走进链表
概念&结构
链表是一种物理存储结构上非连续,非顺序的存储结构。数据元素的逻辑顺序是通过链表中的指针指向来实现的。
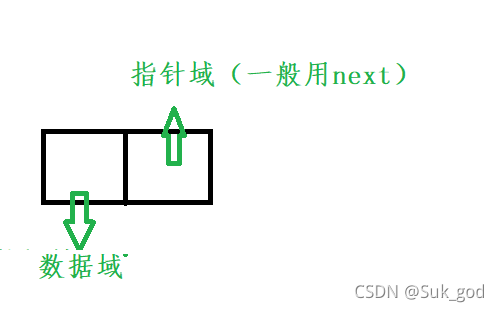
特点
1.物理存储单元不连续
2.依靠指针强前后元素关联起来
3.随用随开辟
链表的分类
1.单向、双向链表


2.带头或者不带头
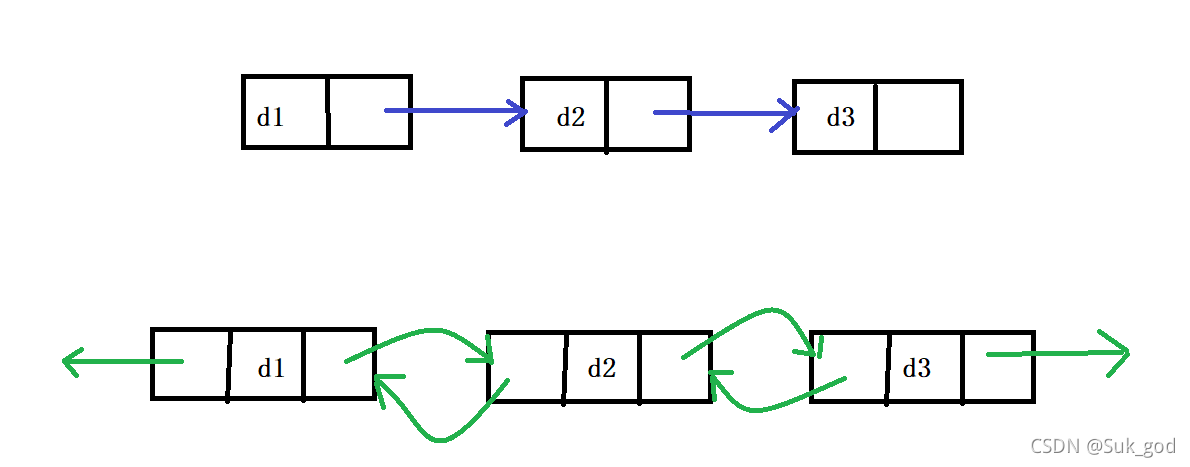
3.循环或者非循环


总结
这么看来,链表情况很多啊,总共有8种组合!我们都要熟练掌握吗?当然可以,但是这8种里面只有两种数实际常用的组合。他们分别是:
无有单向非循环链表=
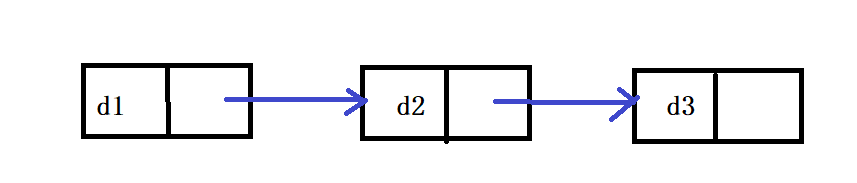
带头双向循环链表
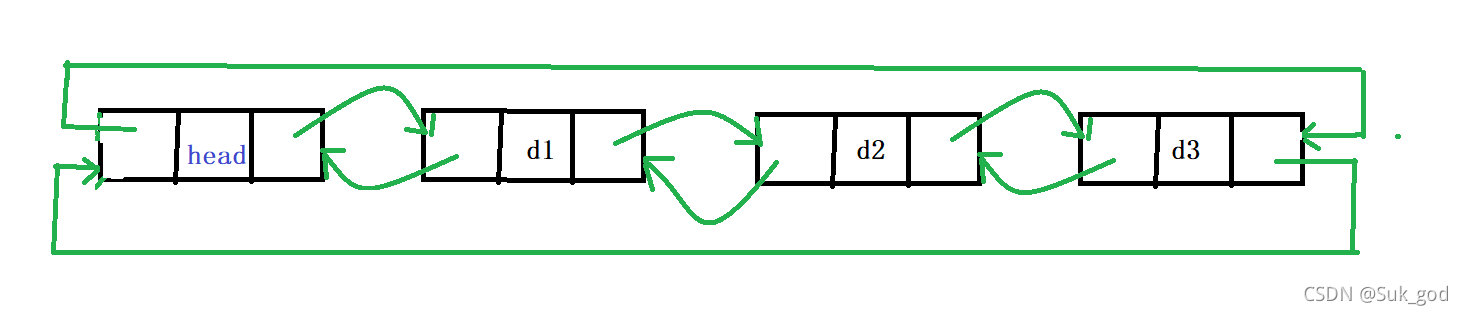
不带头结点、非循环的单链表
结构
typedef int SLDateType;
typedef struct SListNode
{
SLDateType val;//数据域
struct SListNode *next;//指针域
}SListNode;
增删查改打印等基础操作
申请结点
由于链表具有随用随开辟的特点,所以每当要在链表中加入元素的时候,就会想内存申请一个空间来存储该元素的信息。
所以需要动态申请空间(malloc)
头插&尾插
要想向链表中插入一个元素,不管是头插还是尾插,都要考虑以下情况:
1.链表是否为空?
若链表为空,插入的元素就是链表新的头结点。
若链表不空:
1.头插:插入后,头结点发生改变。变成新插入的结点
2.尾插:不会影响头结点,但是需要循环遍历链表,找到之前的尾结点之后再将元素加在该结点后面。
2.在插入元素的过程中,指针改变问题
针对于上一条遗留的指向头结点的指针会发生改变:
我们先来看这样一个例子:
如何使用函数交换两个整型变量的值?
我相信大家对这个函数很熟悉了;`
void Swap(int *xp, int* yp)
{
int temp = *xp;
*xp = *yp;
*yp = temp;
}
那么,这道题函数的参数为什么要传递一级指针呢??
原因是:
函数传参发生临时拷贝,会在函数内部形成一份临时变量,函数执行完成后变量的内存空间也随之被释放。
那么我们要想对该函数外的变量进行交换的话,就必须能够在该函数内操作函数外的变量。我们都知道,只要把外部变量的地址当做函数参数传进来,就可以达到这样的目的。
好的,我们类比一下现在的情况。
我们目前需要改变外部传入的指针变量的指向,我们要怎么做呢??当然是传入指针变量的地址,那不就是二级指针吗??
注意:指针变量也是变量,是变量就要开辟内存空间,有内存空间就有地址能够访问到它!
总结:想要改变一个变量的内容,只需要改变它地址的指向~~
// 单链表的头插
void SListPushFront(SListNode** pplist, SLDateType x)
{
SListNode* newNode = BuySListNode(x);
1.链表为空
//if (NULL == *pplist)
//{
// *pplist = newNode;
//}
2.链表不空
//else
//{
// newNode->next = *pplist;
// *pplist = newNode;
//}
//两种情况合并
newNode->next = *pplist;
*pplist = newNode;
}
// 单链表尾插
void SListPushBack(SListNode** pplist, SLDateType x)//二级指针的理解:pplist指向可能会发生变化
{
//1.尾插时原链表是空链表
if (NULL == *pplist)
{
*pplist = BuySListNode(x);
return;
}
//2.不是空链表
SListNode* cur = *pplist;
//遍历找到尾结点后插入
while (cur->next)
{
cur = cur->next;
}
cur->next = BuySListNode(x);
}
头删&尾删
删除元素,也会有插入元素时指针改变的问题~~
删除该元素时,记得进行free操作(因为每一个结点都是在堆上malloc动态开辟的)
// 单链表头删
void SListPopFront(SListNode** pplist)
{
assert(pplist);
//能不能删除??
//1.链表为空,不能删除
if (NULL == *pplist)
{
printf("链表为空,无法删除!\n");
return;
}
//2.链表不空,可以删除
SListNode* deleteNode = *pplist;
*pplist = (*pplist)->next;
free(deleteNode);
deleteNode = NULL;;
}
// 单链表的尾删
void SListPopBack(SListNode** pplist)
{
assert(pplist);
//考虑是否可以删除??
//1.空链表
if (NULL == *pplist)
{
return;
}
//2.非空链表
//a.链表只有一个元素
else if (NULL == (*pplist)->next)
{
free(*pplist);
*pplist = NULL;
}
//b.有多个元素
else
{
SListNode* tailNode = *pplist;
SListNode* prev = NULL;
while (tailNode->next)
{
prev = tailNode;
tailNode = tailNode->next;
}
prev->next = NULL;
free(tailNode);
tailNode = NULL;
}
}
查找
不破坏链表结构
// 单链表查找
SListNode* SListFind(SListNode* plist, SLDateType x)
{
if (NULL == plist)
{
return NULL;
}
SListNode* cur = plist;
while (cur)
{
if (cur->val == x)
return cur;
else
cur = cur->next;
}
return NULL;
}
打印输出
循环遍历,输出即可
// 单链表打印
void SListPrint(SListNode* plist)
{
if (NULL == plist)
{
return;
}
SListNode* cur = plist;
while (cur)
{
printf("%d--->",cur->val);
cur = cur->next;
}
printf("NULL\n");
}
任意位置插入
在pos后插入元素x
void SListInsertAfter(SListNode* pos,SLTDateType x);
思考为什么要在pos之后插入?
函数传进来的参数位置为pos,而我们的单向非循环链表,在只有pos指针的前提下是没有办法找到pos之前的元素的,所以只能在pos后插入。
void SListInsertAfter(SListNode* pos, SLDateType x)
{
if (NULL == pos || pos->next == NULL)
{
return;
}
SListNode* newNode = BuySListNode(x);
newNode->next = pos->next;
pos->next = newNode;
}
任意位置删除
删除pos的下一个元素
void SListErasetAfter(SListNode* pos);
思考为什么不删除pos的位置?
如果删除pos位置的元素,那么我们无法将pos的前半段链表和pos的后半段链表连接起来,会造成数据的丢失和内存的泄露。所以只能删除pos的后一个结点。
void SListEraseAfter(SListNode* pos)
{
if (NULL == pos || NULL == pos->next)
{
return;
}
SListNode* deleteNode = pos->next;
pos->next = deleteNode->next;
free(deleteNode);
deleteNode = NULL;
}
最重要的一项操作
链表是动态开辟出来的,那么我们一定要在用完之后释放掉!!!
//释放整个链表
void DestorySList(SListNode ** pplist)
{
assert(pplist);
SListNode* cur = *pplist;
while (cur)
{
(*pplist) = cur->next;
free(cur);
cur = *pplist;
}
*pplist = NULL;
}
优缺点
优点:
1.空间开辟方便,能够做到不浪费空间
2.插入元素时只需要改变相关指针的指向,不需要大量移动其他元素。
3.不需要连续的内存空间
缺点
1.查询元素不方便,需要遍历整个链表
2.反向遍历比较困难,用递归实现的话,如果链表元素过多,就会有可能出现栈溢出的问题。
源码分享
各位看官们欢迎来我的Git获取相关代码!!
以上就是对于不带头单向非循环链表的总结~~对你有所帮助的话记得一键三连呀~