一致性哈希
背景:历史故事
问题
- 服务扩缩容,数据迁移成本
- 数据分布不均匀
- 正常:系统运行效率和性能
- 异常:单点故障或者容灾扩容,容易导致雪崩的连锁反应
解决方案和效果
服务扩缩容,数据迁移成本
传统哈希实现
取模数随着节点数变动而变动,节点数不同的情况下数据集合计算的到的哈希分布变动不稳定,数据迁移通常不稳定,全量迁移的可能性相对较大。
例:服务节点从4个缩容为1个,关注其中数据的分布变化情况(如key=5、key=9数据的变化)
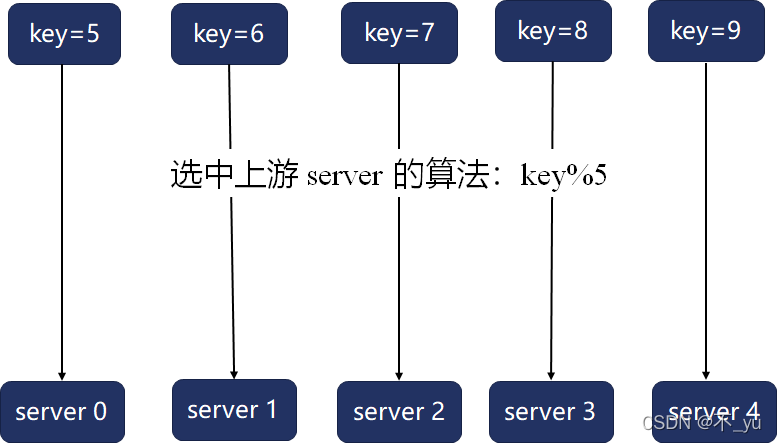
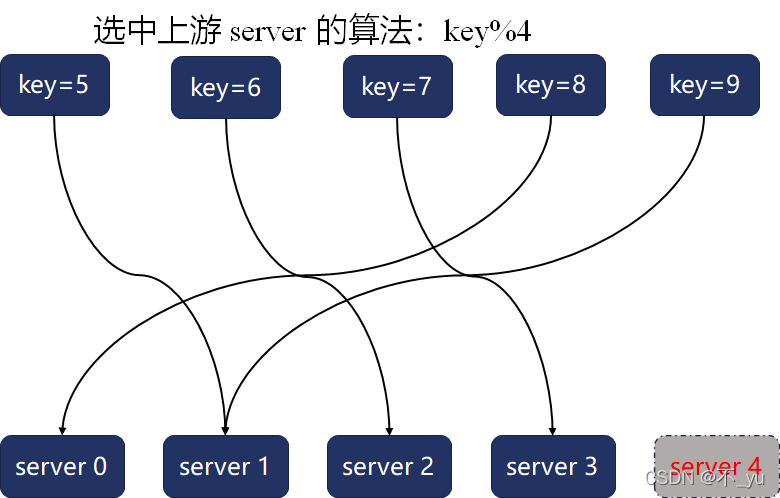
数据迁移成本,假设数据量是M,节点数是N。当服务进行扩缩容时,所有key计算得到的hash值分布和原先的分布大相径庭,那么这种最坏的情况会导致每个服务节点上的全量数据都要进行迁移,时间复杂度是O(M)。
一致性哈希实现
取模数是固定的,和节点数量无关。数据集合计算的到的哈希分布也是稳定的,数据迁移通常是部分的迁移。
例:下面是一个一致性哈希的经典案例
- 首先,将关键字经由通用的哈希函数映射为 32 位整型哈希值。这些哈希值会形成 1 个环,最大的数字 232 相当于 0。
- 其次,设集群节点数为 N,将哈希环由小至大分成 N 段,每个主机节点处理哈希值落在该段内的数据。比如下图中,当节点数 N 等于 3 且均匀地分段时,节点 0 处理哈希值在 [0, 31??232] 范围内的关键字,节点 1 处理 [31??232, 32??232] 范围内的关键字,而节点 2 则处理的范围是 [32??232, 232]
- 3台性能相同的服务器取模分配
- 2:1:1 的权重
- 节点 0 处理哈希值在 [0, 31??232] 范围内的关键字,节点 1 处理 [31??232, 32??232] 范围内的关键字,而节点 2 则处理的范围是 [32??232, 232]

- 3台性能不同的服务器取模分配
- 2:1:1 的权重
- 节点 0 处理的哈希值范围调整为 [0, 231],节点 1 的处理范围调整为 [231, 3?230],节点 2 的处理范围调整为 [3?230, 232]
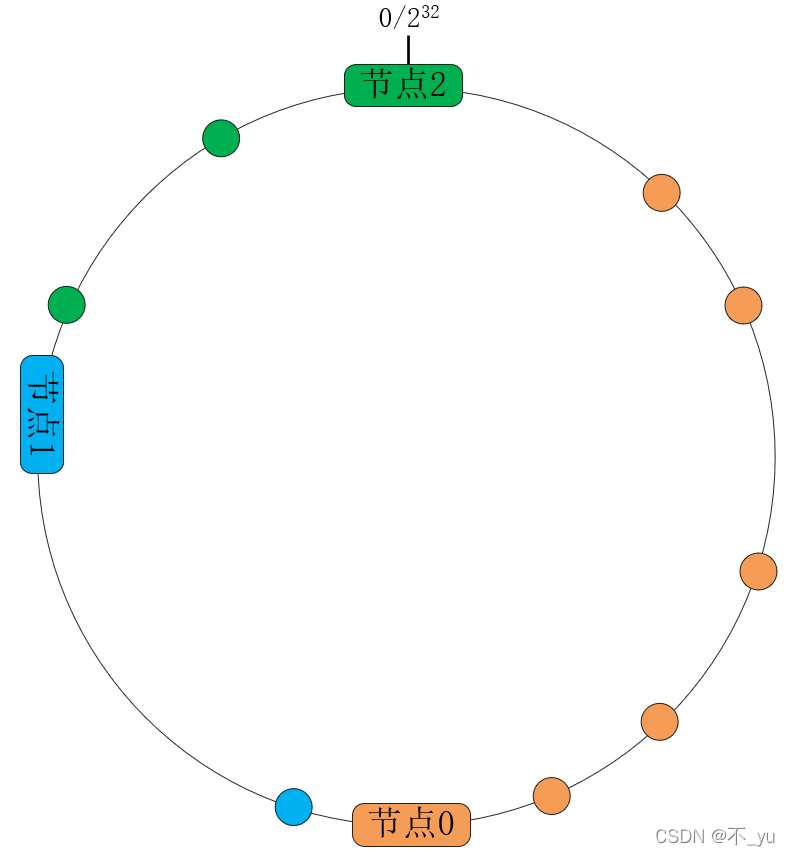
可见,其中取模的值是固定的,于是数据集的hash分布也是稳定的。
数据迁移成本,假设数据量是M,节点数是N。当服务进行扩缩容时,所有key计算得到的hash值分布和原先的分布是几乎没有变化的。那么只要移动M/N的数据量就可以完成数据迁移,时间复杂度也就是O(M/N)。
数据分布不均匀
- 正常:系统运行效率和性能
- 异常:单点故障或者容灾扩容,容易导致雪崩的连锁反应
没有引入虚拟节点层
例:异常情况,节点0宕机,导致0上的数据迁移到相邻的节点1。

引入虚拟节点层
可以理解为额外维护的的一个哈希表,使得物理机上的数据在哈希环上不一定是连续的,可以由隔开的不同分段的数据组合而成。
例:如果图中绿色的节点 0 宕机,按照哈希环上数据的迁移规则,8 个绿色虚拟节点上的数据就会沿着顺时针方向,分别迁移至相邻的虚拟节点上,最终会迁移到真实节点 1(橙色)、节点 2(蓝色)、节点 3(水红色)上。所以,宕机节点上的数据会迁移到其他所有节点上。扩容也是同理。
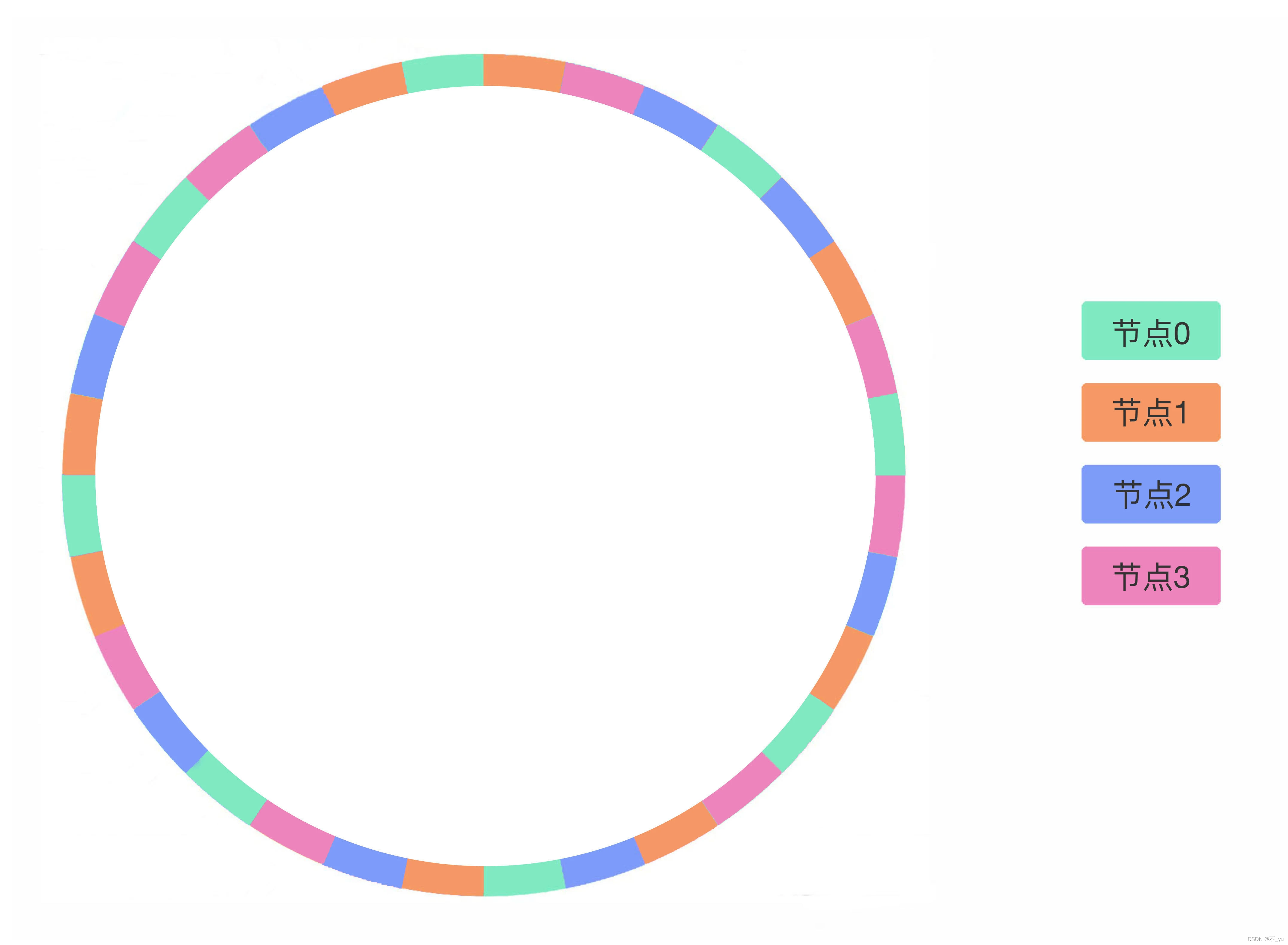
在实际的工程中,虚拟节点的数量会大很多,比如 Nginx 的一致性哈希算法,每个权重为 1 的真实节点就含有160 个虚拟节点。注意,虚拟节点增多虽然会提升均衡性,但也会消耗更多的内存与计算力。