146. LRU 缓存
题目描述:
请你设计并实现一个满足 LRU (最近最少使用) 缓存 约束的数据结构。
实现 LRUCache 类:
- LRUCache(int capacity) 以 正整数 作为容量 capacity 初始化 LRU 缓存(cache)
int get(int key)如果关键字 key 存在于缓存中,则返回关键字的值,否则返回 -1 。void put(int key, int value)- 如果关键字 key 已经存在,则变更其数据值 value ;
- 如果不存在,则向缓存中插入该组 key-value 。如果插入操作导致关键字数量超过 capacity ,则应该 逐出 最久未使用的关键字。
**函数 ****get **和 **put **必须以** O(1)** 的平均时间复杂度运行。
?
示例:
?
输入
[“LRUCache”, “put”, “put”, “get”, “put”, “get”, “put”, “get”, “get”, “get”]
[[2], [1, 1], [2, 2], [1], [3, 3], [2], [4, 4], [1], [3], [4]]
输出
[null, null, null, 1, null, -1, null, -1, 3, 4]
解释
LRUCache lRUCache = new LRUCache(2);
lRUCache.put(1, 1); // 缓存是 {1=1}
lRUCache.put(2, 2); // 缓存是 {1=1, 2=2}
lRUCache.get(1); // 返回 1
lRUCache.put(3, 3); // 该操作会使得关键字 2 作废,缓存是 {1=1, 3=3} 因为2没用过
lRUCache.get(2); // 返回 -1 (未找到)
lRUCache.put(4, 4); // 该操作会使得关键字 1 作废,缓存是 {4=4, 3=3} 1是最早进来的
lRUCache.get(1); // 返回 -1 (未找到)
lRUCache.get(3); // 返回 3
lRUCache.get(4); // 返回 4
一、什么是 LRU 算法
就是一种缓存淘汰策略。
计算机的缓存容量有限,如果缓存满了就要删除一些内容,给新内容腾位置。但问题是,删除哪些内容呢?我们肯定希望删掉哪些没什么用的缓存,而把有用的数据继续留在缓存里,方便之后继续使用。那么,什么样的数据,我们判定为「有用的」的数据呢?
LRU 缓存淘汰算法就是一种常用策略。LRU 的全称是 Least Recently Used,也就是说我们认为最近使用过的数据应该是是「有用的」,很久都没用过的数据应该是无用的,内存满了就优先删那些很久没用过的数据。
举个简单的例子,安卓手机都可以把软件放到后台运行,比如我先后打开了「设置」「手机管家」「日历」,那么现在他们在后台排列的顺序是这样的:
「设置」->「手机管家」->「日历」
但是这时候如果我访问了一下「设置」界面,那么「设置」就会被提前到第一个,变成这样:
「手机管家」->「日历」->「设置」
假设手机只允许同时开 3 个应用程序,现在已经满了。
那么如果新开了一个应用「时钟」,就必须关闭一个应用为「时钟」腾出一个位置,关那个呢?
按照 LRU 的策略,就关最前面的「手机管家」,因为那是最久未使用的,然后把新开的应用放到最后面:
当然还有其他缓存淘汰策略,比如不要按访问时序来淘汰,而是按访问频率(LFU 策略)来淘汰等等,各有应用场景。
二、 LRU 算法描述
LRU 算法实际上是让你设计数据结构:
- 首先要接收一个 capacity 参数作为缓存的最大容量
- 然后实现两个 API
- 一个是 put(key, val) 方法存入键值对
- 另一个是
get(**key**)方法获取 **key **对应的 val,如果 key 不存在则返回 -1。
get 和 put 方法必须都是 O(1) 的时间复杂度,我们举个具体例子来看看 LRU 算法怎么工作。
/* 缓存容量为 2 */
LRUCache cache = new LRUCache(2);
// 可以把 cache 理解成一个队列
// 假设左边是队头,右边是队尾
// 最近使用的排在队头,久未使用的排在队尾
// 圆括号表示键值对 (key, val)
cache.put(1, 1);
// cache = [(1, 1)]
cache.put(2, 2);
// cache = [(2, 2), (1, 1)]
cache.get(1); // 返回 1
// cache = [(1, 1), (2, 2)]
// 解释:因为最近访问了键 1,所以提前至队头
// 返回键 1 对应的值 1
cache.put(3, 3);
// cache = [(3, 3), (1, 1)]
// 解释:缓存容量已满,需要删除内容空出位置
// 优先删除久未使用的数据,也就是队尾的数据
// 然后把新的数据插入队头
cache.get(2); // 返回 -1 (未找到)
// cache = [(3, 3), (1, 1)]
// 解释:cache 中不存在键为 2 的数据
cache.put(1, 4);
// cache = [(1, 4), (3, 3)]
// 解释:键 1 已存在,把原始值 1 覆盖为 4
// 不要忘了也要将键值对提前到队头
?
三、LRU 算法设计
要让 put 和 get 方法的时间复杂度为 O(1),可以总结出 **cache **这个数据结构必要的条件:查找快,插入快,删除快,有顺序之分。
- 显然 cache 必须有顺序之分,以区分最近使用的和久未使用的数据;
- 而且要在 cache 中查找键是否已存在;
- 如果容量满了要删除最后一个数据;
- 每次访问还要把数据插入到队头。
那么,什么数据结构同时符合上述条件呢?
- 哈希表查找快,但是数据无固定顺序;
- 链表有顺序之分,插入删除快,但是查找慢。
- 所以结合一下,形成一种新的数据结构:哈希链表。
LRU 缓存算法的核心数据结构就是哈希链表,双向链表和哈希表的结合体。
这个数据结构长这样:
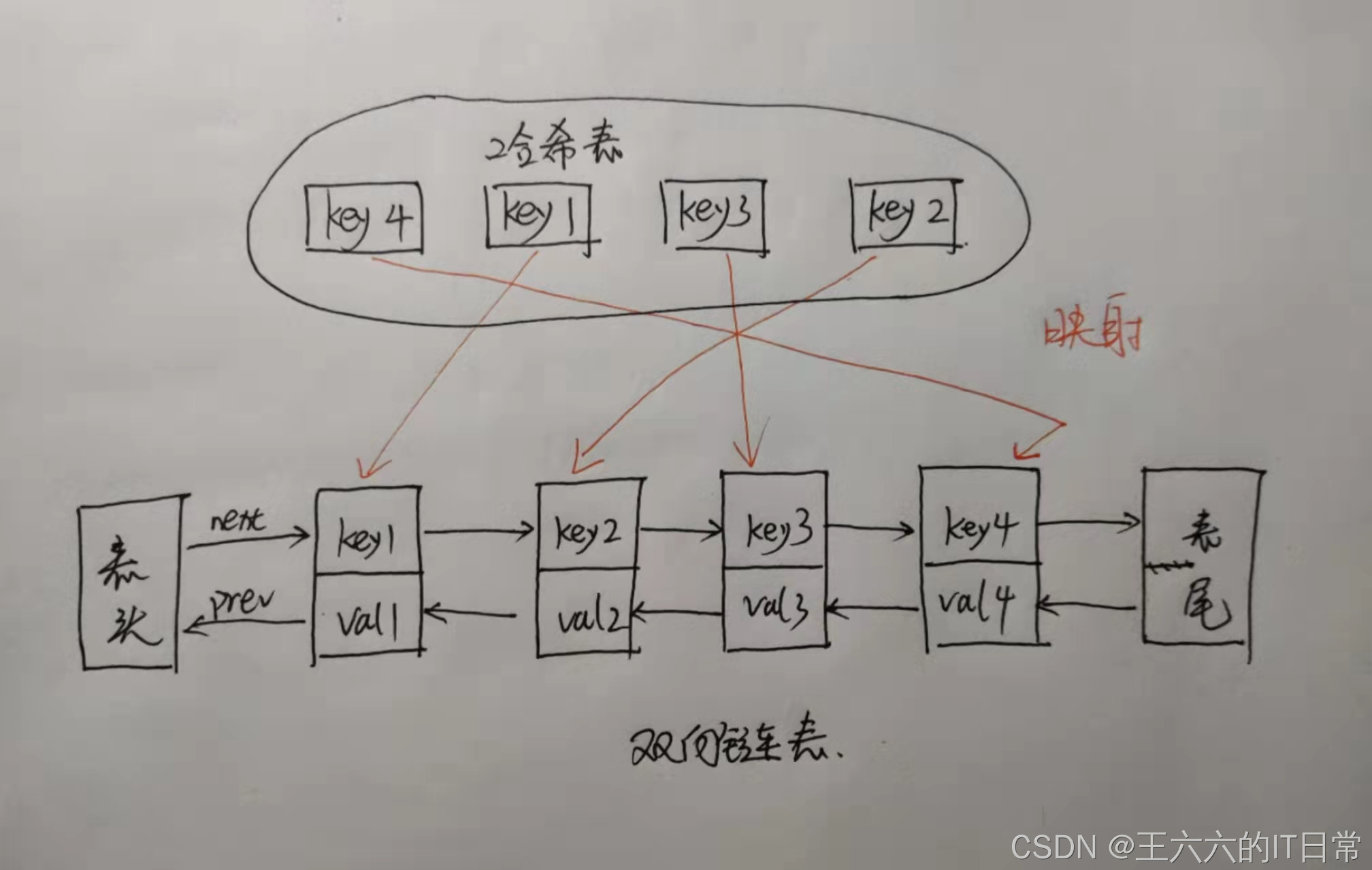
借助哈希表赋予了链表快速查找的特性:
- 可以快速查找某个 key 是否存在缓存(链表)中
- 可以快速删除、添加节点。
四、代码实现
很多编程语言都有内置的哈希链表或者类似 LRU 功能的库函数,但是为了帮大家理解算法的细节,我们用 Java 自己造轮子实现一遍 LRU 算法。
首先,我们把双向链表的节点类写出来,为了简化,key 和 val 都认为是 int 类型:
class Node {
public int key, val;
public Node next, prev;
public Node(int k, int v) {
this.key = k;
this.val = v;
}
}
依靠Node类型构建一个双向链表,实现几个需要的 API(这些操作的时间复杂度均为 O(1)):
class DoubleList {
// 在链表头部添加节点 x,时间 O(1)
public void addFirst(Node x);
// 删除链表中的 x 节点(x 一定存在)
// 由于是双链表且给的是目标 Node 节点,时间 O(1)
public void remove(Node x);
// 删除链表中最后一个节点,并返回该节点,时间 O(1)
public Node removeLast();
// 返回链表长度,时间 O(1)
public int size();
}
// 在链表头部添加节点 node,时间 O(1)
private void addToHead(DLinkedNode node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
// 删除链表中的 node 节点(node 一定存在)
// 由于是双链表且给的是目标 Node 节点,时间 O(1)
private void removeNode(DLinkedNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
//将node移到头节点
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
// 删除链表中最后一个节点,并返回该节点,时间 O(1)
private DLinkedNode removeTail() {
DLinkedNode res = tail.prev;
removeNode(res);
return res;
}
“为什么必须要用双向链表”:
删除一个节点不光要得到该节点本身的指针,也需要操作其前驱节点的指针,而双向链表才能支持直接查找前驱,保证操作的时间复杂度 O(1)。
有了双向链表的实现,我们只需要在 LRU 算法中把双向链表和哈希表结合起来即可。
我们先把逻辑理清楚:
// key 映射到 Node(key, val)
HashMap<Integer, Node> map;
// Node(k1, v1) <-> Node(k2, v2)...
//缓存容量
DoubleList cache;
int get(int key) {
if (key 不存在) {
return -1;
} else {
将数据 (key, val) 提到开头;
return val;
}
}
void put(int key, int val) {
Node x = new Node(key, val);
if (key 已存在) {
把旧的数据删除;
将新节点 x 插入到开头;
} else {
if (cache 已满) {
删除链表的最后一个数据腾位置;
删除 map 中映射到该数据的键;
}
将新节点 x 插入到开头;
map 中新建 key 对新节点 x 的映射;
}
}
class LRUCache {
// key -> Node(key, val)
private HashMap<Integer, Node> map;
// Node(k1, v1) <-> Node(k2, v2)...
private DoubleList cache;
// 最大容量
private int cap;
public LRUCache(int capacity) {
this.cap = capacity;
map = new HashMap<>();
cache = new DoubleList();
}
public int get(int key) {
if (!map.containsKey(key))
return -1;
int val = map.get(key).val;
// 利用 put 方法把该数据提前
put(key, val);
return val;
}
public void put(int key, int val) {
// 先把新节点 x 做出来
Node x = new Node(key, val);
if (map.containsKey(key)) {
// 删除旧的节点,新的插到头部
cache.remove(map.get(key));
cache.addFirst(x);
// 更新 map 中对应的数据
map.put(key, x);
} else {
if (cap == cache.size()) {
// 删除链表最后一个数据
Node last = cache.removeLast();
map.remove(last.key);
}
// 直接添加到头部
cache.addFirst(x);
map.put(key, x);
}
}
}
“为什么要在链表中同时存储 key 和 val,而不是只存储 val”
注意这段代码:
if (cap == cache.size()) {
// 删除链表最后一个数据
Node last = cache.removeLast();
map.remove(last.key);
}
当缓存容量已满,不仅仅要删除最后一个 Node 节点,还要把 map 中映射到该节点的 key 同时删除,而这个 key 只能由 Node 得到。如果 Node 结构中只存储 val,那么我们就无法得知 key 是什么,就无法删除 map 中的键,造成错误。
很容易犯错的一点是:处理链表节点的同时不要忘了更新哈希表中对节点的映射。
哈希表 + 双向链表
思路
LRU 缓存机制可以通过哈希表辅以双向链表实现,我们用一个哈希表和一个双向链表维护所有在缓存中的键值对。
- 双向链表按照被使用的顺序存储了这些键值对,靠近头部的键值对是最近使用的,而靠近尾部的键值对是最久未使用的。
- 哈希表即为普通的哈希映射(HashMap),通过缓存数据的键key映射到其在双向链表中的位置。
先使用哈希表进行定位,找出缓存项在双向链表中的位置,随后将其移动到双向链表的头部,即可在O(1) 的时间内完成 get 或者 put 操作。
函数实现
- 对于
get操作,首先判断 key 是否存在:- 如果 key 不存在,则返回 -1;
- 如果 key 存在
- 则 key 对应的节点是最近被使用的节点
- 通过哈希表定位到该节点在双向链表中的位置
- 并将其移动到双向链表的头部
- 最后返回该节点的值。
- 对于
put操作,首先判断 key 是否存在:- 如果** key 不存在**
- 使用 key 和 value 创建一个新的节点,在双向链表的头部添加该节点,
- 并将 key 和该节点添加进哈希表中。
- 然后判断双向链表的节点数是否超出容量?
- 如果超出容量
- 则删除双向链表的尾部节点
- 并删除哈希表中对应的项
- 如果超出容量
- 如果 key 存在
- 则与 get 操作类似
- 先通过哈希表定位
- 再将对应的节点的值更新为 value
- 并将该节点移到双向链表的头部
- 则与 get 操作类似
- 如果** key 不存在**
上述各项操作中,访问哈希表的时间复杂度为 O(1),在双向链表的头部添加节点、在双向链表的尾部删除节点的复杂度也为 O(1)。而将一个节点移到双向链表的头部,可以分成「删除该节点」和「在双向链表的头部添加节点」两步操作,都可以在 O(1)时间内完成。
小贴士
在双向链表的实现中,使用一个伪头部(dummy head)和伪尾部(dummy tail)标记界限,这样在添加节点和删除节点的时候就不需要检查相邻的节点是否存在。
public class LRUCache {
//双向链表的节点类:为了简化,key 和 val 都认为是 int 类型
class DLinkedNode {
int key;
int val;
//双指针
DLinkedNode prev;
DLinkedNode next;
//构造器
public DLinkedNode() {}
public DLinkedNode(int _key, int _val) {
key = _key;
val = _val;
}
}
//key -> Node(key, val)
Map<Integer, DLinkedNode> cache = new HashMap<Integer, DLinkedNode>();
//大小
private int size;
//最大容量
private int capacity;
private DLinkedNode head, tail;
//初始化LRU 缓存
public LRUCache(int capacity) {
this.size = 0;
this.capacity = capacity;
// 使用伪头部和伪尾部节点
head = new DLinkedNode();
tail = new DLinkedNode();
head.next = tail;
tail.prev = head;
}
//get()方法
public int get(int key) {
DLinkedNode node = cache.get(key);
if (node == null) {
return -1;
}
// 如果 key 存在,先通过哈希表定位,再移到头部
moveToHead(node);
return node.val;
}
//put()方法
public void put(int key, int val) {
DLinkedNode node = cache.get(key);
if (node == null) {
// 如果 key 不存在,创建一个新的节点
DLinkedNode newNode = new DLinkedNode(key, val);
// 添加进哈希表
cache.put(key, newNode);
// 添加至双向链表的头部
addToHead(newNode);
++size;
if (size > capacity) {
// 如果超出容量,删除双向链表的尾部节点
DLinkedNode tail = removeTail();
// 删除哈希表中对应的项
cache.remove(tail.key);
--size;
}
}else {
// 如果 key 存在,先通过哈希表定位,再修改 value,并移到头部
node.val = val;
moveToHead(node);
}
}
// 在链表头部添加节点 node,时间 O(1)
private void addToHead(DLinkedNode node) {
node.prev = head;
node.next = head.next;
head.next.prev = node;
head.next = node;
}
// 删除链表中的 node 节点(node 一定存在)
// 由于是双链表且给的是目标 Node 节点,时间 O(1)
private void removeNode(DLinkedNode node) {
node.prev.next = node.next;
node.next.prev = node.prev;
}
//将节点node移动至头节点
private void moveToHead(DLinkedNode node) {
removeNode(node);
addToHead(node);
}
// 删除链表中最后一个节点,并返回该节点,时间 O(1)
private DLinkedNode removeTail() {
DLinkedNode res = tail.prev;
removeNode(res);
return res;
}
}
补充:
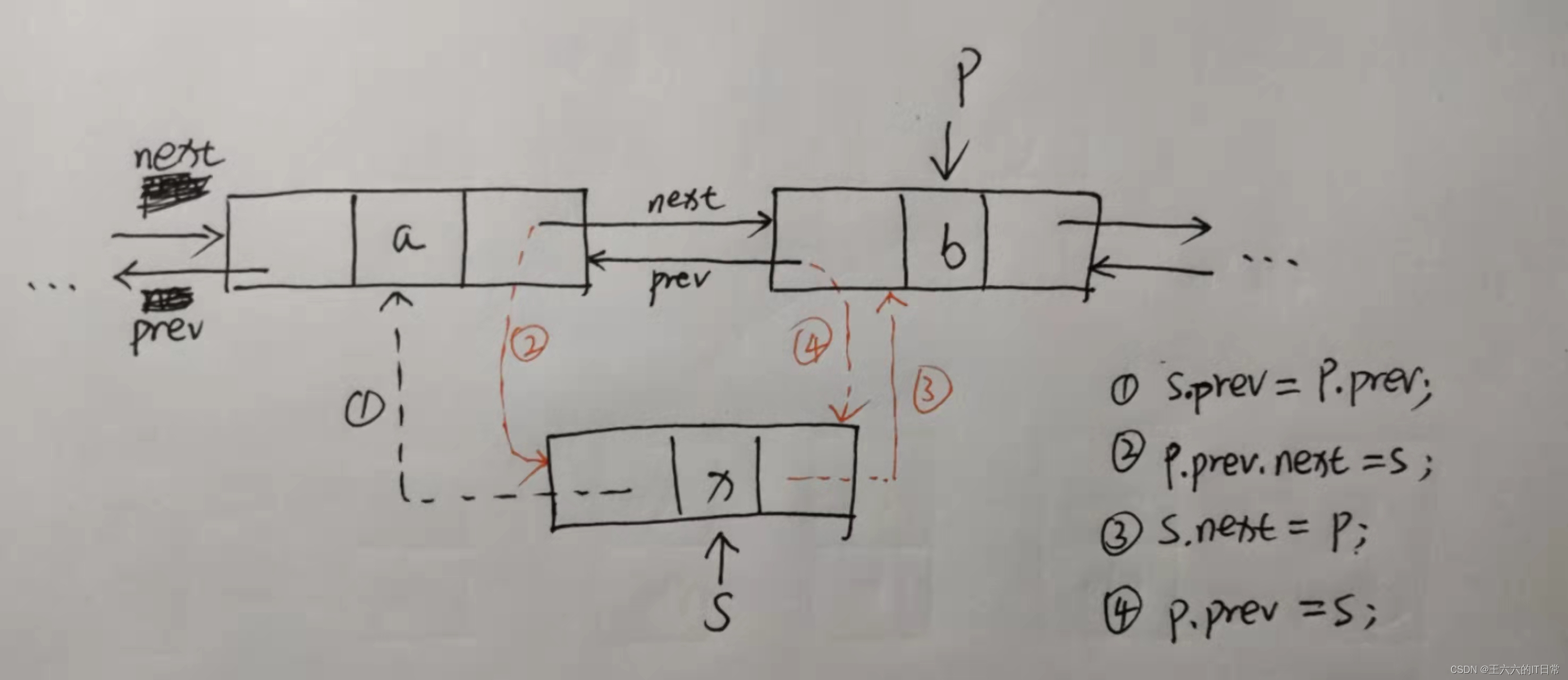
双向链表的插入操作: