ͼ�Ķ���
ͼ(Graph)���ɶ��������ǿռ��ϺͶ���֮��ߵļ������,ͨ����ʾΪ:G(V,E),G��ʾһ��ͼ,V(vertex)��ͼG�ж���ļ���,E(edge)��ͼG�бߵļ��ϡ�
- ͼ�е�����Ԫ�س�Ϊ��㡣
- ��ͼ�ṹ��,���㼯��V����ǿա�
- ��ͼ�ṹ��,������������֮�䶼�����й�ϵ,����������ϵ�ñ�����ʾ,������Ϊ�ա�
ͼ�Ļ�������
��n��ʾͼ�ж�����Ŀ,��e��ʾ�ߵ���Ŀ,������һЩ����ͼ�������ܽ�:
-
����ͼ������ͼ
ͼ���з���������Ϊ����ͼ������ͼ

����ͼ��,���������ӹ�ϵ��Ϊ�����,����߿��Ա�ʾ�������,��**(A,B)Ҳ����д��(B,A)**��
����ͼ��,���������ӹ�ϵ��Ϊ�����,Ҳ��Ϊ��,������Ա�ʾ,��**<A,B>,A�ǻ�ͷ,B�ǻ�β,ע�ⲻ��д��<B,A>**��
-
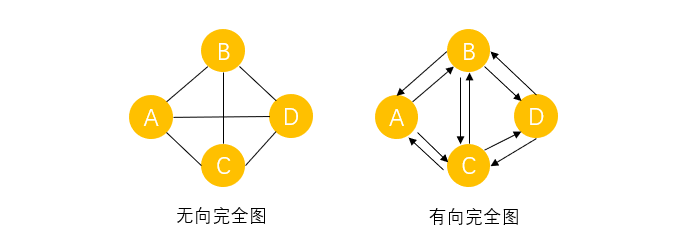
������ȫͼ��������ȫͼ
������ȫͼ:������ͼ��,�����������㶼���ڱߡ�����n�������������ȫͼ�� n ( n ? 1 ) 2 \frac{n(n-1)}{2} 2n(n?1)?���ߡ�
������ȫͼ:������ͼ��,������������֮�䶼���ڷ���Ϊ�෴��������������n�������������ȫͼ�� n ( n ? 1 ) n(n-1) n(n?1)���ߡ�
-
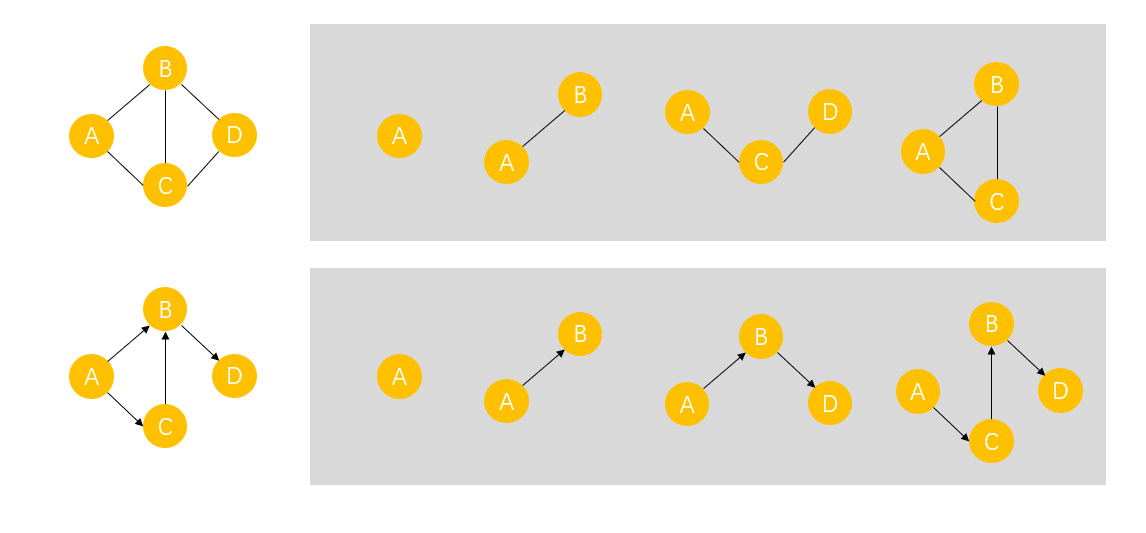
ϡ��ͼ�ͳ���ͼ
�к�������ͼ��Ϊϡ��ͼ,��֮��Ϊ����ͼ,����û����ȷ�ı�,����Զ��Եġ�
-
Ȩ����
���е�ͼ��,ÿ�����Ա��Ͼ���ij�ֺ������ֵ,����ֵ��Ϊ�ñ��ϵ�Ȩ,������Ȩ��ͼͨ����Ϊ����
-
�ڽӵ�
��������ͼG,���ͼ�ı�**(v,v��)��E**,���v ��v����Ϊ�ڽӵ�,��v ��v�����ڽӡ���**(v,v��)����������v ��v��**,����˵��**(v,v��)�붥��v ��v�������**��
-
�ȡ���Ⱥͳ���
����Ķ���ָ��v������ıߵ���Ŀ,��Ϊ T D ( v ) TD(v) TD(v)����������ͼ,����v�Ķȷ�Ϊ��Ⱥͳ���,������Զ���vΪͷ�Ļ�����Ŀ,��Ϊ I D ( v ) ID(v) ID(v),�������Զ���vΪβ�Ļ�����Ŀ,��Ϊ O D ( v ) OD(v) OD(v),����v�Ķ�Ϊ:
T D ( v ) = I D ( v ) + O D ( v ) TD(v)=ID(v)+OD(v) TD(v)=ID(v)+OD(v)
һ���,������� v i v_i vi?�Ķȼ�Ϊ T D ( v i ) TD(v_i) TD(vi?),��ôһ����n������,e���ߵ�ͼ,�������¹�ϵ:
e = 1 2 �� i = 1 n T D ( v i ) e=\frac{1}{2}\sum_{i=1}^{n}{TD(v_i)} e=21?i=1��n?TD(vi?)
-
��·��
��һ����������һ��������ͬ��·����Ϊ��·�Ļ���
-
��·������·���
�����ж��㲻�ظ����ֵ�·����Ϊ��·������·�Ļ��г��˵�һ����������һ������֮��,�������㲻�ظ�����,���Ϊ��·�����
-
·����·���ij���
·���ij�����·���ϱ���Ŀ��
-
��ͨ����ͨͼ����ͨ����
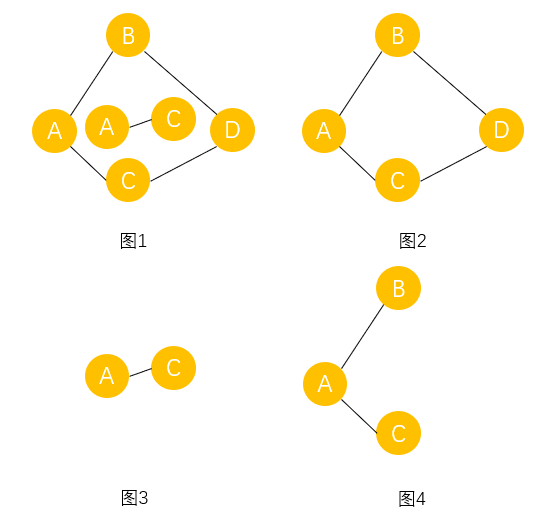
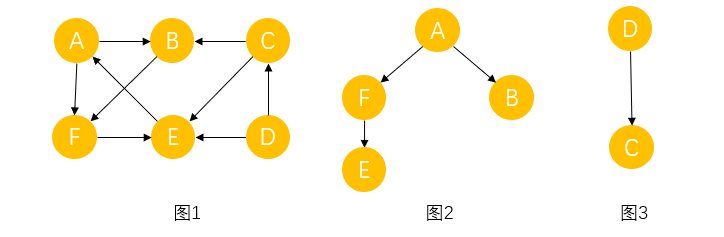
������ͼG��,����Ӷ���v��v����·��,���v��v������ͨ�ġ��������ͼ�������������� v i , v j �� E v_i,v_j��E vi?,vj?��E, v i �� v j v_i��v_j vi?��vj?������ͨ��,���G����ͨͼ,��ͼ1������ͨͼ,��ͼ������ͨͼ��
?
? ����ͼ�еļ�����ͨ��ͼ��Ϊ��ͨ����,ͼ2��ͼ3����ͼ1����ͨ������
-
ǿ��ͨͼ��ǿ��ͨ����
������ͼG��,�������ÿһ�� v i , v j �� V , v i �� v j v_i,v_j��V,v_i��v_j vi?,vj?��V,vi?��?=vj?,�� v i �� v j v_i��v_j vi?��vj?�ʹ� v j �� v i v_j��v_i vj?��vi?������·��,���G��ǿ��ͨͼ������ͼ�еļ���ǿ��ͨ��ͼ��������ͼ��ǿ��ͨ������,����ͼ,ͼ1����ǿ��ͨͼ,��Ϊ��D��Aû��·��,��ͼ2��ͼ3��ͼ1��ǿ��ͨ������

-
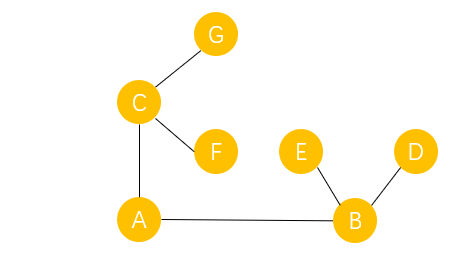
��ͨͼ��������
��ͨͼ����������һ����С��ͨ��ͼ,������ͼ��ȫ����n������,��ֻ�����Թ���һ������n-1���ߡ�����ͼ,������ͨͼ����������
-
������������ɭ��
���һ������ͼǡ��һ����������Ϊ0,���ඥ�����Ⱦ�Ϊ1,����һ��������������ͼ��ͼ2��ͼ3����һ��������,A��D�����Ϊ0,������Ϊ���еĸ���㡣һ������ͼ������ɭ���������ɿ����������,����ͼ��ȫ������,��ֻ�����Թ������ɿŲ��ཻ�������Ļ�,��ͼ1��ʾ��
ͼ�����Ͷ���
ͼ��һ�����ݽṹ,����һ���������,�����˳����������͡�������������ͼ�Ķ�������:
ADTͼ(Graph)
Data
���������ǿռ��Ϻͱߵļ���
Operation
CreateGraph(*G,V,VR) :���ն��㼯V�ͱ߹¼�VR�Ķ��幹��ͼ
DestroyGraph(*G) :ͼG����������
LocateVex(G,u) :��ͼG�д��ڶ���u,��ͼ�е�λ��
GetVex(G,v) :����ͼG�ж���v��ֵ
PutVez(G,v,value) :��ͼG�ж���v��ֵvalue
FirstAdjVex(G,*v) :���ض���v��һ���ڽӶ���,��������G�����ڽӶ��㷵�ؿ�
NextAdjVex(G,v,*w) :���ض���v����ڶ���w����һ���ڽӶ���,��w��v�����һ���ڽӵ��ء��ա�
ISertVex(*G,v) :��ͼG�������¶���v
DeleteVex(*G,v) :ɾ��ͼG�ж���v������صĻ�
InsertArc(*G,v,w) :��ͼG��������<v,w>,��G������ͼ,����Ҫ�����Գƻ�<w,v>
DeleteArc(*G,v,w) :��ͼG��ɾ����<v,w>,��G������ͼ,����Ҫ�����Գƻ�<w,v>
DFSTraverse(G) :��ͼG�н���������ȱ���,�ڱ������̶�ÿ���������
HFSTraverse (G) :��ͼG�н��й�����ȱ���.�ڱ������̶�ÿ���������
endADT
ͼ�Ĵ洢�ṹ
�ڽӾ���
ͼ���ڽӾ���(Adjacency Matrix)�洢��ʽ����������������ʾͼ��һ��һά����洢ͼ�ж�����Ϣ,һ����ά����(�ڽӾ���)�洢ͼ�еı���Ϣ��
��ͼG��n������,���ڽӾ�����һ��n��n�ķ���,���������й�ϵ����1��ʾ,������0��ʾ,��������:
A [ i ] [ j ] = { 1 , �� ( v i , v j ) �� E �� < v i , v j > �� E 0 , �� ֮ A[i][j]=\begin{cases} 1, & ��(v_i,v_j)��E��<v_i,v_j>��E \\ 0, & ��֮ \end{cases} A[i][j]={1,0,?��(vi?,vj?)��E��<vi?,vj?>��E��֮?
����ͼ,��ͼ��һ������ͼ,����ͼ��һά����+��ά�����ʾ
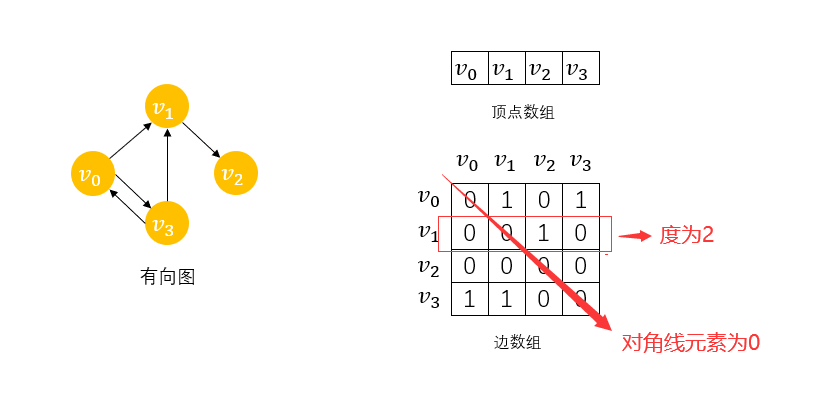
����ͼ��֪,��������Ϊvertex[4]={ v 0 , v 1 , v 2 , v 3 v_0,v_1,v_2,v_3 v0?,v1?,v2?,v3?},������Ϊarc[4] [4],ÿһ��֮�ʹ����ö���Ķ�,������ĶԽ���Ԫ��Ϊ0,������Ϊ�����ڶ��㵽�����ı�,���Ҫ��ij��������ڽӵ�,���ö����Ӧ����ɨ��һ��,1��Ӧλ�õļ�Ϊ�ڽӵ㡣ֵ��ע�����,����ͼ�ı�������һ���Գƾ�����
������������������ͼ,1��ʾһ�����㵽��һ�������л�,0���ʾû��:
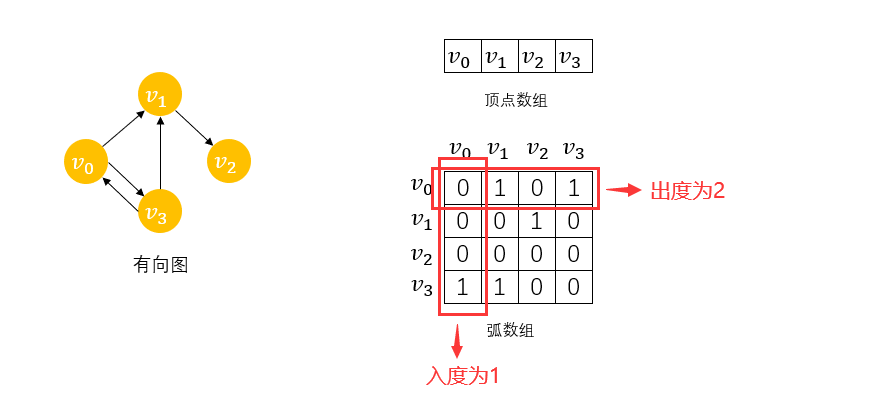
ͬ����,����ͼ�Ķ�������Ϊvertex[4]={ v 0 , v 1 , v 2 , v 3 v_0,v_1,v_2,v_3 v0?,v1?,v2?,v3?},������Ϊarc[4] [4],ÿ��֮�ʹ����ö��������,ÿ��֮�ʹ����ö������,������ĶԽ���Ԫ����Ϊ0,���Ҫ��ij��������ڽӵ�,���ö����Ӧ����ɨ��һ��,1��Ӧ��λ�ü�Ϊ�ڽӵ㡣ע��,����ͼ�ı��������ǶԳƾ�����
����,��������ͼ,������������һ����,ǰ���Ѿ����ܹ���,ÿ�����ϴ�Ȩ��ͼ��������
��ͼG����,��n������,��ij�����㵽��һ������û�б�,���� �� �� ����ʾ, �� �� ����ʾһ������������ġ��������б���Ȩֵ��ֵ,���,�����¶���:
A [ i ] [ j ] = { W i , j , �� ( v i , v j ) �� < v i , v j > �� E �� , �� ֮ A[i][j]=\begin{cases} W_{i,j}, & ��(v_i,v_j)��<v_i,v_j>��E \\��, & ��֮ \end{cases} A[i][j]={Wi,j?,��,?��(vi?,vj?)��<vi?,vj?>��E��֮?
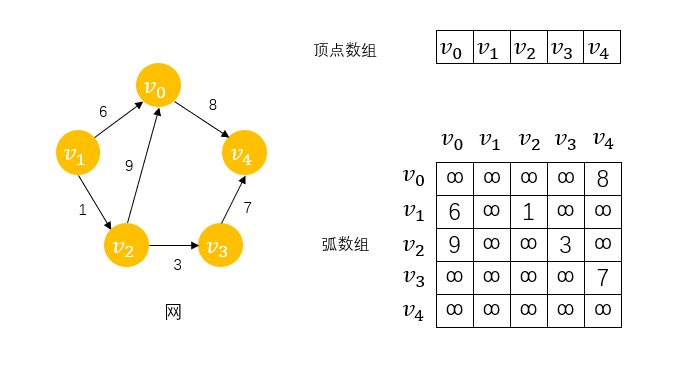
��ô����������ʵ��ͼ�Ĵ���:
#define MaxInt 32767 //��ʾ����ֵ,����
#define MVNum 100 //�����
typedef char VerTexType; //���趥����������Ϊ�ַ���
typedef int ArcType; //����ߵ�Ȩֵ����Ϊ����
typedef struct
{
VerTexType vexs[MVNum]; //�����,һά����
ArcType arcs[MVNum][MVNum]; //�ڽӾ���,��ά����
int vexnum,arcnum; //ͼ�ĵ�ǰ�����ͱ���
}AMGraph;
��������ṹ��,�������������ڽӾ����ʾ������һ��������Ϊ����˵������ͼ���㷨��
�㷨��Ϊ�IJ�:
- ���붥���������ܱ���;
- �������붥����Ϣ;
- ��ʼ���ڽӾ���,ʹ�ڽӾ����ÿ�����ϵ�Ȩֵ��Ϊ �� �� ��
- ����������ÿ����������Ķ����Ȩֵ,ȷ������������ͼ�е�λ�ú�,������Ӧ��һ��Ȩֵ,ͬʱ���ĶԳƱ߸�����ͬ��Ȩֵ,�� ( v 0 , v 1 ) �� ( v 1 , v 0 ) (v_0,v_1)��(v_1,v_0) (v0?,v1?)��(v1?,v0?)��Ϊ�ԳƱߡ�
//�����ڽӾ����ʾ��,��������ͼ
void CreateUDN(AMGraph *G)
{
int i,j,k,w;
scanf("%d,%d",&G->vexnum,&G->arcnum); //�����ܶ��������ܱ���
for(i=0;i<G->vexnum;i++) //�������붥����Ϣ
scanf("%d",G->vexs[i]);
for(i=0;i<G->vexnum;i++) //��ʼ���ڽӾ���,�ߵ�Ȩֵ����Ϊ����ֵMaxint
for(j=0;j<G->vexnum;j++)
G->arcs[i][j] = MaxInt;
for(k=0;k<G->arcnum;k++) //�����ڽӾ���
{
scanf("%d,%d,%d",&i,&j,&w); //����һ���������Ķ����Ȩֵ
G->arcs[i][j] = w;
G->arcs[i][j] = G->arcs[j][i] //����ͼ,�Գƾ���
}
}
����������,n�������e���ߵ�����ͼ�Ĵ���,ʱ�临�Ӷ�Ϊ O ( n + n 2 + e ) O(n+n^2+e) O(n+n2+e),���ж��ڽӾ���ij�ʼ���ķ��� O ( n 2 ) O(n^2) O(n2)��ʱ��,��Ȼ����һ�ֲ�����ͼ�洢�ṹ,��������ڱ�������ڶ�����ٵ�ͼ,�ͻ�����˼���Ŀռ��˷�,��Ϊ��ʱ�����д��� �� �� ��,����������������һ�ֽṹ��
�ڽӱ�
�ڽӱ���ͼ��һ����ʽ�洢�ṹ��
�ڽӱ��ɱ�ͷ���ͱ߽�����������:
-
��ͷ�����һ��һά����洢,���������ݺ�ָ���һ���ڽӵ��ָ�����,������洢���ڲ��Ҷ���ı���Ϣ��
-
ÿ��������ڽӵ��õ������洢,����ͼ�Ƹõ�����Ϊ���� v i v_i vi?�ı߱�,����ͼ���Ϊ���� v i v_i vi?��Ϊ��β�ij��߱�����ͼ����Ȩ,�������еı߽�����������,**һ�����DZ߽���������е�λ��(�±�),��һ������ָ����һ���߽���ָ�롣**��ͼ��Ȩ,�߽��������������,���ӵIJ������ڴ洢Ȩ����Ϣ��
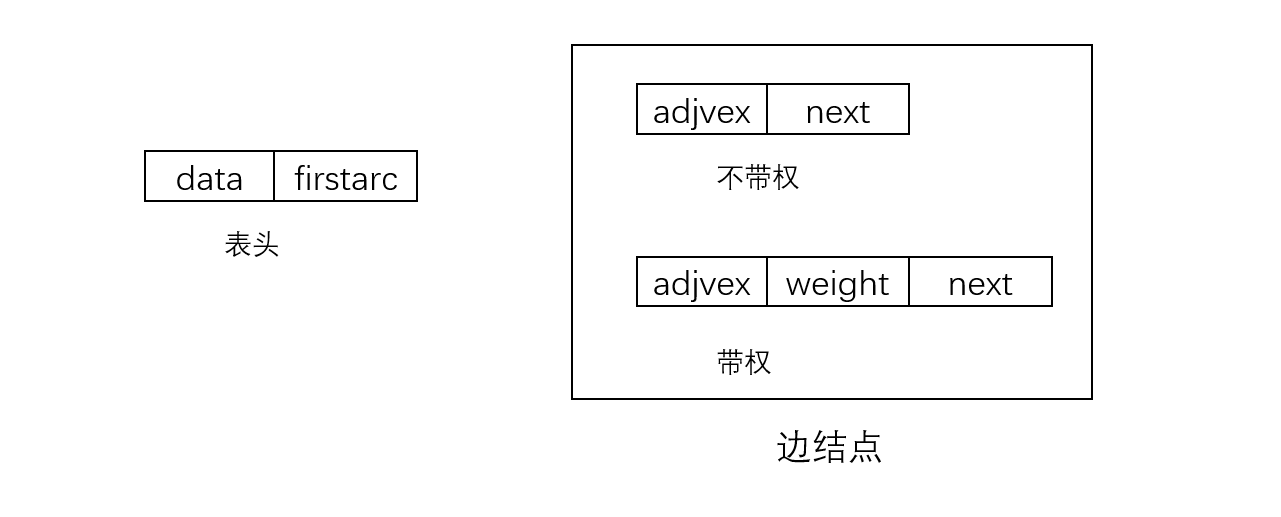
�����ֽṹ��,ÿ����������Ӧ�ĵ�������������Ǹö���Ķ�,���Ҫ�жϴӶ��� v i v_i vi?�� v j v_j vj?�Ƿ���ڱ�,��ֻ����� v i v_i vi?��Ӧ�����Ľ���adjvex��������j���ɡ�
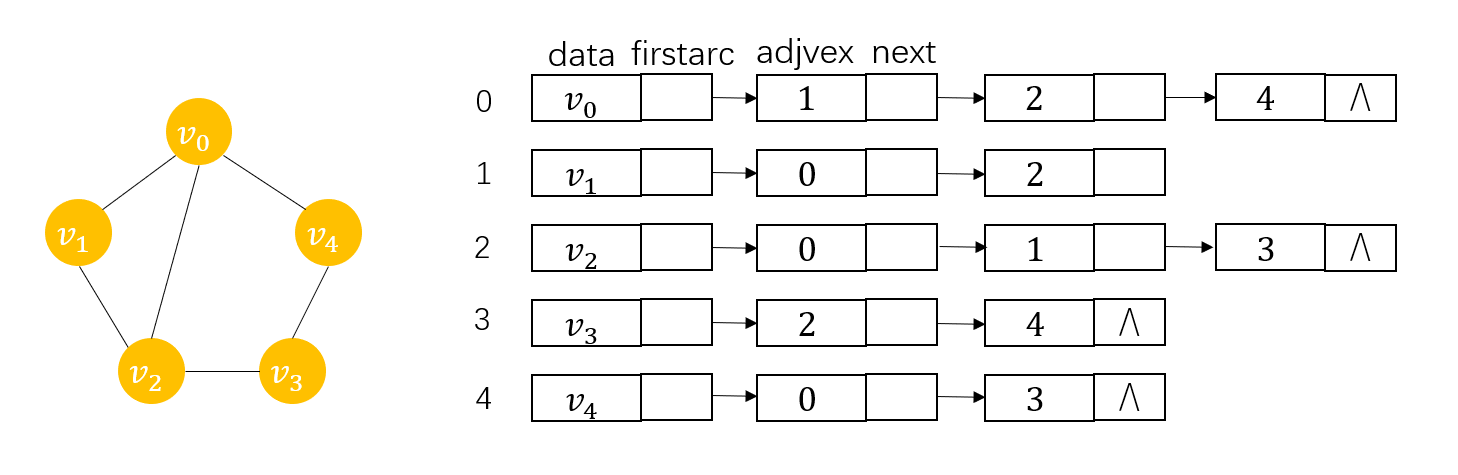
��������ͼ,�ڽӱ������Ƶ�,����Ϊ�������Զ��㻡β���洢�߱���,���Խ�����ֻ�ܴ�������,��Ҫ֪�����,���ǻ����Զ��㻡ͷ���洢�߱�,�õ�һ�����ڽӱ�,���ڽӱ���ijһ�����Ӧ�������Ľ�������Ǹý������,����ͼ:
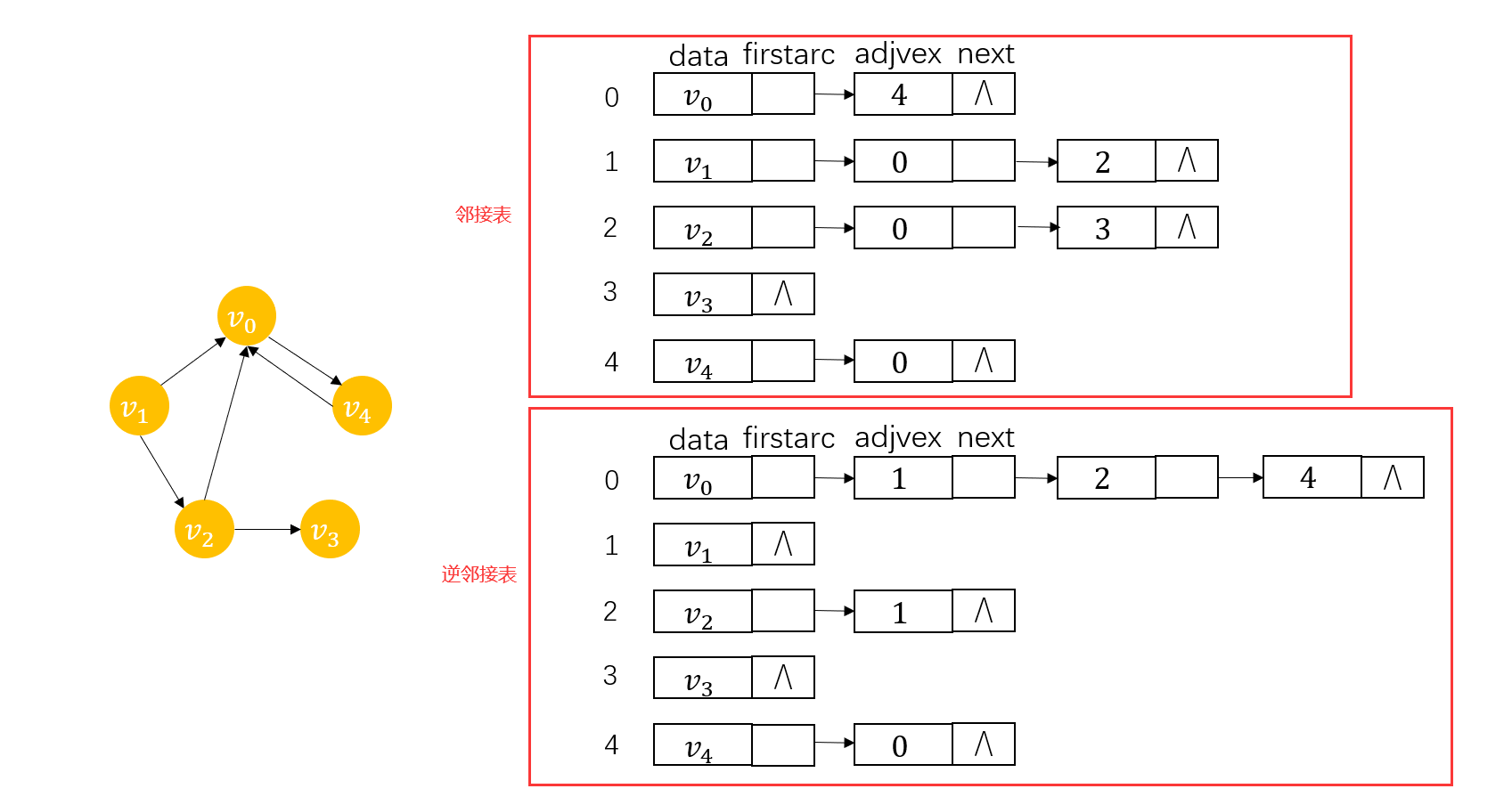
���ڴ�Ȩ����ͼ,�����ڱ߽��������weight�����洢Ȩ���ɡ�
��������ķ���,������������Ӧ�Ľṹ��:
typedef int VertexType;
typedef int ArcType; // ��������Ҫ���ж���
typedef struct ArcNode //����߽��
{
int adjvex; //�洢�ڽӵ��±�
ArcType weight; //�洢Ȩ,���ﲻ����ͼ,����Ҫ��
struct ArcNode* next; //ָ����һ������ָ��
}ArcNode;
typedef struct VertexNode //�����ͷ���
{
VertexType data; //�洢������Ϣ
ArcNode* firstarc; //����ָ���һ���ڽӵ��ָ��
}VertexNode,AdjList[MAXVEX];
typedef struct
{
AdjList adjList;
int vexnum,arcnum; //�ڽӱ���ǰ�������ͱ���
}GraphAdjList;
���洴������ͼ���ڽӱ�:
void CreateGraph(GraphAdjList *G)
{
int i,j,k;
ArcNode *e;
scanf("%d,%d",&G->numvex,&G->arcnum); //���붥�����ͱ���
for(i=0;i < G->numvex;i++) //���붥����Ϣ
{
scanf("%d",&G->adjList[i].data);
G->adjList[i].firstarc = NULL; //�������ͷ����ָ���ÿ�
}
for(k=0;k< G->arcnum;k++) //�����߱�
{
scanf("%d,%d",&i,&j); //�������(v_i,v_j)��ص�������������
e=(ArcNode*)malloc(sizeof(ArcNode)); //�����߽��
//ͷ�巨
e->adivex = j; //�ڽ����Ϊj
e->next = G->adjList[i].firstarc; //e��ָ����ָ��ǰ����ָ�����һ���ڽӵ�
G->adjList[i].firstarc = e; //��ǰ�����ָ��ָ��e
e=(ArcNode*)malloc(sizeof(ArcNode));
e->adivex = i; //�ڽ����Ϊi
e->next = G->adjList[i].firstarc; //e��ָ����ָ��ǰ����ָ�����һ���ڽӵ�
G->adjList[i].firstarc = e; //��ǰ�����ָ��ָ��e
}
}
�����õ���������ͷ�巨,���������Ļ����Կ�����֮ǰ�IJ���,��������
ʮ������
ʮ������ (Orthogonal List) ������ͼ����һ����ʽ�洢�ṹ��
�����������ͼ,���Dz������ڽӱ������ڽӱ�������Ⱥ���ȵ�����,��ʮ�������Ϳ��Խ������ֱ����ϵ�һ��
���ǽ������Ͷ�����Ľṹ�嶨������:

������:firstin����߱���ͷָ��,firstout��ʾ���߱���ͷָ�롣
�����:tailvex��headvex�ֱ�ָ��β�ͻ�ͷ�ڶ�����е��±�,headlinkָ���յ���ͬ����һ����,taillinkָ�������ͬ����һ������
ͼ�ı���
ͼ�ı�����ָ���Ǵ�ͼ�е���һ�������,��ͼ�е����ж������һ����ֻ����һ�Ρ�
������������㷨
�����������(Depth First Search,DFS),��������ǰ�����,��ǰ��������ƹ㡣
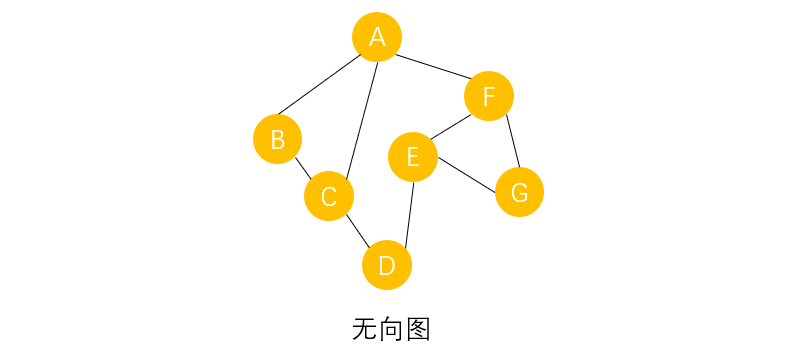
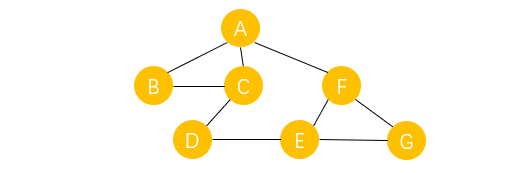
�������������ͼΪ��,˵һ����������㷨����������:
- �Ӷ���A��ʼ,���ʹ�����A��,������������ѡ��,Ҫôȥ����B,ҪôȥC����F,�������ǹ涨,���ȷ����ұ�δ�����ʹ����ڽӵ�,������ұ���ָ��������վ�ڵ�A,��������·ѡ��ʱ�����ֱ�,���Ƿ���B��
- ������B��,ֻ��һ��·ѡ��,���Ƿ���C,C������·ѡ��,������ѡ�����ֱ�δ���ʵ��ڽӵ�,���Ƿ���D,Ȼ���������E��F,Ȼ�����A��
- ����A�Ѿ����ʹ���,������δ�����ʵ��ڽӵ�,����������A���ұߵĶ���B,����BҲ���ʹ���,��B���ڽӵ�Ҳ����������,����A��,�ٷ��ʶ���C,����CҲ�����ʹ���,C���ڽӵ�Ҳ����������,���Ƿ���A�������ŷ��ʶ���F,����F�ѱ����ʹ�,������δ�����ʵ��ڽӵ�,���ŷ��ʶ���G,G���ڽӵ���ȫ��������ϡ�
- ����,ȫ�������Ѿ��������,�õ��Ķ����������Ϊ A B C D E F G ABCDEFG ABCDEFG
���������ô�����ʵ����һ��������,ͼ�Ĵ洢�õ����ڽӾ���ķ�ʽ
int visited[MAX];
void DFS (AMGraph G,int i)
{
int j;
visited[i] = 1; //���ѱ����ʹ�����Ϊ1
printf("%c ",G.vexs[i]); //�ɸ���Ϊ�����Զ���IJ���
for(j = 0;j<G.vexnum;j++)
{
if(G.arcs[i][j] == 1 && !visited[j]) //�ڽӵ������δ������
DFS(G,j); //�ݹ�
}
}
//���������������
void DFSTraverse(AMGraph G)
{
int i;
for(i = 0;i<G.vexnum;i++)
visited[i] = 0; //��ʼ�����нڵ����Ϊδ������
for(i = 0;i < G.vexnum;i++)
{
if(!visited[i])
DFS(G,i);
}
}
��ͼ�Ĵ洢�õ����ڽӱ��ķ�ʽ,���������㷨
//�ݹ����
void DFS(GraphAdjList GL; int i)
{
ArcNode *p; //�߽��
visited[i] = 1;
P = GL->adjList[i].firstarc;
while(p)
{
if(!visited[p->adjvex]) //���������
DFS(GL,p->adjvex);
p = p->next;
}
}
//�����ڽӱ�
void DFSTraverse(GraphAdjList GL)
{
int i;
for(i = 0; i< GL->vexnum; i++)
visited[i] = 0; //��ʼ�����нڵ����Ϊδ������
for(i = 0; i < GL->vexnum; i++)
{
if(!visited[i])
DFS(GL,)
}
}
��������㷨
�����������(Breadth First Search, BFS)�������������IJ�α���,�����IJ���������ƹ㡣
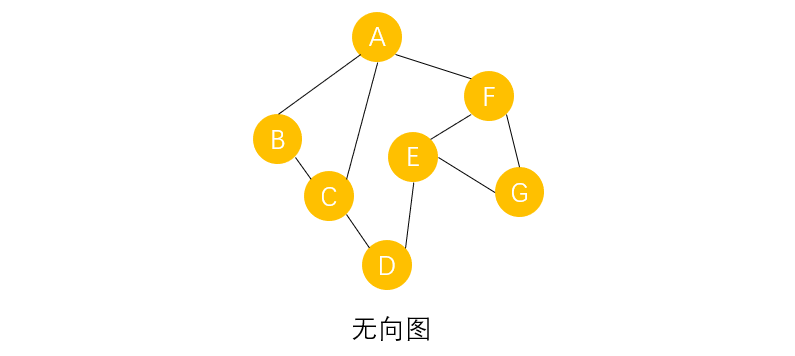
��������ͼΪ��,������������ı�������:
�����Ƚ���ͼ����Ϊ��ͼ,����Aλ�ڵ�һ��,�붥��A�бߵĶ���B��C��Fλ�ڵڶ���,ͬ���붥��B��C��F�бߵ�D��E��Gλ�ڵ����㡣
Ȼ�����ö����Ƚ��ȳ����ص��ͼ���б���:
- ����A���,����A���ӡ�
- ����B��C��F��ӡ�
- ����B����,Ȼ��C����,����D��ӡ�
- ����F����,����E��G��ӡ�
- ����D����,����E����,����G����,����,ͼ�ı�������,����˳��ΪABCFDEG��
����BFSԭ����֮ǰ����һƪ�����������,���潲��ĸ���ϸ,����Ȥ���Ʋ��Ķ�,���ӷ������ˡ�
���������ǿ����ڽӾ���Ĺ�������㷨:
void BFSTraverse(AMGraph G)
{
int i,j;
Queue Q;
for(i = 0; i<G.vexnum;i++)
visited[i] = 0;
//��ʼ������
InitQueue(&Q);
for(i=0; i < G.vexnum;i++)
{
if(!visited[i]) //��δ���ʹ�����з���
{
visited[i] = 1; //����
PushQueue(&Q,i); //�������
while(QueueSize(Q))//�����в�Ϊ��,�����ѭ��
{
PopQueue(&Q,&i);//��ͷ����,��i���������±�
for(j=0;j<G.vexnum;j++)//���ʸոճ��Ӷ�����ڽӵ�
{
if(G.arcs[i][j] == 1 && !visited[j]) //�ڽӵ������δ������
{
visited[j]=1; //���
PushQueue(&Q,j); //��������
}
}
}
}
}
}
�ڽӱ��ĵĹ�������㷨:
void BFSTraverse(GraphAdjList GL)
{
int i;
ArcNode *p;
Queue Q;
for(i = 0; i<G.vexnum;i++)
visited[i] = 0;
InitQueue(&Q);
for(i=0; i < G.vexnum;i++)
{
if(!visited[i])
{
visited[i] = 1;
PushQueue(&Q,i);
while(QueueSize(Q))
{
PopQueue(&Q,&i);
p = GL->adjList[i].firstarc; //��¼�ո�ɾ������ָ��ĵ�һ���ڽӵ�
while(p)
{
if(!visited(p->adjvex)) //�ö���δ������
{
visitde[p->adjvex] = 1;
PushQueue(&Q,p->adjvex);
}
p = p->next;
}
}
}
}
}
��������㷨���������㷨����ȱ��:
�������:�ٶ�����ռ���ڴ��١�
�������:�ٶȿ쵫ռ���ڴ��;
�����:
- �����ݽṹ
- �����ݽṹ��C����(�廪��ε�����а�)