接 集合 - Collection接口
二、Map接口
-
Map的实现类结构
双列数据,存储key - value对的数据 - - - >类似高中的函数:y = f(x)
HashMap:作为Map的主要实现类,线程不安全,效率高,存储 null 的 key 和 value
| - - - - - LinkedHashMap:包装在遍历Map元素时,可按照添加的顺序实现遍历
原因:在原有的HashMap地城结构基础上,添加了一对指针,分别指向前一个和后一个元素对于频繁的遍历操作,此类执行效率高于HashMapTreeMap:保证按照添加的key - value 对进行排序,实现排序遍历。此时考虑key的自然排序或定制排序,底层使用红黑树
Hashtable:作为古老的实现类,线程安全,效率低,不能存储null 的 key 和 value
| - - - - -Properties:常用来处理配置文件。key 和 value 都是 String 类型
注:HashMap的底层:数据 + 链表(jdk 7 之前)
? 数据 + 链表 + 红黑树(jdk8)
-
Map结构的理解
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-GQfwozhp-1637926507636)(F:\MarkDown学习\图片素材\集合\Map接口键值对的存储方式.jpg)]
key:无序的、不可重复的,故使用Set存储 - - - > key所在的类要重写equals() 和 hashCode ()
value:无序的、可重复的,用Collection存储(因Set和List都不符合 - - - > value所在类要重写equals()
Entry:无序的、不可重复的,是key - value 构成的键值对,用Set存储
-
HashMap添加数据的底层实现原理(jdk7之下:)
-1 创建一个HashMap对象
HashMap map = new HashMap();2 调用put( ) 方法,并跳转至putVal( ) 方法
map.put(K key, V value1) putVal(hash(key), key, value)3.1 如果map为空,底层创建了长度为16的一维数组Entry[ ] table
3.2 调用key所在类的hashCode( )计算key对应的哈希值,此哈希值经过某种算法计算之后,得到在 Entry数组中的存放位置
| ---- 此位置数据为空,key1 - value1添加成功 - - - > 情况1
|----- 此位置数据不为空,意味着此位置上存在一个或多个数据(以链表形式存在),比较key 和 已经存在的一个或多个数据的哈希值
|------------- key的哈希值与已存在数据的哈希值都不相同,key- value添加成功 - - - > 情况2
|------------- key的哈希值与已存在某一数据(key1-value1)的哈希值相同,则调用key所在类的equals( key )
| - - ----------------- 如果equals( )返回false:添加成功 - - - > 情况3
| ----------------- - - 如果equals( )返回true:使用value1 替换value2说明:
① 关于情况2和情况3,此时的key1 - value1和原来的数据以链表的方式存储
② 在不断的添加过程中,会涉及到扩容问题,默认的扩容方式:扩容为原来容量的2倍,并将原有的数据赋值过来
jdk8下源码的底层逻辑
①new HashMap( ):底层米有创建一个长度为16的数组
②jdk8 的底层数组:Node[ ] , 而非 Entry[ ],但是Node implements Entry
③首次调用put( )方法时,底层创建长度为16的数组
④HashMap的底层:数据 + 链表 + 红黑树(jdk8)
⑤当数组的某一个索引位置上的元素以链表形式存在的的数据个数 > 8,且当前数组长度 >64,此时索引位置上的所有数据改为使用红黑树存储(红黑树的检索复杂度会大大降低,提高搜索效率)。
⑥HashMap的默认容量16,扩充临界值时12,默认加载因子时0.75,为什么不再Node数组满的时候再扩容,是因为使用hash值进行无序存储,会在某些位置产生链表,所以不能简单说明满还是不满,而且不希望在数组中产生过多的链表,所以加载因子选为0.75,留有裕度,兼顾数组长度和链表数量。
-
HashMap添加数据的源码分析
-
源码中的重要常量
名 限度 DEFAULT_INITIAL_CAPACITY HashMap的默认容量:16 MAXIMUM_CAPACITY HashMap的最大支持容量:230 DEFAULT_LOAD_FACTOR HashMap的默认加载因子:0.75 TREEIFY_THRESHOLD Bucket中链表长度大于该默认值,考虑是否转化为红黑树:8 UNTREEIFY_THRESHOLD Bucket中红黑树存储的Node小于该默认值,转化为链表 MIN_TREEIFY_CAPACITY 同种的Node被树化时最小的hash表容量。(当桶中Node的数量大到需要转变为红黑树时,若hash表容量小于MIN_TREEIFY_CAPACITY时,应执行resize扩容操作这个MIN_TREEIFY_CAPACITY的值至少是TREEIFY_THRESHOLD的4倍。)64 table 存储元素的数组,总是2 的n 次幂 entrySet 存储具体元素的集 size HashMap中存储的键值对的数量 modCount HashMap扩容和结构改变的次数 threshold 扩容的临界值 = 容量 ***** 填充因子 = 16*0.75 = 12 loadFactor 填充因子 -
源码分析手稿

-
源码分析流向图
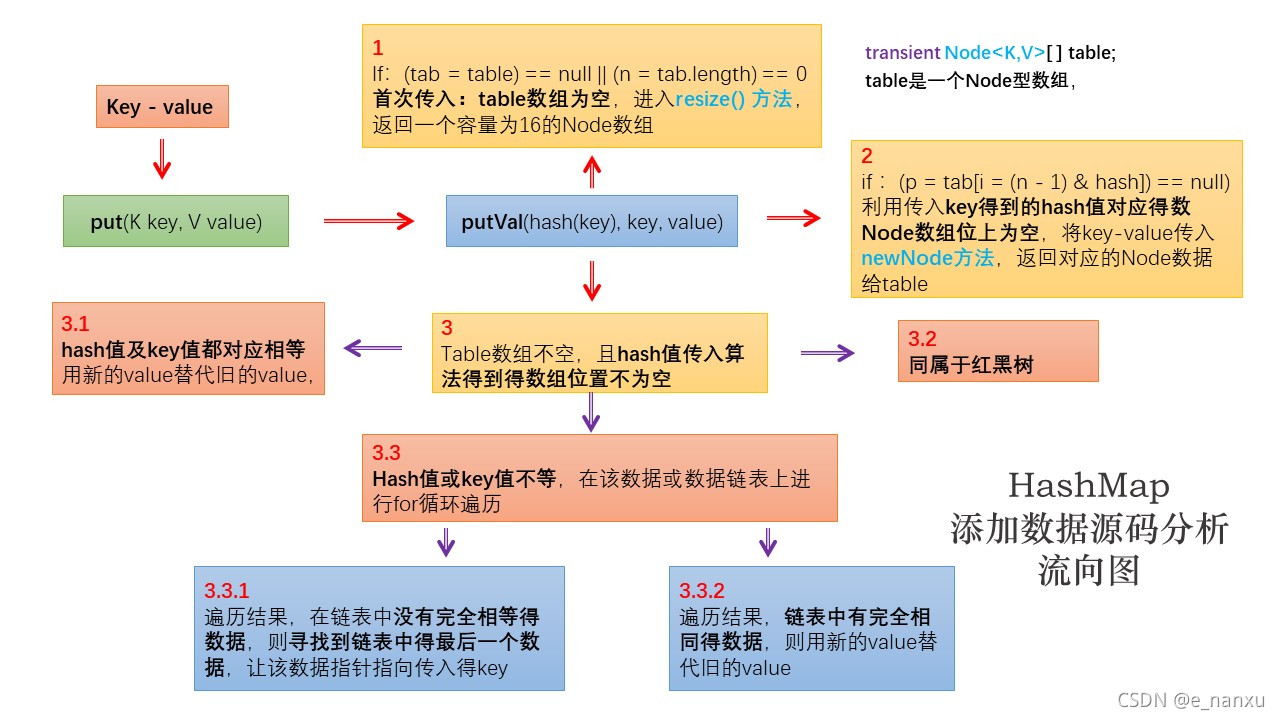
-
-
LinkedHashMap源码分析
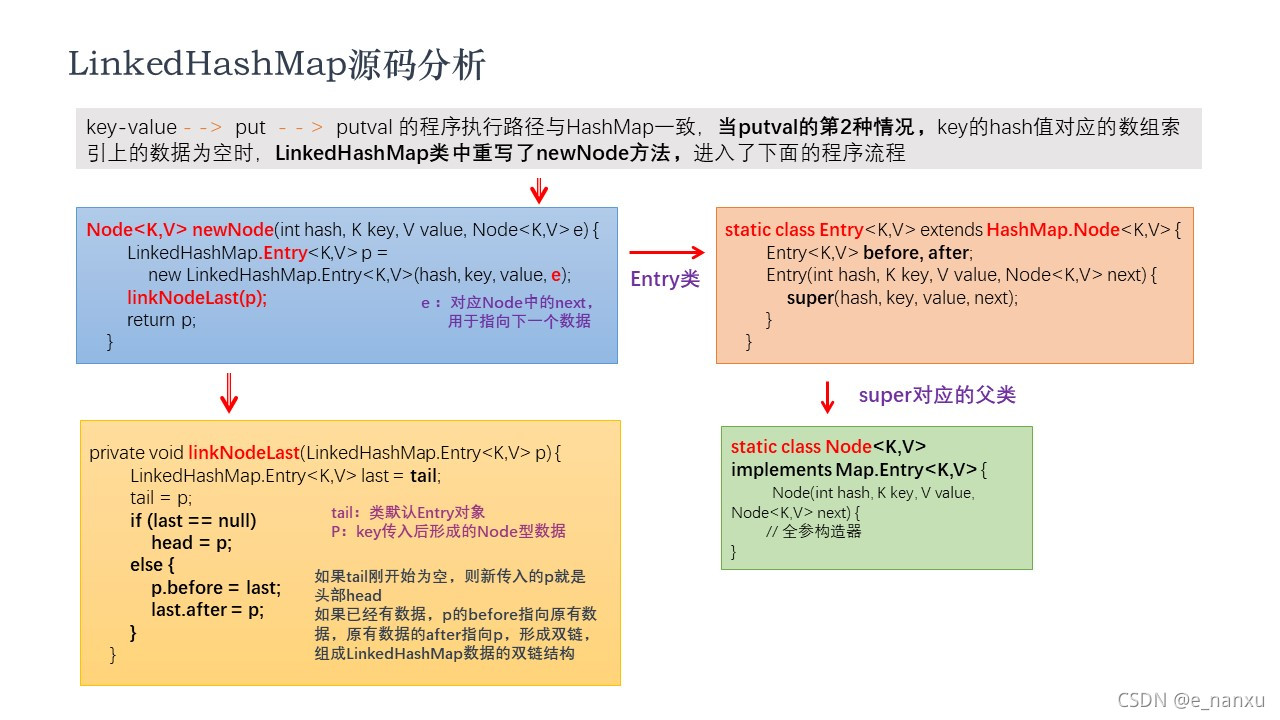
-
Map常用方法
-
方法表
thod summary 添加、删除、修改 Object put(Object key , Object value) 将指定的key-value添加到(或修改)当前map对象中 void putAll(Map m) 将 m中的所有key-value对存放到当前map中 Object remove(Object key) 移除指定key的key-value对,并返回value void clear() 清空当前map中的所有数据,map为{ } 元素查找 Object get(Object key) 获取指定key对应的value boolean containsKey(Object key) 是否包含指定的key boolean containsValue(Object value) 是否包含指定的value int size( ) 返回map中的key-value对的个数 boolean isEmpty( ) 判断当前map是否为空 boolean equals( Object obj ) 判断当前map和参数对象obj是否相等 元视图操作 Set keySet( ) 返回所有key构成的Set集合 Collection values( ) 返回所有value构成的Collection集合 Set entrySet( ) 返回所有key-value对构成的Set集合 -
代码示例
@Test public void hashMapTest() { HashMap map = new HashMap(); // put() 添加 map.put("Tom",23); map.put("Lily",36); map.put("Petty",46); map.put("Jam",28); map.put("Susan",31); // put() 修改 map.put("Tom",18); System.out.println(map); // putAll(m) 将m中的键值对全部导入 HashMap map1 = new HashMap(); map1.putAll(map); System.out.println(map1); // remove() 移除该键值对,并返回value Object s = map1.remove("Tom"); System.out.println(s); System.out.println(map1); // clear() 清空该集合,但该集合对象仍在{} map1.clear(); System.out.println(map1); // get(key) 得到key对应的value Object o = map.get("Lily"); System.out.println(o); // containsKey/Value 判断是否存在该key/value System.out.println(map.containsKey("Petty")); System.out.println(map.containsValue(18)); // size() 获取键值对个数 int m = map.size(); System.out.println(m); // isEmpty() 判断是否为空 System.out.println(map1.isEmpty()); // equals() 判断两个map集合是否相等 map1.putAll(map); System.out.println(map.equals(map1)); // keySet() 获取所有的key组成一个Set集合,并能通过迭代器遍历 Set set = map.keySet(); System.out.println(set); Iterator iterator = set.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } // values() 获得所有value组成的Collection一个集合,可通过迭代器遍历 Collection coll = map.values(); System.out.println(coll); Iterator iterator1 = coll.iterator(); while (iterator1.hasNext()) { System.out.println(iterator1.next()); } /* entrySet 获得所有键值对组成的一个Set集合,并能通过迭代器遍历 通过迭代器获得的每一个键值对Entry对象,可以通过getKey和getValue获得对应的key和value */ Set set1 = map.entrySet(); System.out.println(set1); Iterator iterator2 = set1.iterator(); while (iterator2.hasNext()) { Object o1 = iterator2.next(); Map.Entry entry = (Map.Entry) o1; System.out.println(entry.getKey() + "- - >" + entry.getValue()); } }
总结
增 :put
删 :remove
改 :put
查 :get
长度:size
遍历:keySet / valueSet / entrySet -
-
TreeMap
@Test public void treeMapTest() { TreeMap treeMap = new TreeMap(); Customer c1 = new Customer("Tom",24); Customer c2 = new Customer("Jack",53); Customer c3 = new Customer("Rose",18); Customer c4 = new Customer("Lily",63); Customer c5 = new Customer("Lily",57); Customer c6 = new Customer("Ala",26); treeMap.put(c1,89); treeMap.put(c2,45); treeMap.put(c3,90); treeMap.put(c4,48); treeMap.put(c5,69); treeMap.put(c6,100); Set set = treeMap.entrySet(); Iterator iterator = set.iterator(); while (iterator.hasNext()) { System.out.println(iterator.next()); } } class Customer { // name,age;setter/getter;contructo;equals;hashCode;compareTo; } -
Properties
① 是Hashtable的子类(Hashtable已经基本弃用了),该对象用于处理属性文件,将属性文件导入内存;
② 属性文件里的key、value都是字符串类型
③ 存取数据时,建议使用setProperty(String key, String value) 方法和 **getProperty( String key)**方法
④ 代码示例
public class PropertyTest { public static void main(String[] args) { FileInputStream fileInputStream = null; try { Properties properties = new Properties(); // 1.导入文件 fileInputStream = new FileInputStream("jdbc.properties"); // 2.加载流对应的文件 properties.load(fileInputStream); // 3.提取文件中的内容 // 账户:e_n密码:123nanxu String user = properties.getProperty("user"); String password = properties.getProperty("password"); System.out.println("账户:" + user + "密码:" + password); // 如果输入错误,返回空 // 账户:e_n密码:null String user1 = properties.getProperty("user"); String password1 = properties.getProperty("password1"); System.out.println("账户:" + user + "密码:" + password1); } catch (IOException e) { e.printStackTrace(); } finally { // 4.关闭文件 if (fileInputStream != null) { try { fileInputStream.close(); } catch (IOException e) { e.printStackTrace(); } } } } }
-
⑤ 创建properties文件步骤图示



-
⑥ 修改File Encodings配置


