�����㷨�����Ա�����
��������:�����ȡ��˳���ȡ������洢��˳��洢
�����ȡ��˳���ȡ������洢��˳��洢���ĸ���������ȫ��һ����,�в��ɽ�֮����
�ܶ��˰����ҿ�����Ϊ�����ȡ��������洢,˳���ȡ����˳���ȡ,��ʵ����������
���������Ľ���һ����4������
1����ȡ�ṹ
��Ϊ�����ȡ���������ȡ(�ֳ�˳���ȡ)
1��
�����ȡ����ֱ�Ӵ�ȡ,����ͨ���±�ֱ�ӷ������������ݽṹ,���洢λ�������������顣?
�������ȡ����˳���ȡ,����ͨ���±������,ֻ�����մ洢˳���ȡ,���洢λ���й�,����������2��
˳���ȡ���Ǵ�ȡ��N������ʱ,�����ȷ���ǰ(N-1)������ (list);?
�����ȡ���Ǵ�ȡ��N������ʱ,����Ҫ����ǰ(N-1)������,ֱ���Ϳ��ԶԵ�N�����ݲ��� (array)��
2�������ṹ
��Ϊ˳��洢������洢
3��˳��洢�ṹ
�ڼ��������һ����ַ�����Ĵ洢��Ԫ���δ洢���Ա��ĸ�������Ԫ��,�������Ա���˳��洢�ṹ��
- ˳��洢�ṹ�Ǵ洢�ṹ�����е�һ��,�ýṹ�ǰ�**�������ڵĽڵ�**�洢��**����λ�������ڵĴ洢��Ԫ**��,���֮�������ϵ�ɴ洢��Ԫ���ڽӹ�ϵ�����֡� - �ɴ˵õ��Ĵ��ṹΪ˳��洢�ṹ,ͨ��˳��洢�ṹ�ǽ����ڼ���������������(����c/c++)�������������ġ�? �C ��Ҫ�ŵ�:��ʡ�洢�ռ䡣
? ��Ϊ��������ݵĴ洢��Ԫȫ�ô�Ž�������(������c/c++������������ָ����С�����),���֮�������ϵû��ռ�ö���Ĵ洢�ռ䡣�������ַ���ʱ,��ʵ�ֶԽ��������ȡ,��ÿһ������Ӧһ�����,�ɸ���ſ���ֱ�Ӽ���������Ĵ洢��ַ��
? �C ��Ҫȱ��:��������,�Խ��IJ��롢ɾ������ʱ����Ҫ�ƶ�һϵ�еĽ�㡣
4������洢�ṹ
�ڼ��������һ������Ĵ洢��Ԫ�洢���Ա�������Ԫ��(����洢��Ԫ������������,Ҳ�����Dz�������)������Ҫ���������ڵ�Ԫ��������λ����Ҳ���ڡ������û��˳��洢�ṹ�����е�����,��Ҳͬʱʧȥ��˳����������ȡ���ŵ㡣
? --����洢����͵Ĵ���Ϊ��ʽ�洢:
��ʽ�洢�ṹ�ص�
1����˳��洢�ṹ�Ĵ洢�ܶ�С (ÿ���ڵ㶼���������ָ�������,������ͬ�ռ��ڼ���ȫ�����Ļ�˳�����ʽ�洢����)��
2���������ڵĽڵ������ϲ������ڡ�
3�����롢ɾ����� (�����ƶ��ڵ�,ֻҪ�ı�ڵ��е�ָ��)��
4�����ҽ��ʱ��ʽ�洢Ҫ��˳��洢����
5��ÿ����������������ָ�������
һ�����ݽṹ�ĸ���
1����������:
- ����:��������ʵ�ķ���,�Ǽ�����п��Բ����Ķ���,�ܱ������ʶ��,���������������ķ��ż��ϡ�
- ����Ԫ��:��������ݵġ���һ������Ļ�����λ,�ڼ������ͨ����Ϊ���崦��,Ҳ����Ϊ��¼��
- ���ݶ���:��������ͬ����Ԫ�صļ���,�����ݵ�һ���Ӽ���
- ������:һ������Ԫ�ؿ��������ɸ����������,�����������ݲ��ɷָ����С��λ��
- ���ݽṹ:�֮�����һ�ֻ��߶����ض���ϵ������Ԫ�صļ��ϡ��ɷ�Ϊ���ṹ�������ṹ��
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-H2EEsw2b-1641217649127)(myReviewPicture/���ݽṹ�����-16411800000834.jpg)]](https://img-blog.csdnimg.cn/155d756e7f9b498a85daf38ffab96742.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_12,color_FFFFFF,t_70,g_se,x_16)
2���㷨
(1)����
����ض��������ⲽ���һ������,����ָ�����������,���е�ÿ��ָ���ʾһ������������
(2)��Ҫ����:
������:�����������߶����
�����:ֻ��һ�����߶�����
��������:�㷨��ִ����������ʱ,���Զ�������������������ѭ������
��ȷ����:�㷨��ÿһ������ȷ���ĺ����������ֶ�����
�ݿ�����:�㷨��ÿһ��������ͨ����������ɡ�
3���㷨�����۱�(���á����㷨Ӧ�ÿ��Ǵﵽ����Ŀ��)
����ȷ�����㷨�ܹ���ȷ��������⡣
�ڿɶ������㷨�ܾ������õĿɶ���,�����������⡣
�۽�׳��������Ƿ�����ʱ,�㷨���ʵ���������Ӧ����д��������������Ī���������������
��Ч����ʹ洢��������Ч��ָ�㷨ִ�е�ʱ��,�洢��������ָ�㷨ִ�й�������������洢�ռ䡣
4���㷨��ʱ��Ч��
(1)ʱ�临�Ӷ�
�����㷨д�ɵij�����ִ��ʱ�ķ�ʱ��ij���,��ΪT(n) = O(n)
(2)�ռ临�Ӷ�
�����㷨д�ɵij�����ִ��ʱռ�ô洢��Ԫ�ij��ȼ�ΪS(n)
(3)���Ƶ��
һ���㷨�е����ִ�д�����Ϊ���Ƶ�Ȼ�ʱ��Ƶ��,��ΪT(n)
ʱ�临�Ӷ�:ʱ�临�Ӷ�ʵ������һ������,�������������ظ�ִ�еĴ���,������������������ı仯��ȷ��������,��������O��ʾ,�����㷨��ʱ�临�Ӷ�Ϊ: T(n)=O(f(n))
��һ���㷨����****��á�ƽ�����*�������,����һ���ע����*�*���,ԭ����,������*�κ�����ʵ��������ʱ����Ͻ�****,����ijЩ�㷨��˵,�������ֵıȽ�Ƶ��,�Ӵ���������,ƽ�����������һ���
(4)һ��O(n)�ļ��㷽��:
����****1*������������ʱ���г��ֵ�*�ӷ�����****;
�����ĺ�����к�����****������߽���****;
�����****��߽�*����*ϵ������*1,��*ȥ�������ϵ��****��
****�ݹ��㷨***��ʱ�临�Ӷ�Ϊ:�ݹ��ܴ���ÿ�εݹ��л�������ִ�еĴ�����
(5)������ʱ�临�Ӷ�����������:
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-fChDxRHo-1641217649129)(myReviewPicture/ʱ�临�ӶȵıȽ�-16411800195595.png)]](https://img-blog.csdnimg.cn/8fe936bd9da248b186a6019e2fd4fcdb.png)
�� O(1)������;�� O(log2N)������;�� O(N)������;�� O(Nlog2N)��ά��;�� O(N^2)ƽ����;�� O(N^3)������;�� O(2^N)ָ���͡�
����:
i=1;��
while (i<=n)
{
i=i*2; ��
}
��:���1��Ƶ����1,
�����2��Ƶ����f(n),��:2^f(n)<=n;f(n)<=log2n
ȡ���ֵf(n)= log2n, T(n)=O(log2n )
�������Ա�
1��˳��洢
(1)�ṹ��Ķ���
typedef int Position;
typedef struct LNode * PtrToLNode;
struct LNode
{
ElmenetType Data[ MAXSIZE ];
Position Last;
};
typedef PtrToLNode List;
(2)˳����ij�ʼ��
1������һ���ձ�
2����̬������ṹ����Ĵ洢�ռ�,Ȼ����Lastָ����Ϊ-1 ��ʾ����û�����ݡ�
List MakeEmpty()
{
List L;
L = (List)malloc(sizeof(struct LNode));
L->Last = -1; //Last ��Ϊ-1 ��ʾ����û������Ԫ��
Return L;
}
-
ͨ��L���ǿ��Է�����Ӧ���Ա������ݡ�����:�±�Ϊi ��Ԫ��:L->Data[i]
-
��ѯ���Ա��ij���:L->Last+1;
(3)˳����IJ���(ʱ�临�Ӷ�ΪO(n))
�����Ա��в��������ֵ X ��ȵ�����Ԫ�ء�
�������Ա���Ԫ�ض��洢������Data��,����������ҵĹ���ʵ���Ͼ�����������˳�����:
- �ӵ� 1 ��Ԫ�� a1 �����κ� X �Ƚ�, ֱ���ҵ�һ���� X ��ȵ�����Ԫ��,��������˳����еĴ洢�±�;
- ���߲����������û���ҵ��� X ��ȵ�Ԫ��,�ش�����Ϣ ERROR��
#define ERROR -1 /* ��������Ϣ ERROR ��ֵ����Ϊ��һ���������� */
Position Find( List L, ElementType X )
{
Position i = 0;
While( i <= L->Last && L->Data[i] != X)
i++;
if( i > L->Last)
return ERROR; /* ���û���ҵ�,�ش�����Ϣ */
else
return i; /* �ҵ��ص��Ǵ洢λ�� */
}
(4)˳����IJ��� (ʱ�临�Ӷ�ΪO(n))
�ڱ��IJ�����ָ�ڱ��ĵ� i(1�� i �� n + 1)��λ���ϲ���һ��ֵΪ X ����Ԫ��(Ҳ��������Ϊ�ڵ� i ��Ԫ��֮ǰ�����µ�Ԫ��)
�����ʹ��ԭ������Ϊ n ������,��Ϊ ����Ϊ n+1������(i = 1ʱ�������е���ǰ��,i = n+1 ʱ�������е����)
- ��ai~an˳������ƶ�(�ƶ������Ǵ� an ��ai),Ϊ��Ԫ���ó�λ��;
- �� X ����ճ����� i ��λ��;
- �� Last ָ��(�൱���ı���),ʹָ֮�����һ��Ԫ����
bool Insert( List L, ElementType X, int i)
{ /* �� L ��ָ��λ�� i ǰ����һ����Ԫ�� X; λ�� i Ԫ������λ���±�Ϊ i-1 */
Postion j;
if(L->Last == MAXSIZE-1)
{/* ���ռ�����,���ܲ��� */
printf("����!\n");
return false;
}
if( i<1 || i > L->Last+2)
{/* ������λ��ĺϷ���:�Ƿ��� 1~n+1; nΪ��ǰԪ�ظ���,��Last+1 */
printf("λ�Ϸ�!\n");
return false;
}
for( j = L->Last; j >= i-1; j--) /*Last ָ���������Ԫ��an */
L->Data[j+1] = L->Data[j]; /* ��λ��Ϊ i ���Ժ��Ԫ��˳������ƶ� */
L->Data[i-1] = X; /* Last ��ָ�����һ��Ԫ�� */
L->Last++;
return true;
}
(5)˳�����ɾ��(ʱ�临�Ӷ�ΪO(n))
�����е�λ��Ϊ i(1�� i �� n + 1)��Ԫ�ش����Ա���ȥ��,ɾ����ʹԭ����Ϊ n ������Ԫ������,��Ϊ����Ϊ n-1 ������
��a[i+1]~a[n] ˳����ǰ�ƶ� ,a[i] Ԫ�ر�a[i+1]����;
�� Last ָ��(�൱���ı���)ʹ֮��ָ�����һ��Ԫ����
bool Delete(List L, int i)
{ /*�� L ��ɾ��ָ��λ�� i ��Ԫ��,��Ԫ�������±�Ϊ i-1*/
Position j;
if(i < 1 || i > L->Last + 1)/* ���ձ���ɾ��λ��ĺϷ���*/
{
printf("λ��%d������Ԫ��",i);
return false;
}
for( j = i; i <= L->Last; j++)
L->Data[j-1] = L->Data[j];/*��λ�� i+1 ���Ժ��Ԫ��˳����ǰ�ƶ�*/
L->Last--;/*Last ��ָ�����Ԫ��*/
return true;
}
2�������洢
(1)�ṹ��Ķ���(ʱ�临�Ӷ�ΪO(n))
typedef struct LNode * PtrToLNode;
struct LNode
{
ElementType Data;
PtrToLNode Next;
};
typedef PtrToLNode Position; /*�����λ���ǽ��ĵ�ַ */
typedef PreToLNode List;
(2)�����(ʱ�临�Ӷ�ΪO(n))
��˳��洢��������Ǻ�����,ֱ�ӷ��� Last+1 �Ϳ����ˡ�������ʽ�洢��,��Ҫ��������ͷ��β����һ��
- ��һ���ƶ�ָ��p�ͼ�����cnt,��ʼ����,p�ӱ��ĵ� 1 ����㿪ʼ��������,ͬʱ������ cnt+1.
- �����治���н��ʱ,cnt ��ֵ���ǽ�����,�� ������
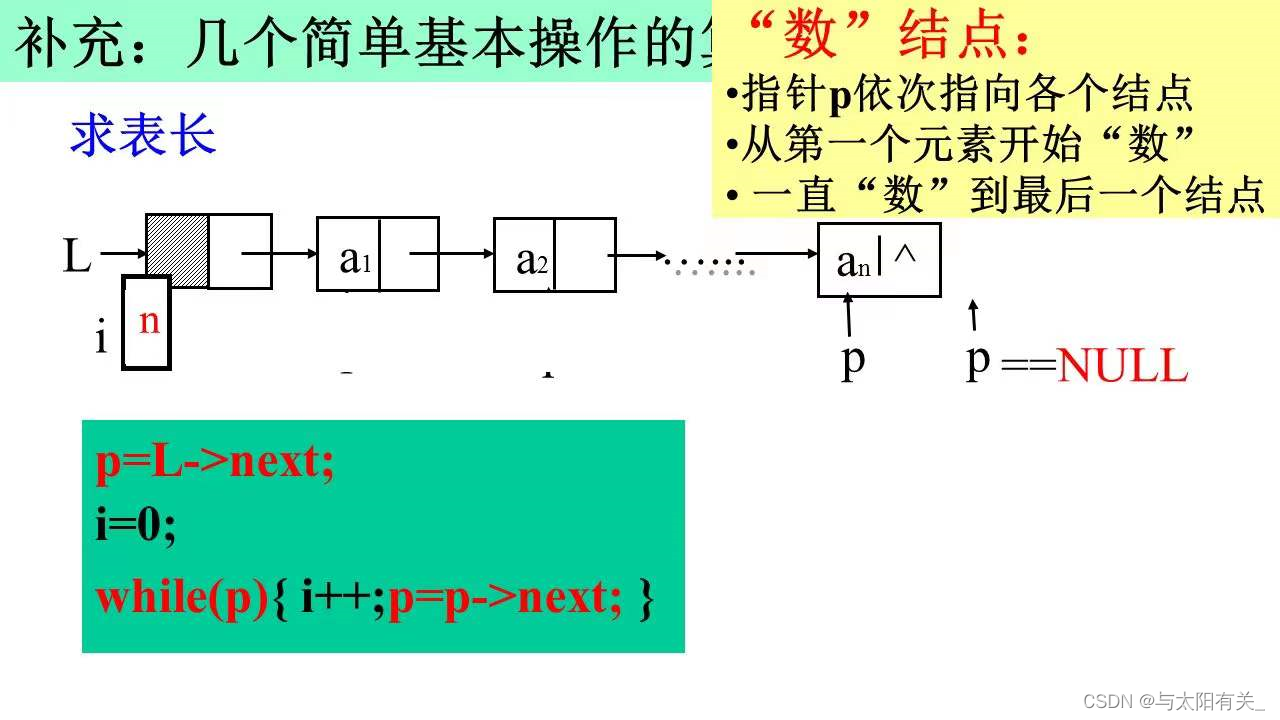
int Length(List L)
{//Ĭ�ϸ���������ͷ����
Position p;
int i=0; /* ��ʼ�������� */
//���������ı���(������)
p = L->next; /* pָ����ĵ� 1 ����� */
while(p)
{ /* ����������,ͳ�ƽ���� */
p=p->next;
i++;
}
return i;
}
(3)�п�
int ListEmpty(LinkList L)
{ //�� L ��,��1,���� 0
if(L->Next) //�ǿ�
return 0;
else
return 1;
}
(4)����(ʱ�临�Ӷ�ΪO(n))
������ ����Ų���(FindKth)�� ��ֵ����(Find)
�ٰ���Ų��� FindKth(ʱ�临�Ӷ�ΪO(n))
����˳��洢,����Ų����Ǻ�ֱ�ӵ�����,Ҫ�õ��� K ��Ԫ�ص�ֵ,ֱ��ȡL->Data[K-1]������
���Ƕ�����ʽ�洢����Ҫ���ø���������Ƶ�˼·:
- ���������� 1 ��Ԫ�������,�ж���ǰ����Ƿ��ǵ� K ��;
- ����,�������ý���ֵ,��������ԱȺ�һ��,ֱ��������Ϊֹ��
- ���û���� K �������������Ϣ��
#define ERROR -1 /* һ�㶨��Ϊ����Ԫ�ز�����ȡ����ֵ */
ElementType FindKth(List L, int K)
{ /* ����ָ����λ�� K, ���� L ����Ӧ��Ԫ�� */
Position P;
int cnt = 1; /* λ��� 1 ��ʼ */
p = L; /* p ָ�� L�ĵ� 1 ����� */
while(p && cnt < K)
{
p = p->next;
cnt++
}
if((cnt == K) && p)
return p->Data; /* ���ص� K �� */
else
return ERROR; /* ���ش�����Ϣ */
}
�ڰ�ֵ����,����λ Find(ʱ�临�Ӷ�ΪO(n))
��������:Ҳ�Ǵ�ͷ��β����,ֱ���ҵ�Ϊֹ:
- ���������� 1 ��Ԫ�������,�ж���ǰ����ֵ�Ƿ���� X;
- ����,�����ý���λ��,��������ԱȺ�һ��,ֱ��������λ��Ϊֹ;
- �Ҳ���ʱ����������Ϣ��
#define ERROR NULL /*�յ�ַ��ʾ���� */
Position Find( List L, ElementType X)
{
Position p = L;/* pָ�� L �ĵ� 1 ��Ԫ�� */
while(p && p->Data != x)
{
p = p->Next;
}
if(p)
return p;
else
return ERROR;
}
(5)�����IJ���(ʱ�临�Ӷ�ΪO(n))
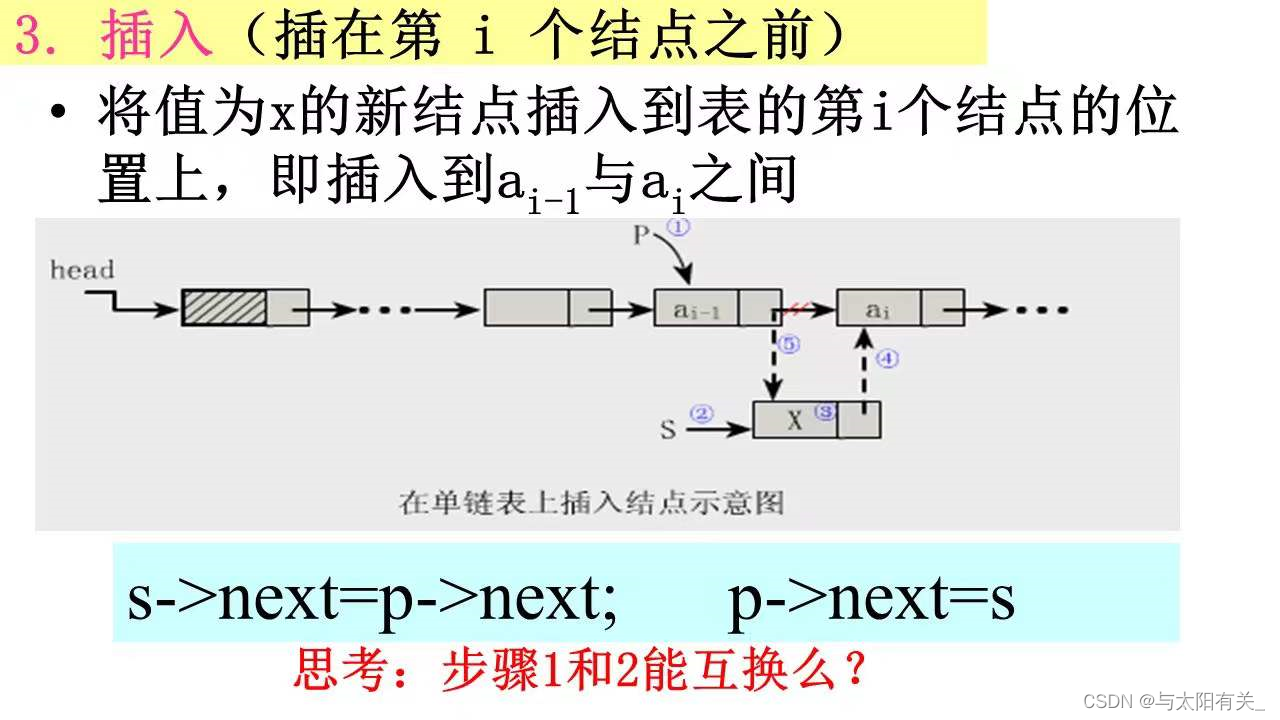

int ListInsert_L(LinkList &L, int i,ElementType e)
{
p = L;
j = 0;
while(p&& j<i-1)
{//Ѱ�ҵ� i-1 �����
p = p->next;
++=j;
}
if(!p || j > i-1)
return ERROR;//
s = (LinkList)malloc(sizeof(LNode));//�����½��s
s->data = e; //�����s ���������ֵ ����Ϊ e
s->next = p->next; //�����s ���� L ��
p->next = s;
return OK;
}
(6)��������(ʱ�临�Ӷ�ΪO(n))
1����ͷ���ġ�ͷ�巨��(ʱ�临�Ӷ�ΪO(n))
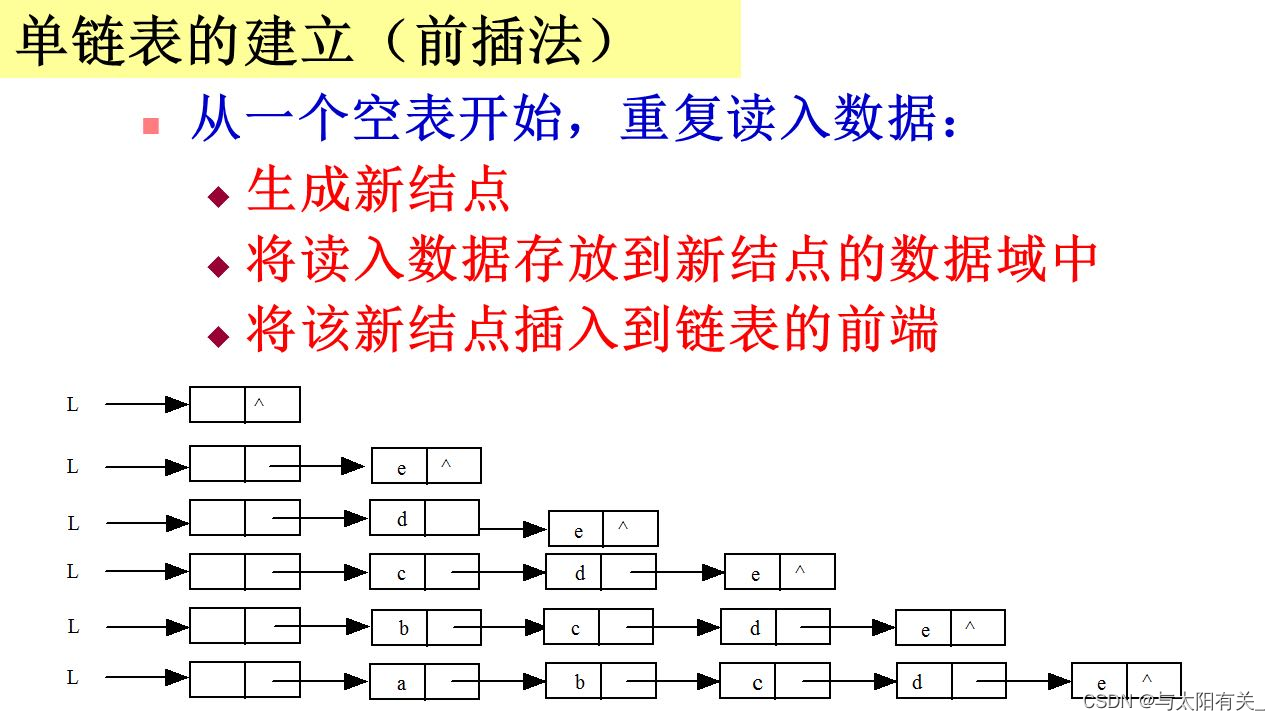
/* ��ͷ���IJ��봴�� */
void createListHead( Linklist L, int n )
{
//����ͷ���
L = (LNode*)malloc(sizeof(struct LNode));
L->Next = NULL;
//����������(ͷ�巨)
LNode *temp = NULL;
//����ռ�,д������
for(int i = 0; i < n; i++)
{
tmp = (LNode*)malloc(sizeof(struct LNode)); /* ���롢��װ��� */
scanf("%d",&tmp->Data);//����Ԫ��ֵ
//���뵽ͷ���ĺ���
tmp->Next = L->Next;
L->Next = tmp;
}
}
2����β���IJ��롾β�巨��(ʱ�临�Ӷ�ΪO(n))
/*����IJ���*/
void CreateList_L( Listlist &L, int n )
{ //��λ�������� n ��Ԫ�ص�ֵ,��������ͷ���ĵ�����L
//����ͷ���
L = (LNode*)malloc(sizeof(struct LNode));
L->Next = NULL;
//����������(β�巨)
LNode r = L; //βָ��ָ��ͷ���
//����ռ�,д������
for(int i = 0;i < n; i++)
{
LNode *tmp = (LNode*)malloc(sizeof(struct LNode)); /* �����½�� */
scanf("%d",&tmp->Data); //����Ԫ��
tmp->Next = NULL;
//���뵽β������
r->next = temp;
r = tmp; //rָ���µ�β���
}
}
(7)ɾ��(ʱ�临�Ӷ�ΪO(n))
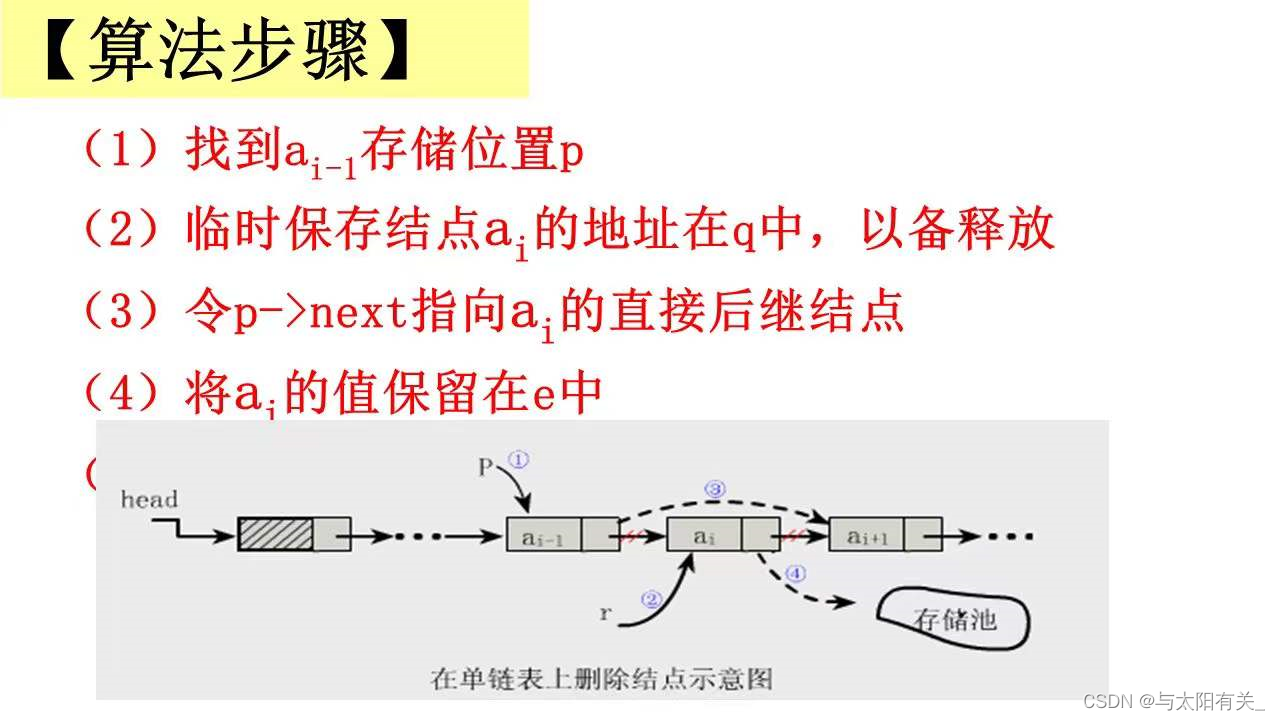
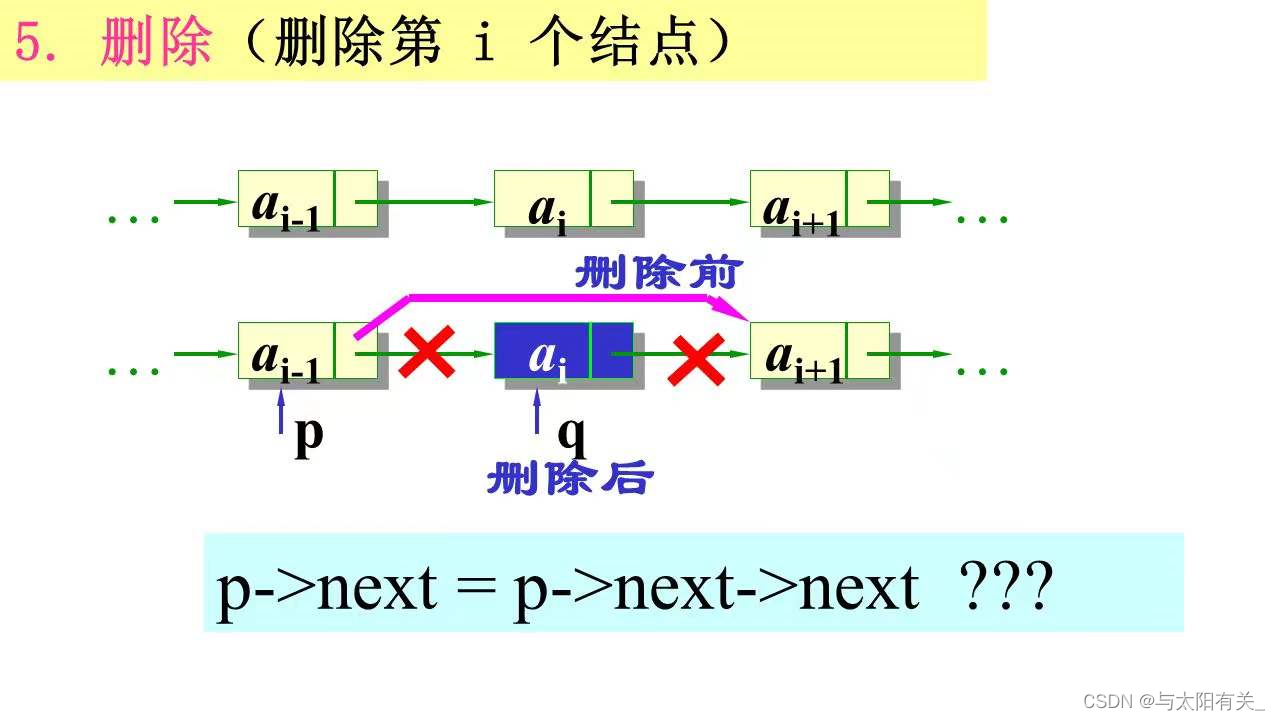
//�����Ա�L �е� i ������Ԫ��ɾ��
int ListDelete_L(LinkList &L, int i, ElementType &e)
{
p=L;
int j=0;
while(p->next && j < i-1)
{//Ѱ�ҵ� i �����,����pָ����ǰ��
p = p>next;
++j;
}
if(!(p->next)||j < i-1)
return ERROR;//ɾ��λ�ò�����
q = p->next; //��ʱ���汻ɾ�����ĵ�ַ�Ա��ͷ�
p->next = q->next; //�ı䱻������������ָ����
e = q->data; //���汻ɾ������������
free(q); //�ͷű�ɾ�����Ŀռ�
return OK;
}
3������ʱ�临�ӶȺ���ȱ��ıȽ�
1�����߸��ӶȱȽ�
| ���� | ���� | ɾ�� | |
|---|---|---|---|
| ˳��� | O(1) | O(1) | O(n)ͨ���±�ֱ���ҵ�������Ԫ��,��Ҫʱ�仨���ƶ�Ԫ���ϡ� |
| ���� | O(n) | O(n)��Ҫʱ�������ҵ�����Ԫ�ص�λ�� | O(n)��Ҫʱ�������ҵ���ɾ��Ԫ�ص�λ�� |
2��������ȱ��Ƚ�
| ���� | �ŵ� | ȱ�� |
|---|---|---|
| ���������ǿ;�����ٶȿ� | �����ɾ��Ч�ʵ�;�����˷��ڴ�;�ڴ�ռ�Ҫ���,�������㹻�������ڴ�ռ�;�����С�̶�,���ܶ�̬��չ |
| ���� | �ŵ� | ȱ�� |
|---|---|---|
| ����ɾ���ٶȿ�;�ڴ������ʸ�,�����˷��ڴ�;��Сû�й̶�,��չ���� | �����������,����ӵ�һ����ʼ����,����Ч�ʵ� |
���ߵ���������˳��ṹ��Ҫ��һƬ�����Ĵ洢�ռ�,����ʽ�ṹ�IJ�Ҫ��洢�ռ�������
����ջ
1��ջ��˳��洢ʵ��
ͨ����һ��һά������һ����¼ջ��Ԫ��λ�õı�����ɡ�
(1)˳��ջ�ṹ��Ķ���
�� Top = -1ʱ,��ʾջ��;��Top = MaxSize -1 ʱ,ջ��!
typedef int Position;
typedef int ElementType;
typedef struct SNode *PtrToNode;
struct SNode
{
ElementType * Data; /*�洢Ԫ�ص�����*/
Position Top; /*ջ��ָ��*/
int MaxSize; /*��ջ�������*/
};
typedef PtrToNode Stack;
(2)˳��ջ�Ĵ���
Stack CreateStack(int MaxSize) /*˳��ջ�Ĵ���*/
{
Stack S = (Stack)malloc(sizeof(struct SNode));
S->Data = (ElementType *)malloc(MaxSize * sizeof(ElementType));
S->Top = -1; /*"-1"��ʾ��ջ "MaxSize-1"��ʾ��ջ*/
S->MaxSize = MaxSize; /*ָ��ջ���������*/
return S;
}
(3)����
bool IsFull(Stack S) /*�ж�ջ�Ƿ�����*/
{
return(S->Top == S->MaxSize-1);
}
(4)�п�
bool IsEmpty(Stack S) /*�ж϶�ջ�Ƿ�Ϊ��*/
{
return(S->Top == -1);
}
(5)��ջ
��ִ�ж�ջ Push ����ʱ,���ж�ջ�Ƿ���;
- ������,Top ��1,������Ԫ�ط��� Data�����Topλ����
- ����,�ش����־
bool Push(Stack S, ElementType X) /*˳��ջ�� ��ջ ����*/
{
if(IsFull(S))
{
printf("��ջ��!");
return false;
}
else
{
S->Data[++(S->Top)] = X; /*����ջ����,��Top�� 1,������Ԫ�ط���Data�����Topλ����*/
return true;
}
}
(6)��ջ
ִ��Pop����ʱ,�����б�ջ�Ƿ�Ϊ��;
- ����Ϊ��,����Data[Top],ͬʱ��Top-1;
- ����Ҫ���ش����־
ElementType Pop(Stack S) /*˳��ջ �� ��ջ ����*/
{
if(IsEmpty(S))
{
printf("��ջ��!");
return ERROR; /*ERROR �� ElementType ���͵�����ֵ,��־������������ջԪ�����ݲ�����ȡ����ֵ */
}
else
return(S->Data[(S->Top)--]); /*������,����Data[Top],ͬʱ��Top�� 1*/
}
2��ջ��˳��洢ʵ��
��ջ�뵥��������,�������������,�����ɾ������ֻ������ջ��ջ�����С�
(1)˳��ջ�ṹ��Ķ���
typedef struct SNode *PtrToSNode;
typedef int ElementType;
struct SNode
{
ElementType Data;
PtrToSNode Next;
};
typedef PtrToSNode Stack;
(2)˳��ջ�Ĵ���
Stack CreateStack()
{ /*����һ����ջ��ͷ���,���ظý��ָ��*/
Stack S;
S = (Stack)malloc(sizeof(struct SNode));
S->Next = NULL;
return S;
}
(3)�п�
bool IsEmpty(Stack S)
{ /*�ж϶�ջ S �Ƿ�Ϊ��,���Ƿ��� true,���� false*/
return(S->Next == NULL);
}
(4)���� ע��:��ջ,�����ж϶�ջ�Ƿ���
(5)��ջ
��ջ,�����ж϶�ջ�Ƿ���
bool Push(Stack S, ElementType X)
{ /*��Ԫ�� X ѹ���ջ S */
PtrToSNode TmpCell;
TmpCell = (PtrToSNode)malloc(sizeof(struct SNode));
TmpCell->Data = X;
//ͷ�巨
TmpCell->Next = S->Next;
S->Next =TmpCell;
return true;
}
(6)��ջ
ElementType Pop(Stack S) ElementType Pop(Stack S)
{ /*ɾ�������ض�ջ S ��ջ��Ԫ��*/
PtrToSNode FirstCell;
ElementType TopElem;
if(IsEmpty(S))
{
printf("��ջ��!");
return ERROR;
}
else
{
FirstCell = S->Next;
TopElem = FirstCell->Data;
S->Next = FirstCell->Next;
free(FirstCell);
return TopElem;
}
}/*˳��ջ �� ��ջ ����*/
{
if(IsEmpty(S))
{
printf("��ջ��!");
return ERROR; /*ERROR �� ElementType ���͵�����ֵ,��־������������ջԪ�����ݲ�����ȡ����ֵ */
}
else
return(S->Data[(S->Top)--]); /*������,����Data[Top],ͬʱ��Top�� 1*/
}
3��ջ��Ӧ��
�ġ�����
1�����е�˳��洢ʵ��
(1) ѭ�����еĽṹ�嶨��
typedef int Status;
typedef int QElemType; /* QElemType������ʵ���������,�������Ϊint */
/* ѭ�����е�˳��洢�ṹ */
typedef struct QNode
{
QElemType data[MAXSIZE];
int front; /* ͷָ�� */
int rear; /* βָ��,�����в���,ָ�����βԪ�ص���һ��λ�� */
}SqQueue;
(2)���ɿն���
/* ��ʼ��һ���ն���Q */
Status CreateQueue(SqQueue *Q)
{
SqQueue *Q = (SqQueue)malloc(sizeof(struct QNode));
Q->data = (ElementType*)malloc(MaxSize * sizeof(ElementType));
Q->front = Q->rear = 0;
return OK;
}
(3)�п�
�ӿյ�������:rear=front
bool IsEmpty(SqQueue *Q)
{
return(Q->front == Q->rear);
}
(4)����
������������:(rear+1)%����ij��ȵ��� front
bool IsFull(SqQueue *Q)
{
return((Q->rear+1)% MaxSize == Q->front);
}
(5)���
/* ������δ��,�����Ԫ��eΪQ�µĶ�βԪ�� */
Status EnQueue(SqQueue *Q,QElemType e)
{
if ((Q->rear+1)%MAXSIZE == Q->front) /* ���������ж� */
return ERROR;
Q->data[Q->rear]=e; /* ��Ԫ��e��ֵ����β */
Q->rear=(Q->rear+1)%MAXSIZE;/* rearָ�������һλ��, */
/* ���������ת������ͷ�� */
return OK;
}
(6)����
/* �����в���,��ɾ��Q�ж�ͷԪ��,��e������ֵ */
Status DeQueue(SqQueue *Q,QElemType *e)
{
if (Q->front == Q->rear) /* ���пյ��ж� */
return ERROR;
*e=Q->data[Q->front]; /* ����ͷԪ�ظ�ֵ��e */
Q->front=(Q->front+1)%MAXSIZE; /* frontָ�������һλ��, */
/* ���������ת������ͷ�� */
return OK;
}
2�����е���ʽ�洢ʵ��
�������ջһ��,Ҳ���Բ�����ʽ�洢�ṹ,�����е�ͷ(front)����ָ��������ͷ���,���е�β(rear)ָ��������β��㡣
(1)���е���ʽ�洢�ṹ�嶨��
typedef int Status;
typedef int QElemType; /* QElemType������ʵ���������,�������Ϊint */
typedef struct QNode /* ���ṹ */
{
QElemType data;
struct QNode *next;
}QNode,*QueuePtr;
typedef struct /* ���е������ṹ */
{
QueuePtr front,rear; /* ��ͷ����βָ�� */
}LinkQueue;
(2)���ɿն���
/* ����һ���ն���Q */
Status InitQueue(LinkQueue *Q)
{
Q->front=Q->rear=(QueuePtr)malloc(sizeof(QNode));
if(!Q->front)
exit(OVERFLOW);
Q->front->next=NULL;
return OK;
}
(3)�п�
�ӿյ�������:rear=front
Status QueueEmpty(LinkQueue Q)
{
if(Q.front==Q.rear)
return TRUE;
else
return FALSE;
}
(4)���� ��ʽ����,�����ж϶�ջ�Ƿ���
(5)���
/* ����Ԫ��eΪQ���µĶ�βԪ�� */
Status EnQueue(LinkQueue *Q,QElemType e)
{
QueuePtr s=(QueuePtr)malloc(sizeof(QNode));
if(!s) /* �洢����ʧ�� */
exit(OVERFLOW);
s->data=e;
s->next=NULL;
Q->rear->next=s; /* ��ӵ��Ԫ��e���½��s��ֵ��ԭ��β���ĺ��,��ͼ�Т� */
Q->rear=s; /* �ѵ�ǰ��s����Ϊ��β���,rearָ��s,��ͼ�Т� */
return OK;
}
(6)����
/* �����в���,ɾ��Q�Ķ�ͷԪ��,��e������ֵ,������OK,����ERROR */
Status DeQueue(LinkQueue *Q,QElemType *e)
{
QueuePtr p;
if(Q->front==Q->rear)
return ERROR;
p=Q->front->next; /* ����ɾ���Ķ�ͷ����ݴ��p,��ͼ�Т� */
*e=p->data; /* ����ɾ���Ķ�ͷ����ֵ��ֵ��e */
Q->front->next=p->next;/* ��ԭ��ͷ���ĺ��p->next��ֵ��ͷ�����,��ͼ�Т� */
if(Q->rear==p) /* ����ͷ���Ƕ�β,��ɾ����rearָ��ͷ���,��ͼ�Т� */
Q->rear=Q->front;
free(p);
return OK;
}
�塢ջ�Ͷ��в������ص�
| ��ͬ�� | ��ͬ�� | |
|---|---|---|
| ��ջ(FILO) | ֻ�����ڶ˵㴦�����ɾ��Ԫ��; | ջ���Ƚ�������ߺ���ȳ�;ջ��ֻ���ڱ���һ�˽��в����ɾ�����������Ա� |
| ����(FIFO) | ֻ�����ڶ˵㴦�����ɾ��Ԫ��; | �������Ƚ��ȳ�;������ֻ���ڱ���һ�˽��в���,Ȼ��������һ�˽���ɾ�����������Ա� |
��������洢��ַ�ļ���
| �������� | �洢��ַ�ļ���(a��������ַ,len��ÿ������Ԫ����ռ����) |
|---|---|
| һά���� | a[i]�Ĵ洢��ַ:a+i*len |
| ��ά����:a[m] [n] | ���д洢:a+(i * n+j) * len;���д洢:a+(j * m+i) * len |
����:����洢��ַ�ļ���ʾ��:
1)��֪һά����a��ÿ��Ԫ��ռ��2���ֽ�,��a[10]�Ĵ洢��ַ?
��:a[10]�Ĵ洢��ַΪ:a+10*2=a+20
2)��֪��ά����a[4][5]��, ÿ��Ԫ��ռ��2���ֽ�,��Ԫ��a[3][2]����Ϊ����洢�Ĵ洢��ַ�Ͱ���Ϊ����洢�Ĵ洢��ַ?
��: ���д洢:a+(35+2) *2 = a+34
���д洢:a+(24+3) *2 = a+22
����������������������
һ��������
1������
��������ÿ���ڵ�������������������ṹ��
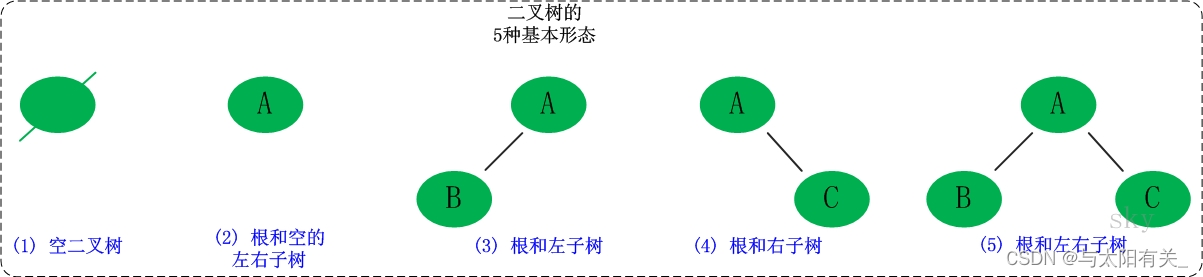
�������ֻ�����̬:
- �����������ǿռ�;
- �������пյ���������������;
- ��������������Ϊ�ա�
2�����Ķȡ����ӡ�˫�ס���ȡ��������������������ĸ߶�
a.��㡢Ҷ�ӡ����Ķ�
- ���Ķ�:���ӵ�е���������Ŀ��
- Ҷ��:��Ϊ��Ľ�㡣
- ���Ķ�:���н������Ķ�
b.���ӡ�˫�ס��ֵܡ��������
- ˫��:��һ�����������,�ý���Ϊ��������"˫��"��
- ����:�����ĸ��Ǹý���"����"��
- �ֵ�:����ͬ˫�Ľ�㻥Ϊ"�ֵ�"��
- ����:һ���������������ϵ��κν�㶼�Ǹý������
- ����:�Ӹ���㵽ij������·���ϵ����н�㶼�Ǹý������ȡ�
c.����������������ɭ��
- ������:������н��ĸ�����֮��Ĵ����������,���Խ���λ����
- ������:������н��ĸ�����֮��Ĵ������д����, �����Խ���λ����
- ɭ��:0���������ཻ������ɡ���ɭ�ּ���һ����,ɭ�ּ���Ϊ��;ɾȥ��,������Ϊɭ�֡�
d.��Ρ��߶�
���:�����IJ��Ϊ1,������IJ�ε��ڸý���˫���IJ�μ�1��
������Ⱥ߶�:�������нڵ������γ�Ϊ����������Ȼ�߶ȡ�
2������
����1:�������� i �������Ϊ 2^(i-1) (i��1)����㡣
����2:���Ϊk�Ķ�����������2^k - 1�����(k��1)��
����3:����n�����ġ���ȫ���������ĸ߶�kΪ
([log2n]��ʾ���������������)
����4:������һ�ö�������,���ն˽��ĸ���Ϊn0,��Ϊ2�Ľ����Ϊn2,��n0=n2+1��
����5:�����һ���� n��������ȫ������(�����Ϊ
- ��� i = 1,���� i�Ƕ������ĸ�,��˫��;��� i > 1,����˫���ǽ�� [i/2];
- ���2i >n,���� i ������(����� i ΪҶ�ӽ��);�����������ǽ�� 2i;
- ��� 2i+1 >n,���� i ���Һ���;�������Һ����ǽ�� 2i+1��
3��������������ȫ�������Ͷ���������
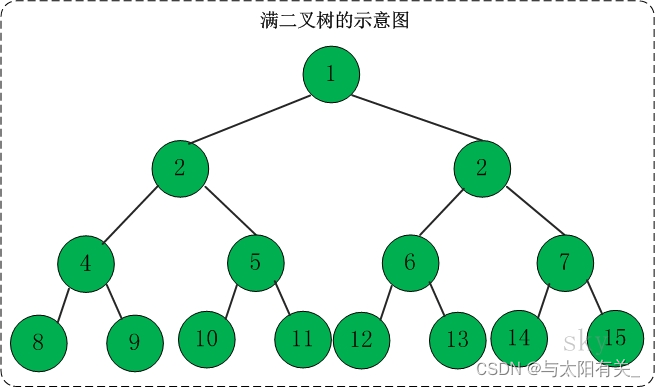
a.��������
����:�߶�Ϊh,������2{h} �C1�����Ķ�����,����Ϊ����������
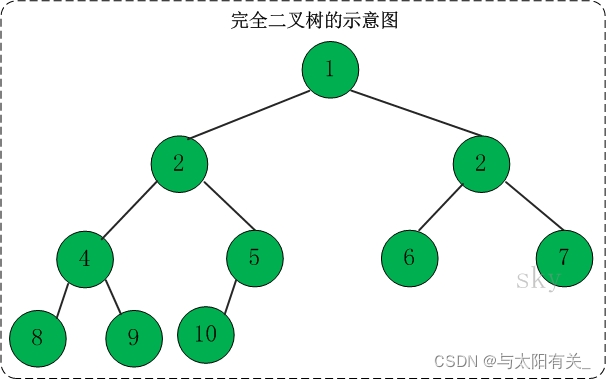
b.��ȫ������
����:һ�ö�������,ֻ��������������Ķȿ���С��2,��������һ���Ҷ��㼯���ڿ��������λ���ϡ������Ķ�������Ϊ��ȫ��������
�ص�:Ҷ�ӽ��ֻ�ܳ��������²�ʹ��²�,�����²��Ҷ�ӽ�㼯������������Ȼ,һ�����������ض���һ����ȫ������,����ȫ������δ��������������
c.���������
����:���������(Binary Search Tree),�ֱ���Ϊ��������������С�Ҵ�,���������������Ҳ�Ƕ��������
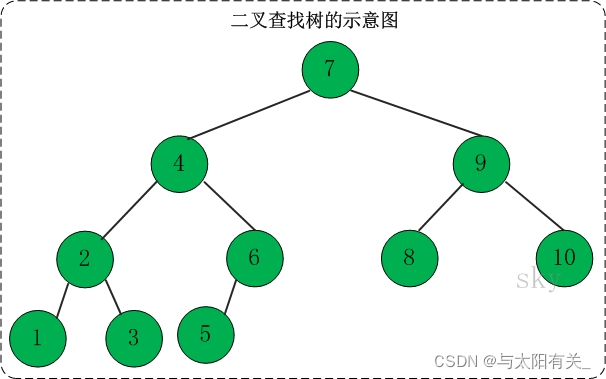
�ڶ����������:
(01) ������ڵ������������,�������������н���ֵ��С�����ĸ�����ֵ;
(02) ����ڵ������������,�������������н���ֵ���������ĸ�����ֵ;
(03) ����ڵ����������Ҳ�ֱ�Ϊ�����������
(04) û�м�ֵ��ȵĽڵ�(no duplicate nodes)��
������̬����
1��˳��洢�ṹ
ָ��һ���ַ�����Ĵ洢��Ԫ�������϶��¡��������Ҵ洢��ȫ�������Ľ��Ԫ��,������ȫ�������ϱ��Ϊi�Ľ��Ԫ�ش洢��һά�����±�i-1�ķ����С�
2��˳�����
�ӱ���һ�˿�ʼ,�������¼�Ĺؼ��ֺ���ֵ�Ƚ�,���ҵ�һ����¼�Ĺؼ��������ֵ���,����ҳɹ�;���������м�¼���ȽϹ�,��δ�ҵ��ؼ��ֵ��ڸ���ֵ�ļ�¼,�����ʧ�ܡ�
**ȱ��:**���ұ��ij���Խ��,����Ч��Խ�͡�
**�ŵ�:**����Ӧ���,�Բ��ұ��ṹû��Ҫ��,��˳��洢����ʽ�洢�����á�
3�����ֲ���(Ҳ�ơ��۰���ҡ�,��һ�á�������������)
����ұ�Ԫ�ش洢��һά����r[1,��,n]��,�ڱ��е�Ԫ���Ѿ����ؼ��ֵ�����ʽ����������,
����[�۰����]�ķ�����:���Ƚ�����Ԫ�صĹؼ���(key)ֵ���r�м�λ����(�±�Ϊmid)��¼�Ĺؼ��ֹؼ��ֽ��бȽ�,
- �����,����ҳɹ�;
- ��key>r[mid].key,��˵�������¼ֻ�����ں����ӱ�r[mid+1,��,n]��;
- ��key<r[mid].key,��˵�������¼ֻ������ǰ����ӱ�r[1,��,mid-1]��;
��������С��Χ,ֱ�����ҳɹ����ӱ�Ϊ��ʱʧ��Ϊֹ��
ע��:ÿ����С��Χ��,�ı���±����ĸ�
//�����ķ�ʽ����,���۰���ҵ��㷨Ϊ
//������r[low...high],������r����ֵΪkey��Ԫ��
int Bsearch(int r[],int low,int high,int key)
{
int mid;
while(low <= high)
{
mid = (low + high)/2;
if(key == r[mid])
return mid;
else if(key < r[mid])
high = mid-1;
else
low = mid+1;
}
return -1;
}
//�۰����,�ݹ��㷨
int Bsearch_rec(int r[],int low,int high,int key)
{
int mid;
if(low <= high)
{
mid = (low + high)/2;
if(key == r[mid])
return mid;
else if(key < r[mid])
return Bsearch_rec(r,low,mid-1,key);
else
return Bsearch_rec(r,mid+1,high,key);
}
return -1;
}
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-VgJbPWx2-1641217649130)(myReviewPicture/����11�����Ķ��ֲ����ж���.png)]](https://img-blog.csdnimg.cn/fcf30f3d8df741998eb546fede72a518.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_16,color_FFFFFF,t_70,g_se,x_16)
�۰���ҵĹ��̿�����һ�Ŷ�����������,�Ե�ǰ�����������м�λ�������Ϊ��,�����ӱ����Ұ���ӱ��еļ�¼��ŷֱ�ֱ���Ϊ�������������������ϵĽ��,��������Ķ�������Ϊ�۰�����ж���,�����Ͽ��Կ���:
? ���ҳɹ�ʱ,�۰���ҵĹ���ǡ������һ���Ӹ���㵽�����ҽ���·��,��ؼ��ֽ��бȽϵĴ�����Ϊ�����ҽ�������еIJ��������,�۰�����ж����ڲ��ҳɹ�ʱ���бȽϵĹؼ��ָ����������������,������n�������ж��������Ϊ;�����۰�����ڲ��ҳɹ�ʱ����ֵ���бȽϵĹؼ��ָ������Ϊ��
�ŵ�:����Ч�ʸ���,����Ҫ����ұ�����˳��洢�����ؼ��ֽ�������
ȱ��:�Ա����в����ɾ��ʱ,��Ҫ�ƶ�����Ԫ�ء�
����:�����ױ䶯,���־������в��ҵ����
4�����ֲ����ж���ASL����
�۰���ҵĹ��̿�,���ö�����������,�������е�ÿ������Ӧ������е�һ����¼,����е�ֵΪ�ü�¼�ڱ��е�λ�á�ͨ������������۰���Ҷ������Ĺ��̳�Ϊ�۰�����ж�����
����:˳��洢������{1,2,3,4,5,6,7,8,9,10} �����������ж���,������ASL
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-giB8nBKX-1641217649131)(myReviewPicture/���ֲ����ж���ASL�ɹ�-16411799392662.png)]](https://img-blog.csdnimg.cn/f25d4f432493489c8c87ce0cde1a8221.png)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-rHJdmL7J-1641217649131)(myReviewPicture/���ֲ����ж���ASL���ɹ�-16411799619963.png)]](https://img-blog.csdnimg.cn/0d7204efe94d4d1895da073d03229606.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_17,color_FFFFFF,t_70,g_se,x_16)
����:����Ϊ10���۰�����ж����ľ������ɹ���:
����ѭ�������,���ӽ��<�����<�Һ��ӽ�� ����С�Ҵ�
(1)�ڳ���Ϊ10��������н����۰����,���۲����ĸ���¼,��������м��¼���бȽ�,���м��¼Ϊ
(1+10)/2 =5 (ע��Ҫȡ��) ���ж����ĵĸ����Ϊ5,��ͼ7-2(a)��ʾ��
(2)�����ж�����������,����������������������,��ʱ�IJ�������Ϊ[1,4],��ô�м�ֵΪ(1+4)/2 =2 (ע��Ҫȡ��) ,���������Ӹ����Ϊ2,��ͼ7-2(b)��ʾ��
(3)�����ж�����������,������������������Ұ���,��ʱ�IJ�������Ϊ[6,10],��ô�м�ֵΪ(6+10)/2 =8 (ע��Ҫȡ��) ,���������Ӹ����Ϊ8,��ͼ7-2(c)��ʾ��
(4)�ظ����ϲ���,����ȥȷ�����Һ��ӡ�
�ص�:
1.�۰������һ������������,ÿ��������ֵ�����������������н���ֵ,С�����������н���ֵ��
2.�۰�����ж����еĽ�㶼�Dz��ҳɹ������,��ÿ�����Ŀ�ָ��ָ��һ��ʵ���ϲ����ڵĽ�㡪����������,�������㶼�Dz��Ҳ��ɹ������,��ͼ7-2(e)��ʾ�����������ij���Ϊn,������һ����n+1����
(1)���ҳɹ���ASL
�۰�����ж�����,ij������ڵIJ������Ǽ���Ҫ�ȽϵĴ���,�����ж����������������ƽ�����ҳ��ȼ�Ϊ����ÿ�����ıȽϴ���֮�ͳ���������� ���ȡ�
ASL�ɹ� = ÿ�������ڸ߶ȡ�ÿ������ ֮�� ���� �ܽ����
����:����Ϊ10���������ƽ�����ҳ���Ϊ
ASL=(1��1+2��2+3��4+4��3)/10=29/10;
(2)���Ҳ��ɹ���ASL
�۰�����ж�����,���Ҳ��ɹ��Ĵ�����Ϊ������Ӧ����(�������Ϸ�)���ڽ��ıȽϴ����������ж����������������ƽ�����ҳ��ȡ�����ʧ��ʱ���������ƽ�����ҳ��ȼ�Ϊ����ÿ������ıȽϴ���֮�ͳ�������ĸ�����
ASLʧ�� = (ÿ�㡾���ϵġ�������ڸ߶�-1)��ÿ�㡾���ϵġ������ ֮�� ���� �����ϵġ��ܽ����
����:����ʧ��ʱ,����Ϊ10���������ƽ�����ҳ���Ϊ:
ASL=(3��5+4��6)/11=39/11;
������̬����
1�������������ṹ��������:
typedef struct TNode *Position;
typedef Position BinTree; /* ���������� */
struct TNode
{/*����㶨�� */
ElementType Data; /* �������*/
BinTree Left; /*ָ��������*/
BinTree Right;/*ָ��������*/
};
�����������ٰ���3����:������ data����ָ���� lchild����ָ���� rchild
ָ����: n�������2n��ָ����
��ָ����:n �����Ķ��������к��� n+1 ����ָ����
?
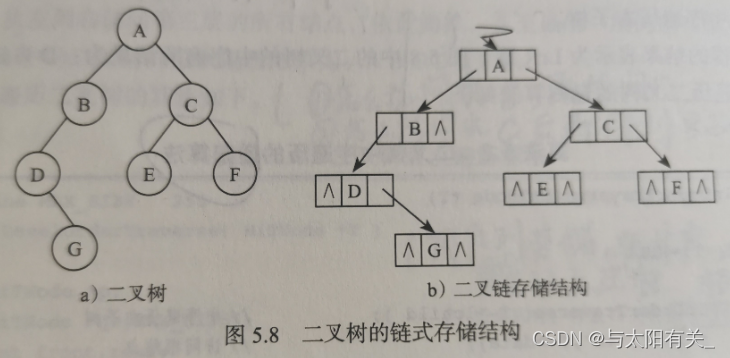
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-PqXCTOH8-1641217649132)(myReviewPicture/����������ʽ�洢�ṹ.png)]](https://img-blog.csdnimg.cn/ff91003008114e3287ef55d063b2d462.png)
2����������(������)���������
(1)�������
��������������Ĺ���,���Ǵӿն�������ʼ,��������в���ڵ�Ĺ��̡�
���¼�Ĺؼ�������Ϊ:63,90,70,55,67,42,98,83,10,45,58
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-HIN82LwY-1641218126672)(myReviewPicture/����������������.png)]](https://img-blog.csdnimg.cn/d3fc4077086c40f19f68f4c747a2f7de.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_1,color_FFFFFF,t_70,g_se,x_16)
(2)��������㷨�������
�������ڵ�ؼ���ֵΪ X :
(1)�������в���ֵΪ X �Ľڵ�,�����ҳɹ�,˵���ڵ��Ѵ���,�������;
(2)������ʧ��,˵���ڵ㲻����,������뵽����
���,�²���ڵ�һ������ΪҶ�ӽڵ����ġ�
BinTree Insert(Bintree BST, ElmentType X)
{
if(!BST)
{/*��ԭ����Ϊ��,���ɲ�����һ�����Ķ���������*/
BST = (BinTree)malloc(sizeof(struct TNode));
BST->Data = X;
BST->Left = BST->Right = NULL;
}
else
{/*��ʼ���Ҳ���Ԫ�ص�λ��*/
if(X < BST->Data)
BST->Left = Insert(BST->Left, X);/*�ݹ����������*/
else if(X > BST->Data)
BST->Right = Insert(BST->Right, X);/*�ݹ����������*/
}
return BST;
}
(2)ɾ�������㷨�������
������������ɾ������������������Ϊ����,Ҫɾ����������е�λ�������˲��������õ�������
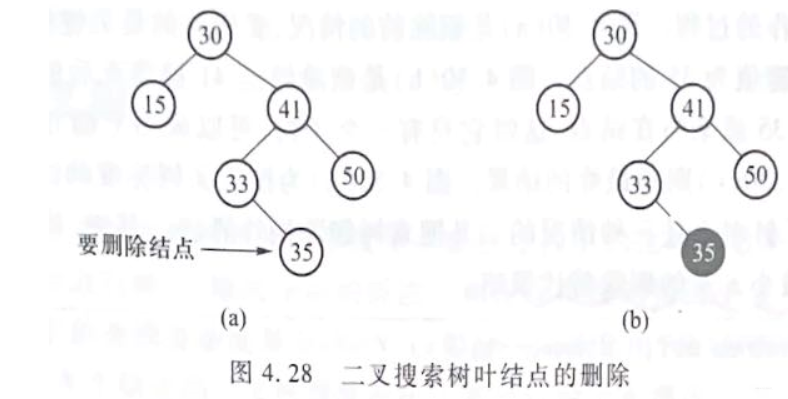
a.��Ҫɾ���Ľ����Ҷ�ӽ��
? ����ֱ��ɾ��,Ȼ�������丸����ָ�롣
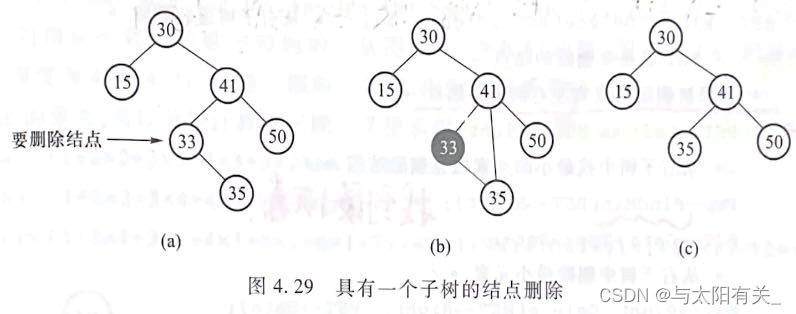
b.��Ҫɾ���Ľ��ֻ��һ�����ӽ��(�ý�㲻һ����Ҷ���,�����������ĸ�)
? ɾ��֮ǰ��Ҫ�ı丸����ָ��,ָ��Ҫɾ�����ĺ��ӽ�㡣
?
c.��Ҫɾ���Ľ����������������,������ѡ��:
? ����ԭ��:���ֶ�����������������
? 1��ȡ���������е���СԪ��;
? 2��ȡ���������е����Ԫ�ء�
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-Wzu1zptj-1641217649133)(myReviewPicture/�������������Ľ��ɾ��.png)]](https://img-blog.csdnimg.cn/048efb03866a4b1eace9c2b8f004d28b.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_20,color_FFFFFF,t_70,g_se,x_16)
(3)���ҹ����㷨�������
BST���IJ���˼��:
���Ƚ�������Kֵ����������������ڵ��Ĺؼ��ֽ��бȽ�:
�����,�����ҳɹ�;
��������KֵС��BST���ĸ��ڵ�Ĺؼ���:�����ڸýڵ���������Ͻ��в���;
��������Kֵ����BST���ĸ��ڵ�Ĺؼ���:�����ڸýڵ���������Ͻ��в�����
a.�����������ĵݹ���Һ���
�ڶ����������Ͻ��в���,���Ǵ��������������һ���Ӹ����������·��;
�����Ҳ��ɹ�,���ǴӸ�����������һ���Ӹ���ijһҶ����·����
Position Find(BinTree BST,ElementType X)
{
if(!BST->Data)
return NULL;/* ����ʧ�� */
if(X > BST->Data)
return Find(BST->Right, X);/* �� ������ �еݹ���� */
else if(X < BST->Data)
return Find(BST->Left, X);/* �� ������ �еݹ���� */
else
return BST;/* �ڵ�ǰ�����ҳɹ�,���ص�ǰ���ĵ�ַ*/
}
b.���������㷨
���ڷǵݹ麯����ִ��Ч�ʸ�,һ����÷ǵݹ�ĵ�����ʵ�ֲ��ҡ��������ݹ麯����Ϊ��������
whileѭ�� ���� Find�ݹ���ü���
Position Find(BinTree BST,ElementType X)
{
while(BST)
{
if(X > BST->Data)
BST = BST->Right;/* �� ������ ���ƶ�,�������� */
else if(X < BST->Data)
BST = BST->Left; /* �� ������ ���ƶ�,�������� */
else /* X == BST->Data;*/
break;/* �ڵ�ǰ�����ҳɹ�,����ѭ�� */
}
return BST;/* �����ҵ��Ľ���ַ,����NULL */
}
(4)�������ֵ����Сֵ
���ݶ���������������,��СԪ��һ���������������֧�Ķ˵����������֧�Ķ˵�:�����֧�������ӵĽ�㡣
���Ԫ��һ�������ҷ�֧�Ķ˽���ϡ�
- �Ӹ���㿪ʼ,���䲻Ϊ��ʱ,�����֧�����ҷ�֧����жϸ�����ָ��,ֱ��������ָ��Ϊֹ��
- �����֧������������ҵ�������СԪ�ء�
- ��֮,���ҷ�֧������������ҵ��������Ԫ�ء�
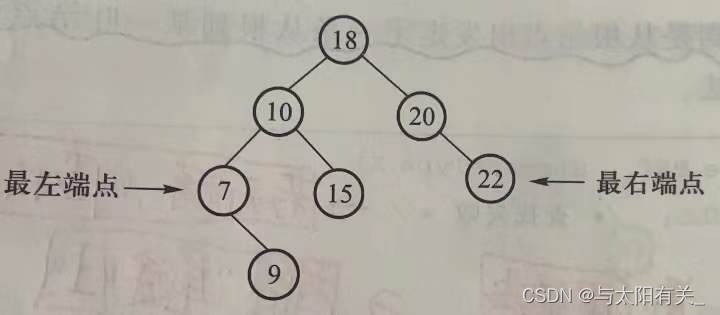
a.��СԪ�صĵݹ麯��
Position FindMin(BinTree BST)
{ /* ��СԪ��������˵� */
if(!BST)
return NULL;/* �յĶ���������,����NULL */
else if(!BST->Left)
return BST; /* �ҵ�����˵㲢���� */
else
return FindMin(BST->Left); /*�����֧�ݹ���� */
}
b.�������Ԫ�صĵ�������
Position FindMax(BinTree BST)
{
if(BST)
while(BST->Right);
BST = BST->Right; /*���ҷ�֧һֱ����,ֱ�����Ҷ˵� */
return BST;
}
�ġ��������ı���
ָ����ij�ִ�����ʶ����������н��,����ÿ����������һ��,�õ�һ���������С�
1���������
(1)���ʸ����
(2)�������������
(3)�������������-�������������
�������:A �� B �� D �� C
�������:B �� D �� A �� C
��������:D �� B �� C �� A
�������:A �� B �� C �� D
void PreOrderTraverse(BiTree T) //��ʽ��������������ݹ��㷨
{
if (T != NULL)
{
printf_s("%d ", T->data); //���ʸ����
PreOrderTraverse(T->lchild); //�������������
PreOrderTraverse(T->rchild); //�������������
}
}
//��ʽ��������������ݹ��㷨
void InOrderTraverse(BiTree T)
{
if (T != NULL) {
InOrderTraverse(T->lchild);
printf_s("%d ", T->data);
InOrderTraverse(T->rchild);
}
}
//��ʽ��������������ݹ��㷨
void PostOrderTraverse(BiTree T)
{
if (T != NULL) {
PostOrderTraverse(T->lchild);
PostOrderTraverse(T->rchild);
printf_s("%d ", T->data);
}
}
2���������(����ʵ��)
��ϸ���������������,��ʵ���Ǵ��ϵ���,���������ν�ÿ�������뵽������,Ȼ��˳�����δ�ӡ������Ҫ�Ľ����
ʵ�ֹ���
- �Ӷ�����ȡ��һ��Ԫ��;
- ���ʸ�Ԫ����ָ���;
- ����Ԫ����ָ�������Һ��ӽ��ǿ�,�������Һ��ӵ�ָ��˳����ӡ�
����ִ������������,ֱ������Ϊ��,����Ԫ�ؿ�ȡ,�������ij������������ˡ�
void LevelorDerTraversal(BinTree BT)
{
Queue Q;
BinTree T;
if(!BT)
return;/* ���ǿ�����ֱ�ӷ��� */
Q = CreatQueue(); /* �����ն��� */
AddQ(Q, BT);
while(!IsEmpty(Q))
{
T = DeteleQ(Q);
printf("%d",T->Data); /* ����ȡ�����еĽ�� */
if(T->Left)
AddQ(Q, T->Left);
if(T->Right)
AddQ(Q, T->Right);
}
}
3���ɱ������л�ԭ������
��֪����������������,���Ի�ԭ������;
��֪��������ͺ������,���Ի�ԭ������;
��֪��������ͺ������,�����Ի�ԭ������.
a.��֪������������������ԭ������
˼·:
1����������������ȷ�����ڵ㡣��������ĵ�һ���ڵ�Ϊ���ڵ㡣
2�� ���������������ҵ����ڵ�,���ڵ����IJ���Ϊ�������ڵ�,���ڵ��Ҳ�IJ���Ϊ�������ڵ㡣
3�� ����������Ľ�������ڵ��Ϊ������,������ִ�е�һ���͵ڶ���,ֱ����ԭ������������
����:��֪��������Ľ��Ϊ:ABDHIEJKCFLMGNO,��������Ľ��Ϊ:HDIBJEKALFMCNGO
�������Ϊ���½ṹ:
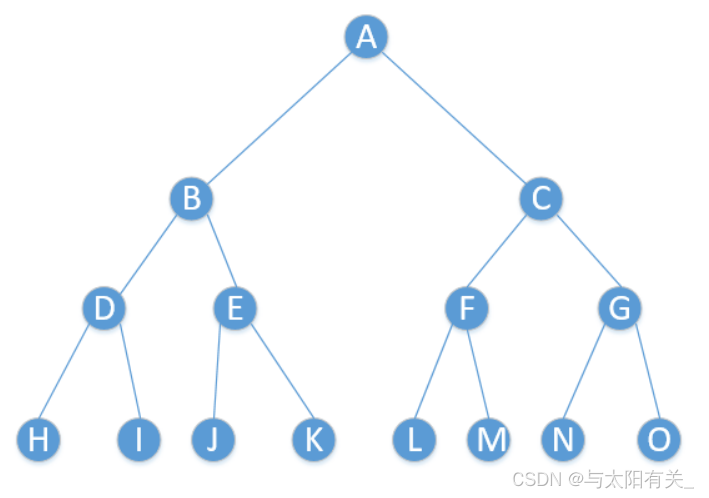
�����������Ϊ:HIDJKEBLMFNOGCA
b.��֪������������������ԭ������
˼·:
1�����ݺ���������ȷ�����ڵ㡣
������������һ���ڵ�Ϊ���ڵ㡣
2�����������������ҵ����ڵ�,���ڵ����IJ���Ϊ�������ڵ�,���ڵ��Ҳ�IJ���Ϊ�������ڵ㡣
3������������Ľ�������ڵ��Ϊ������,������ִ�е�һ���͵ڶ���,ֱ����ԭ������������
����:��֪��������Ľ��Ϊ:HIDJKEBLMFNOGCA,��������Ľ��Ϊ:HDIBJEKALFMCNGO
�������Ϊ���½ṹ:
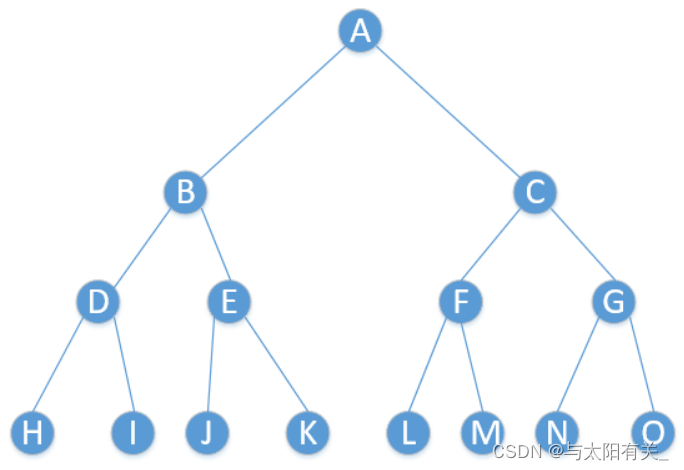
������������Ϊ:ABDHIEJKCFLMGNO
�塢�ݹ�����㷨��Ӧ��
1�������������
//���������
int TreeDeep(BiTree T)
{
int deep = 0;
if (T != NULL)
{
int leftDeep = TreeDeep(T->lchild);
int rightDeep = TreeDeep(T->rchild);
deep = leftDeep >= rightDeep ? leftDeep + 1 : rightDeep + 1;
}
return deep;
}
2����������Ҷ����
//��Ҷ����
int LeafCount(BinTree T,int num)
{
if(T)
{
if(!T->Left && !T->Right)
{
nm++;
}
TreeDeep(T->lchild, num);
TreeDeep(T->rchild, num);
}
return num;
}
3��������������
void Swap(BiTree *&right,BiTree *&left)
{
BiTree *temp=right;
right=left;
left=temp;
}
void SwapSubtrees(BiTree *T)
{
if(!T)
return ;
SwapSubtrees(T->rchild);
SwapSubtrees(T->lchild);
Swap(T->rchild,T->lchild);
}
������̬���ҺͶ�̬���ҵĸ�������
-
�������ڶ����������Ķ�̬����,���Ļ���ԭ���ͻ������Ա��ľ�̬���ֲ��Һ�����,�������������Բ�����С���ҿռ䡣
-
��֮�����о�̬�Ͷ�̬֮��,��Ҫ��Ϊ����Ӧ��ͬ��Ӧ������
| �ʺ����� | |
|---|---|
| ��̬���� | ����һ��������,����Ҫ���ߺ��ٽ��� ɾ�� �� ���� ���� |
| ��̬���� | Ƶ�������ݱ仯,���� �� ɾ�� �ǻ������� |
�ߡ���/ɭ�����������ת��
1������ɭ�����������ת��
���ڶ������������,Ϊ�˱������,����������,����Լ�����е�ÿ�����ĺ��ӽ�㰴�����ҵ�˳����б�š�
����ת���ɶ������IJ�����:
(1)���ߡ������������ֵܽ��֮���һ������;
(2)Ĩ�ߡ����Ƕ����е�ÿ�����,ֻ���������һ�����ӽ��֮�������,ɾ�������������ӽ��֮�������;
(3)��ת�����������ĸ����Ϊ����,��������˳ʱ����תһ���Ƕ�,ʹ֮�ṹ��η�����
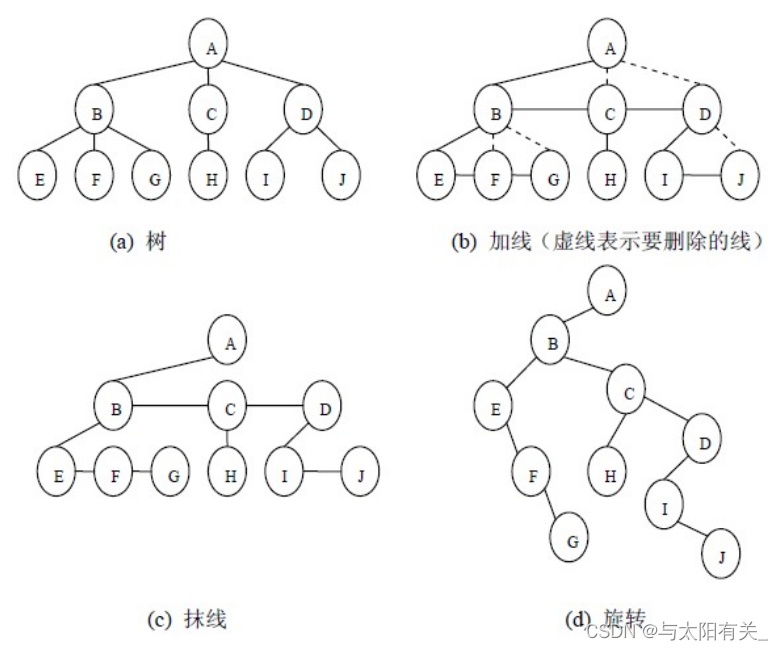
2��ɭ��ת��Ϊ������
ɭ���������ɿ������,���Խ�ɭ���е�ÿ�����ĸ���㿴�����ֵ�,����ÿ����������ת��Ϊ������,����ɭ��Ҳ����ת��Ϊ��������
��ɭ��ת��Ϊ�������IJ�����:
(1)�Ȱ�ÿ����ת��Ϊ������;
(2)��һ�ö���������,�ӵڶ��ö�������ʼ,���ΰѺ�һ�ö������ĸ������Ϊǰһ�ö������ĸ������Һ��ӽ��,�������������������еĶ���������������õ��Ķ�����������ɭ��ת���õ��Ķ�������
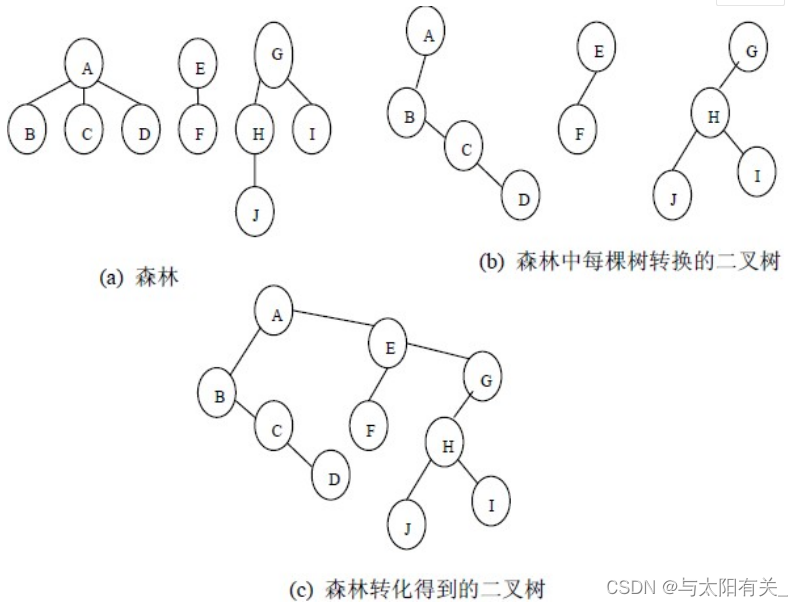
3��������ת��Ϊ��
������ת��Ϊ������ת��Ϊ�������������,�䲽����:
(1)��ij�������ӽ�����,�����ӽ����Һ��ӽ�㡢�Һ��ӽ����Һ��ӽ�㡭������Ϊ�ý��ĺ��ӽ��,���ý������Щ�Һ��ӽ��������������;
(2)ɾ��ԭ�����������н�������Һ��ӽ�������;
(3)����(1)��(2)�����õ�����,ʹ֮�ṹ��η�����
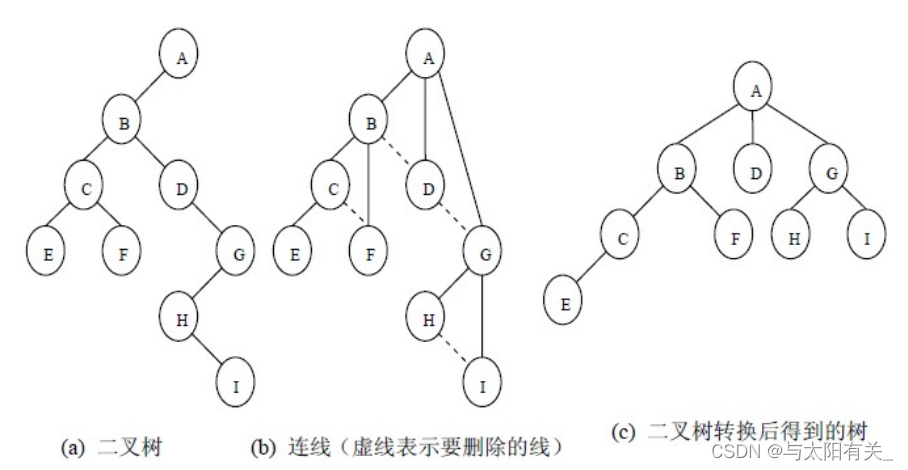
4��������ת��Ϊɭ��
������ת��Ϊɭ�ֱȽϼ�,�䲽������:
(1)�Ȱ�ÿ��������Һ��ӽ�������ɾ��,�õ�����Ķ�����;
(2)�ѷ�����ÿ�ö�����ת��Ϊ��;
(3)������(2)���õ�����,ʹ֮�淶,�����õ�ɭ�֡�
5��ת���Ժ���ص�:
? ���������������ת����ϵ�Լ��������ı������������֪:
-
���������������ת������Ӧ�Ķ���������������Ľ��������ͬ;
-
���ĺ����������ת���Ķ���������������Ľ��������ͬ;
-
���IJ����������ת���Ķ������ĺ�������Ľ��������ͬ��
��ɭ�����������ת����ϵ�Լ�ɭ����������ı��������֪:
? ɭ�ֵ���������������������ת���õ��Ķ������������������������Ľ��������ͬ��
�ˡ�����������
��ͳ�Ķ��������������ֳ�һ�ָ��ӹ�ϵ,����ֱ�ӵõ�����ڱ����е�ǰ�����̡�
���롾����������������Ϊ���ӿ���ҽ��ǰ���ͺ�̵��ٶȡ�
�涨:
- ����������,�� lchildָ����ǰ�����;
- ����������,��rchildִ��ָ�����̽��
- ����������־���ʶ��ָ����/�Һ��ӻ���ָ��ǰ��/��̡�
1���洢�ṹ
//�����������洢�ṹ
typedef struct ThreadNode{
char data;
struct ThreadNode *lchild, *rchild; // ���Һ���ָ��
int ltag, rtag; // ����������־
}ThreadNode, *ThreadTree;
2������ж��Ǻ��ӻ�������
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-fXyUjz8c-1641217649133)(myReviewPicture/�����������Ľṹ.png)]](https://img-blog.csdnimg.cn/0a88106aad604198821f66f4bb6631ae.png)
���־λ��������:
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-gl66MqHn-1641217649134)(myReviewPicture/�����������ı�ʶ������.png)]](https://img-blog.csdnimg.cn/31374bcb44574a9eae67b9f3b0c659fb.png)
-
���ּ��������Ķ���������Ϊ��������,��Ӧ�Ķ�������Ϊ������������
-
�����������ʵIJ�ͬ, �����������ɷ�Ϊǰ�������������� ���������������ͺ����������������֡�
3�����ֱ���
��Ϊ��������, �������ָ���б仯, ���ԭ���ı�����ʽ����ʹ��, ��Ҫʹ���µķ�ʽ������������������
���������������Ľ����������������������ǰ���ͺ����Ϣ��
�ڶ������ʱ,��Ҫ�ҵ���һ������ǰ����������,Ȼ�������ҽ��ĺ�̡�
�������������������ҽ���̵Ĺ�����:
- �����ұ�־Ϊ1,������Ϊ����,ָʾ����;
- ��������������е�һ�����ʵĽ��(�������������µĽ��)Ϊ���̡�
void InOrderTraverse(BiThrTree T){ // �������
if(T)
{
InOrderTraverse(T->lchild); //�������������
cout<< T->data;
InOrderTraverse(T->rchild); //�������������
}
}
�š���������
1����Ȩ·������WPL
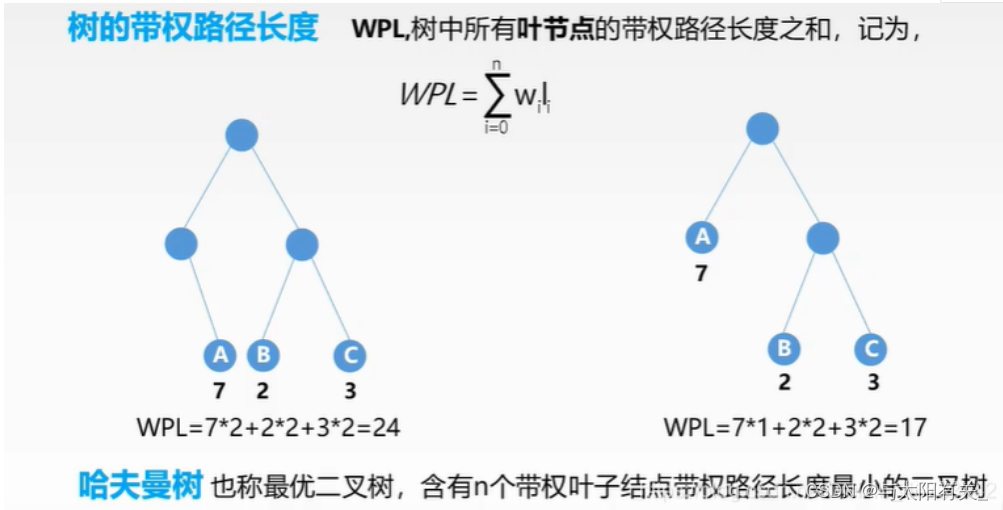
2�����������Ĺ���(�㷨)
���� Huffman ���Ļ���˼��:Ȩֵ��Ľ���ö�·��,ȨֵС�Ľ���ó�·����
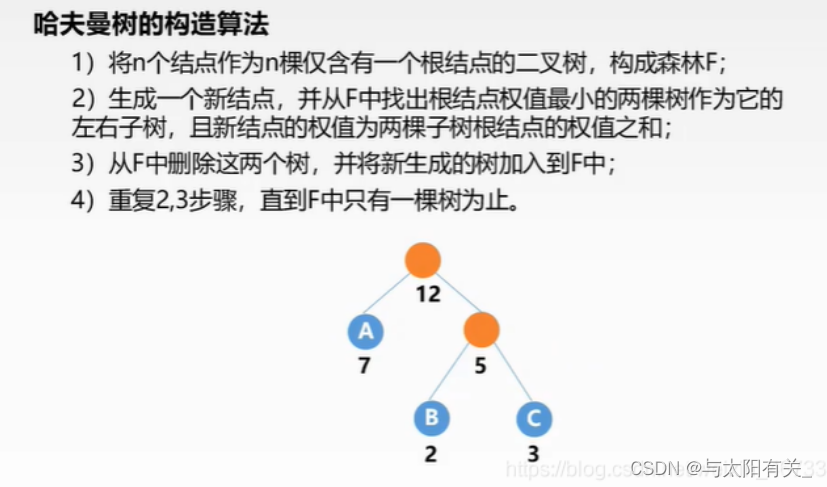
�������
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-FRkUM4N5-1641217649134)(myReviewPicture/huffmantree.png)]
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-S9xCYfbA-1641217649135)(myReviewPicture/huffmantree2.png)]](https://img-blog.csdnimg.cn/3a87797fe936496c82da32a3737eb2e7.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_17,color_FFFFFF,t_70,g_se,x_16)
3����������������

4������������

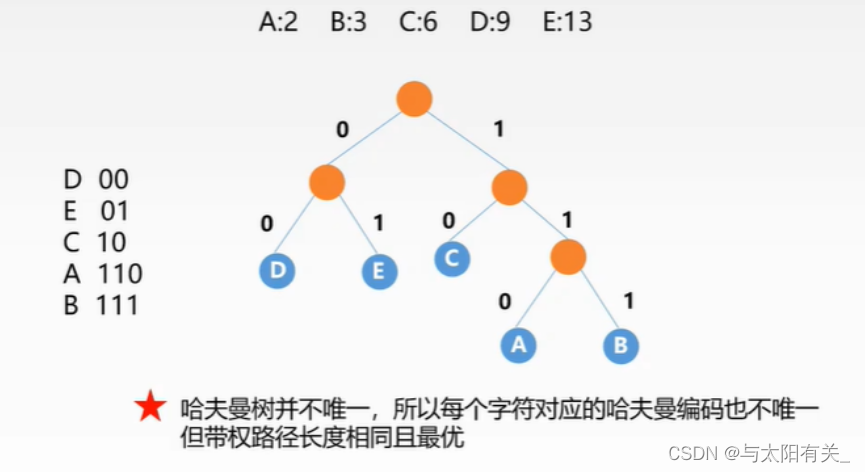
������ɢ�в��ҡ�����
һ��ɢ�в���
1����������
- ɢ�к���
? �ڽ��в���ʱ,�ڼ�¼�Ĵ洢λ�������Ĺؼ���֮�佨��һ��ȷ���Ķ�Ӧ��ϵh,�����Ա���ÿ��Ԫ�صĹؼ���KΪ�Ա���,ͨ������h(K)�������Ԫ�صĴ洢λ��,���ǽ�h������Ϊɢ�к������ϣ������h(K)��ֵ��Ϊɢ�е�ַ���ϣ��ַ��
- ��ͻ
? ��ʵ��Ӧ����,ͨ�����ܳ���һ��������Ԫ�ص�ɢ�е�ַ��Ԫ�ѱ�ռ�����,ʹ�ø�Ԫ����ֱ�Ӵ���˵�Ԫ,���������Ϊ��ͻ��
-
ͬ���
? ���в�ͬ�ؼ��ֶ�������ͬɢ�е�ַ��Ԫ�س�Ϊͬ���,��key1��key2,��h(key1)=h(key2)����ͬ�������ij�ͻ����ͬ��ʳ�ͻ��
-
װ������(��)
ָɢ�б����Ѵ����Ԫ����n��ɢ�б��ռ��Сm�ı�ֵ,��:��=n/m������ԽСʱ,��ͻ�����Ծ�ԽС,��ͬʱ,�洢�ռ������ʾ�Խ�͡�
ɢ�б�:�����趨�Ĺ�ϣ������������ͻ�ķ�����һ��ؼ���ӳ��һ�����������ĵ�ַ����,���Ѽ�¼����ڱ���ӳ���λ����,���ֱ����Ϊɢ�б�(��ϣ��)��
- һ��ɢ�б��ĺû������������й�:1.װ������ 2�������õ�ɢ�к��� 3�������ͻ�ķ���
�ٶ�һ�����Ա�ΪA=(18,75,60,43,54,90,46),ѡȡɢ�к���Ϊ:h(K)=K%m ȡm=13
���ÿ��Ԫ��ɢ�е�ַ:
h(18)=18 % 13=5
h(75)=75 % 13=10
h(60)=60 % 13=8
h(43)=43 % 13=4
h(54)=54 % 13=2
h(90)=90 % 13=12
h(46)=46 % 13=7
����ɢ�е�ַ,ʵ��Ԫ�صĴ洢ӳ��H[m]:
0 1 2 3 4 5 6 7 8 9 10 11 12 H 54 43 18 46 60 75 90
��:�����±����ٲ���Ԫ��70ʱ,70%13=5,������˳�ͻ
0 1 2 3 4 5 6 7 8 9 10 11 12 H 54 43 18 46 60 75 90
2��ɢ�к���
[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-OtlYI1uv-1641217649135)(myReviewPicture/ɢ�к���.png)]
����ɢ�к�����Ŀ����ʹɢ�е�ַ�����ܾ��ȷֲ���ɢ�пռ���,ͬʱʹ���㾡���ܼ�,�Խ�ʡ����ʱ�䡣
(1���ؼ���Ϊ����ʱ:
a.ֱ�Ӷ�ַ��
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-VlxRhB6x-1641217649136)(myReviewPicture/ֱ�Ӷ�ַ��.png)]](https://img-blog.csdnimg.cn/37f573e1743541dfac0f8a7096daf677.png)
b.����������(����)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-fZm4ezqe-1641217649136)(myReviewPicture/����������.png)]](https://img-blog.csdnimg.cn/2ffd9c6927634234ae7783150861260a.png)
c.���ַ�����
�������ֹؼ����ڸ�λ�ϵı仯���,ȡ�Ƚ������λ��Ϊɢ�е�ַ,��绰���롢����֤����ij��λ��Ƚ����;
**��:**��һ��ؼ�������:
? 92326875
? 92739628
? 92343634
? 92706816
? 92774638
? 92381262
? 92394220
ͨ������:ÿ���ؼ��ִ����ҵ�1��2��3λ�͵�6λȡֵ�ϼ���,������ɢ�е�ַ,����ĵ�4��5��7��8λȡֵ��ɢ,����ѡ��,��ȡ�����λ��ɢ�е�ַ,��:(2,75,28,34,16,38,62,20)
d.ƽ��ȡ�з�
keyȡƽ����ȡ�м伸λ
(2���ؼ���Ϊ�ַ�ʱ:
a��ASCII��Ӻͷ�
h(key)=(���key[i])mod TableSize
b��ǰ3���ַ���λ��
h(key)=(key[0]*27*27+key[1]*27+key[2])mod TableSize
����������ͻ�ķ���
1�����Ŷ�ַ��
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-w3vCRkqI-1641217649137)(assets/���Ŷ�ַ��2.png)]](https://img-blog.csdnimg.cn/9d3b4a588f474c4c8997e8266772ba24.png)
a.����̽�ⷨ
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-CKgRc9iU-1641217649138)(myReviewPicture/����̽�ⷨ.png)]](https://img-blog.csdnimg.cn/76011ef539d546f58ff3fbacdc7ad1a1.png)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-dRJEytI9-1641217649139)(myReviewPicture/���Ŷ�ַ��.png)]](https://img-blog.csdnimg.cn/7ea9e25b68dc465f9e57faaa32d54eaf.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_19,color_FFFFFF,t_70,g_se,x_16)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-s9TU3kVj-1641217649139)(myReviewPicture/ASL.png)]](https://img-blog.csdnimg.cn/d9626b76bc0149db83f3e27e5b4d7d9a.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_18,color_FFFFFF,t_70,g_se,x_16)
ע��:����ij��ֵʱ,��ɢ�к����������,����Ǹ����λ���ϵ�������ؼ��ʲ�һ��ʱ,�����ܶ϶��ؼ��ʲ�����,��Ӧ�ð��ճ�ͻ������Լ�����,ֱ���ҵ���λ���˻�û�ҵ�,���ܶ϶��ùؼ��ʲ����ڡ�
b��ƽ��̽��(����̽��)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-tK3J9VUv-1641217649140)(myReviewPicture/ƽ��̽�ⷨ5.png)]](https://img-blog.csdnimg.cn/0149efbfb6574e53a0001838eee2d47e.png)
����:h(key)=key mod 11;
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-jyTvTfbw-1641217649140)(myReviewPicture/ƽ��̽�ⷨ.png)]](https://img-blog.csdnimg.cn/981799dfe85642b4ac3a6b58c4f5ad04.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_18,color_FFFFFF,t_70,g_se,x_16)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-XTqZBJVG-1641217649140)(myReviewPicture/ƽ��̽�ⷨ2.png)]](https://img-blog.csdnimg.cn/eab66eb289aa49b4b96081dd2ebbbe6b.png)
**ע��:**ȡ������Ϊ�˼��ٹ�����(���ٳ�ͻ)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-RL4wdkRn-1641217649142)(myReviewPicture/ɢ�б���װ������.png)]](https://img-blog.csdnimg.cn/8c2a05ba4e504e8f9e0bbd2bc9509692.png)
c.��ɢ�з�
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-sXqpjUkM-1641217649142)(myReviewPicture/��ɢ�з�.png)]](https://img-blog.csdnimg.cn/25736c5928d04296b9b3bb64dcb102d6.png)
2���������ӷ�

![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-QpGllGXr-1641217649142)(myReviewPicture/����ַ��.png)]](https://img-blog.csdnimg.cn/3f9c9183afa04c67b51ad43a3d19ad0f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_20,color_FFFFFF,t_70,g_se,x_16)
������������������������������ͼ��������������������������������
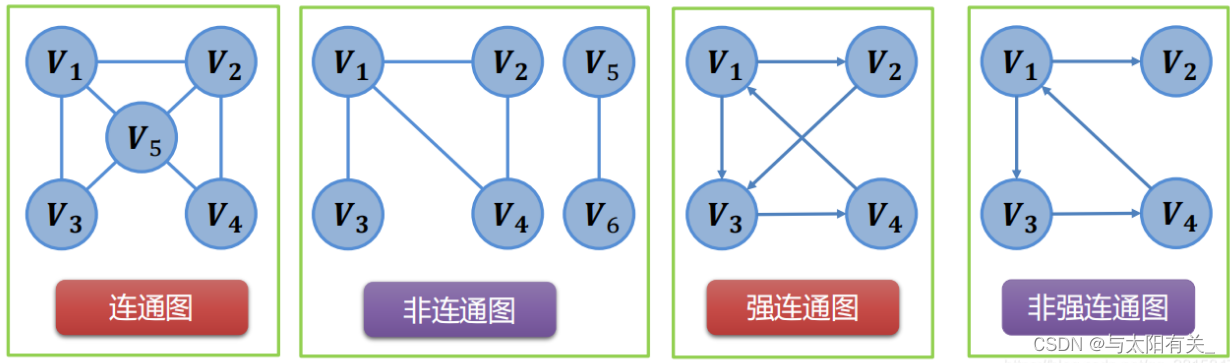
һ��ͼ�Ļ�������
����ֻ��ͬ����һ������;���Խṹ����һ��һ�Ĺ�ϵ;���νṹ����һ�Զ�Ĺ�ϵ;ͼ״�ṹ���ڶ�Զ�Ĺ�ϵ��

1����ͼ
��ͼ����������������:
1)�������ظ���
2)�����ڶ��㵽�����ı�
2����ȫͼ
����������֮�䶼���ڱ�
3����ͨ����
������ͼ��,��������·������,�ͳ�Ϊ��ͨ�ġ���ͼ�����������㶼��ͨ,ͬ��ͼΪ��ͨͼ������ͼ�еļ�����ͨ��ͼ��Ϊ��ͨ������
4��ǿ��ͨ����
������ͼ��,����������������·��,�������Ϊǿ��ͨ��
����һ���㶼��ǿ��ͨ��,��Ϊǿ��ͨͼ������ͼ�м���ǿ��ͨ��ͼΪ����ͼ��ǿ��ͨ������
5.����Ķȡ���Ⱥͳ���
����Ķ�Ϊ�Ըö���Ϊһ���˵���ߵ���Ŀ��
��������ͼ,����ı���Ϊ��,����֮���Ƕ�������� 2 ����
��������ͼ,������Զ���Ϊ�յ�,�����෴������ͼ��ȫ���������֮�͵��ڳ���֮���ҵ��ڱ���������Ķȵ�����������֮��
ע��:�����������������ͼ��˵��
����ͼ�Ĵ洢
1������(�ڽӾ���)��ʾ��
-
����һ�������(��¼����������Ϣ)��һ���ڽӾ���(��ʾ��������֮���ϵ)��
-
��ͼA=(V,E)��n������,��

-
ͼ���ڽӾ�����һ����λ����A.arcs[n] [n],����Ϊ:
??����??��????��?
��????��????��?��
a.����ͼ���ڽӾ����ʾ��
����1:����ͼ���ڽӾ������Գ���;
����2:����i�Ķ�=��i��(��)��1�ĸ���;
�ر�:��ȫͼ���ڽӾ�����,�Խ�Ԫ��Ϊ0,����1��

b.����ͼ���ڽӾ����ʾ��
ע:������ͼ���ڽӾ�����,
�� i ������:�Խ��viΪβ�Ļ�(�����ȱ�)
�� i ������:�Խ��viΪͷ�Ļ�(����ȱ�)
����1:����ͼ���ڽӾ��������Dz��Գ���;
����2:����ij��� = �� i ��Ԫ��֮��
�������� = �� i ��Ԫ��֮��
����Ķ� = �� i ��Ԫ��֮�� + �� i ��Ԫ��֮��
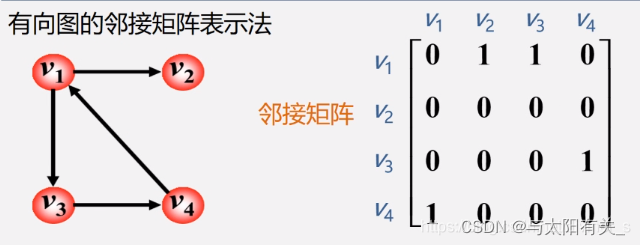
c.��Ȩͼ(��)���ڽӾ����ʾ��


2.�ڽӱ�(˳��洢����ʽ�洢���)


a.����ͼ���ڽӱ�
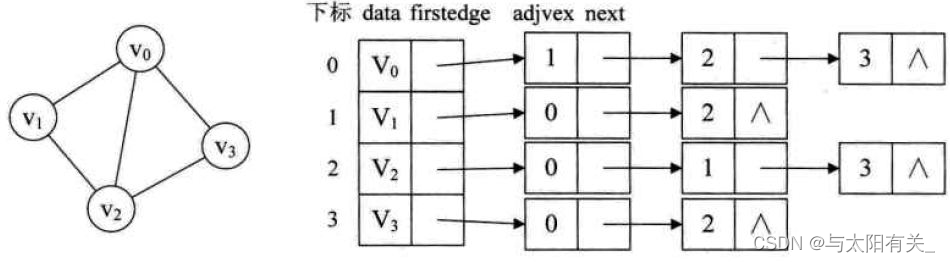
b.����ͼ���ڽӱ������ڽӱ�
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-trpuTIAt-1641217649145)(myReviewPicture/����ͼ���ڽӱ�.jpeg)]](https://img-blog.csdnimg.cn/2229a0e5a6f54d05a2652b88656402d7.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_20,color_FFFFFF,t_70,g_se,x_16)
c.��Ȩֵ����ͼ
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-Ah5zBlPv-1641217649146)(myReviewPicture/��ͼ���ڽӱ�.png)]](https://img-blog.csdnimg.cn/ac35e05e27e9437ea55762722b9cb538.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_20,color_FFFFFF,t_70,g_se,x_16)
����ͼ�ı���
1��������ȱ����㷨
������������������������������
�����˼����:
���ȷ�����ʼ����v,Ȼ����v����,������v �ڽ���δ����������һ����w1,�ٷ�����w1 �ڽ���δ�����ʵ���һ����W2�����ظ�����������
�������ټ������·���ʱ,�����˻ص���������ʵĶ���,���������ڽӶ���δ�����ʹ�,��Ӹõ㿪ʼ����������������,ֱ��ͼ�����ж���������ʹ�Ϊֹ��
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-tAlBFL32-1641217649146)(myReviewPicture/������ȱ���.png)]](https://img-blog.csdnimg.cn/169fa2d113c340b79534ea756f511f8e.png)
�Ӷ���a ����,����������ȱ���,���Եõ���һ�ֶ�������Ϊ:a e d f c b
2��������ȱ����㷨
����������������ڶ������IJ�������㷨��
�����˼����:
- ���ȷ�����ʼ����v,�����ɦͳ���,���η���v �ĸ���δ���ʹ����ڽӶ���W1,W2,��,Wi,Ȼ�����η���W1,W2,��,Wi������δ�����ʹ����ڽӶ���;
- �ٴ���Щ���ʹ��Ķ�������,������������δ�����ʹ����ڽӶ���,ֱ��ͼ�е����ж��㶼�����ʹ�Ϊֹ��
- ����ʱͼ�����ж���δ������,����ѡͼ�е�һ��δ�����ʵĶ�����Ϊʼ��,�ظ���������,ֱ��ͼ�����ж��㶼�����ʵ�Ϊֹ��
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-4dDjFgZo-1641217649147)(myReviewPicture/������ȱ���.png)]](https://img-blog.csdnimg.cn/dff7cc39e2bd4e578bbf3c99856bbf29.png)
�Ӷ���1 ����,���չ�����ȹ������,���Եõ���һ�ֶ���������: 1234576
������������
1������
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-hfg0lPhL-1641217649147)(myReviewPicture/��С������������.png)]](https://img-blog.csdnimg.cn/e347e25127b942438717030d7116e21e.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_20,color_FFFFFF,t_70,g_se,x_16)
2��Prim�㷨
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-uhZfCQrh-1641217649147)(myReviewPicture/Prim�㷨.png)]](https://img-blog.csdnimg.cn/ef3ac943225a4cb5a4515625d54a26cf.png)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-hrqqoFVo-1641217649148)(myReviewPicture/��С������Prim�㷨.png)]](https://img-blog.csdnimg.cn/8764850480164f1aa6c28a7b855a3ef5.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_20,color_FFFFFF,t_70,g_se,x_16)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-te5iPtxy-1641217649149)(myReviewPicture/��С������Prim�㷨2.png)]](https://img-blog.csdnimg.cn/12fdbfbd81dd46478a8ca15b9a9d2929.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_20,color_FFFFFF,t_70,g_se,x_16)
3��Kruskal�㷨
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-l7q0KxrC-1641217649149)(myReviewPicture/Kruskal�㷨.png)]](https://img-blog.csdnimg.cn/e204e60970d54b62ab9ea93384510c71.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_20,color_FFFFFF,t_70,g_se,x_16)
������������
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-UnFfZk1Y-1641217649149)(myReviewPicture/��������.png)]](https://img-blog.csdnimg.cn/ceab0f0502cd48bda516db85b04184df.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_20,color_FFFFFF,t_70,g_se,x_16)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-zr1pgvkl-1641217649150)(myReviewPicture/������������.png)]](https://img-blog.csdnimg.cn/fc02d98282f44404b0b9a234a52d1305.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_20,color_FFFFFF,t_70,g_se,x_16)
�ġ����·��
�Ͻ�˹�����㷨
ͨ���Ͻ�˹�����㷨����ͼG�е����·��ʱ,��Ҫָ�����s��
? ����,��Ҫ������������S��U��
- S������:��¼��������·���Ķ���(�Լ���Ӧ�����·������),
- U������:��¼��δ������·���Ķ���(�Լ��ö��㵽���s�ľ���)��
- ��ʼʱ,S��ֻ�����s;
- U���dz�s֮��Ķ���,����U�ж����·���ǡ����s���ö����·������
- Ȼ��,��U���ҵ�·����̵Ķ���,��������뵽S��;
- ����,����U�еĶ���Ͷ����Ӧ��·����
- Ȼ��,�ٴ�U���ҵ�·����̵Ķ���,��������뵽S��;����,����U�еĶ���Ͷ����Ӧ��·����
- �ظ���������,ֱ�����������ж��㡣
�������
1����ʼ��,���ж���ľ����ʼ��Ϊ�����(INFINITY)
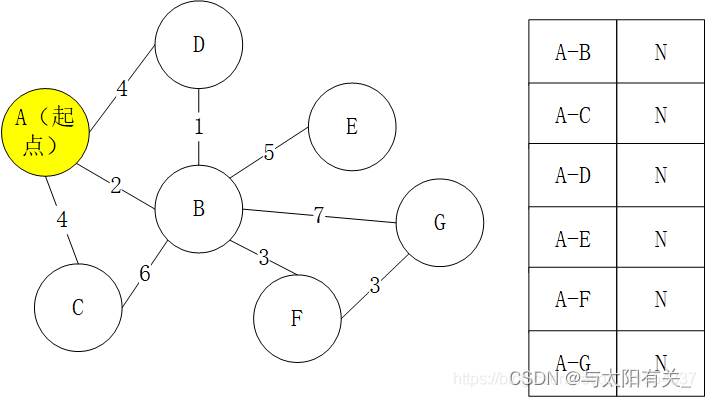
2��ѡ����A,����(A-A������Ϊ0)
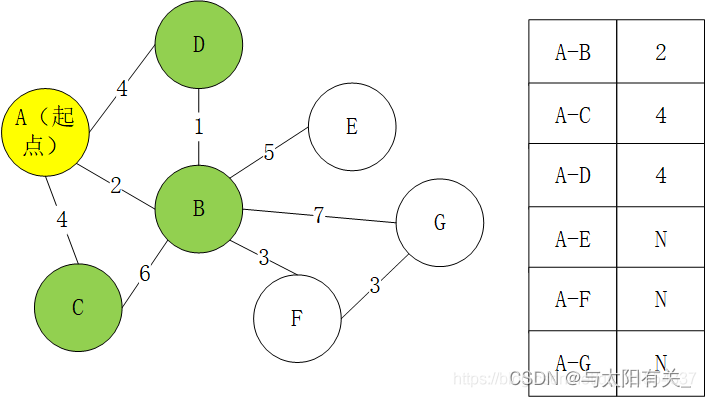
3��S����Ϊ{A,B},����B�������ڽӵ�
Ϊʲôѡ��B���뼯��S?
��Ϊ�����ܻ�������·����2����,�Ҳ��ܾ���C��B����D��B����������·��С��2,�������ǵõ���A->B�����·��
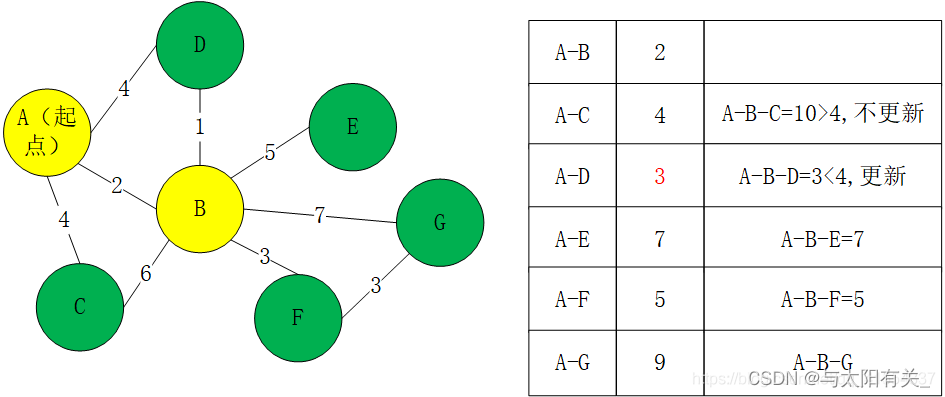
������һ��,��һ�����뼯��S����D
��ΪĿǰA->D��·���������,Ϊ3(���Ѿ�֪����Aֱ�ӵ�D��A����B��D��·������)
���A->B->X->DС��min{A->D,A->B->D},��ôA->B->XС��min{A->D,A->B->D},��ô���뼯�ϵ�Ӧ����X,����ì�ܵ�(�������IJ�������һ���ĵ���
4��S����Ϊ{A,B,D},��U��û��D���ڽӵ�,������
5��S����Ϊ{A,B,D,C},��U��û��C���ڽӵ�,������
6��S����Ϊ{A,B,D,C,F},����
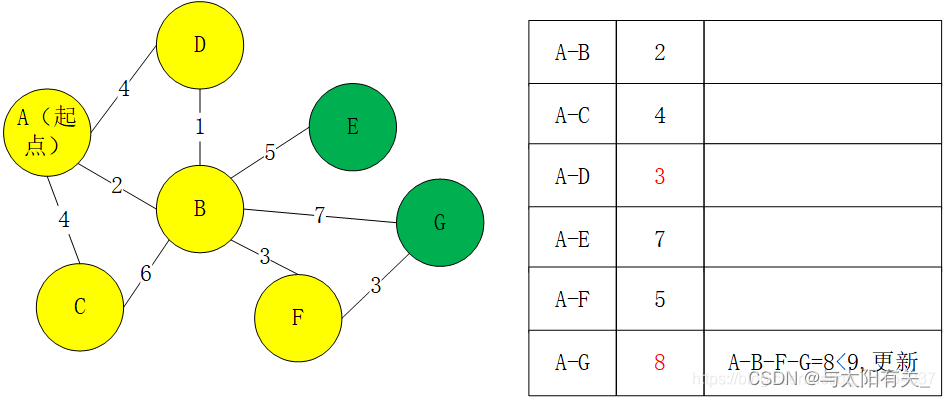
7��S����Ϊ{A,B,D,C,F,E},��U��û��E���ڽӵ�,������
8��S����Ϊ{A,B,D,C,F,E,G},��U��û��G���ڽӵ�,������
9�����ս������ͼ��
������������
һ����������
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-IBiNgFub-1641217649151)(myReviewPicture/����.png)]](https://img-blog.csdnimg.cn/3ead781541bd4020b4860e986ffd357a.png)
1����������
����˼��:
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-W5Hwkv7f-1641217649151)(assets/�����������˼��.png)]](https://img-blog.csdnimg.cn/a716ae4bd0ec414cb6de5820b623cceb.png)
��1��ֱ�Ӳ�������
(1������˼��:
1)�����������һ������(��N����)��Ϊ���źõ���δ�źõ� 2������;
2)����ʼ״̬ʱ,������������������1 ��Ԫ��,δ���������е�Ԫ��Ϊ��ȥ��1 ��Ԫ�������N-1 ��Ԫ��;
3)���˺�,��δ���������е�Ԫ����һ���뵽�������������;
4)���������,����N-1 �������,δ����������Ԫ�ظ���Ϊ0 ,��������ɡ�
(2��ִ�й���
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-7EB0PiaP-1641217649152)(myReviewPicture/ֱ�Ӳ�����������1.png)]](https://img-blog.csdnimg.cn/cd59ca85143d47ecae662a837e5d66e7.png)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-59uBl571-1641217649152)(myReviewPicture/ֱ�Ӳ�������2.png)]](https://img-blog.csdnimg.cn/c82a0073b02a405f8510d1de35db6e54.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_19,color_FFFFFF,t_70,g_se,x_16)
(3��ʱ��Ч�ʼ��ȶ���
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-SxUpnfwg-1641217649152)(myReviewPicture/ֱ�Ӳ���ʱ��Ч��.png)]](https://img-blog.csdnimg.cn/81c9cea5df3847ebb12c1280bc2a914b.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_20,color_FFFFFF,t_70,g_se,x_16)
��2��ϣ������
(1������˼��:
1)�������������е�һ��Ԫ�ذ�һ�������Ϊ���������ֱ������������;
2)����ʼʱ���õġ�������ϴ�,��ÿ��������,��**�����������С**
3)��ֱ���������Ϊ 1,Ҳ�͵������һ��,������������
(2��ִ�й���
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-auVhyLOw-1641217649153)(myReviewPicture/ϣ������2.png)]](https://img-blog.csdnimg.cn/e32753471f04474396c8ed5ad3388f56.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_20,color_FFFFFF,t_70,g_se,x_16)
(3��ʱ��Ч�ʼ��ȶ���
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-Ux0GsKAK-1641217649153)(myReviewPicture/ϣ������3.png)]](https://img-blog.csdnimg.cn/8890b05da7c44a5ea91bf5798f2e156a.png)
2����������
����˼��:
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-ZgGwNJn5-1641217649154)(myReviewPicture/�����������˼��.png)]](https://img-blog.csdnimg.cn/959f6476e86343899ed6098d8d877ceb.png)
��1������
(1������˼��:
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-zJfYxzHa-1641217649155)(myReviewPicture/ð���������˼��.png)]](https://img-blog.csdnimg.cn/b36ed4fd74534dd880c736fbb3581b07.png)
(2��ִ�й���
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-95qkCnr1-1641217649155)(myReviewPicture/ð������ִ�й���.png)]](https://img-blog.csdnimg.cn/5f0bc425e5d5433bb5adc6dba830d17e.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_18,color_FFFFFF,t_70,g_se,x_16)
(3��ʱ��Ч�ʼ��ȶ���
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-xRUZHEtW-1641217649155)(myReviewPicture/ð������ʱ��Ч��.png)]](https://img-blog.csdnimg.cn/3dc2e60a1ba54a42897ee7811ec80ab7.png)
��2����������
(1������˼��:
1)����δ����Ԫ�ظ���һ����Ϊ���ġ���Ԫ(pivot)��Ϊ����������;
2)������һ�������еļ�¼����������Ԫ��,��һ����������С������Ԫ;
3)���ݹ��ض����������������Ƶķ�����������
(2��ִ�й���
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-8y2pVgAJ-1641217649155)(myReviewPicture/������������1.png)]](https://img-blog.csdnimg.cn/8dd2741b540e485a894d20cb5803ec16.png)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-Q4MhHTt1-1641217649156)(myReviewPicture/������������2.png)]](https://img-blog.csdnimg.cn/1b76780be69d40df9f23af2833c5c70b.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_15,color_FFFFFF,t_70,g_se,x_16)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-YNkG7K8J-1641217649156)(myReviewPicture/��������3.png)]](https://img-blog.csdnimg.cn/056543775a4242bb9568ec55bb8bab0a.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_20,color_FFFFFF,t_70,g_se,x_16)
(3��ʱ��Ч�ʼ��ȶ���
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-E3u9CHCI-1641217649156)(myReviewPicture/��������ʱ��Ч��.png)]](https://img-blog.csdnimg.cn/6c08c4434d164e1c99766524b796862d.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_20,color_FFFFFF,t_70,g_se,x_16)
3��ѡ������
����˼��:
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-6WCpUUz3-1641217649157)(myReviewPicture/ѡ������Ļ���˼��.png)]](https://img-blog.csdnimg.cn/8b44fd37c6d048cdb5f5f43d2e7e0ce5.png)
��1����ѡ������
(1������˼��:
1)����δ�����������ѡ����СԪ�غ����е���λԪ������,
2)������ʣ�µ�������������ѡ����СԪ�������еĵ�2 ��λ��Ԫ�ؽ���
3)���Դ�����,����βδ�С��������������С�
(2��ִ�й���
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-eenzDDlH-1641217649158)(myReviewPicture/��ѡ������ִ�й���.png)]](https://img-blog.csdnimg.cn/f01586c330b94cb4a04088d6f4f40290.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_20,color_FFFFFF,t_70,g_se,x_16)
(3��ʱ��Ч�ʼ��ȶ���
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-HhrGBaPc-1641217649158)(myReviewPicture/��ѡ������3.png)]](https://img-blog.csdnimg.cn/adb783e44fab40d2b8af0d26ca789430.png)
��2��������
(1������˼��:
1)����������(����С��)����Ѷ�Ԫ��,�����ֵ(����Сֵ);
2)����ʣ��Ԫ��������������(����С��),��������Ѷ�Ԫ��;
3)���ظ��˹���,֪��ȫ��Ԫ�ض������,�õ������Ԫ�����м�Ϊ��������
(2��ִ�й���Ҫ��
<1>��ʼ���ѵĹ���
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-BUmqOTks-1641217649159)(myReviewPicture/ִ�й���.png)]](https://img-blog.csdnimg.cn/c51e5a45d1214b328b40410942e961dd.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_15,color_FFFFFF,t_70,g_se,x_16)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-amUvD16w-1641217649159)(myReviewPicture/������.png)]](https://img-blog.csdnimg.cn/2c915096382d4db99e74dd806db1f80e.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_20,color_FFFFFF,t_70,g_se,x_16)
�����ǹ�����ʼ�ѵĹ���
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-WbussFeE-1641217649160)(myReviewPicture/������2.png)]](https://img-blog.csdnimg.cn/a703e036f4994e1dbf10536178d9d6bd.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_20,color_FFFFFF,t_70,g_se,x_16)
�����Ƕ�����Ĺ���
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-jBlnfC3t-1641217649160)(myReviewPicture/������1.png)]](https://img-blog.csdnimg.cn/3e197289c21d482b9fb30c3612c610f8.png)
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-sWcyGiCK-1641217649160)(assets/image-20220103210541040.png)]](https://img-blog.csdnimg.cn/7f25521727a14858bff6f220cf3b734e.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_15,color_FFFFFF,t_70,g_se,x_16)
(3��ʱ��Ч�ʼ��ȶ���
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-GOajy21Q-1641217649161)(myReviewPicture/������ռ�Ч��.png)]](https://img-blog.csdnimg.cn/a1854cd415f443f5b03babae330af06a.png)
4���鲢����
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-g1lLA8Bd-1641217649161)(myReviewPicture/�鲢����.png)]](https://img-blog.csdnimg.cn/df241b859fb74202a013ee553205f60a.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_20,color_FFFFFF,t_70,g_se,x_16)
������������ıȽ�
�ھ�:��ѡ��ϣ����,ѡ�ѹ������
����:˵���� �㷨���ȶ�
����:˵���� �����ƶ������ؼ���˳���ص�����
![[����ͼƬת��ʧ��,Դվ�����з���������,���齫ͼƬ��������ֱ���ϴ�(img-Srey30WJ-1641217649161)(myReviewPicture/��������ıȽ�.png)]](https://img-blog.csdnimg.cn/a6e10eb1343f4715b890c9c6f0a8f86f.png?x-oss-process=image/watermark,type_d3F5LXplbmhlaQ,shadow_50,text_Q1NETiBA5LiO5aSq6Ziz5pyJ5YWzXw==,size_20,color_FFFFFF,t_70,g_se,x_16)