Ŀ¼?
һ��hashmap�ײ�ʵ��ԭ��
Hash����һ������+�����Ľṹ,���ֽṹ�ܹ���֤�ڱ�������ɾ�Ĺ�����,���������hash��ײ,����һ�ζ�λ�Ϳ����,ʱ�临�Ӷ��ܱ�֤��O(1)�� ?��jdk1.7��,ֻ�ǵ���������+�����Ľṹ,�������ɢ�б��е�hash��ײ����ʱ,�����Ч�ʵĽ���,������JKD1.8�ж�������������˿���,��һ��hashֵ�ϵ��������ȴ���8ʱ,�ýڵ��ϵ����ݾͲ������������д洢,����ת����һ���������
����:
�µ�Entry�ڵ��ڲ���������ʱ��,����ô�����ô?
java8֮ǰ��ͷ�巨,����˵������ֵ��ȡ��ԭ�е�ֵ,ԭ�е�ֵ��˳�Ƶ�������ȥ
��java8֮��,��������β��������,��Ϊjava8֮�������к�����IJ���,��ҿ��Կ��������Ѿ����˺ܶ�if else�����ж���,���������������Ľ�ԭ��O(n)��ʱ�临�ӶȽ��͵���O(logn)��ʹ��ͷ����ı��������ϵ�˳��,�������ʹ��β��,������ʱ�ᱣ������Ԫ��ԭ����˳��,�Ͳ�����������ɻ��������ˡ�
����˵ԭ����A->B,�����ݺ��Ǹ���������A->B
Java7�ڶ��̲߳���HashMapʱ����������ѭ��,ԭ��������ת�ƺ�ǰ������˳����,��ת�ƹ���������ԭ�������нڵ�����ù�ϵ��
Java8��ͬ����ǰ���²�����������ѭ��,ԭ��������ת�ƺ�ǰ������˳��,����֮ǰ�ڵ�����ù�ϵ��
���Dz�����ζ��Java8�Ϳ���HashMap���ڶ��߳�����?
����Ϊ��ʹ���������ѭ��,����ͨ��Դ�뿴��put/get������û�м�ͬ����,���߳���������׳��ֵľ���:����֤��һ��put��ֵ,��һ��get��ʱ����ԭֵ,�����̰߳�ȫ��������֤��
�����������
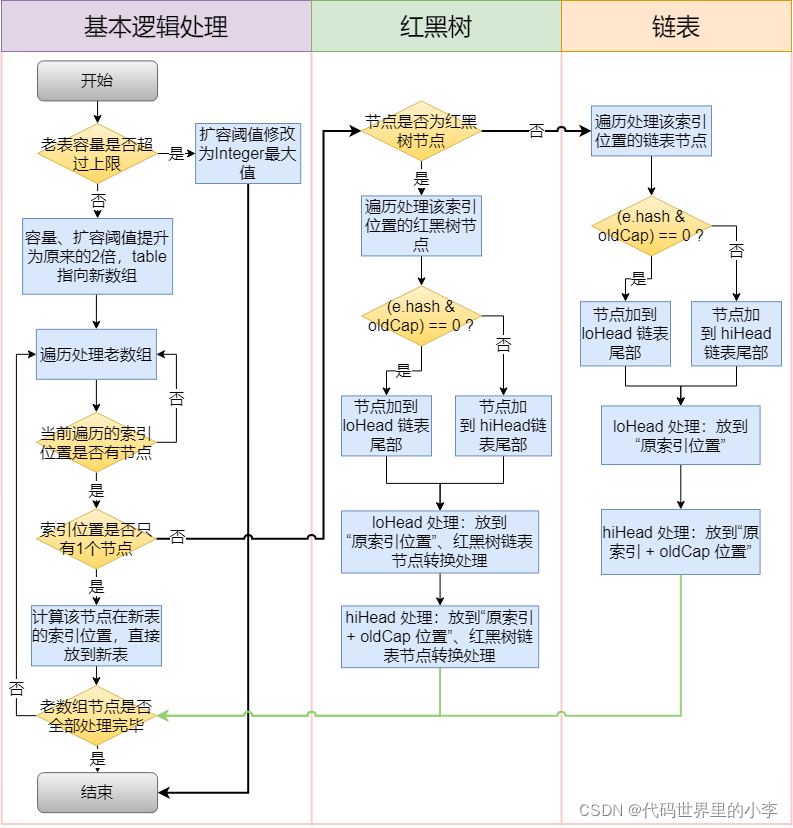
��������������,���ݶ�β����,����һ���������ͻ��������,Ҳ����resize��
Դ������:
final Node<K,V>[] resize() { Node<K,V>[] oldTab = table; int oldCap = (oldTab == null) ? 0 : oldTab.length; int oldThr = threshold; int newCap, newThr = 0; if (oldCap > 0) { if (oldCap >= MAXIMUM_CAPACITY) { threshold = Integer.MAX_VALUE; return oldTab; } else if ((newCap = oldCap << 1) < MAXIMUM_CAPACITY && oldCap >= DEFAULT_INITIAL_CAPACITY) newThr = oldThr << 1; // double threshold } else if (oldThr > 0) // initial capacity was placed in threshold newCap = oldThr; else { // zero initial threshold signifies using defaults newCap = DEFAULT_INITIAL_CAPACITY; newThr = (int)(DEFAULT_LOAD_FACTOR * DEFAULT_INITIAL_CAPACITY); } if (newThr == 0) { float ft = (float)newCap * loadFactor; newThr = (newCap < MAXIMUM_CAPACITY && ft < (float)MAXIMUM_CAPACITY ? (int)ft : Integer.MAX_VALUE); } threshold = newThr; @SuppressWarnings({"rawtypes","unchecked"}) Node<K,V>[] newTab = (Node<K,V>[])new Node[newCap]; table = newTab; if (oldTab != null) { for (int j = 0; j < oldCap; ++j) { Node<K,V> e; if ((e = oldTab[j]) != null) { oldTab[j] = null; if (e.next == null) newTab[e.hash & (newCap - 1)] = e; else if (e instanceof TreeNode) ((TreeNode<K,V>)e).split(this, newTab, j, oldCap); else { // preserve order Node<K,V> loHead = null, loTail = null; Node<K,V> hiHead = null, hiTail = null; Node<K,V> next; do { next = e.next; if ((e.hash & oldCap) == 0) { if (loTail == null) loHead = e; else loTail.next = e; loTail = e; } else { if (hiTail == null) hiHead = e; else hiTail.next = e; hiTail = e; } } while ((e = next) != null); if (loTail != null) { loTail.next = null; newTab[j] = loHead; } if (hiTail != null) { hiTail.next = null; newTab[j + oldCap] = hiHead; } } } } } return newTab; }�����һ����������
? 2.1 ʲôʱ������
������Ҫ����:
? ? Capacity:HashMap��ǰ����
? ? LoadFactory:��������,Ĭ��ֵΪ0.75f
��ô������,�ͱ��統ǰ��������СΪ100,��������76����ʱ��,�жϷ�����Ҫ����resize��,�Ǿͽ�������,����HashMap������Ҳ���Ǽ������������ô��
??2.2 ����
�ٴ���һ���µ�Entry������,������ԭ����2��
��ReHash:����ԭEntry����,�����е�Entry����hash��������
ΪʲôҪ����hash��?
��Ϊ���������,hash�Ĺ���Ҳ����֮�ı�
hash��ʽ����>index=HashCode(key)&(Length-1)
����hash�㷨
��JDK1.8��ʵ����,�Ż��˸�λ������㷨,ͨ��hashCode()�ĸ�16λ����16λʵ�ֵ�:(h = k.hashCode()) ^ (h >>> 16),��Ҫ�Ǵ��ٶȡ���Ч�����������ǵġ����Ϸ����õ���int��hashֵ,Ȼ����ͨ��
h & (table.length -1)���õ��ö����������б����λ�á�hashԴ��:
static final int hash(Object key) { int h; return (key == null) ? 0 : (h = key.hashCode()) ^ (h >>> 16); }?hashMap����֪��Ĭ�ϳ�ʼ������16,Ҳ������16��Ͱ��(�����ڴ���HashMap��ʱ��,����Ͱ淶���������������ø���ֵ,���������2���ݡ�������Ϊ��λ����ķ���,λ����������������Ч�ʸ��˺ܶ�,֮����ѡ��16,��Ϊ�˷���Keyӳ�䵽index���㷨 )
��Ϊɶ��16���ñ����?
��Ϊ��ʹ�ò���2���ݵ����ֵ�ʱ��,Length-1��ֵ�����ж�����λȫΪ1,���������,index�Ľ����ͬ��HashCode��λ��ֵ��
ֻҪ�����HashCode�����ֲ�����,Hash�㷨�Ľ�����Ǿ��ȵġ�
����Ϊ��ʵ�־��ȷֲ���
��hashmap��ͨ��ʲô�������put�����ʱ��÷ŵ��ĸ�Ͱ��
final Node<K,V> getNode(int hash, Object key) { Node<K,V>[] tab; Node<K,V> first, e; int n; K k; if ((tab = table) != null && (n = tab.length) > 0 && (first = tab[(n - 1) & hash]) != null) { if (first.hash == hash && // always check first node ((k = first.key) == key || (key != null && key.equals(k)))) return first; if ((e = first.next) != null) { if (first instanceof TreeNode) return ((TreeNode<K,V>)first).getTreeNode(hash, key); do { if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } while ((e = e.next) != null); } } return null; }��?(n - 1) & hash?Ҳ����˵hashmap��ͨ�����鳤��-1&key��hashֵ������������±��,�����hashֵ��������(h = key.hashCode()) ^ (h >>> 16)���������ֵ
ע:���鳤��-1��^���㡢>>>16,��������������Ϊ����key��hashmap��Ͱ�о����ܷ�ɢ
��&������%��Ϊ�����������1��Ϊʲô���鳤��Ҫ - 1,ֱ�����鳤��&key.hashCode������?
�����±�Խ��
2��ΪʲôҪlength-1&key.hashCode�����±�,��������key.hashCode%length?
�١���ʵ(length-1)&key.hashCode���������ֵ��key.hashCode%length��һ����
�ڡ�ֻ�е�lengthΪ2��n�η�ʱ,(length-1)&key.hashCode�ŵ���key.hashCode%length
�ۡ���&������%��Ϊ�����������,���ڴ���������,&�����Ч���Ǹ���%�����,����ô��,����֮��,������Ч��Ҳû&��
3��ΪʲôҪ����^����,|���㡢&���㲻����?
��������,��һ���������ĵĵ�nλ�ڵڶ����������ĵ�nλ�෴��Ϊ1,����Ϊ0
4��ΪʲôҪ>>>16,>>>15������?
������������16λ,λ������,��λ��0
������˵���� ^ �����е���ѧ,��ʵ>>>16�� ^ �������ศ��ɵĹ�ϵ,��һ�ײ�����Ϊ�˱���hashֵ��16λ�͵�16λ������,��Ϊ���鳤��(��Ĭ�ϵ�16����)��1��Ķ��������16λ��Զ��1111,���ǿ϶�Ҫ�����ܵ���1111��hashֵ������ϵ,���Ǻ���Ȼ,���ֻ��1111&hashֵ�Ļ�,1111ֻ����hashֵ�ĵ���λ������ϵ,Ҳ����˵�����㷨������ֵֻ������hashֵ����λ������,ǰ�滹��28λ������ȫ����ʧ��;
��Ϊ&�����Ƕ�Ϊ1��Ϊ1,1111���ǿ϶��Ǹı䲻�˵�,ֻ�д�hashֵ����,����hashMap���߲����� key.hashCode() ^ (key.hashCode() >>> 16) ���������Ŷ��㷨,key��hashֵ������������16λ,����keyԭ����hashֵ���� ^ ����,���ܺܺõı���hashֵ����������,������ɢЧ��������������Ҫ�ġ�
���������λ���������>>>16�� ^ ����ľ�������,���û����,��������Ϣһ����ٻ�����,��֮��ס,Ŀ�Ķ���Ϊ���������±����ɢ
�ٲ���һ���,��ʵ�����Ƿǵ�����16λ,������ò���,����8λ����12λ�����ܺõ��Ŷ�Ч��,����hashֵ�Ķ���������32λ,����������Ŀ϶����۰뿩
hashcode��equals�Ĺ�ϵ
java��:
? ? ? ? ������������hashcode()���,equals��һ�����
? ? ? ? ������������equals()���,hashcode()�ض����
��дequals()����ʱ,һ��Ҫ��дhashcode,Ϊʲô��?
��������Ѿ���HashMap��ԭ������һ���˽�,�������Ͳ��������ˡ����������ڽ���get��put������ʱ��,ʹ�õ�key�����Ͻ��ǵ�ֵ��(ͨ��equals�Ƚ�����ȵ�),������û����дhashCode����,����put����ʱ,key(hashcode1)�C>hash�C>indexFor�C>��������λ�� ,��ͨ��keyȡ��value��ʱ�� key(hashcode1)�C>hash�C>indexFor�C>��������λ��,����hashcode1������hashcode2,����û�ж�λ��һ������λ�ö��������ϴ����ֵnull(Ҳ�п������ɶ�λ��һ������λ��,����Ҳ���ж���entry��hashֵ�Ƿ����,����get���������ᵽ��)
����,����дequals�ķ�����ʱ��,����ע����дhashCode����,ͬʱ��Ҫ��֤ͨ��equals�ж���ȵ���������,����hashCode����Ҫ����ͬ��������ֵ�������equals�жϲ���ȵ���������,��hashCode������ͬ(ֻ�����ᷢ����ϣ��ͻ,Ӧ��������)��
�ġ�hashmap��put��get����
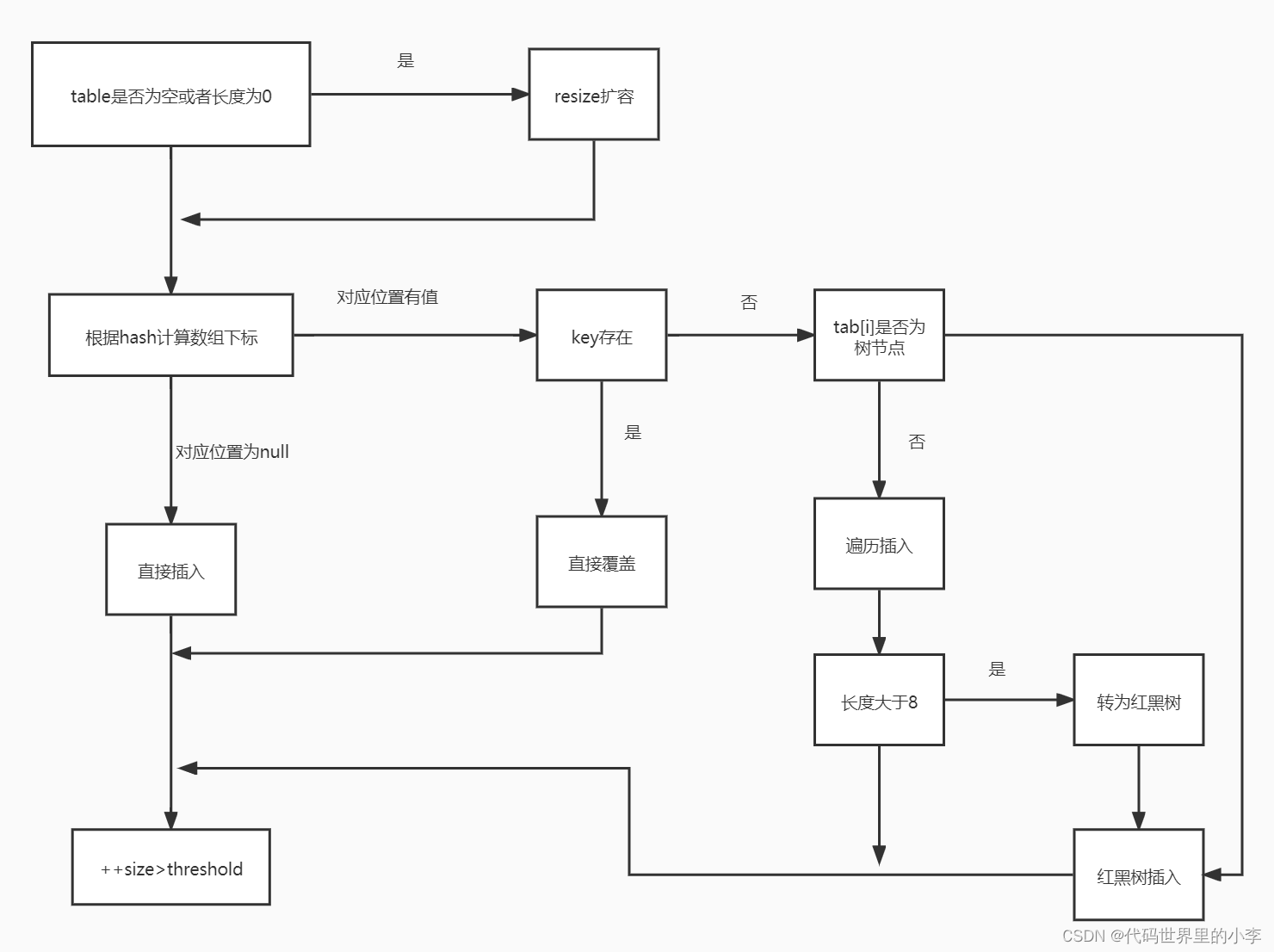
JDK7��HashMap���õ���λͰ+�����ķ�ʽ,�����dz�˵��ɢ�������ķ�ʽ,��JDK8�в��õ���λͰ+����/�����,���イ���� JDK8�е�put������
hashmap-putԴ��:
public V put(K key, V value) { return putVal(hash(key), key, value, false, true); } final V putVal(int hash, K key, V value, boolean onlyIfAbsent, boolean evict) { Node<K,V>[] tab; Node<K,V> p; int n, i; if ((tab = table) == null || (n = tab.length) == 0) n = (tab = resize()).length; if ((p = tab[i = (n - 1) & hash]) == null) tab[i] = newNode(hash, key, value, null); else { Node<K,V> e; K k; if (p.hash == hash && ((k = p.key) == key || (key != null && key.equals(k)))) e = p; else if (p instanceof TreeNode) e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value); else { for (int binCount = 0; ; ++binCount) { if ((e = p.next) == null) { p.next = newNode(hash, key, value, null); if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st treeifyBin(tab, hash); break; } if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) break; p = e; } } if (e != null) { // existing mapping for key V oldValue = e.value; if (!onlyIfAbsent || oldValue == null) e.value = value; afterNodeAccess(e); return oldValue; } } ++modCount; if (++size > threshold) resize(); afterNodeInsertion(evict); return null; }HashMap��put������,��ʹ��hashCode()��equals()������������ͨ������key-value�Ե���put������ʱ��,HashMapʹ��Key hashCode()��ϣ�㷨���ҳ��洢key-value�Ե����������������Ϊ��,��ֱ�Ӳ��뵽��Ӧ��������,����,�ж��Ƿ��Ǻ����,����,����������,�����������,�����Ȳ�С��8,������תΪ�����,ת�ɹ�֮�� �ٲ��롣
?hashmap-get����Դ��:
public V get(Object key) { �������� //���keyΪnull,��ֱ��ȥtable[0]��ȥ�������ɡ� if (key == null) return getForNullKey(); Entry<K,V> entry = getEntry(key); return null == entry ? null : entry.getValue(); }get����ͨ��keyֵ���ض�Ӧvalue,���keyΪnull,ֱ��ȥtable[0]�������������ٿ�һ��getEntry�������
final Entry<K,V> getEntry(Object key) { if (size == 0) { return null; } //ͨ��key��hashcodeֵ����hashֵ int hash = (key == null) ? 0 : hash(key); //indexFor (hash&length-1) ��ȡ������������,Ȼ���������,ͨ��equals�����ȶ��ҳ���Ӧ��¼ for (Entry<K,V> e = table[indexFor(hash, table.length)]; e != null; e = e.next) { Object k; if (e.hash == hash && ((k = e.key) == key || (key != null && key.equals(k)))) return e; } return null; }���Կ���,get������ʵ����Լ�,key(hashcode)-->hash-->indexFor-->��������λ��,�ҵ���Ӧλ��table[i],�ٲ鿴�Ƿ�������,��������,ͨ��key��equals�����ȶԲ��Ҷ�Ӧ�ļ�¼��Ҫע�����,���˾��������ڶ�λ������λ��֮��Ȼ�����������ʱ��,e.hash == hash����ж�û��Ҫ,��ͨ��equals�жϾͿ��ԡ���ʵ��Ȼ,����һ��,��������key������д��equals����ȴû����дhashCode,��ǡ�ɴ˶���λ���������λ��,���������equals�жϿ�������ȵ�,����hashCode�͵�ǰ����һ��,�������,����Object��hashCode��Լ��,���ܷ��ص�ǰ����,��Ӧ�÷���null��
�塢hashmap��hashtable������
�� ���ߵĴ洢�ṹ�ͽ����ͻ�ķ���������ͬ�ġ�
�� HashTable�ڲ�ָ������������µ�Ĭ������Ϊ11,��HashMapΪ16,Hashtable��Ҫ��ײ����������һ��ҪΪ2����������,��HashMap��Ҫ��һ��Ϊ2���������ݡ�
�� HashTable �� key�� value��������Ϊ null,��HashMap��key��value������Ϊ null(keyֻ����һ��Ϊnull,��value������ж��Ϊ null)����������� Hashtable�������� put( null, null)�IJ���,����ͬ������ͨ��,��Ϊ key�� value����Object����,������ʱ���׳� NullPointerException�쳣��
�� Hashtable����ʱ,��������Ϊԭ����2��+1,��HashMap����ʱ,��������Ϊԭ����2����
�� Hashtable����hashֵ,ֱ����key��hashCode(),��HashMap���¼�����key��hashֵ,Hashtable�ڼ���hashֵ��Ӧ��λ������ʱ,�� %����,�� HashMap����λ������ʱ,���� &����
�ܽ�
HashMapԴ����,ÿһ�ж�������˼,��ֵ�û�ʱ��ȥ���С����á�
ͨ�������ײ��Դ�����ڽ������д����ز���,���Ŵ�Ҷ��������ջ�
�������Ҹ����ڵ�һ��ѧϰ�ʼ�,���в���,��ӭ����......
����˵:����֪����Խ��,��֪����Խ�ࡱ
����:�������������