����ѧϰ04:�������ر�Ҷ˹�б��������۵������û�(���չ�˾���ݼ�)
����Ŀ¼
ǰ��
�ڻ���ѧϰ����������㷨ͨ��һϵ�о�������,�߽�(������,kNN�㷨,֧����������)���Ը������Խ��л��֡�Ȼ���������㷨ȴ���������ij����ֵķ������,���ԭ��ܴ������,�㷨�����ľ��߽߱��������ѵ�����������ǽ�����ܵ��㷨���ر�Ҷ˹ʹ�ñ�Ҷ˹��ʽ��Ϊ�㷨����,������Ѱ�Ҿ��߽߱����������,���㷨����ȥ�����������ʡ�����ʲô��˼��?���Ǽ���Ҫ�������������������:
�� ����ĺ�ϲ���㰡��������������������,����Carol!,Ϊ������Ҫ�ú�ѧϰŬ������,��һ����������õ���!!!!!!!!!!!!!!!��
�ĺ�🥰��😅�����ʹ�þ������������ǿ��ܻ�ȥѰ�Ҽ����ؼ���Ȼ������������ࡣ���ǻ������ر�Ҷ˹����,����Ҫȥ����ļ�������һ�����õ�����������,����������ַ����ĸ��ʡ�ͬ������Ҳ��Ҫ��������һ���õ�����,����������ַ����ĸ��ʡ����Ƚ����������ʵĴ�С�������������۷����Ǻ�🥰��😅��
��ƪ�����㷨�����Լ���Դ,��Ҫ�Ļ�������github��ȡ(liujiawen-jpg/Naive-Bayes: ʹ�����ر�Ҷ˹�㷨�Ժ��չ�˾�������ݼ����з��� (github.com))
1.�㷨���۷���
1.1��Ҷ˹��ʽ
��Ҷ˹��ŷ����������������ѧ��,�������������˾�Ĺ��ס����������ı�Ҷ˹��ʽ��ʽ��ʵ�dz���:
P
(
A
�O
B
)
=
P
(
B
,
A
)
P
(
B
)
=
P
(
B
�O
A
)
P
(
A
)
P
(
B
)
P(A \mid B)=\frac{P(B, A)}{P(B)}=\frac{P(B \mid A) P(A)}{P(B)}
P(A�OB)=P(B)P(B,A)?=P(B)P(B�OA)P(A)?
�����ʽ������ͨ�ؽ���һ�°ɡ����Ǽ������ڸ����ַ���B:
�� ����ĺ�ϲ���㰡��������������������,����Carol!,Ϊ������Ҫ�ú�ѧϰŬ������,��һ����������õ���!!!!!!!!!!!!!!!��
���Ǽ���A�Ǹ���������������һ�ࡣ��������Ҫ����B�ַ��������ݼ���������������͵ĸ���P(A|B)��ͨ����Ҷ˹��ʽ��ת��,ת����������Ϊ�������ĸ���P(A)�뵱������������ʱ�ַ���������:
�� ����ĺ�ϲ���㰡��������������������,����Carol!,Ϊ������Ҫ�ú�ѧϰŬ������,��һ����������õ���!!!!!!!!!!!!!!!��
�ĸ��ʡ��������ǽ���һ������������ʡ���ʵ�������ù�ȥ��֪ʶ�Ƶ������ĸ��ʡ�������������ʮ�������������۳��ֵĸ�����0.7,��ô���Ǿ���Ϊ���P(A)=0.7������������һ������P(B)����˼��������ַ������������۳��ֵĸ���,����Ƿdz�����ġ��ر��������������û��Ӵ�Ľ���,�ҿ������ýű�ˢ����,���߶���û�����ճ��������,�������Ҫȥȡ��������Ƿdz��ѵġ���ô���ǿɲ����Բ��������?������������һ����ʽ,���Ǽ����������😈ΪC����ôͬ���ɵ��ַ���B����C��ĸ���Ϊ:
P
(
C
�O
B
)
=
P
(
B
,
C
)
P
(
B
)
=
P
(
B
�O
C
)
P
(
C
)
P
(
B
)
P(C \mid B)=\frac{P(B, C)}{P(B)}=\frac{P(B \mid C) P(C)}{P(B)}
P(C�OB)=P(B)P(B,C)?=P(B)P(B�OC)P(C)?
���Կ���P(C|B) ��P(A|B)�ķ�ĸ��һ��,��ô���DZȽϴ�Сֻ��Ҫ�ȽϷ��Ӽ���,��ĸ����Ҫ����,Ҳ����˵:
P
(
A
�O
B
)
��
P
(
B
�O
A
)
P
(
A
)
P(A \mid B) \propto P(B \mid A) P(A)
P(A�OB)��P(B�OA)P(A)
1.2 ���ر�Ҷ˹������(Na?ve Bayes Classifie)
��ôʲô�����ر�Ҷ˹��������,Ϊ�˸���ͨ�ؽ���������ӡ������Ǽ���ʹ����������˵�������Ƕ�����ʹ�õ��ַ��������з�:
import re
import jieba.posseg as pseg
#�������ַ���������ϸ������ҿ��Բ鿴��֮ǰ�IJ��� https://blog.csdn.net/theworld666/article/details/116904510
def word_slice(lines):
corpus = []
corpus.append(lines.strip())
stripcorpus = corpus.copy()
for i in range(len(corpus)):
stripcorpus[i] = re.sub("@([\s\S]*?):", "", corpus[i]) # ȥ��@ ...:
stripcorpus[i] = re.sub("\[([\S\s]*?)\]", "", stripcorpus[i]) # [...]:
stripcorpus[i] = re.sub("@([\s\S]*?)", "", stripcorpus[i]) # ȥ��@...
stripcorpus[i] = re.sub(
"[\s+\.\!\/_,$%^*(+\"\']+|[+����!,��?��~@#¥%����&*()]+", "", stripcorpus[i])
# ȥ����㼰�������
stripcorpus[i] = re.sub("[^\u4e00-\u9fa5]", "",
stripcorpus[i]) # ȥ�����зǺ�������(Ӣ������)
stripcorpus[i] = re.sub("ԭ����", "", stripcorpus[i])
stripcorpus[i] = re.sub("�ظ�", "", stripcorpus[i])
stripcorpus[i] = re.sub("(��)", "", stripcorpus[i]) # �൱��replace
#������ʹ��re����ϴ����,����Ӱ��ԭ����˼�������ַ�ȫ��ȥ��
onlycorpus = []
for string in stripcorpus:
if(string == ''):
continue
else:
if(len(string) < 5):
continue
else:
onlycorpus.append(string)
cutcorpusiter = onlycorpus.copy()
cutcorpus = onlycorpus.copy()
wordtocixing = [] # ����ִʺ�Ĵ���
for i in range(len(onlycorpus)):
cutcorpusiter[i] = pseg.cut(onlycorpus[i])#��
cutcorpus[i] = ""
for every in cutcorpusiter[i]:
cutcorpus[i] = (cutcorpus[i] + " " + str(every.word)).strip()
wordtocixing.append(every.word)
return wordtocixing
lenx=[]
content = ["����ĺ�ϲ���㰡��������������������,����Carol!,Ϊ������Ҫ�ú�ѧϰŬ������,��һ����������õ���!!!!!!!!!!!!!!"]
for string in content:
if not isinstance(string,str):
continue
lines=word_slice(string)
print(lines)
������: [���ҡ�, ����ġ�, ���á�, ��ϲ����, ���㡯, ����������, ����������, ����������, ������, ������, ���졯, ���֡�, ��Ϊ�ˡ�, ���㡯, ���ҡ�, ��Ҫ��, ���ú�ѧϰ��, ��Ŭ����, �����С�, ������, ��һ����, ���ԡ�, ����ᡯ, �����á�, ���ġ�, ���ˡ�]
�������ǵ����۴�������,�����������з���ɾ�����б�������Ӣ�ġ����Կ�����������Ľ����һ�ѵ��ʵ�����б�����Կ������ǵ���������x,��ô��������Ĺ�ʽ������ȡ�ĸ���ת��Ϊ
P
(
c
�O
x
)
=
P
(
c
)
P
(
x
�O
c
)
P
(
x
)
P(c \mid \mathbf{x})=\frac{P(c) P(\mathbf{x} \mid c)}{P(\mathbf{x})}
P(c�Ox)=P(x)P(c)P(x�Oc)?
P?���������֪,P(x)��������ô�����������ǻ�û������ľ���P(x|c)��������ʵ���˼��,���������C��ʱ��,���Dz���x��һ�б��ĸ��ʡ�����ô����?��ʱ�����Ǿ͵�ʹ�����ر�Ҷ˹�����ˡ����ر�Ҷ˹�������о�������ȫ���������������Ӱ��ġ�Ҳ�������dz�˵��
P
(
A
,
B
)
=
P
(
A
)
P
(
B
)
P(A,B) = P(A)P(B)
P(A,B)=P(A)P(B)
��ôҲ����˵���������һ�ѵ��������е��ʶ��ǻ���Ӱ��ġ����統"���"������ʳ��ֺ�,�����á�������ʵij��ָ���û���κι�ϵ,�����ǹ�ϵ�dz�С����������ȫ����������ôͨ��������Щ�����������ս�����ת��Ϊ:
P
(
c
�O
x
)
=
P
(
c
)
P
(
x
�O
c
)
P
(
x
)
=
P
(
c
)
P
(
x
)
��
i
=
1
d
P
(
x
i
�O
c
)
P(c \mid \mathbf{x})=\frac{P(c) P(\mathbf{x} \mid c)}{P(\mathbf{x})}=\frac{P(c)}{P(\mathbf{x})} \prod_{i=1}^{d} P\left(x_{i} \mid c\right)
P(c�Ox)=P(x)P(c)P(x�Oc)?=P(x)P(c)?i=1��d?P(xi?�Oc)
��ô��ô��P(x|c)��?�������������̽��
1.3 �ʼ�ģ�ͺʹʴ�ģ��
�������ǵ�����ת������������xi���Գ�����C���еĸ��ʡ������ô����?���ǿ���ͳ������C����еĴ��顣�����ҽ�ѵ��������������C����D���ı��ĵ���ȫ�����ϳ�һ������n���ʵ��ֵ䡣��ô���ʱ�����ǿ������:
p
(
x
i
�O
c
)
=
�O
D
c
,
x
i
�O
�O
D
c
�O
D
c
��
ʾ
ѵ
��
��
��
��
��
C
��
��
��
��
��
�O
D
c
,
x
i
�O
��
ʾ
ѵ
��
��
��
��
��
C
��
��
��
��
i
��
��
��
ȡ
ֵ
Ϊ
x
i
��
��
��
p\left(x_{i} \mid c\right)=\frac{\left|D_{c, x_{i}}\right|}{\left|D_{c}\right|}\\D_c��ʾѵ����������C���ļ���\\|D_{c, x_{i}}| ��ʾѵ����������C����ڵ�i������ȡֵΪx_i�ļ���
p(xi?�Oc)=�ODc?�O�ODc,xi??�O?Dc?��ʾѵ����������C�����������ODc,xi??�O��ʾѵ����������C��������i������ȡֵΪxi?������
��ô���ǵ������ת��Ϊͳ����������C������ڵ�i��������ȡֵΪxi������,��������ȫ��C�������������,����������Եĸ���ȫ����˾͵õ������ǵ�p(x|c).��ô���ڼ������������������������ȫ��ͬ�ķ��������������������ܵĴʼ�ģ�ͺʹʴ�ģ�͡�
1.3.1�ʼ�ģ��
����������������ѵ���ı�����һ���������е��ʵ��ֵ伯��������û���κ��ظ���Ԫ�ذɡ�������1000�����ʡ���ô����Ϊ�˷���ͳһ�����������ݡ����ǽ����еľ���ȫ������Ϊ���ȵ�һǧ���б�������б���ȫ��������͵��ʳ��ִ����Ĺ�ϵ,����ͳ��1000�����ʳ����ھ���������������Ϊ0������Ϊ1:
def createVocabList(dataSet):
vocabSet = set([])
for document in dataSet:
vocabSet = vocabSet | set(document) #ɾ���������ظ��ĵ���
return list(vocabSet) #���ز��ظ��ĺ���ѵ�������е��ʵĴʼ�
def setOfWords2Vec(vocabList, inputSet): #�������������ݹ���ʼ�
returnVec = [0]*len(vocabList) #��ʼ������ȫ0����
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1 #�õ��ʳ��־ͼ�Ϊ1
else:
print("the word: %s is not in my Vocabulary!" % word)
return returnVec
��ô���Ǽ������ڵ�C��ڶ�������ȡֵΪ����"�ľ�����100��,��C���1000������,��ô���ǵĸ��ʾ͵���:
P
(
x
i
�O
c
)
=
100
/
1000
=
0.1
P(x_i \mid c) = 100/1000 = 0.1
P(xi?�Oc)=100/1000=0.1
��������б�ƽ��ȫ�����˵��ʳ��ִ����������Ӱ��,ͬһ�����ʶ�γ���˵���õ��ʵ���˼�ھ����п����Ƿdz���Ҫ��(����ظ���ǿ������),����Ϊ���������Ӱ��,����ʹ���˴ʴ�ģ�Ͷ������������и��ơ�
1.3.2 �ʴ�ģ��
�ʴ�ģ��������һ��Ҳ��Ҫ�ȹ������е�����ɵ��ı���Ȼ�������������,���Dz��ǵ�����ͳ�Ƹõ����Ƿ���ֶ���ͳ�����е��ʳ��ֵĸ���,���ǻ���ͳ�����뵥�ʳ��ֵĴ����������������������ͼ�������ʾ��

�������Ĵ���ֻ��Ҫ�ڴʼ������Ͻ���������:
def bagOfWord2VecMN(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for words in inputSet:
if words in vocabList:
returnVec[vocabList.index(words)]+=1
return returnVec
��ôͬ���������Ǽ������ڵ�C��ڶ�������ȡֵΪ����"�ľ�����100��,��C���1000������(��������������һ��)����һ���������к���1000���� �� ��,1000����������100000������ô���ǵĸ��ʾ͵���:
P
(
x
i
�O
c
)
=
1000
/
100000
=
0.01
P(x_i \mid c) = 1000/100000 = 0.01
P(xi?�Oc)=1000/100000=0.01
���Կ������������صĽ���Dz�һ�µ�,�ڶ��ھ�������ѡ������㷨��ѡ���Ǵʼ��㷨���Ǵʴ��㷨�Ե���Ϊ��Ҫ��
? �㷨�����������Ѿ����е���β��😲,���Ǽ��������ʦ�������㷨ʵ����ʱ����㷨������һ��������,����ѧ���ֶ����ǽ�����һ���̶ȵ��Ż�
1.4 ������˹����
���Ǽ���"��ª"������ʴ���û����ѵ����C�������г��ֹ�,����������֤�����������ǵļ�������ʲô������?����Ȼ���ǵ�ͳ�ƸĴʵĸ���Ϊ0.һ��0��һ����ʽ�л�ʹ���ճ˻�Ϊ0.��ô������������ʲô���Զ���������������ǵľ�����������:
? ��������ɰ��ļ�Ȼ��һ����������ھ���ij�ª�ƻ���
��仰��Ȼ�Ƕ����˵�����,�������������ᵽ��Ӱ��ֱ��ʹ��仰����Ϊ�������������Ӱ����������ʹ��������˹���������������������,��Ҷ˹��ʽ����Ϊ:
P
^
(
c
)
=
�O
D
c
�O
+
1
�O
D
�O
+
N
P
^
(
x
i
�O
c
)
=
�O
D
c
,
x
i
�O
+
1
�O
D
�O
+
N
i
\hat{P}(c)=\frac{\left|D_{c}\right|+1}{|D|+N} \quad \hat{P}\left(x_{i} \mid c\right)=\frac{\left|D_{c, x_{i}}\right|+1}{|D|+N_{i}}
P^(c)=�OD�O+N�ODc?�O+1?P^(xi?�Oc)=�OD�O+Ni?�ODc,xi??�O+1?
����N,NiΪC�����ܹ�ȡֵ����������Ϊ�˷�ֹDcΪ0,���ǶԷ��ӽ��м�һ������ͨ��������������������ѵ�������ܵ��µ�����ʧ����������ʵ����һ�������Ǿ��Ƕ���dz�С����(����1000��)����������ѧ�����������ҿ��Լ���ġ����ڼ�������ִ�������Զ��ڸ�����������С����ֵ�ġ�������0.1��1000�η����dz�С���Լ����ø�������ʾ��������������ʹ�ö���������������
1.5 ʹ�ö��������ֹ�����
�ڴ�������ln(a*b) = ln(a)+ln(b),��˿������������۳�ת���ɶ����ۼӡ���ʵ֮��������ô������Ҳ������̫����������Ϊy=x �� y=lnx ���ߵ������Ժ���������һ�µ�:
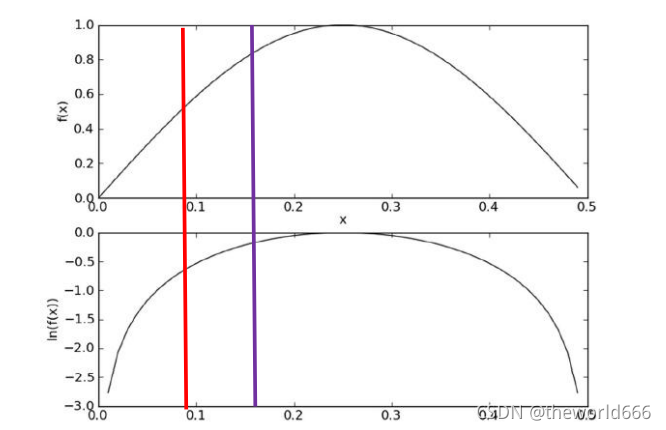
����������Աȸ��ʵĶ����ۼӷ� ��������ֵ,��ȷ�����ֵ���� ���������ǵĹ�ʽת��Ϊ:
P
(
c
�O
x
)
=
P
(
c
)
P
(
x
�O
c
)
P
(
x
)
��
[
l
n
(
P
(
c
)
)
+
��
i
=
1
d
l
n
(
P
(
x
i
�O
c
)
)
]
P(c \mid \mathbf{x})=\frac{P(c) P(\mathbf{x} \mid c)}{P(\mathbf{x})} \propto [{ln(P(c))} + \sum_{i=1}^{d} ln(P\left(x_{i} \mid c\right))]
P(c�Ox)=P(x)P(c)P(x�Oc)?��[ln(P(c))+i=1��d?ln(P(xi?�Oc))]
�������ǵ�����ͳ��������ˡ���ô���ھ͵�������ʹ���㷨����ʵ����ʱ���ˡ������������������DZ��ε����ݼ���
2. ���ݼ�Ԥ����
����ʵ�����Dz����������չ�˾��Tweet�϶����ǹ�˾���۽��л��ܵ����ݼ�(���ص�ַ:Twitter US Airline Sentiment | Kaggle),��Ϊ�ĸ�ÿ�����۶����ϱ�ǩ,һ����������ǩneural(������),positive(������),negative(������)��

��������ʵ��ֻѡȡ���л��������ۺ���ͬ����������������ʹ�����ر�Ҷ˹����������ѵ�����������ݸ�ʽΪcsv���ݼ����˷dz�����������������ڴ˴δ�����ʱ��ֻѡ��text�����ı�,��sentiment�����������ڷ���:
import pandas as pd
data = pd.read_csv('Tweets.csv')
data = data[['airline_sentiment', 'text']] #��ȡ���������ı��ͱ�ǩ����
data.airline_sentiment.value_counts() #�鿴��ǩ�����ݷֲ�
������:
negative 9178
neutral 3099
positive 2363
���Կ���������չ�˾��̫�а�😂😂,14000�����������ݼ�9178���Ƕ������õ����ۡ��������ѵ������������Ļ�,���ʱ����ʵ���Ǹ������ݷֲ�һ�¼����е�����һ�²Ų������������ڷ����ʱ��Ӱ�������(ʹ��ѭ�������紦�������ݼ�Ҳ����:RNNѧϰ:����LSTM,GRU�������չ�˾��������Ԥ������_theworld666�IJ���-CSDN����)�����������ʹ�õ��DZ�Ҷ˹�Ļ�,����Ϊ�˻�ø�����ʵ��������ʲ�Ӧ���������Ĵ�����������������������ʹ��ȫ�����������ݺ�ȫ���Ļ������ݽ��д���:
sentiment_to_index = {'positive': 1, 'negative': 0}
def to_index(sentiment): # ���ú���ת����ǩ
return sentiment_to_index.get(sentiment)
data_good = data[data.airline_sentiment == 'positive']
data_negative = data[data.airline_sentiment == 'negative']
dataSet = pd.concat([data_good,data_negative]) #����������������һ��
dataSet['sentiment'] = dataSet.airline_sentiment.apply(to_index) #����ǩ�滻��0��1
del dataSet['airline_sentiment'] # ɾ��ԭ�е�һ��
dataSet = dataSet.sample(len(dataSet)) #���ݼ����д��Ҵ���
��ô���ǵ����ݼ����ձ㴦�������,�ٽ�����ת��Ϊ�ʼ����ߴʴ�ģ��ǰ,����������Ը����ݼ���дһ�����ر�Ҷ˹���������롣
3.���ر�Ҷ˹�㷨����
def trainNB0(trainMatrix, trainCategory):
numTrainDocs = len(trainMatrix) #trainMatrix����������ת��Ϊ�ʼ���ļ���
numWords = len(trainMatrix[0]) #ͳ��ÿ��Ԫ�صij���
pAbusive = np.sum(trainCategory)/np.float(numTrainDocs) #�����������۵��������
p0Num = np.ones(numWords)
p0Demon = 2.0
p1Num = np.ones(numWords) #����������˹������ԭ����ȫ1����ͷ�ĸ��ʼֵΪ2
p1Demon = 2.0
for i in range(numTrainDocs):
if trainCategory[i] ==1:
p1Num +=trainMatrix[i]
p1Demon += np.sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Demon+= np.sum(trainMatrix[i]) #�ֱ�ͳ�Ƶ�0��͵�һ��ʵ�������
p1Vect = np.log(p1Num/p1Demon)
p0Vect = np.log(p0Num/p0Demon)#Ϊ�˷�ֹ̫��̫С������˵������������ȡ��������
return p0Vect,p1Vect,pAbusive #���ص�0��͵�һ��ÿ�����ʵĸ��ʺ͵�һ�����۵��������
#���ø����ľ���,�Լ��������з���
def classifyNB(vec2Classify, p0Vec, p1Vec, p1Class):
p0 = np.sum(vec2Classify*p0Vec)+np.log(1.0-p1Class) #������p0Class = (1.0-p1Class)
p1 = np.sum(vec2Classify*p1Vec)+np.log(p1Class)
if p0 > p1:
return 0
else:
return 1
ͨ���������Ǿ������������˹�����µ����ر�Ҷ˹�㷨�ı�д,���Կ�����ʵ����dz���,������ʵ��Ҷ˹�ĺô����������ٶ���ʵ�dz���Ҳ�dz�������Ƕ�롣��ô�������ڽ��в������в������ս�����з�����
4.���Բ��������
�����ڵ�2�������ݼ�Ԥ�����½�һ����д��������:
import re
token = re.compile('\\w*') #ʹ��Ԥ����ӿ�ƥ���ٶ�
def textParse(bigString):
listOfToken = token.findall(bigString)
return [str.lower() for str in listOfToken if len(str)>0] #���շ������е���
#��������ѵ�������е��ʵĴʼ�
def createVocabList(dataSet):
vocabSet = set([])
for document in dataSet:
vocabSet = vocabSet | set(document) #ɾ���������ظ��ĵ���
return list(vocabSet)
def setOfWords2Vec(vocabList, inputSet):
returnVec = [0]*len(vocabList)
for word in inputSet:
if word in vocabList:
returnVec[vocabList.index(word)] = 1
else:
print("the word: %s is not in my Vocabulary!" % word)
return returnVec
def airlineSentimentTest(dataSet):
dataStr = np.array(dataSet['text']).tolist() #���ı����������б��洢
docList = [textParse(sentence) for sentence in dataStr]
classList = np.array(dataSet['sentiment']).tolist() #�����б�ǩ����ʹ���б��洢
vocabList = createVocabList(docList)
testNum = int(len(classList)*0.3) #ȡ�ٷ�֮��ʮ�����������Լ�
testData = docList[:testNum] #�������ݼ���ǰ����,����ֱ��ȡǰ�ٷ�֮��ʮ����
testClassList = classList[:testNum]
trainData = docList[testNum:]
trainClassList = classList[testNum:]
trainMat = []
for data in trainData:
trainMat.append(setOfWords2Vec(vocabList,data)) #�������ݼ����������ݼ�ʹ�ôʼ�ģ������ʾ
p0V, p1V, pSPam = trainNB0(np.array(trainMat), np.array(trainClassList)) #ͨ��ѵ�����ݼ��ɼ�������ʵ�һϵ��ģ��
errorCount = 0
for i in range(len(testData)): #ͳ�Ʋ��Լ����д������
wordVector = setOfWords2Vec(vocabList, testData[i])
if classifyNB(np.array(wordVector), p0V, p1V, pSPam)!= testClassList[i]:
errorCount+=1
result = float(errorCount)/len(testData) #���������
print("��������: %.3f" % result)
return result
#ѭ��ʮ�μ���ƽ��������
for i in range(10):
dataSet = dataSet.sample(len(dataSet)) #ÿ��ѭ������ǰ��������
errorSum += airlineSentimentTest(dataSet)
errorSum /= 10.0 #����ƽ�������ʰ�
print("ƽ����������%.3f" % errorSum)
ʹ�ôʼ�ģ�����շ�����Ϊ:
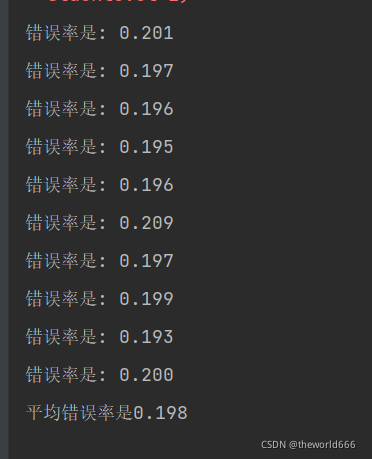
���Կ������շ�������ʽ���0.10,���ڶ�������˵�����ʵ�Ƿdz������ȷ�ʡ�
�������ʹ�ôʴ�ģ�͵ķ�����������?������Ҫע��һ����,ʹ�ôʴ�ģ�ͺ��������˹������Ҫ�����ġ���Ϊԭ�й�ʽ��
P
^
(
c
)
=
�O
D
c
�O
+
1
�O
D
�O
+
N
P
^
(
x
i
�O
c
)
=
�O
D
c
,
x
i
�O
+
1
�O
D
�O
+
N
i
\hat{P}(c)=\frac{\left|D_{c}\right|+1}{|D|+N} \quad \hat{P}\left(x_{i} \mid c\right)=\frac{\left|D_{c, x_{i}}\right|+1}{|D|+N_{i}}
P^(c)=�OD�O+N�ODc?�O+1?P^(xi?�Oc)=�OD�O+Ni?�ODc,xi??�O+1?
NiΪ����xi����ȡֵ����,�ڴʴ�ģ���������Ե�ȡֵ�����ǵ����б��ij���+1���������Ĵ�������
def trainNB0(trainMatrix, trainCategory):
numTrainDocs = len(trainMatrix)
numWords = len(trainMatrix[0])
pAbusive = np.sum(trainCategory)/np.float(numTrainDocs) #�����������ĸ���
p0Num = np.ones(numWords)
p0Demon = numWords+1
p1Num = np.ones(numWords)
p1Demon = numWords+1 #����������˹�������ǽ���һЩ��
for i in range(numTrainDocs):
if trainCategory[i] ==1:
p1Num +=trainMatrix[i]
p1Demon += np.sum(trainMatrix[i])
else:
p0Num += trainMatrix[i]
p0Demon+= np.sum(trainMatrix[i])
p1Vect = np.log(p1Num/p1Demon)
p0Vect = np.log(p0Num/p0Demon)#Ϊ�˷�ֹ̫��̫С������˵������������ȡ��������
return p0Vect,p1Vect,pAbusive
def airlineSentimentTest(dataSet):
dataStr = np.array(dataSet['text']).tolist()
docList = [textParse(sentence) for sentence in dataStr]
classList = np.array(dataSet['sentiment']).tolist()
vocabList = createVocabList(docList)
print(len(vocabList))
testNum = int(len(classList)*0.3)
testData = docList[:testNum]
testClassList = classList[:testNum]
trainData = docList[testNum:]
trainClassList = classList[testNum:]
trainMat = [bagOfWord2VecMN(vocabList,data) for data in trainData]
# for data in trainData:
# trainMat.append(setOfWords2Vec(vocabList,data))
p0V, p1V, pSPam = trainNB0(np.array(trainMat), np.array(trainClassList))
errorCount = 0
for i in range(len(testData)):
wordVector = bagOfWord2VecMN(vocabList, testData[i])
# wordVector = setOfWords2Vec(vocabList, testData[i])
if classifyNB(np.array(wordVector), p0V, p1V, pSPam)!= testClassList[i]:
errorCount+=1
result = float(errorCount)/len(testData)
print("��������: %.3f" % result)
return result
ͨ�����������������յó����:
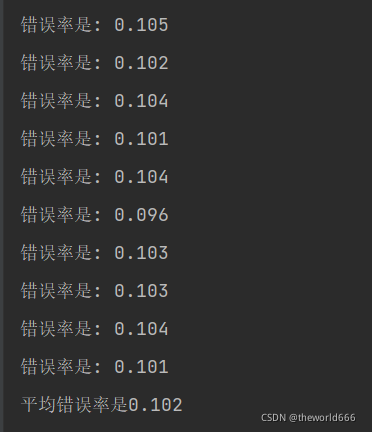
���Կ���ʹ�ôʴ�ģ�͵����ر�Ҷ˹�㷨ȡ�ø�������ijɹ�,��������ʽ���ֻ�аٷ�֮ʮ����˵����ʹ�ñ�Ҷ˹�㷨��ʹ����˸��ӵ����ݼ���Ҳ����ȡ�ò�����Ч��ͬʱ��Ҷ˹�㷨Ҳӵ�м����ٶȿ���ŵ㡣
����
���üĸ�����֪ʶ��������Ч���ٵķ�������ͬʱ�������ø��㷨�������ĺ��չ�˾�������ݼ������ôʴ�ģ��ȡ����ֻ��10%�����ʵ�����ɼ���
����Ҳ̸�����⻰🤐🤐🤐ͨ�������ر�Ҷ˹�㷨�����ѧϰ,�������˶����κ�����ȫ����������������뷨,���˽�����Ҫ��Ϊһ��������㷨������ԱӦ�ý�����ѡ��ÿ���㷨��˿�����ȷ���ٶ���ѡ����ȷ���㷨,������ѧϰ���������������ijЩ��������Ȼ��ʮ����������Dz������Ǻ��ӵġ�
ͬʱ�����˽һϵ�л���ѧϰ�㷨������ѧ�ĸ߶�Ҫ��,���Ҵ�һ��ʼ�ִ����в��뿼��Ҳ��ʼ���⿼�ж���ѧ�ĸ�Ҫ���ԭ��Ҳ�Ǽ�ʹ���տ�������ͨ��,���������ڱ�������ѧ����,�����о����������˹�����������������,����Щ�ɹ������Ƿdz����ѵġ�����Ҳϣ���Ҹ��˿���������һ���ʱ����ʵ���˵���ѧ������Ҳϣ������һ�����о�������������ȡ������ijɼ�,���������е�ѧУ��