
private static List<String> preOrderTraversal(BinaryTreeNode root) {
List<String> result = new ArrayList<>();
if (root == null) {
return result;
} else {
result.add(root.val);
result.addAll(preOrderTraversal(root.left));
result.addAll(preOrderTraversal(root.right));
return result;
}
}
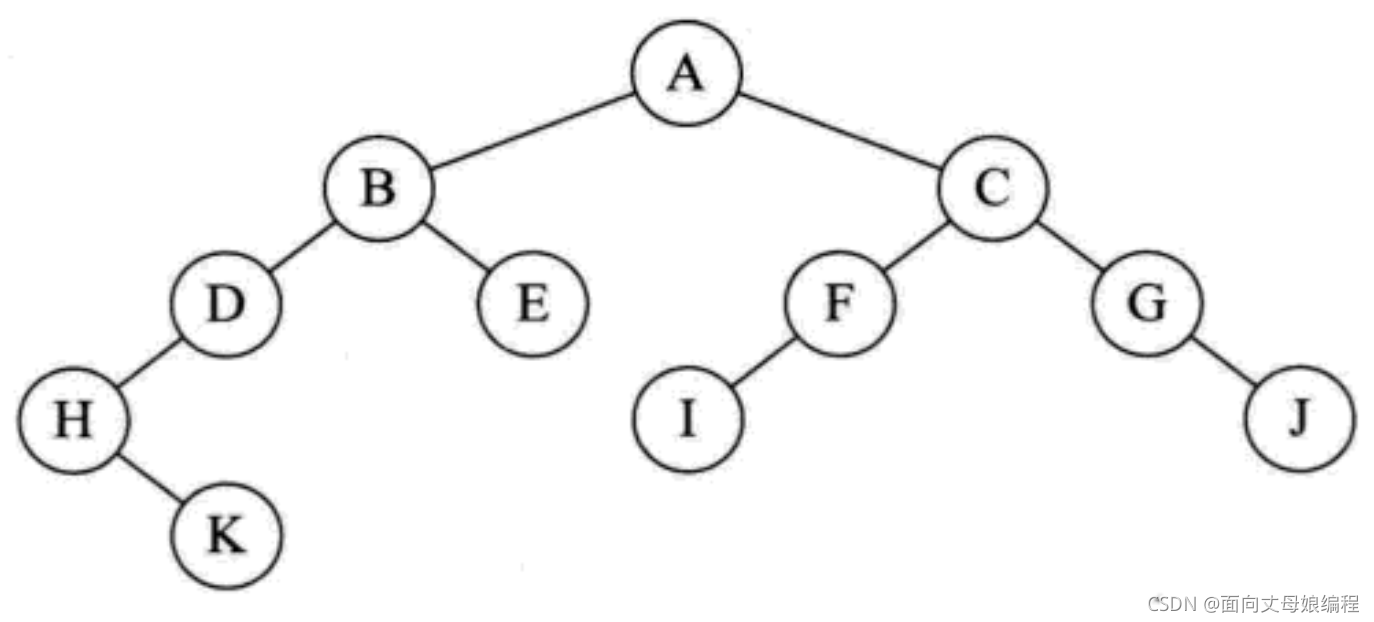
A B D H K E C F I G J
��ʾ�ݹ�ǰ���������
- ����
preOrderTraversal(BinaryTreeNode root), root ���ڵ㲻Ϊ��, ����ִ��System.out.print(root.val + " ");��ӡ��ĸ A
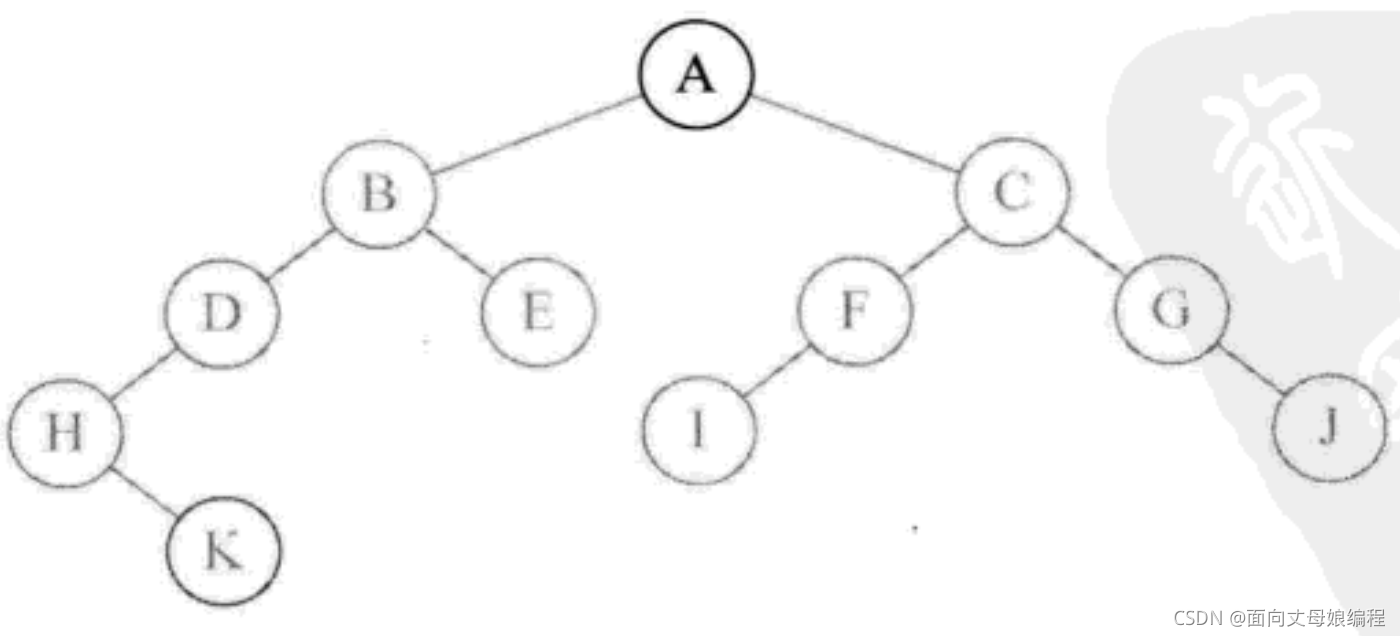
- ����
preOrderTraversal(root.left), ������A �ڵ������, ��Ϊ null, ִ��System.out.print(root.val + " ");��ӡ��ĸ B
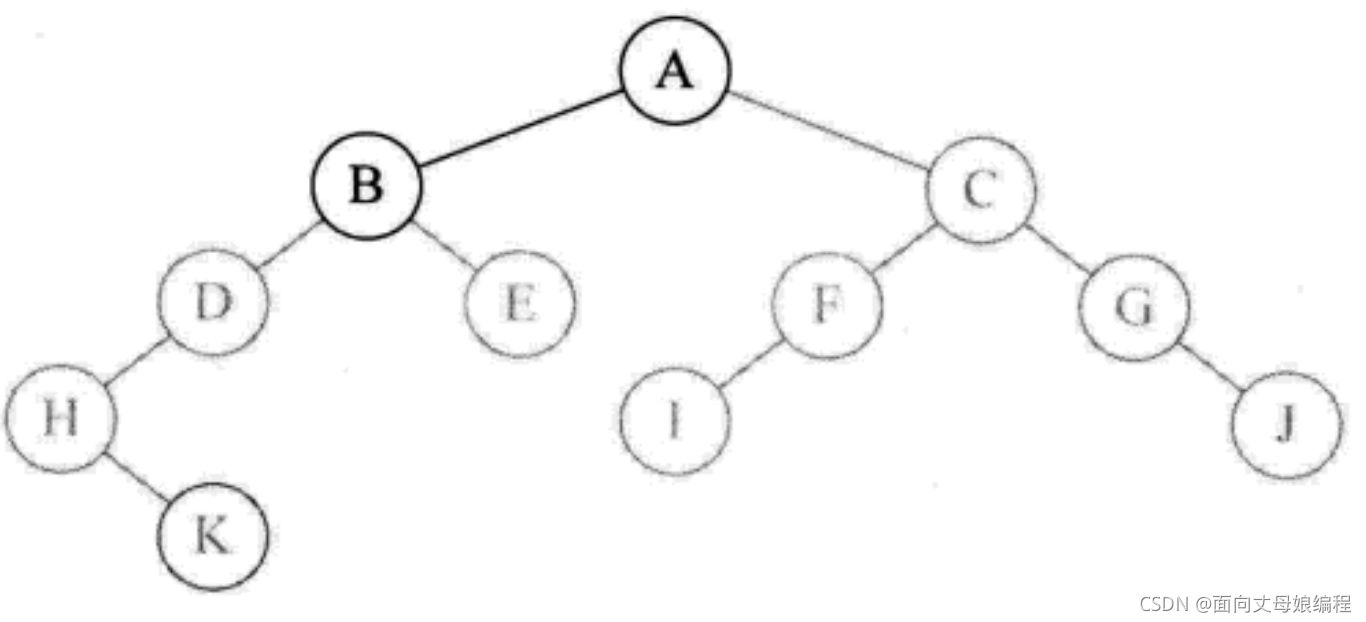
- �ٴεݹ����
preOrderTraversal(root.left), ������B �ڵ������, ��Ϊ null, ִ��System.out.print(root.val + " ");��ӡ��ĸ D
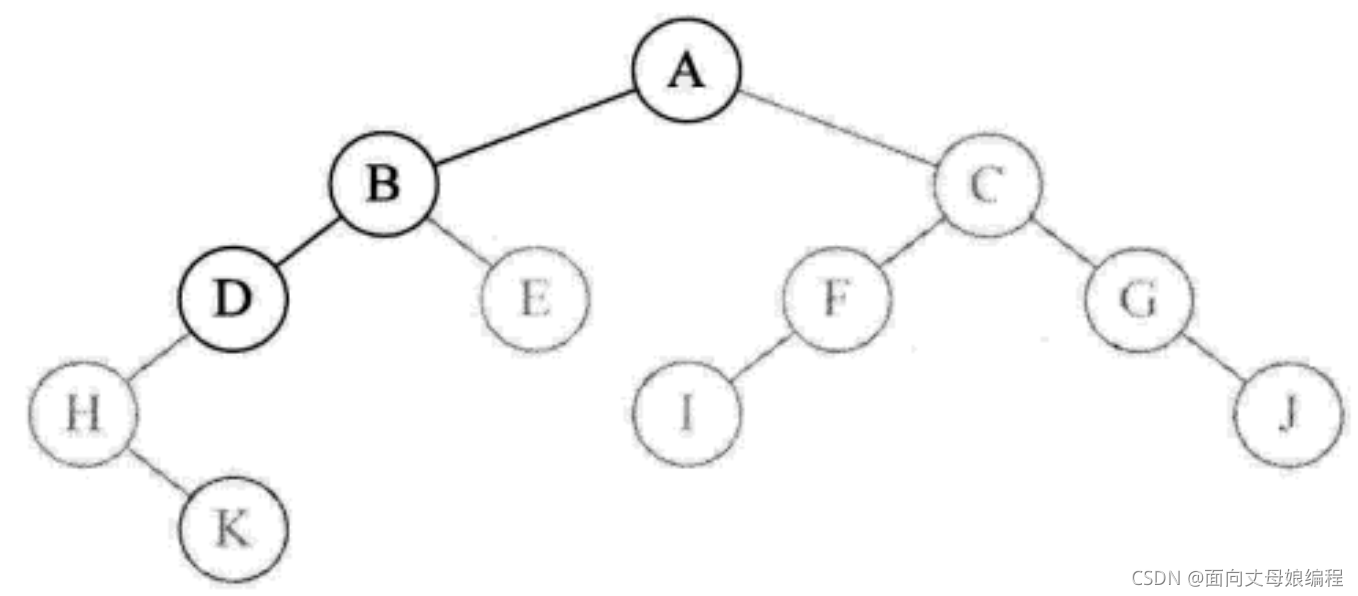
- �ٴεݹ����
preOrderTraversal(root.left), ������D �ڵ������, ��Ϊ null, ִ��System.out.print(root.val + " ");��ӡ��ĸ H
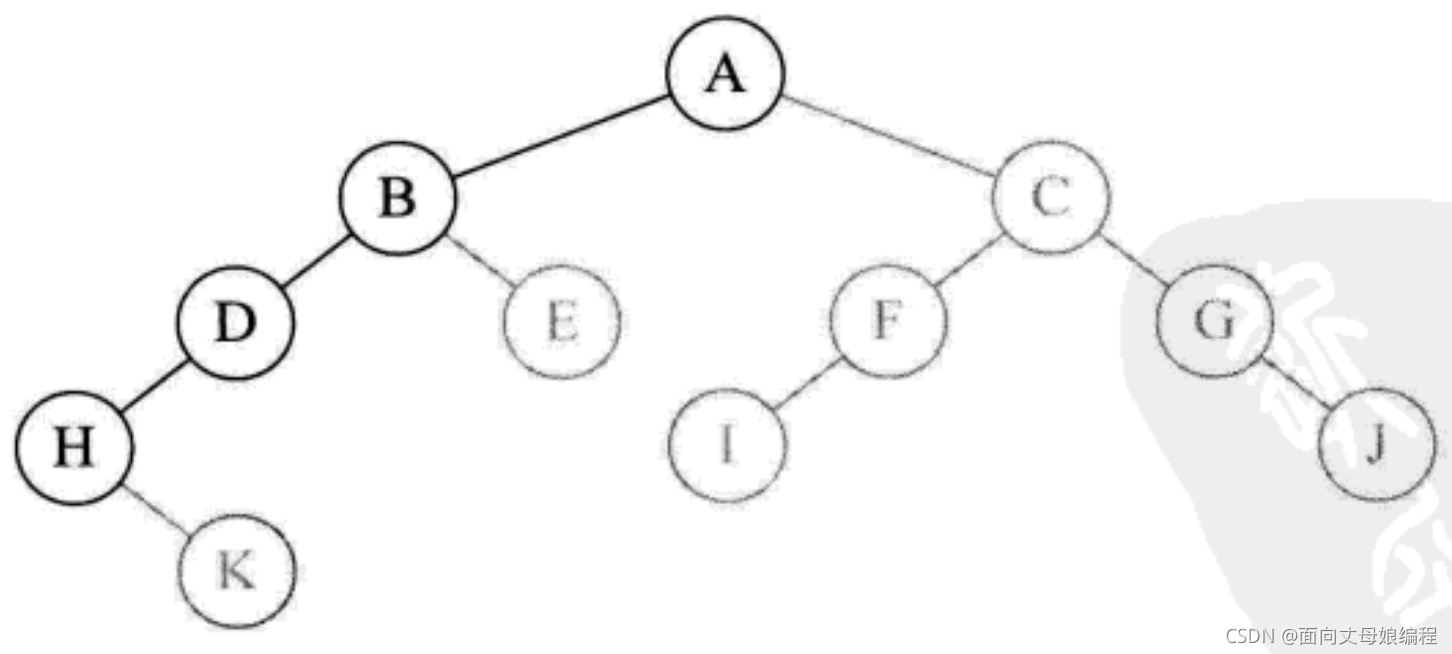
- �ٴεݹ����
preOrderTraversal(root.left), ����H �ڵ������, ��ʱ��Ϊ H �ڵ�������, ����root == null���ش˺�, ��ʱ�ݹ����preOrderTraversal(root.right);������ H �ڵ���Һ���, ִ��System.out.print(root.val + " ");��ӡ��ĸ K
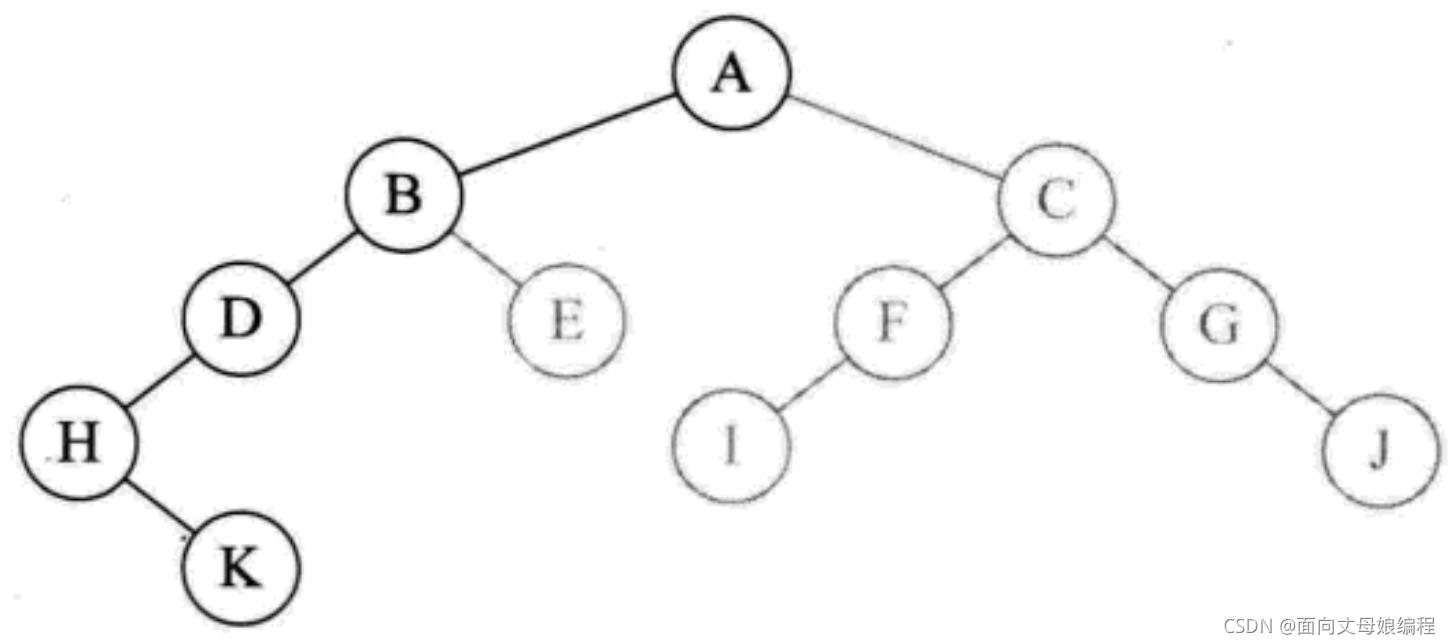
- �ٴεݹ����
preOrderTraversal(root.left), ���� K �ڵ������, ����
����preOrderTraversal(root.right), ������ K �ڵ���Һ���, Ҳ�� null, ����.���Ǻ���ִ�����.
���ص���һ���ݹ�ĺ���(����ӡ H �ڵ�ʱ�ĺ���), Ҳִ�����.[�����Ҷ��Ѿ�������, ����ִ�����]
���ش�ӡ D �ڵ�ʱ�ĺ���, ����preOrderTraversal(root.ri ght)���� D �ڵ���Һ���, ������
���ص� B �ڵ�, ����preOrderTraversal(root.right), ���� B �ڵ���Һ���, ��ӡ��ĸ E
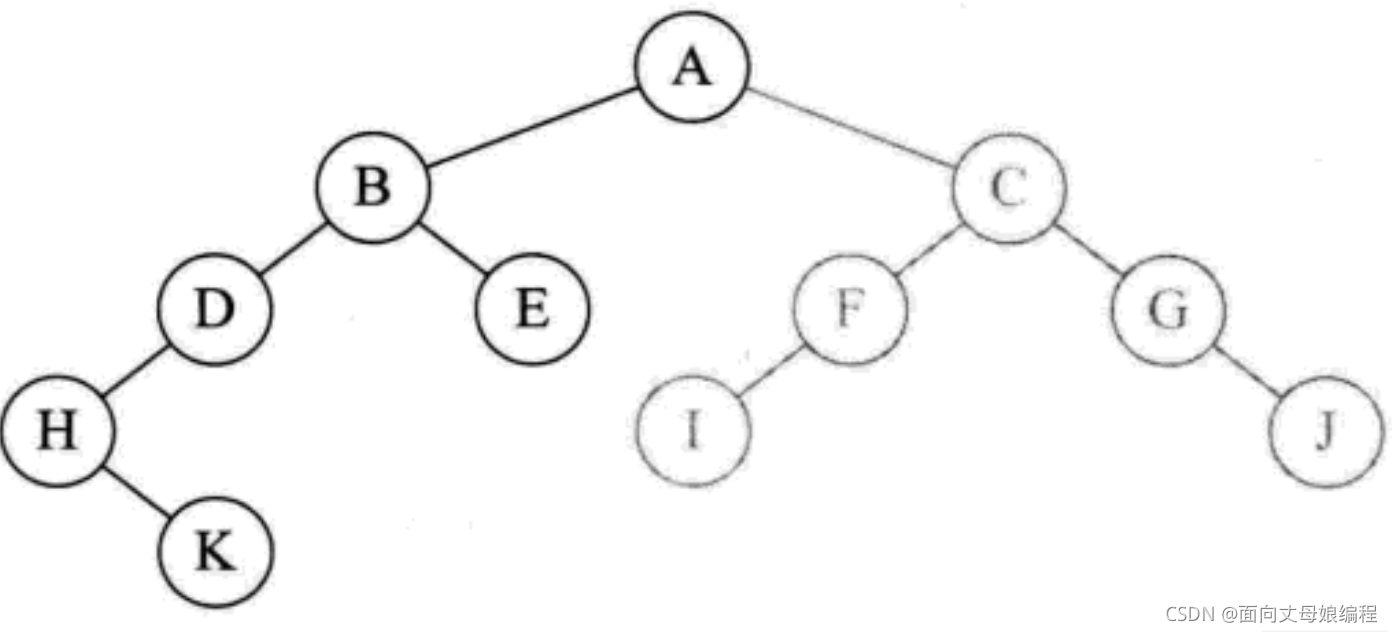
- ���ڽڵ� E û�����Һ���, ���ش�ӡ�ڵ� B ʱ�ĵݹ麯��, �ݹ�ִ�����. ���ص������
preOrderTraversal(root), ����preOrderTraversal(root.right), ���� A �ڵ���Һ���, ��ӡ��ĸ C
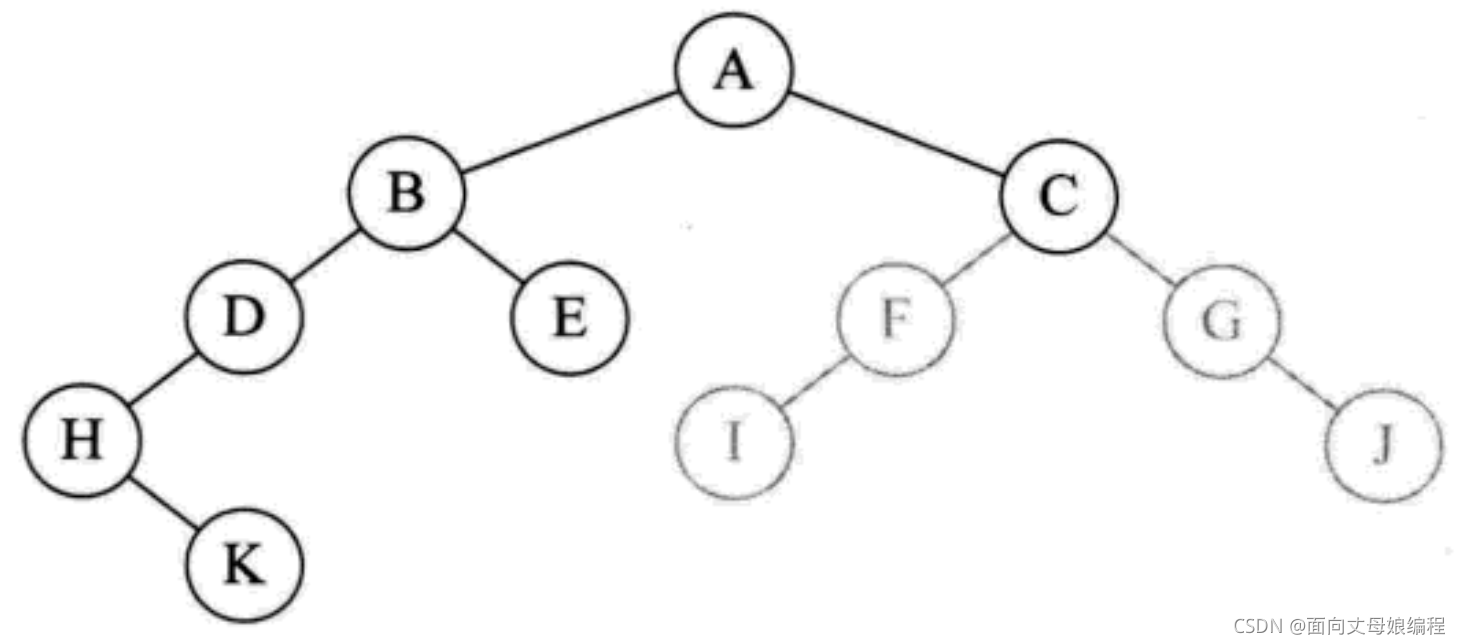
- ֮������ǰ��ĵݹ����, һ�μ�����ӡF, I, G, j
֪���˵ݹ�Ĵ����������, �������ٿ����ǵݹ�ʵ��ǰ�����
/*
�ǵݹ�
1.�ȴ���һ��ջ
2.���ڵ�Ž�ջ��
3.ѭ��ȡջ��Ԫ��
4.��ջ���������Ԫ��ֵ��
5.�ѵ�ǰԪ�ص���������ջ, ����������ջ����Ϊ�ȴ�ӡ���������ӡ���������Զ���ջ����Ӧ������������������������
*/
private static void preOrderTraversalNo(BinaryTreeNode root) {
if (root == null) {
return;
} else {
Stack<BinaryTreeNode> stack = new Stack<>();
stack.push(root);
while (!stack.empty()) {
BinaryTreeNode top = stack.pop();
System.out.print(top.val + " ");
if (top.right != null) {
stack.push(top.right);
}
if (top.left != null) {
stack.push(top.left);
}
}
}
}
A B D H K E C F I G J
��ʾ����ǰ���������
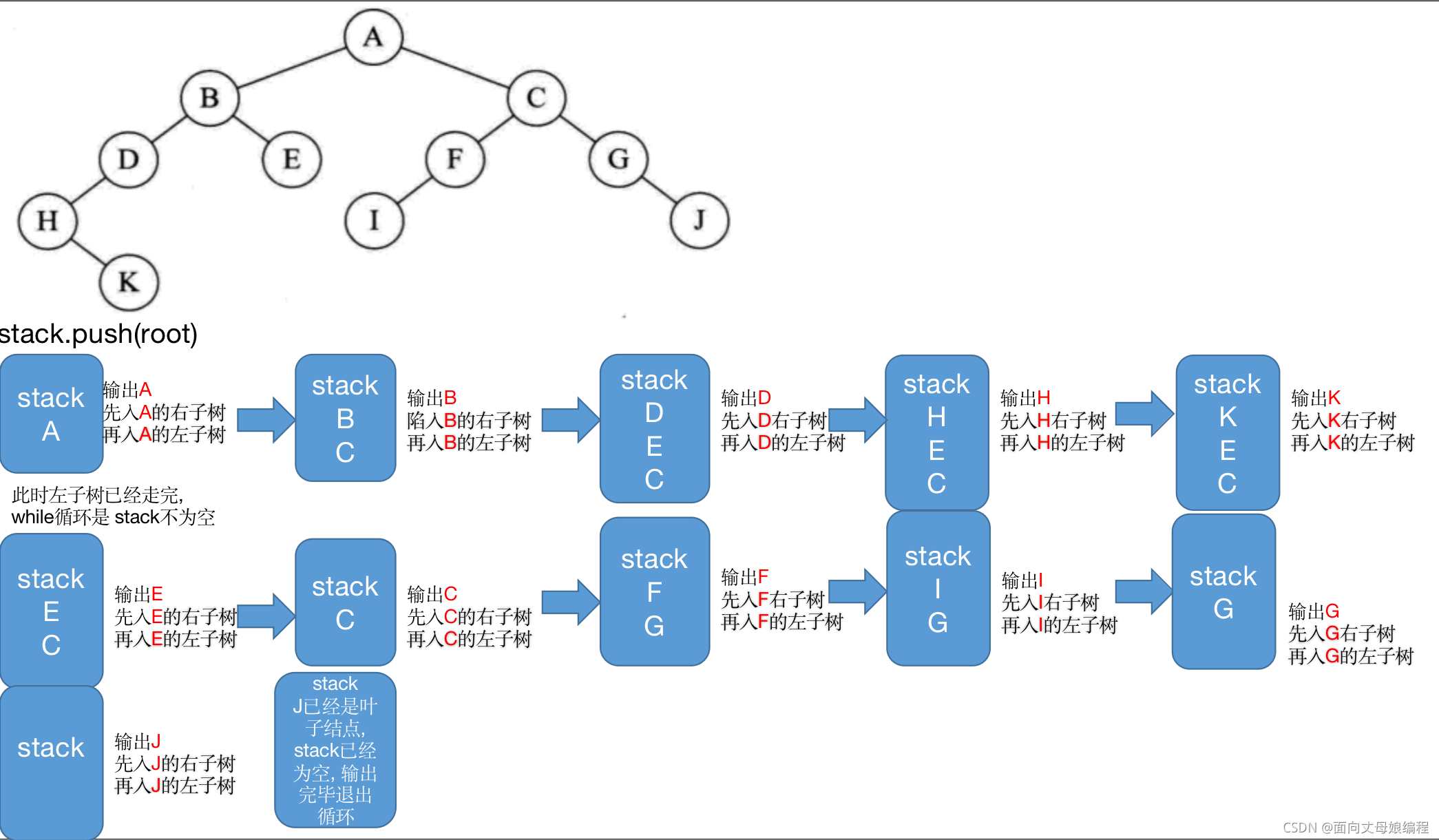
�ǵݹ�˼·�������������ջ���Ƚ�������Խ���ǰ�����
3.1.3.2 ��������㷨�����
OJ��Ŀ����
�ݹ��������
private static void inOrderTraversal(BinaryTreeNode root) {
if (root == null) {
return;
} else {
preOrder(root.left);
System.out.print(root.val + " ");
preOrder(root.right);
}
}
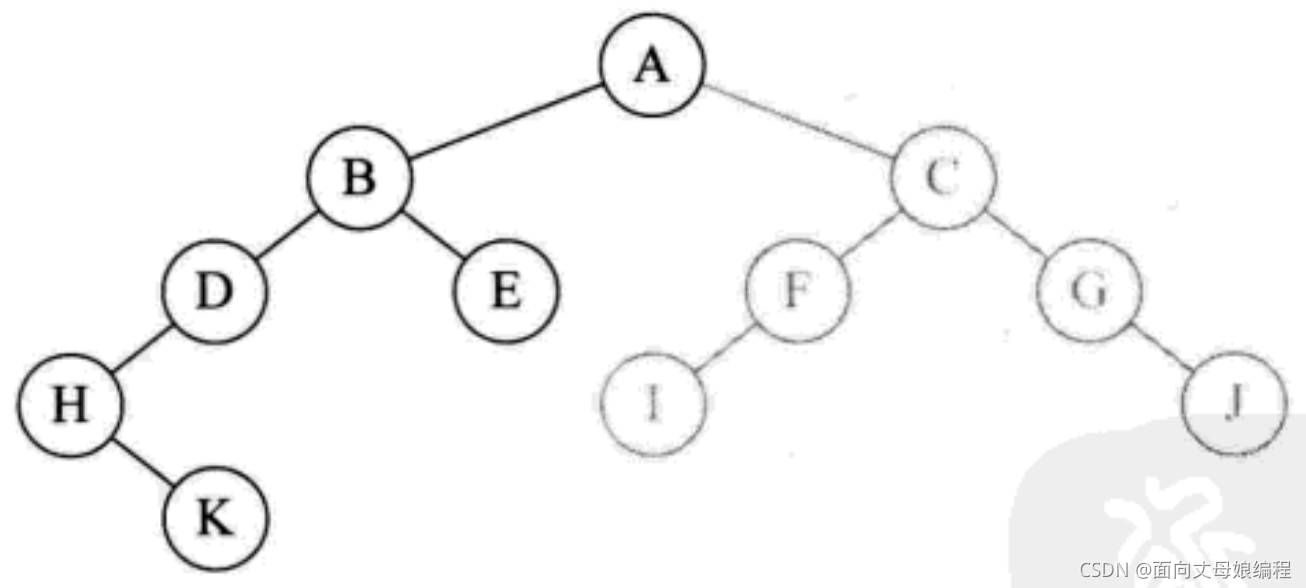
H K D B E A I F C G J
��ʾ�ݹ������������
- ����
inOrderTraversal(BinaryTreeNode root), root �ĸ��ڵ� A ��Ϊ null, ���ǵ���inOrderTraversal(root.left), ���ʽڵ� B; B ��Ϊ��, ��������inOrderTraversal(root.left), ���ʽڵ� D; D ��Ϊ��, ��������inOrderTraversal(root.left), ���ʽڵ� H; H ��Ϊ��, ��������inOrderTraversal(root.left), ���ʽڵ� H������; Ϊ��, ����. ��ӡ��ǰ�ڵ� H
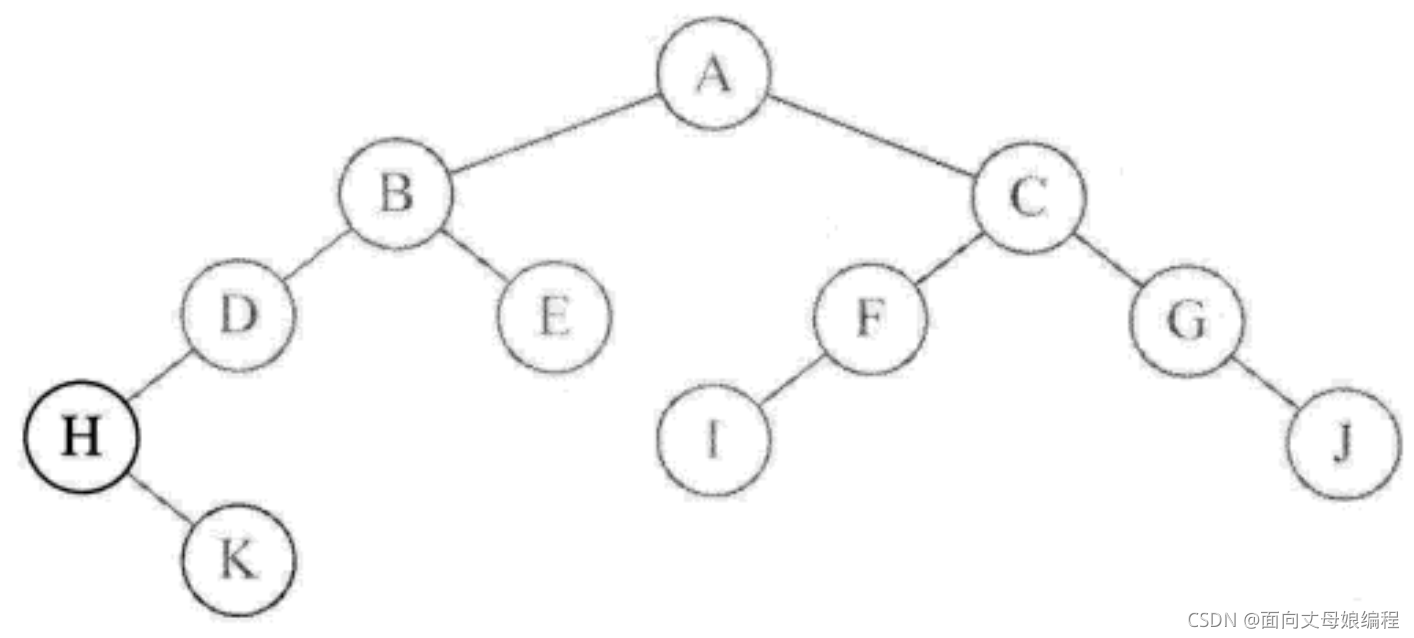
- Ȼ�����
inOrderTraversal(root.right), ���� H �ڵ���ҽڵ� K.��Ϊ K ������, ���Դ�ӡ K
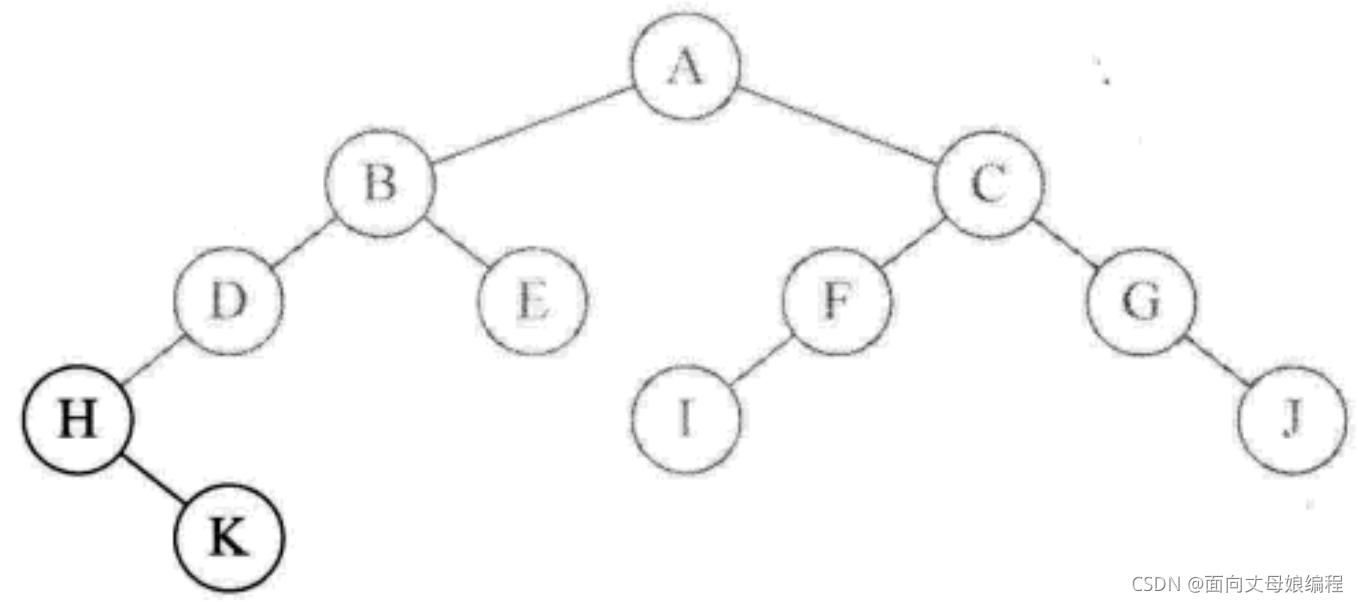
- ��Ϊ K û���ҽڵ�, ���Է���. ��ӡ H �ڵ�ĺ���ִ�����, ����. ��ӡ��ĸ D
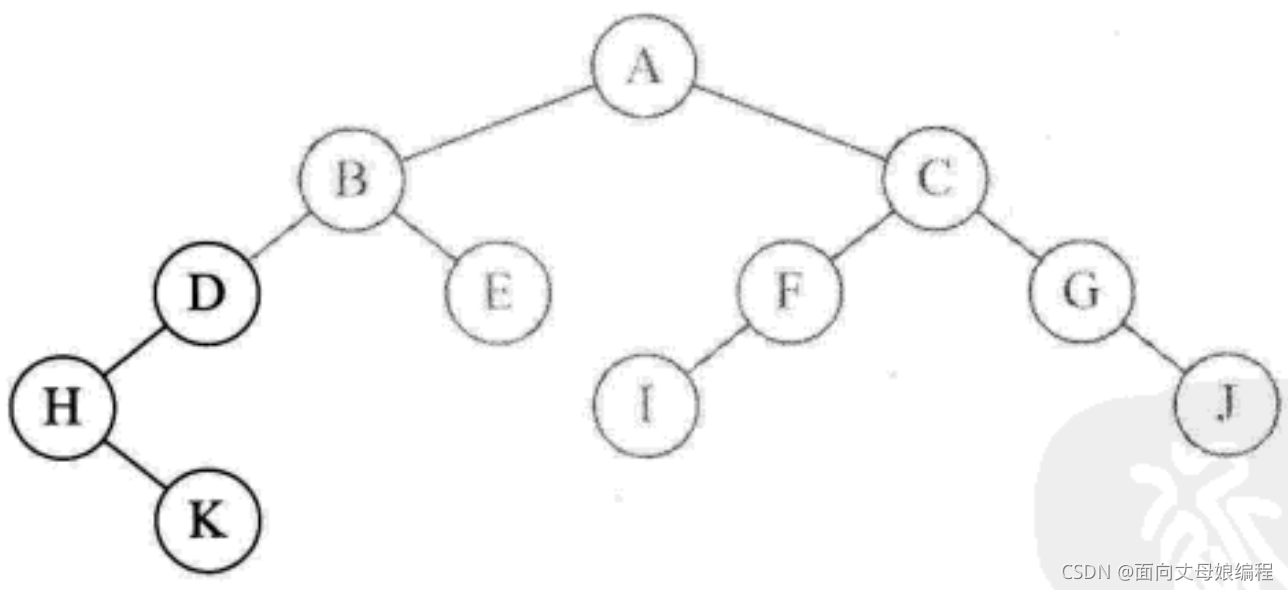
- �ڵ� D û���Һ���, ���Է���. ��ӡ B
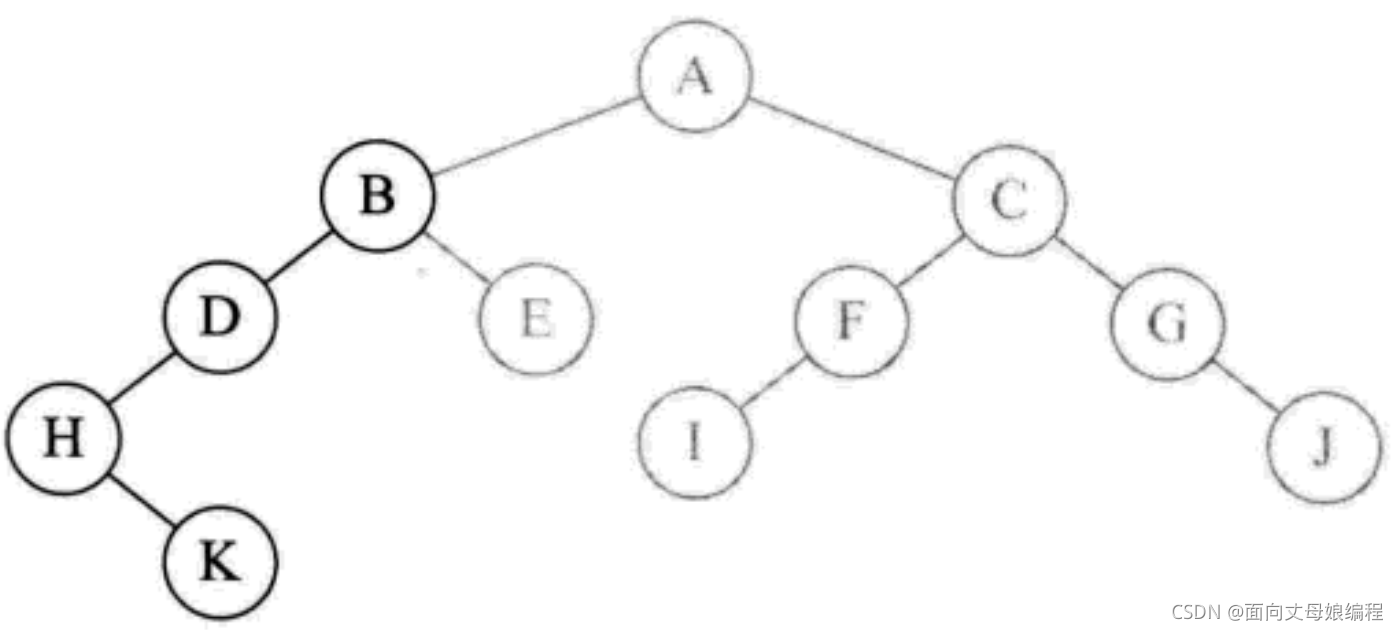
- ����
inOrderTraversal(root.right), ���� B �ڵ���ҽڵ� E, ��Ϊ E û������, ���Դ�ӡ E
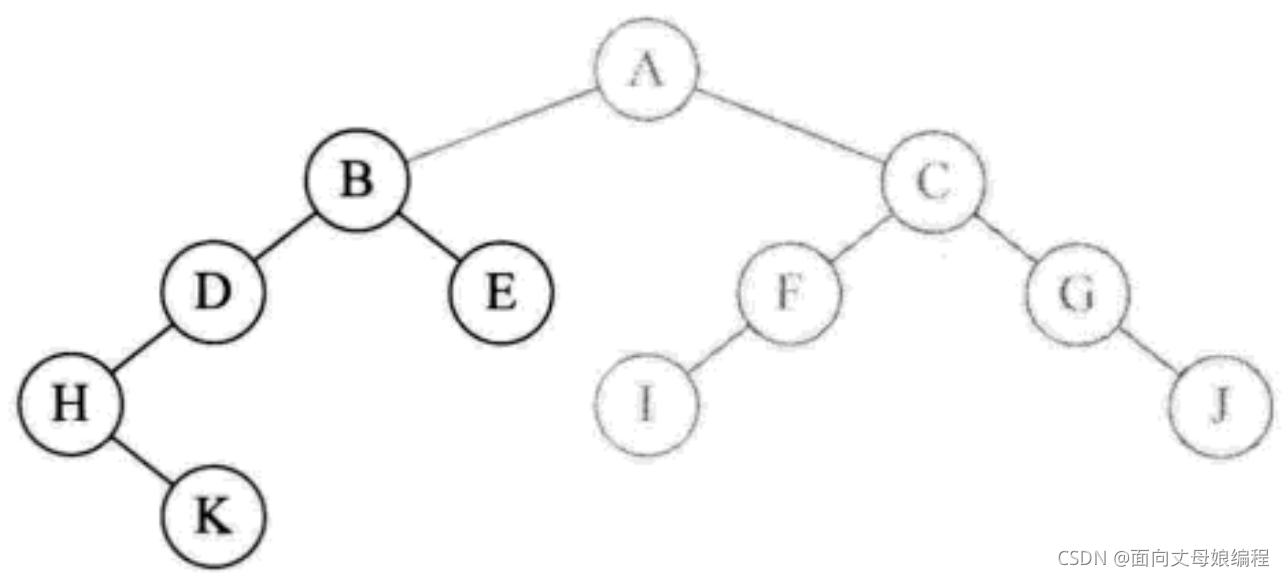
- �ڵ� E ���Һ���, ����. ��ӡ B �ĺ���ִ�����, ���ص����������ִ��
inOrderTraversal(root)�ĵط�, ��ӡ��ĸ A
- ����
inOrderTraversal(root.right), ���� A �ڵ���Һ���C,�ٵݹ���� C ������ F, F ������ I, ��Ϊ I ���Һ���, ���Դ�ӡ I. ֮��ֱ��ӡ F, C, G, J
�����������
/*
1.�ȴ���һ��ջ
2.���ڵ���ջ
3.ѭ��ȡջ��Ԫ��
4.������ ������ջ������������
5.����� while ѭ���ж���Ҫ����.��Ϊ cur= cur.right �ᵼ�� cur == nulll, ����ڼ���һ�� !stack.empty() ���ж�
*/
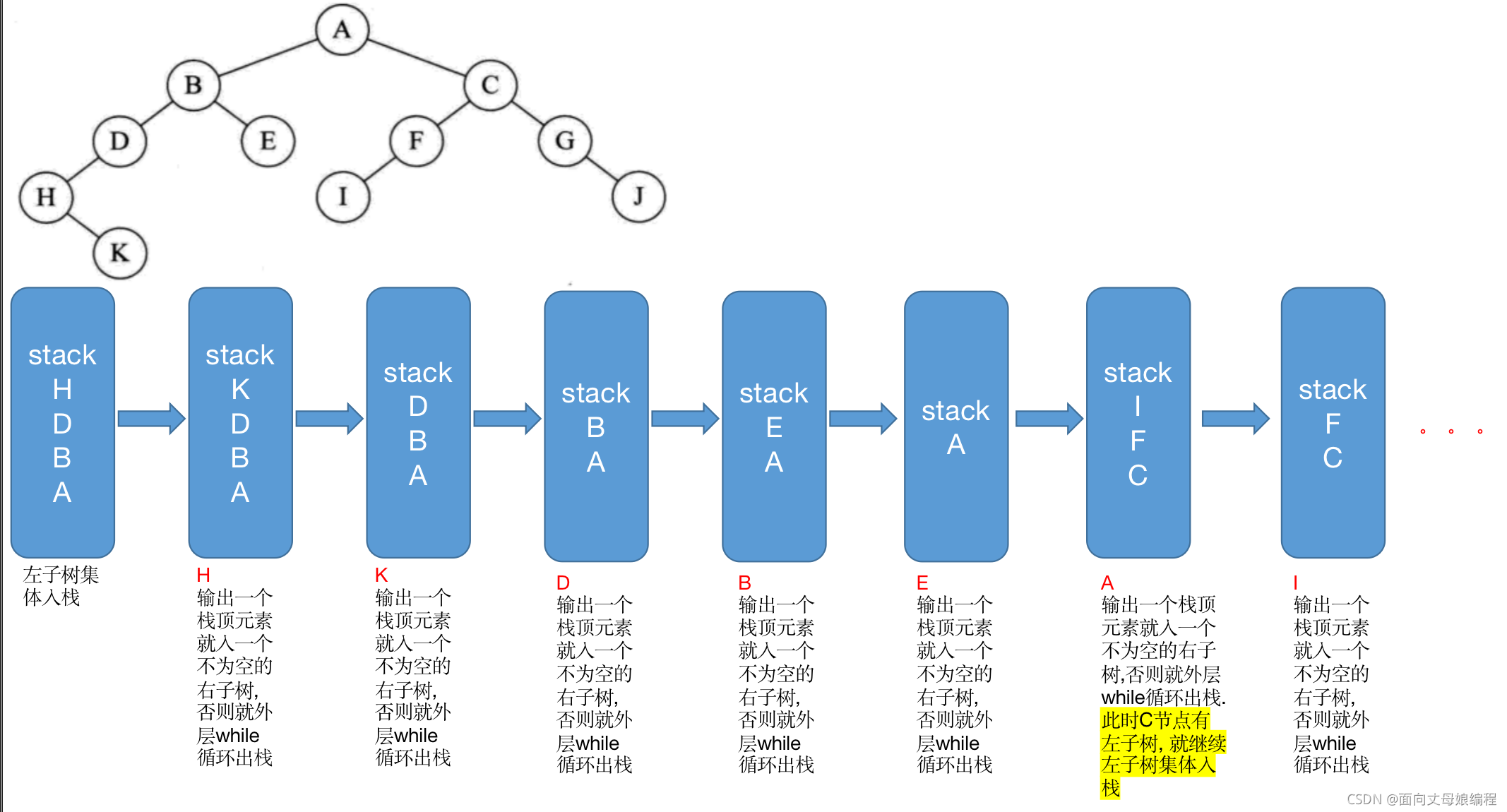
private static void inOrderTraversalNo(BinaryTreeNode root) {
if (root == null) {
return;
} else {
Stack<BinaryTreeNode> stack = new Stack<>();
BinaryTreeNode cur = root;
while (cur != null || !stack.empty()) {
while (cur != null) {
stack.push(cur);
cur = cur.left;
}
cur = stack.pop();
System.out.print(cur.val + " ");
cur = cur.right;
}
}
}
H K D B E A I F C G J
��ʾ���������������
3.1.3.2 ��������㷨���Ҹ�
OJ��Ŀ����
�ݹ�������
/*
OJ: ͨ��
*/
class Solution {
List<Integer> list = new ArrayList<>();
public List<Integer> postorderTraversal(TreeNode root) {
if(root == null){
return list;
}else{
postorderTraversal(root.left);
postorderTraversal(root.right);
list.add(root.val);
return list;
}
}
}
private static void postOrderTraversal(BinaryTreeNode root) {
if (root == null) {
return;
} else {
postOrderTraversal(root.left);
postOrderTraversal(root.right);
System.out.print(root.val + " ");
}
}
��ʾ�ݹ�����������
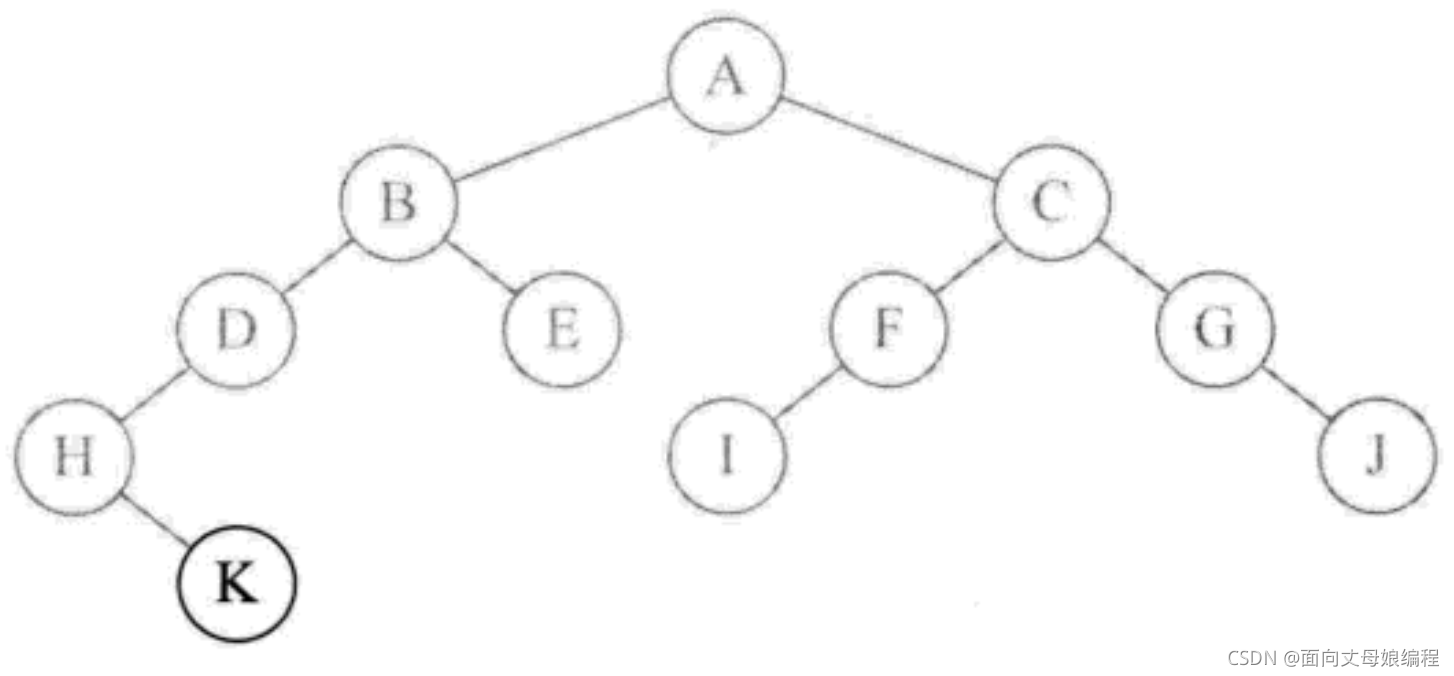
- ��������ȵݹ�������, �ɸ��ڵ� A->B->D->H, �ڵ� H ������, �ٲ鿴 H ���Һ��� K, ��Ϊ�ڵ� K �����Һ���, ������ӡ K.
- K��ӡִ����֮�ص�ִ�д�ӡ H �ij���
System.out.print(root.val + " ");, ��ӡ H �ڵ� - �����ķ�������Ͷ��ǿ����صĽڵ��������������Ƿ��������: �������˾�������ڵ�, ����ͼ�������
�����������
/*
�������������
1.���ѭ��������Ҫ���� !stack.empty()������ѭ��
2.����ӡ��Ľڵ���Ϊ null, �����жϸýڵ��Ƿ�ӡ��
3.�ж�
��ʱ
*/
private static void postOrderTraversalNo(BinaryTreeNode root) {
if (root == null) {
return;
} else {
Stack<BinaryTreeNode> stack = new Stack<>();
BinaryTreeNode cur = root;
BinaryTreeNode prev = null;
while (cur != null || !stack.empty()) {
while (cur != null) {
stack.push(cur);
cur = cur.left;
}
cur = stack.peek();
if (cur.right == null || cur.right == prev) {
stack.pop();
System.out.print(cur.val + " ");
prev = cur;
cur = null;
} else {
cur = cur.right;
}
}
}
}
K H D E B I F J G C A
��ʾ���������������

3.1.3.2 ��������㷨������, ������
class Solution {
public List<List<Integer>> levelOrder(TreeNode root) {
// 1.���ؿպ���
List<List<Integer>> list = new ArrayList<>();
if(root == null){
return list;
}else{
// 2.����
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
while(!queue.isEmpty()){
int size = queue.size();
List<Integer> tmp = new ArrayList<>();
while(size-- > 0){
TreeNode top = queue.poll();
tmp.add(top.val);
if(top.left != null){
queue.offer(top.left);
}
if(top.right != null){
queue.offer(top.right);
}
}
list.add(tmp);
}
return list;
}
}
}
[[A], [B, C], [D, E, F, G], [H, I, J], [K]]
��ʾOJ��ϰ���еĴ���ִ������
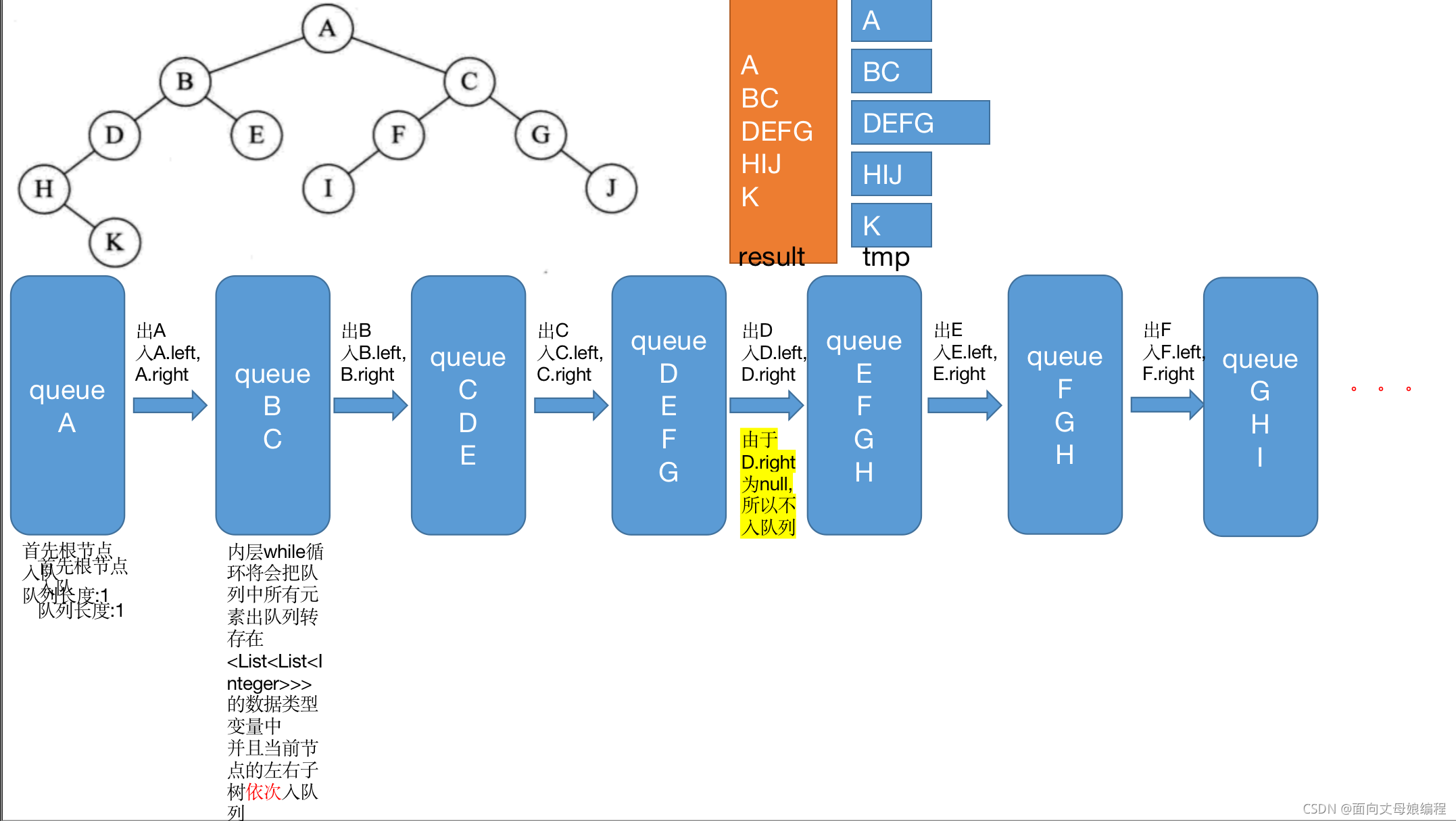
�����IJ������
/*
1.�ȴ���һ������
2.�Ѹ��ڵ���ڶ���
3.ѭ��ȡ����Ԫ��ȫ��
4.�ڲ� list ���� ��ǰԪ��
4.�ٰѵ�ǰԪ�ص������������, ����������
5.��� ret ����ÿ������Ԫ�غ�� list
*/
private static void levelOrder(BinaryTreeNode root) {
if (root == null) {
return;
} else {
Queue<BinaryTreeNode> queue = new LinkedList<>();
queue.offer(root);
while (!queue.isEmpty()) {
BinaryTreeNode top = queue.poll();
System.out.print(top.val + " ");
if (top.left != null) {
queue.offer(top.left);
}
if (top.right != null) {
queue.offer(top.right);
}
}
}
}
A B C D E F G H I J K
3.2 ��������������
3.2.1 ǰ������������
class Solution {
private int findInorderIndex(int[] inorder, int inbegin, int inend, int key){
for(int i=inbegin; i<=inend; ++i){
if(inorder[i] == key){
return i;
}
}
return -1;
}
private TreeNode buildTreeChild(int[] preorder, int[] inorder, int inbegin, int inend){
if(inbegin > inend){
return null;
}else{
TreeNode root = new TreeNode(preorder[preIndex++]);
int rootIndex = findInorderIndex(inorder, inbegin, inend, root.val);
root.left = buildTreeChild(preorder, inorder, inbegin, rootIndex-1);
root.right = buildTreeChild(preorder, inorder, rootIndex+1, inend);
return root;
}
}
private int preIndex = 0;
public TreeNode buildTree(int[] preorder, int[] inorder) {
if(preorder == null || inorder == null){
return null;
}else{
return buildTreeChild(preorder, inorder, 0, inorder.length-1);
}
}
}
��ʱ����������Ҳ�������˵ݹ��ԭ��. ֻ�����ڵ�����ӡ�ڵ�Ĵ��뻻�������ɽڵ�, ���ڵ㸳ֵ�IJ�������.
ǰ������ĵ�һ���ڵ�һ���� ���ڵ�, ������������������л��ָ��ڵ����������, Ȼ��ݹ��Ҹ��ڵ��ٻ�����������, �ݹ����ֹ������ �������һ��Ҫ�����������
����˼·:
- �ж�ǰ��������Ƿ���һ��Ϊ null���������������
- ����
buildTreeChild�������ظ��ڵ�- �ȹ�����ڵ�, �ٵݹ鹹����������������
- ���еݹ���֮������ root �������ĸ��ڵ�
��ʾͼ
- ��һ���ҵ���
preorder[preIndex]�ĸ��ڵ㡾preIndexֵΪ0��
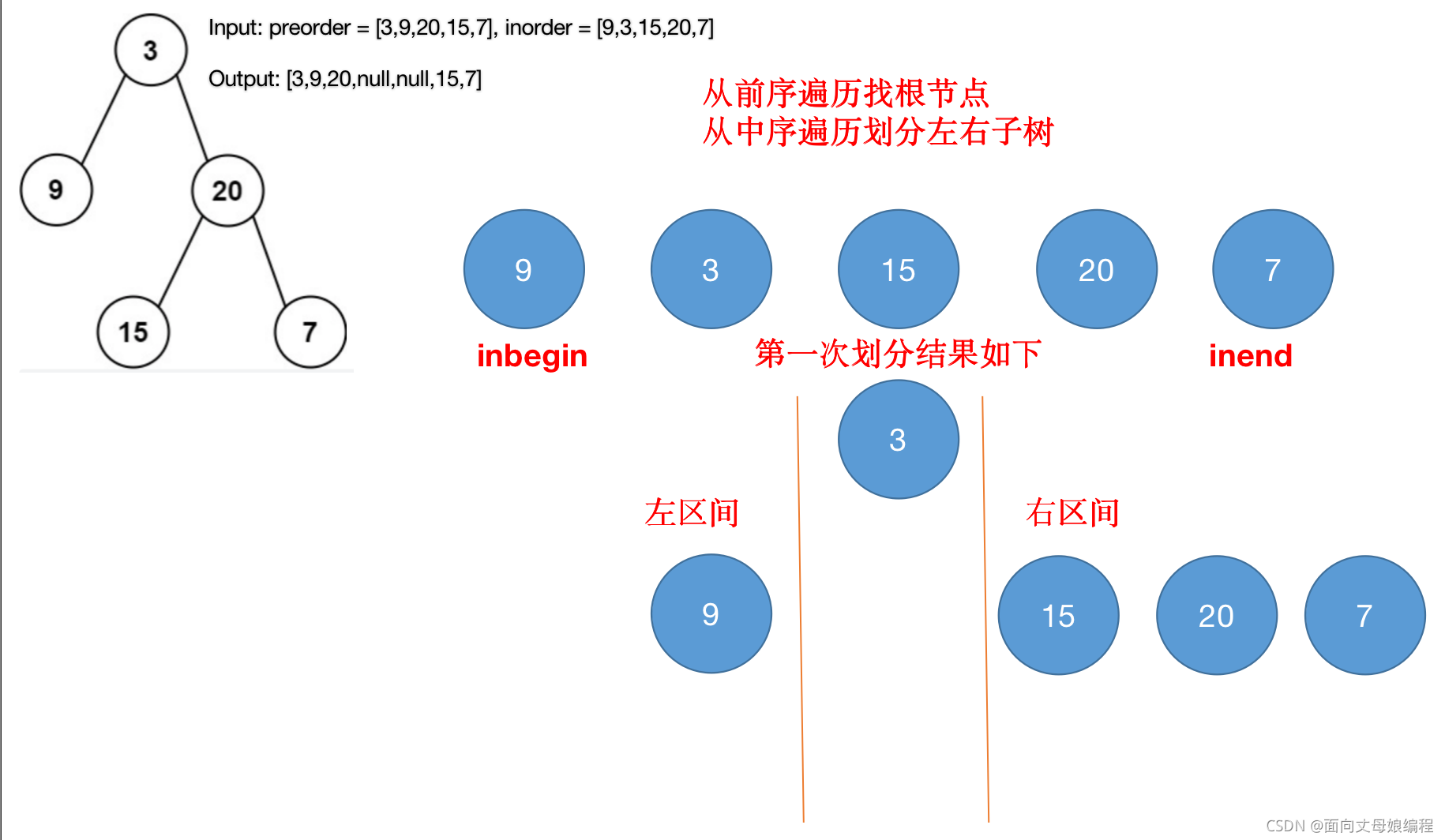
- ���ڵڶ��λ��ֵ�ʱ��, �µ� inend �� rootIndex-1 ���Ե��µ�
if(inbegin>inend) return;����ִ��root.right = buildTreeChild(preorder, inorder, rootIndex+1, inend);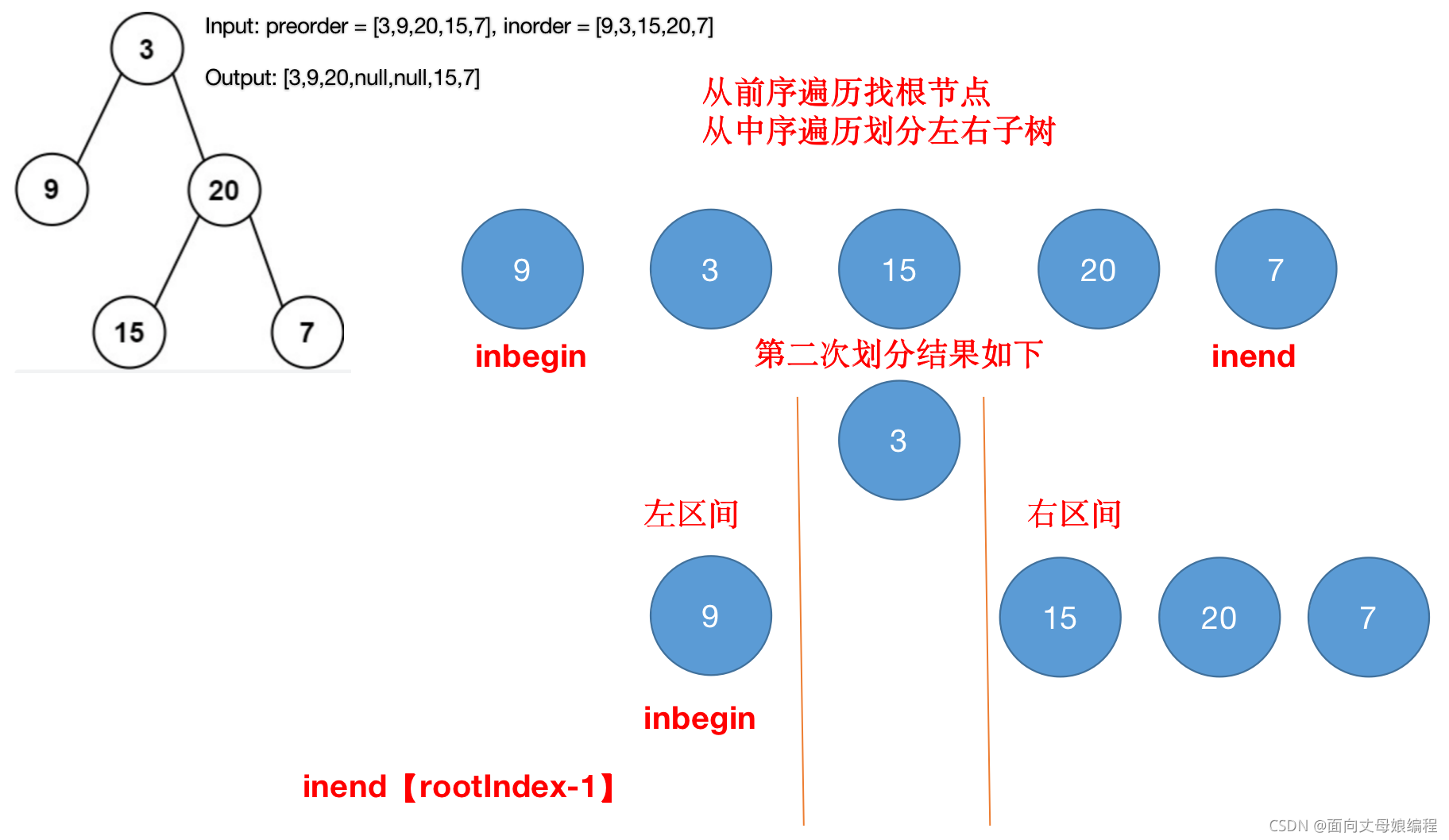
- �������
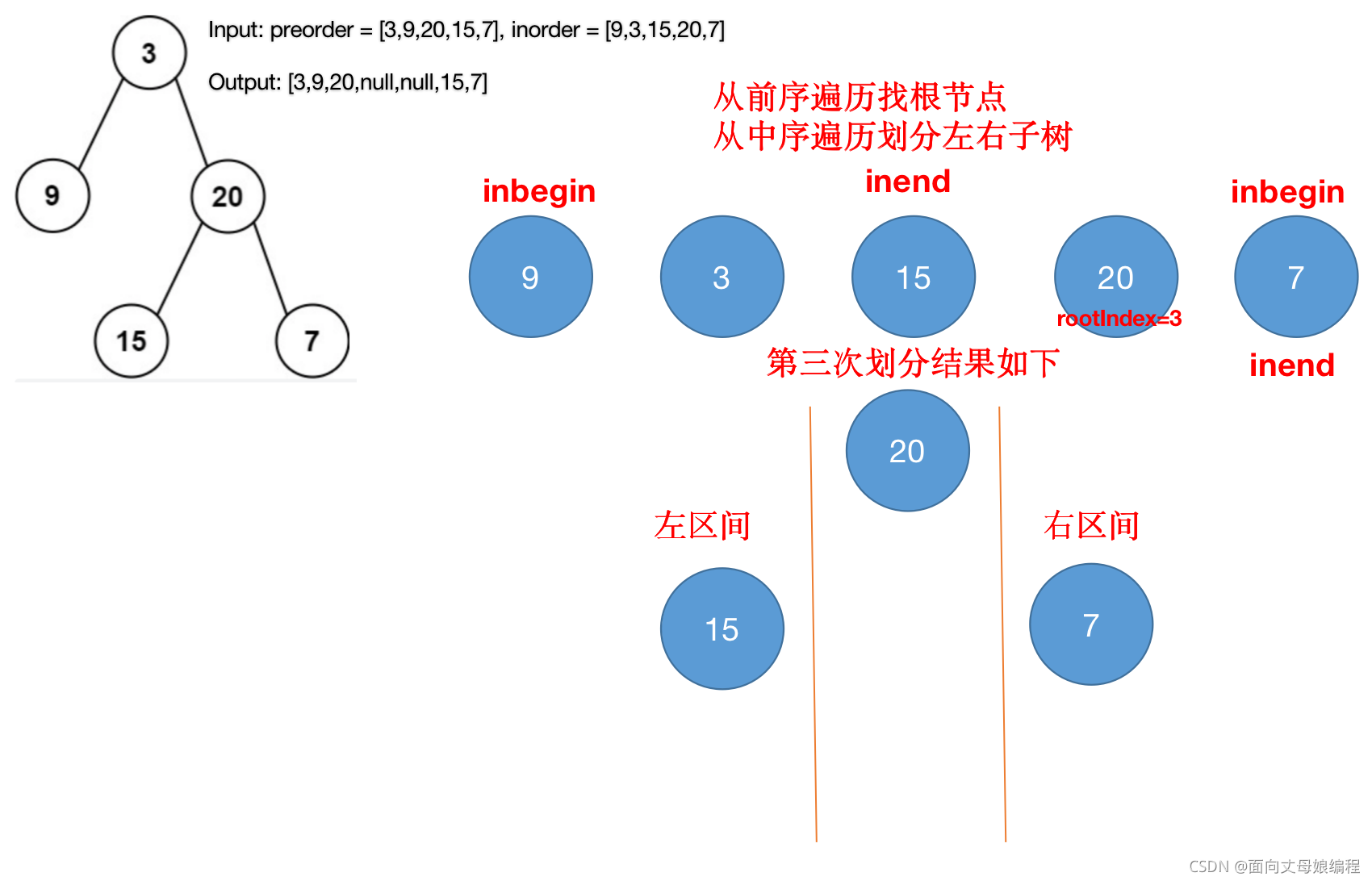
- �ۺ�
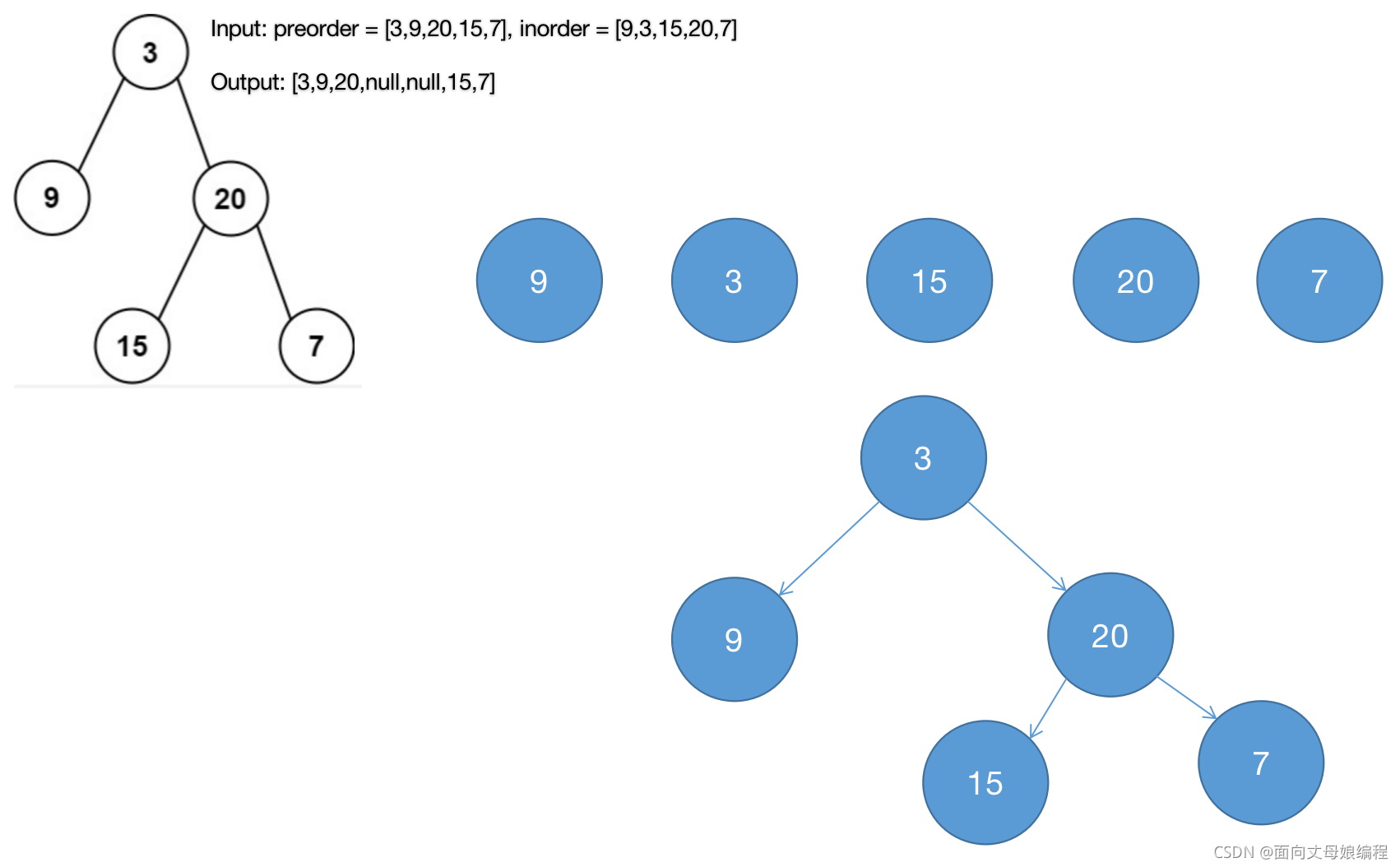
3.2.2 �������������
class Solution {
private int postIndex = 0;
private int findInorderIndex(int[] inorder, int inbegin, int inend, int key){
for(int i=inbegin; i<=inend; ++i){
if(inorder[i] == key){
return i;
}
}
return -1;
}
private TreeNode buildTreeChild(int[] inorder, int[] postorder, int inbegin, int inend){
if(inbegin > inend){
return null;
}else{
TreeNode root = new TreeNode(postorder[postIndex--]);
int rootIndex = findInorderIndex(inorder, inbegin, inend, root.val);
root.right = buildTreeChild(inorder, postorder, rootIndex+1, inend);
root.left = buildTreeChild(inorder, postorder, inbegin, rootIndex-1);
return root;
}
}
public TreeNode buildTree(int[] inorder, int[] postorder) {
if(inorder == null || postorder == null){
return null;
}else{
postIndex = postorder.length-1;
return buildTreeChild(inorder, postorder, 0, postIndex);
}
}
}
���������ǰ���һ���뷨һ��, ����Ӧ��ע��˳����������һ�Ǹ�, ��ǰ�������һ�����Ǹ���
��ʾͼ
��Ϊ�Ӻ���ǰ���Ļ�, ���ڵ���������ҽڵ�, �����ȹ����������ڹ���������. �����ݹ�˼·������һ��, ����Ͳ�����
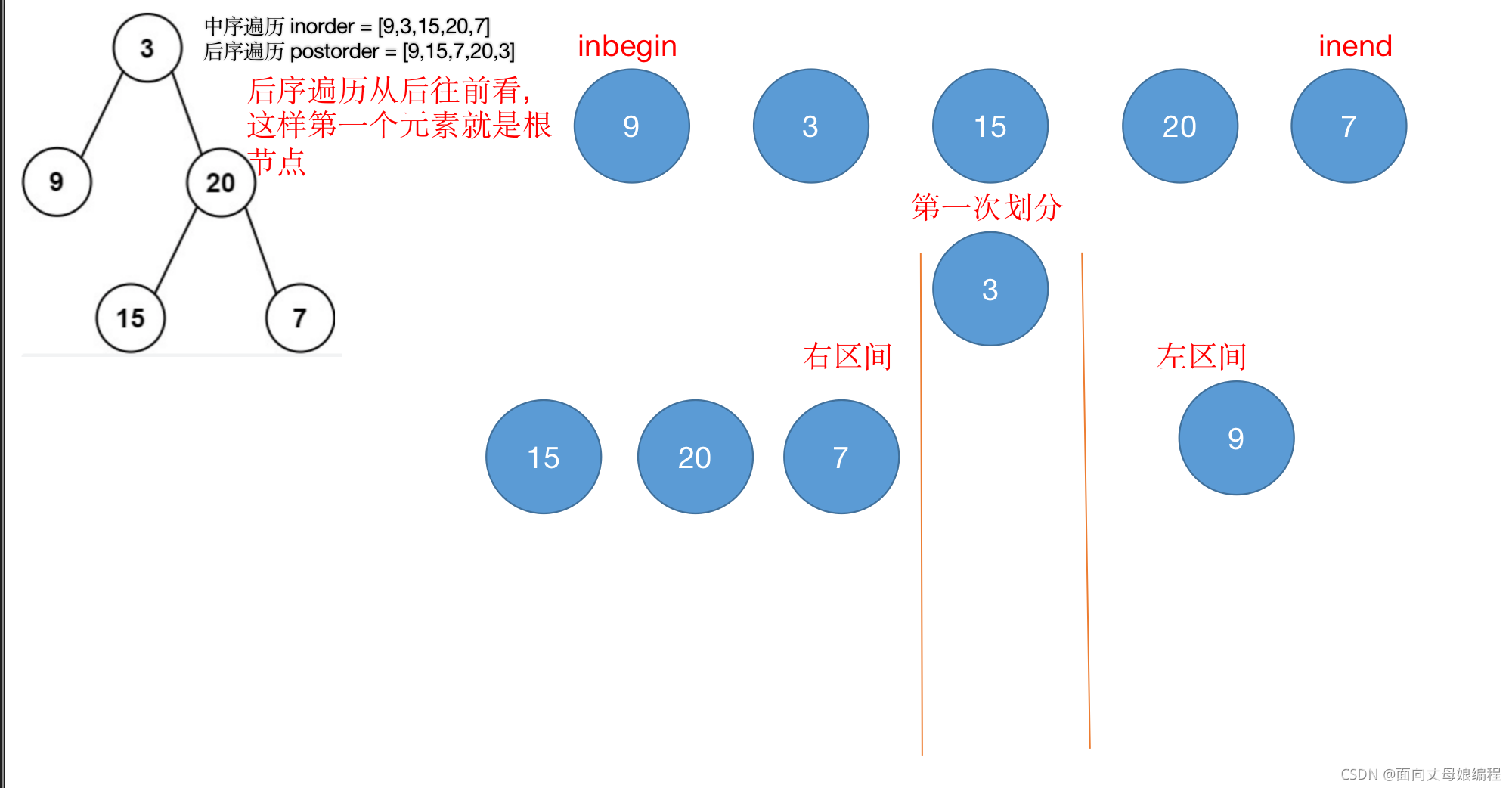
�ܽ��һ��������������
- ��֪ǰ��������������, ����ȷ��Ψһ��һ�Ŷ�����
- ��֪��������ͺ������, ����ȷ��Ψһ��һ�Ŷ�����
˼��: ��֪ǰ������ͺ�������ܷ�Ψһ��һ�Ŷ�����
����, ԭ��ܼ�. ����һ�ö�����ǰ�������ABC ��������� CBA ���ǿ���ȷ�����ڵ��� A ������ȷ�� A ����������. ������������µ����ֿ���
3.2.3 ���ݶ����������ַ���
�ⷨ1
- �ȴ���������, �ٴ���������
- ������ĿҪ�����һ��һ����������
class Solution {
private void tree2strChild(TreeNode root, StringBuffer stringBuffer){
if(root == null){
return;
}else{
stringBuffer.append(root.val);
// 1.����������
if(root.left == null){
if(root.right == null){
return;
}else{
stringBuffer.append("()");
}
}else{
stringBuffer.append("(");
tree2strChild(root.left, stringBuffer);
stringBuffer.append(")");
}
// 2.����������
if(root.right == null){
return;
}else{
stringBuffer.append("(");
tree2strChild(root.right, stringBuffer);
stringBuffer.append(")");
}
}
}
public String tree2str(TreeNode root) {
if(root == null){
return "";
}else{
StringBuffer stringBuffer = new StringBuffer();
tree2strChild(root, stringBuffer);
return stringBuffer.toString();
}
}
}
�ⷨ2
������, ��������, ������Ч�ʵ�
- �ݹ�ǰ���������ʽ��������
- �������֮����ɾ����һ�������һ�����ż���
class Solution {
private StringBuffer stringBuffer = null;
private void tree2strChild(TreeNode root){
if(root == null){
return;
}else{
stringBuffer.append("("+root.val);
tree2strChild(root.left);
if(root.left == null && root.right != null){
stringBuffer.append("()");
}
tree2strChild(root.right);
stringBuffer.append(")");
}
}
public String tree2str(TreeNode root) {
if(root == null){
return "";
}else{
stringBuffer = new StringBuffer();
tree2strChild(root);
stringBuffer.deleteCharAt(0);
stringBuffer.deleteCharAt(stringBuffer.length()-1);
return stringBuffer.toString();
}
}
}
3.2.4 ǰ������ַ�������������
import java.util.Scanner;
import java.util.Stack;
class TreeNode{
char val;
TreeNode left;
TreeNode right;
TreeNode(char val){
this.val = val;
}
}
public class Main{
// 1.���õ��ǵ����ķ�ʽ�����������
private static void inOrderTraversal(TreeNode root){
if(root == null){
return;
}else{
Stack<TreeNode> stack = new Stack<>();
TreeNode cur = root;
while(cur != null || !stack.empty()){
// 2. ������������ջ
while(cur != null){
stack.push(cur);
cur = cur.left;
}
cur = stack.pop();
System.out.print(cur.val + " ");
cur = cur.right;
}
}
}
private static int index = 0;// ��¼��ӡ���ַ����±�, ��Ϊ�ǵݹ�, ����Ӧ��ʹ��ȫ�ֱ��������Ǿֲ�����
private static TreeNode createTree(String str){
if(str == null){
return null;
}else{
TreeNode root = null;
// 1.Խ���սڵ�
if(str.charAt(index) == '#'){
++index;
}else{
// 2. ����ǰ������ҵ���ʽ�ݹ鹹��������
root = new TreeNode(str.charAt(index++));
root.left = createTree(str);
root.right = createTree(str);
}
return root;
}
}
public static void main(String[] args){
Scanner scanner = new Scanner(System.in);
while(scanner.hasNext()){
String str = scanner.next();
TreeNode root = createTree(str);
inOrderTraversal(root);
System.out.println();
}
}
}
3.2.5 �ϲ�������
class Solution {
public TreeNode mergeTrees(TreeNode root1, TreeNode root2) {
// 1.���ij���ڵ�Ϊnull, ����һ���ڵ�
if(root1 == null){
return root2;
}else if(root2 == null){
return root1;
}else{
// 2.��������ڵ㶼��Ϊnull, ��ʼ�ϲ�������
TreeNode root = new TreeNode(root1.val+root2.val);
root.left = mergeTrees(root1.left, root2.left);
root.right = mergeTrees(root1.right, root2.right);
return root;
}
}
}
3.2.6 ����������
class Solution {
private TreeNode cur = null;
private void inOrderTraversal(TreeNode root){
if(root == null){
return;
}else{
//1.��
inOrderTraversal(root.left);
// 2.��
cur.right = root;
root.left =
// 3.��
inOrderTraversal(root.right);
}
}
public TreeNode increasingBST(TreeNode root) {
if(root == null){
return null;
}else{
// 1.���ܽڵ���������cur�ڵ��λ�����ڷ���
TreeNode newRoot = new TreeNode(-1);
// 2.�ƶ��ڵ�
cur = newRoot;
inOrderTraversal(root);
return newRoot.right;
}
}
}
3.3 ������Ŀ����
3.3.1 ������
/*
�������
����˼·: �ݹ�ÿ�α��������� 1[���� OJ ���ܻᷭ��: ����һ��С������ gerSize1 ����, Ȼ������һ������������� getSize1]
������˼·: return 1+func()...�Դ�����ֵ
*/
private static int size = 0;
private static void getSize1(BinaryTreeNode root) {
if (root == null) {
return;
} else {
++size;
getSize1(root.left);
getSize1(root.right);
}
}
private static int getSize2(BinaryTreeNode root) {
if (root == null) {
return 0;
} else {
return 1 + getSize2(root.left) + getSize2(root.right);
}
}
3.3.2 Ҷ�ӽ�����
/*
��Ҷ�ӽ�����
����˼·: �ݹ����
������˼·: return 1+func()...
*/
private static int leaftSize = 0;
private static void getLeafSize1(BinaryTreeNode root) {
if (root == null) {
return;
} else {
if (root.left == null && root.right == null) {
++leaftSize;
} else {
getLeafSize1(root.left);
getLeafSize1(root.right);
}
}
}
private static int getLeafSize2(BinaryTreeNode root) {
if (root == null) {
return 0;
} else {
if (root.left == null && root.right == null) {
return 1;
} else {
return getLeafSize2(root.left) + getLeafSize2(root.right);
}
}
}
3.3.3 ��k�������
private static int getKLevelSize(BinaryTreeNode root, int k) {
if (root == null || k < 1) {
return 0;
} else {
if (k == 1) {
return 1;
} else {
return getKLevelSize(root.left, k - 1) + getKLevelSize(root.right, k - 1);
}
}
}
3.3.4 ���� val ���ڽ��
private static BinaryTreeNode find(BinaryTreeNode root, String val) {
if (root == null) {
return null;
} else {
if (root.val.equals(val)) {
return root;
} else {
BinaryTreeNode ret = find(root.left, val);
if (ret != null && ret.val.equals(val)) {
return ret;
}
ret = find(root.right, val);
if (ret != null && ret.val.equals(val)) {
return ret;
}
return null;
}
}
}
3.3.5 ��ͬ����
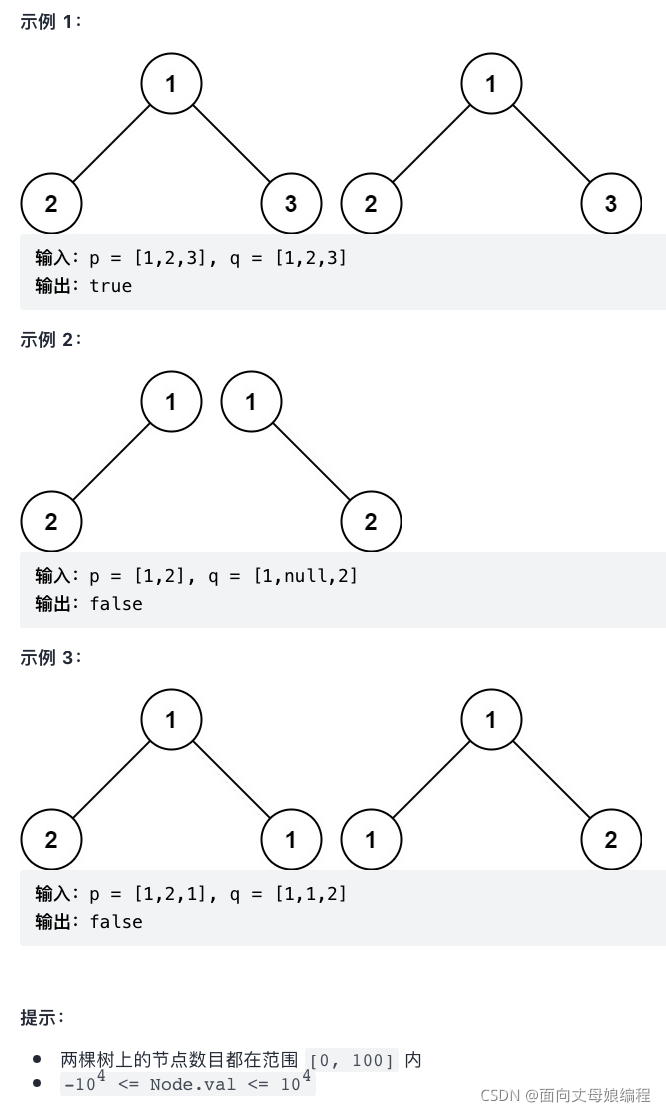
class Solution {
public boolean isSameTree(TreeNode p, TreeNode q) {
// 1.��Ϊnull: ˵��֮ǰ�Ľڵ�ͽڵ�ֵ���, �������; ���������սڵ�Ҳ����ȵ�
if(p == null && q == null){
return true;
// 2.ij���ڵ�������˵���һ���ڵ㲻Ϊnull, ������false
}else if(p == null || q == null){
return false;
}else{
// 3�ڵ�ֵ����Ⱦ� false
if(p.val != q.val){
return false;
}else{
// 4. �ݹ������һ�αȽ�
return isSameTree(p.left, q.left) && isSameTree(p.right, q.right);
}
}
}
3.3.6 ��һ��������
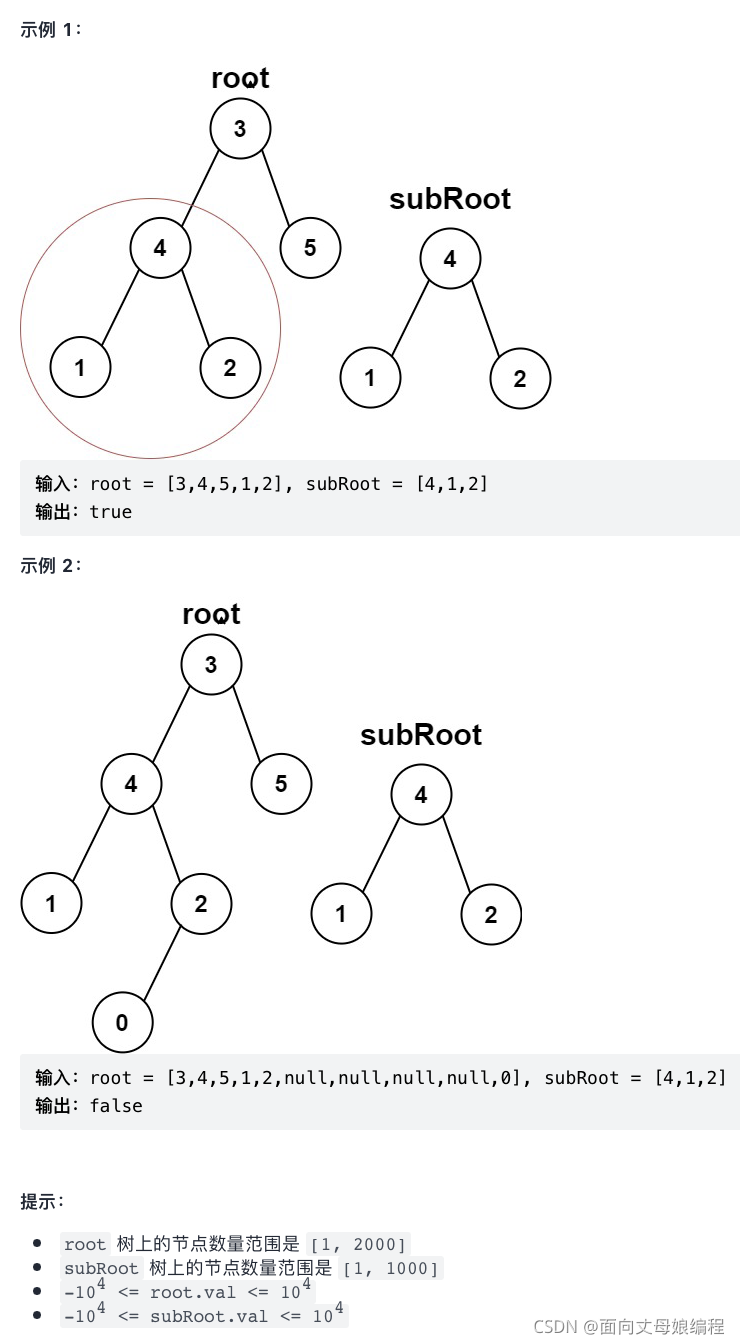
class Solution {
public boolean isSameTree(TreeNode p, TreeNode q) {
// 1.��Ϊnull: ˵��֮ǰ�Ľڵ�ͽڵ�ֵ���, �������; ���������սڵ�Ҳ����ȵ�
if(p == null && q == null){
return true;
// 2.ij���ڵ�������˵���һ���ڵ㲻Ϊnull, ������false
}else if(p == null || q == null){
return false;
}else{
// 3�ڵ�ֵ����Ⱦ� false
if(p.val != q.val){
return false;
}else{
// 4. �ݹ������һ�αȽ�
return isSameTree(p.left, q.left) && isSameTree(p.right, q.right);
}
}
}
public boolean isSubtree(TreeNode root, TreeNode subRoot) {
// 1.���� nullnull ��������; ��������Ҷ�ӽ�����������Ȼ�����ڡ�, ˵��֮ǰ�����Ķ�����ȵ�
if(root == null && subRoot == null){
return true;
}else if(root == null && subRoot != null || root != null && subRoot == null){
return false;
}else{
// 1.��������ڵ㲻Ϊ��, �����, ��������
if(isSameTree(root, subRoot)){
return true;
// 2.�ݹ��ж��Ƿ�Ϊ����
}else if(isSubtree(root.left, subRoot)){
return true;
}else if(isSubtree(root.right, subRoot)){
return true;
}else{
return false;
}
}
}
}
3.3.7 ������������

class Solution {
public int maxDepth(TreeNode root) {
if(root == null){
return 0;
}else{
// 1.�����������ĸ߶�
int left = maxDepth(root.left)+1;
// 2.�����������ĸ߶�
int right = maxDepth(root.right)+1;
if(left>right){
return left;
}else{
return right;
}
}
}
}
3.3.8 ƽ�������
class Solution {
private int maxDepth(TreeNode root){
if(root == null){
return 0;
}else{
int left = 1+maxDepth(root.left);
int right = 1+maxDepth(root.right);
return left>right?left:right;
}
}
public boolean isBalanced(TreeNode root) {
if(root == null){
return true;
}else{
int left = maxDepth(root.left);
int right = maxDepth(root.right);
if(Math.abs(left-right)>1){
return false;
}else{
return isBalanced(root.left) && isBalanced(root.right);
}
}
}
}
// 1. �Ż���Ĵ���: ����߶ȱ������������߶Ȳ�, ���õݹ�����
class Solution {
private int maxDepth(TreeNode root){
if(root == null){
return 0;
}else{
int left = maxDepth(root.left);
int right = maxDepth(root.right);
if(left >= 0 && right >= 0 && Math.abs(left-right)<=1){
return Math.max(left, right)+1;
}else{
return -1;
}
}
}
public boolean isBalanced(TreeNode root) {
return maxDepth(root) > -1;
}
}
3.3.9 �Գƶ�����

class Solution {
private boolean isSameTree(TreeNode leftTree, TreeNode rightTree) {
if (leftTree == null && rightTree == null) {
return true;
} else if (leftTree != null && rightTree == null || leftTree == null && rightTree != null) {
return false;
} else {
if (leftTree.val != rightTree.val) {
return false;
} else {
/*
1. ֮ǰ���жϲ���� �Ƚ϶������Ƿ���ͬ �е�����
2. ֮��Ӧ�ñȽ� �������� �� ��������; �������� �� �������� �Ƿ���ͬ
*/
return isSameTree(leftTree.left, rightTree.right) && isSameTree(leftTree.right, rightTree.left);
}
}
}
public boolean isSymmetric(TreeNode root) {
if (root == null) {
return true;
} else {
return isSameTree(root.left, root.right);
}
}
}
3.3.10 ����������ȫ�Լ���

���ö������Խ���ȫ�������(���� null �ڵ�)�ٽ��г������ж�
/*
1. ������ null �ڵ�ʱ��˵���Ѿ�����������ȫ���������˳�
2. �ڶ���ĩβ��������Ԫ��, ��������˲�Ϊ null ��˵������һ����ȫ������
*/
class Solution {
public boolean isCompleteTree(TreeNode root) {
if(root == null){
return true;
}else{
Queue<TreeNode> queue = new LinkedList<>();
queue.offer(root);
// 1.ֱ������ null �ڵ��ֹͣ�����
while(!queue.isEmpty()){
TreeNode top = queue.poll();
if(top != null){
queue.offer(top.left);// �����ߵ�Ҷ�ӽ��, ���� null �ڵ�Ҳ�������, ������ peekpeek ̽���ʱ����������˲�Ϊ null �Ľڵ�Ļ��ʹ��������� null �ڵ�֮��������Ҷ�ӽ��, ��ʱһ��������ȫ������
queue.offer(top.right);
}else{
break;
}
}//����ִ�е����, ˵���������Ѿ��洢���еĽڵ�
// 2.�ڵ������, peek̽��Ԫ���Ƿ�Ϊ null
while(!queue.isEmpty()){
TreeNode top = queue.peek();
if(top != null){
return false;
}else{
queue.poll();//������
}
}
return true;
}
}
}
�Ż�: ��Ч��ͨ���ԱȽڵ������±����ж�
class Solution {
private int n=0, p=0;
private boolean dfs(TreeNode root, int k){
if(root == null){
return true;// 1.�ڵ�������
}else if(k > 100){
return false;// 2.��Ŀ��ʾ: ���н����� 1 �� 100 �����
}else{
++n;// 3.ÿ����һ��, ������������һ, ��¼��ǰ�ڵ��±�
p = Math.max(p, k);// 4.��Ϊ����������, ����ÿ��Ӧ��ѡȡ����±�ſ�
return dfs(root.left, 2*k) && dfs(root.right, 2*k+1);
}
}
public boolean isCompleteTree(TreeNode root) {
if(root == null){
return true;
}else{
if(!dfs(root, 1)){
return false;// 1. ���� 100 �ڵ�ͷ��� false
}else{
return n == p;// 2.δ���� 100 �ڵ�, �жϽڵ���������±����Ƿ����
}
}
}
}
3.3.11 �����������������

/*
left == null, right == null: return null
left != null, right != null: return root
left == null, right != null: return right
left != null, right == null: return left
*/
class Solution {
public TreeNode lowestCommonAncestor(TreeNode root, TreeNode p, TreeNode q) {
if(root == null || root == p || root == q){
return root;
}else{
TreeNode left = lowestCommonAncestor(root.left, p, q);
TreeNode right = lowestCommonAncestor(root.right, p, q);
if(left == null && right == null){
return null;
}else if(left != null && right == null){
return left;
}else if(left == null && right != null){
return right;
}else{
return root;
}
}
}
}
3.3.12 ������������

class Solution {
public int widthOfBinaryTree(TreeNode root) {
if(root == null){
return 0;
}else{
LinkedList<TreeNode> queue = new LinkedList<>();
queue.offer(root);
int max_width = 0;
while(!queue.isEmpty()){
int cur_width = queue.getLast().val-queue.getFirst().val+1;// 1.���ý���ֵ���¼��ǰ���п���
// 2.ͷ�ڵ���������������, Ϊ��һ�ο��ȼ�������
int count = queue.size();// 3.���д�Сʱ�̱仯�ŵ�, ����Ӧ�ñ��������֮ǰ�Ķ��д�С
for(int i=0; i<count; ++i){
TreeNode top = queue.poll();// 4.������Ԫ���ұ���, Ϊ��������������������̵�
if(top.left != null){
queue.offer(top.left);
top.left.val = top.val << 1;// 5.���ݵ��Ƕ�����������5--����:2*i ��:i �Һ���: 2*i+1
}
if(top.right != null){
queue.offer(top.right);
top.right.val = (top.val << 1) + 1;
}
}
if(max_width < cur_width){
max_width = cur_width;
}
}
return max_width;
}
}
}
��������Ҫ�����·���ʾ: �����������
3.4. ����Ķ���������
3.4.1 ����������
static class BinaryTreeNode {
// ��ֵ�Ե���ʽ�洢
int key;
int value;
BinaryTreeNode left;
BinaryTreeNode right;
public BinaryTreeNode(int key, int value) {
this.key = key;
this.value = value;
}
}
// root: ��ʾ���ĸ��ڵ�, ���������� null ����ʾ
private BinaryTreeNode root = null;
//����: ���� Key �� Value
private Integer search(int key) {
BinaryTreeNode cur = root;
while (cur != null) {
if (key < cur.key) {
cur = cur.left;
} else if (key > cur.key) {
cur = cur.right;
} else {
return key;
}
}
return null;
}
// ����
private void insert(int key, int value) {
if (root == null) {
root = new BinaryTreeNode(key, value);
} else {
BinaryTreeNode cur = root;
BinaryTreeNode parend = null;
while (cur != null) {
parend = cur;
if (key < cur.key) {
cur = cur.left;
} else if (key > cur.key) {
cur = cur.right;
} else {
return;// �������������������, ������Ҳû��Ҫ��ֵ
}
}
// ����ִ�е����, ˵�� parent �Ѿ��� cur �ĸ��ڵ�, �ĸ��ڵ㼴��
if (key < parend.key) {
parend.left = new BinaryTreeNode(key, value);
} else {
parend.right = new BinaryTreeNode(key, value);
}
}
}
// ɾ��: ���� key ɾ��
private void remove(int key) {
// 1.�Ȳ��� key ��Ӧ��λ��
BinaryTreeNode cur = root;
BinaryTreeNode parent = null;
while (cur != null) {
parent = cur;
if (key < cur.key) {
cur = cur.left;
} else if (key > cur.key) {
cur = cur.right;
} else {
/*
2.����ɾ��
���ǵ�ǰ cur.left Ϊ��
�Ƿ�Ϊ���ڵ� root
��: ����������
��: �����жϵ�ǰɾ�����ӽڵ� cur ���丸�ڵ� parent �ڵ������������ϵ
���ǵ�ǰ cur.right Ϊ��
���� cur.left ���ڵ��ж�һ����˼·
���ǵ�ǰ cur.right �� cur.left ����Ϊ��
���λ�Ӱɾ��
*/
if (cur.left == null) {
if (cur == root) {
root = cur.right;
} else if (cur == parent.left) {
parent.left = cur.right;
} else if (cur == parent.right) {
parent.right = cur.right;
}
} else if (cur.right == null) {
if (cur == root) {
root = cur.left;
} else if (cur == parent.left) {
parent.left = cur.left;
} else if (cur == parent.right) {
parent.right = cur.left;
}
} else {
// �������λ�Ӱ����
// 1.����������Сֵ, ����¼�丸�ڵ�
BinaryTreeNode targetParent = cur;
BinaryTreeNode target = cur.right;
while (target.left != null) {// ��Сֵ�ص���: ������Ϊ��
targetParent = target;
target = target.left;
}
// 2.����ִ�е����: targetParent �� target ���ڵ�; target ������������Сֵ
// 3.�Ͱ� ������target �ڵ��ֵ��ֵ��ɾ���ڵ�
cur.key = target.key;
cur.value = target.value;
// 4.�Ͽ�ĩβ ��Сֵ�ڵ� �Ĺ�ϵ, �����µĹ�ϵ
if (target == targetParent.left) {
targetParent.left = target.right;// ��Сֵ��ڵ�Ϊ null
} else if (target == targetParent.right) {
targetParent.right = target.right;
}
}
}
}
}
3.4.2 �շ���������Ӧ��
3.4.1. �շ�����
ʲô����������
����������Ŀ����Ϊ���ַ�����ѹ��, ���Ǿ����õ� zip, tar, ara���ȵ�ѹ�����ǻ��� ����������ԭ��

�ٸ���Сѧͨ�õ����ֱ�
if (a < 60) {
b = "������";
} else if (a < 70) {
b = "����";
} else if (a < 80) {
b = "�е�";
} else if (a < 90) {
b = "����";
} else {
b = "����";
}
�ֿ�ûʲô����, ����ǶԵ�. һ�źõ��Ծ�Ӧ����ѧ���ɼ��ִ��� �е� �� ���� ��Χ, ���� �� ������ Ӧ�ú��ٲŶ�. ������ij���, ����Ҫ�����еijɼ��ж��Ƿ�, �����ϵõ����. ���������ʱ��, �㷨Ч�ʺܵ���
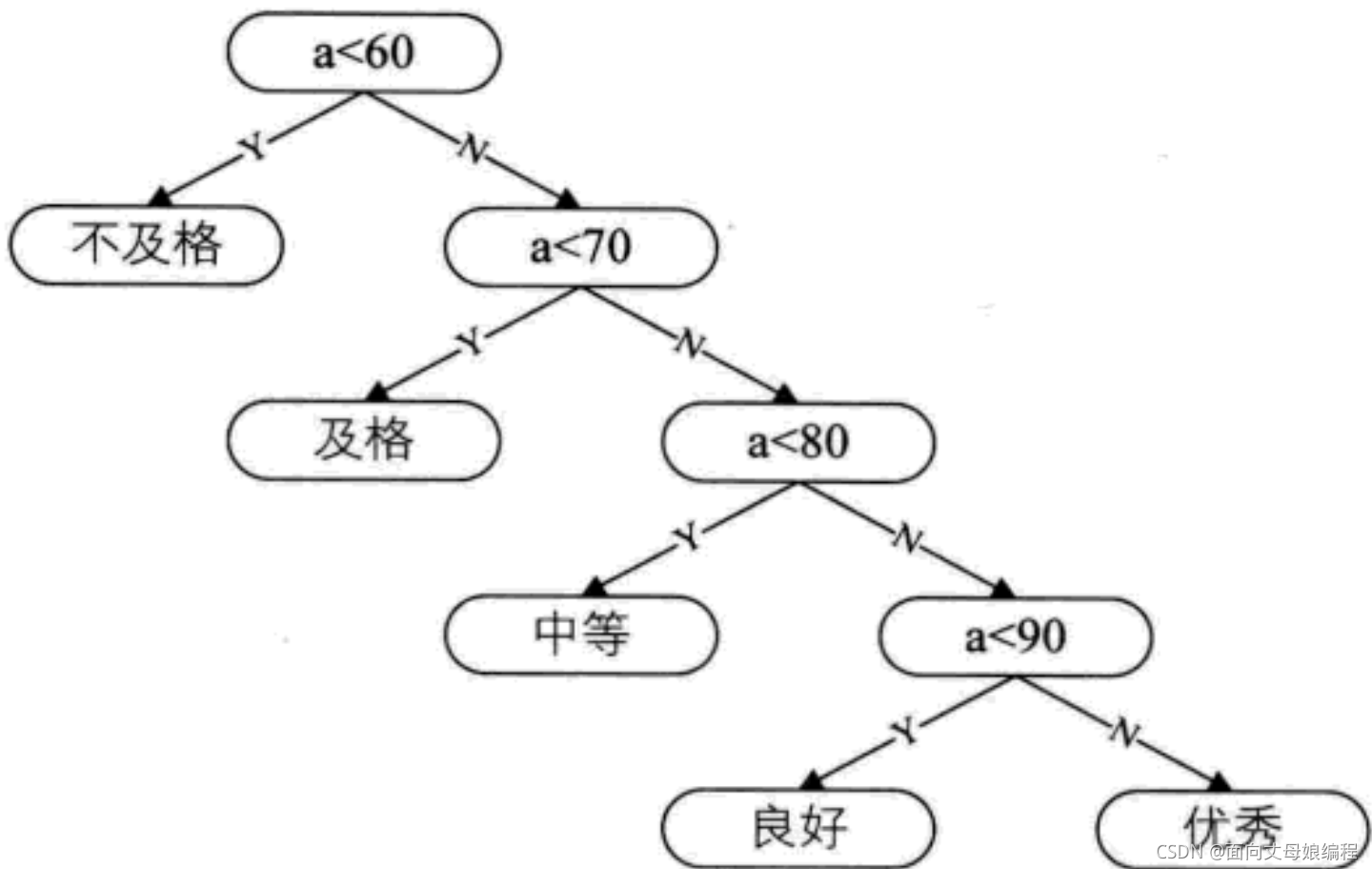
ʵ��������ѧ���ɼ��ֲ��������±�

��ô 70 �����ϴ�Լռ����80%�ijɼ�����Ҫ���� 3 �����ϵ��жϲſ��Եõ����, ����Ȼ������.
��ϸ�۲췢��: �еȳɼ�(70~79)�������, ��������óɼ�, ��������ռ��������. �������Ķ��������·�������(�е�������������, ��ʵ�����ǵ�, ��ϸ����������¿�):
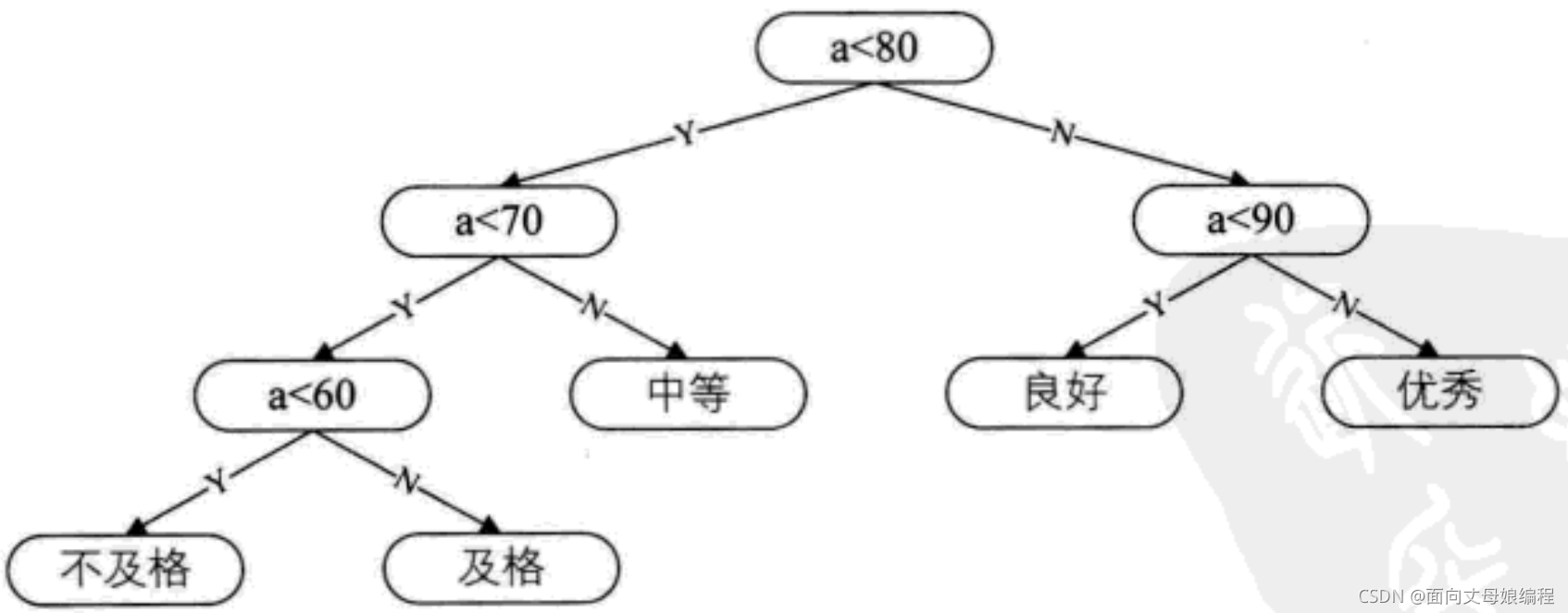
3.4.2.�շ�����������ԭ��
�����Ŷ�������Ҷ�ӽ���Ȩ�Ķ�������A: ������, B: ,����C: �е�,D:����, E:���㡿
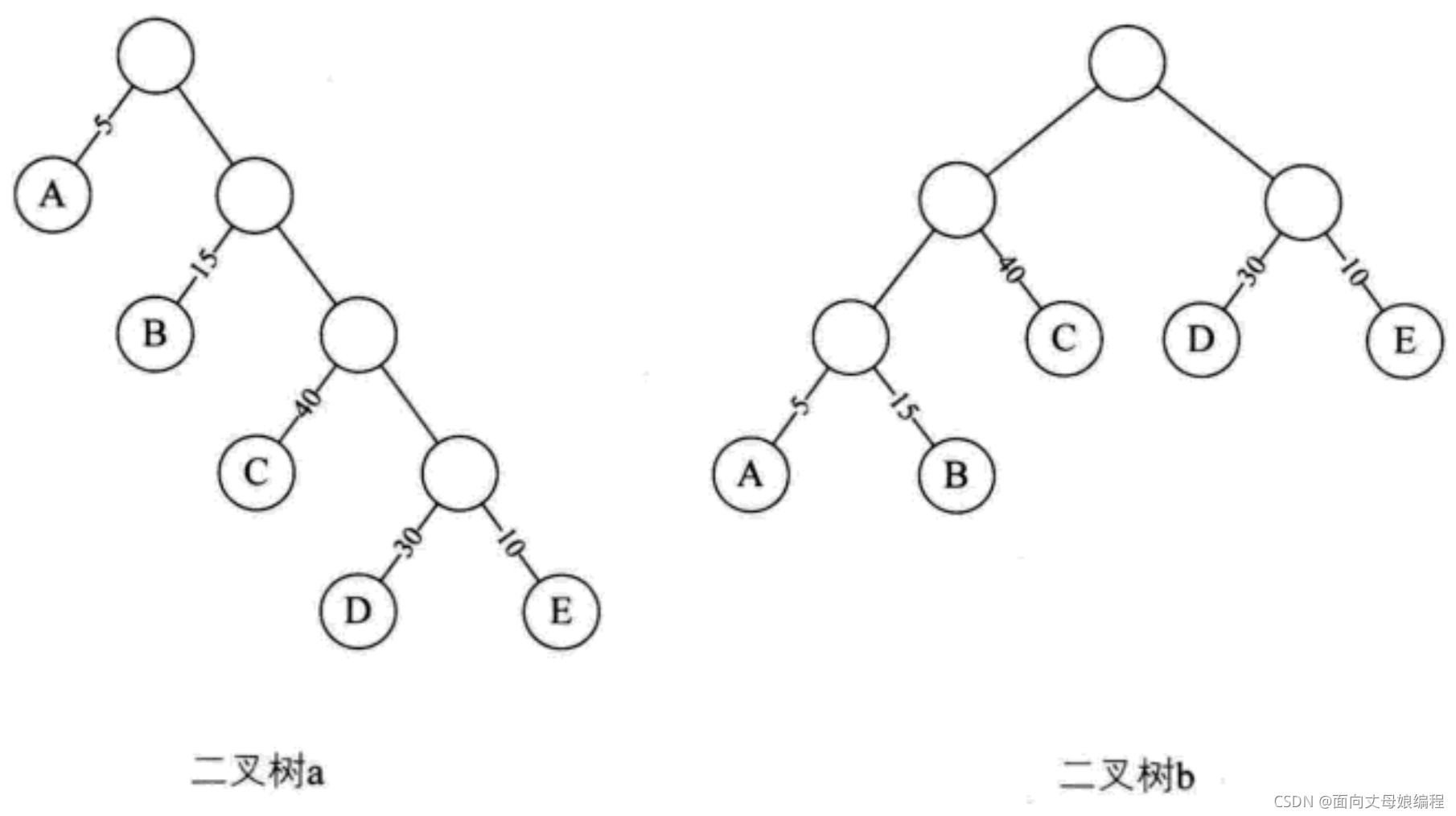
������һ���ڵ㵽��һ���ڵ�֮��ķ�֧�ṹ��������������֮���·��, ·���ϵķ�֧��ľ����·������
������a�и��ڵ㵽D�ڵ�·�����Ⱦ���4, ������b�и��ڵ㵽D�ڵ㳤�Ⱦ���2
������a�ܳ���: 1+1+2+2+3+3+4+4=20
������b�ܳ���: 1+1+2+2+2+2+3+3=16
������Ǵ�Ȩ�Ľڵ�: �ýڵ㵽����֮���·��������ڵ���Ȩ�ij˻�. ���Ĵ�Ȩ·��������Ϊ��Ϊ��������Ҷ�ӽ��Ĵ�Ȩ·�����ȵ�֮��, �� WPL ����ʾ. ������С�� WPL ������Ϊ �շ�����.
������a WPL: 5 * 1 + 15 * 2 + 40 * 2 + 30 * 4 + 10 * 4 = = 315
������b WPL: 5 * 3 + 15 * 3 + 40 * 2 + 30 * 2 + 10 * 2 = 220
�����Ľ����ζ������� 1_0000 ��ѧ���İٷ������ݼ����弶���Ƴɼ�, ������a��Ҫ����31500�αȽ�, ������b��Ҫ2200�αȽ�. �������1/3����, ��������߲���һ���
����ι����շ�������?
- �Ȱ���Ȩֵ��Ҷ�ӽ�㰴�մ�С�����˳�����г�һ����������[A5, E10, B15, D30, C40]
- ȡͷ������Сȫֵ�Ľڵ���Ϊһ���½ڵ� N1 �������ֽڵ�, A �� N1 ������, E �� N1 ������. ע������������С��ϵ
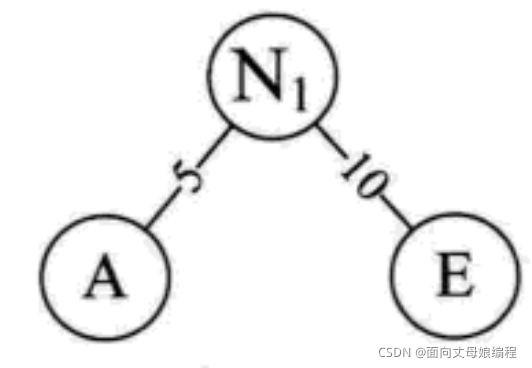
- �� N1 �滻 A �� E, ��������������, ���ִ�С��������[N1 15, B15, D30, C40]
- �ظ�����2. �� N1 �� B ��Ϊһ���½ڵ� N2 �������ֽڵ�
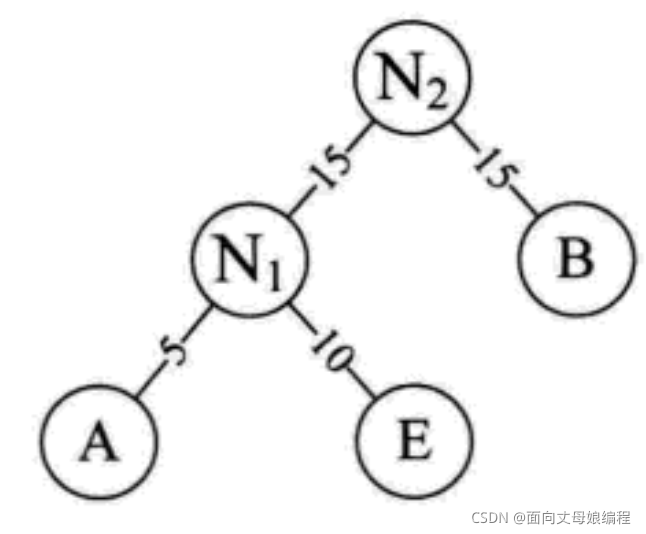
�ظ�����3�������滻������Сֵ, ���ظ�����2�����µĽڵ㡭
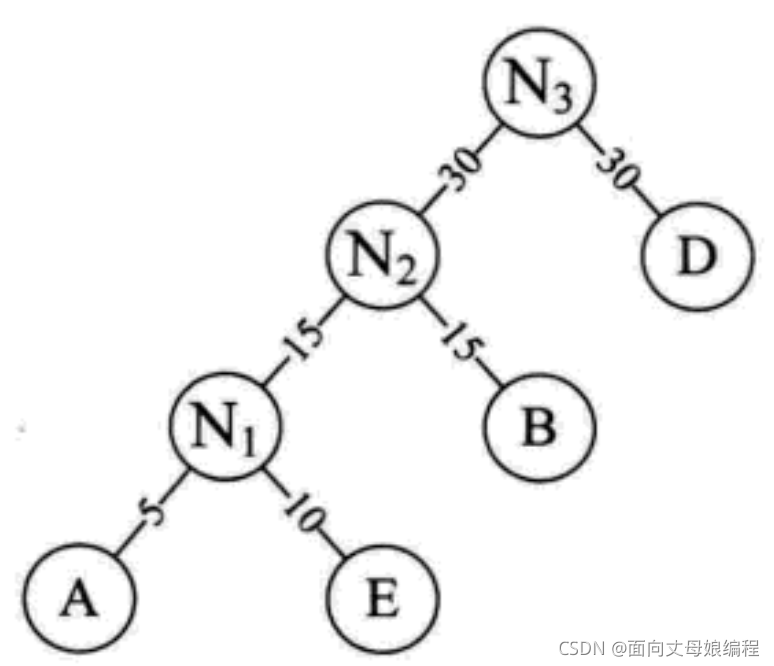
������:
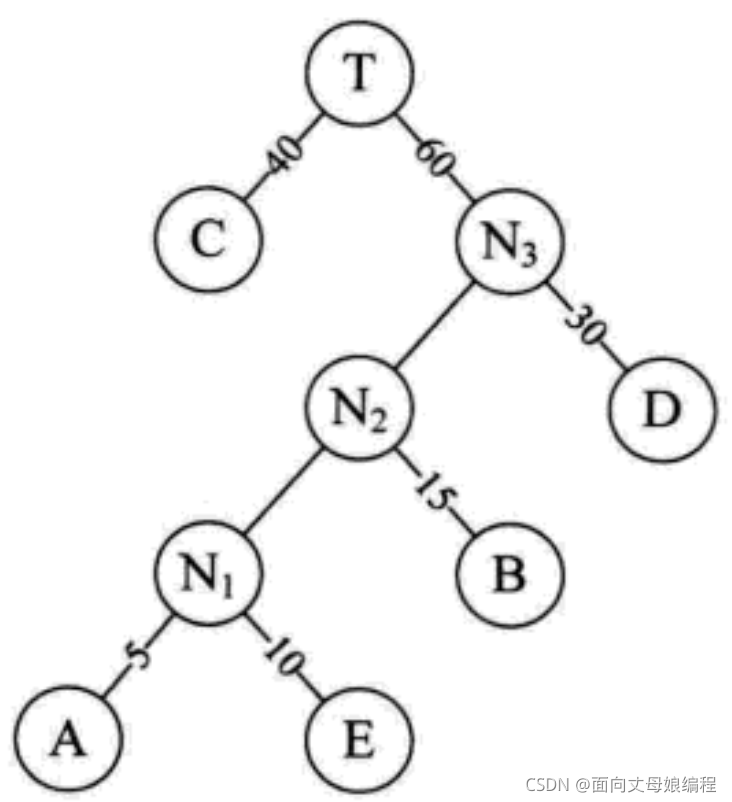
WPL=40 * 1 + 30 * 2 + 15 * 3 + 10 * 4 + 5 * 4 = 205, ������������������15, �����������ŵĺշ�����
3.4.3 �շ�������
�շ���������������Ϊ�������Զ����ͨ��(��Ҫ�ǵ籨)�����ݴ�������Ż�����.
������һ����������Ϊ ��BADCADFEED�� Ҫ���紫�������, ��Ȼ�ö����Ƶ�����(0 �� 1)����ʾ�Ǻ���Ȼ���뷨, ��������� 6 ����ĸABCDEF.
��Ӧ�Ķ��������ݱ�ʾ����:

������������ľ��DZ����� ��001000011010000011101100100011��, �Է����ܿ����� 3 λһ��������. ����������ݺܳ�, �����Ķ����ƴ�Ҳ�ܿ���.
��ʱ��Ӧ��ʹ�� �շ�����.
����6����ĸ��Ƶ��: A:27, B:8, C:15, D:15, E:30, F:5 ������������100%.
��ͼ����շ������Ĺ���Ȩֵ��ʾ; ��ͼ�ǽ�Ȩֵ��������Ϊ0, ���������Ƹ�Ϊ1��ĺշ�����
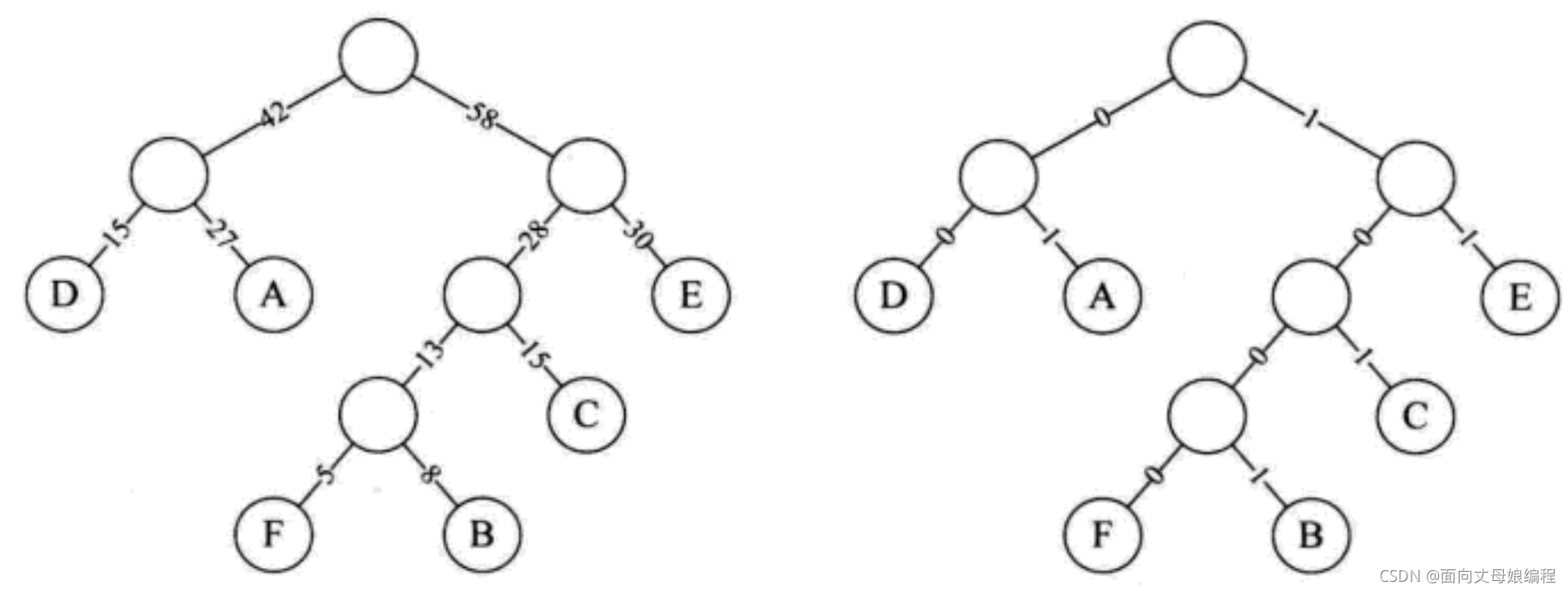
��ʱ���Ƕ� 6 ����ĸ���±���

ԭ����: 001000011010000011101100100011[30���ַ�]
�±���: 1001010010101001000111100[25���ַ�]
����5���ַ�, Ҳ���Ǵ�Լ 17%[5/30=0.167] �ijɱ�.
�ַ�����, ����ѹ��Ч��������
��������: �յ��˺շ��������ָ���ν�����?
�����з�0��1, ���̲��ȵĻ���ʵ����������, ����Ҫ��Ƴ��̲��ȵı���: ��һ�ַ��ı��붼������һ���ַ������ǰ, ���ֱ������Ϊǰ����[01, 1001, 101, 00, 11, 1000���Dz�ͬ���̳���, ��˲�������]
������������, ����ȥ����Ľ���, ����ڽ����ʱ����շ��ͷ��ͷ�������ҪԼ������ͬ�� �շ����������
���յ� 1001010010101001000111100 ʱ, Լ���õ� �շ���������� ��֪ 1001 �õ���һ����ĸ�� B, ���������� 01 ��ζ�ŵڶ�����ĸ A��
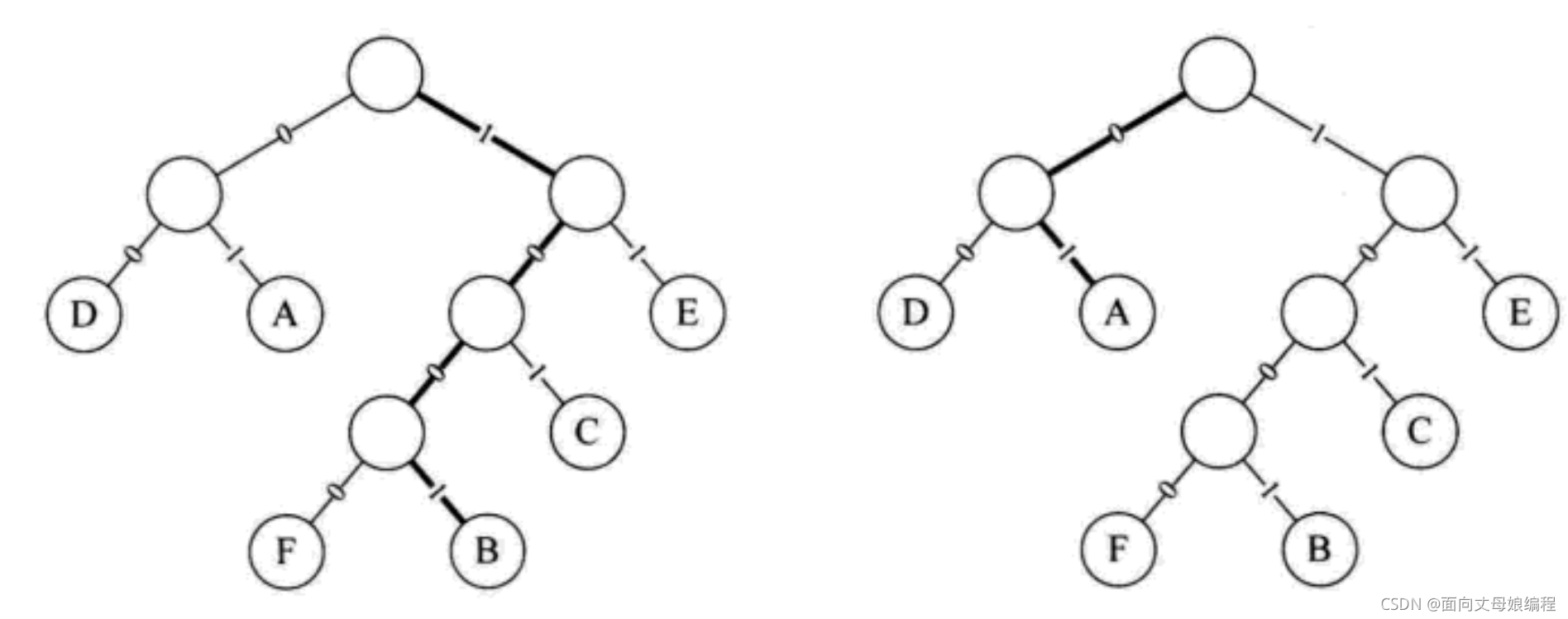
һ���,����Ҫ������ַ���Ϊ{ d1,d2, ��, dn },�����ַ��ڵ����г��ֵĴ�����Ƶ�ʼ���Ϊ{ w1,w2, ��, wn}, ��d1,d2,��, dn��ΪҶ�ӽ��,��w1,w2, ��, wn��Ϊ��ӦҶ�ӽ���Ȩֵ������һ�úշ�������
�涨�շ����������֧����0,�ҷ�֧����1,��Ӹ���㵽Ҷ�ӽ����������·����֧��ɵ�0��1�����б�Ϊ�ý���Ӧ�ַ��ı���,����Ǻշ������롣
3.4.3 ����������
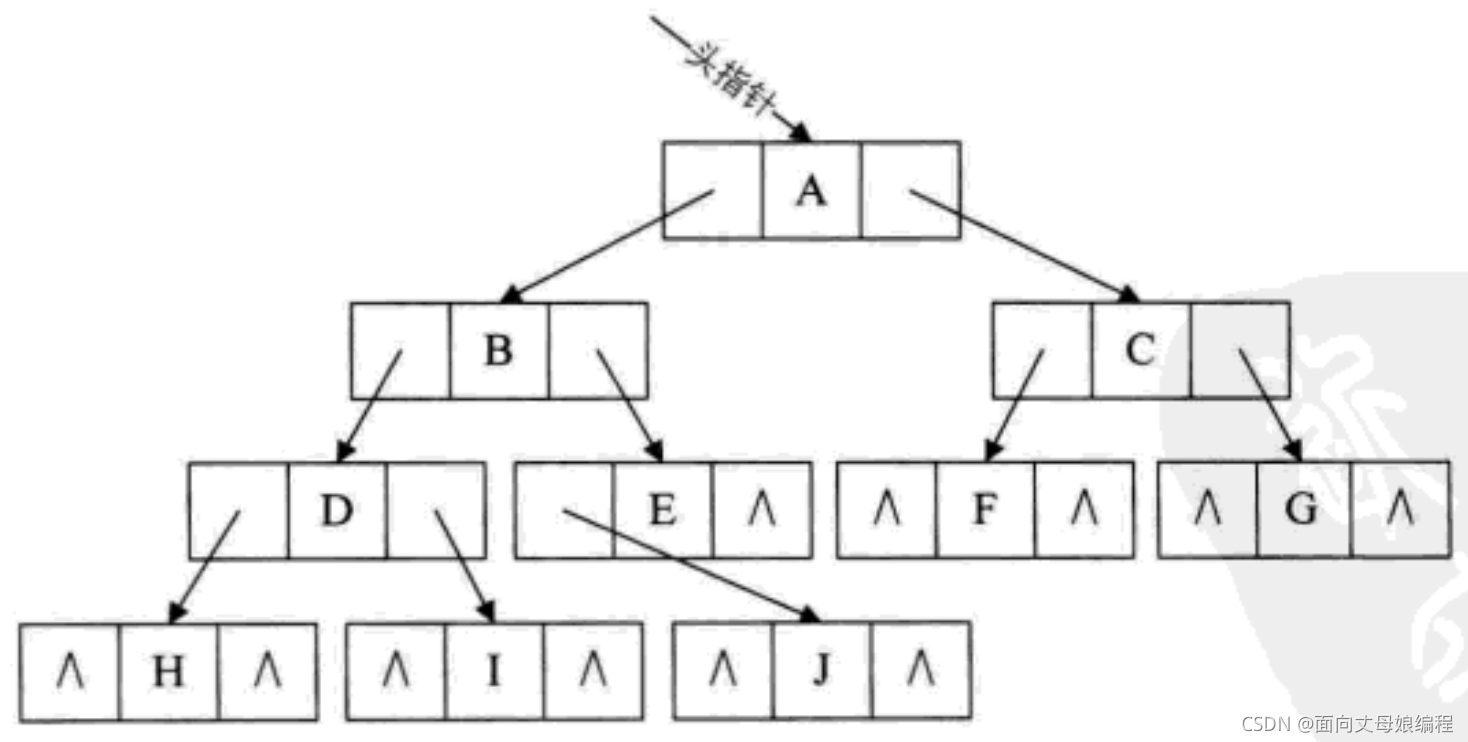
^: ��ʾ��ָ��, ͼ�ж������������ָ��, ������Щ�ռ䶼û������. ����ʵ����һ��������, Ӧ�ú�����������.
�����������������ж��ٸ����ٸ���ָ����?
����һ���� n ���ڵ�Ķ������� 2n ��ָ��, �� n ���ڵ�Ķ�����һ���� n-1 ����֧����, Ҳ����˵���� 2n-(n-1)=n+1 ����ָ����. ��Ӧ����Ŀ�о��� 11 ����ָ����˷�.
��һ����, ������������������ó� HDIBJEAFCG, �������ַ�����, ����֪�� J ��ǰ���� B ����� E, Ҳ����˵������������������ǿ���֪������һ���ڵ��ǰ���ͺ��
����: �ϱ��ҵ��Ĺ����ǽ������Ѿ��������Ļ�����, �ڶ�������������ֻ֪��ÿ�����Һ��ӵĵ�ַ, ����֪�������˭, �����˭Ҫ��֪������Ҫ�ٴα���һ��
�������
�����ڱ�����ʱ��ʹ�����ǰ�����.
���ǰ�����ǰ���ͺ�̵�ָ���Ϊ����, ���������Ķ���������Ϊ��������, ��Ӧ�Ķ�������Ϊ����������(Threaded Binary Tree)
���ǰ���ö����������������, �����п�ָ��� rchild, ��Ϊָ�����ĺ������. ���ǾͿ���ͨ��ָ��֪�� H �ĺ���� D(1??), I �ĺ���� B(2??), J �ĺ���� E(3??)(E.next = A(4??), F.next = C(5??), G.next = null(6??)). ��ʱ���� 6 ����ָ�뱻����.
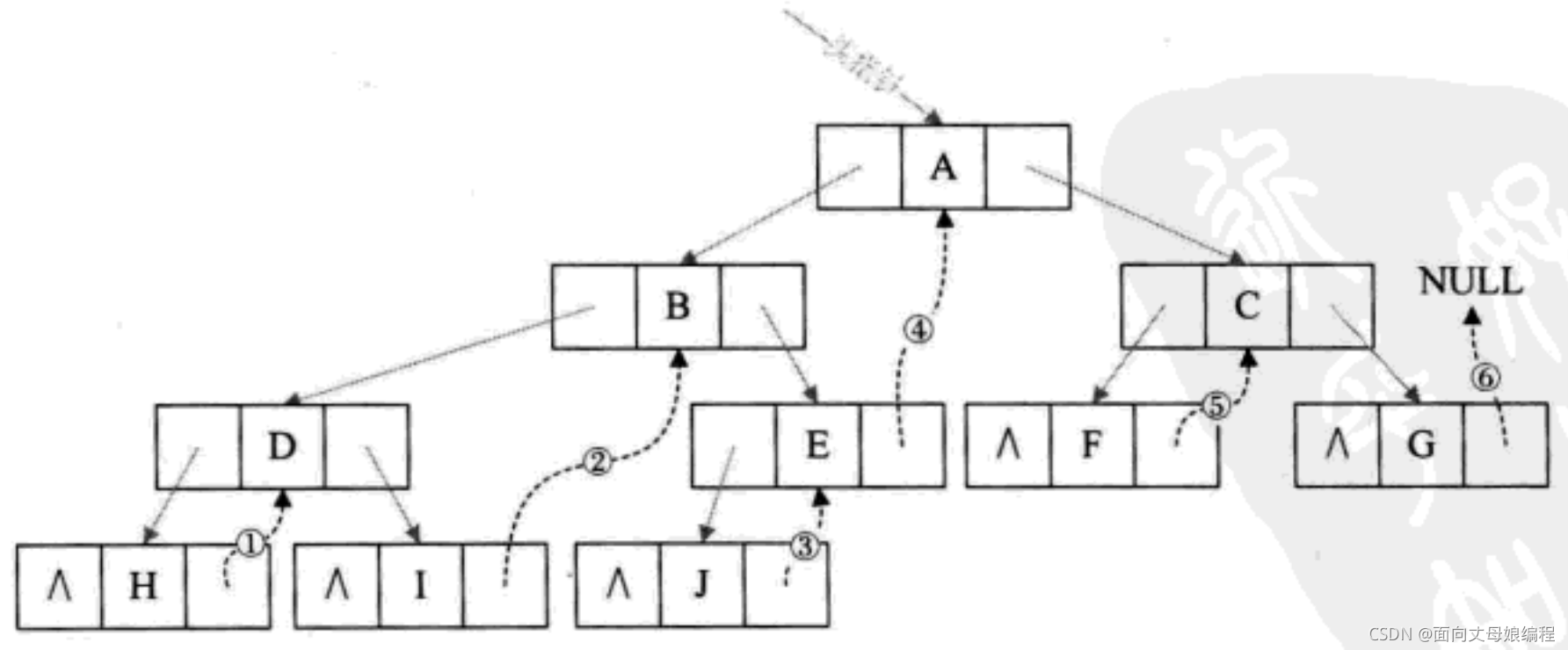
�ٿ�ͼ, ����ö������е����п�ָ�����е� lchild, ��Ϊָ��ǰ����ǰ��. ��� H ��ǰ���� NULL(1??), I ��ǰ���� D(2??)[J.prev = B(3??), F.prev = A(4??), G.prev = C(5??)].һ���� 5 ����ָ�뱻����, ��������� ������ ���ú�һ���� 11 ����ָ�뱻����
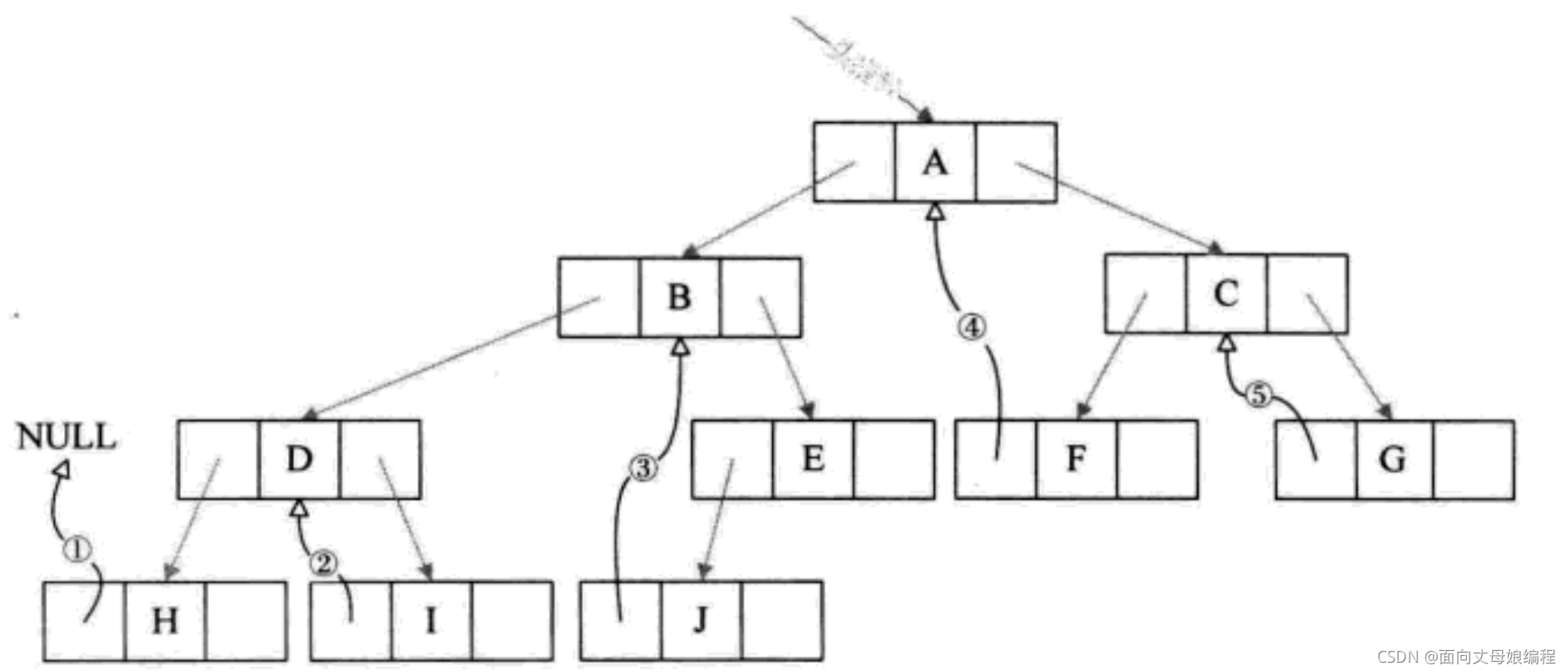
ʵ�߿��ļ�ͷΪǰ�� prev, ����ʵ�ļ�ͷΪ��� next
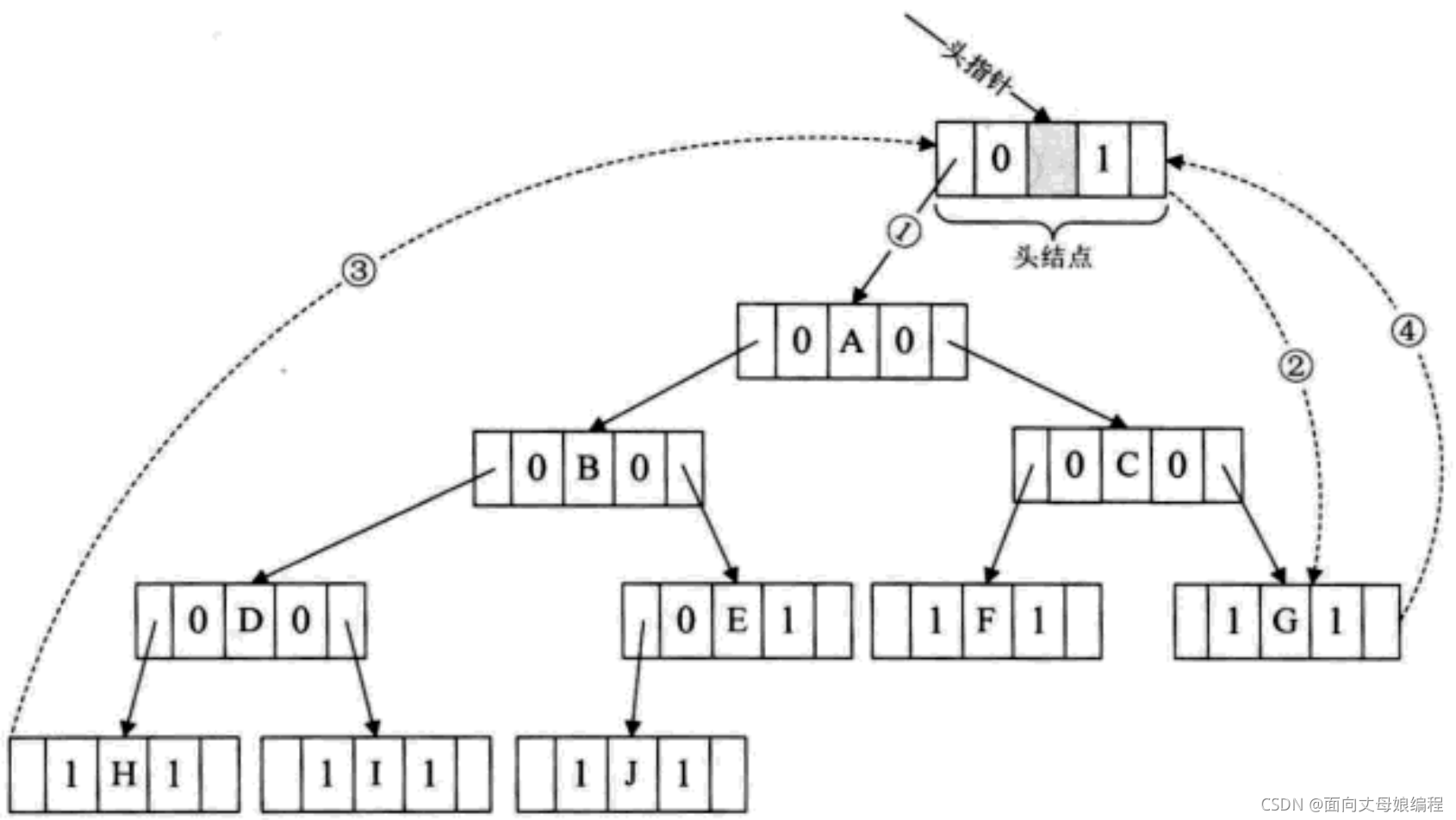
��������, ����������, �����ǰ�һ�ö����������һ��˫������, �����������ǵIJ���ɾ���ڵ�, ����ij���ڵ㶼�����˷���. �������Ƕ���������ij�ִ������ʹ���Ϊ�����������Ĺ���Ϊ������
������������˫������
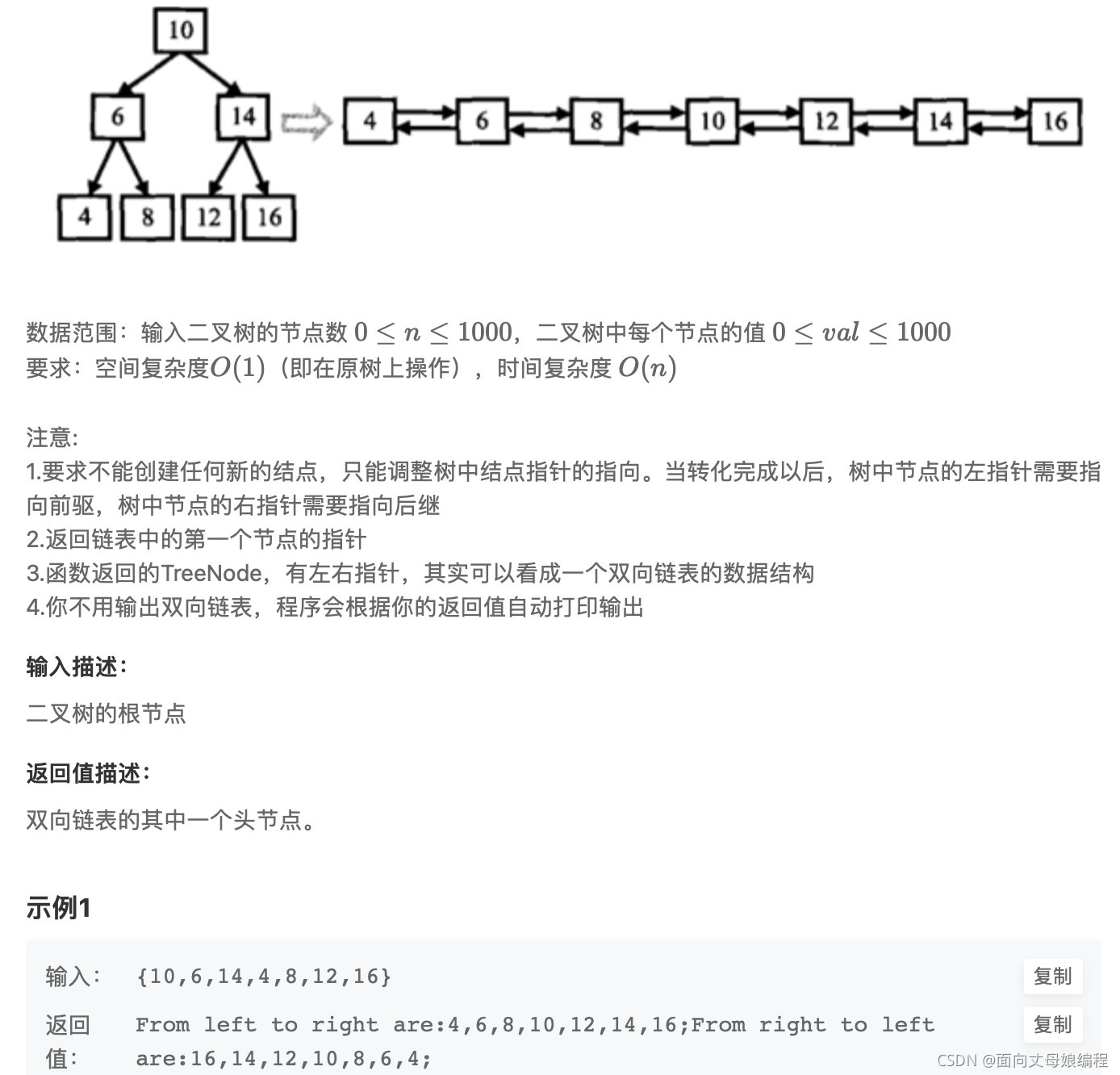
OJ��Ŀ��ϰ
Java: ��������
/**
public class TreeNode {
int val = 0;
TreeNode left = null;
TreeNode right = null;
public TreeNode(int val) {
this.val = val;
}
}
*/
public class Solution {
private TreeNode prev = null;// 1. ������¼ǰ���ڵ�
private void ConvertChild(TreeNode root){
if(root == null){
return;
}else{
// 2.������������������: �����������������
ConvertChild(root.left);
/*
3.����ǰ��ָ��
�ڵ����������ǰ��, �������Ǻ��
���������Ҷ�ӽ�� 4 ����û�����������Ľ��Ҫ���⿼��: ������ǰ���ڵ��������ָ��ǰ�������õĽڵ㡾4.right = 6��, �����������������Ҫ�ж����Ƿ�Ϊ null, ����ͻ� ��ָ���쳣
4.left = null
null.right = 4;��ָ���쳣
null = 4;
���� if �жϺ�:
4.left = null;
null = 4;
���� return ���ص� 6�ڵ㺯��
6.left = 4;
4.right = 6;
4 = 6;
*/
root.left = prev;// ��һ�εݹ�������ص� root ��4����ڵ�
if(prev != null){
prev.right = root;
}
prev = root;
ConvertChild(root.right);
}
}
public TreeNode Convert(TreeNode pRootOfTree) {
if(pRootOfTree == null){
return null;
}else{
ConvertChild(pRootOfTree);
while(pRootOfTree.left != null){
pRootOfTree = pRootOfTree.left;
}
return pRootOfTree;
}
}
}
Java �����ڶ���ڵ����ʱ��ֻ��Ҫ: ������val, ������left, ������right, ��ʵ��˫��������ʱ����Ҫ����һ�� prev�ڵ�����ŵ�ǰ�ڵ��ǰ������������
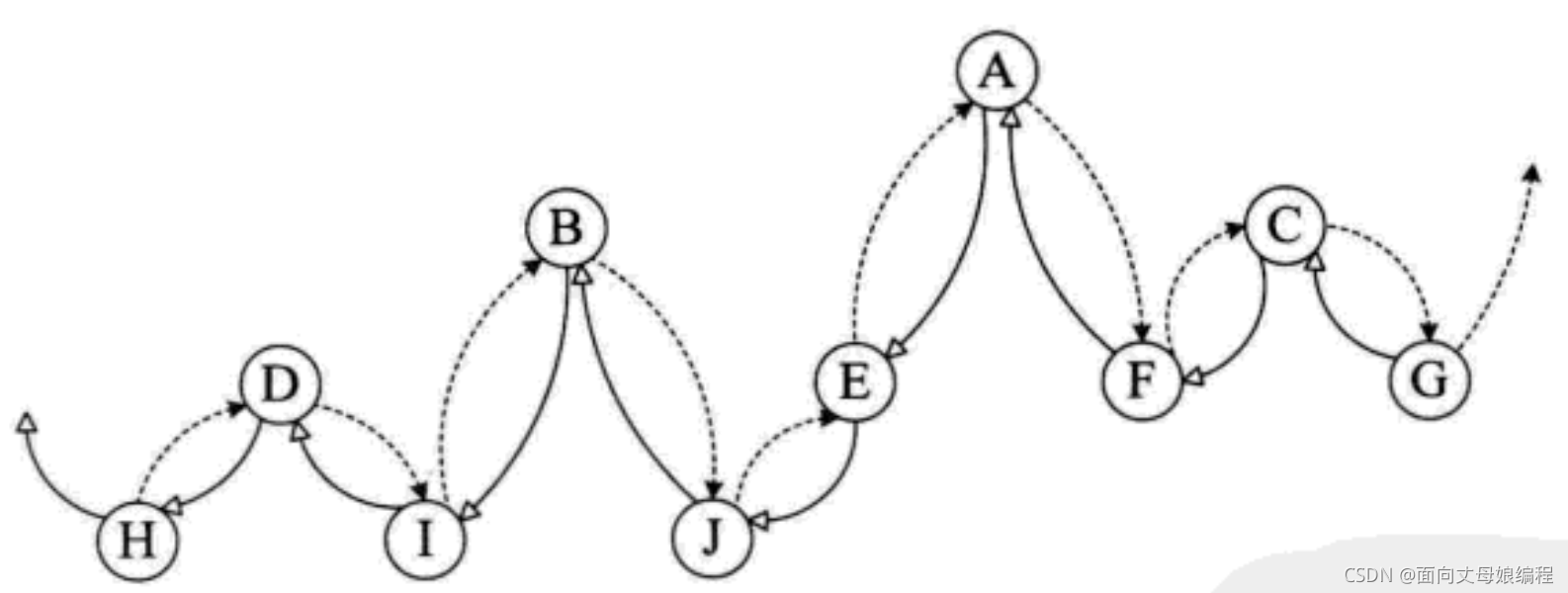
C: �����������ṹ��˼·
lchild: ������, rchild: ������
����C���Զ���, �������֪��ijһ�ڵ�� lchild ��ָ���������ӻ���ָ��ǰ����? rchild ��ָ���Һ��ӻ��Ǻ����?
����: E �ڵ�� lchild ��ָ������������ J, �� rchild ȴ��ָ�����ĺ�� A. ��Ȼ�����ھ��� lchild ��ָ�����ӻ���ǰ��, rchild ��ָ���Һ��ӻ��Ǻ��������Ҫһ�����ֱ�־��. ������Ǹ�ÿ���ڵ�������������־�� ltag �� rtag, ע�� ltag �� rtag ֻ�Ǵ�� 0 �� 1�IJ����ͱ���, ��ռ�õ��ڴ�ռ�ҪС���� lchild �� rchild ��ָ�����
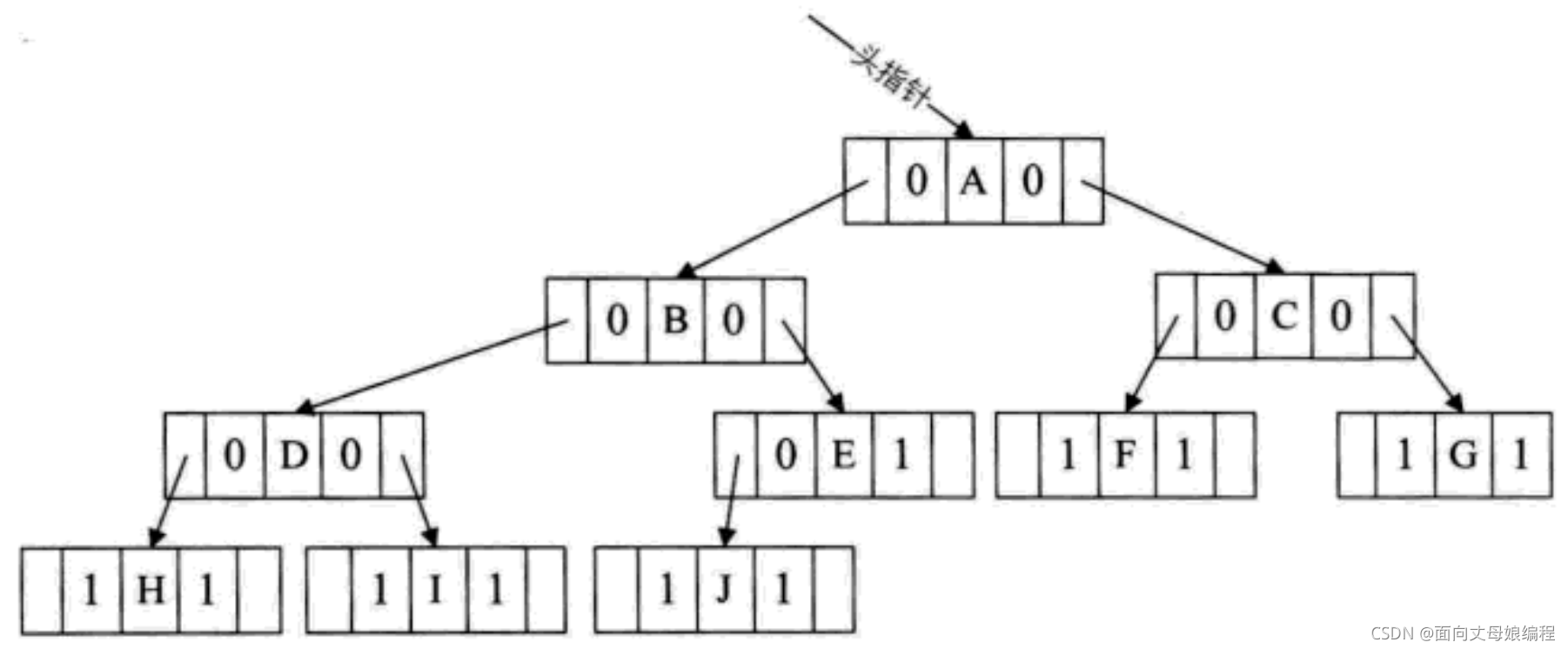
| lchild | ltag | data | rtag | rchild |
|---|
- ltag == 0ʱָ��ýڵ������, Ϊ1ʱָ��ýڵ�ĺ��
- rtag == 0ʱָ��ýڵ���Һ���, Ϊ1ʱָ��ýڵ�ĺ��
typedef int DataType;// ��������
typedef enum {
Link,//Link == 0��ʾֻ������������ָ��
Thread, //Thread == 1��ʾֻ��ǰ�����̵�����
} PointerTag;
typedef struct BiThrNode {// �������洢�ڵ�ṹ
DataType data;// ������
struct BiThrNode *lchild, *rchild;// ��������
PointerTag LTag;// ���־
PointerTag RTag;// �ұ�־
}BiThrNode, *BiThrTree;
��ô�˽���C���ԵĽṹ�幹������������ԭ�������Ǹ����ʵ����?
�ο�ǰ�� Java�����ʵ��, ���Ƿ��ֿ��Թ�������������ķ�ʽ��������. �����м��Dz��� �� ��������δ���
BiThrNode *prev;// ȫ�ֱ���, ʼ��ָ��ոշ��ʹ��Ľڵ�
void InThreading(BiThrNode *pb) {
if (pb) {
/*
* ��������������������ݹ麯��
*/
// 1. ��
InThreading(pb->lchild);
/*
* 2.�м䲿�ֽ�����ϵ
* ��Ϊ�������֮���һ��Ԫ�ؾ��� ������ͷ�ڵ�, ����Ӧ��ѡȡ��ڵ�Ϊ�յĽڵ���� ����ͷ�ڵ�
*
* ǰ������:
* if(!pb->lchild): ��ʾ���ij������������Ϊ��, ��Ϊ��ǰ���ڵ�ոշ��ʹ�
* ��ֵ���� prev, ���Կ��� prev ��ֵ�� pb->lchild, ���� pb->Ltag=Thread.�����ǰ���ڵ��������
* ��̷���:
* ��ʱ pb �ڵ�ĺ�̻�û�з��ʵ�, ֻ��ͨ������ǰ���ڵ� prev �������� rchild ���ж�:
* if(!prev-rchild)Ϊ��, �� pb ���� prev �ĺ��, ���� prev-Thread, prev->rchild = pb ��ɺ�̽ڵ��������
* ���ǰ���ͺ�̵��жϺ�� pb �� prev, ������һ�α���
*/
if (!pb->lchild) {// ���û������
pb->LTag = Thread;// ǰ������
pb->lchild = prev;// ����ָ��ָ��ǰ��
}
if (!prev->rchild) {// ���û���Һ���
prev->LTag = Thread;// �������
prev->lchild = pb;// �Һ���ָ��ָ����
}
prev = pb;
// 3.��
InThreading(pb->rchild);
}
}
4. �ܽ�ع�
- ������ÿ����������������,������֮�֡��ᵽ��б��,������������ȫ������������������ĸ���
- ���ǽ���̸�����ĸ�������,��Щ���ʸ������о������������˷��㡣
- �������Ĵ洢�ṹ������������ʹ�üȿ�����˳��洢�ṹ�ֿ�������ʽ�洢�ṹ��ʾ
- �����Ƕ���������Ҫ��һ��ѧ��,ǰ���������Լ��������������Ҫ�������յ�֪ʶ��Ҫ���Լ�Ҫѧ���ü����������˼άȥģ��ݹ��ʵ��,���Լ������ǶԵݹ�����⡣����,���Ƕ�����������һ��Ҫ�õ��ݹ�, ֻ�����ݹ��ʵ�ֱȽ����Ŷ��ѡ������Ҫ��ȷ
- �������Ľ�����ȻҲ�ǿ���ͨ���ݹ���ʵ��
- ������������ʵ�ֲ���Ч�ʽϴ�, ������� б�� ����ĺ���
- �о���Ҳ����,���������кܶ��˷ѵĿ�ָ���������,����ij������ǰ���ͺ��Ϊʲô��Ҫÿ�α����ſ��Եõ�,�����������ι���һ�����������������⡣�������������������Ľ����Һͱ��������˸�Ч��
- ���,����֪���˹��ڶ���������һ��Ӧ��,�շ������ͺշ�������,���ڴ�Ȩ·���Ķ����������꾡�ؽ���,���������������ѹ����ԭ��,����������������������,�����ᵽ�˹��ڶ�������-һ��Ӧ��,�շ������ͺշ�������,���ڴ�Ȩ·���Ķ����������꾡�ؽ���,���������������ѹ����ԭ��,�������������������������������
- �м�����һЩ ����, ţ�� ����OJ�͵����������, ����Ȥ�Ŀ���ȥˢһˢ.
5. ������
���������������, ����, ջ��Ȼ����һ��¥.·��������Զ��, �Ὣ���¶�����.�����Լ�ҳ��ÿһ�������Ҳ��͵��˹�ͬ����, ѧϰ����������֪ʶΪĿ��.