������
��ϣ��(��ϣ��ͻ):
? ��ϣ��������������Ĵ洢,ÿ������������ʱ��,��Ҫָ���е�hashֵ,ȡģ���������±�,��Ԫ�ز����±�λ�ü��ɡ�
? �ʺϳ���:
? ��ֵ��ѯ
? ���е���������������(��Χ���ҵ�ʱ��Ƚ��˷�ʱ��,��Ҫ�������б�������)������ҵ�ж����Ƿ�Χ��ѯ,���Դ�ʱhash�������ر��ʺ�,
hash����ʹ�õ�ʱ��,��Ҫ��ȫ�������ݼ��ص��ڴ�,�ȽϺķ��ڴ�Ŀռ�,Ҳ���Ǻܺ���
��:
�����,������(���ֲ���),AVL��(ƽ����),�����
�������Ľṹ��,����������С�ڸ��ڵ�,������������ڸ��ڵ�,����Ƕ�����Ļ�,������������ġ�
AVL��:��һ���ϸ������ƽ����,�����������������߶�ֻ��ܳ���1,����ڽ���Ԫ�ز����ʱ��,����� 1-N ����ת,�������Ӱ���������ܡ�
�����:�ǻ���AVL����һ������,��ʧ�˲��ֲ�ѯ������,���������������,�ں����������������������֮��,С����������,�ڲ����ʱ��,����Ҫ����N��ε���ת����,���Ҽ����˱�ɫ������,���������Ͳ�ѯ������ƽ��
����������N��ı���,������֧������,ԭ������,�������������,���߲������ݵ����ܱȽϵ�
B��
B�����ص�:
- ���Լ�ֵ�ֲ�����������
- �����п����ڷ�Ҷ�ӽ�����,�ڹؼ�������һ�β���,���ܱƽ����ֲ���
- ÿ���ڵ����ӵ��m������
- ���ڵ�������2������
- ��֧�ڵ�ֻҪӵ��m/2������(�����ڵ��Ҷ�ӽڵ㶼�Ƿ�֧�ڵ�)
- ����Ҷ�ӽڵ㶼��ͬһ�㡢ÿ���ڵ���������m-1��key,��������������
ȱ��:
- ÿ���ڵ㶼��key,ͬʱҲ������data,��ÿ��ҳ�洢�ռ�����,���data�Ƚϴ�Ļ��ᵼ��ÿ���ڵ�洢��key������С
- ����ֵ��������ܴ��ʱ��ᵼ����Ƚϴ�,�����ѯ�Ĵ��̵�io����,����Ӱ���ѯ����
B+��
B+Tree����B Tree�Ļ���֮������һ���Ż�,�仯����:
- B+Treeÿ���ڵ����������Ľڵ�,�������ԭ��������
- Ϊ�˽������ĸ߶�
- �����ݷ�Χ��Ϊ�������,����Խ��,���ݼ���Խ��
- ��Ҷ�ӽڵ�洢key,Ҷ�ӽڵ�洢key������
- Ҷ�ӽڵ�����ָ�������(���ϴ��̵�Ԥ������),˳���ѯ�Ը���
ע��:��B+Tree ��������ͷָ��,һ��ָ����ڵ�,��һ��ָ���ϵ��С��Ҷ�ӽڵ�,��������Ҷ�ӽڵ�(�����ݽڵ�)֮����һ����ʽ���ṹ,��˿��Զ� B+Tree �������ֲ�������
- ���������ķ�Χ���Һͷ�ҳ����
- �Ӹ��ڵ㿪ʼ,�����������
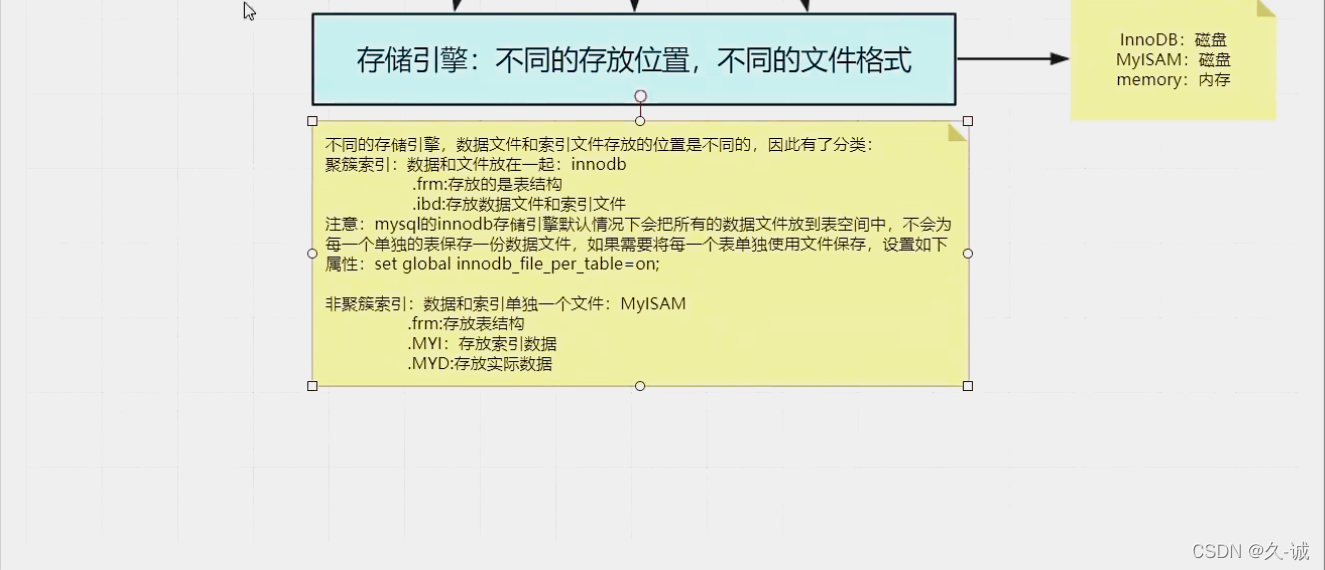
MySql�洢����
mysql InnoDB�CB+Tree
? Ҷ�ӽڵ�ֱ�ӷ������� ���ر���
ע��:
- InnoDB��ͨ��B+Tree�ṹ��������������,Ȼ��Ҷ�ӽڵ�洢��¼,���û������,��ô��ѡ��Ψһ��,���û��Ψһ��,��ô������һ��6λ��row_id����Ϊ����
- ������������������ֶ�,��ô��Ҷ�ӽڵ�洢ʱ�ü�¼������,Ȼ����ͨ�����������ҵ���Ӧ�ļ�¼,�����ر�
���ݽṹѧϰ��վ
https://www.geeksforgeeks.org
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
https://visualgo.net/zh
mysql MyISAM --B+Tree
Ҷ�ӽڵ��ŵĵ�ַ,��Ӧ��data����
�����ķ���
? :����������Ψһ��������ͨ������ȫ���������������
-
��������
�C ������һ��Ψһ������,��������ָ��ΪPRIMARY KEY,ÿ����ֻ����һ��������
-
Ψһ����
�C �����е�����ֵ��ֻ�ܳ���һ��,������Ψһ,ֵ����Ϊ�ա�
-
��ͨ����
�C ��������������,ֵ����Ϊ��,û��Ψһ�Ե����ơ�(��������)
-
ȫ������
�C ȫ����������������ΪFULLTEXT��ȫ������������varchar��char��text���͵����ϴ������������ؼ��֡�
-
�������
�C ����ֵ���һ������,ר�������������(����ƥ��ԭ��)
������
? �����ڲ����µ�ֵ��ʱ��,Ϊ��ά��������������,����Ҫά��, ��ά��������ʱ����Ҫ��Ҫ�����¼������:
�C 1���������һ���Ƚϴ��ֵ,ֱ�Ӳ��뼴��,����û�гɱ�
�C 2�������������м��ijһ��ֵ,��Ҫ�����ƶ�������Ԫ��,�ճ�λ��
�C 3�������Ҫ���������ҳ����,����Ҫ��������һ���µ�����ҳ,Ȼ���� ���������ݹ�ȥ,����ҳ����,��ʱ���ܻ���Ӱ��ͬʱ�ռ��ʹ����Ҳ�ή ��,����ҳ����֮�����ҳ�ϲ�
? ����ʹ������������Ϊ��
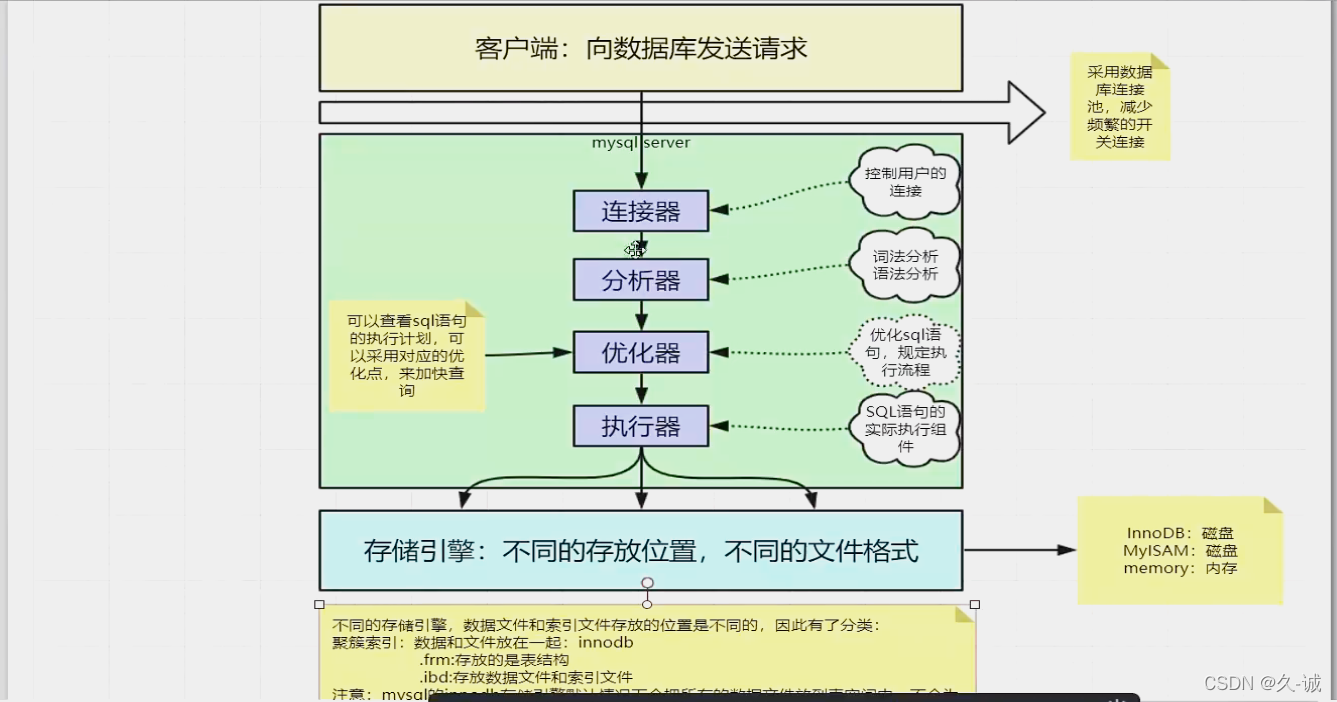
MySQL�ܹ�
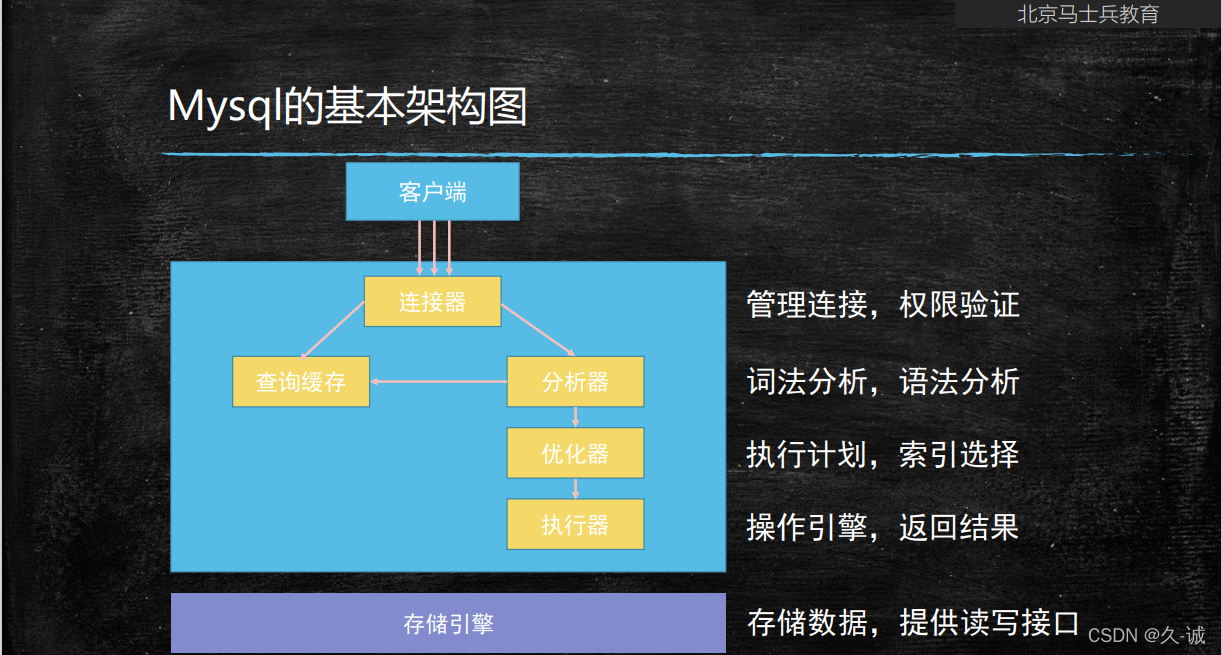
������
? ������������ͻ��˽�������,��ȡȨ�ޡ�ά�ֺ�������
�C �û���������֤
�C ��ѯȨ����Ϣ,�����Ӧ��Ȩ��
�C ����ʹ��show processlist�鿴���ڵ�����
�C ���̫��ʱ��û�ж���,�ͻ��Զ��Ͽ�,ͨ��wait_timeout����,Ĭ��8Сʱ
? ���ӿ��Է�Ϊ����:
�C ������:�Ƽ�ʹ��,����Ҫ�����ԵĶϿ�������
�C ������:
��ѯ����
? ��ִ�в�ѯ����ʱ��,����ȥ��ѯ�����в鿴���,֮ǰִ�� ����sql��估����������key-value����ʽ�洢�ڻ�����,�� �����ҵ���ֱ�ӷ���,����Ҳ���,�ͼ���ִ�к����ĽΡ�
? ? ����,���Ƽ�ʹ�ò�ѯ����:
�C 1����ѯ�����ʧЧ�Ƚ�Ƶ��,ֻҪ������,����ͻ����
�C 2�������Ӧ�¸��µ����������ʱȽϵ�
������
? �ʷ�����:Mysql��Ҫ��������ַ�������ʶ��ÿ�����ִ���ʲ ô��˼
�C ���ַ��� T ʶ��� ���� T
�C ���ַ��� ID ʶ��� ��ID
? �����:
? ����������ж����sql����Ƿ�����mysql���,������� �Ͼͻᱨ����You have an error in your SQL synta��
�Ż���
? �ھ���ִ��SQL���֮ǰ,Ҫ�Ⱦ����Ż����Ĵ���
? �C �������ж��������ʱ��,�������ĸ�����
�C ��sql�����Ҫ�����������ʱ��,������������˳��
? �C �ȵ�
? ��ͬ��ִ�з�ʽ��SQL����ִ��Ч��Ӱ��ܴ�
? �C RBO:���ڹ�����Ż�
? �C CBO:���ڳɱ����Ż�
��־
Redo��־�Cinnodb�洢������־�ļ� ��ǰ����
- �����������ĵ�ʱ��,innodb������Ƚ���¼д��redo log��, �������ڴ�,��ʱ���¾����������,ͬʱinnodb������ں��� ��ʱ������¼������������
- Redolog�ǹ̶���С��,��ѭ��д�Ĺ���
- ����redolog֮��,innodb�Ϳ��Ա�֤��ʹ���ݿⷢ���쳣����, ֮ǰ�ļ�¼Ҳ���ᶪʧ,����crash-safe
Undo log ���ع���
- Undo Log��Ϊ��ʵ�������ԭ����,��MySQL���ݿ�InnoDB�洢������, ����Undo Log��ʵ�ֶ�汾��������(���:MVCC)
- �ڲ����κ�����֮ǰ,���Ƚ����ݱ��ݵ�һ���ط�(����洢���ݱ��ݵĵط� ��ΪUndo Log)��Ȼ��������ݵ��ġ���������˴�������û�ִ���� ROLLBACK���,ϵͳ��������Undo Log�еı��ݽ����ݻָ�������ʼ֮ ǰ��״̬
ע��:undo log������־,��������Ϊ:
? �C ��deleteһ����¼ʱ,undo log�л��¼һ����Ӧ��insert��¼
? �C ��insertһ����¼ʱ,undo log�л��¼һ����Ӧ��delete��¼
? �C ��updateһ����¼ʱ,����¼һ����Ӧ�෴��update��¼
�ع���ԭ��״̬
binlog�C����˵���־�ļ�
�鵵��־,���߶�������־
? Binlog��server�����־,��Ҫ��mysql���ܲ��������
? ��redo��־������:
? �C 1��redo��innodb���е�,binlog���������涼����ʹ�õ�
? �C 2��redo��������־,��¼������ij������ҳ������ʲô��,binlog���� ����־,��¼�����������ԭʼ��
? �C 3��redo��ѭ��д��,�ռ������,binlog�ǿ�����д��,���Ḳ��֮ǰ ����־��Ϣ
- Binlog�л��¼���е���,���Ҳ�����д�ķ�ʽ
- һ������ҵ�����ݿ���б���ϵͳ,���Զ���ִ�б���,���ݵ� ���ڿ����Լ�����
�ָ����ݵĹ���:
- �ҵ����һ�ε�ȫ����������
- �ӱ��ݵ�ʱ��㿪ʼ,�����ݵ�binlogȡ����,�طŵ�Ҫ�ָ����Ǹ�ʱ��
ִ��˳��
- ִ�����ȴ��������ҵ�����,����� �ڴ���ֱ�ӷ���,��������ڴ���,�� ѯ��
- ִ�����õ�����֮�����������, Ȼ���������ӿ�������������
- ���潫���ݸ��µ��ڴ�,ͬʱд���� ��redo��,��ʱ����prepare��,��ͨ ִ֪����ִ�����,��ʱ���Բ���
- ִ�����������������binlog
- ִ������������������ύ�ӿ�,�� ��Ѹո�д���redo�ij�commit״̬, �������
Redo loh �������ύ
? ? ��дredo log��дbinlog:������redo logд��,binlog��û��д���ʱ��,MySQL���� �쳣��������������ǰ��˵����,redo logд��֮��,ϵͳ��ʹ����,��Ȼ�ܹ������ݻָ� ����,���Իָ�����һ��c��ֵ��1����������binlogûд���crash��,��ʱ��binlog���� ��û�м�¼�����䡣���,֮����־��ʱ��,��������binlog�����û��������䡣 Ȼ����ᷢ��,�����Ҫ�����binlog���ָ���ʱ��Ļ�,�����������binlog��ʧ,�� ����ʱ��ͻ�������һ�θ���,�ָ���������һ��c��ֵ����0,��ԭ���ֵ��ͬ��
? ? ��дbinlog��дredo log:�����binlogд��֮��crash,����redo log��ûд,�����ָ� �Ժ����������Ч,������һ��c��ֵ��0������binlog�����Ѿ���¼�ˡ���c��0�ij�1����� ��־������,��֮����binlog���ָ���ʱ��Ͷ���һ���������,�ָ���������һ��c��ֵ ����1,��ԭ���ֵ��ͬ
������־��ʱ��,��������binlog�����û��������䡣 Ȼ����ᷢ��,�����Ҫ�����binlog���ָ���ʱ��Ļ�,�����������binlog��ʧ,�� ����ʱ��ͻ�������һ�θ���,�ָ���������һ��c��ֵ����0,��ԭ���ֵ��ͬ��
? ? ��дbinlog��дredo log:�����binlogд��֮��crash,����redo log��ûд,�����ָ� �Ժ����������Ч,������һ��c��ֵ��0������binlog�����Ѿ���¼�ˡ���c��0�ij�1����� ��־������,��֮����binlog���ָ���ʱ��Ͷ���һ���������,�ָ���������һ��c��ֵ ����1,��ԭ���ֵ��ͬ