引言
数据库索引的重点知识梳理~
1、索引是什么,有什么作用,有何优缺点?
索引是帮助Mysql高效获取数据的一种数据结构,通常用B树,B+树实现(Mysql不支持hash)
2、为什么用B+树而不用B树,B+树有什么优势?
(1)IO代价更低。B+树由于非叶子节点中不存放data,因此可以存放更多的索引值(单个大节点的容量固定,每个小单位size变小了),从而使得树的高度更低,磁盘IO次数更少。
(2)查询效率稳定。B+树由于所有data都放在叶子节点中,因此每次查询都要走完整的根节点到叶子节点的路径,所有查询的路径长度相同,查询效率更加稳定。
(3)更利于范围查询。B+树叶子节点之间有指针,更利于范围查询。
案例分析:索引如何支撑千万级表的快速查找?(B+树)
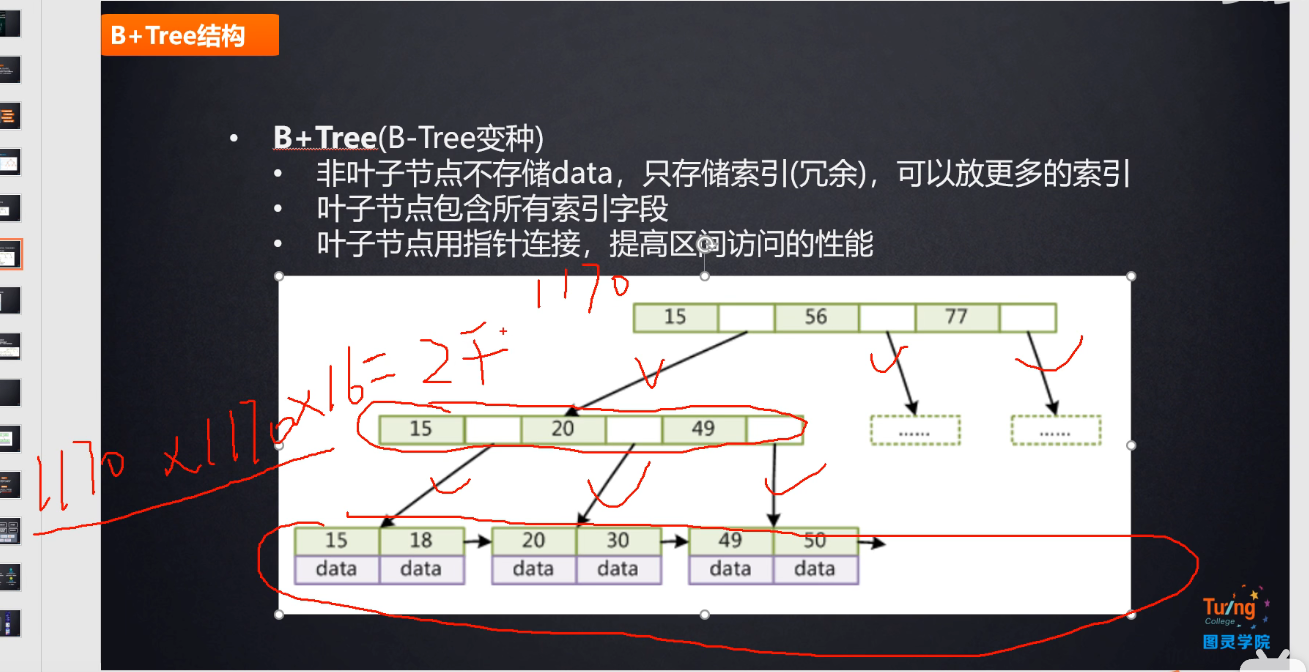
Mysql底层用B+树存储索引,假设现在用3层B+树来存储(层数越少,磁盘I/O次数越少),我们来看一共能存多少行数据:
(1)Mysql规定一个页面大小为16KB(即图中一个大节点),假设现在存的数据字段是bigint型的,占8B,指针根据底层源码规定占6B,则一个大节点一共可以存放索引记录共16KB/(8+6)B=1170,则叶子节点的节点个数共有1170x1170个。
(2)假设叶子节点中一个索引+data占用1KB,则一个节点中可存放索引+data记录共16KB/1KB=16个。
(3)因此叶子节点层一共能存放索引+data记录数目为1170117016=2190 2400
(4)因此3层B+树即可存放两千万以上的数据
3、为什么用B+树索引而不用哈希索引?
哈希索引,建立的是索引值的哈希值和物理磁盘地址之间的映射
(1)哈希冲突多的时候,性能也不一定就比B+树好
(2)哈希索引不支持范围查询,只能点对点查询,哈希运算前的索引值和哈希运算后的哈希值顺序并不一定一样
(3)哈希索引不能利用部分索引键查询,哈希索引在计算哈希值的时候是组合索引键合并后再一起计算哈希值,而不是单独计算哈希值,所以通过组合索引的前面一个或几个索引键进行查询的时候,哈希索引也无法被利用
4、为什么InnoDB推荐用整型自增主键,而不是uuid?
(1)uuid占用空间更多。uuid是随机字符串,占用空间更多,整型更少。
(2)uuid排序不如整型容易。uuid是字符串,而节点中的索引值需要排序,显然整型排序更容易。
(3)整型自增插入时可避免节点频繁分裂。插入数据时,自增主键对B+树结构影响很小,由于是递增,往后加就行,而uuid是随机的,可能插到中间,如果前面节点已经满了,会导致节点分裂(页分裂)、树结构调整等大量耗费性能的操作。
聚簇索引和非聚簇索引
索引可分为两个大类:
- 主键索引:主键本身就是一个索引
- 辅助索引(也称为非主键索引、二级索引):设置主键之外的其他字段为索引
聚簇索引定义:
- 索引和数据是放在一块的(一个文件存储,主键索引的B+树的叶子节点中存放了索引值和数据行所有字段)
- 索引的顺序和数据的物理存储一致(因为字段也在B+树的叶子节点中,因此索引按序则整个数据行也是按序的)
非聚簇索引定义:
- 索引和数据是分开存放的(两个文件存储,索引的B+树的叶子节点中只存放了索引值和指向对应数据行的物理地址)
- 索引的顺序和数据的物理存储不一致(B+树中的索引值是按序的,但指针中的对应数据行的物理地址并不是按序的)
记住一个结论:
- InnoDB使用的都是聚簇索引
- Myisam使用的都是非聚簇索引
InnoDB的主键索引是严格的聚簇索引,B+树叶子节点中存放主键索引值和对应数据行所有字段。非主键索引不是严格的聚簇索引但也归为其中,B+树叶子节点中存放的是非主键索引值和对应主键值。因此InnoDB中使用非主键索引来查询数据,需要查两棵B+树。
Myisam的主键索引和非主键索引都是非聚簇索引,B+树叶子节点中存放的都是索引值和对应数据行的物理磁盘地址
下面两张图非常直观理解:
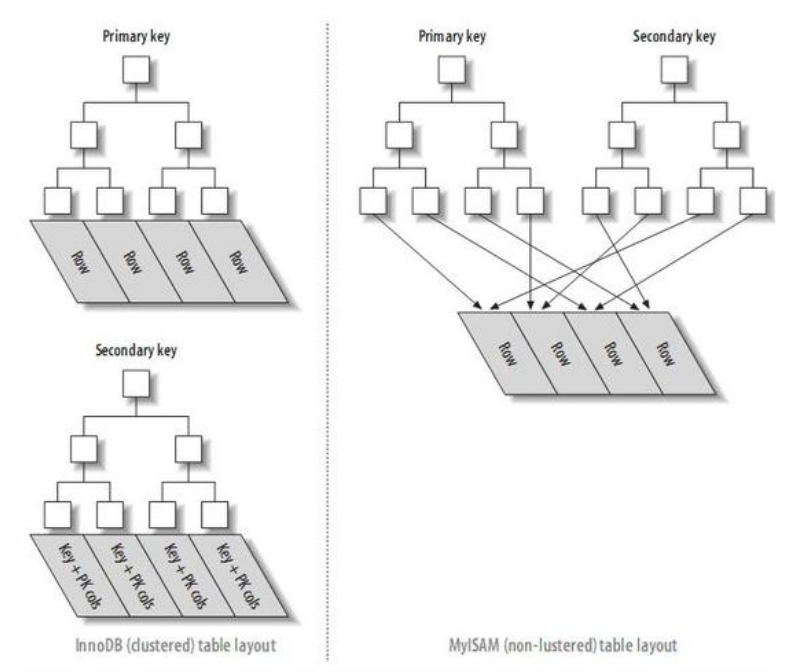
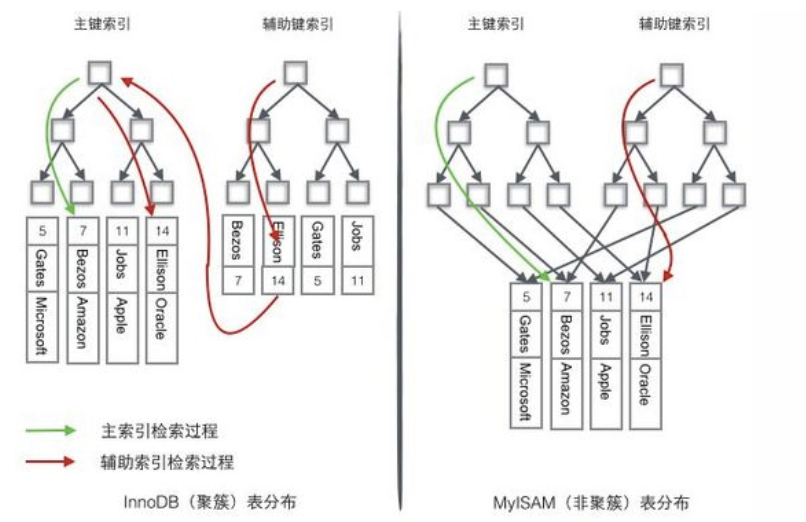
注意:如果有人问Innodb辅助索引是不是非聚簇索引,可以这么回答:从定义的角度innodb的辅助索引确实不算是严格的聚簇索引,但它和Myisam的辅助索引并不相同,一个存的数据行物理磁盘地址,一个存的是主键值。一般不会这么问,因为聚集索引主要是用来区分Innodb和Myisam的,不会单独针对辅助索引再胡搅蛮缠
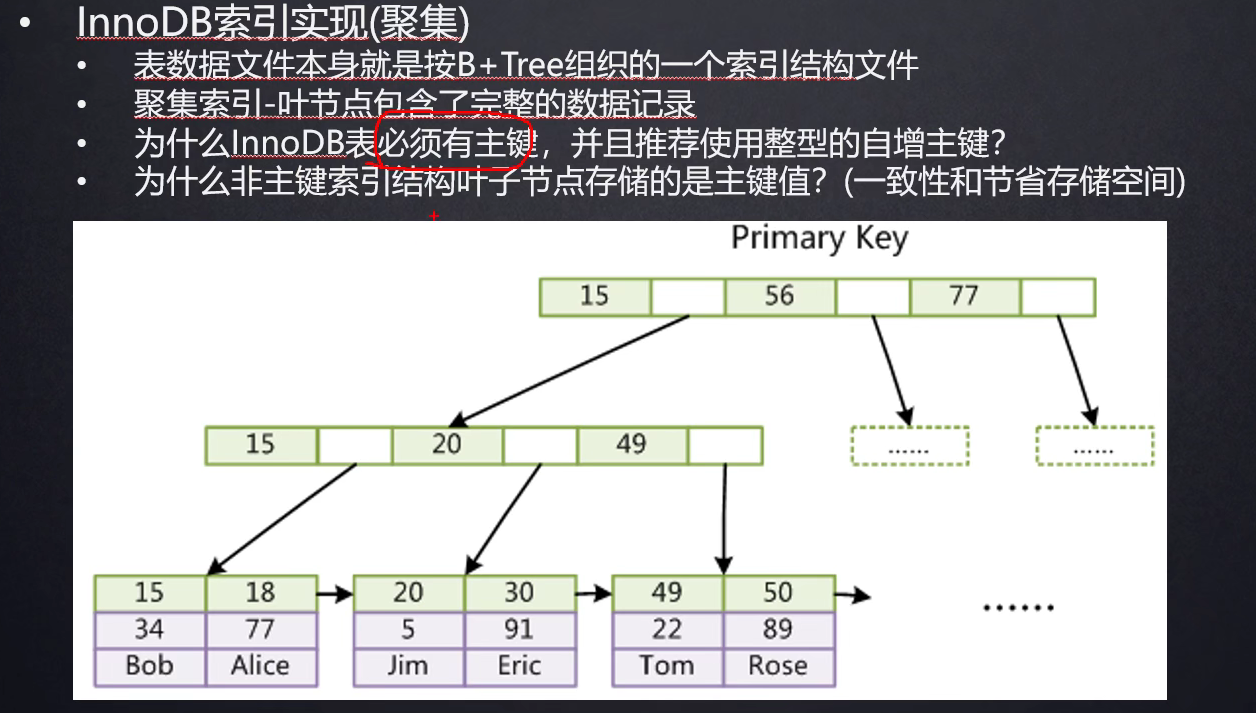
为什么Innodb的辅助索引不直接存数据物理地址,其相对于Myisam的索引有何优势?
(1)如果存的是物理地址,那么当表中数据行有位置移动时(例如不断插入数据时,会涉及节点分裂,物理地址会变化),就需要去更新叶子节点中存的这个物理地址值
(2)如果存的是主键,确实会比存地址花费更多空间,但如果有行移动,辅助索引树不需要有任何变动,减少了维护开销