һ.��������
1.ʲô������
????????������Ϊ�˼��ٶԱ������ݼ��ټ�����һ�ַ�ɢ�洢�����ݽṹ,ּ�������з��ز��ҵ����ݻ���ָ�����ݵ�ָ��.ͨ˵������:�����ͺñ�һ�����Ŀ¼,�������������ҵ��Լ���Ҫ������,�û�ȡ�����ݸ���Ŀ����,�Ӷ�������ݿ�������ݵ�����

?���ϱ���,���û������,����ͨ��select * from user where id = 40��Ҫ����ȫ��ɨ��,���������,����ֻ��Ҫ���ϱ����ж��ֲ���,���ҵ�������Ӧ��������
2.��������
��������:��һ������ֻ����������,һ���������ж����������
�������:��һ�������������
��ͨ����,Ψһ����,��������,�������,ǰ����?
2.1 ��ͨ����
���������������,��û���κ�����,�����¼��ַ�ʽ����:
// 1.��������
CREATE INDEX indexName ON mytable(username(length));
//�����CHAR,VARCHAR����,length����С���ֶ�ʵ�ʳ���;�����BLOB��TEXT����,����ָ��length,��ͬ
//2.�ı��ṹ
ALTER mytable ADD INDEX [indexName] ON (username(length)); //��������ʱ��ֱ��ָ��
CREATE TABLE mytable(
ID INT NOT NULL,???
username VARCHAR(16) NOT NULL,??
INDEX [indexName] (username(length))??
);
//ɾ������
DROP INDEX [indexName] ON mytable;2.2 Ψһ����
����ǰ�����ͨ��������,��ͬ�ľ���:�����е�ֵ����Ψһ,�������п�ֵ��������������,����ֵ����ϱ���Ψһ�������¼��ַ�ʽ����:
//����
CREATE UNIQUE INDEX indexName ON mytable(username(length))
//�ı��ṹ
ALTER mytable ADD UNIQUE [indexName] ON (username(length))
//��������ʱ��ֱ��ָ��
CREATE TABLE mytable(??
ID INT NOT NULL,???
username VARCHAR(16) NOT NULL,??
UNIQUE [indexName] (username(length))??
);2.3��������
����һ�������Ψһ����,�������п�ֵ��һ�����ڽ�����ʱ��ͬʱ������������,��������:
CREATE TABLE mytable(??
ID INT NOT NULL,???
username VARCHAR(16) NOT NULL,??
PRIMARY KEY(ID)??
);
// ��ȻҲ������ ALTER �����ס:һ����ֻ����һ������2.4�������
Ϊ������ضԱȵ����������������,Ϊ�����Ӷ���ֶ�,��������:
//1.������
CREATE TABLE mytable(??
ID INT NOT NULL,???
username VARCHAR(16) NOT NULL,??
city VARCHAR(50) NOT NULL,??
age INT NOT NULL?
);
//2.Ϊ�˽�һ��եȡMySQLЧ��,��Ҫ���ǽ���������������ǽ� name, city, age����һ��������,��������:
ALTER TABLE mytable ADD INDEX name_city_age (name(10),city,age);2.5ǰ����?
�����ֶε�ǰN���ַ���������,��������:
#����ǰ����
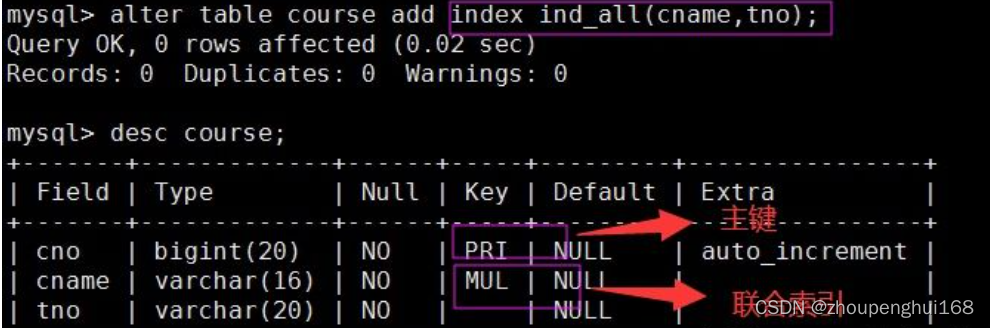
mysql> alter table student2 add index idx_sname2(sname(3));3.�鿴���������ַ�ʽ?
#�鿴�������ַ�ʽ
mysql> desc student4;
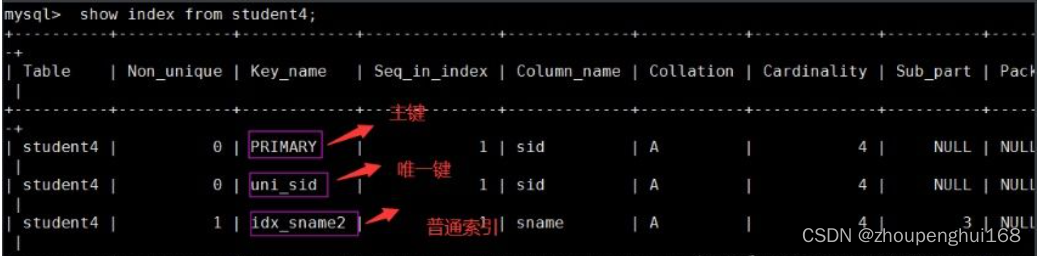
mysql> show index from student4;
mysql> show create table student4;
 ?
? ?
? ?4.���������ܽ�
?4.���������ܽ�
????????4.1.��Ҫ�������ֶ��϶���������
????????4.2.����������ֶαȽ϶�,ѡ����������
????????4.3.����������ֶ����ݱȽϴ�,ѡ��ǰ����
????????4.4.������Դ���Ψһ����,һ������Ψһ����
5.ʲô�����������,���ò���
����������ʱʱ������Ч��,�������¼������,����������ʧЧ:
5.1.�����������or,��ʹ�����в�������������Ҳ����ʹ��(��Ҳ��Ϊʲô��������or��ԭ��),
ע��:Ҫ��ʹ��or,������������Ч,ֻ�ܽ�or�����е�ÿ���ж���������
5.2.���ڶ�������,����ʹ�õĵ�һ����,��ʹ������
5.3.like��ѯ����%��ͷ,����������Ч
5.4.���������е�������������ת��,���ò�������,�������������ַ���,��һ��Ҫ�������н�����ʹ��������������,����ʹ������
5.5. where �Ӿ����������������ѧ����,�ò�������
5.6. where �Ӿ������������ʹ�ú���,�ò�������
5.7.���mysql����ʹ��ȫ��ɨ��Ҫ��ʹ��������,��ʹ������:�������������ٵı�
6.ʲô����²��Ƽ�ʹ������
6.1 ����Ψһ�Բ�(һ���ֶε�ȡֵֻ�м���ʱ)���ֶβ�Ҫʹ������:
????????�����Ա�,ֻ�����ֿ�������,��ζ�������Ķ�����������,����ƽ��,�����Ķ���������������ȫ��ɨ�衣
6.2 Ƶ�����µ��ֶβ�Ҫʹ������:
????????����logincount��¼����,Ƶ���仯��������ҲƵ���仯,�������ݿ����,����Ч�ʡ�
6.3 �ֶβ���where������ʱ��Ҫ��������,���where��IS NULL /IS NOT NULL/ like ��%�����%��������,������ʹ������; ֻ����where������,mysql�Ż�ȥʹ������
6.4 where �Ӿ����������ʹ�ò�����(<>),ʹ������Ч��һ��
��.��������mysql B+tree��������
Mysql���ݿ�ΪʲôҪʹ��B+Tree��Ϊ���������ݽṹ?
1.������Ϊʲô������?
����������Ԫ�صĸ��Ӷ�ΪO(log2n)
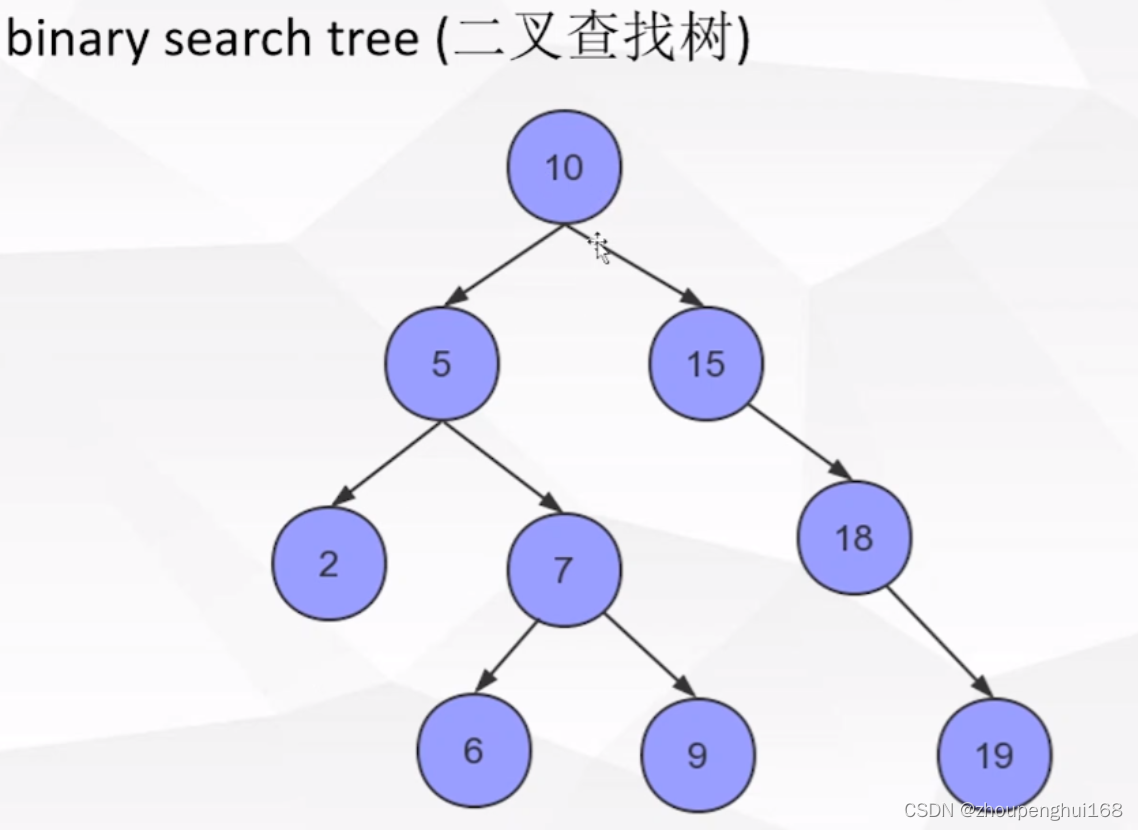
�����������൱��һ�����ֲ��ҷ�,�������7,7С��10,��ƥ����ڵ�����ӽڵ�,7����5,ƥ��5�ڵ�����ӽڵ�,7����,�������ڳ���һ������,�ڶ���ID�����ı���,����������Ϊ����ͼ��ʾ,����һ����������,����ѯ�ڵ�Ϊ4��ʱ��,������ȫ��ɨ�衣���ڸ�����Ĵ���,���Զ�����������ʺ���Ϊ���������ݽṹ
?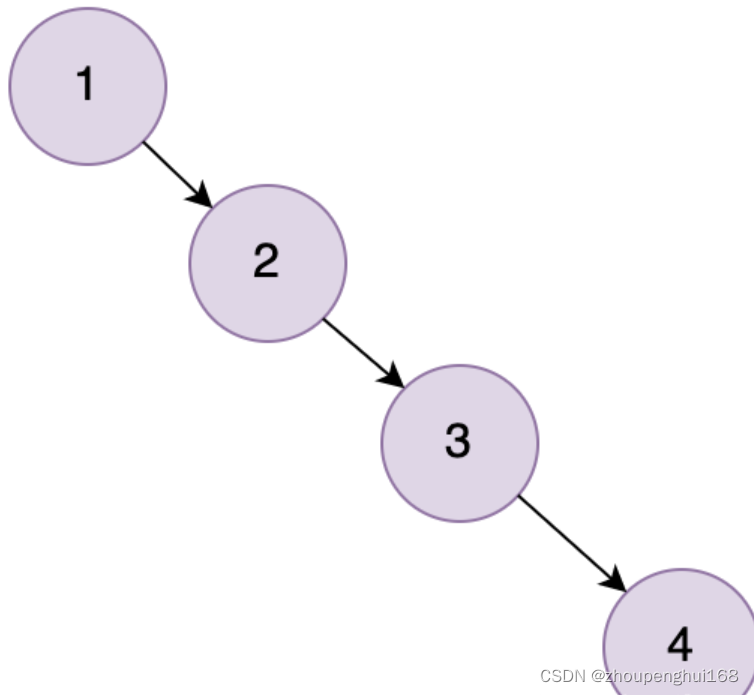
2.ƽ�����������ΪʲôҲ������?
Ϊ�˽��������������������(������ȫ��ɨ��)������,���ܻ�����ƽ�������������������,����ͼ: �ڵ���ӽڵ�߶Ȳ�ܳ���1,����ͼ�е�20�ڵ�,���ӽڵ�߶�Ϊ1,���ӽڵ�߶�Ϊ0,�ӽڵ�߶Ȳ�Ϊ1,����?����ƽ�����������Ĺ���
���������������������ݵķ�ʽ������:
????????1.����������id ��Ӧ�����ݵ���������
????????2.������������������ݵĴ��̵�ַ
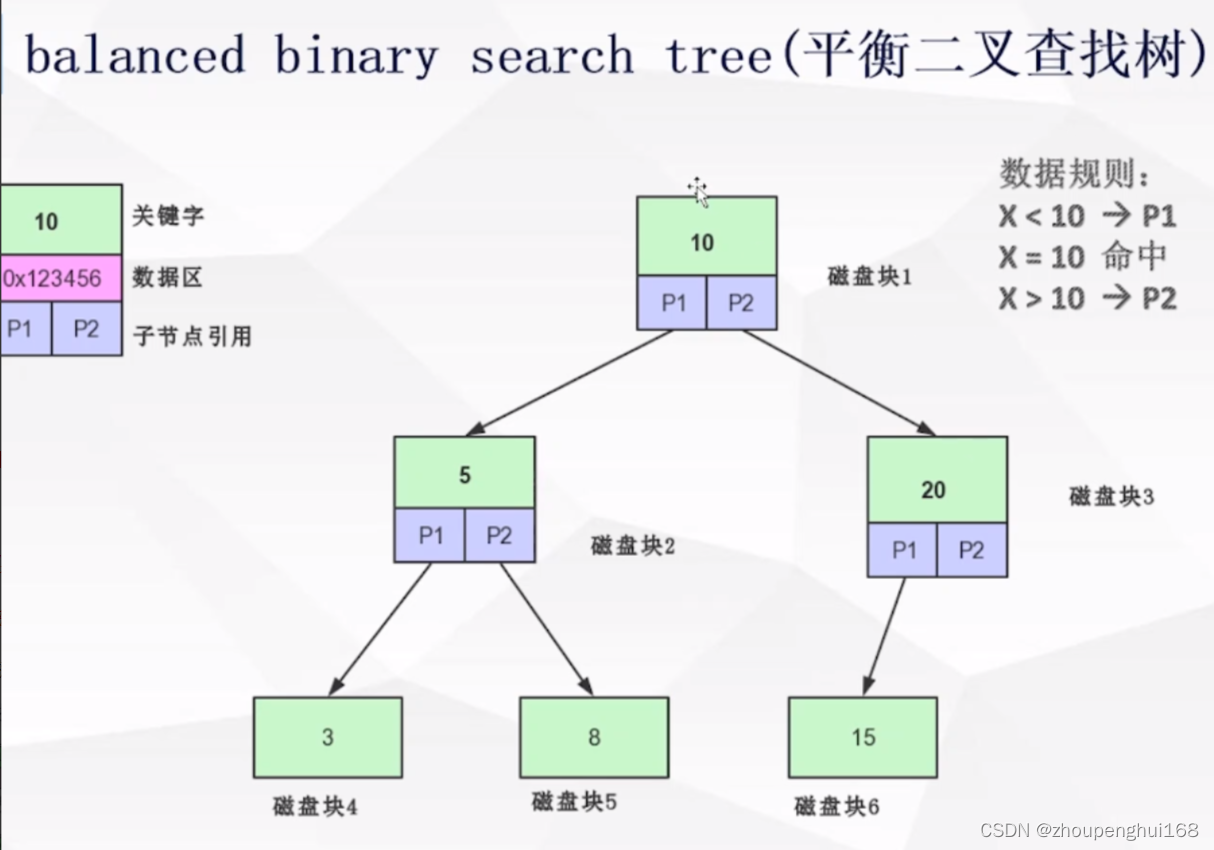
������ͼ�洢����id����,��id=8�����ݽ�������:
????????1. �Ѹ��ڵ���ؽ��ڴ�,8С��10,���ظ��ڵ�������� ?
???????? 2. ��5���ؽ��ڴ�,8����5,����5�ڵ�������� ?
???????? 3. ��ʱ����id����,����Ӧ������������
ƽ��������IJ���Ч��Ҳ�ܴﵽO(log2n),���Ҳ������������������,��ôΪʲô��ʹ��ƽ���������Ϊ�洢���������ݽṹ��?
-
����Ч�ʲ���:�����ṹ��,�������������,����������ʱ��IO���(Mysql��ÿ���ڵ�����Ϊһҳ��С,һ��IO��ȡһҳ/һ���ڵ�),����ͼ�����ڵ�8������,��Ҫ����3��IO,����������ܴ�,���㹻��,��ô������Ч��Ҳ�ͷdz�����
-
��ѯ���ȶ�:���ڸ��ڵ�,ֻ��Ҫ1��IO���ɲ鵽,����Ҷ�ӽڵ��֧�ڵ�,����Ҫ���IO�����ܲ�ѯ9��10�ڵ������ѵ�ʱ������ܶ�,��������
-
�ڵ�洢����������̫��:����ϵͳ�ʹ���֮��һ�����ݽ�������ҳ(������Ϊһ���ڵ�)Ϊ��λ��,һҳ��СΪ4k,��ÿ��IO�����Ὣ4K���ݼ��ؽ��ڴ��С����ڶ�������ÿ���ڵ�ֻ����һ���ؼ���,һ��������,�����ӽڵ������,����������4k�Ĵ�С,����ÿ��IO����ֻ������һ���ؼ���,�������㹻��,�������Ľڵ���ǡ��λ��Ҷ�ӽڵ����֧�ڵ�,��ôIO�Ĵ���Ҳ��������(IO�����ڼ�������Ƿdz��ķ�ʱ���)
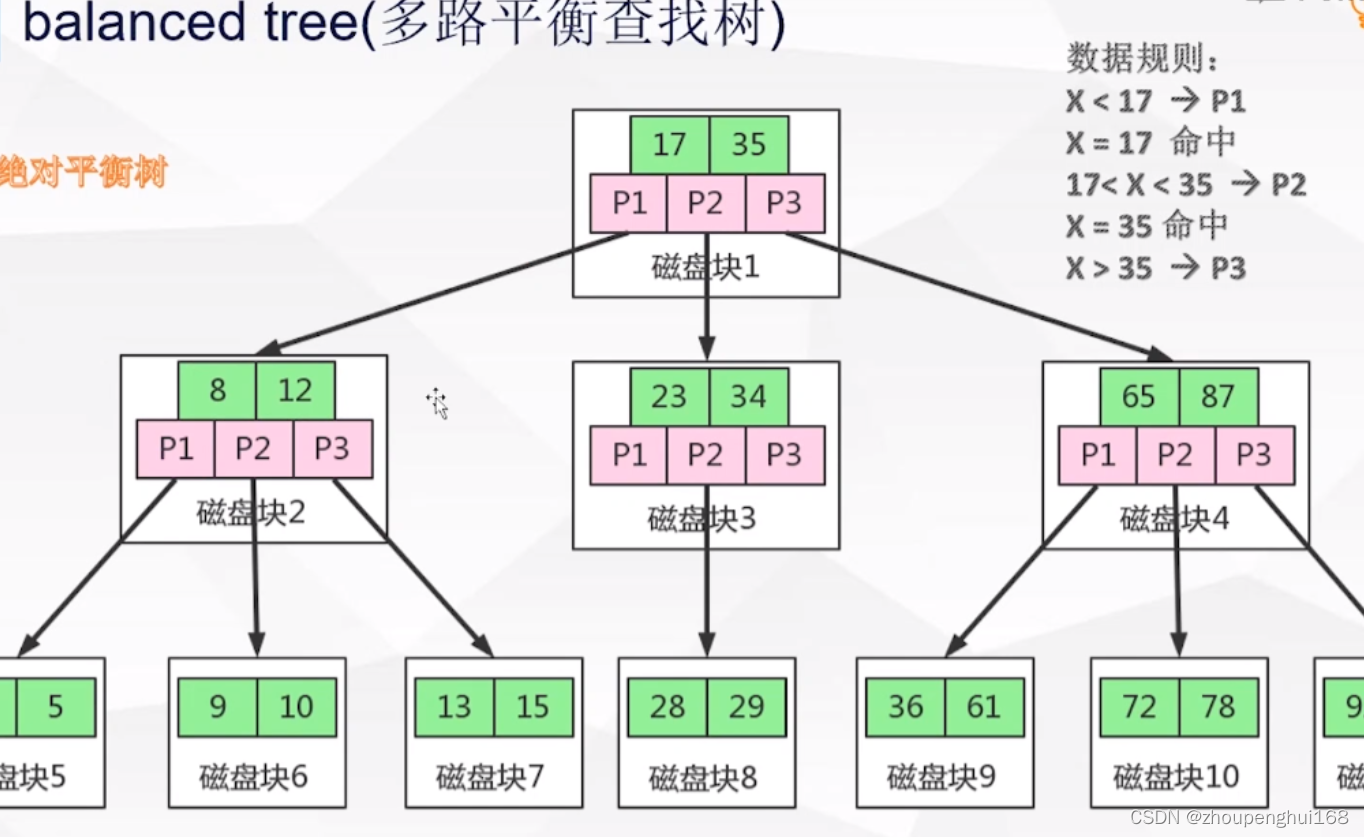
3.B tree(��·ƽ�������)
B Tree��һ������ƽ����,������Ҷ�ӽڵ㶼��ͬһ�߶�
 ?
?
��ͼΪһ��2-3��(ÿ���ڵ�洢2���ؼ���,��3·),��·ƽ�������Ҳ���Ƕ�����˼,����ͼ�п��Կ���,ÿ���ڵ㱣��Ĺؼ��ֵĸ�����·����ϵΪ:�ؼ��ָ��� = ·�� �C 1��
�������ͼȡ��id = X������,������������:
1.ȡ�������̿�,����40��60�������ݿ�
2.���X=40,������,���X<40,����P1;���40<X<60,����P2;���X>60,����P3
3.�������Ϲ������к�,������������Ӧ������,�������д洢���Ǿ�������ݻ�����ָ�����ݵ�ָ��
Ϊʲô˵BTree�����ƽ�������������?
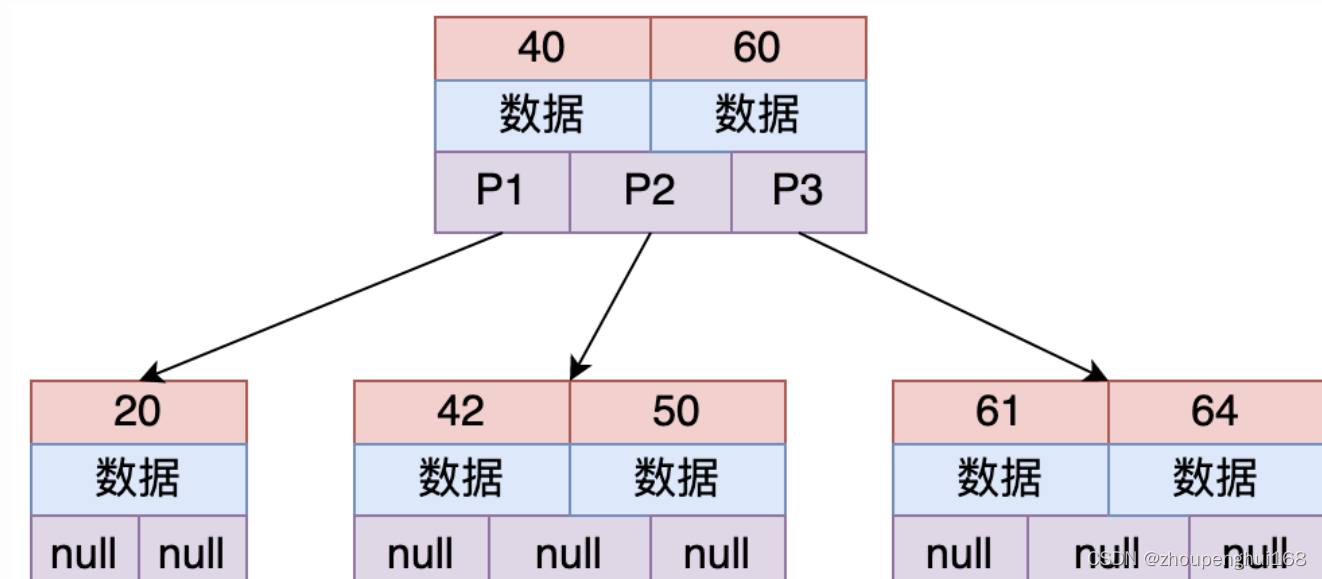
��:B Tree�ܹ��ܺõ����ò���ϵͳ�ʹ��̵Ľ�������,Mysql���ô��̵�Ԥ������,��һҳ��С����Ϊ16k,����һ���ڵ�Ĵ�С����Ϊ16k,һ��IO��һ���ڵ���ؽ��ڴ��С�����ؼ�������Ϊint,��4�ֽ�,�ڲ������ӽڵ����õ������,����ͼ��ÿ���ڵ��Լ���Դ洢(16*1024)/8=2000���ؼ���,·��Ϊ2001�������ڶ�����,3��߶�,���ֻ�ܱ���7���ؼ���,����B������,3��߶ȿ��Դ洢Լ2000���ؼ���,�ɼ�һ��
ע���:
��B Tree��֤����ƽ�������,ÿ�ιؼ��ֵı仯, ���ᵼ�����ṹ�����仯�������ڴ���������ʱ��Ҫ�����������,�����ǰ������ֶζ���������,������������ֻ��� �����ڽ�����ɾ�ĵ�ʱ�����������ϵ�����
B��ȷʵ�Ѿ��ܺõĽ��������,���������ȼ�����һ��B+Tree�ṹ,��������BTree��B+Tree������
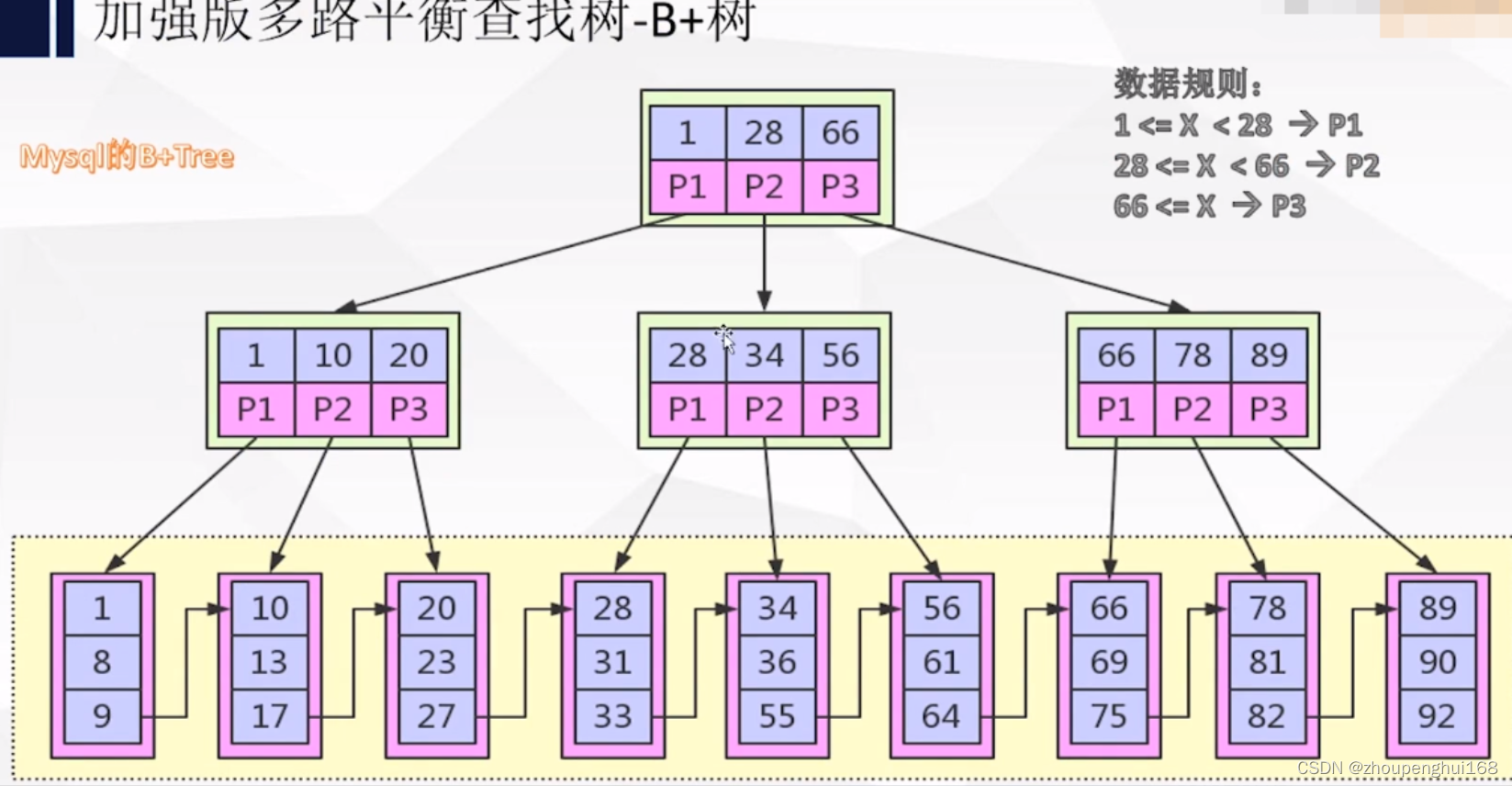
�ȿ���B+Tree��������,B+Tree��B Tree��һ������,��B+Tree��,B����·���ؼ��ֵĸ����Ĺ�ϵ���ٳ�����,���ݼ���������õ�����պ�����,·���ؼ�������ϵΪ1��1,��������ͼ��ʾ:
?
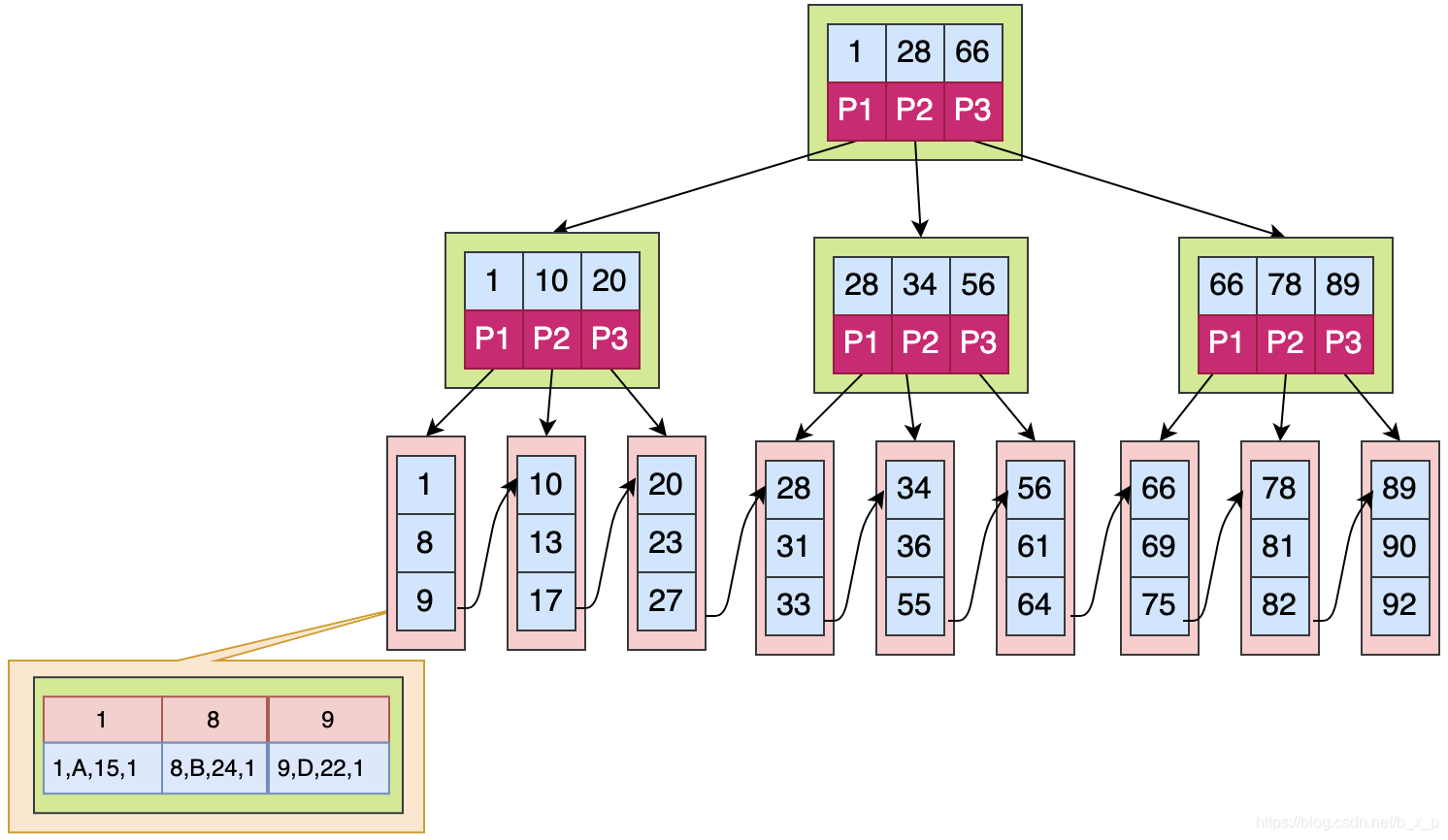
����Ѱ��id=1������:��
1.ȡ�������̿�,����1,28,66�����ؼ���
2.X<=1��P1,����1,10,20�����ؼ���
3.X<=1��P1,����1,8,9�����ؼ���
4.�Ѿ�����Ҷ�ӽڵ�,����1,���������ض�Ӧ������,ͼ��Ҷ�ӽڵ��Ӧ�Ĵ��̿�洢���Ǿ�������
3.1 B Tree��B+ Tree������ʲô?
1.B+ Tree�ؼ��ֵ��������õ�����պ�����,ԭ����Ҫ���õ�֧��id����
2.B+ Tree �и��ڵ��֧�ڵ���û��������,�ؼ��ֶ�Ӧ��������ֻ������Ҷ�ӽڵ���;����B Tree��,����ڷ�Ҷ�ӽڵ�������,��?��ֱ�ӷ�������
3.��B+ Tree��,Ҷ�ӽڵ㲻�ᱣ���ӽڵ������
4.B+ Tree��,Ҷ�ӽڵ���˳�����е�,Ҷ�ӽڵ���ָ�����õĹ�ϵ
3.2 MysqlΪʲô����Ҫѡ��B+ Tree?
1.B Tree�ܽ��������,B+ TreeҲ�ܽ��,�����ܸ��õ�֧��ID����,�������ĸ߶�,����ڵ�洢�ؼ�������
2.B+ Treeɨ��ɨ��������ǿ:����B+ Treeֻ��Ҫ��������Ҷ�ӽڵ㼴��(���ݶ���Ҷ�ӽڵ���,Ҷ�ӽڵ��������);����B Tree��?Ҫ����������
3.B+ Tree���̶�д������ǿ:B+ Tree�ĸ��ڵ��֧�ڵ㲻��������,���Խڵ㱣��Ĺؼ�������Ҫ��B Tree��Ķ�;����Ҷ�ӽڵ㲻?�����ӽڵ������,�����ڱ������Ĺؼ��ֺ�����
4.B+ Tree֧����Ȼ������
5.B+ Tree��ѯ�����ȶ�:ÿ�β�ѯ���ݶ��ᵽҶ�ӽڵ���ȥ����
4.Mysql ��B+ Tree���������ʽ
����B+Tree�����ṹ��ͬ�����ִ洢����(MYISAM �� INNODB)��ʵ��B+ Tree:
MYISAM�洢����洢���ݿ�����,һ���������ļ�:?Frm:���Ķ����ļ�; MYD:�����ļ�,���е����ݱ���������ļ���; MYI:�����ļ���
Innodb�洢����洢���ݿ�����,һ���������ļ�(û��ר�ű������ݵ��ļ�):???Frm�ļ�: ���Ķ����ļ�; Ibd�ļ�:���ݺ������洢�ļ�,�������������оۼ��洢,�����������ݱ�����Ҷ�ӽڵ���
4.1MyISAM�洢����
���ݺ������Ĺ�ϵ����: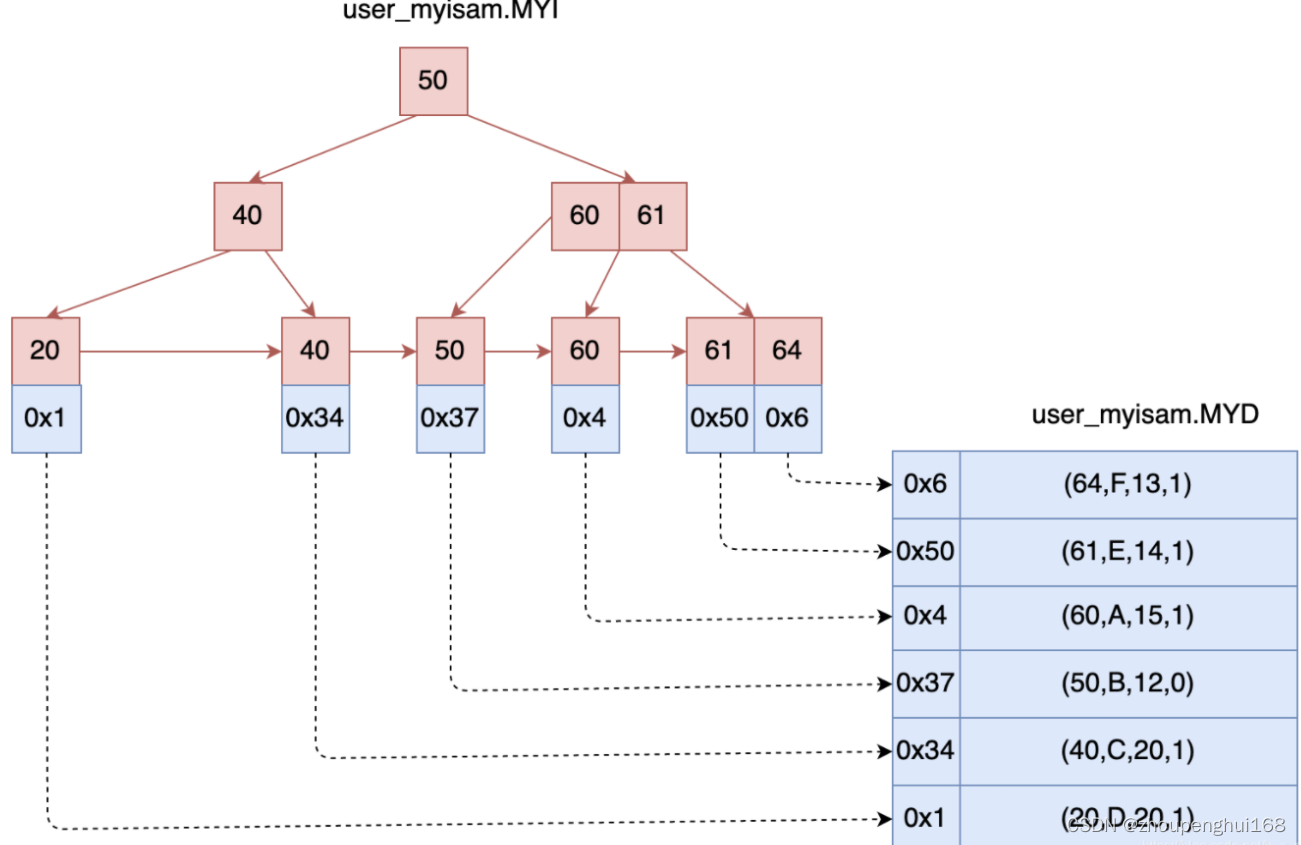
��β������ݵ���??���Ҫ��ѯid = 40������:�ȸ���MyISAM�����ļ�(����ͼ��)ȥ��id = 40�Ľڵ�,ͨ������ڵ���������õ������������ݵĴ��̵�ַ,��ͨ�������ַ��MYD�����ļ�(����ͼ��)�м��ض�Ӧ�ļ�¼��
����ж������,������ʽ����: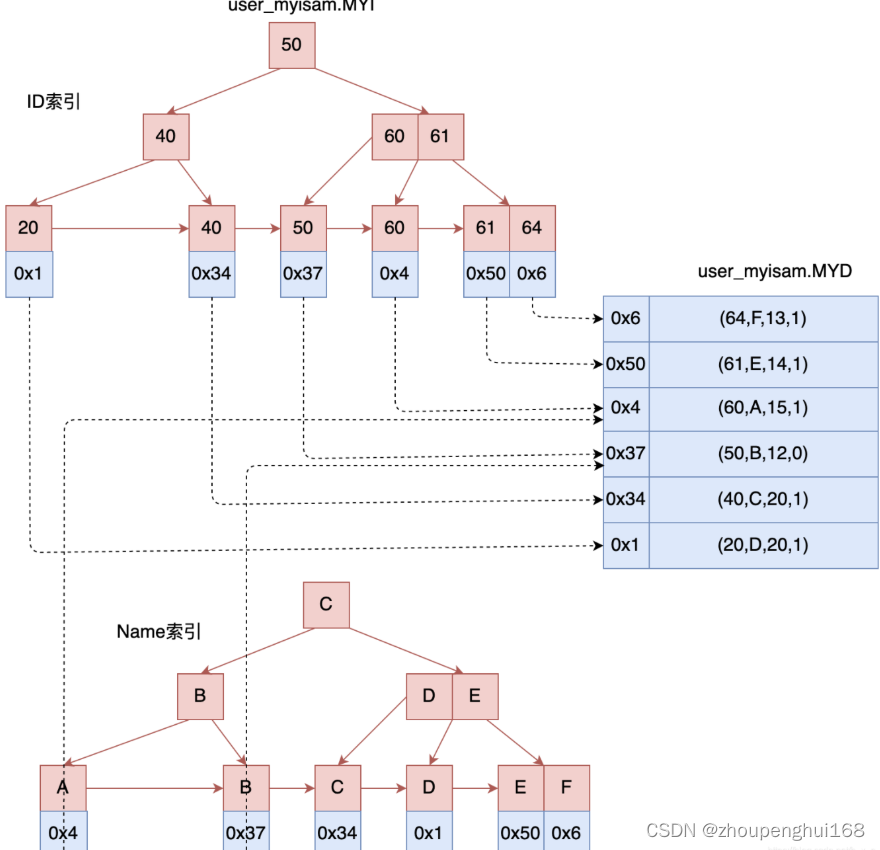
4.2Innodb�洢����?
Innodb��������Ϊ�ۼ�����,����:���ݿ���������ݵ�����˳��ͼ�ֵ����˳����ͬ
-
�۴�����:�����ݴ洢�������ŵ���һ��,�ҵ�����Ҳ���ҵ�������
-
�Ǿ۴�����:�����ݴ洢�������ֿ��ṹ,�����ṹ��Ҷ�ӽڵ�ָ�������ݵĶ�Ӧ��,myisamͨ��key_buffer�������Ȼ��浽�ڴ���,����Ҫ��������ʱ(ͨ��������������),���ڴ���ֱ����������,Ȼ��ͨ�������ҵ�������Ӧ����,��Ҳ����Ϊʲô��������key buffer����ʱ,�ٶ�����ԭ��
Innodb�������������ۼ���֯���ݵĴ洢,���濴��Innodb�������֯���ݵ�
?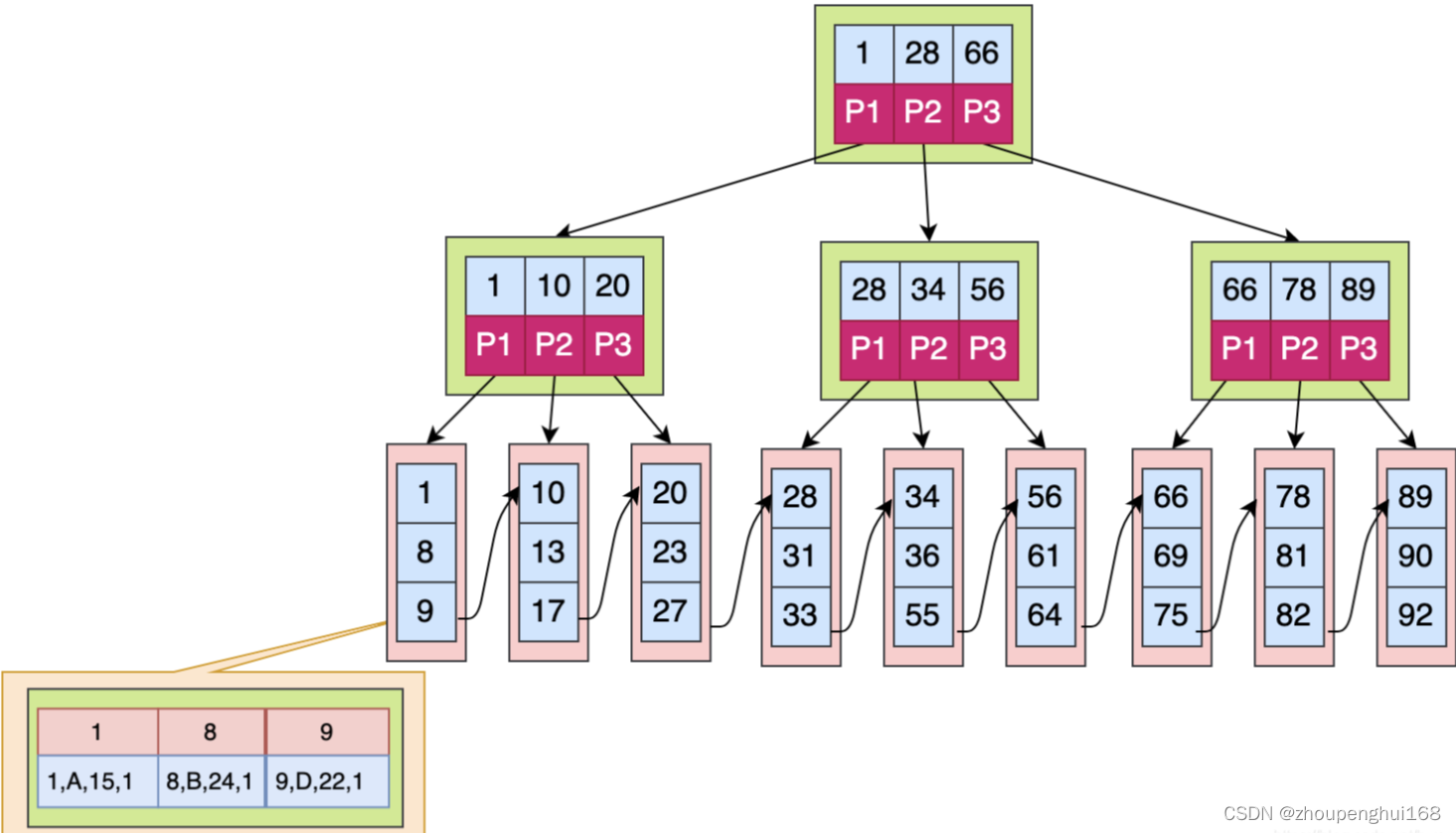
����ͼ��,Ҷ�ӽڵ������������ľ�����ʵ������,��ͨ���������м�����ʱ��,����Ҷ�ӽڵ�,�Ϳ���ֱ�Ӵ�Ҷ�ӽڵ���ȡ�������ݡ�mysql5.5�汾֮ǰĬ�ϲ��õ���MyISAM����,5.5֮��Ĭ�ϲ��õ���innodb���档
��innodb��,���������ĸ�ʽ����ͼ��ʾ?
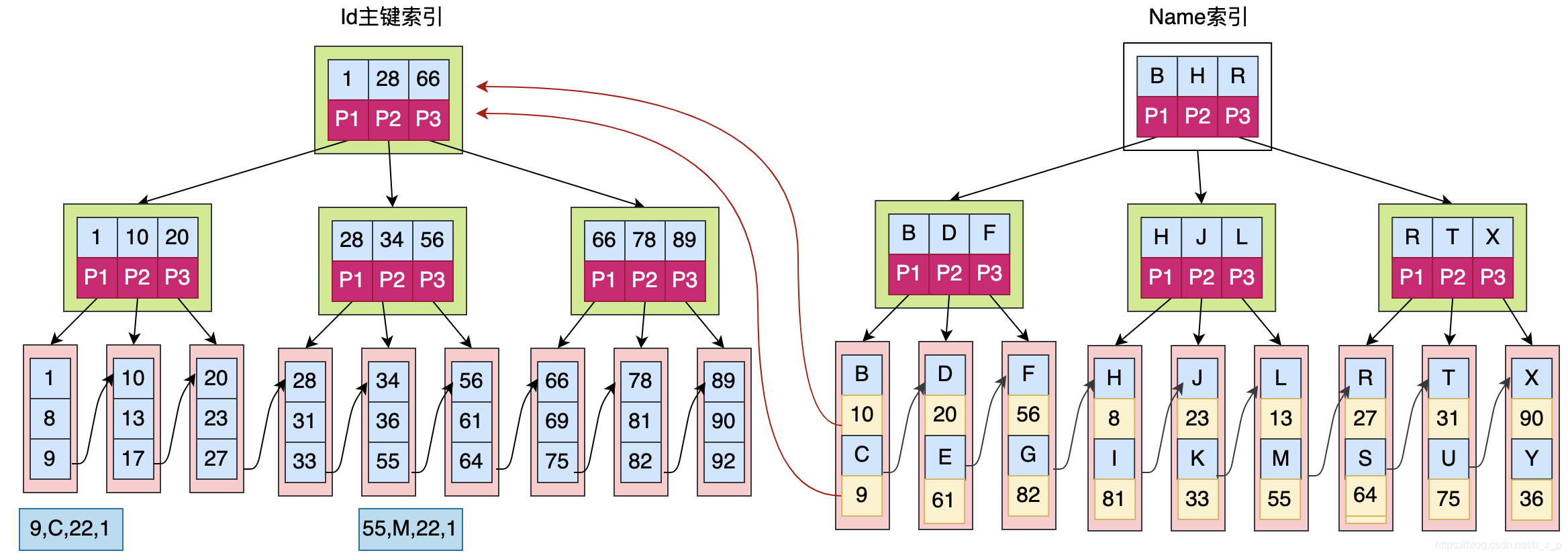
����ͼ,����������Ҷ�ӽڵ㱣��������������ݡ�����������Ҷ�ӽڵ������������������������ؼ��ֵ�ֵ��
����Ҫ��ѯname = C ������,��������������:
1.���ڸ���������ͨ��C��ѯ����ҵ�����id = 9.???2.����������������idΪ9������,����������������Ҷ�ӽڵ��л�ȡ�����������ݡ�??
����ͨ�������������м���,��Ҫ��������������֮�����������,һ��ԭ�����:�����MyISAMһ����������������������Ҷ�ӽڵ��ж����������ָ��,һ�����ݷ���Ǩ��,����Ҫȥ������֯ά�����е�������
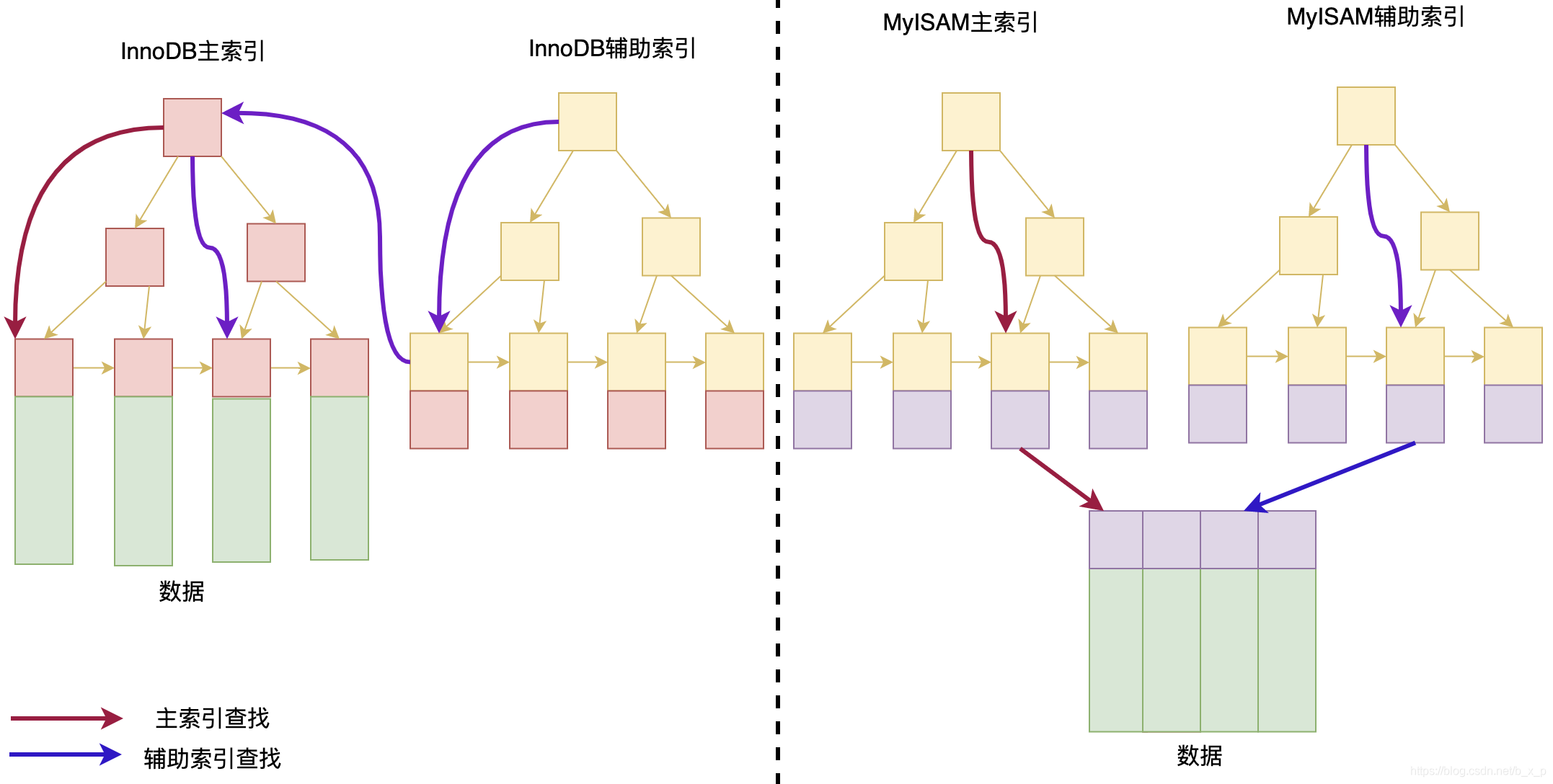
��Innodb �� MYISAM�������һ��ͼ�п�,��������ʾ:
?5.���������ļ���ԭ��
1.�е���ɢ��(��ɢ��Խ��,ѡ����Խ��)): ���㹫ʽ count(distinct(column)):count(column)
2.����ƥ��ԭ��: �������йؼ��ֽ��жԱ�,һ���Ǵ����������ν����Ҳ�������
3.���ٿռ�ԭ��: ǰ���Ѿ�˵��,���ؼ���ռ�õĿռ�ԽС,��ÿ���ڵ㱣��Ĺؼ��ָ�����Խ��,ÿ�μ��ؽ��ڴ�Ĺؼ��ָ�����Խ��,����Ч�ʾ�Խ�ߡ����������Ĺؼ���Ҫ������ռ�ÿռ�С