1 哈希槽是什么
1.1 为什么出现?
????????由于一致性哈希算法的数据倾斜问题,Redis集群并没有使用一致性hash而是引入了哈希槽的概念。
????????哈希槽实质就是一个数组空间,数组[0, 2^14 - 1]形成hash solt空间。
2.2 能干什么?
????????解决均匀分配问题,在数据和节点之间又加入了一层,把这层称为哈希槽(slot),用于管理数据和节点之间的关系,现在就相当于节点上放的是槽,槽里放的是数据。
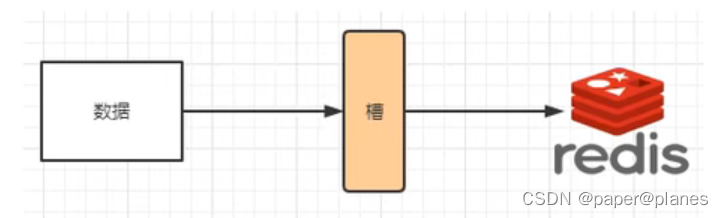
槽解决的是粒度问题,相当于把粒度变大,这样便于数据移动。
哈希解决的是映射问题,使用key的哈希值来计算所在的槽,便于数据分配。
2.3 多少个hash槽
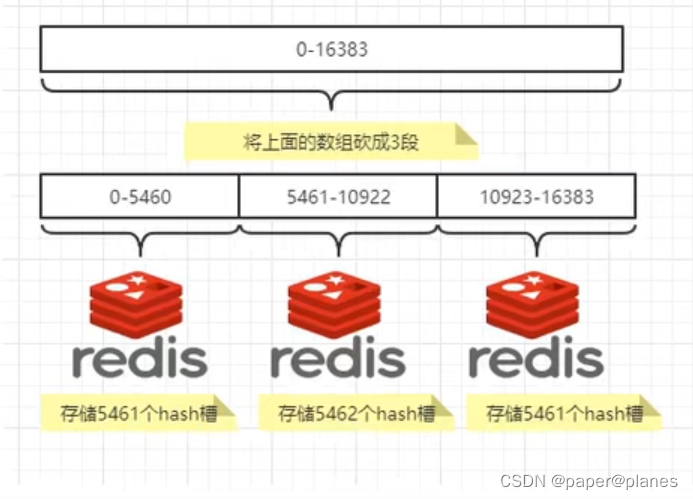
? ? ? ? 一个集群只能有16384个槽,编号0--16383。这些槽会分配给集群中所有主节点,分配策略没有要求。可以指定哪些编号的槽分配给哪个主节点。集群会记录节点和槽的对应关系。解决了节点和槽的关系后,接下来就需要对key求哈希值,然后对16384取余,余数是几key就落入对应的槽里。slot = CRC16(key) % 16384。以槽为单位移动数据,因为槽的数目是固定的,处理起来比较容易,这样数据移动问题就解决了。
| CRC16算法产生的hash值有16bit,该算法可以产生2^16=65536个值。 换句话说值是分布在0~~65535之间。那在做mod运算的时候,为什么不mod65536,而选择mod16384? |
(1)如果槽位为65536,发送心跳信息的消息头达8k,发送的心跳包过于庞大。
(2)redis的集群主要节点数量基本不可能超过1000个。
(3)槽位越小,节点少的情况下,压缩比高,容易传输
希槽计算
Redis集群中内置了16384个哈希槽,redis会根据节点数量大致均等的将哈希槽映射到不同的节点。当需要在Redis集群中放置一个key-value时,redis先对key使用crc16算法算出一个结果,然后把结果对16384求余数,这样每个key都会对应一个编号在0--16383之间的哈希槽,也就是映射到某个节点上。如下代码,key之A、B在Node2,key之C落在Node3上
@Test
public void test3(){
//import io.lettuce.core.cluster.SlotHash;
System.out.println(SlotHash.getSlot("A")); //6373
System.out.println(SlotHash.getSlot("B")); //10374
System.out.println(SlotHash.getSlot("C")); //14503
System.out.println(SlotHash.getSlot("hello")); //866
}