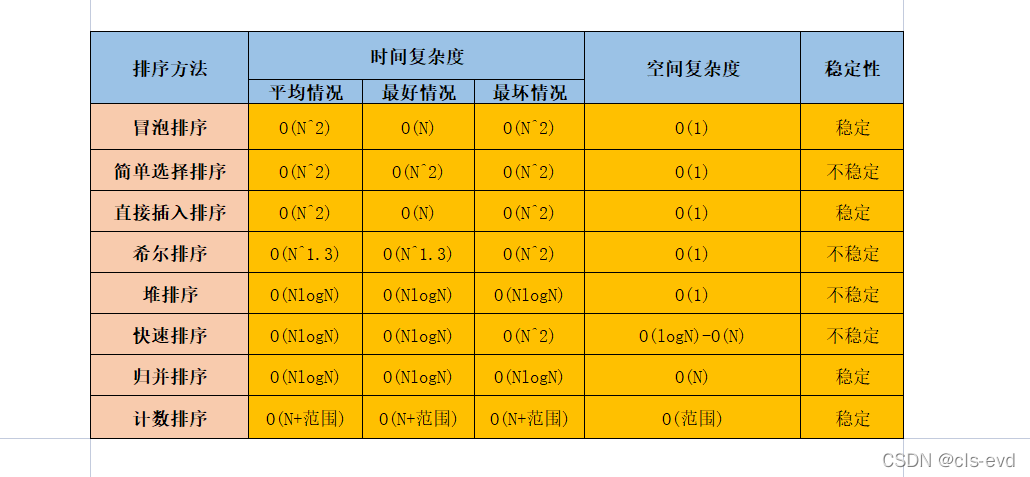
ФПТМ
АЫДѓХХађзмНс(ЪБМф,ПеМфИДдгЖШ,ЮШЖЈад)
ЧАбд
ЙигкХХађФуЫљвЊСЫНтЕФИХФю
ГЃМћХХађЫуЗЈЕФЪЕЯж
ВхШыХХађ
ЛљБОЫМЯы:жБНгВхШыХХађЪЧвЛжжМђЕЅЕФВхШыХХађЗЈ,ЦфЛљБОЫМЯыЪЧ:АбД§ХХађЕФМЧТМАДЦфЙиМќТыжЕЕФДѓаЁж№ИіВхШыЕНвЛ ИівбОХХКУађЕФгаађађСажа,жБЕНЫљгаЕФМЧТМВхШыЭъЮЊжЙ,ЕУЕНвЛИіаТЕФгаађађСа ЁЃ

??
ЫМТЗЭМШчЯТ:
 ?ДњТыЪЕЯж:
?ДњТыЪЕЯж:
ЮвУЧЯШНЋЮЪЬтВ№Нт
1.0ЯШаДЕЅЬЫХХађ
2.0дкаДЖрЬЫ
3.0ЛЭМ
1.0ЕЅЬЫВхШыЫМТЗЭМ:
ВхШы0

ЕЅЬЫХХађЕФДњТы:
void InsertSort(int* a, int n)
{
int tmp;
int end = n - 1;
while (end > 0)
{
if (tmp < a[end])
{
a[end + 1] = a[end];
}
else
{
a[end + 1] = tmp;
break;
}
a[end + 1] = tmp; //Р§ШчЩЯЭМВхШы0,Лђепtmp>a[end];
}
}
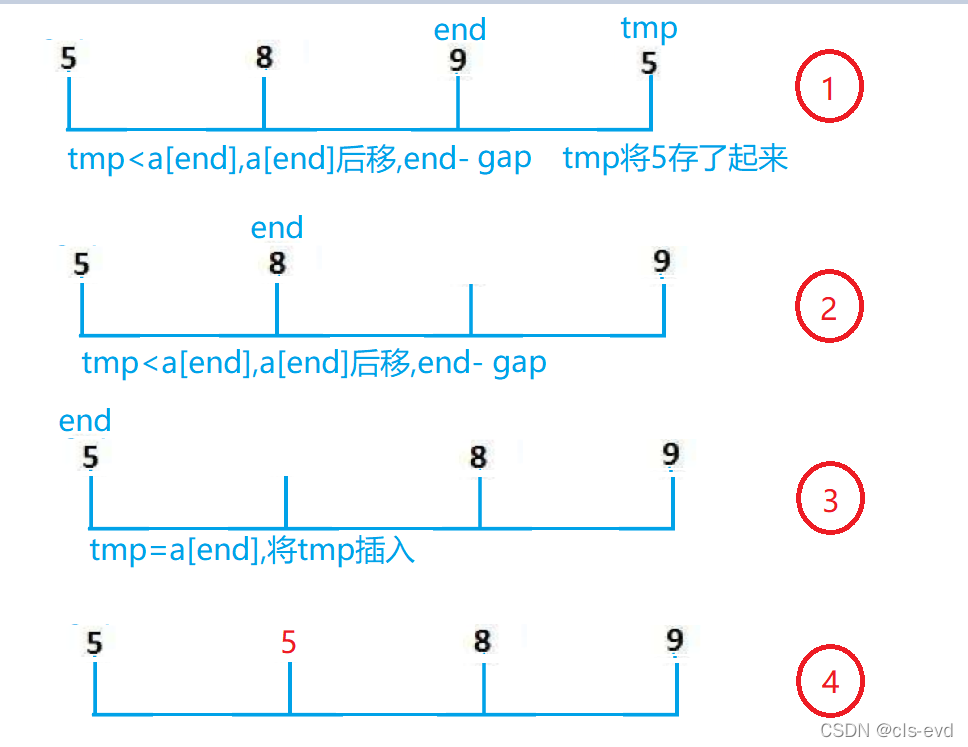
ШчЙћДцдкtmp>a[end],ЛђепВхШыЕФдЊЫиЪЧ0,ЖМжЛашНЋtmpИГИјa[end+1]МДПЩ
ЫљвдПЩвдНјааЯТаЁгХЛЏ
void InsertSort(int* a, int n)
{
int tmp;
int end = n - 1;
while (end > 0)
{
if (tmp < a[end])
{
a[end + 1] = a[end];
}
else
{
break;
}
a[end + 1] = tmp; //Р§ШчЩЯЭМВхШы0,Лђепtmp>a[end];
}
}? 2.0 дйгЩЕЅЬЫЭЦЙуЕНЖрЬЫ,вВОЭЪЧашвЊШЗЖЈУПДЮЕЅЬЫХХађЪБendгыtmpЕФЮЛжУ
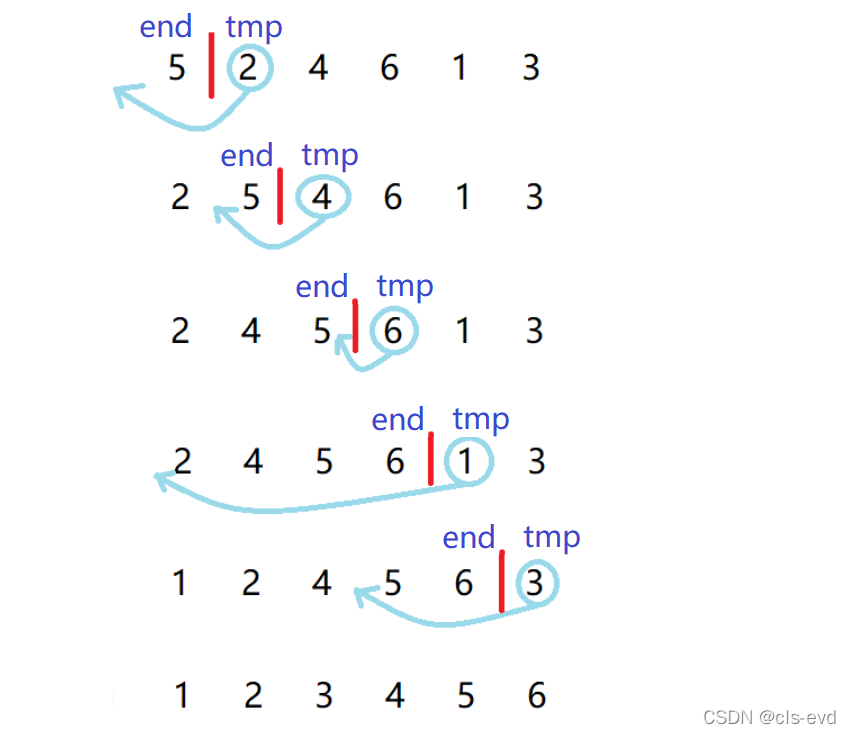
ЭЦЙуЕНЖрЬЫЕФДњТы
void InsertSort(int* a, int n)
{
for (int i = 0; i < n - 1; i++)
{
int end = i;
int tmp=a[end+1];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + 1] = a[end];
end--;
}
else
{
break;
}
a[end + 1] = tmp;
//Р§ШчЩЯЭМВхШы0;
}
}
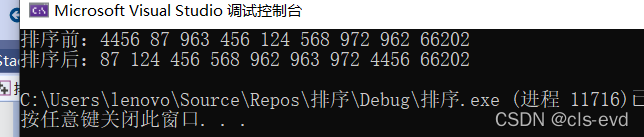
}ВтЪдДњТы:?
void Test1()
{
int a[] = { 4456,87,963,456,124,568,972,962,66202 };
int n = sizeof(a) / sizeof(a[0]);
PrintfArray(a, n);
InsertSort(a, n);
PrintfArray(a, n);
}аЇЙћЭМШчЯТ:?
?
ЯЃЖћХХађ
ЯЃЖћХХађЗЈгжГЦЫѕаЁдіСПЗЈЁЃЯЃЖћХХађЗЈЕФЛљБОЫМЯыЪЧ:ЯШбЁЖЈвЛИіећЪ§,АбД§ХХађЮФМўжаЫљгаМЧТМЗжГЩИі зщ,ЫљгаОрРыЮЊЕФМЧТМЗждкЭЌвЛзщФк,ВЂЖдУПвЛзщФкЕФМЧТМНјааХХађЁЃШЛКѓ,ШЁ,жиИДЩЯЪіЗжзщКЭХХађЕФЙЄ зїЁЃЕБЕНДя=1ЪБ,ЫљгаМЧТМдкЭГвЛзщФкХХКУађЁЃ
ЯЃЖћХХађПЩвдЫЕЪЧжБНгВхШыХХађЕФНјНзАц,ЫќЕФЙиМќдкгквдЯТСНВН
1.0?дЄХХађ? ?НгНќгаађ? ЯШЗжзщЖдЗжзщЕФЪ§ОнНјааВхШыХХађ
2.0 жБНгВхШыХХађ
дЄХХађШчЯТ:
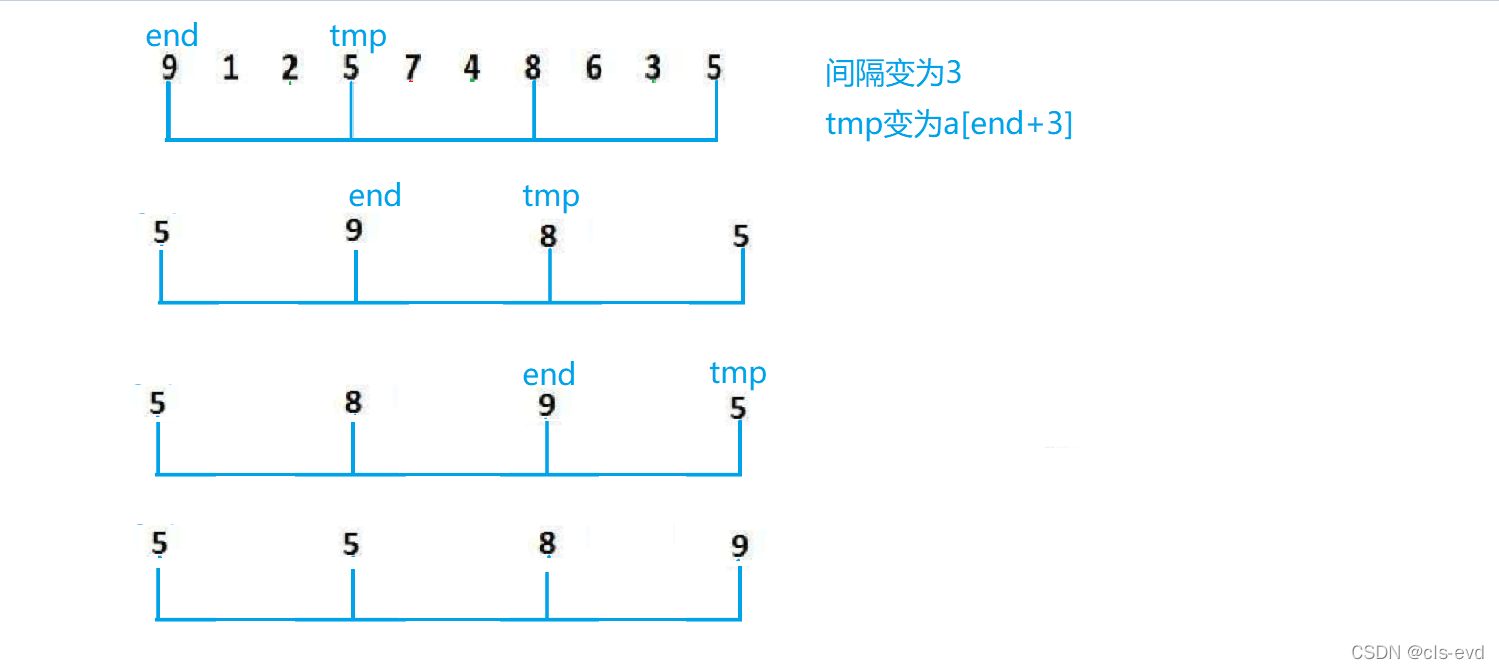
МфИєЮЊgapЗжЮЊвЛзщ,ЖдвЛзщНјааВхШыХХађ,ЮвУЧЯШМйЩшgapЪЧ3,ЗжГЩgapзщ
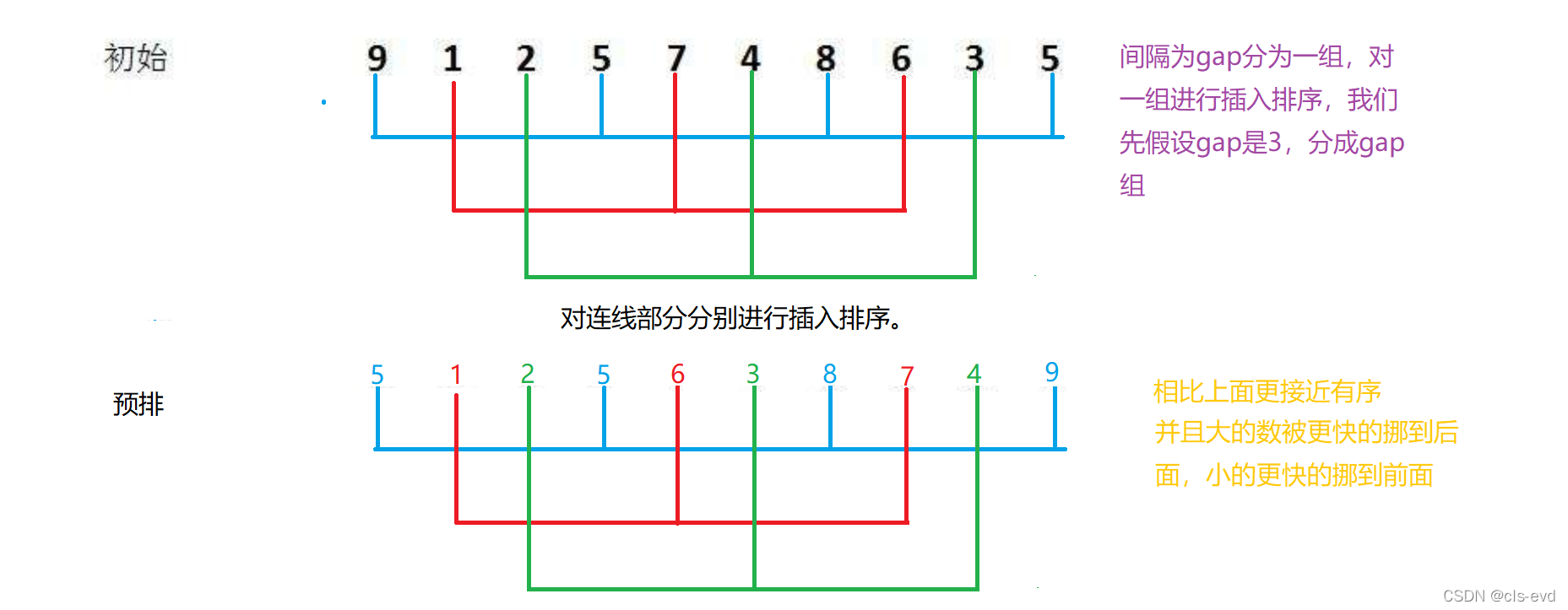
?ДњТыЪЕЯж:
НЋЮЪЬтВ№Нт
1.0? ЕЅЬЫ,ВЛжЊЕРgapЪЧМИ,ЖдУПзщНјааХХ
2.0 ЖрЬЫ
вдРЖЩЋетзщЮЊР§
?ЕЅЬЫХХЕФДњТы
void ShellSort(int* a, int n)
{
int gap=3;
int end;
int tmp=a[end+gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end-=gap;
}
else
{
break;
}
a[end + gap] = tmp;
}
}?ЭЦЙуЕНЖрЬЫ,endгыgapЕФЮЛжУШчЭМ
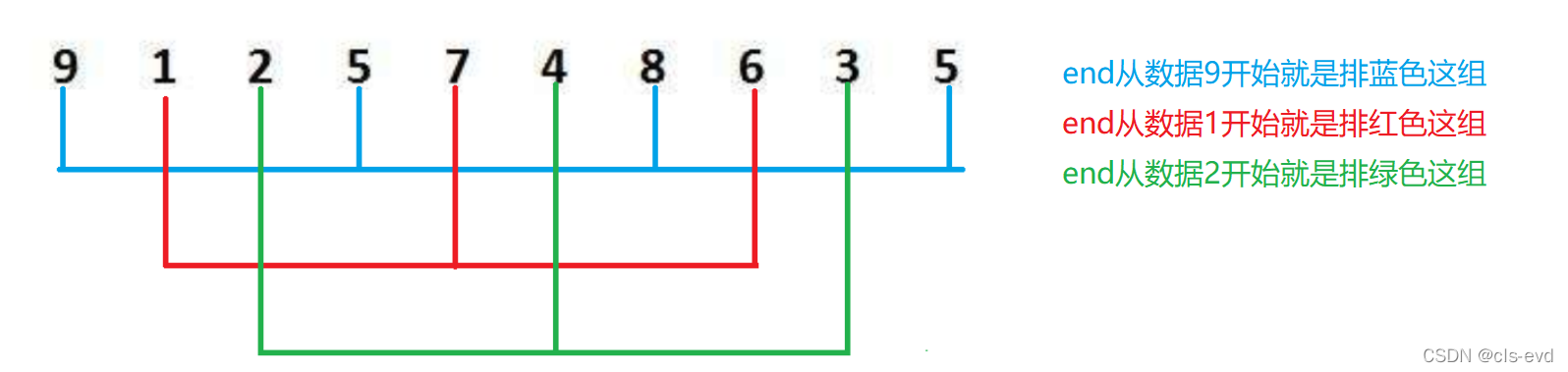
етРяИјГіРЖЩЋзщЕФЮЛжУ,КьЩЋКЭТЬЩЋзщЭЌРэ
?ХХРЖЩЋетзщЕФДњТы,ЦфЪЕКЭжБНгВхШыЭъШЋвЛбљ,НіНіЪЧСНИіЪ§жЎМфЕФМфОргЩ1БфГЩСЫgap
int gap=3;
for (int i = 0; i < n - gap; i + gap)
{
int end;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
a[end + gap] = tmp;
}
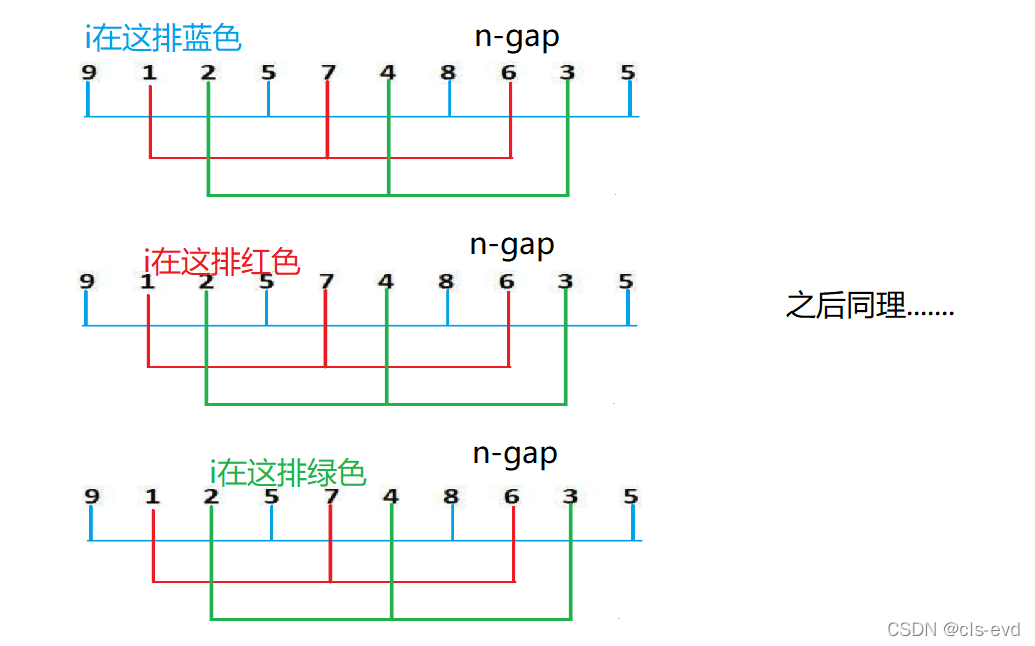
}?НгЯТРДЮвУЧашвЊНтОіЕФЮЪЬтОЭЪЧ,ЪЕЯжХХКьЩЋзщКЭТЬЩЋзщ,вВОЭЪЧШУendЗжБ№Дг0,1,2ПЊЪМЮвУЧгУЯТУцетжжЗНЪННтОі
int gap=3;
for (int i = 0; i < n - gap; i++)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
a[end + gap] = tmp;
}
}?НіНіЪЧНЋi+=gapИФЮЊi++етбљОЭЪЕЯжСЫЭЌЪБПЩвдХХађКьТЬРЖШ§зщ(gapЮЊ3)
?a [ n-gap ]ЮЊ6,iзюжеЕНДя8ФЧИіЮЛжУОЭХХКУСЫ
зюКѓвЛИіЮЪЬт,gapЕФШЁжЕЮЪЬт,ЩЯЪіДњТыЮвУЧЪЧШЁgap=3ЮЊР§ ,ЕЋдкЪЕМЪХХађжа,ИјgapвЛИіЖЈжЕПЯЖЈЪЧВЛааЕФ,Ъ§зщПЩФмКмДѓвВПЩФмКмаЁ
ОЙ§ЗжЮіЮвУЧПЩвджЊЕР
gapдНДѓ,ДѓЕФКЭаЁЕФЪ§ПЩвдИќПьЕФХВЕНЖдгІЗНЯђШЅ
gapдНДѓ,дНВЛНгНќгаађ
gapдНаЁ,ДѓЕФКЭаЁЕФЪ§ПЩвдИќТ§ЕФХВЕНЖдгІЗНЯђШЅ
gapдНаЁ,дННгНќгаађ
ШчЙћgap==1 ,ОЭЪЧжБНгВхШыХХађ

ЕБgap>1ЕФЪБКђОЭЪЧдЄХХађ,gap==1ЕФЪБКђОЭЪЧжБНгХХађ
gap=(gap/3+1)ЕФФПЕФЪЧБЃжЄзюКѓвЛДЮвЛЖЈЪЧ1
етРяgapГ§5вВПЩвд?
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)
{
gap = (gap / 3 + 1);
for (int i = 0; i < n - gap; i++)
{
int end=i;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
{
break;
}
a[end + gap] = tmp;
}
}
}
}?ЭъећДњТы
void ShellSort(int* a, int n)
{
//gap>1 дЄХХађ
//gap==1 жБНгХХађ
int gap=n;
while (gap > 1)
{
gap = (gap / 3 + 1);
for (int i = 0;i < n - gap;i++)
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end-=gap;
}
else
{
break;
}
a[end + gap] = tmp;
}
printf("gapЮЊ%dдЄХХКѓ->", gap);
PrintfArray(a, n);
}
}
}ВтЪдДњТы
void Test2()
{
int a[] = { 4456,87,963,456,124,568,972,962,66202 };
int n = sizeof(a) / sizeof(a[0]);
printf("ХХађЧА:");
PrintfArray(a, n);
ShellSort(a, n);
printf("ХХађКѓ:");
PrintfArray(a, n);
}аЇЙћбнЪО:?
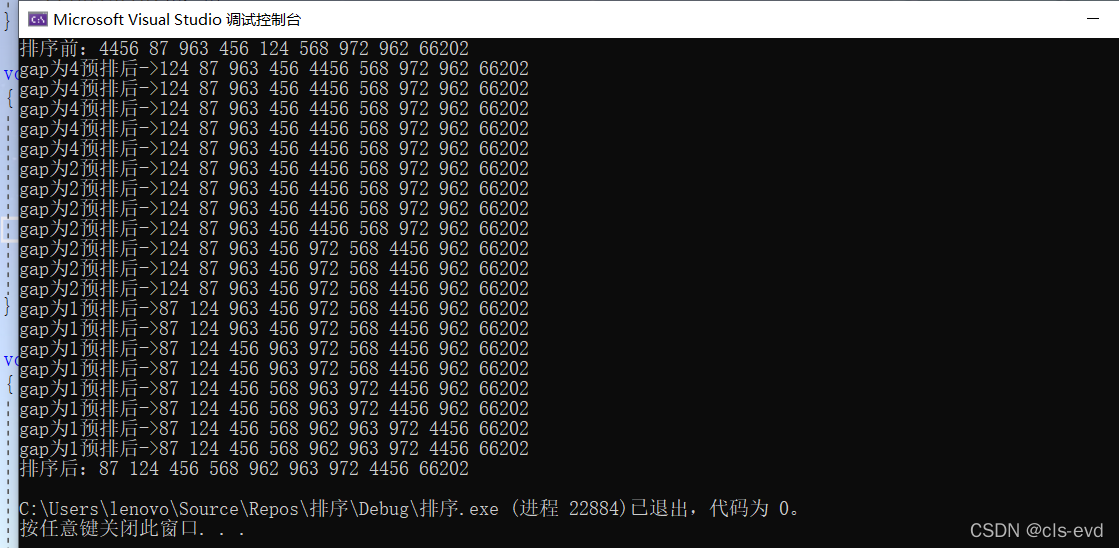
?бЁдёХХађ
ЛљБОЫМЯы: УПвЛДЮДгД§ХХађЕФЪ§ОндЊЫижабЁГізюаЁ(ЛђзюДѓ)ЕФвЛИідЊЫи,ДцЗХдкађСаЕФЦ№ЪМЮЛжУ,жБЕНШЋВПД§ХХађЕФ Ъ§ОндЊЫиХХЭъ ЁЃ
ЕквЛжжбЁдёХХађ?
жБНгбЁдёХХађ :дкдЊЫиМЏКЯ array[i]--array[n-1] жабЁдёЙиМќТызюДѓ ( аЁ ) ЕФЪ§ОндЊЫиШєЫќВЛЪЧетзщдЊЫижаЕФзюКѓвЛИі ( ЕквЛИі ) дЊЫи,дђНЋЫќгыетзщдЊЫижаЕФзюКѓвЛИі(ЕквЛИі)дЊЫиНЛЛЛ ,дкЪЃгрЕФarray[i]--array[n-2] ( array[i+1]--array[n-1] )МЏКЯжа,жиИДЩЯЪіВНжш,жБЕНМЏКЯЪЃгр 1 ИідЊЫи

int min=0;
for(int i=0;i<n-1;i++)
{
if(a[i]<a[min])
min=i;
}
Swap(&a[0],&a[min]);ЖрЬЫЫМТЗ,ГѕЪМдЊЫиЕФЮЛжУдкИФБф,БщРњЕФЧјМфЪ§ФПвВдкИФБф
ДњТыЪЕЯж:
void SelectSort(int* a, int n)
{
for (int j = 0; j < n-1 ; j++)
{
int min = j;
for ( int i = j; i < n; i++)
{
if(a[i] < a[min])
min = i;
}
Swap(&a[j], &a[min]);
}
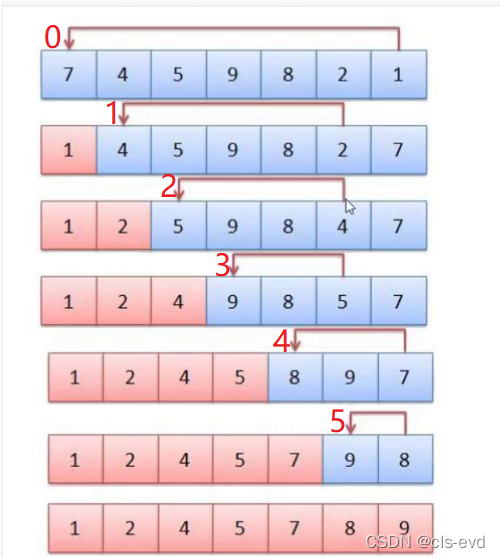
}ЕкЖўжжбЁдёХХађ
ЫМТЗ:БщРњЧјМф? [left,right]? ЭЌЪБбЁГізюаЁЕФКЭзюДѓЕФ,АбзюаЁЕФЗХдкзѓБп,зюДѓЕФЗХдкгвБп,БШИеВХЕФПьвЛБЖ,ЪЧжЎЧАЕФгХЛЏ
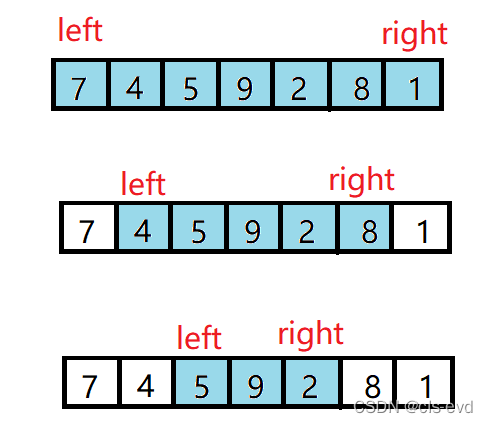
int left = 0;
int right = n - 1;
while (left < right)
{
int min = left;
int max = left;
for (int i = left; i <=right ; i++)
{
if (a[i] < a[min])
min = i;
if (a[i] > a[max])
max = i;
}
Swap(&a[left], &a[min]);
Swap(&a[right], &a[max]);
left++;
right--;
}

? ?
?
?ЮЪЬтЗжЮіМАдвђ
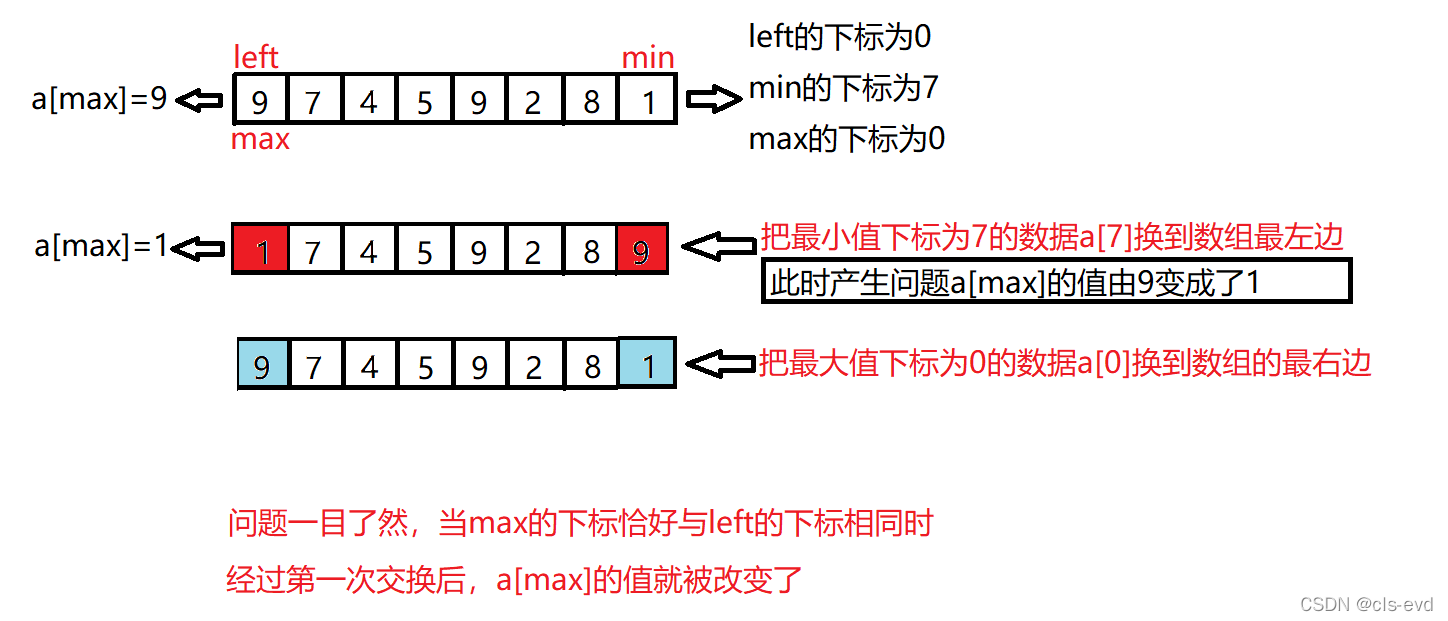
?ИФНјЗНЗЈ,ШчЙћmaxЕФЯТБъгыleftЕФЯТБъЯрЭЌЪБ,жЛашвЊдкЕквЛДЮНЛЛЛжЎКѓ,НЋзюаЁжЕminЕФЯТБъИГИјзюДѓжЕmaxЕФЯТБъКѓМДПЩЁЃ
void SelectSort(int *a,int n)
{
int left = 0;
int right = n - 1;
while (left < right)
{
int min = left;
int max = left;
for (int i = left; i <=right ; i++)
{
if (a[i] < a[min])
min = i;
if (a[i] > a[max])
max = i;
}
Swap(&a[left], &a[min]);
if (left == max)
{
max = min;
}
Swap(&a[right], &a[max]);
left++;
right--;
}
}?ЭъећДњТы:
void SelectSort(int *a,int n)
{
int left = 0;
int right = n - 1;
while (left < right)
{
int min = left;
int max = left;
for (int i = left; i <=right ; i++)
{
if (a[i] < a[min])
min = i;
if (a[i] > a[max])
max = i;
}
Swap(&a[left], &a[min]);
if (left == max)
{
max = min;
}
Swap(&a[right], &a[max]);
left++;
right--;
}
}ЖбХХађ
ВЉжїжЎЧАгаЙ§ЯъНт:
ДЋЫЭУХ:(14ЬѕЯћЯЂ) Ъ§ОнНсЙЙжЎЁОЖбЯъНтЁП_clsЕФВЉПЭ-CSDNВЉПЭ
(14ЬѕЯћЯЂ) Ъ§ОнНсЙЙжЎЁОЖбХХађЁП_clsЕФВЉПЭ-CSDNВЉПЭ
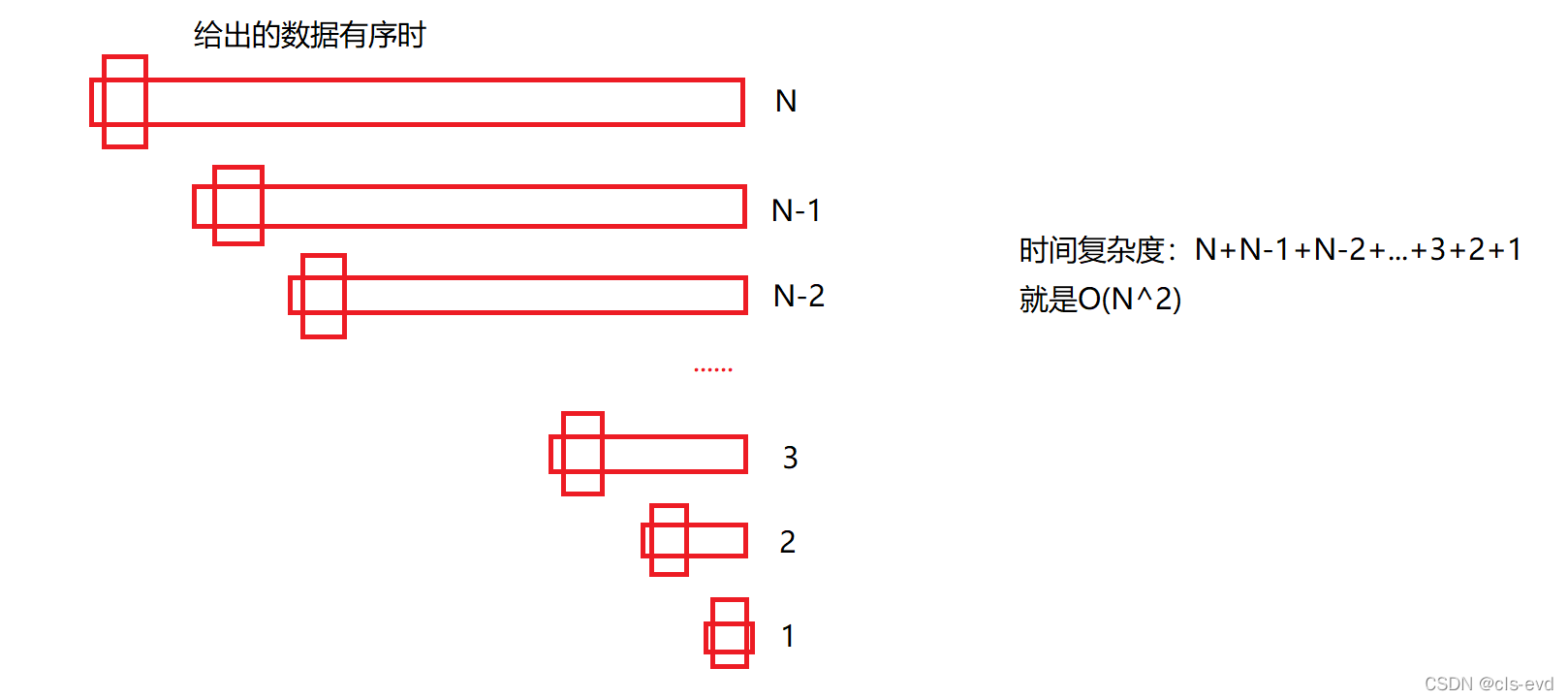
ЖбХХађПЯЖЈвЊгХгкжБНгбЁдёХХађЁОO(N^2)ЁПВХЛсгаМлжЕЁЃ
ФЧУДХХЩ§ађЪЧгУДѓЖбЛЙЪЧаЁЖб?
Д№АИЪЧ:НЈДѓЖбЁЃ
Щ§ађ,ЮЊЪВУДВЛФмНЈаЁЖб?
ЮЪЬтдкгкбЁГізюаЁЕФЪ§зжКѓШчКЮбЁГіДЮаЁЕФЪ§зж
? ? НЈЖббЁГізюаЁЕФЪ§,ЛЈСЫO(N),НєНгзХбЁдёДЮаЁЕФЪ§,ЪЃЯТЕФN-1ИіЪ§МЬајНЈЖб,гжЪЧO(N), зюжеГЩЮЊN^2{вђЮЊЪЃЯТЪ§зжЕФИИзгЙиЯЕЭъШЋТвСЫ,жЛФмжиаТНЈЖб,аЇТЪЬЋЕЭ}
? ? етбљНЈЖбХХађЕФЪБМфИДдгЖШОЭКЭжБНгХХађвЛбљУЛгаЪВУДЪЕМЪЕФвтвхЁЃВЛЪЧВЛПЩвд,ЖјЪЧУЛгаЪВУДМлжЕЁЃ
ЖјЭЈЙ§НЈДѓЖб,
ЪзЯШбЁГізюДѓЕФЪ§зж,ШУЫќгызюКѓвЛИіЪ§зжНЛЛЛ,НєНгзХбЁдёДЮДѓЕФЪ§,ВЛАбзюКѓвЛИіЪ§ПДзіЪЧЖбРяУцЕФ,ЯђЯТЕїећОЭФмбЁГіДЮДѓЕФ
ЫМТЗШчЭМ:
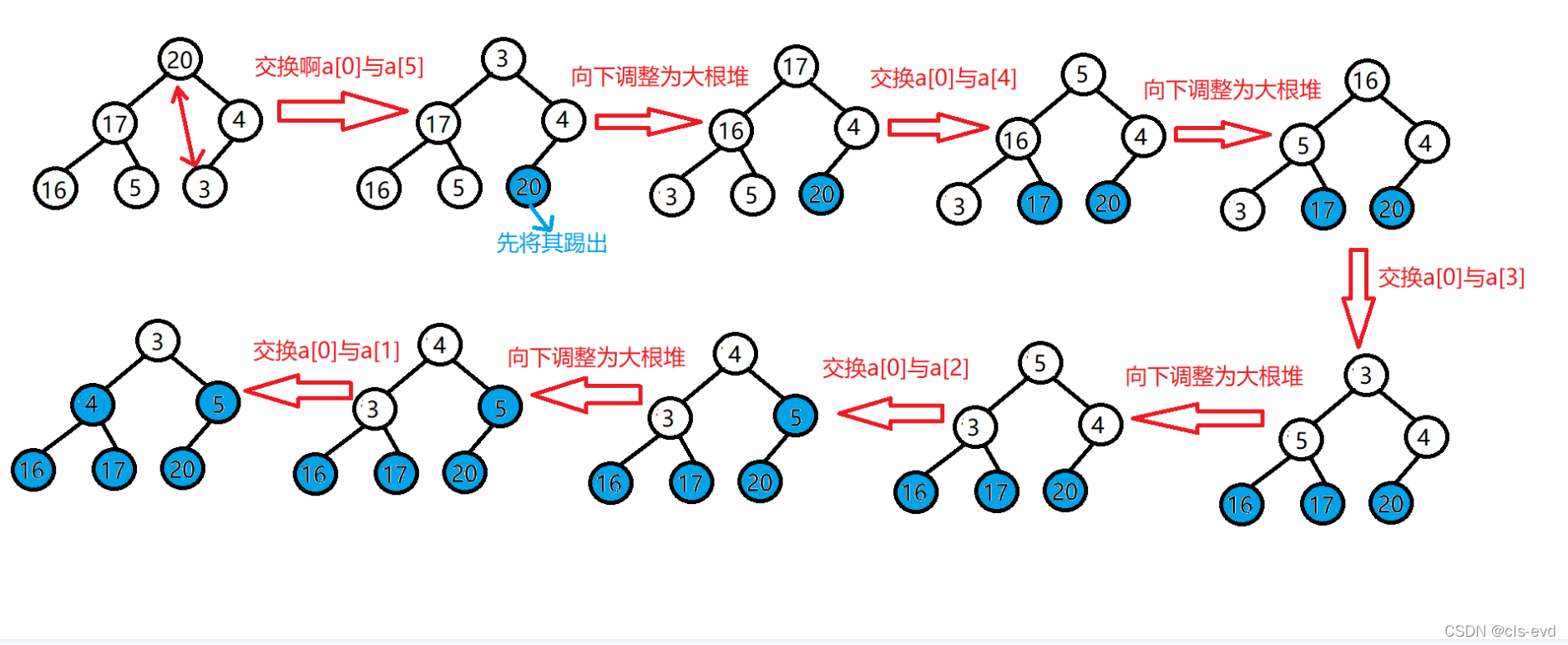
?ЭЌРэХХНЕађ ОЭгІИУНЈаЁЖб,двђМАЫМТЗКЭЩЯУцЭъШЋвЛжТЁЃ
?ХХЩ§ађДњТыШчЯТ:
void HeapSort(int* a, int n)
{
?? ?for (int i = (n - 1 - 1) / 2;i >= 0;i--)
?? ?{
?? ??? ?AdjustDown(a, n, i);
?? ?}
?? ?int end = n - 1;
?? ?while (end > 0)
?? ?{
?? ??? ?Swap(&a[0],&a[end]);
?? ??? ?AdjustDown(a, end, 0);
?? ??? ?end--;
?? ?}
}
?
?ЖбХХађЕФЪБМфИДдгЖШОЭЪЧ:O(NlogN) [ N+NlogN,NЯрЖдгкlogNЬЋаЁСЫПЩвдКіТд]
?МђЕЅЗжЮіЯТ,ЖбХХађКЭУАХнХХађЕФВюБ№гаЖрДѓЪ§зжаЁСЫПДВЛГіРДЩЖЧјБ№
?МйЩшХХ100WИіЪ§зжЁЃ
?N^2 ашвЊ100вкДЮ
?NlogN ашвЊ 100W*20 ДЮ ЖбХХЕФгХЪЦОЭЯдЪОГіРДСЫ
ЭъећДњТы:
#include <stdio.h>
?
void Swap(int* p1, int* p2)
{
?? ?int tmp = *p1;
?? ?*p1 = *p2;
?? ?*p2 = tmp;
}
?
void AdjustDown(int* a, int n, int parent)
{
?? ?//евГізѓгвКЂзгаЁЕФФЧИі
?? ?int child = parent * 2 + 1; //зѓКЂзг
?? ?while (child < n)
?? ?{
?? ??? ?//евГізѓгвКЂзгаЁЕФФЧвЛИі
?? ??? ?if (child + 1 < n && a[child + 1] > a[child]) ?
?? ??? ?{
?? ??? ??? ?//ФЌШЯзіКЂзгаЁ,ШчЙћгвКЂзгаЁОЭ++,МгЕНгвКЂзг
?? ??? ??? ?++child;
?? ??? ?}
?? ??? ?if (a[child] > a[parent])
?? ??? ?{
?? ??? ??? ?Swap(&a[parent], &a[child]);
?? ??? ??? ?parent = child;
?? ??? ??? ?child = parent * 2 + 1;
?? ??? ?}
?
?? ??? ?else ?//bЧщПі
?? ??? ?{
?? ??? ??? ?break;
?? ??? ?}
?? ??? ?
?? ?}
}
void HeapSort(int* a, int n)
{
?? ?for (int i = (n - 1 - 1) / 2;i >= 0;i--)
?? ?{
?? ??? ?AdjustDown(a, n, i);
?? ?}
?? ?int end = n - 1;
?? ?while (end > 0)
?? ?{
?? ??? ?Swap(&a[0],&a[end]);
?? ??? ?AdjustDown(a, end, 0);
?? ??? ?end--;
?? ?}
}
?
?
?
int main()
{
?? ?//ЧАЬсзѓгвзжЪїЪЧаЁЖб
?? ?int a[] = { 15,18,28,34,65,19,49,25,37,27 };
?? ?int n = sizeof(a) / sizeof(a[0]);
?? ?HeapSort(a, n);
?? ?return 0;
}УАХнХХађ
ЛљБОЫМЯы:ЫљЮННЛЛЛ,ОЭЪЧИљОнађСажаСНИіМЧТММќжЕЕФБШНЯНсЙћРДЖдЛЛетСНИіМЧТМдкађСажаЕФЮЛжУ,НЛЛЛХХ ађЕФЬиЕуЪЧ:НЋМќжЕНЯДѓЕФМЧТМЯђађСаЕФЮВВПвЦЖЏ,МќжЕНЯаЁЕФМЧТМЯђађСаЕФЧАВПвЦЖЏЁЃ

ДњТыЪЕЯж,ЮЪЬтВ№Нт
1.0 ЕЅЬЫХХ? ЫМЯы,ШчЙћЧАвЛИіЪ§ДѓгкКѓвЛИіЪ§ОЭНЛЛЛ,зюжеЪЕЯжНЋзюДѓЕФЪ§ОнЗХдкЪ§зщФЉЮВ
for (int i = 0; i < n - 1; i++)
{
if (a[i] > a[i + 1])
{
Swap(&a[i], &a[i + 1]);
}
}?2.0 ЖрЬЫХХ ЛљБОЫМЯы:вбОдкФЉЮВЪ§ОнОЭВЛгУдйШЅЙм,ПижЦЕЅЬЫХХађЕФГЄЖШМДПЩ,вВОЭЪЧЭМжаТЬЩЋПђжЎЧАЕФВПЗж
ЕквЛжжЗНЗЈ:
for (int j = 0; j < n; j++)
{
for (int i = 0; i < n - 1 - j; i++)
{
if (a[i] > a[i + 1])
{
Swap(&a[i], &a[i + 1]);
}
}
}?ЕкЖўжжЗНЗЈ:
for (int end = n;end > 0;--end)
{
for (int i = 0;i < end - 1;i++)
{
if (a[i] > a[i + 1])
{
Swap(&a[i], &a[i + 1]);
}
}
}?гХЛЏ
?ЖдвЛзщгаађЕФЪ§Жјбд,ЫќЪЧВЛНјааНЛЛЛЕФ,вђДЫЮвУЧЩшжУвЛИіexchangeНјааМьВщ,ШчЙћУЛЗЂЩњНЛЛЛОЭжЄУїЫќЪЧгаађЕФЕФ,жБНгЬјГіНсЪјГЬађЁЃ
for (int end = n;end > 0;--end)
{
int exchange = 0;
for (int i = 0;i < end - 1;i++)
{
if (a[i] > a[i + 1])
{
Swap(&a[i], &a[i + 1]);
exchange = 1;
}
}
if (exchange == 0)
{
break;
}
}УАХнХХађЕФЬиадзмНс:
1. УАХнХХађЪЧвЛжжЗЧГЃШнвзРэНтЕФХХађ2. ЪБМфИДдгЖШ: O(N^2)3. ПеМфИДдгЖШ: O(1)4. ЮШЖЈад:ЮШЖЈ
УАХнХХађКЭВхШыХХађБШНЯ:
ЫГађгаађ:ЫћСЉвЛбљКУ
НгНќгаађ:ВхШыХХађКУ??
ПьЫйХХађ:
ПьХХЕФИљБОЫМЯыЛЙЪЧЗжжЮ1.0? ХХЕЅЬЫЧјМф2.0? ЯёЖўВцЪївЛбљЕнЙщХХађЫќЕФзѓгвзгЪї
НЋЧјМфАДееЛљзМжЕЛЎЗжЮЊзѓгвСНАыВПЗжЕФГЃМћЗНЪНга:1. hoare АцБО2. ЭкПгЗЈ3. ЧАКѓжИеыАцБОPS:вдЯТДњТыВЉжїаДСЫгаЗЕЛижЕКЭЮоЗЕЛижЕЕФ,СНепУЛШЮКЮЧјБ№,гаЗЕЛижЕжЛЪЧЮЊСЫБугкИДгУЁЃ
hoareЗЈ(зѓгвжИеыЗЈ)
ПьХХЪзЯШНјааЕЅЬЫХХађ
? ?бЁГівЛИіЪ§зжKey,вЛАуЪЧзюзѓБпЕФ,ЛђепЪЧзюгвБпЕФ,KeyЗХЕНЫќЕФе§ШЗЕФЮЛжУЩЯШЅ,зѓБпЕФвЊБШKeyаЁ,гвБпЕФвЊБШKeyДѓ
? бЁдёзѓБпЕФжЕзїЮЊKey,rightЯШзп,rightевБШkeyаЁЕФжЕ,leftевБШkeyДѓЕФжЕ,евЕНжЎКѓНјааНЛЛЛ,жБЕНЫћСЉЯргі,зюКѓдйАбkeyгызѓгвЯргіЕиЗНЕФжЕНЛЛЛ
зюжеkeyЫљдкЕФЮЛжУОЭЪЧ,ЫћдкзюКѓХХКУађЕФЕФвЛЖбЪ§РяУцЕФЮЛжУ,ШчЯТЭМ,6зюжеЕФЮЛжУОЭЪЧЫћдкзюКѓгаађЪ§зжжаЕФЮЛжУ,ЮЛгкЕкСљИі
ЫМТЗЭМ:
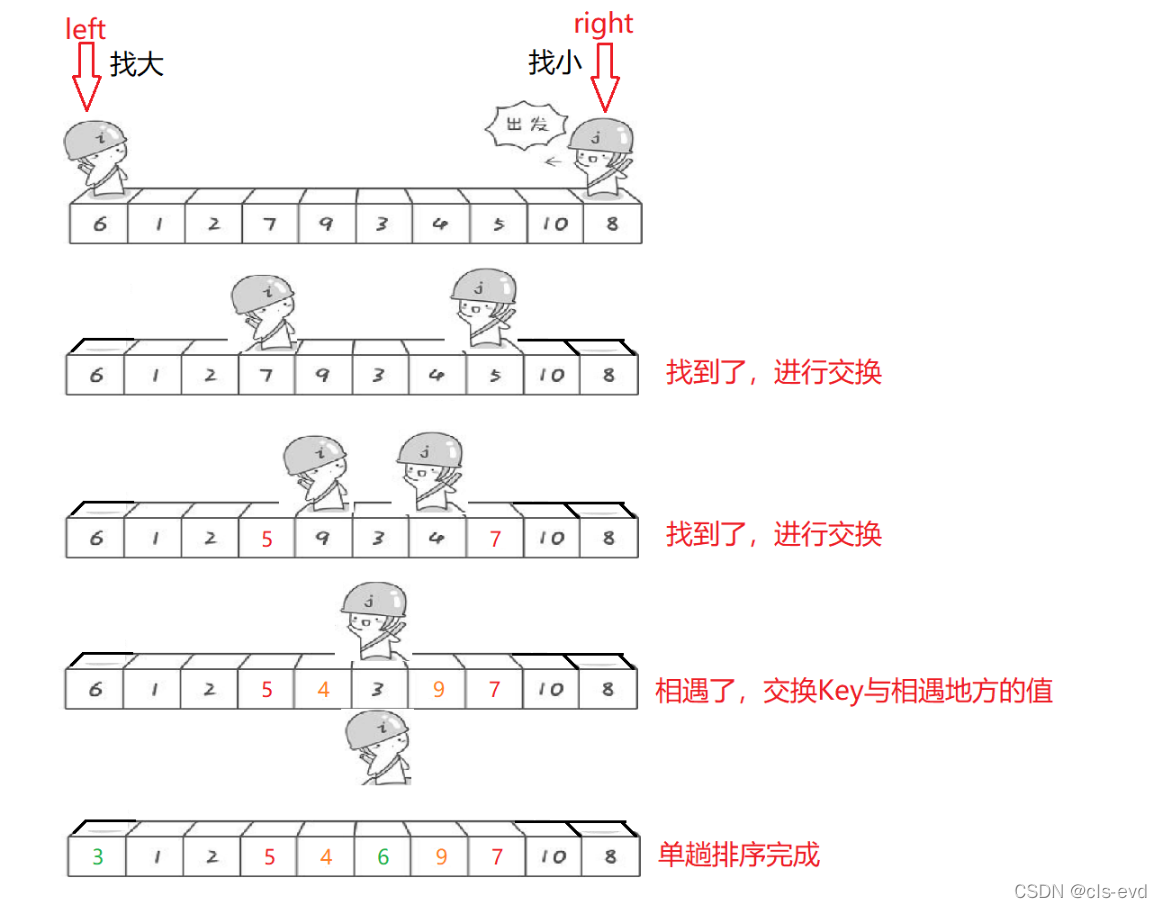
ЮЊЪВУДзѓБпзіkey,вЊШУгвБпЯШзп?
ЯргіДцдкСНжжЧщПі:зѓгіЕНгвгыгвгіЕНзѓ
ШчЙћзѓБпзіkey,зѓБпЯШзп,зюжеНсЙћШчЭМ

?ДяВЛЕНЮвУЧЕФдЄЦк(keyЕФзѓБпЖМБШЫќаЁ,гвБпЖМБШЫќДѓ)
ЖјШУгвБпЯШзп,ЮоТлЪЧзѓгігв,ЛЙЪЧгвгізѓ,ЖМПЩвдБЃжЄзюКѓНсЪјЕФЮЛжУЕФжЕБШkeyЕФжЕвЊаЁ
?зѓгвжИеыЗЈЕФДњТы
void PartSort1(int* a, int n)
{
int left = 0, right = n - 1;
int keyi = left;
while (left < right)
{
while (a[right] >= a[keyi])
{
right--;
}
while (a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[keyi], &a[right]);
}ЕЋЪЧвдЩЯДњТыДцдквЛИіЮЪЬт:ЖдетбљЕФвЛжжЧщПі

 ?етВПЗжДњТыОЭЛсвЛжБНјаа,дьГЩдННчЕФЧщПі;
?етВПЗжДњТыОЭЛсвЛжБНјаа,дьГЩдННчЕФЧщПі;
?ЭЌЪБ![]() ,
,![]() ЫћУЧжЎМфЕФЕШгкКХвВЪЧБиВЛПЩЩйЕФ
ЫћУЧжЎМфЕФЕШгкКХвВЪЧБиВЛПЩЩйЕФ
ШчЙћШЅЕєЕШгкКХ,ЖдетбљЕФЧщПіОЭЛсдьГЩЫРбЛЗ

?вЛжБНЛЛЛзѓгвСНБпЕФ5.
зюжезѓгвжИеыЗЈЕФЭъећДњТыШчЯТ:(ЮоЗЕЛижЕЕФ)
void PartSort1(int* a, int n)
{
int left = 0, right = n - 1;
int keyi = left;
while (left < right)
{
while (left < right && a[right] >= a[keyi])
{
right--;
}
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[keyi], &a[right]);
}гаЗЕЛижЕЕФ
int PartSort1(int* a, int left, int right)
{
int keyi = left;
while (left < right)
{
//еваЁ
while (left < right && a[right] >= a[keyi])
{
right--;
}
//евДѓ
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[keyi], &a[left]);
return left;
}ЕЅИіЧјМфЕФХХађвбОЭъГЩ,жЎКѓдйНјаазѓгвЧјМфЕФЕнЙщ,вВОЭЪЧећИіПьХХЕФЙ§ГЬ
?НЋЪ§зщЗжЮЊ? [begin,meeti-1]? meeti? [meeti+1,end] Ш§ВПЗж,ЕнЙщетСНИіЧјМф,meetОЭЪЧУПДЮзѓгвЯргіЕФЮЛжУ,ЕБетИіЧјМфвЛИіжЕвВУЛгаЛђепжЛгавЛИіжЕОЭНсЪј,
ЭъећЕФПьХХДњТыШчЯТ:(ШчЙћНіЪЧаДвЛИіПьХХетбљаДМДПЩ)
void QuickSort(int* a, int begin, int end)
{
if (begin >= end)
{
return;
}
int left = begin;
int right = end;
int keyi = left;
while (left < right)
{
//еваЁ
while (left < right && a[right] >= a[keyi])
{
right--;
}
//евДѓ
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
int meeti = left; //Лђеп int meeti = right; ЖМЪЧПЩвдЕФ
Swap(&a[keyi], &a[meeti]);
// [begin,meeti-1] meeti [meeti+1,end]
QuickSort(a, begin, meeti - 1);
QuickSort(a, meeti + 1, end);
}ЭкПгЗЈ:
ЪБМфИДдгЖШO(N)
ЛљБОЫМТЗ
ЯШеввЛИізюзѓБпЛђепзюгвБпЕФжЕДцЦ№РД,
1.0? ЮвУЧдкетРябЁдёзюзѓБпЕФжЕзїЮЊkeyНЋЫќБЃДцЦ№РД,етбљЫћОЭаЮГЩСЫвЛИіПг,
2.0? ДггвБпПЊЪМевБШkeyаЁЕФжЕ,евЕНжЎКѓАбЫќЗХЕНИеПЊЪМЕФетИіПгРяШЅ,етИіЕиЗНОЭаЮГЩвЛИіаТЕФПг
3.0 дйДгзѓБпПЊЪМевБШkeyДѓЕФжЕ,евЕНжЎКѓдйАбЫќЗХЕНаТЕФПгРяШЅ,бЛЗ2,3ВНжБЕНзѓгыгвЯргі
4.0 зюКѓзѓгвЯргіЭЃжЙЪБ,АбkeyЗХЕНзюжеНсЪјЕФПгжаШЅЁЃ
PS:ШчЙћПЊЪМевЕФЪЧзюгвБпЕФжЕ,ОЭвЊДгзѓБпПЊЪМ,вВОЭЪЧ2 ,3ВНЛЛЯТЫГађ
ЫМТЗЭМШчЯТ:

ДњТыШчЯТ:
int PartSort2(int* a, int left, int right)
{
int key = a[left];
while (left < right)
{
//еваЁ
while (left < right && a[right] >= key)
{
right--;
}
//евЕНКѓЗХЕНзѓБпЕФПгжаШЅ,гвБпаЮГЩаТЕФПг
a[left] = a[right];
//евДѓ
while (left < right && a[left] <= key)
{
left++;
}
//евЕНКѓЗХЕНгвБпЕФПгжаШЅ,зѓБпаЮГЩаТЕФПг
a[right] = a[left];
}
//НЋИеПЊЪМБЃДцЕФЪ§зжЗХЕНзѓгвЯргіЕФЕиЗНЕФПгжаШЅ
a[left] = key;
return left;
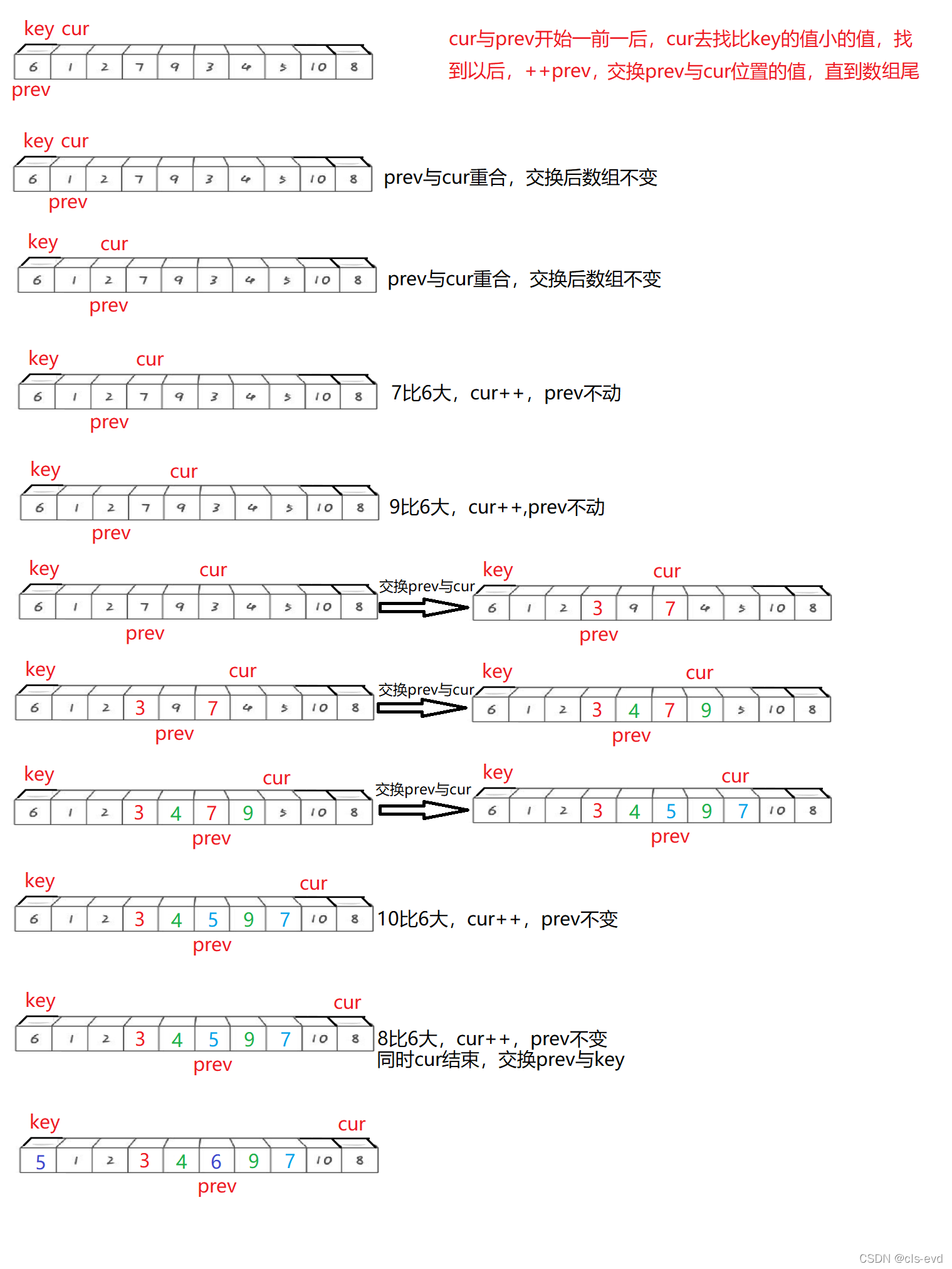
}зѓгвжИеыЗЈ:
ЫМТЗ:етРяЮвУЧбЁШЁзюзѓБпЕФЕБзіkey,ЩшжУcurгыprev,ПЊЪМвЛЧАвЛКѓ,curШЅевБШkeyаЁЕФжЕ,евЕНвдКѓ++prev,ЭЌЪБНЛЛЛprevгыcur,жБЕНЪ§зщЮВ
ЫМТЗЭМ:
ДњТыШчЯТ:
int PartSort3(int *a,int left,int right)
{
int key = left;
int cur = key + 1;
int prev = key;
while (cur <= right)
{
if (a[cur] < a[key] && ++prev != cur)
{
Swap(&a[cur], &a[prev]);
}
cur++;
}
Swap(&a[key],&a[prev]);
return prev;
}дкбЇЯАЩЯЪіШ§жжЗНЗЈКѓПьХХНјЖјПЩвдаДГЩетбљ:ЕЅЬЫХХЯыгУФЧжжЗНЗЈ,ОЭгУФФжжЗНЗЈ
void QuickSort(int* a, int begin,int end)
{
if (begin >= end)
{
return;
}
int keyi = PartSort3(a,begin,end); //ЯыгУЦфЫћЕЅЬЫХХЕФЗНЗЈИФЯТетМДПЩ
// [begin,keyi-1] keyi [keyi+1,end]
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi + 1, end);
}ПьХХЕФЪБМфИДдгЖШO(NlogN)
РэЯыЕФПьХХЧщПі,УПДЮЕЅЬЫХХЖМЪЧЖўЗж,бЁЕФkeyУПДЮЖМЪЧетзщЪ§ОнЕФжаЮЛЪ§ ,ЪБМфИДдгЖШОЭЪЧO(NlogN)

зюЛЕЕФЧщПі:МДИјГіЕФЪ§ОнЪЧгаађЕФ,ЪБМфИДдгЖШОЭЪЧO(N^2)
?еыЖдзюЛЕЕФЧщПіЮвУЧНјаавдЯТгХЛЏ:
1.0 Ш§Ъ§ШЁжа
2.0 аЁЧјМфгХЛЏ
?ЗжЮівЛЯТЖдПьХХгАЯьзюДѓЕФЪЧбЁЕФkey,ШчЙћkeyдННгНќжаЮЛЪ§,ОЭдННгНќЖўЗж,аЇТЪОЭдНИп
Ш§Ъ§ШЁжаЗЈ
Ш§ИіЪ§ЗжБ№ЪЧвЛзщЪ§ОнжазюзѓБпЕФЪ§,зюгвБпЕФЪ§,КЭжаМфЕФФЧИіЪ§,ШЁГіетШ§ИіЪ§жазюаЁЕФФЧИіЪ§,етбљОЭПЩвдБмУтгаађЕФЧщПіЁЃ
ДњТыШчЯТ:left rightЖМжИЕФЪЧЯТБъ
int GetMidIndex(int* a, int left, int right)
{
int mid = (left + right) >> 1;
//left mid right
if (a[left] < a[mid])
{
if (a[mid] < a[right])
{
return mid;
}
else if (a[right] < a[left])
{
return left;
}
else
{
return right;
}
}
else
{
if (a[mid] > a[right])
{
return mid;
}
else if (a[left] < a[right])
{
return left;
}
else
{
return right;
}
}
}?ЪЙгУЗНЗЈ:ЮвУЧдкPastsortжаШЮШЛЪЧШЁзюзѓУцЕФвЛИі,жЛашвЊдкУПИіPastsortжаМгШывдЯТетЖЮДњТыМДПЩЁЃ
int midIndex = GetMidIndex(a, left, right);
Swap(&a[left], &a[midIndex]);eg:Pastsort1ЁЃ
int PartSort1(int* a, int left, int right)
{
int midIndex = GetMidIndex(a, left, right);
Swap(&a[left], &a[midIndex]);
int keyi = left;
while (left < right)
{
//еваЁ
while (left < right && a[right] >= a[keyi])
{
right--;
}
//евДѓ
while (left < right && a[left] <= a[keyi])
{
left++;
}
Swap(&a[left], &a[right]);
}
Swap(&a[keyi], &a[left]);
return left;
}аЁЧјМфгХЛЏ:
? ? ? ЕБЕнЙщЕНзюКѓЕФЪБКђ,дНЕнЙщЕНзюКѓ,ЕнЙщЕФДЮЪ§ОЭдНЖр,вђЮЊПьХХЕФЕнЙщЯрЕБгквЛПХЭъШЋЖўВцЪї,зюКѓМИВужДааЕФДЮЪ§ОЭЪЧ2^nИННќ,ЫљвдЮЊСЫМѕЩйЕнЙщЕФДЮЪ§,ЮвУЧПЩвдевЦфЫћХХађАяжњЮвУЧЁЃ
1.0 ШчЙћзгЧјМфЪ§ОнКмЖр,МЬајбЁдёkeyЕЅЬЫ,ЗжИюзгЧјМфЗжжЮЕнЙщ
2.0 ШчЙћзгЧјМфЪ§ОнКмаЁ,дйШЅЕнЙщВЛЬЋЛЎЫугУВхХХДњЬцPS:аЁЧјМфгХЛЏВЂВЛЬЋУїЯд,двђЪЧЫќЫфШЛМѕЩйЕнЙщЪїЕФзюКѓМИВу,гХЛЏЕНгаНЯЩйЕФЕнЙщЕїгУВуЪ§,ЕЋЪЧВхШыХХађвВЪЧгаЯћКФЕФЁЃ
ВхШыХХађЕФДЋжЕ: вђЮЊВхХХаЮВЮДЋЕФЪЧЪ§зщгыИіЪ§,ЫљвдЮвУЧНЋПьХХЕФЧјМфзЊЛЏГЩЪ§зщгыИіЪ§ЁЃ
вђЮЊВхХХаЮВЮДЋЕФЪЧЪ§зщгыИіЪ§,ЫљвдЮвУЧНЋПьХХЕФЧјМфзЊЛЏГЩЪ§зщгыИіЪ§ЁЃ
ОЙ§гХЛЏЕФПьХХШчЯТ:
void QuickSort(int* a, int begin,int end)
{
if (begin >= end)
{
return;
}
int keyi = PartSort3(a,begin,end);
//1.0 ШчЙћзгЧјМфЪ§ОнКмЖр,МЬајбЁдёkeyЕЅЬЫ,ЗжИюзгЧјМфЗжжЮЕнЙщ
//2.0 ШчЙћзгЧјМфЪ§ОнКмаЁ,дйШЅЕнЙщВЛЬЋЛЎЫугУВхХХДњЬц
if (end - begin > 10)
{
// [begin,keyi-1] keyi [keyi+1,end]
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi + 1, end);
}
else
{
InsertSort(a + begin, end - begin + 1);
}
}ПьХХЕФЗЧЕнЙщаДЗЈ
ЕнЙщ,ЯждкЕФБрвыЦїгХЛЏКмКУ,адФмВЛЪЧДѓЕФЮЪЬт
ЕнЙщзюДѓЕФЮЪЬтОЭЪЧЕнЙщЕФЩюЖШЬЋЩю,ГЬађБОЩэУЛгаЮЪЬт,ЕЋЪЧеЛЕФПеМфВЛЙЛ,ЕМжТеЛвчГі
жЛФмИФГЩЗЧЕнЙщ,ИФГЩЗЧЕнЙщДцдкСНжжЗНЪН
1.0 жБНгИФГЩбЛЗ Р§ШчьГВЈФЧЦѕЪ§
2.0 ЪїБщРњЗЧЕнЙщКЭПьХХЗЧЕнЙщ,жЛФмНшжњеЛРДЪЕЯжФЃФтЕнЙщЕФЙ§ГЬ
ЪзЯШЮвУЧвЊУїАзеЛЪЧКѓНјЯШГіЕФ,ПьХХЕФЕнЙщ,ЕнЙщЕФЪЧвЛЖЮЧјМф
ЮвУЧгУЪЎИіЪ§зжОйР§,МйЩшШчЭМЪЧЕнЙщЕФШЋЙ§ГЬ
 ? ? ?ЕнЙщЕФЫГађПЩвдРрБШЮЊЖўВцЪїЕФЧАађБщРњвВОЭЪЧИљзѓгв,ЮвУЧгУеЛФЃФтетИіЕнЙщЕФЙ§ГЬ,ЮвУЧЯШШУ09ШыеЛЖд[0 9]ЧјМфевkey,дйШы69, 04 вђЮЊКѓНјЯШГі,дйШы34, 01,зюКѓШы89, 6,етбљОЭЭъУРФЃФтСЫећИіЕнЙщЕФЙ§ГЬ,ШчЙћЮвУЧЯывЊЕнЙщЕФЫГађЪЧИљгвзѓ,ОЭЯШШУ09 ШыеЛ,дйШы04,69,дйШы01 34,дйШы6,89МДПЩ,ЗДвЛЯТЁЃ?
? ? ?ЕнЙщЕФЫГађПЩвдРрБШЮЊЖўВцЪїЕФЧАађБщРњвВОЭЪЧИљзѓгв,ЮвУЧгУеЛФЃФтетИіЕнЙщЕФЙ§ГЬ,ЮвУЧЯШШУ09ШыеЛЖд[0 9]ЧјМфевkey,дйШы69, 04 вђЮЊКѓНјЯШГі,дйШы34, 01,зюКѓШы89, 6,етбљОЭЭъУРФЃФтСЫећИіЕнЙщЕФЙ§ГЬ,ШчЙћЮвУЧЯывЊЕнЙщЕФЫГађЪЧИљгвзѓ,ОЭЯШШУ09 ШыеЛ,дйШы04,69,дйШы01 34,дйШы6,89МДПЩ,ЗДвЛЯТЁЃ?
ДњТыЪЕЯжШчЯТ(НшжњжЎЧАЪЕЯжЕФеЛ)
Stack.h
#pragma once
#include<stdio.h>
#include<stdlib.h>
#include<assert.h>
#include<stdbool.h>
//typedef int BOOL;
//#define TURE 1;
//#define FALSE 0;
// ОВЬЌЕФеЛ
//typedef int STDataType;
//typedef struct Stack
//{
// STDataType array[1000]; //ОВЬЌЕФеЛОЭЪЧвЛИіЪ§зщ
// int top; //еЛЖЅ
//
//}Stack;
// ЖЏЬЌЕФеЛ
typedef int STDataType;
struct Stack
{
STDataType* a;
int top; //еЛЖЅ
int capacity; //ШнСП,ЗНБудіШн
};
typedef struct Stack Stack;
//ЭЌбљДЋжИеы,аЮВЮИФБфВЛгАЯьЪЕВЮ,ЪЕВЮДЋЙ§ШЅЪЧЫќЕФПНБД
void StackInit(Stack* pst); //ГѕЪМЛЏ
void StackDestory(Stack* pst); //ЯњЛй
//аджЪОіЖЈдкеЛЖЅГіШыЪ§Он
void StackPush(Stack* pst, STDataType x); //ШыеЛ
void StackPop(Stack* pst); //ГіеЛ
//ШЁеЛЖЅЕФЪ§Он
STDataType StackTop(Stack* pst);
// ПеЗЕЛи1,ЗЧПеЗЕЛи0
//int StackEmpty(Stack* pst);
bool StackEmpty(Stack* pst); //ХаЖЯеЛЪЧЗёЮЊПе
int StackSize(Stack* pst); //ЭГМЦеЛжаЕФЪ§ОнStack.c
#include"Stack.h"
void StackInit(Stack* pst)
{
assert(pst);
/*pst->a = NULL;
pst->capacity = 0;
pst->top = 0;*/
pst->a = (STDataType*)malloc(sizeof(STDataType)*4);
pst->capacity = 4;
pst->top = 0;
}
void StackDestory(Stack* pst)
{
assert(pst);
free(pst->a);
pst->capacity = pst->top = 0;
}
void StackPush(Stack* pst, STDataType x)
{
if (pst->top == pst->capacity)
{
STDataType* tmp = (STDataType*)realloc(pst->a,sizeof(STDataType)*(pst->capacity * 2));
if (tmp == NULL)
{
printf("reallocЪЇАм\n");
exit(-1); //НсЪјГЬађ
}
pst->a = tmp;
pst->capacity *= 2;
}
pst->a[pst->top] = x;
pst->top++;
}
void StackPop(Stack* pst)
{
assert(pst);
assert(!StackEmpty(pst));
pst->top--;
}
STDataType StackTop(Stack* pst)
{
assert(pst);
assert(!StackEmpty(pst));
return pst->a[pst->top - 1];
}
bool StackEmpty(Stack* pst)
{
assert(pst);
return pst->top == 0;
}
int StackSize(Stack* pst)
{
assert(pst);
return pst->top ;
}//ФЃФтИљзѓгвЕФЫГађЕнЙщ
void QuickSortNonR(int* a, int begin, int end)
{
Stack st;
StackInit(&st);
StackPush(&st, end);
StackPush(&st, begin);//ЯШШыгв,дйШызѓ
while (!StackEmpty(&st))
{
int left, right;
left = StackTop(&st);//ЫљвдЯШГізѓ,дйГігв
StackPop(&st);
right = StackTop(&st);
StackPop(&st);
int keyi = PartSort1(a, left, right);
if (keyi + 1 < right)
{
StackPush(&st, right);
StackPush(&st, keyi + 1);
}
if (left < keyi - 1)
{
StackPush(&st, keyi - 1);
StackPush(&st, left);
}
}
StackDestory(&st);
}//ФЃФтИљгвзѓЫГађЕФЕнЙщ
void QuickSortNonR(int* a, int begin, int end)
{
Stack st;
StackInit(&st);
StackPush(&st, begin);
StackPush(&st, end);
while (!StackEmpty(&st))
{
int left, right;
right = StackTop(&st);
StackPop(&st);
left = StackTop(&st);
StackPop(&st);
int keyi = PartSort1(a, left, right);
if (left < keyi - 1)
{
StackPush(&st, left);
StackPush(&st, keyi - 1);
}
if (keyi + 1 < right)
{
StackPush(&st, keyi + 1);
StackPush(&st, right);
}
}
StackDestory(&st);
}ЙщВЂХХађ
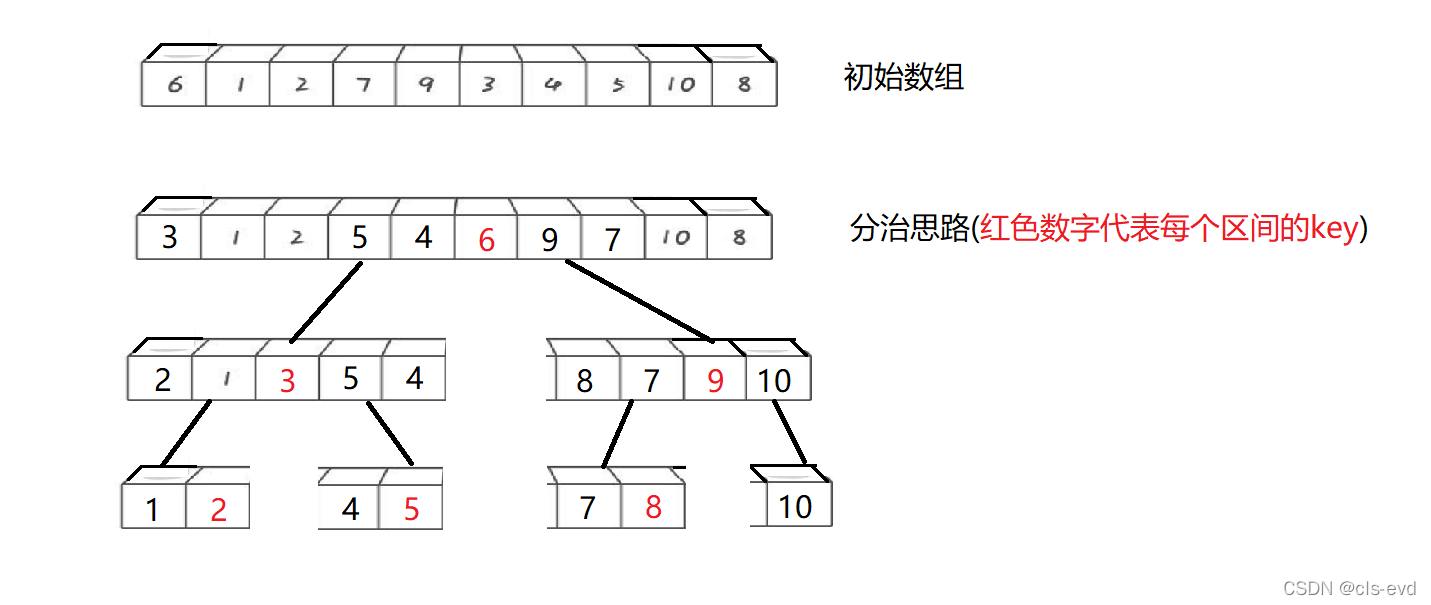
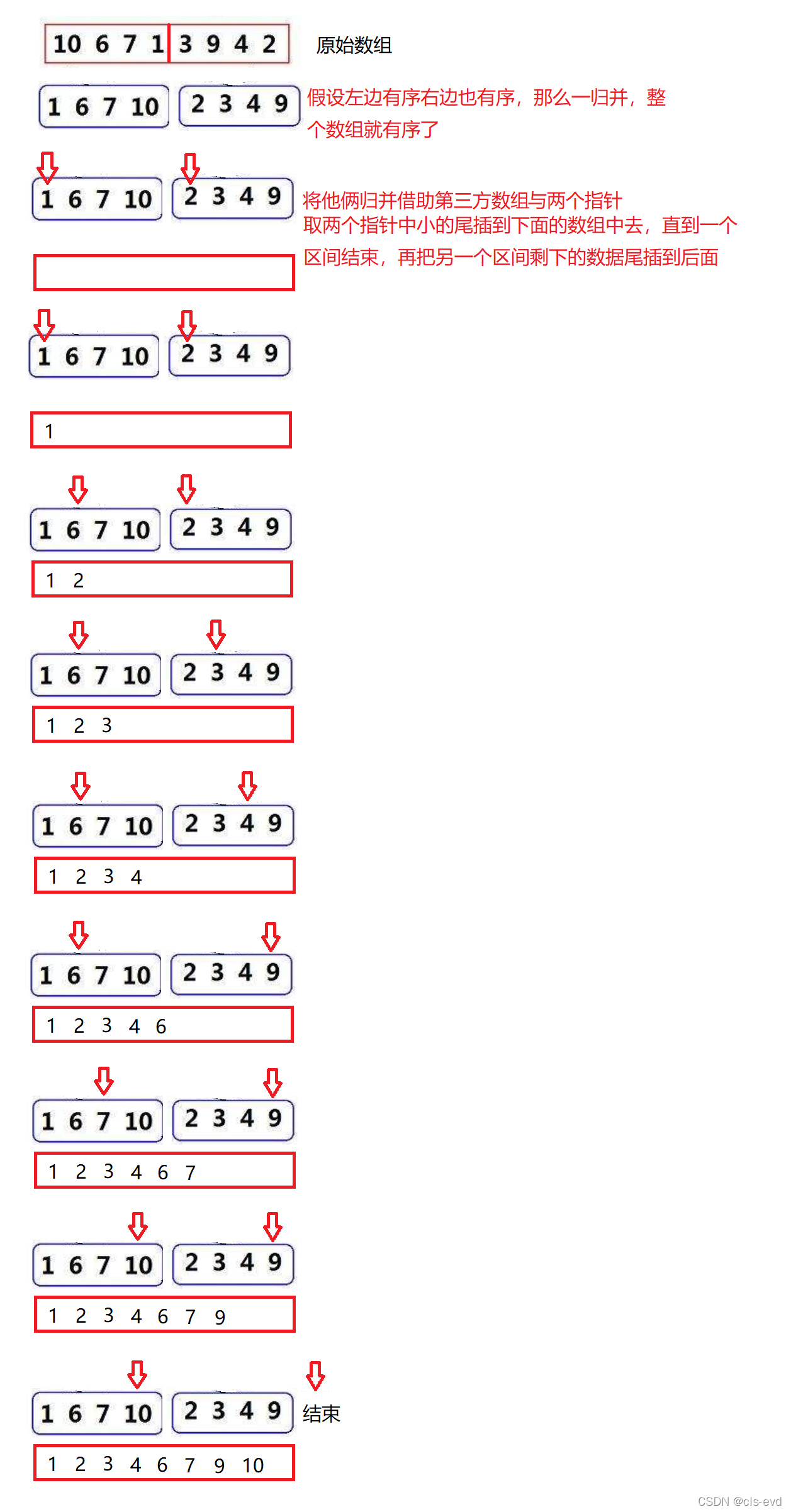
ЛљБОЫМЯы:ЙщВЂХХађ( MERGE-SORT )ЪЧНЈСЂдкЙщВЂВйзїЩЯЕФвЛжжгааЇЕФХХађЫуЗЈ , ИУЫуЗЈЪЧВЩгУЗжжЮЗЈ( Divide and Conquer)ЕФвЛИіЗЧГЃЕфаЭЕФгІгУЁЃНЋвбгаађЕФзгађСаКЯВЂ,ЕУЕНЭъШЋгаађЕФађСа;МДЯШЪЙУПИізгађСагаађ,дйЪЙзгађСаЖЮМфгаађЁЃШєНЋСНИігаађБэКЯВЂГЩвЛИігаађБэ,ГЦЮЊЖўТЗЙщВЂЁЃ
ЙщВЂЕФЫМТЗ:
НЋСНЖЮгаађЕФЧјМфЙщВЂГЩвЛЖЮгаађЕФЧјМфНшжњЕкШ§ЗНЪ§зщгыСЉжИеы,ШЁСНИіжИеыжааЁЕФФЧИіЪ§,ЮВВхЕНЯТУцЕФЪ§зщжаШЅ,жБЕНвЛИіЧјМфНсЪј,дйАбСэвЛИіЧјМфЪЃЯТЕФЪ§ОнЮВВхЕНКѓУц
ЙщВЂЕФЫМТЗЭМ:
ЙщВЂХХађЕФЫМТЗ:ЕнЙщШУЫћзгЧјМфгаађ
ЙщВЂХХађЕФЫМТЗЭМ:(ЙщВЂХХађВЂВЛвЊЧѓСНБпЭъШЋЯрЕШ)
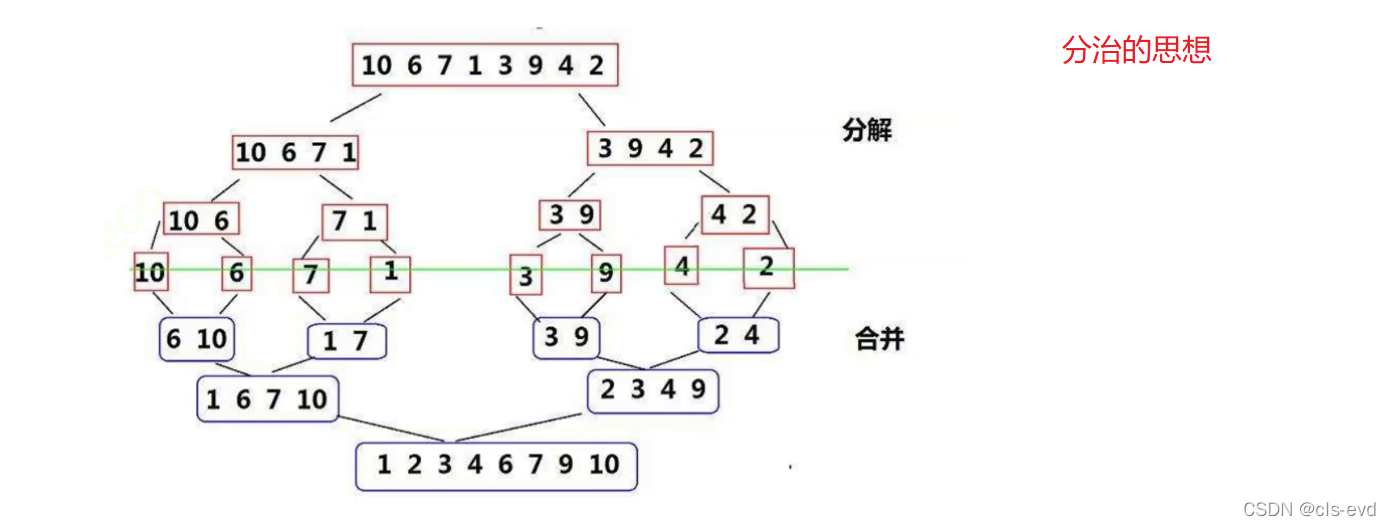
ЙщВЂХХађДњТы
void _MergeSort(int* a, int left, int right,int *tmp)
{
//НсЪјЬѕМў,ЧјМфжЛгавЛИіЛђепВЛДцдк
if (left >= right)
{
return;
}
int mid = (left + right) >> 1;
//[left,mid] [mid+1,right]
_MergeSort(a, left, mid, tmp);
_MergeSort(a, mid + 1, right, tmp);
//СНЖЮгаађзгЧјМфЙщВЂtmp,ВЂЧвПНБДЛиШЅ
int begin1 = left, end1 = mid; //ЕквЛЖЮЧјМф
int begin2 = mid + 1, end2 = right; //ЕкЖўЖЮЧјМф
int i = left;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
//ЙщВЂЭъГЩвдКѓПНБДЛиЕНдЪ§зщ
for (int j = left; j <= right; j++)
{
a[j] = tmp[j];
}
//_Merge(a, tmp, left, mid, mid + 1, right);
}
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
printf("malloc fail");
exit(-1);
}
_MergeSort(a, 0, n - 1, tmp);
free(tmp);
}ЙщВЂХХађЕФЗЧЕнЙщаДЗЈ:
ЫМТЗ:
ЙщВЂЕФЪЧвЛИіаЁзщ,gapОЭДњБэУПИіаЁзщжЎМфгаМИИіЪ§Он,УПДЮЙщВЂЖМЪЧСНзщСНзщНјааЙщВЂ
вЛвЛЙщВЂжИЕФЪЧgapЮЊ1 ЕФСНИіаЁзщНјааЙщВЂ,СНСН,ЫФЫФЭЌРэ
вЛДЮбЛЗДњБэСНИіЧјМфНјааЙщВЂ,бЛЗвЊШЁГіМфИєЮЊgapЕФЫљгаЧјМф
еыЖд [ 10 6 7 1 3 9 4 2 ]етбљвЛИіЪ§зщ
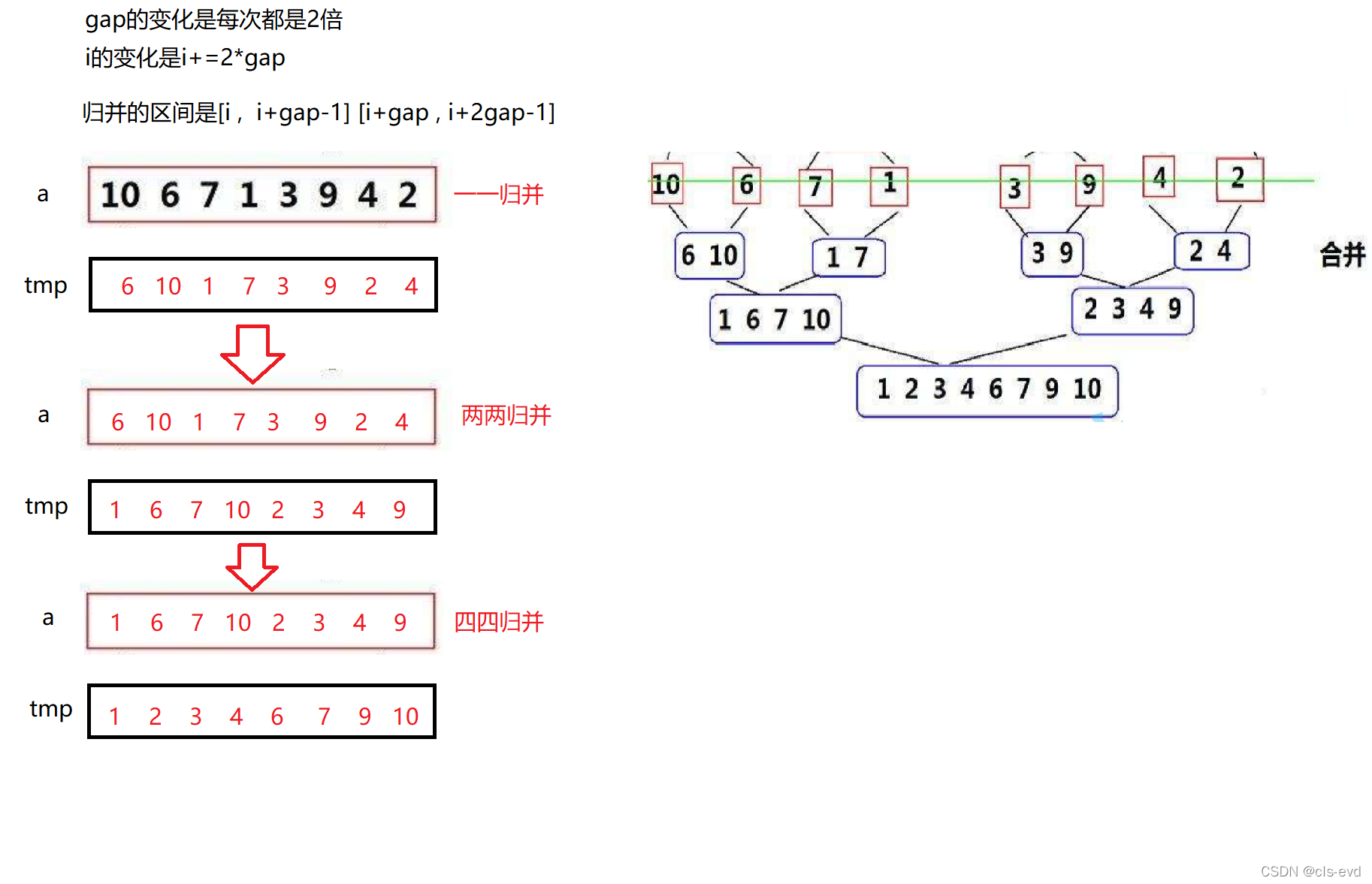
ДњТыШчЯТ:
_Merge(int* a, int* tmp, int begin1, int end1, int begin2, int end2)
{
int j = begin1;
int i = begin1;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
//ЙщВЂЭъГЩвдКѓПНБДЛиЕНдЪ§зщ
for ( j ;j <= end2; j++)
{
a[j] = tmp[j];
}
}
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
printf("malloc fail");
exit(-1);
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
_Merge(a, tmp, i,i+gap-1,i+gap,i+2*gap-1);
}
gap = gap * 2;
}
free(tmp);
}ЕЋЪЧетЖЮДњТыжЛеыЖдЕФШчЩЯЪ§зщ,Ъ§зщжЛга8ИіЪ§Он,вђДЫЮвУЧгЩЬиЪтЭЦЙуЕНвЛАу,ЖдвЛАуЕФЪ§зщЛсДцдквдЯТМИжжЮЪЬт
1.0? зюКѓвЛИіаЁзщЙщВЂЪБ,ЕкЖўИіаЁЧјМфВЛДцдк,ВЛашвЊЙщВЂСЫ
2.0??зюКѓвЛИіаЁзщЙщВЂЪБ,ЕкЖўИіаЁЧјМфДцдк,ЕЋЪЧЕкЖўИіаЁЧјМфВЛЙЛgapИіСЫ
3.0? зюКѓвЛИіаЁзщЙщВЂЪБ,ЕквЛИіаЁЧјМфВЛЙЛgapИіСЫ,ВЛашвЊЙщВЂСЫ????????
ЕкЖўИіаЁЧјМфВЛДцдк,жЛвЊМьВщiЪЧЗёДѓгкnОЭаа?
ШчЭММИжжЮЪЬт:
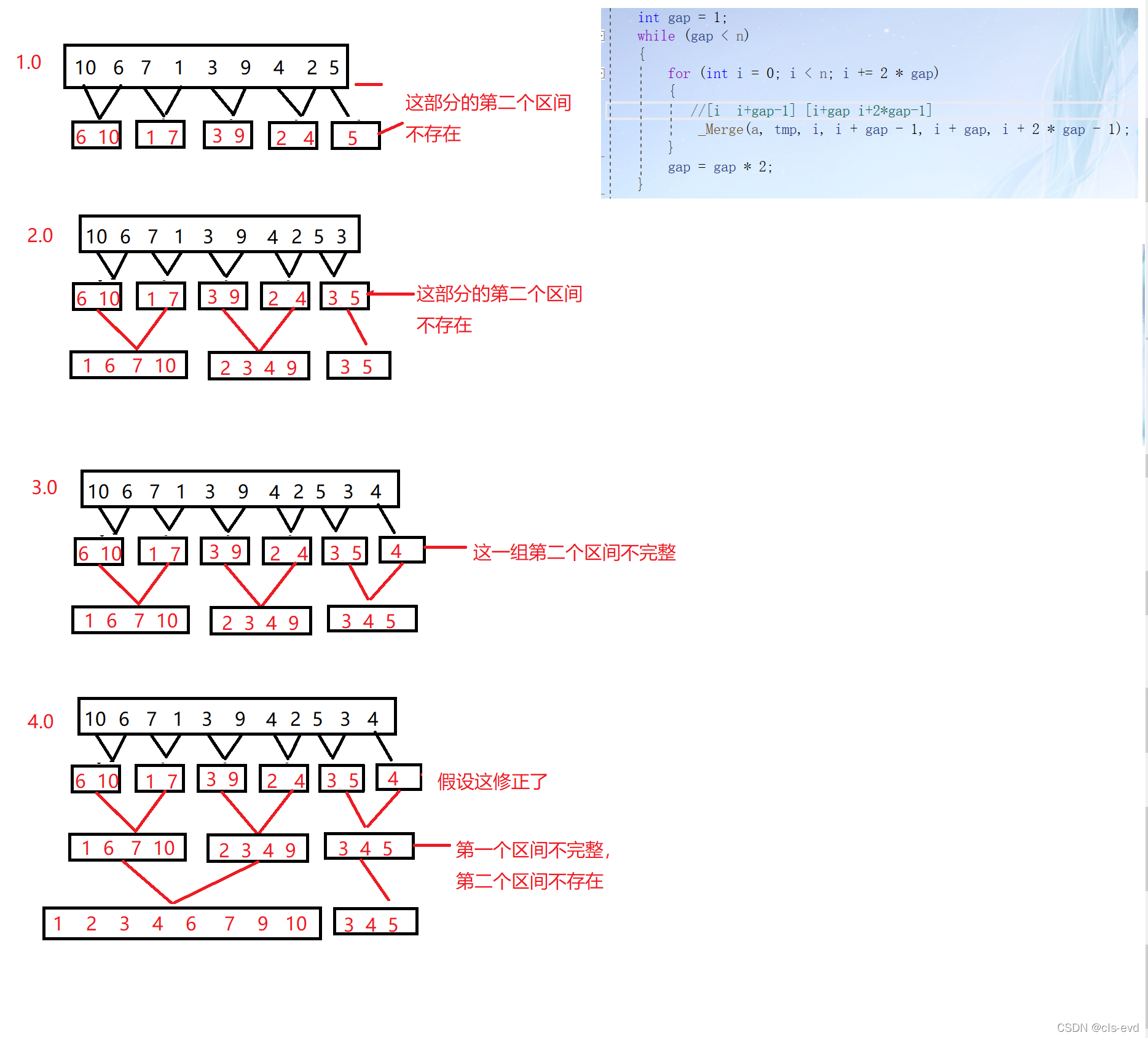
НтОіЗНЗЈ:
ШчЙћЕкЖўИіаЁЧјМфВЛДцдкОЭВЛашвЊЙщВЂСЫ,НсЪјБОДЮбЛЗ
ШчЙћЕкЖўИіаЁЧјМфДцдк,ЕЋЪЧЕкЖўИіаЁЧјМфВЛЙЛgapИі,НсЪјЕФЮЛжУОЭдННчСЫ,ашвЊаое§вЛЯТ
ДњТыШчЯТ:
_Merge(int* a, int* tmp, int begin1, int end1, int begin2, int end2)
{
int j = begin1;
int i = begin1;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[i++] = a[begin1++];
}
else
{
tmp[i++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[i++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[i++] = a[begin2++];
}
//ЙщВЂЭъГЩвдКѓПНБДЛиЕНдЪ§зщ
for ( j ;j <= end2; j++)
{
a[j] = tmp[j];
}
}
//ЖдШЮвтИіЪ§ЖМГЩСЂ
void MergeSortNonR(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
if (tmp == NULL)
{
printf("malloc fail");
exit(-1);
}
int gap = 1;
while (gap < n)
{
for (int i = 0; i < n; i += 2 * gap)
{
//[i i+gap-1] [i+gap i+2*gap-1]
int begin1 = i, end1 = i + gap - 1, begin2 = i + gap, end2 = i + 2 * gap - 1;
//ШчЙћЕкЖўИіаЁЧјМфВЛДцдкОЭВЛашвЊЕнЙщСЫ,НсЪјБОДЮбЛЗ
if (begin2 >= n)
{
break;
}
//ШчЙћЕкЖўИіаЁЧјМфДцдк,ЕЋЪЧЕкЖўИіаЁЧјМфВЛЙЛgapИі,НсЪјЕФЮЛжУОЭдННчСЫ,ашвЊаое§вЛЯТ
if (end2 >= n)
{
end2 = n - 1;
}
_Merge(a, tmp, begin1, end1, begin2, end2);
}
gap = gap * 2;
}
free(tmp);
}Р§зг:
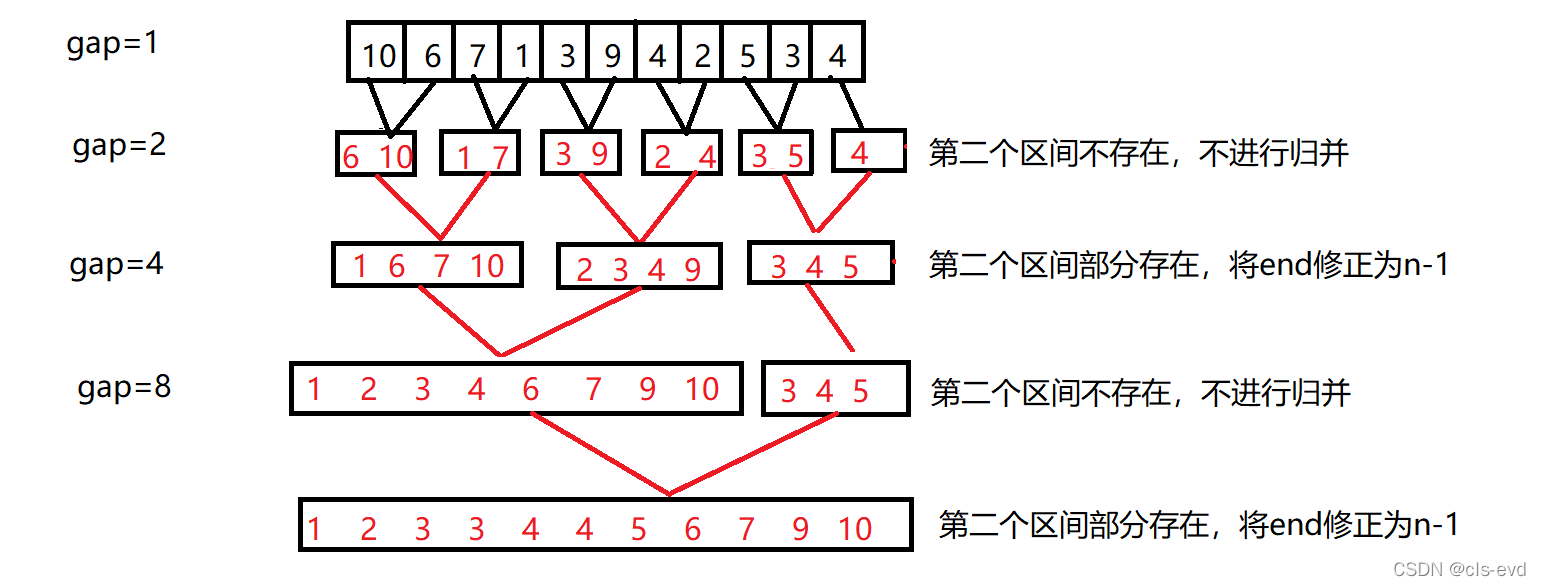
ФкХХађгыЭтХХађ
ФкХХађ:Ъ§ОнСПЯрЖдЩйвЛаЉ,ПЩвдЗХЕНФкДцжаХХађ,вдЩЯХХађЖМПЩвдФкХХађ
ЭтХХађ:Ъ§ОнСПНЯДѓ,ФкДцжаЗХВЛЯТ,Ъ§ОнЗХЕНДХХЬЮФМўжа,ашвЊХХађ
ЙщВЂХХађМШПЩвдгУРДФкХХађ,гжПЩвдгУРДЭтХХађ
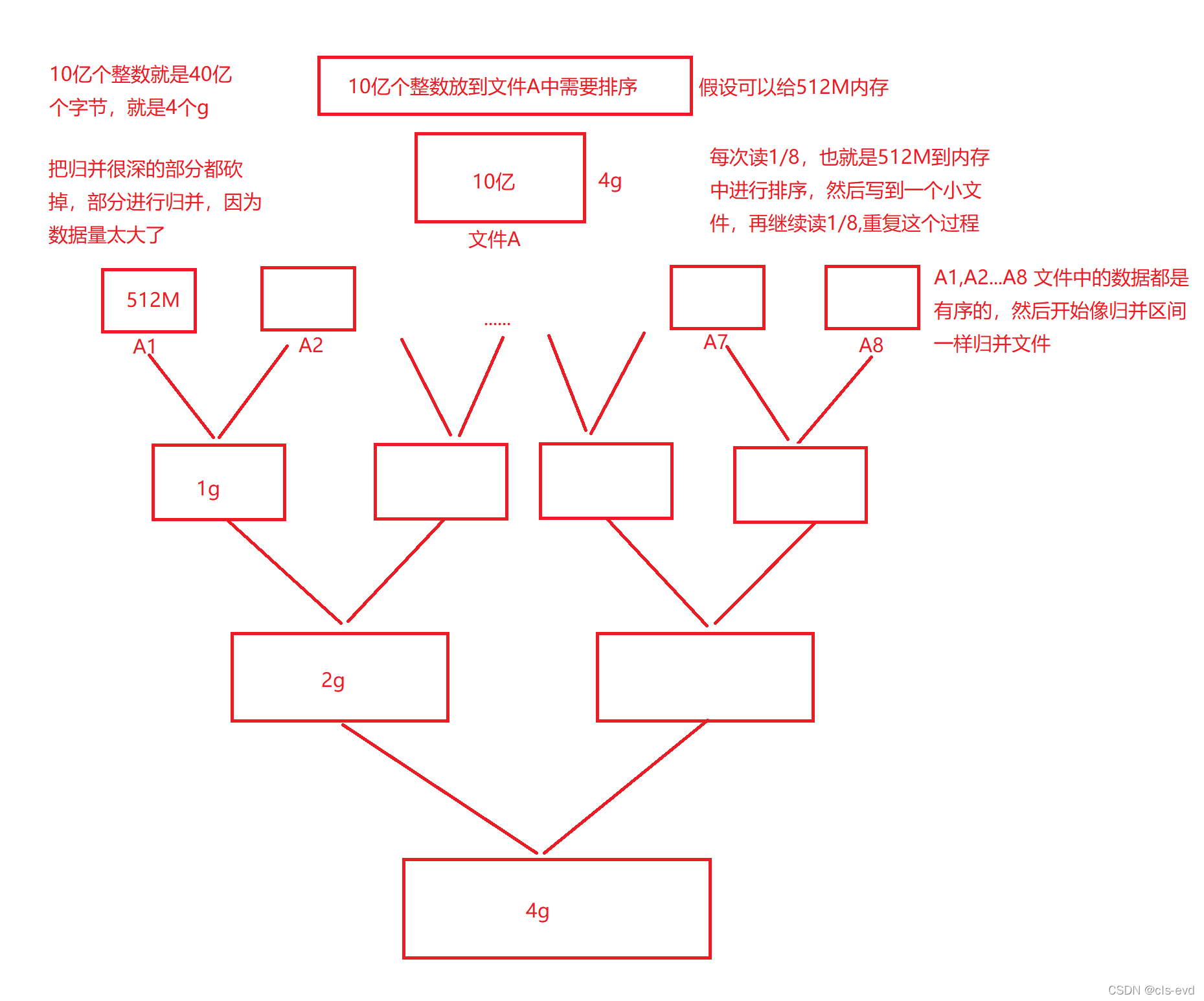
ЖдетбљЕФвЛЕРЬт:НЋ10вкИіећЪ§ЗХЕНЮФМўAжаНјааХХађ,МйЩшПЩвдИј512MЕФФкДц,ШчКЮНјаа?
ЫМТЗ:ЪзЯШЯыАьЗЈЫуГіЮФМўгаЖрДѓ,10вкИіећЪ§ОЭЪЧ40вкИізжНкОЭЪЧ4gЕФФкДц,ИјСЫ512MЕФФкДцФмгУ,ЮвУЧОЭПЩвдПМТЧНЋЦфЗжГЩ8Зн,УПДЮЖС1/8,вВОЭЪЧ512MЕНФкДцжаНјааХХађ,ШЛКѓаДЕНвЛИіаЁЮФМўжа,дйМЬајЖС1/8,жиИДетИіЙ§ГЬ,НгЯТРДОЭПЩвдНјааЙщВЂСЫ,вђЮЊУПИіаЁЮФМўжаЕФЪ§ОнЖМЪЧгаађЕФ(РрБШЙщВЂгаађЕФЧјМф),етРяЕФЙщВЂЯрЕБгкАбЙщВЂКмЩюЕФВПЗжЖМПГЕє,ВПЗжНјааЙщВЂ,вђЮЊЪ§ОнСПЬЋДѓСЫ,зЂвт:етРядк512MФкДцжаЕФХХађПЩвдгУЦфЫћХХађ,ЕЋВЛгУЙщВЂ,вђЮЊЫќгаO(N)ЕФПеМфИДдгЖШ
СНИіЮФМўЙщВЂжЛвЊЧѓСНИіЖМгаађОЭаа,ЫљвдетРяЕФЙщВЂгаСНжжЗНЗЈ:
1.0??СНСНЙщВЂ
ШчЭМ:
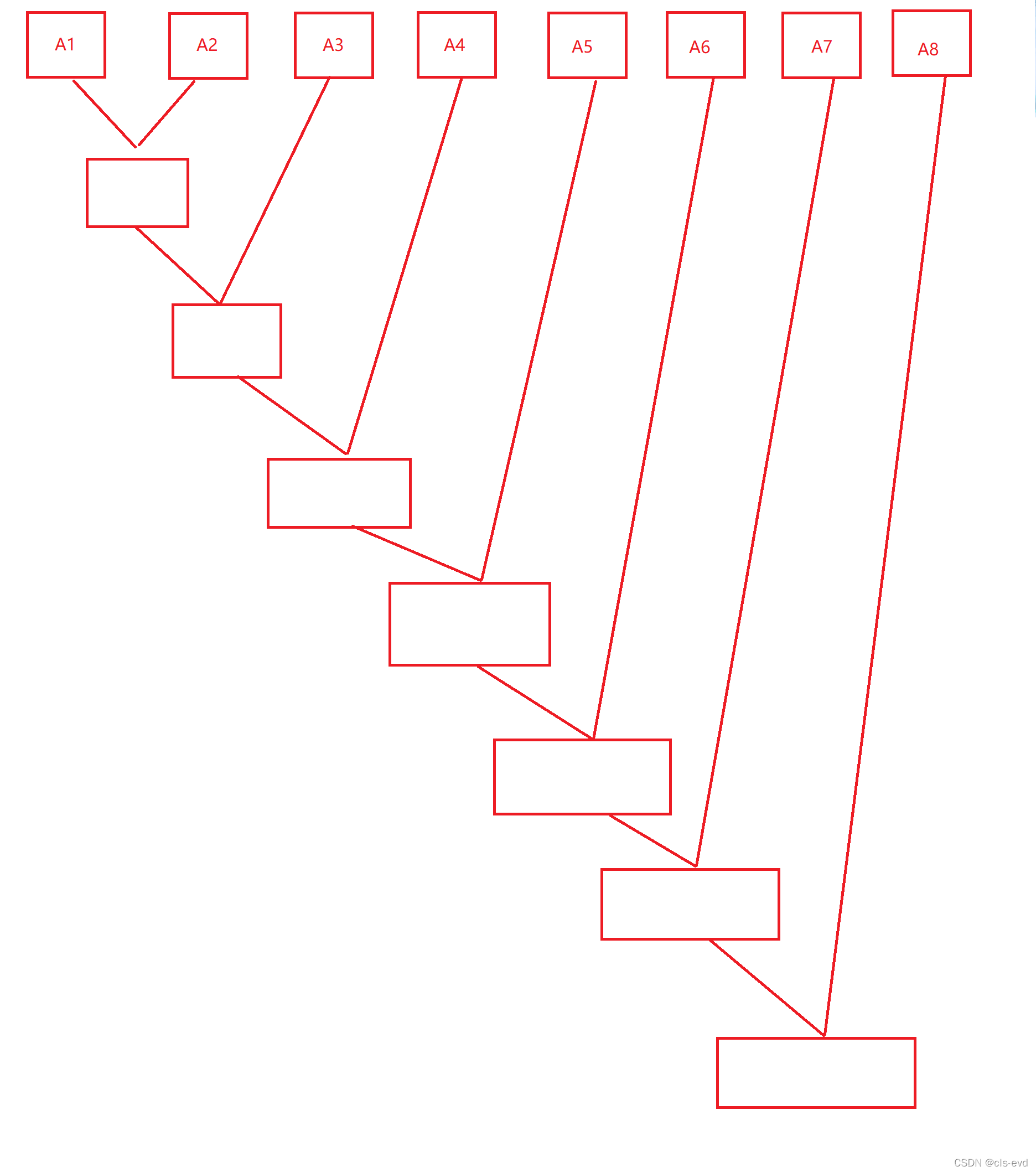
?2.0 ЭЗСНИіЙщВЂКѓгыЯрСкЕФНјааЙщВЂ
ШчЭМ:?
МЦЪ§ХХађ?
ЫМЯы:МЦЪ§ХХађгжГЦЮЊИыГВдРэ,ЪЧЖдЙўЯЃжБНгЖЈжЗЗЈЕФБфаЮгІгУЁЃ ВйзїВНжш:1. ЭГМЦЯрЭЌдЊЫиГіЯжДЮЪ§2. ИљОнЭГМЦЕФНсЙћНЋађСаЛиЪеЕНдРДЕФађСажа
ЯрЙиИХФю:(НсКЯЯТЭМПД)
ОјЖдХХађ:УПИіЪ§зжЖМЗХЕНгыЫќБОЩэЕФжЕЖдгІЕФЮЛжУ,Р§Шч:5ЖдгІ5,2ЖдгІ2
ЯрЖдгГЩф:вЛИіжЕгГЩфЕНФФИіЮЛжУ,ОЭгУЫќЕФжЕМѕШЅИУЪ§зщжазюаЁЕФжЕ
ЫМТЗЭМ: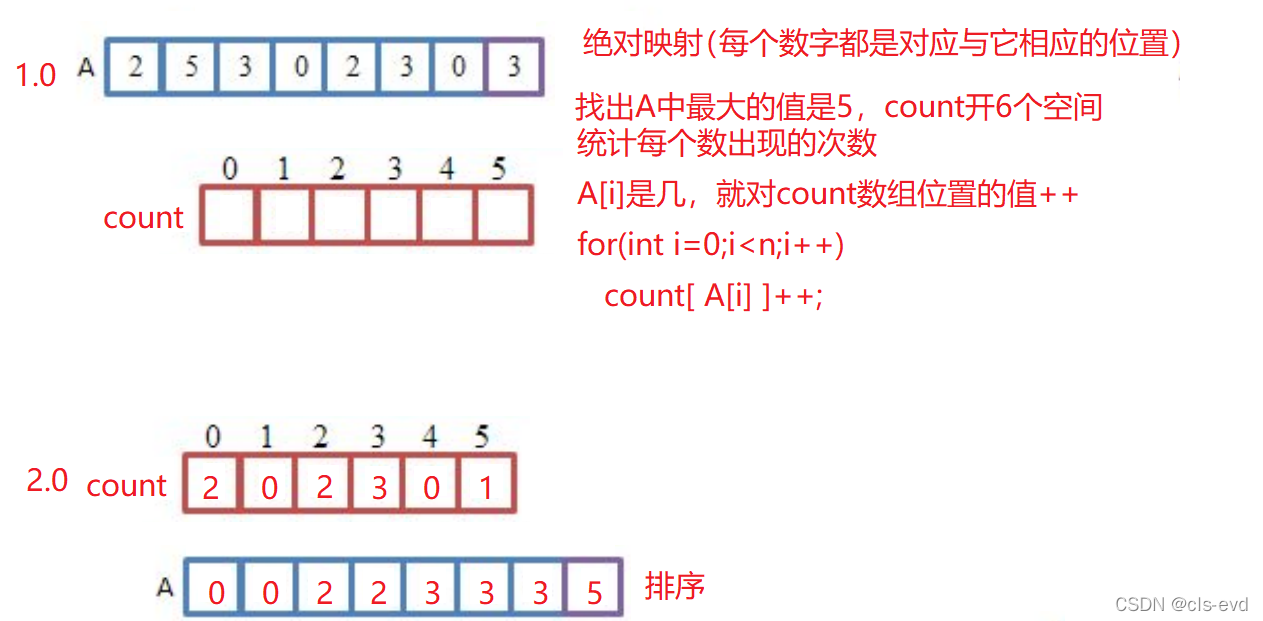
ЖјЖдетбљЕФЪ§зщ: ЫМТЗМАЦфЫМТЗЭМШчЯТ
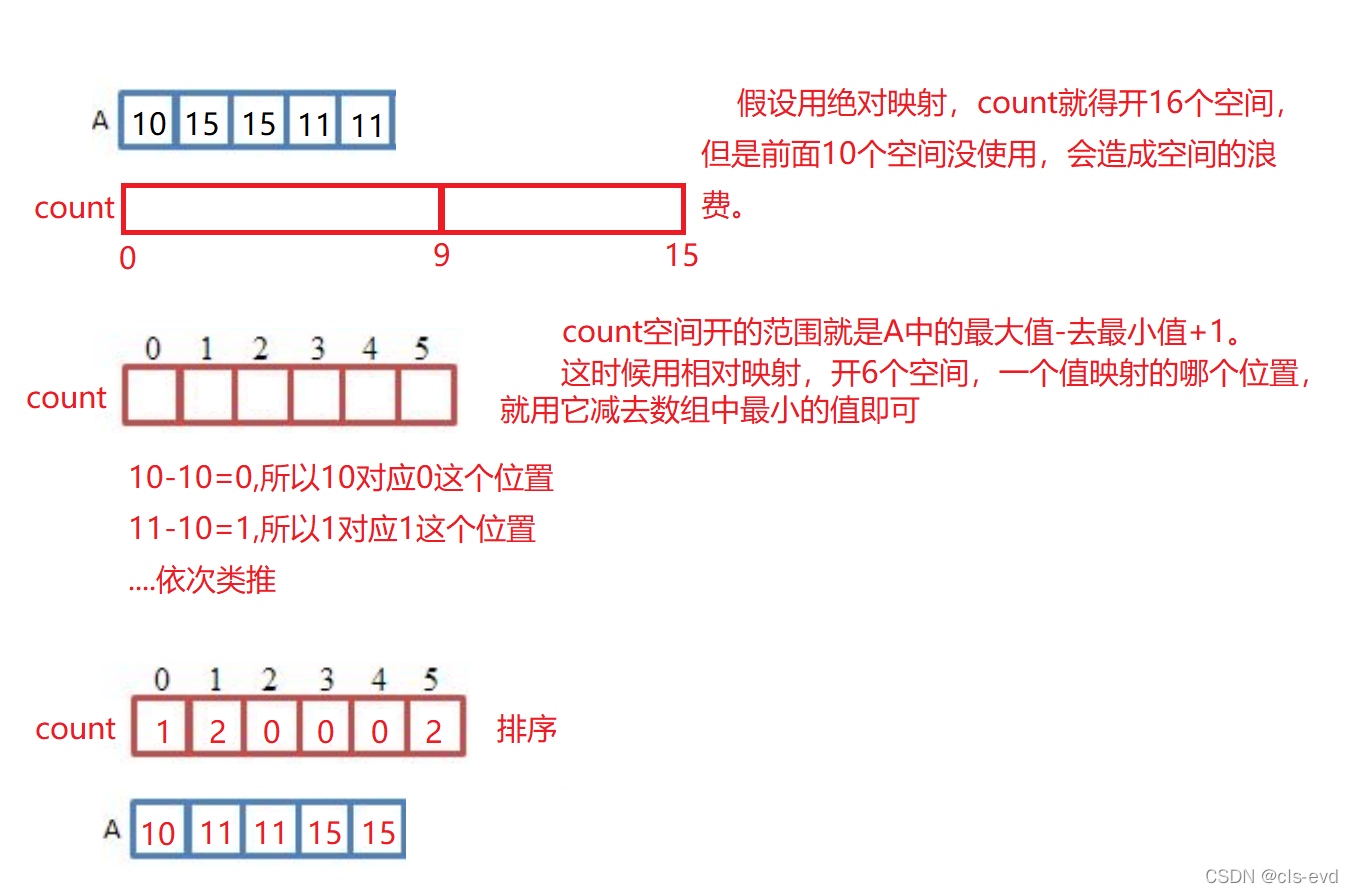
? ? ЕБШЛетжжЪ§зщвВПЩвдгУОјЖдгГЩф,жЛВЛЙ§ЛсдьГЩПеМфРЫЗб,МйШчИјЕФЪ§зжКмДѓ,?дьГЩЕФПеМфРЫЗбвВЛсКмДѓЁЃ
ДњТыЪЕЯж:
void CountSort(int* a, int n)
{
int max = a[0], min = a[0];
for (int i = 0; i < n; i++)
{
if (a[i] > max)
{
max = a[i];
}
if (a[i] < min)
{
min = a[i];
}
}
int range = max - min + 1;//взДэ
int* count = malloc(sizeof(int) * range);
memset(count, 0, sizeof(int) * range);
for (int i = 0; i < n; i++)
{
count[a[i]-min]++; //взДэ
}
int i = 0;
for (int j = 0; j < range; j++)
{
while (count[j]--)
{
a[i++] = j + min;
}
}
free(count);
}ЪБМфИДдгЖШO(N+range)
ПеМфИДдгЖШO(range)
МЦЪ§ХХађЕФЬиЕу:
? ?жЛЪЪКЯвЛзщЪ§Он,Ъ§ОнЕФЗЖЮЇБШНЯЕФМЏжа,ШчЙћЗЖЮЇМЏжааЇТЪЪЧКмИпЕФ,ЕЋЪЧОжЯоадвВдкетРя
ВЂЧвжЛЪЪКЯећЪ§,ШчЙћЪЧИЁЕуЪ§КЭзжЗћДЎЕШОЭВЛааСЫЁЃ
ИїИіХХађЕФЮШЖЈад
?Ъ§зщжаЯрЭЌЕФжЕ,ХХЭъађвдКѓ,ЯрЖдЫГађВЛБф,ОЭЪЧЮШЖЈЕФ,ЗёдђОЭЪЧВЛЮШЖЈЕФЁЃЖдХХађРДЫЕ,ШчЙћЫћПЩвдЭЈЙ§ЕїећЫуЗЈзіЕНЮШЖЈ(ЖдШЮвтЕФЧщПіЖМЪЧЮШЖЈЕФ)ОЭЫЕЫќЪЧЮШЖЈЕФ,ЗёдђОЭВЛЪЧЮШЖЈЕФЁЃ
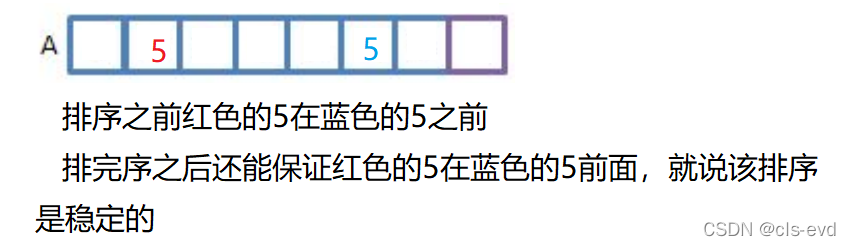
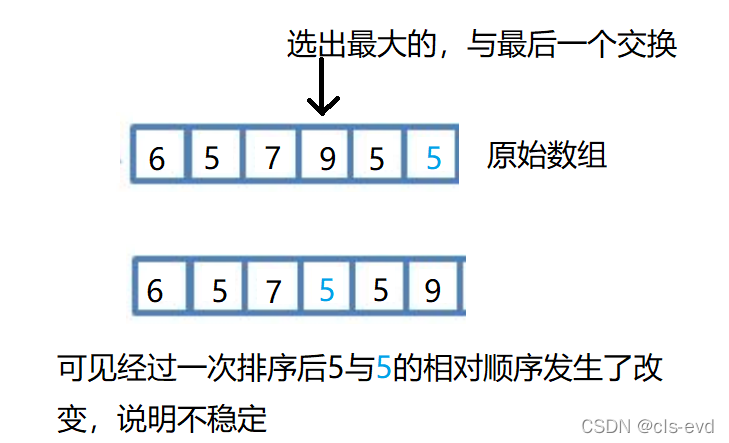
ЮШЖЈадЕФгІгУ:
ПДЫЦХХађЕФЮШЖЈадКУЯёУЛЩЖМлжЕ,ЕЋдкетбљвЛжжЬиЪтЧщПіжа,ОЭеЙЯжСЫЫќЕФМлжЕ
ПМЪдЕФЪБКђ,ЬсНЛЪдОэвдКѓ,здЖЏХаОэФУЕНГЩМЈЁЃ
ГЩМЈАДееНЛОэЫГађХХЕНЪ§зщжаШЅ,ШЛКѓЮвУЧЖдЪ§зщНјааХХађ,НјааХХУћЁЃ
вЊЧѓ:ЗжЪ§ЯрЭЌ,ЯШНЛОэЕФХХдкЧАУц?

УАХнХХађ:ЮШЖЈ,УАХнЪЧСНИіЪ§ДѓЕФЪ§ЗХКѓУц,жЛвЊБЃжЄСНЪ§ЯрЕШВЛЛЛОЭзіЕНЮШЖЈСЫЁЃ?
МђЕЅбЁдёХХађ:ВЛЮШЖЈ,ПЩФмгаШЫЛсЫЕ,УцЖдСНИіЯрЭЌЕФзюДѓЪ§зж,бЁдёКѓвЛИі,СНИіЯрЭЌаЁЕФЪ§зжбЁдёЧАвЛИіОЭПЩвдзіЕНЮШЖЈ,ЕЋЪЧЖдвдЯТЧщПі,ОЭЪЧВЛЮШЖЈЕФЁЃ
жБНгВхШы:ЮШЖЈ,УцЖдЯрЕШЕФСНИіЪ§,жБНгЗХдкКѓУц
ЯЃЖћ:ВЛЮШЖЈ,ЯрЭЌЕФжЕдкдЄХХађЕФЪБКђЗжЕНСЫВЛЭЌЕФзщРяУц
ЖбХХађ:ВЛЮШЖЈ
?ЙщВЂХХађ:ЮШЖЈ?СНЧјМфЙщВЂЕФЪБКђ,гіЕНЯрЭЌЕФжЕ,ШУЕквЛИізщРяЪ§ЯШЯТРД,ОЭЪЧЮШЖЈЕФ
?ПьЫйХХађ:ВЛЮШЖЈ


АЫДѓХХађзмНс(ЪБМф,ПеМфИДдгЖШ,ЮШЖЈад)