- AlphaGo ���ĵ�ַ:https://www.nature.com/articles/nature16961
- AlphaGo Zero ���ĵ�ַ:https://www.nature.com/articles/nature24270
- AlphaZero ���ĵ�ַ:https://arxiv.org/abs/1712.01815
- MuZero ���ĵ�ַ:https://arxiv.org/abs/1911.08265
DeepMind ��������:https://deepmind.com/research/case-studies/alphago-the-story-so-far
4. AlphaZero
2017 ���,DeepMind �Ƴ��� AlphaZero,����һ�����㿪ʼ��ѧ������չ������塢�ձ�����(Shogi)��Χ����Ϸ�ĵ�һϵͳ,����Щ��Ϸ�ж��ܻ�������ھ������������� AlphaZero ����Ϸ�п�����һ�������Եġ��߶ȶ�̬�ġ��Ǵ�ͳ����Ϸ���,��֮ǰ���κ���Ϸ�������ڲ�ͬ��
AlphaGo Zero �㷨��Χ�������ȡ���˳��˵ı���,��ͨ��ʹ����Ⱦ�������������ʾΧ��֪ʶ,��������ȫ��ͨ�������Ҳ����н���ǿ��ѧϰ��ѵ���ġ��� AlphaZero Ӧ����һ�����Ƶ�ͨ�õ��㷨��
1997 ��,�����ڹ��������������������ھ�,ʵ�����˹����ܵ���̱����ڽ������Ķ�ʮ����,��������������������Ȳ���Խ����ˮƽ����Щ����ʹ��ר���ֹ���������������ϸ������Ȩ��������λ��,����ϸ����ܵ� alpha-beta ����,������ʹ�ô������������ʽ�������ض��������Ӧ����չ�Ӵ����������
�ͼ���ĸ����Զ���,������һ���ȹ��������ѵö����Ϸ:������һ������������Ͻ��е�,�κα��Ե��Ķ��ֵ����Ӷ���ı䷽��,�����ܴεڵر��������̵��κεط���֮ǰ��ǿ�Ľ������,�����������Э��(CSA)������ھ� Elmo,����Ŵ��������ھ�����Щ����ʹ����������������������Ƶ��㷨,ͬ���ǻ��ڸ߶��Ż��� alpha-beta ��������������ض��������Ӧ����
Χ��dz��ʺ� AlphaGo ��ʹ�õ�������ܹ�,��Ϊ��Ϸ������ƽ�Ʋ����(����������Ȩ�ع����ṹ��ƥ��),�������ϸ���֮������ڹ�ϵ����Ӧ�����ɶ�������(���������ľֲ��ṹ��ƥ��),��������ת�ͷ���Գ���(����������ǿ�����)������,�ж��ռ�ܼ�(��ÿ�����ܵ�λ�ö����Է���һ������),��Ϸ���������Ϊ�����Ƶ�ʤ����ʧ��,�����㶼�������������ѵ����
��������ͽ��岻̫�ʺ� AlphaGo ��������ṹ����Щ������λ���йغͲ��Գơ��������Զ����Ļ���������������ж��ռ���������������������ӵ����кϷ�Ŀ�ĵ�;���廹���������Ե������ӷŻ������ϡ���������ͽ������Ӯ����֮��,�����ܵ���ƽ��;��ʵ��,������Ϊ�����������ѽ��������ƽ����
AlphaZero �� AlphaGo Zero ��һ����ͨ�õİ汾,���㷨����Χ��ı������״��Ƴ��ġ���������������������ǿ��ѧϰ�㷨( Tabula rasa reinforcement learning )ȡ���˴�ͳ���ij�����ʹ�õ��˹�֪ʶ���ض��������ǿ���ܡ�
4.1 AlphaZero ����ṹ
AlphaZero ���ò���Ϊ �� \theta �� ����������� ( P , V ) = f �� ( s ) (P,V) = f_\theta(s) (P,V)=f��?(s) ,�������˹���Ƶ������������ƶ���������������������罫�����ϵ�λ�� s s s ��Ϊ����,�����һ���ƶ��������� p p p ,����ÿ���ж� a a a �ijɷ� p a = P r ( a �O s ) p_a=Pr(a|s) pa?=Pr(a�Os),�Լ�һ����������λ�� s s s ��Ԥ�ڽ�� z z z �ı���ֵ v v v , v �� E [ z �O s ] v��\mathbb{E}[z|s] v��E[z�Os]��AlphaZero ��ȫ�����Ҳ�����ѧϰ��Щ�ж����ʺͼ�ֵ����;Ȼ������Щ���Ľ���������
AlphaZero ʹ��ͨ�����ؿ��������� (MCTS) �㷨,�����Ǿ����ض�������ǿ���ܵ� alpha-beta ������ÿ����������һϵ��ģ������Ҳ������,��Щ��Ϸ�Ӹ���Ҷ����һ���������ݵ�ǰ������ f �� f_�� f��?,ÿ��ģ��ͨ����ÿ��״̬ s s s ��ѡ����еͷ��ʴ��������ƶ����ʺ�ֵ(�ڴ� s s s ��ѡ�� a a a ������ģ���Ҷ�ӽڵ�״̬��ƽ��ֵ)���ƶ� a a a �����С���������һ������ �� �� ��,��ʾ�ƶ��ĸ��ʷֲ�,���״̬�ķ��ʼ����ɱ�����̰�ġ�
AlphaZero �����������IJ��� �� �� �� ��ͨ�����Ҳ���ǿ��ѧϰѵ����,�������ʼ���IJ��� �� �� �� ��ʼ��ͨ�� MCTS Ϊ�������ѡ���ƶ�������Ϸ a t �� �� t a_t \sim \pi_t at?����t?����Ϸ����ʱ,������Ϸ������վ�λ�� s T s_T sT? ��������,�Լ�����Ϸ��� z z z (-1 Ϊ��,0 Ϊƽ��,+1 ΪӮ)��������������� �� �� �� ����С��Ԥ���� v t v_t vt? ����Ϸ��� z z z ֮������,��ʹ�������� p t p_t pt? ���������� �� t ��_t ��t? �����ƶ������������˵,���� �� �� �� ͨ����ʧ���� l l l ���ݶ��½����е���,����ʧ���� l l l Ϊ�������ͽ�������ʧ���,
( p , v ) = f �� ( s ) , (p,v) = f_\theta(s), (p,v)=f��?(s),
l = ( z ? v ) 2 ? �� ? log ? P + c �O �O �� �O �O 2 ??? ( 1 ) l = (z-v)^2 - \pi^{\top}\log P +c||\theta||^2 \ \ \ (1) l=(z?v)2?��?logP+c�O�O���O�O2???(1)
���� c c c �ǿ��� L 2 L_2 L2? Ȩ������ˮƽ�IJ��������º�IJ������ں��������Ҳ��ġ�
AlphaZero �㷨�����¼���������ԭʼ�� AlphaGo Zero �㷨��ͬ:
- AlphaGo Zero ���Ʋ��Ż���ʤ�ĸ���,�����Ԫ��Ӯ������෴,AlphaZero ����ƺ��Ż�Ԥ�ڽ��,ͬʱ����ƽ�ֻ�DZ�ڵ����������
- Χ��Ĺ������ת�ͷ���(reflection)�Dz���ġ�AlphaGo �� AlphaGo Zero �����ַ�ʽ�����������ʵ������,ͨ��Ϊÿ��λ������ 8 ���ԳƵ�������ѵ�����ݡ����,�� MCTS �����ڼ�,����λ���ڱ�����������֮ǰ,ʹ�����ѡ�����ת�������ת��,�������ؿ��������ڲ�ͬ��ƫ������ƽ���ġ���������ͽ���Ĺ����Dz��ԳƵ�,ͨ����˵,���ܼ���Գ��ԡ�AlphaZero������ͨ�����ַ�ʽѵ������,Ҳ���� MCTS �����ڼ�ת������λ�á�
- �� AlphaGo Zero ��,���Ҳ��ĵ��������֮ǰ���е����е�����������ɵġ���ÿ�ε���ѵ��֮��,������ı��ֶ�Ҫ�����������бȽ�;����������� 55% �����ƻ�ʤ,��ô���ͻ�ȡ���������,���������������������Ҳ��ĶԾ������֮��,AlphaZero ֻ��ά����һ�����ϸ��µĵ�һ������,������ͨ��������ɡ����Ҳ���ͨ��ʹ�ø�����������²���,ʡ���������������������ѡ��
- AlphaGo Zero ͨ����Ҷ˹�Ż������������ij��������� AlphaZero ��,����Ϊ������Ϸ������ͬ�ij�����,�����������Ϸ���е�����Ψһ�����������ӵ���ǰ��������ȷ��̽��������;�������Ϸ���ͺϷ��������ɱ�����
- AlphaZero �� AlphaGo Zero һ��,����״̬�ɿռ�ƽ�����,ֻ����ÿ����Ϸ�Ļ����������ɿռ�ƽ���ƽ����������,ͬ��������ÿ����Ϸ�Ļ�������
4.2 AlphaZero ѵ����Ч��
���߽� AlphaZero �㷨Ӧ���ڹ������塢�����Χ�塣���������������,������Ϸ��ʹ����ͬ���㷨���á�����ܹ��ͳ�����������Ϊÿ����Ϸѵ����һ�������� AlphaZero ʵ����ѵ�������� 700,000 ��(��СΪ 4,096 ��С����),�������ʼ���IJ�����ʼ,ʹ�� 5,000 ����һ�� TPU ����������Ϸ,��ʹ�� 64 ���ڶ��� TPU ��ѵ�������硣
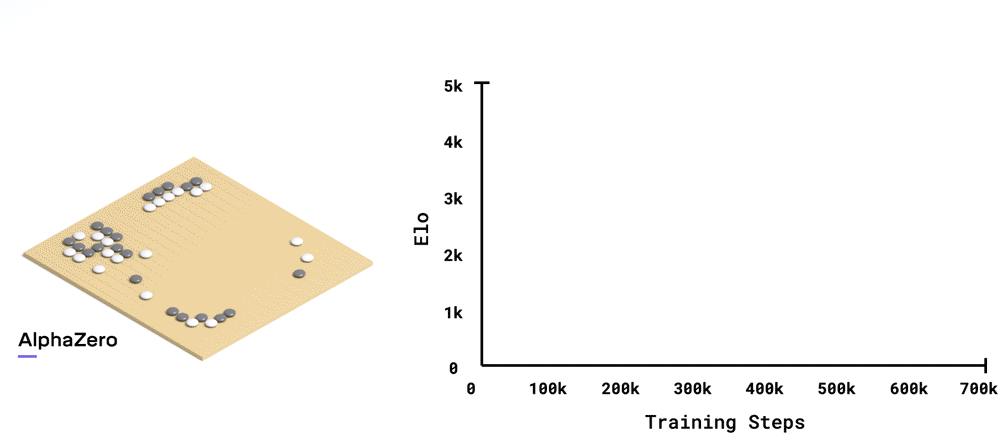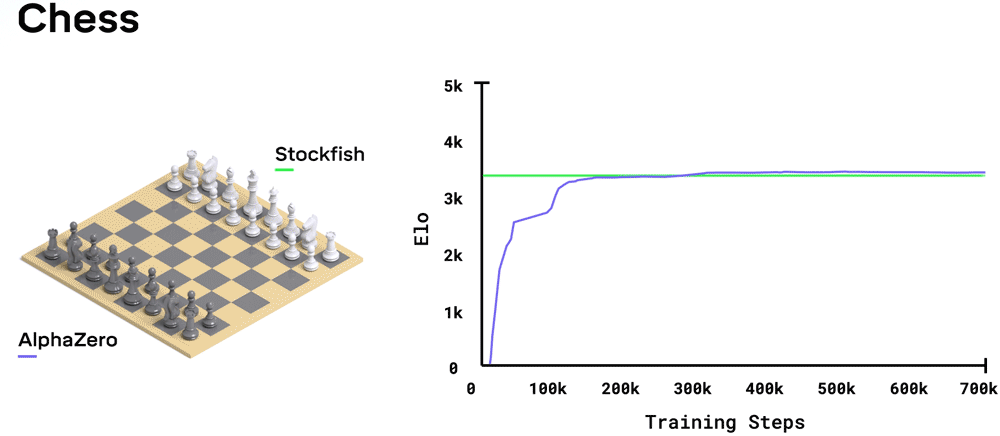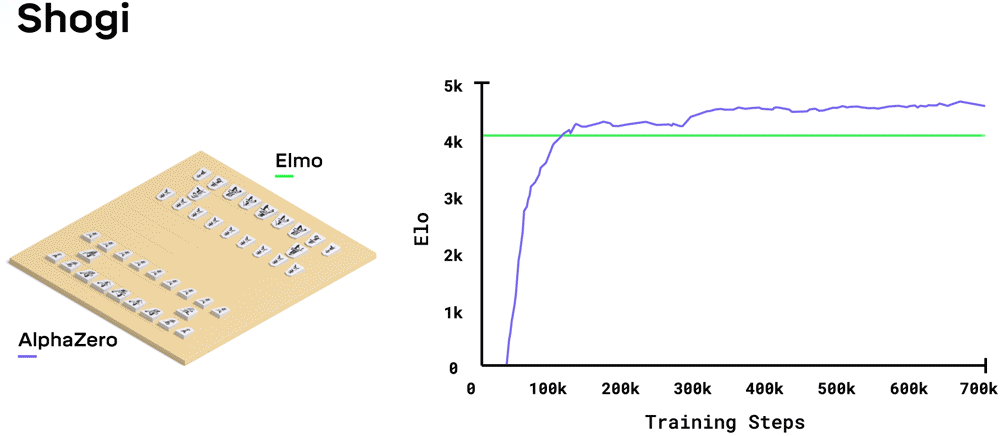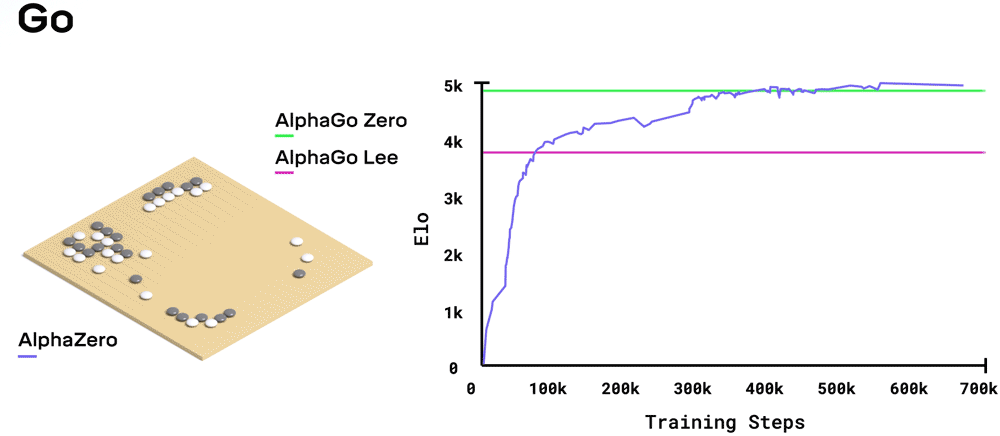
�ڹ���������,AlphaZero �� 4 Сʱ���״γ�Խ Stockfish;�ڽ�����,AlphaZero �� 2 Сʱ���״γ�Խ�� Elmo;����Χ����,AlphaZero �� 30 Сʱ���״γ�Խ�� 2016 ����ܴ�����������ʯ�� AlphaGo �汾��ÿ��ѵ��������� 4,096 ������λ�á�
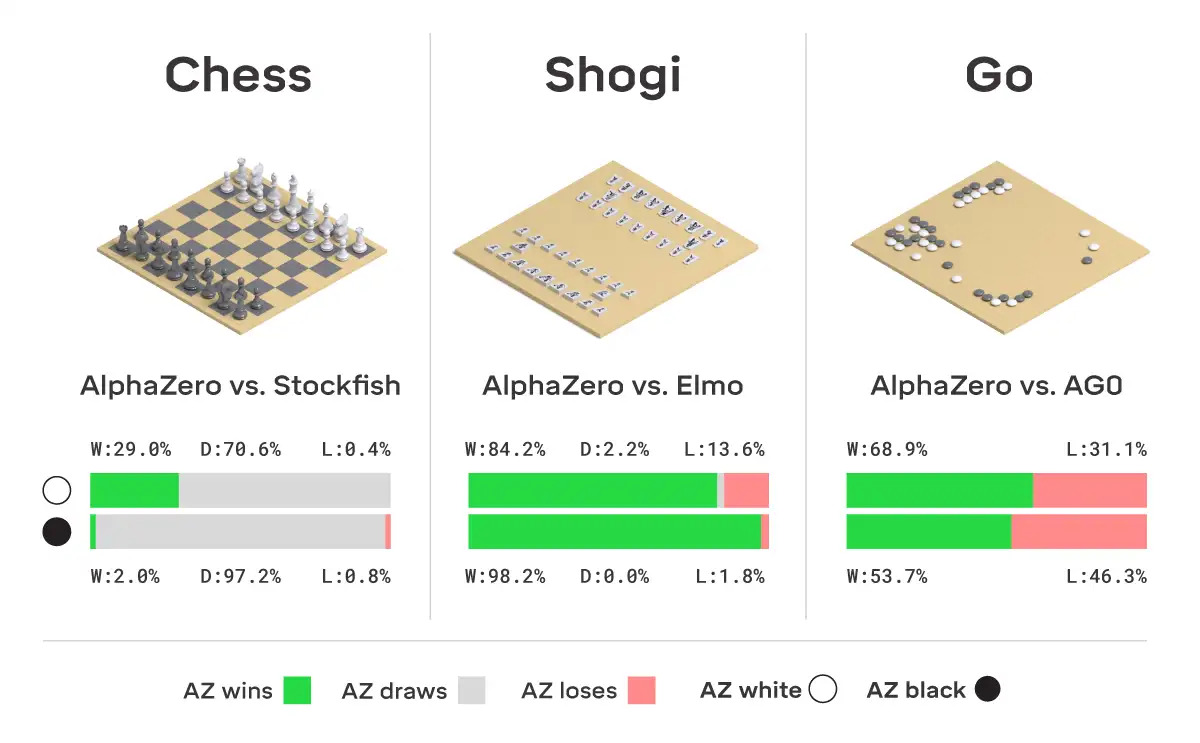
��ÿ��������,AlphaZero ����������ػ����������ھ�����:
- �ڹ���������,AlphaZero ������ 2016 �� TCEC(�� 9 ��)����ھ� Stockfish,Ӯ���� 155 ������,���� 1,000 �������н����� 6 ����Ϊ����֤ AlphaZero ���Ƚ���,����������һϵ�еı���,�ӳ���������ֿ�ʼ����ÿ��������,AlphaZero �������� Stockfish����������һ���� 2016 �� TCEC �����������ʹ�õĿ���λ�ÿ�ʼ�ı���,ͬʱ��������һϵ�ж���ı���,������� Stockfish �����¿����汾,�Լ�ʹ��ǿ�ֵ� Stockfish ���塣�����еı�����,AlphaZero ��Ӯ�ˡ�
- �ڽ�����,AlphaZero ������ 2017 �� CSA ����ھ���� Elmo,Ӯ���� 91.2% �ı�����
- ��Χ����,AlphaZero ������ AlphaGo Zero,Ӯ���� 61% �ĶԾ֡�
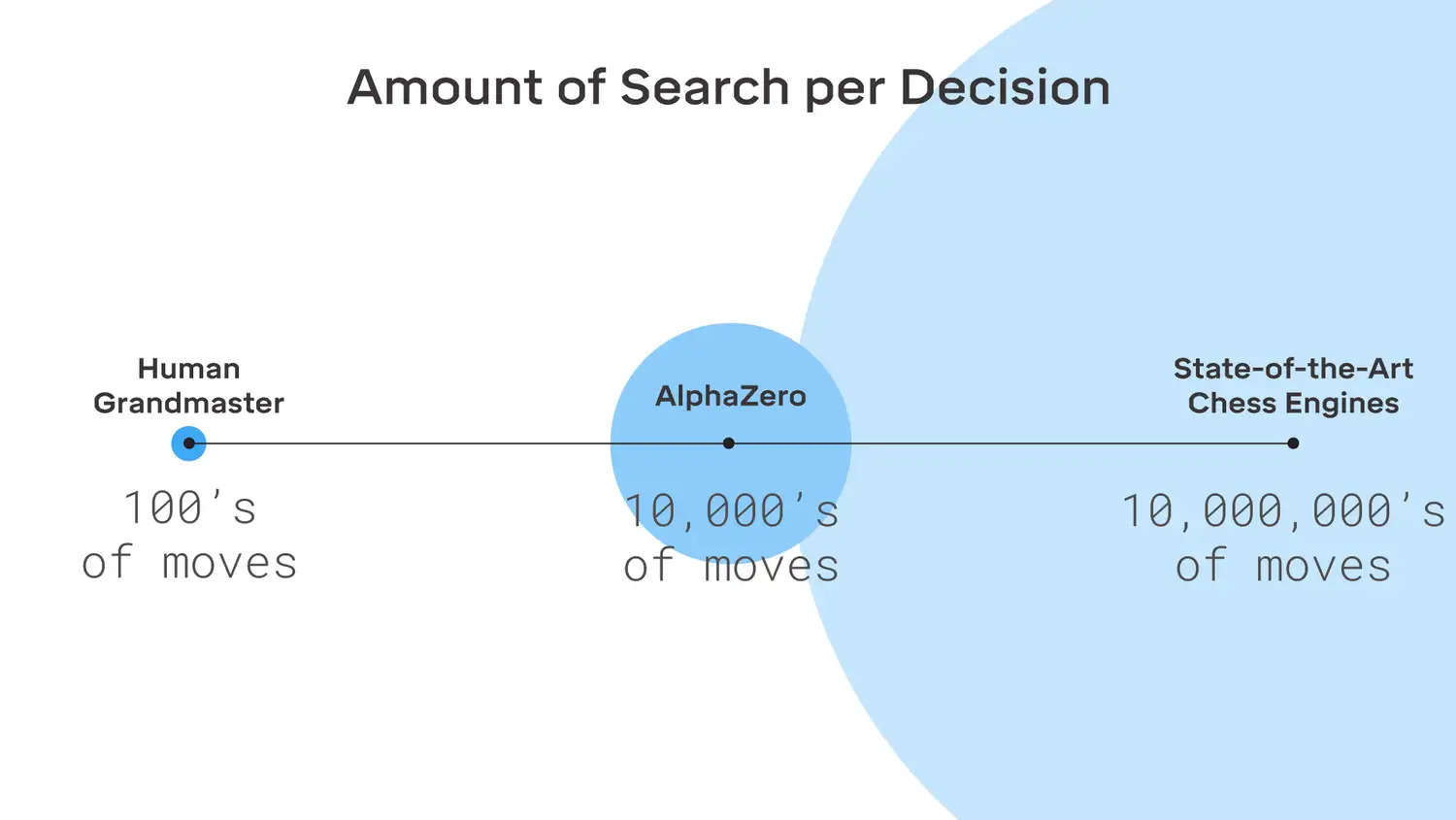
ֵ�ù�ע���Ƕ���ÿһ��,AlphaZero ֻ������ͳ�����������濼�ǵ�һС����λ�á�����,�ڹ���������,��ÿ������� 6 �����������λ��,�� Stockfish ��ԼΪ 6000 �����
�����
- http://tromp.github.io/go.html
- https://towardsdatascience.com/the-upper-confidence-bound-ucb-bandit-algorithm-c05c2bf4c13f
- https://en.wikipedia.org/wiki/AlphaGo
- https://deepmind.com/blog/article/alphago-zero-starting-scratch
- https://towardsdatascience.com/the-evolution-of-alphago-to-muzero-c2c37306bf9