Ŀ¼
д��ǰ��
���߰�ȥ��ʵ�ʿ�������,���䲢��д�����͡��������ղ�,��Կ����а���,�ǵû��������ޡ�����Բ������������ʿ���ֱ�����ԡ�
����ƪ
��������
ȥ���һ�⡢�ڶ���Ϊ˳���,������Ϊ����,��������Ҫ��dfs��������Ϊѹ���⿼�������������
���ݽṹ��ĩ����������5����,�Ѷ���dz����,����ȥ��ʵ������,�����˾�AC2~3�⡣ǰ������ѶȻ���ԱȽϼ�,��Ҫ��Ҫ�ص㸴ϰ��˳���,���������Խṹ,�����㷨(ѡ��,����,ð�ݡ�),��ϣ���ҡ�������һ��������һЩ,��Ҫ�ص㸴ϰһ��ͼ��dfs,bfs�����·����Dijkstra�㷨�Լ���С������Prim��Kruskal�㷨�����һ���Ƚ���,���ܻ������Ƚϸ��ӵ����ݽṹ,����������ǰ����ȫ��AC�������һ�¡�
����
�ⲿ�ֵ�����������ȥ������ĵ��ĵ�����(ǰ����Dz�����),ƾ�Ż������Ŀ����д����,������һ��,�Լ����˱�̡�
����ͼ����
������˳���������ͼ�����и�㡣(���:��һ������ͼ��,���ɾ��ij�������Լ���ö�������������бߺ�,ͼ����ͨ��������,�ͳ������Ϊ��㡣)
����
��һ��Ϊ����������������ÿ���������,��һ������
n
n
n��ʾ������ͼ�Ĵ�С��������
n
n
n���ַ���Ϊÿ����������ơ�����������һ��
n
?
n
n*n
n?n�ķ�����Ϊ����ͼ,0��ʾ��������֮�䲻���ڱ�,1��ʾ��������֮����ڱߡ�
���
��������������ơ�ÿ��������ݵ����ռһ�С����û�и��,�����No!
��������
4
8
0 1 2 3 4 5 6 7
0 0 0 0 0 0 0 0
0 0 0 1 1 0 0 0
0 0 0 1 1 1 1 0
0 1 1 0 0 0 0 0
0 1 1 0 0 0 0 0
0 0 1 0 0 0 0 0
0 0 1 0 0 0 0 1
0 0 0 0 0 0 1 0
3
A B C
0 1 0
1 0 1
0 1 0
5
a b c d e
0 1 0 0 1
1 0 1 1 0
0 1 0 0 0
0 1 0 0 0
1 0 0 0 0
6
v1 v2 v3 v4 v5 v6
1 1 1 1 1 1
1 1 1 1 1 1
1 1 1 1 1 1
1 1 1 1 1 1
1 1 1 1 1 1
1 1 1 1 1 1
�������
2 6
B
a b
No!
�����
#include <iostream>
#include <vector>
using namespace std;
bool *isVisited;
int **matrix;
int n = 0;
//node:��ǰ���ѵ� cur:��ǰ�жϵĸ��
void dfs(int node, int cur) {
isVisited[node] = true;
for (int i = 0; i < n; i++) {
if ((!isVisited[i]) && i != cur && node != cur && (matrix[node][i] || matrix[i][node])) {
dfs(i, cur);
}
}
}
int main() {
int t;
cin >> t;
while (t--) {
cin >> n;
vector<string> vertex;
vector<string> res;
isVisited = new bool[n];
matrix = new int *[n];
for (int i = 0; i < n; i++) {
string temp;
cin >> temp;
vertex.push_back(temp);
matrix[i] = new int[n];
}
for (int i = 0; i < n; i++) {
for (int j = 0; j < n; j++) {
cin >> matrix[i][j];
}
}
int cc = 0;
for (int i = 0; i < n; i++) {
if (!isVisited[i]) {
cc++;
dfs(i, -1);
}
}
for (int i = 0; i < n; i++) {
int temp = 0;
for (int ii = 0; ii < n; ii++) {
isVisited[ii] = false;
}
for (int j = 0; j < n; j++) {
if (!isVisited[j]) {
temp++;
dfs(j, i);
}
}
if (temp > cc + 1) {
res.push_back(vertex[i]);
}
}
if (res.empty()) {
cout << "No!" << endl;
} else {
for (int i = 0; i < res.size(); i++) {
cout << res[i] << " ";
}
cout << endl;
}
}
return 0;
}
���������
����n��Ȩֵ,������ЩȨֵ���������������,������������������롣
����
��һ������
t
t
t,��ʾ��
t
��
t��
t������ʵ��
�ڶ���������
n
n
n,��ʾ��1��ʵ����
n
n
n��Ȩֵ,��������
n
n
n��Ȩֵ,Ȩֵȫ��С��1���������
��������
���:
�������ÿ��Ȩֵ��Ӧ�ı���,��ʽ����:Ȩֵ-����
��ÿ�������1��Ȩֵ,�����һ���̻���,�������Ӧ����,������һ�������һ��Ȩֵ�ͱ��롣
�Դ�����
��������
2
8
1 5 3 4 9 2 6 10
10
1 5 9 6 3 4 7 8 11 12
�������
1-100
5-01
3-102
4-00
9-11
2-101
6-02
10-12
1-010
5-120
9-02
6-121
3-011
4-012
7-122
8-00
11-10
12-11
��������
#include <iostream>
#include <queue>
#include <vector>
#include <algorithm>
using namespace std;
struct Node {
int value;
int father = -1;
int son[3];
string code;
Node(int value, int father) {
this->value = value;
this->father = father;
for (int i = 0; i < 3; i++) {
this->son[i] = -1;
}
}
};
bool cmp(const Node &a, const Node &b) {
return (a.father == -1 ? a.value : (9999 + a.value)) < (b.father == -1 ? b.value : (9999 + b.value));
}
int getNode(int num, vector<Node> nodeList) {
for (int i = 0; i < nodeList.size(); i++) {
if (nodeList[i].value == num && nodeList[i].father == -1) {
return i;
}
}
return -1;
}
void dfs(int index, vector<Node> &nodeList) {
if (index == -1) {
return;
}
for (int i = 0; i < 3; i++) {
if (nodeList[index].son[i] == -1) {
continue;
}
nodeList[nodeList[index].son[i]].code += (nodeList[index].code + to_string(i));
dfs(nodeList[index].son[i], nodeList);
}
}
int main() {
int t;
cin >> t;
while (t--) {
int n;
cin >> n;
vector<Node> nodeList;
for (int i = 0; i < n; i++) {
int temp;
cin >> temp;
nodeList.push_back(Node(temp, -1));
}
while (true) {
vector<Node> temp(nodeList);
sort(temp.begin(), temp.end(), cmp);
if (temp[2].father == -1) {
nodeList.push_back(Node(0, -1));
for (int i = 0; i < 3; i++) {
nodeList[nodeList.size() - 1].value += temp[i].value;
nodeList[nodeList.size() - 1].son[i] = getNode(temp[i].value, nodeList);
nodeList[getNode(temp[i].value, nodeList)].father = nodeList.size() - 1;
}
continue;
} else if (temp[1].father == -1) {
nodeList.push_back(Node(0, -1));
for (int i = 0; i < 2; i++) {
nodeList[nodeList.size() - 1].value += temp[i].value;
nodeList[nodeList.size() - 1].son[i] = getNode(temp[i].value, nodeList);
nodeList[getNode(temp[i].value, nodeList)].father = nodeList.size() - 1;
}
break;
} else {
break;
}
}
dfs(nodeList.size() - 1, nodeList);
for (int i = 0; i < n; i++) {
cout << nodeList[i].value << "-" << nodeList[i].code << endl;
}
}
return 0;
}
����ƪ
����ƪ���Ͽν���˳��,���½�Ϊ��λ������֯
Chapter 1
- ���ṹ���ֻ�����ʽ:���Ͻṹ,���Խṹ,��״�ṹ,ͼ״�ṹ
- ���ݽṹ�Ƕ�Ԫ��(���ݶ���,�������������ݳ�Ա֮���ϵ��������)
- �洢�ṹ(�ֽ������ṹ)����˳ʽ,��ʽ(����,ɢ��)
- �㷨:������,ȷ����,������,������&���
- �� O O O��Ƿ�=>ʱ�临�Ӷ�&�ռ临�Ӷ�
Chapter 2
- ˳���
- ��������:����,ɾ��,�ϲ�
- �ŵ�:���������ȡ,Ԫ�ص�ַ���ü�ʽ��ʾ
- ȱ��:�����ɾ��ʱҪ�ƶ�����Ԫ��,ռ��������ַ�ռ�
- ����
- ������
- ÿ���ڵ�ֻ��һ��ָ����
- ָ����Ԫ��֮������ϵ��ӳ��
- ��ַ������
- ����ɾ������,������Ҫ����
- ����:ͷ��,β��(ͷ����Ҫ��������)
- ѭ������
- ÿ���ڵ�������ָ��,ǰ��prior,���next
- ����ɾ����Ҫ�ı����������ָ��
- �����洢�ܶ�С��1
- һ��˳����ռ�Ϊ��̬����,������̬����
- ������
Chapter 3
- ջ:Stack
- ����ȳ� LIFO
- ˳��ջ
- top=base ��ջ
- base=NULL ջ������
- ����Ԫ��/ɾ��Ԫ��:top++/top�C
- top-base=stacksize ջ��
- ��ջ
- ջ��Ӧ��:����ת��,����ƥ��,�б༭����,�Թ����,����ʽ���(�沨��ʽ)
- ����:Queue
- �Ƚ��ȳ� FIFO
- rear��βָ��->ͷԪ��,front��ͷָ��->��βԪ�ص���һ��λ��
- ��������:��������,�жӿ�����
- ˳�����:����rear++,����front++
- ѭ������:
- front=rear �ӿ�
- (rear+1)%MAXSIZE=front (����һ���ռ������ֿն�)
- ����:rear=(rear+1)%MAXSIZE
- ɾ��:front=(front+1)%MAXSIZE
- �����:(rear-front+MAXSIZE)%MAXSIZE
Chapter 4
- ��
- �Ӵ�,���Ӵ�
- �����洢,�洢�ܶ�С��1
- ģʽƥ��
- �����㷨:BF�㷨(Brute Force)
- ����ָ���ظ�����
- ����ʱ�临�Ӷ� O ( n ) O(n) O(n)(nΪģʽ����,mΪ������)
- ���ʱ�临�Ӷ� O ( n ? m ) O(n*m) O(n?m)
- KMP�㷨:��Ҫ˼������������ָ���ظ�����
- next����:ֻ��ģʽ���й�,��������
- n e x t [ j ] = { 0 j = 1 max ? ( k �O 1 < k < j �� �� t 1 . . . t k ? 1 �� = �� t j ? k + 1 . . . t j ? 1 �� ) �� �� �� �� �� �� ʱ 1 e l s e next[j]=\begin{cases} 0 & j=1 \\ \max(k|1<k<j ��'t_1...t_{k-1}'='t_{j-k+1}...t_{j-1}') & ���˼��Ϸǿ�ʱ \\ 1 & else \end{cases} next[j]=??????0max(k�O1<k<j����t1?...tk?1��?=��tj?k+1?...tj?1��?)1?j=1������������ʱelse?
- KMP�㷨�Ľ�:nextval
- ʱ�临�Ӷ� O ( n + m ) O(n+m) O(n+m)
- �����㷨:BF�㷨(Brute Force)
| j j j | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 |
|---|---|---|---|---|---|---|---|---|---|---|
| ģʽ�� | a | b | a | c | a | b | a | a | a | d |
| n e x t [ j ] next[j] next[j] | 0 | 1 | 1 | 2 | 1 | 2 | 3 | 4 | 2 | 2 |
| n e x t v a l [ j ] nextval[j] nextval[j] | 0 | 1 | 0 | 2 | 0 | 1 | 0 | 4 | 2 | 2 |
Chapter 5
- ����
- ������˳��,������˳��
- ��ַ����
- ����
- ����ѹ��
- �Գƾ���
- �洢�ռ��Ż�: n 2 ? > n ( n + 1 ) 2 n^2->\frac{n(n+1)}{2} n2?>2n(n+1)?
- k = { i ( i ? 1 ) 2 + j ? 1 i �� j j ( j ? 1 ) 2 + i ? 1 i < j k=\begin{cases} \frac{i(i-1)}{2}+j-1 & i\geq j \\ \frac{j(j-1)}{2}+i-1 & i< j \end{cases} k={2i(i?1)?+j?12j(j?1)?+i?1?i��ji<j?
- ���Ǿ���
- ϡ�����:��Ԫ��洢 ( i , j , a i j ) (i,j,a_{ij}) (i,j,aij?)
- �Գƾ���
- ����ѹ��
- �����:
a
1
a_1
a1?��ͷ,
(
a
2
,
.
.
.
,
a
n
)
(a_2,...,a_n)
(a2?,...,an?)��β
- ����:Ԫ�ظ���
- ���:Ƕ�����(�ݹ�)
- ��1: A = ( ) A=() A=()����Ϊ0,���Ϊ1
- ��2: B = ( ( ) ) B=(()) B=(())����Ϊ1,���Ϊ2
- Head ȡ��ͷ,Tail ȡ��β
- ���ڵ�tag=1,ԭ�ӽڵ�tag=0
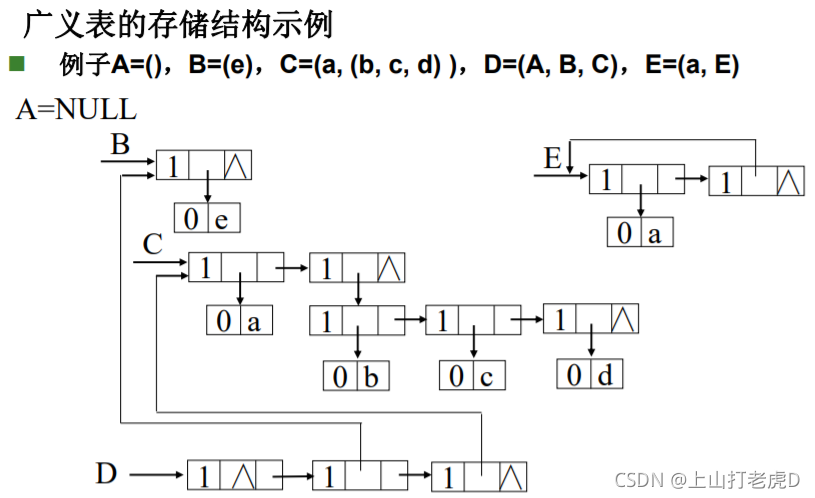
Chapter 6
- ��
- ����:�ڵ�,�ڵ�Ķ�,���Ķ�,Ҷ�ӽڵ�(�ն˽ڵ�),��֧�ڵ�(���ն˽ڵ�),����,�ֵ�,����,���,���(�߶�),������,������,ɭ��
- ����:���нڵ�����һ���ڶ�����
- ������
- ����:�� i i i�������� 2 i ? 1 2^{i-1} 2i?1���ڵ�,���Ϊ k k k�Ķ���������� 2 k ? 1 2^{k-1} 2k?1���ڵ㡣�������ն˽ڵ������ڶ��Ƚڵ�����һ
- ��ȫ������:Ҷ�ӽڵ�ֻ���������,��������ȵ�����������Ȼ��һ
- ���: ? log ? 2 n ? + 1 \lfloor\log_2{n}\rfloor+1 ?log2?n?+1
- ˫��: ? n 2 ? \lfloor\frac{n}{2}\rfloor ?2n??
- ����: 2 ? i 2*i 2?i,�Һ���: 2 ? i + 1 2*i+1 2?i+1
- ������˳��洢:�˷ѿռ�
- ��������
- ����n�ڵ�Ķ���������n+1����ָ����
- ����������:�����Խṹ���Ի�
- DLR:�������
- LDR:�������
- LRD:�������(���ڵ����һ�����)
- �沨��ʽ��һ�ֽⷨ:ͨ����������γɺ�����ʽ
- ��α���:����ʵ��(����һ���ڵ�,������Һ���)
- ����ǵݹ�ʵ��:ջ���Һ���
- ����������
- ����:ָ��ǰ���ͺ�̵�ָ��
- ��������
- ��������������Ҫջ
- ����ɭ��
- ˫�ױ�ʾ��:��������(������̫��)
- ������
- �����ֵܱ�ʾ��
- ��ָ��:����
- ��ָ��:�ֵ�
- ɭ��������ת��
- ��ɭ�ֵ��������:������һ������
- ��ɭ�ֵ��������:���������κ���
- �շ�����(���Ŷ�����)
- ·��,·������,����·������
- �ڵ�Ĵ�Ȩ·������,���Ĵ�Ȩ·������
- Ȩֵ�������,ȨֵС���Զ
- ������1�Ƚڵ�
- �����n��Ҷ�ӽڵ�,����2n-1���ڵ�
- �շ�������:���ȳ�����,Ŀ�������̱��볤��
- ���������
Chapter 7
- ͼ
-
����ͼ:�ڽӵ�,��,����
-
������ȫͼ: 1 2 n ( n ? 1 ) \frac{1}{2}n(n-1) 21?n(n?1)����
-
����ͼ:�ڽӵ�,���,����,����
-
������ȫͼ: n ( n ? 1 ) n(n-1) n(n?1)����
-
ϡ��ͼ,����ͼ
-
��ͨ,��ͨͼ,��ͨ����
-
ǿ��ͨ,ǿ��ͨͼ,ǿ��ͨ����
-
ͼ�ı�ʾ:�ڽӾ���,�ڽӱ�(���ڽӱ�)
-
����ͼ���ڽӾ���洢,ϡ��ͼ���ڽӱ��洢
-
ͼ�ı���:dfs,bfs
-
dfs:ջʵ��,�ȸ������ƹ� �ڽӾ��� O ( n 2 ) O(n^2) O(n2) �ڽӱ� O ( n + e ) O(n+e) O(n+e)
-
bfs:����ʵ��,����α��� �ڽӾ��� O ( n 2 ) O(n^2) O(n2) �ڽӱ� O ( n + e ) O(n+e) O(n+e)
-
��ͨ����
-
������(bfs������,dfs������)=������ɭ��
-
��������
- Prim�㷨:
- ѡ��˼��:�����ڳ���ͼ
- O ( n 2 ) O(n^2) O(n2)
- Kruskal�㷨
- ѡ��˼��:������ϡ��ͼ
- O ( e log ? e ) O(e\log e) O(eloge)
- Prim�㷨:
-
AOV��
- �ؼ�·��:·������,�ؼ��
- �����Ӧ�¼�,�߶�Ӧ�
- ���緢��ʱ��,������ʼʱ��
- ���翪ʼʱ��,������ʼʱ��,ʱ������
- ����:�������� ����:��������

-
���·��
- �Ͻ�˹�����㷨 O ( n 2 ) O(n^2) O(n2)
-
Chapter 9
-
���ұ�:��̬���ұ�,��̬���ұ�
-
�ؼ���:���ؼ���(Ψһ),�ιؼ���(��Ψһ)
-
��̬��:˳���,�����(�۰����,��ֵ����),����˳���,쳲���������
-
��̬��:����������,ƽ�������,B��,ɢ�б�
-
���۱�:ƽ�����ҳ���:ASL
-
˳���������:���������
- �ŵ�:��,��Ӧ���
- ȱ��:ASL�Ƚϴ�,���ݶ�ʱ����Ч�ʺܵ�
-
�������ұ�:�ȸ��������ҵ���¼���ڵĿ�,�ٴӿ�����
-
�ڱ���:ʡ�Զ��±�Խ��ļ��,����㷨ִ���ٶ�
-
�۰����(���ֲ���)
- ǰ��:����,˳��洢
- �ж���: n n n���ڵ�,����ж� ? log ? 2 n ? + 1 \lfloor\log_2{n}\rfloor+1 ?log2?n?+1��
- A S L = n + 1 n log ? 2 ( n + 1 ) ? 1 �� log ? 2 ( n + 1 ) ? 1 ASL=\frac{n+1}{n}\log_2(n+1)-1\approx\log_2(n+1)-1 ASL=nn+1?log2?(n+1)?1��log2?(n+1)?1
- ֻ�������������˳��洢
- Ч�ʺܸ�
-
����˳���
- ����:��һ���ؼ���������Ӧ�ļ�¼������Ĺ���
- �����洢�ṹ:��������,������
- �������һ����ʽ:�ؼ���ֵ+��ַ
- ����:�����������¼,ÿ������Ԫ��������һ���ؼ�����
- ������:���ؼ�������,����ÿ���ڵ������ؼ������ָ��ĵ�һ���ڵ��ָ��
- �������,��������
- �� i + 1 i+1 i+1����Ĺؼ��־�����(С��)�� i i i����ļ�¼�ؼ���
- A S L = log ? 2 ( n s + 1 ) + s 2 ASL=\log_2(\frac{n}{s}+1)+\frac{s}{2} ASL=log2?(sn?+1)+2s?(����Ϊn�ı���Ϊb��,ÿ����s����¼)
-
����������
- ��С�Ҵ�
- ������������������õ�������
- ����,ɾ��������������
-
ƽ�������(AVL��)
- ƽ������(Balance Factor):�������߶ȼ��������߶�
- ƽ�⻯��ת
- ����:��������,��������
- ˫��:�������,���Һ���
- �ʺϲ���,���ٲ����ɾ��
-
B��(��·ƽ�������)
- B-:���ն˽ڵ�������
?
m
2
?
\lceil\frac{m}{2}\rceil
?2m??������,�����
m
m
m������
- Ҷ�ӽڵ㶼ͬһ����Ҳ������κ���Ϣ
- �� m m m��B-������ N N N���ؼ���,��Ҷ�ӽڵ�(���Ҳ��ɹ��Ľڵ�)�� N + 1 N+1 N+1��
- B-:���ն˽ڵ�������
?
m
2
?
\lceil\frac{m}{2}\rceil
?2m??������,�����
m
m
m������
-
B+��
- һ���ڵ��� N N N���ؼ���,��һ���� N N N������
- Ҷ�ӽڵ㰴С��������
- Ҷ�ӽ�������ȫ����¼�Ĺؼ�����Ϣ�Լ��ؼ��ּ�¼��ָ��
- ���ն˽ڵ���ֻ�������������ڵ��������С�ؼ���
-
��ϣ
- ��ϣ�洢:����洢
- ��ϣ����:�ؼ������Ӧ��ַ����ϵ(��ϣ������һ��ѹ��ӳ��)
- ֱ�Ӷ�ַ��:�ؼ��ֵ����Ժ���,�������ڵ�ַ����ؼ��ּ��ȴ�
- ���ַ�����:ѡ��λ
- ƽ��ȡ�з�:�����ڹؼ�����(�Ƚϳ���)
- �۵���:��λ���,������(��������)��������ָ� �����ڹؼ���λ���Ƚ϶�,���ֲַ��ȽϾ��ȵ����
- ����������:���,��á�(ѡ������,��20���������ӵĺ���)
- ��ƹ�ϣ����Ӧ����:
- �����ϣ��������ʱ��
- �ؼ��ֳ���
- ��ϣ����С
- �ؼ��ֲַ����
- ��¼����Ƶ��
- �����ͻ
- ���Ŷ�ַ��:����̽����ɢ��,����̽����ɢ��,α���̽����ɢ�С�������ÿռ�,���Ƚ����ײ����ۼ�
- �ٹ�ϣ��:�������ɸ���ϣ����,���ۼ������Ӽ���ʱ��
- ����ַ��(������):��ǰ����/�������
- �������������
- ��ϣ����:���մ�����ͻ�ķ�ʽ����,֪����ַ��ӦֵΪ��
- װ������ �� = �� ¼ �� �� ϣ �� �� \alpha=\frac{��¼��}{��ϣ����} ��=��ϣ������¼��?
- ����̽����ɢ��: A S L = 1 2 ( 1 + 1 1 ? �� ) ASL=\frac{1}{2}(1+\frac{1}{1-\alpha}) ASL=21?(1+1?��1?)
- ����̽����ɢ��: A S L = ? 1 a ln ? ( 1 ? a ) ASL=-\frac{1}{a}\ln{(1-a)} ASL=?a1?ln(1?a)
- ����ַ��: A S L = 1 + �� 2 ASL=1+\frac{\alpha}{2} ASL=1+2��?
-
����
- ��������:ʱ�临�Ӷ�,�����ռ�,�ȶ���
- �ڲ�����
- ��������
- ֱ�Ӳ�������
- �ȶ�
- ������:�Ƚ� n ? 1 n-1 n?1�� �ƶ� 0 0 0��
- ������:�Ƚ� n ( n ? 1 ) 2 \frac{n(n-1)}{2} 2n(n?1)?�� �ƶ� 1 2 ( n ? 1 ) ( n + 4 ) \frac{1}{2}(n-1)(n+4) 21?(n?1)(n+4)��
- ϣ������
- ���ȶ�
- �˷���ֱ�Ӳ�������ÿ��ֻ�ܽ�������������¼��ȱ��
- ֱ�Ӳ�������
- ѡ������
- ��ѡ������
- ���ȶ�
- �����ռ� O ( 1 ) O(1) O(1)
- ʱ�临�Ӷ� O ( n 2 ) O(n^2) O(n2)
- ������
- ���ȶ�
- �����ռ� O ( 1 ) O(1) O(1)
- ʱ�临�Ӷ� O ( n log ? n ) O(n\log{n}) O(nlogn)
- ��ѡ������
- ��������
- ����
- �ȶ�
- ʱ�临�Ӷ� O ( n 2 ) O(n^2) O(n2)
- ��Ƚϴ��� n ( n ? 1 ) 2 \frac{n(n-1)}{2} 2n(n?1)?,�������� 3 n ( n ? 1 ) 2 \frac{3n(n-1)}{2} 23n(n?1)?
- ��������
- ���ȶ�
- ���ʱ�临�Ӷ� O ( n log ? n ) O(n\log{n}) O(nlogn)
- �ʱ�临�Ӷ� O ( n 2 ) O(n^2) O(n2)
- ����
- �鲢����
- �ȶ�
- 2·�鲢
- �����ռ� O ( n ) O(n) O(n)
- ʱ�临�Ӷ� O ( n log ? n ) O(n\log{n}) O(nlogn)
- ��������
- �ȶ�
- ʱ�临�Ӷ� O ( d ( n + r a d i x ) ) O(d(n+radix)) O(d(n+radix))(�ؼ���dλ,ÿλ����radix,n������)
- �����ռ� O ( n + r a d i x ) O(n+radix) O(n+radix)
- ��������
������Dz�����,ֻ�ǵ�ȥ����Ը����⿼��ʮ������
д�ں���
�ǵ�ȥ�꿼���ݽṹʱ��ͷ�ö�,����ǰһ������ͨ��һ��������ϰ��һ���顣��ʱ����Ҫ��,���ں��������ǿ���⡣���ڰѵ�ʱ�ʼ����������·�������,�����Ҹ�ϰ����Ҽ����!!!