�Ƽ�һ������ѧԺ��ѹ����γ�,���˾�����ʦ���ò���,���������:Linux,Nginx,ZeroMQ,MySQL,Redis,fastdfs,MongoDB,ZK,��ý��,CDN,P2P,K8S,Docker,TCP/IP,Э��,DPDK�ȼ�������,����ѧϰ
����
- ��ʹ?word?��ʱ,word����ж�ij��������
- ��ƴд��ȷ?
- ?����?����,��ô������ȥ����ͬ��url???���������
- �����ʼ�(����)�����㷨������?���������
- �����참ʱ,����ж�ij����?�Ƿ���?��������?������� ������
- ���洩������ν��?���������
���洩

- �������泡��,Ϊ�˼����������ݿ�(mysql)�ķ���ѹ?,��server����mysql֮���??�㻺�����ݲ�(?������ȵ�����);
- ���洩��?�ij�����server�������ݿ���������ʱ,�������ݿ�(redis)���������ݿ�(mysql)��������������,��������ѹ?ȫ��ӿ���������ݿ�(mysql)��
- ����������:����ͼ 2 ������;
- ��?ԭ��:?����?©��α�����ݹ��������ڲ�ҵ��bug�ظ�?�������ڵ�����;
- ���?��:����ͼ 3 ������;
����
- �Ӻ��������в�ѯij�ַ����Ƿ���ڡ�
set��map
- c++����(STL)�е�set��map�ṹ���Dz�?��?��ʵ�ֵ�
- ͼ�ṹʾ��
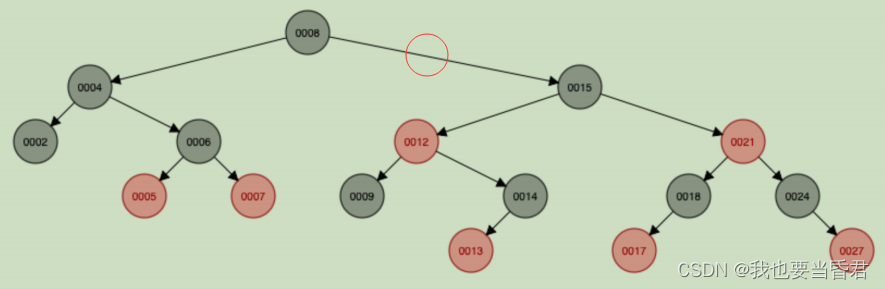
- �����ϸ�ƽ��?��������(AVL),100w��������ɵĺ�?��,ֻ��Ҫ?��20�ξ����ҵ���ֵ;����10��������ֻ��Ҫ?��30�ξ����ҵ�������;Ҳ���Dz��Ҵ���������?����?�µ�;
- ���ں�?����˵ƽ�����?�ڵ�?��,�����о�?�ϴ�����Ҫ��������?�Ȳ�,������ij������·ȫ��?�ڵ�,�����ʱ?��Ϊh1,������ij������·ȫ��?��ڵ���,��ô��ʱ��?��Ϊ2*h1;
- �ں�?����ÿ?���ڵ㶼�洢key��val�ֶ�,key��?����?�ϵ��ֶ�;��?����û��Ҫ��key�ֶ�Ψ?,��set��mapʵ�ֹ�����������key�ֶ�Ψ?����������nginx�ĺ�?��ʵ��:
// ����ǽ�ȡ nginx �ĺ�?����ʵ��,��δ����� insert �����е�?����,ִ?�������������Ҫ����?�ڵ���Ƿ�ƽ��(��Ҫ�ǿ�����?�ڵ��Ƿ�Ҳ�Ǻ�?�ڵ�)
// ��? ngx_rbtree_insert_value ʱ,temp���IJ���Ϊ ��?���ĸ��ڵ�,node���IJ���Ϊ����?�Ľڵ�
void ngx_rbtree_insert_value(ngx_rbtree_node_t *temp, ngx_rbtree_node_t
*node,
ngx_rbtree_node_t *sentinel)
{
ngx_rbtree_node_t **p;
for ( ;; )
{
p = (node->key < temp->key) ? &temp->left : &temp->right;// ��?����Ҫ
if (*p == sentinel)
{
break;
}
temp = *p;
}
*p = node;
node->parent = temp;
node->left = sentinel;
node->right = sentinel;
ngx_rbt_red(node);
}
// ����?��ͬ�ڵ� �����?��ͬ ��������IJ��� ��ʱ ��?�����оͲ�������ͬ��key�˶�ʱ�� key ʱ���
// ������Dz�?key = 12,����ͼ��?��,12�Žڵ�Ӧ�����ĸ�λ��? �������Ҫʵ�ֲ�?���ڵĽڵ����IJ���,����ô����?�ĺ���
void ngx_rbtree_insert_value_ex(ngx_rbtree_node_t *temp, ngx_rbtree_node_t
*node,
ngx_rbtree_node_t *sentinel)
{
ngx_rbtree_node_t **p;
for ( ;; )
{
// {-------------add-------------
if (node->key == temp->key)
{
temp->value = node->value;
return;
}
// }-------------add-------------
p = (node->key < temp->key) ? &temp->left : &temp->right;// ��?����Ҫ
if (*p == sentinel)
{
break;
}
temp = *p;
}
*p = node;
node->parent = temp;
node->left = sentinel;
node->right = sentinel;
ngx_rbt_red(node);
}
- ����set��map�Ĺؼ�������set���洢val�ֶ�;
- �ŵ�:�洢Ч��?,�����ٶ�?Ч;
- ȱ��:����������?�Ҳ�ѯ�ַ���?��?�Ҳ�ѯ�ַ�������ʱ������ج��;
����֪���˵�һ��������������Ҫ�ҵ����λ��,Ȼ���ذ�������Ϊ��ɫ�ڵ�,�ҵ���ɫ�ڵ�֮�������Ǿ���Ҫ������ɫ,������ǵĽڵ���һ����,��ɫ��һ���Ļ����Ǻ�ɫ�Ļ�,������Dz���Ľڵ�����ĸ��ڵ㶼�Ǻ�ɫ�Ļ�,��ô���ǾͲ���Ҫ������ɫ,�������������ڽڵ�ĸ߶Ȳ�һ��,�����ǻ���Ҫ��������ת����ת�Բ���?
��,��ô���������Dz����ҵ�����������һ�δ���,����Ҫ���ҵ����Ǵ�����Ľڵ��λ��,�ҵ����λ�ò���ɫ����ҿ��������һ���ؾ��Ǹ���������ڵ������ɫ��
**�������������?**������Ҫ��������������,��һ,�ҵ�������ڵ��λ��,Ȼ�������Ǿͽ�����ڵ�����Ϊ��ɫ,
��,��Ȼ���浱Ȼ���������������,�����Ż���Ҫ����Ԥ���ڵ��ж�,�Բ���?��ɫ�Ƚ�������Ǻ�ɫ,��ô���Ǿ���Ҫ������ɫ,�Բ���?��,������ɫ֮��,����������IJ�ƽ��,������ɫ,��������˲�ƽ��,���Ǻ�ɫ�ڵ㲻ƽ��,��ô����Ҫͨ����ת���ﵽƽ������á�
�����������������������,����1��2,����������ܵ������ؾ���1��2��
��������������������������ǵ�1��2���������
��ô��������һ��,��ô������������������ڵ�����������һ������жϡ�
��ҿ�һ������ж�����ж��ؾ��Ǹ�������,���ȸ����ǵ�����ڵ�Ƚ�,���
������,��ҿ�һ��,������ŵ���������������˵һ��������� temp,
��� temp�����IJ����������Ǻ�ɫ�ĸ��ڵ�,���Ǻ�����ĸ��ڵ�,�����ǵĸ��ڵ�,
�����ǵ�node�������Ǵ�����Ľڵ�,������Ľڵ㡣
��,��Ҽ�סһ�´�Ҽ�סһ�¶�˫Ŀ��������,
Ҳ����˵���Ǵ�����Ľڵ�,����˵����������һ��12,�����˼��һ��,���Dz���12,��ô��������ڵ�?
����8���Ǹ�8�ڵ���бȽ�,����������8,�����������ұ߲���,���ұ߲߱��ҡ�
��ҿ�һ�������С��temp�����ǵĸ��ڵ�Բ���?���ڵ㡣
�������С�����Ļ�,���������Ǵ�������������8����ڵ�,
����8����ڵ����8����ڵ��Dz������ұ���?��ô����15�Բ���?15,��,Ȼ������� temp����15����ڵ�,��� temp����15�Žڵ�,
���ʱ�������ǵ�12���15�Ƚ�,���Dz���С�����ǵ�15, 12С��15,���������,
�Dz��ǵ�12��?
���ע�����ʱ�����Ǵ�����Ľڵ���12,��� tempҲ��ָ��12,�������ڴ�����Ľڵ���12,
���Ҹ����DZȽϵĽڵ���Ҳ��12,��ô��������Ӧ������ôӦ����ô��Ӧ����ô��?
�������һ������Ӧ����ô��?
������������������ұ���?��ҿ�һ�������Ŵ���������������������ұ���?�������node����temp key,����ǵ��ڵ�,��ô����Ӧ�����ı���?
������������ұ���?��������ǵ��������Dz������ұ��߶Բ���?��,�����ұ��ߡ�
���ǵ�node,node�������Ǵ�����Ľڵ���12,���12С��12 12��С��12��?��Ȼ�Dz������ĶԲ���?�������������,���������ұ���,�����ؾ�����14����߶Բ���?��,��ô����12��14�Ƚ���,��ô����������������ұ���?�������Ǹ�14�Žڵ���бȽϺ�,�������������,�����ǵ���13����ڵ���������������ұ���?
�Dz���С�����Dz����������?�Dz��ǽ����������?��ô�������ڲ�����������Ҫ�����node����12�Žڵ�Ļ�,��ô�����Dz��Dz������λ��?
����12Ӧ��Ҫ����������,���������������ʲô����δ����������ʲô��?
���ǿ��Բ�����ͬ��key,
������Ľ����ؾ������ǿ��Բ�����ͬ��node,���Ǻ�����������ǿ��Բ�����ͬ�Ľڵ�,
���ǿ��Բ�����ͬ�Ľڵ�,��ô������ͬ�Ľڵ��
��һ����ʲô?�������������������ô����,��,��ô����������Ҫʵ��,
����������Ҫʵ�ֲ��ܲ�����ͬ�Ľڵ�,����Ҫʵ��һ�����ܲ�����ͬ�Ľڵ�Ӧ����ô��?
���Dz�������ͬ�Ľڵ�Ӧ����ô��?�����Dz��ǿ���Լ��һ��,���������ͬ�Ľڵ�,������Ϊ��ֵ����,�����IJ�����
�Բ���?��ô�����ͬ�Ļ�,��ô���Ǿͱ���ĵIJ���,��ô����Ӧ����ô��?
��Ÿ���һ���汾,��ô�����Dz��ǿ����������Ŀ����֮ǰ��һ���ж�?
�����ȵĻ�,������ǵ�ǰ��t���������ڱȽϵ�k��ȵĻ�,��ô�����Dz���ֱ�ӽ��и�ֵ������?
���ǰ����ֵ�ľ����ˡ�

���Ǽ�������һ������֮��,���Ǿͻ�ֻ�DZ���IJ���,��ô���Ǵ�ʱ
��ʱ���ע����,��ʱ���������������оͲ�������ͬ��key�ˡ�
��,��������Ҳ����ҽ���һ�¾������ǵĺ����������������ʵ�����ǵĶ�ʱ��,
��ʱ����Ҷ�֪�����������t��ʱ����Ļ�,
k�洢���ǵ�ʱ����Ļ�,�����Dz��Dz��ܱ�֤���ʱ����Ƿ���ͬ��ͬ,���ǿ��ܻ����һ����ͬ��ʱ�������,
Ҳ����˵���ǵĺ�����������Դ洢��ͬ��key,���������ؾ��������ɫ����Ҫ�ı��,���Ǹո�������12��Ҫ������ɫ��,
�������10�Ų����ʱ������һ����ɫ�ڵ�,��Ҫ������ɫ
��ô����������һ�����ǵ�set��map���Ĺؼ�����,ʲô�йؼ�����?��������Ҫ������
�ոո����д��,���Ǻ�����Ľڵ���,���ȴ洢���ǵ�keyҲ�洢���ǵ�value,�Dz���?���ǵ�map�Ͳ��洢��� Value�ֶξ����ˡ�
��������ؾ���������ƽ��������������,�������Ժ�������˽�Ļ�,���Ǿͻ�
֪����ôȥ���������ǵ�map,�ڶ����ֶε�valueֵ�Dz��Dz���Ҫ�洢,��Ϊ����
�Ǹ�map��key�����DZȽϵĹؼ�Ԫ��,��� Key value���key�������������Ƚϵ���������ĶԲ���?�����Ƚϵġ�
��,��������һ�����ǵ��ŵ��ȱ��,
����ش��˼��һ�����ǵĺ�������Dz���û���˷ѿռ�,û���˷ѿռ�,���ǵ�key��value���Ǵ洢�����ǵ�����ڵ㵱��,����û�ж�����˷ѿռ�ȥ�洢���ǵ�Ԫ��,
���Ӧ���ܹ������?���ǵĺ����������û���˷����ǵĸ���Ŀռ����洢���ǵĽڵ�**,�����ط����ٶȸ�Ч,��Ȼ��������ٶȸ�Ч��**
����ԵĶԲ���?������Ǵ洢һ�������ǵ�Ȼ��ܿ�Բ���?
��ô���100�������ݱȽ�20��,���������������Ϊkey�Ļ�,��ô20���Dz��Ǻܺܿ찡�������Ժ��Բ����Բ���?��ô1���������Dz���Ҳ���Ժ��Բ���,��������ȥ��ѯ��ʱ��,
��ô����ȱ���ش������,������ǵ�������,��Ϊ�������������洢��key��value����Ҫ�洢,
����������������Dz�ѯ�ַ����Ƚϳ���ʱ��,���DZȽϵ����DZȽ��鷳�ġ�
�����������ַ��������ǵ��ʼ���������Ϊkey�Ļ�,��ô���DZȽ������ػ�dz���ʱ,����Ч�����Ƿdz��͵�,������ǵIJ�ѯ�ַ������Ƶ�ʱ��,ʲô������?
�ַ������Ƶ�ʱ��,���ıȽϴ���,�Ƚ��ؾͻ�Խ��ʱ,������Ӧ����������?�����ַ�������,��ô���DZȽ�������Ҳ���ʱ��,��ô����ַ����Ƚϳ�,��Ҳ���ʱ��,��������,���Ǵ洢��Ҳ�Ƚ϶ࡣ
��ô������˼��һ������һ�����ݽṹ,Ҳ�������ǵ�STL�����Ǹ�unordered_map
unordered_map
-
c++����(STL)�е�unordered_map<string, bool>�Dz�?hashtableʵ�ֵ�;
-
����:����+hash����;
-
���ǽ��ַ���ͨ��hash����?��?��������ӳ�䵽���鵱��;����ɾ�IJ��ʱ�临�Ӷ���o(1);
-
ͼ�ṹʾ��:
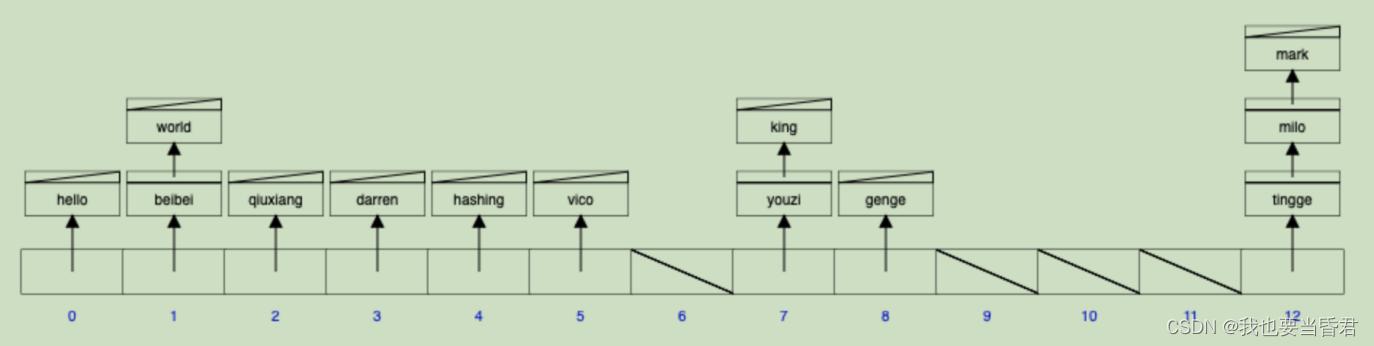
-
hash��������?:�����?��ʱ���ַ�����?��;hash�������������ֵͨ��������?�ȵ�ȡģ������ֲ������鵱��;
-
hash����?�㷵�ص���64λ����,�����?��ӳ�䵽?��?������,��Ȼ���?��ͻ;
-
���ѡȡhash����?
1.ѡȡ�����ٶȿ�;
2.��ϣ�����ַ����ܱ���ǿ����ֲ���(����ײ); -
murmurhash1,murmurhash2,murmurhash3,siphash(redis6.0����ʹ?,rust��?������?ѡ?��hash�㷨��ʵ��hashmap),cityhash���߱�ǿ����ֲ���;���Ե�ַ����:
https://github.com/aappleby/smhasher -
������?:����洢Ԫ�صĸ���/����?��;������?Խ?,��ͻԽ?;������?Խ?,��ͻԽ?;
-
hash��ͻ���?��:
- ������
��?������������ϣ��ͻ;Ҳ���ǽ���ͻԪ��?������������;��Ҳ�dz�?�Ĵ�����ͻ��?ʽ;���ǿ��ܳ���?�ּ������,��ͻԪ��?�϶�,�ó�ͻ������?,���ʱ����Խ��������ת��Ϊ��?��;��ԭ������ʱ�临�Ӷ� o(n) ת��Ϊ��?��ʱ�临�Ӷ� ;��ô�жϸ�������?�������Ƕ���?���Բ�?����256(����ֵ)���ڵ��ʱ�������ṹת��Ϊ��?���ṹ;
-����Ѱַ��
�����е�Ԫ�ض�����ڹ�ϣ����������,��ʹ?��������ݽṹ;?��ʹ?����̽���˼·���;
- ����?��Ԫ�ص�ʱ,ʹ?��ϣ�����ڹ�ϣ���ж�λԪ��λ��;
- ��������иò�λ�����Ƿ����Ԫ�ء�����ò�λΪ��,���?,����3;
- �� 2 ���IJ�λ�����ϼ�?����?���ż��2;
��?����?������?��:- i+1,i+2,i+3,i+4 �� i+n
- i- ,i+ ,i- ,1+ ��
- ������
�����ֶ��ᵼ��ͬ��hash�ۼ�;Ҳ���ǽ���ֵ����hashֵҲ����,��ô���������λҲ����,�γ�hash�ۼ�;��?��ͬ��ۼ���ͻ��ǰ,��?��ֻ�ǽ��ۼ���ͻ�Ӻ�;
�������ʹ?˫�ع�ϣ�������?����hash�ۼ�����:
��.net HashTable���hash����Hk��������:
Hk(key) = [GetHash(key) + k * (1 + (((GetHash(key) >> 5) + 1) %
(hashsize �C 1)))] % hashsize
�ڴ� (1 + (((GetHash(key) >> 5) + 1) % (hashsize �C 1))) �� hashsize
��Ϊ����(������Ϊ������ʾ����û�й�ͬ������?);
ִ?�� hashsize ��̽���,��ϣ���е�ÿ?��λ�ö�����ֻ��?�α����ʵ�,Ҳ����˵,���ڸ����� key,�Թ�ϣ���е�ͬ?λ�ò���ͬʱʹ? Hi �� Hj;
����ԭ��:https://www.cnblogs.com/organic/p/6283476.html
- ͬ����hashtable�нڵ�洢��key��val,hashtable��û��Ҫ��key��??˳��,����ͬ�������Ĵ����ò�?���ڵ����ݱ���IJ���;
- �ŵ�:�����ٶȸ���;����Ҫ��?�ַ���?��;
- ȱ��:��Ҫ��?���Ա����ͻ,�洢Ч�ʲ�?;�ռ任ʱ��;
Ҳ�������ǵ�c++����(STL)�е�unordered_map<string, bool>��
��,���Ӧ��ʹ�ù��Բ���?���Dz���ʹ������,ʹ�����������ǵ�mapûʲô������,�Բ���?�����ǵ�mapʹ��������û�ж��IJ���Բ���?
��ô�����������ʵ��,���е�����û��ʹ�ù������� unordered_map�����ǵ�mapʹ������ûʲô����,��Ҳ��һ��key��value��
��ʹ������ûʲô����,��ô��������һ�����ǵ�����ʲô��ͬ,���ƽ���ڹ����Ĺ��̵��������ѡ��map������ѡ��unordered_map,����Ӧ�������ѡ����?
��,��������������������Ҫ��ȷ����unordered_map�������ɹ�ϣtable��ʵ�ֵ�,
unordered_map���Ĺ����ؾ�������������ǵĹ�ϣ����,������Ϲ�ϣ����,Ҳ���Ǹ��������ͼ�Ľṹ�غ�����,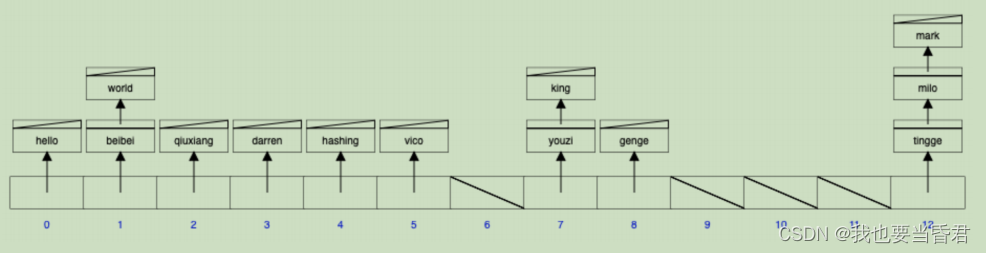
����������ṹ������,����������һ������ ,Ȼ��������ÿһ������������������������ͬʱ��ϣ����ͬ��λ�İ�����������,������һ���ṹ���ǹ�ϣ����,��ϣ�����ǽ����ǵ��ַ���,�����?��ʱ���ַ�����?��;hash�������������ֵͨ��������?�ȵ�ȡģ������ֲ������鵱��;
����˵���ǽ����������ǽ��ַ���ȥһ�������ַ������ȥ��ѯ�Ƿ����,��ô
���������ϣ�����ؾ��Ƕ����ǵ���� key��� key���й�ϣ,
Ȼ������һ������,��������֮��,���һ��������64λ������,64λ��������Ȼ����ӳ������ǵ�������鳤�Ƚ���ȡ�ࡣ
����˵�������������12,��ô���ɵ������ض����ǵ�12����ȡ��,ȡ��֮�������Ǿͻ��䵽����������鵱�е�ijһ��λ�õ���,���ǽ����������
��λ�õ���,���ǵ������ϣ�����ݽṹ,�����ǽ����ǵĺᴮͨ����ϣ������ϣ��һ������,Ȼ��ӳ�䵽����������鵱��,Ȼ�����Ǿͽ���� key��value�洢�����ǵ�������鵱��,��,�����ǵ�ǰ������ṹ�رȽ����ơ�
��,��ô���Ǿ���Ҫ��ȷһ��������,
����ΪʲôҪʹ�ù�ϣ����?ΪʲôҪʹ�ù�ϣ����?
��Ȼ����Ƿǵ�����ǰ��ʹ��map�ṹ��ʱ��,����ַ����ܳ��Ļ�,���ǵ�˵��ѯЧ�ʸ�,����Ч�ʸ������,��ô����ǰ��map��һ��ǵð����ǵĺ���������нڵ�Ƚϵ�ʱ��,����Ҫ�Ƚ�key
�Բ���?������Ҫ�Ƚ�key��ô���ǰ�unordered_map�����ͽ��һ�����DZ������ַ����ıȽ�,
���������?
����ȥ����ڵ��ʱ��,�����Dz���Ҫ�����ǽ��бȽ�,����ֱ��ͨ��һ����ϣ����ӳ�䵽ijһ��λ��,
��ô����ȥ��������ʱ��,��ͬ������ͨ�������ϣ����ӳ�䵽��ͬ��λ��,�Բ���?�����ϣ����ͬ��λ��,
��ô�����Dz��Dz���Ҫ�Ƚ�,���ǹ���ĺ����Dz��ǽ����һ���Ƚϵ�����?
���ǵ�map��Ȼ���IJ���Ч�ʸ�,���DZȽ��ַ����Ƿdz�������
��Ȼ������г�ͻ��ʱ��������Ҫ�Ƚϵ�,�����䵽�����λ����Ϊ��
������������г�ͻ��ʱ��,�����ǻ�Ҫ��key���εıȽϡ�
��ô������Ƕ�ӳ�䵽���λ��,ӳ�䵽���λ�����ǵĹ�ϣֵ,
Ȼ���ٸ����ǵ�����ȡ���Ժ���,����������ͬ��λ��,��ô�����ǻ���Ҫ�Ƚ��������ַ�����,
��������г�ͻ�������,��ȻҪ�Ƚ����ǵ��ַ���,��ȻҪ�����ַ����ıȽ�,
����ֻ�Dz��������ʱ����Ҫ�Ƚ�.
ȡģ֮�������ܹ�����ֲ������鵱��,
����ķֲ������鵱��,Ҳ����˵���ǹ�ϣ������Ŀ���ؾ����������Dz���ڵ��ʱ��,���ܹ�����ֲ�������������鵱��,�������Ǿͱ����˱���˵���������ͻ��,������ͻ��,�����Dz��ǻ���Ҫ�����ַ����ıȽ�,������ҵ�ʱ������Ҫ�����ַ����ıȽ�,��ô��������һ�����Ĺ�ϣ����������Ŀ���������������ܹ�����ķֲ������ǵ����鵱��,
���ǵĹ�ϣ������һ�㷵�ص���64λ����,���ǽ�һ��64λ���������뵽һ����С�����鵱��,
��ô���п��ܻ������ͻ,��Ȼ�������ͻ,Ϊʲô�������ͻ?
���������ض��Ż��˱Ƚϴ���,��ô��������һ��Ϊʲô
�������һ��Ϊʲô���ǻ��Ȼ������ͻ?
��������ͨ�����ι�ϣ����,��һ����ϣ�����ع�ϣ������ֵ��һ,
�ڶ�����ϣ����������ֵ����5,��ô������ǰ������뵽4����,
������ǰ���ӳ�䵽4������ֵ���4�����ֵ���,�Dz������ǵ�һ���о�?
һ�����ǵĴ���ģ,Ȼ�����1,�Բ���?��ô5��
�����ǵ�4ȡģ�Dz��ǵ���1?Ҳ�ǵ���1,��ô�����Dz��Ƕ��������ǵ�һ�Ų�λ����,��������һ�Ų�λ����?
��,
���ǵĴž����͵ĺ�������DZȽ�����,��ô��������һ��,
��,��ô��������һ��size����8��ʱ��,size����8��ʱ���Dz���һ��ӳ�䵽1,һ��ӳ�䵽5,��ô�����Dz��Ǿͱ�����һ��
��û�г�ͻ��,����ܿ�������?
����ͬ������1��5,���ǵ�����ij����ز�ͬ,�����ǿ��ܾ�һ��������ͻ,��һ����������ͻ,���Ӧ���ܿ����װ�?
��,��ô����Ӧ�������ѡ���ϣ������?
���Ǹ��ݹ�ϣ����������,���Ǿ�֪�������ѡ����,���������Dz���Ҫѡ������ٶȿ��?
����ͨ��һ�������ַ���,�������ǵĹ�ϣ�����ܹ����ٵ��������64λ����,�Բ���?
��ô�ڶ����ؾ��������ַ�����������ܹ�����һ��ǿ����ֲ���,���ʲô��ǿ����ֲ���?���Ǿ����ļ��ٳ�ͻ����,���ǵ�������ȫ���������ǵ����ֵ���,���ٱ���ı������ǵij�ͻ,�Բ���?
��ô����һ��ѡȡ�����Ĺ�ϣ��������murmurhash1,murmurhash2,murmurhash3,siphash(redis6.0����ʹ?,rust��?������?ѡ?��hash�㷨��ʵ��hashmap),����ֲ��Ծ��DZ���˵���Dz���һ��MACһ��MAC��,���ǹ�ϣ������ֵ�ػ����Ƚϴ�,�����������ǵ�һ���оۼ�����,����˵���ǵ�MACһ��ϣ��������,��ôMark����
��֪�������������ؾ���һ�־ۼ���һ�־ۼ���,����һ�����߱�ǿ����ֲ��Ե�,
��ô������ǵ�һ����2,һ����11,����֮���������Զ,��ô���������ؾ;߱�ǿ����ֲ��ԡ�
����ôһ�������Ǿ�ʹ������Щ
murmurhash��ϣϵ�и����ǵ�siphash�����ǵ�c���ϣ�����Ƕ��߱�һ��ǿ����ֲ��ԡ�
������������һ�¸�������,ʲô�и�������?���������������
�����������Dz������ǵĹ�ϣtable�������������ϣ�����������ɵ�,��ô������������Ԫ�ظ������������ij��ȵĹ�ϵ�ı�ֵ�ؾ������ǵ������������,Ҳ����˵��������洢Ԫ�صĸ����������������ij��ȵı�ֵ�ؾ��Ǹ������ӡ�
���������������,ռ���ʵ�����,���Ǵ洢��Ԫ��ռ������������ܹ�ռ�˼���λ��,�Բ���?��Ȼ������ܻ������ͻ,�Բ���?
��ô��������ԽС�Ļ�,��ͻ��ԽС,ʲô�и�������ԽС?
�ؾ���������һ��������,
������Խ����ͻԽС,�������Dz��Ǿͳ�ͻ��ԽС,��������Խ��,��ô�����ǵij�ͻ�ؾͻ�Խ��
����˵����һ�������,�DZ�Ȼ�������ͻ�Բ���?ʲô�д���һ?�������Ǵ洢��Ԫ�ض����������������ij�����,��ô��Ȼ�������ͻ,
�Բ���?����ͱ�Ȼ����һ��ʱ���Ȼ��ͻ��
���dz��ԭ��,����˵7��ƻ���ŵ�6����������,�Dz���������1������������2��ƻ��,���Ӧ�ú���������,
����һ��ʱ���Ȼ�������ͻ,�Բ���?
��,��ô����������һ��,���һ��Ҫ������,�����ڷdz��ؼ�,��Ϊ���ǵĹ�ϣ��ͻ�Ľ�������ؾ�ֱ�����������ǽ����
����������,Ҳ�������ǵ����ܹ�����,��������һ�����ǵĹ�ϣ��ͻ������Щ���������
�������� ��ʾ�����ֹ�ϣ��ͻ�Ľ������,Ϊʲôֻ�г�������,����Ϊ����������ʹ�õ���������,�����Ķ��Dz���ô���õ�,�����Ҽ������ĵ�������û��ʹ�õ�,
ֻ�����������ѵ���������,���������������Ľ����ͻ�ķ�������������û�п�������ʹ�ù�,
��ֻ�����������ֵ�ʹ�÷���,���ǽ����ͻ�����ַ���,��һ���ؾ������ǵ�������,�����ǵ���ʱ����ṹ����1013��
��������Ҫ˵�ĺ���Ҫ��ô,����ؾ���Ϊ�˱����ڴ�Ĵ������ڴ����Ĵ������ڴ�,��Ϊ
�������һ����������,���������ؾ�˵����������������кܶ�����������ͼ������ͼ����
�Dz����е�����IJ�κ����û�д洢������,��69 10 11����û�д洢����,��û�д洢���ݡ�
��,��ô���ǽ�������������,�б������Ǵ����ʹ��
������Ľ������,�����ǵ�radius����,������ʹ�õ�������,�������ؾ��ǽ���ͻ��Ԫ����
�������ķ�ʽ�ذ�����������,������ڵ������������,����ؾ������������õ�����DZȽϳ��õĴ�����ͻ�ķ�ʽ,
�����������ܻ����һ�ּ��˵����,��ҿ�˼��һ��,����˵���������������������ڵ�,��
�������ڵ㷢����ͻ��,��ô����������������Ӻܳ�,����Ƿǵ����ǵ�map,
������������Dz���Ҫ�Ƚ�20��,����˵������100�������Ҫ�Ƚ�20��,��ô������ǵĹ�ϣ��ͻ������20���Ļ�,��ô�Dz���Ч��Ҳ��ܵ�,
�Բ���?
��ô��������ֹ�ϣ��ͻ�����ص��������������ص������,�����ǾͿ���
���������ת���ɺ����ת���ɺ����,�����������ֿ���
���ٱȽϵĴ���,�ֿ��Լ��ٱȽϵĴ���,�����ǵ�Java Java�˴����ؾ�����ô������,�������ǵ�Java���Ե�����������ô������,
�������ǿ����ؽ����������������������,���ǾͰ���ת���ɺ������
��ô
��Ϊ���ǵĵ������ʱ�临�Ӷ���onҲ�����������������,Ҫ�����еĵ������Ҫ�Ƚ�,
��ô������ǰ���ת�ɺ����,�Dz�����ת����o log��,��ô���ǵıȽϴ������ܹ����ļ�С,�Բ���?
��ô����������һ��,��ô��ʵ��Ӧ�ù��̵���,��������б������ж�����б�������
����ʲô,���ǿ��Բ��ó���256������512,������п��������������Ŀ�Դ��Ŀ������ʹ��512��,Ҳ��ʹ��256��,��ô������ؾ���һ������ֵ��
���dz�������ڵ��ʱ��,���Ǿͽ���������ṹת��Ϊ������Ľṹ,���������Ǿͼ�����������ıȽϵĴ���,��������ǵ���������
��,��ô�ڶ��ַ������������û��������һ���µĽṹ,Ҳ����˵��������һ�������Ľṹ�����洢���ǵ����ݶԲ���?
�����������ķ�ʽ,��ô����һ��������Ѱַ��,������ֱ�ӽ����ݴ洢�����ǵ����ݵ���,�������κ����������ݽṹ,
�������κ����������ݽṹ,����������ǵĿ���Ѱִ��,һ������ʹ�����ǵ�����̽���������һ�����˼·,
�Գ�����������ؾ�������,
�ܽ�
��?����hashtable�����ܽ��������������,���Ƕ���Ҫ�洢�����ַ���,���������?,�ṩ����?��G���ڴ�;������Ҫ����̽Ѱ���洢key��?��,����ӵ��hashtable���ŵ�(����Ҫ?���ַ���)
�����������Ǵ�������������,��������
�ó�һ������������������һ���ַ���ȥ����һ���������ݴ����ַ�����һ������ز�ѯ����ַ����Ƿ����,
�������ǵ�һ����������,Ȼ���ػ�������ܽ���һ�¾������ǵ����洩������,������ô���������ԵĹ�����������ش��������,�Լ�
������������������ӵ�,�����������ӵ�,����ʲô���������,��������д������,���������������ݵ�ʱ��
���ֵ�����,��ô���ֵ�������ʲô?
�������ǵ�redis��mysql��������ݶ���������ô�����ǿ��ܺڿ;Ϳ������ô�©��,�Ͳ����������ǵ�mysql�����ݶԲ���?���ҵ�mysql����,�����ؿ��ܻ������ǵ�mysqlѹ������,���ܻ�������������ϵͳ������̱��,�Ͳ��ܶ����ṩ����,������һ������ؾͽ������洩������
��ô���ǵĽ��������Ҳ������,��һ���ؾͲ�����ҽ�����,�ڶ��־���������Ҫ��serve������һ�����ݽṹ�ܹ����ٵ��ж�����ַ����Ƿ���mysql����,���Ǿ���һ�����ݽṹ���ܹ����ٵ��ж���������Ƿ������ǵ�mysql����,��,����ؾ������ǵĻ��洩����Ľ��,Ȼ�������Ǿ����������ǵ�set��map��
Ϊʲô��������Ҫ����ҽ���һ����� set��map��?
Ϊʲô��set��map�������������,��Ϊ�����ִ����������Ǻ���Ϥ�������غ��������뵽��һ�ֽ������
��һ��ǵ�������ǵ������������,���ǵĸ��������Dz���Ҫ
С��һ��ð�С��һ,Ҳ�������ǵ�����ij���Ҫ������������洢Ԫ�صĸ���,�������Խ���Dz������ǵij�ͻ��ԽС?
��ͻ̫��,���ǵ�Ч�ʾͻ����ˡ�
��,���ǽ������ع˰�����ΪʲôҪʹ����������,�������ǵ�set��map������ҽ���,��һ���ǰ��һع�һ������ǰ�����µ��к�������������
�����ʵ���Լ����Dz����ʱ��Ӧ�����������,Ȼ����������Ҳ����ҽ����˸���ҽ������������������Ľڵ�,�����Դ洢��ͬkeys��ֵ,���Դ洢��ͬkey��ֵ,ֻ�����ǵ�map������������������Բ���?
�����������ж�,
Ҳ��������ͨ�������ж��ص��������ǾͰ����ij��IJ���,���Dz����ʱ���ذ������������ͬ��Ԫ��,�����ǾͰ����ij��IJ���,
��������ǵ�ɫ��� map�����ǵĺ����������������,���ǵĺ������û��������,��û�������һ��Ҫ��ס��,��û���������Ƿ���Դ洢��ͬ,
���������ʲô������ set��map��ʵ��,�����Dz���Ҫ����� keyȫ��Ҫ�洢,���ǵ�һ��,������Ҫȫ���洢��
�ڶ�������������ַ����Ƚϳ���ʱ��,���
һ�����ع�һ��,���������ĸ��Ƚϳ���ʱ��,���Ǿ���ֵ�Ƚ�20��30��,��ô��Ҳ��һ���dz���IJ���,��ô���Ч����
����Ҫ���Dz�����������ַ�������ʱ�����Dz��ý����
����һ���������ǵĴ������������,������Ҫȫ���洢��,�Dz�������������?
��ô���������������ַ����Ƚϳ�������,
**�ַ����Ƚϳ���ô��?**��Ϊ���ǵ��ú������ʵ�ֵĻ�,���Ǿͱ�ȻҪ�����ַ����ıȽ�,��ô�������ܲ��ܽ��һ������Ҫ�����ַ����Ƚ�,����ô���Ǿ����������ǵ�unordered_map�İ취,
���Ͳ���Ҫ�����ַ����ıȽ�,��Ϊ������ͨ����ϣ����������ַ���������ַ����ذ���
��ϣ����ϣ��һ������,Ȼ������ӳ�䵽���ǵ����鵱��,���������ǾͿ���
���Բ���Ҫ���бȽ�,�����´�������,�������˵����������������λ,���Dz��ҵ�λ����ڵ�,��ô������һ��
ͨ����ϣ�����Dz��ǻ���ӳ�䵽�������λ��,����û�и��κε��ַ�����������κ��ַ������бȽ�
����˵���Dz���daring����ڵ�,�����Dz��ǻ��ǽ�daring����ַ���ͨ����ϣ������ϣ������,Ȼ��������ӳ�䵽�����λ��,
��ô�Dz�������û�и��κ��ַ�����ַ�Ƚ�?
��ô��Ҳ��������������ǹ�ϣ����������,���������ؾ��ǿ��Ա������Dz����ʱ����һ���ַ����ıȽϡ�
ͬʱ���ǹ�ϣ���������������б���Ҫ�߱�һ������,����������Ҫ�߱�һ��ǿ����ֲ��ԡ�
���˼��һ��,������Ǹոո���Ҿٸ�������,���� Markһ��Mark��,������Dz��߱�ǿ����ֲ��ֲ��ԵĻ�,�������������ϣ����,��ô���ǿ��ܻ�����,������ڵĻ�,�����´β����ʱ����
���ij�ͻ�ļ����ؾͻ��������,����������ij�ͻ�ļ����ػ��������,
��������Ҳ����Ҿ��˼���ǿ����ֲ��Եļ����м�����ϣ����,ʹ�õ����ľ�������������,
��һ����murmurhash2,
���ǵ�rads6.0֮ǰ,radies6.0֮ǰ�ؾ���ʹ�õ����ǵ�murmurhash2,�����Ҳ���Կ�һ��Դ��,��������Ҳ����ע��,���ǵ�radish����������ע��,
���ǿ�����һ�´�ҿ��Կ�һ�����ǵ�murmurhash2,��������֮ǰ������ʹ�õ����ǵ�murmurhash2,
��������֮ǰ�Dz��õ�murmurhash2,,����������ʹ�õ���siphash,����������ע�͵�����
�����ǵ���ʾ,Ҳ����������6.0֮ǰ,���Dz��õ����ǵ�murmurhash2,
�ҵĵȻ�IJ��Դ���,Ҳ�������Ǵ����ϴ��뵱�пٳ����Ĵ���,����Ҳ�Dz��õ����ǵ�murmurhash2,
���ǵ�siphash�������ǵ�redis6.0����Ŀǰʹ�õ���,
��һ�¹�ϣ��ͻ�Ľ��������ϣ��ͻ�����DZ�Ȼ������,Ϊʲô�������������Ȼ������ϣ��ͻ?��һ����һ��ԭ������ԭ��,��һ��ԭ���ؾ����������
��һ���ܴ����ӳ�䵽һ��С���鵱��,�����п��ܾ��DZ�Ȼ�������ͻ���ڶ����ؾ������ǿ����Ǹ������ӵ�ԭ��,�������Ǹ�������Խ��,
����˵��������������Ӵ���2>3,��ô������Ȼ�������ͻ��,��Ϊ���ǵ�����ij��ȶ�С���˶�С���������洢Ԫ�صĸ�����,��ô����Ҳ���Ȼ������ͻ��
��ô�����ܲ������Ѿ�������ͻ��,���Ǿ�Ҫ����ȥ��ô�����ϣ��ͻ�����⡣��һ���ؾ������ǵ��б���Ҳ�dz��õ�һ��
�����ǵ�redis6.0,������ʹ�õ����ǵ�������,��ôredisΪʲôʹ�����ǵ�������?������Ҫԭ�������ǵ�radies6.0,�����ڴ������ϸ��Ҫ���,
**Ҳ����˵���Dz��ܹ��˷ѿռ�������֤��IJ���Ч��,���������Ǿͱ���ʹ��������,**�����ػ����õ���һ��ͷ�淨��
��ô��������һ�½�������Ҫ��һ���������ǿ���Ѱַ��,���ǵ��б���������������һ�����ݽṹ��
�����������ͻ�Ľڵ�,��ô���ǵĿ���Ѱַ�������ǽ����е�Ԫ���ض�����������鵱��,��ʹ�ö�������ݽṹ,
����ʹ���κζ�������ݽṹ��
��,��ô���ǵĿ�����ʽ�������������ַ����������ַ���,��һ����
��,������������һ�¿���ѡַ������һ�����衣
���������Dz�����Ԫ�ص�ʱ��,ʹ�ù�ϣ������ȥ��λԪ�ص�λ��,������Ӧ�úܺ��������⡣
�ڶ����ؾ������������ж���������Ƿ����Ԫ��,����ò�λΪ�������,�����Ϊ���Ǿ��Dz�����ͻ��,������ͻ�����Ǿ��н������,��Ϊ�������
���鲻Ϊ��,�������IJ�κ��Ϊ��,��ô�����IJ�κ���ܻ�Ϊ�նԲ���?��ô���Ǿ�ȥ����,
���Ǿ�ȥ���������IJ�κ�Dz���û��Ԫ�ضԲ���?��ô���ǵ����Ѳ�ӷ�����Ҫ�ĺ���˼�����
ȥ������κû��Ԫ�صĵط�ȥ̽��ʲô��̽��,̽���������������IJ�κû��Ԫ�ص���Щ��κ,
��������ǵĺ���˼��,��ô���ļ��ַ�ʽ��̽��?
�ص�һ�־������Ǻ������뵽��,
����˵���ǵ�ǰ�����Ԫ�ص�����,���������������I��ô���ǿ���I��һ����һ��,
�������������ұ��ƶ�һ��,���������������,����˵����1��λ��������������,������5����������������,��ô���Ǽ�1������6��λ�ÿ�һ����û������,���û������,��ô���ǾͲ��뵽���λ������,���ǵ�һ�֡�
��ô�ڶ�������
�����ʲô�������Dz��Ǹ�����ǰ�潲�ľۼ���ϣ��һ����,����
���ǰ�������һ����,��ô���
��ô�Dz��Ǻ��������������������һ�γ�ͻ?
�Dz��Ǻ�����������һ�γ�ͻ,��ô�������˵ڶ��ַ���,���ǰ���������Ӵ�һ�����ǰ���������Ӵ�һ��,
��ƽ��,����˵�����������̽��,Ȼ�������ұ�̽��,���Ǽ��ž��������̽��,
�Ӻ��ؾ������ұ�̽��,�����������һ����̽��,����ÿһ��̽��IJ����ذ�������,���Ǹ���һ��ƽ��,����˵3��ƽ��9,
ͨ�����ַ�ʽ������������̽��,����������Ҳ���Խ��ǰ�����־ۼ���ϣ�����⡣
��,����������һ��ʲô��ͬ���ϣ�ۼ���������Ȼ���ǶԲ������ӳ�����Ͳ�������,
������,���ǵ�Ȼ�����´β��һ���Ҫͨ������,�����Dz������ֹ���ȥ̽���,��ô������һ��ȥ�������λ�õ�ʱ��,��Ҳ��Ҫͨ�����ַ�������ȥ̽��,һֱ�ҵ���� TΪֹ,
����������DZȽ��鷳�ĶԲ���?
�����Dzɲ������ֲ���ȥ̽���,��ô�����´����������Ԫ�ص�ʱ��,��ȻҪ�����������ȥ�����Ǹ�Ԫ��,
���Ӧ����������,����ؾ�������
Ϊ�˱���ͬ���ϣ�ۼ�,��ô���ǾͰ���������Ӵ�һ��,�Ӵ�һ��,���������ߵ�̽��,������������ȥ����̽�顣
��Ȼ������Dz���ڵ�֮��,��һ��ͬ����ҲҪ�������ֹ���ȥ̽��,
���Ǹ�Ԫ����������?������ȻҪ�����������ȥ̽���Ǹ�Ԫ�ء���,
����ؾ��ǽ���ͬ���ϣ�ۼ�,Ҳ�������Ľ���ֵ,�ر���˵���ǵĹ�ϣ���ľ�����������ַ�������ֵ���Ƶ�ʱ��,���Ĺ�ϣֵ����������Ҳ��ȽϽ���,��Ȼ�����������ǰ�������ǽ���
������ֲ�ʽ�Ĺ��溯������������Ƚ���,���Dz���˵����������������?
���������������Ƚ���,�����ǰ�%��,
���ǽ������Ե�,Ҳ��ȽϿ���,Ҳ��ȽϿ������ǽ����ֲ���,��������Զ��Ե�,
��ô�������Ĺ�ϣֵҲ����,��������������IJ�λ��Ҳ��ȽϿ���,
Ҳ��ȽϿ���,��ô�ؾͻ��γ�һ����ϣ�ۼ�,Ҳ����˵����ͨ������
�����̵ܶĻ�һֱ�ᷢ����ײ,��һֱ������ײ,��ô��������ܻ����쵽a��n
��û���ҵ���κ,��������?
��ô��������һ��,
���ǵ�һ���ع�ϣ��ͻ�ػ����ϳ���,���ǵڶ��ִ��˼��һ��,��Ȼ���������������߽�������,��ֻ�ǽ����ǵľۼ���ͻ֮��
���ַ���ֹͣ,�����ֻҪ�������ֻҪ�������,��ô���´β����ٰ��������ֹ�������ȥ̽��,��ôҲ�ǿ��Եġ�
���ǵڶ���ֻ�ǽ��ۼ���ͻ�Ӻ���,
������Ȼ�Ѳ���������,����������������ۼ���ͻ,��ֻ�ǰ�����ۼ���ͻ��û�и���,��ô��ô������?
��ô��ô������������?��ô�ͳ�����˫�ع�ϣ,���벼¡������������Ҫ��һ������,����Ҫ��һ�����ݾ������ǵ�˫�ع�ϣ�������Ĺ�ϣ�ۼ����⡣
��,�����������ҵ���һ���Գ������ײ,��ô������ô��˫�ع�ϣ���������Ĺ�ϣ�ۼ�����?�������ǵ���ʱ����,
Ҳ�������ǵ�c #���Ե���,��ϣtable�������Ĺ���ϣ�����������������,��ҿ�һ��,�������Ĺ�ϣ�����Ķ��塣
��.net HashTable���hash����Hk��������:
Hk(key) = [GetHash(key) + k * (1 + (((GetHash(key) >> 5) + 1) %
(hashsize �C 1)))] % hashsize
�ڴ� (1 + (((GetHash(key) >> 5) + 1) % (hashsize �C 1))) �� hashsize
��Ϊ����(������Ϊ������ʾ����û�й�ͬ������?);
ִ?�� hashsize ��̽���,��ϣ���е�ÿ?��λ�ö�����ֻ��?�α����ʵ�,Ҳ����
˵,���ڸ����� key,�Թ�ϣ���е�ͬ?λ�ò���ͬʱʹ? Hi �� Hj;
��,���ǰ������Ƶ������,
���ֶ�����Ȼ��������������һ������,��Ȼ����ʹ�õ���һ����ϣ����,���һ��Ҫ��ȷһ��,����ʹ�õ���ͬ���Ĺ�ϣ����,
ͬ���Ĺ��溯��ͨ����������,��ͨ�������������ͨ����������֮��,��ҿ�һ��,��������������һ��
������һ������ǵĹ�ϣ���Ӽ�һ������Ϊ����,ʲô�л�Ϊ����?Ҳ��������֮��û�й��Ѿ���û�й�Լ��,
�Ǹ��ر���˵�������ڵ����Ԫ��,����˵����������ڵ�Ԫ��,���ڵ�Ԫ�ظ�����ֵ�Ļ�,��ôͬʱҲ�����ֵ���л�ֵ��
���Ļ����д����ԶԲ���?�������д�����,��ô�Dz���
ͨ����������ڵ�,���Dz���Ҳ����һ������ȥ̽��,Ҳ����һ�����ٵ�λ�ø���������ٵ�λ���ؽ���̽�顣
��,����е����,���һ��Ҫ����һ��,�������������������д�����,����������,��Ϊ����,�����Ǿ��д�����,
�����������������ڵ�Ԫ�����ǹ�ֵ�Ļ�,
�������ǵ�һ��Ԫ��������һ�����Ƶĵط�,Ȼ��ڶ���Ԫ����Ҳ����һ�����Ƶĵط�,��ô����֮�䲻�������ײ��
��,�������,��,
��ô���ǰ���������ƹ���һ���,��,����������װ�?
�ٸ�����,
������Ӳ��þ�,��Ϊ�����������ȡ��ֵ����,���ֻ������,��������ͨ��������������ֱ�۵Ķ��ǰ�?
��ô����Ӧ����ô����,�������Ϊ����ѧ��Ҳ���þ���,
��Ϊ�������ѧ�Ҳ��þ���,���ֻ��
һ�ֹ�ʶ��֮һ�ֹ�ʶ,��Ҽ�ס��ǰ��������ǿ����ܹ������ƶ�������λ��,����Dz����ƶ��൱�ڸ����ƶ�һ��λ��,��
���������൱�ڸ����ƶ�һ�����ٵ�λ��,������֮����ټ�����ײ,������ôʵ�ֵġ�
ͨ�����ַ�ʽ�������ܹ�������ײ,�����Ҿ��������ԭ��������������������ԭ��,
������������»����������ײ��
������������������������ξ������Ǹոջ������ͼһ��,
��������?˫������������?˫����Ҫ����������
���������ϣ������ϣ���������Dz�����һ��������������Ĺ�ϣ�������ָ�ǰ��Ĺ�ϣֵ��?
������൱��������ϣֵ,������?������൱��һ����ϣһ,��,���ǰ��������������һ��,���൱�����ǵĹ�ϣһ�������ǵĹ�ϣ���䱸��
��ϣ��,���װ�?������ͨ�������ǰ�?��Ϊ���ǵĺ����ضԹ�ϣ��ֵ,��Ϊ���ǵĹ�ϣ�����Ǹ��ݹ�ϣһ�������,
���ǵĹ�ϣ�����Ǹ��ݹ�ϣһ�������,����ʵ�ֲ��ܹ�������ʱ����Ҳ�Dz�������˼��,Ҳ�Dz�������˼����ʵ�ֵ�,
��ô���Ǿ��൱��һ����ϣһ����һ����ϣ��,���������IJ����ؽ���
������̽,�������ǵ�������̽���ǵ���̽�����ؾ�����������̽������
��,����ȼ�ס���,���������ҿ��������?
����ǹ�ϣ��ϣһ����,���������ϣһ������һ������,�����ǰ������ɿ��ɹ�ϣ��,��������?
��,�����ز��������ϸ�Ľ��ͽ�����,��������һ����ѧ���۹����ġ�
������Ҫ��Ŀ��,����������һ�������������
���������ʵ�ֵ�,����Ӧ����ô��ʹ����,����֪������ԭ���������ˡ�
�ö�ʹ�õ�Ȼ��Ҳ�ܹ�˵������ԭ��,
���ԭ�������ѧ���۵�ԭ���Ͳ��ò��ô��ȥѧϰ��,����б�Ҫ��?�Ҿ���û�б�Ҫ��
���Dz���Ҫȥ������Щ��ϣ����,����ѧ�Ұ�����ȥʵ����Щ��ϣ����,�Լ�����ѧ�Ұ�����ȥ�о��������,Ϊʲô�����ܹ�������ײ?
�����˰����������,��,�ǵÿ�����ѧ���ˡ���,��ô������������˾���ԭ��,�ش�ҿ��Կ�һ�¡�
��,ͬ�������ǵĹ�ϣpaper�����ǵ������ϣ��ͻ�Ľ������,���������������,�ؾ������������ϣ table�����Ľڵ���Ҳͬʱ�洢�����ǵ�key��value,
�����������Ƶ��ַ��Ͽ��ܲ������ƵĹ�ϣֵ,˫���Dz����ٽ��������ƵĹ�ϣֵ����һ�ζ�?
�ζԿ�����ô���������ô���⡣
�������ǵ�Ȼ�������λ��������Dz��������ַ���֮��,�����Dz�����,����ÿ�ο���ֻ����һ���ַ���,
���������Dz�û��Ҫ��key�Ĵ�С˳��,������ǰ������һ����,�����ǵ�ǰ������һ����,����ͬ���Ŀ����Ĵ���,
�ò�����ڵ������ؽ����IJ���,������Ӧ���������������������ز�û��Ҫ������t�Ĵ�С˳��,
�������Ҫ���Ǹ��ֶεĻ�,�����Dz���ҲҪ
�ҵ��Ǹ� Key,Ȼ����ֵ,�����DZ�ɲ������,���ǵ�hash table�����ǵĺ������һģһ����,������
û��Ҫ�����ǵ��Ƿ�һ��,�����˰�?
��,��ô���ǽ������������ŵ��ȱ��,�����ŵ���
����Ҫ�����ַ����ıȽ�,�����ҿ������⡣
�ڶ����ؾ��Ƿ����ٶȸ���,����ʱ�临�Ӷ�����oһ,�Բ���?����ʱ�临�Ӷ���oһ,
oһ����һ�ξ��ܹ��ҵ��Բ���?��,��ô����ȱ��������Ҫ��������������ͻ,��Ϊ��ͻ�˵Ļ�,
�������ͻ������,��ô��������dz��ַ����Ļ�,������ȻҪ�Ƚ������ַ���,�ַ����ıȽ���Ȼ�����ζԲ���?
������������Ҫ����һ�������������ͻ,���ٳ�ͻ,�Բ���?��������˵������һ���ռ任ʱ��IJ�����
��,��ô��������һ��,
���Ǹո�˵��,������Ҫ�������ڴ����洢��� t����,������ʹ�õ���ɫ�ӻ�����map,����ʹ�õ����ǵ�unordered_map,
�Dz��Ƕ���Ҫ�洢���ֵ?
��������ǰ�潲�������ṹ����Ҫ�洢���ֵ,���˼��һ��,�������
���������ʼ������ʼ�,
���˼��һ��,�����11�������ʼ�,11�������ʼ�,����ʼ�Ҫ�����ֱȽϳ��Ļ�,��ô�Dz���Ҫ����Ҫռ��GT��
�ڴ�,�����Ǽ�ʮg����g���ڴ����洢���洢���ǵ�t��value��TTֵ,�������ṹ�Dz��Ƕ�Ҫ�洢���ǵ���� string����tֵ?
��ô�����Dz��Dz�û�������⼸���ṹ�Ƕ����ܽ������ǰ�������,���ǵ�map�����Լ�����unordered_map
�����ܽ�����������,Ϊʲô���ܽ��?��Ϊ������Ҫ�洢���string,����������ݵ������,����û����ô����ڴ�,
��ô������Dz���������һ������������ɶԲ���?
���Dz�������һ������������������һ������������,��Բ���?�����������������˵˵��Ϻ���?
��¡������
������������,��������
���ܹ��˽���,Ҳ�������ԵĹ��̵��о������ʵ���,����
���Թٿ��ܻ������ǵĹ�������������һ��ʵ�ַ���,��Ϊʲô���Խ���������?
��ô������������һ��һ��������,���Dz�¡����������������һ���ṹ?
��¡������������Ȼ������������Ҫ�洢string,��ô��Ȼ���ǵIJ�¡�����������Dz���Ҫ�洢�����string��,��ô���ǿ�һ�����ǵIJ�¡������
�������Ҫ�洢�������stringҲ�ܹ�ȷ�������ڻ��Dz������������ġ�
��,��������һ�²�¡�������Ķ���,��¡�������Ķ���������һ�ָ����͵�,���һ��Ҫ�����
������������һ�������Ե����ݽṹ,�������Ի������ҽ�������,
��������Ҳ��һ�������Ե����ݽṹ,
����Ѿ������˸������������������ݽṹ�����������dz�ǿ��,��ô���Ǻ��潲������ʱ����Ҳ����������������һ�ָ����Ե����ݽṹ,
�����ص��ؾ��Ǹ�Ч�IJ���Ͳ�ѯ,�ܹ���ȷ�ĸ�֪ij���ַ���һ��������,
��ҿ���һ��Ҫע��,һ��������,���ܴ���,һ��Ҫע����������һ��������Ҳ����˵���Dz��ܹ�ȷ����
һ������,���Dz���ȷ����һ���ܴ���,ֻ��˵�����ܴ���,������������ȷ��֪����һ��������,
�����Dz��ǿ��Խ��������������⡣
��ҿ�һ����������ļ�����������,������������참������������참�Լ����ǵ���� Word��ѯ,
�������������Dz������������?
�����ֶ�������������,
�Բ���?����������������,������ǵĵ����ڶ��ֵ�һ�ָ��������ܹ�����,**����ܹ����Ƽ����ʵĻ�,Ҳ�ܹ���������Ļ�,��ô���Dz��ܹ������ؽ����5�����ⶼ�ǿ��Եġ�**��,��ô��һ����
����������,��������һ�²�¡������,
��¡��������������ڴ�ͳ�IJ�ѯ�ṹ,�����Ǹո�˵����Щ�ṹ�������Ӹ�Ч,������ĺ�,���Ӹ�Ч,ռ�ÿռ��ظ�С,
���Ǹո��Dz���������������һ��,
���ǵ��������Ҫ�洢,��������ռ�ÿռ��,Ȼ���ظ�Ч��̸���϶Բ���?
���ǵ�map����������Ҫ�����ǵ��ַ������бȽ�,
maps��Ҫ���Ͻ��бȽ�,�����У̸����,��ô���ǵ�unordered_map�����ĸ�У�����ǵij�ͻ�������,unordered_map��У�����ǵij�ͻ�����,
�����ͻ�ʱȽϴ�Ļ�,Ҳ����˵������������ܳ��Ļ�,����Ҳ��Ҫ���кܶ�εıȽ�,Ҳ����Ҫ���кܶ�εıȽ�,���ܹ��ҵ������Ǹ�����,���������������Dz���ʹ�õġ�
��,��������Ŵ��Ӧ���ܹ��������Ƕ�̸���ϸ�Ч,��Ϊ���Ƕ��и��Ե�ȱ��,��һ����ͬ��ȱ��,��������Ҫռ�ô������ڴ�,
��ô���ǵ�unordered_map�ر���������Ҫ����һ��,����Ҫ�����ַ����Ƚ�,�����ͻ�ʺܸߵ������,
��ôҲ�Dz��е�,��ô�����������˫�ػ������ܹ�������������,���Dz��ܲ���
���������⡣��,��ô��������¡������,�������������ǵ������������ϵ��������ǵ��ŵ�,�������ǵ��ŵ�������
ʵ�ֵġ�
��,�������ر���Ҫ�������ȷһ������ȱ��,���ȱ����Ҳ�����ԵĹ����о������ʵ���,����ȱ�����
���������Ǵ�������,���ǿ��ܴ��ڲ���ȷ����һ�����ڡ�
��,��������һ�������������ɵ�,���Ǹոյ����ǸոյĹ�ϣtable����������ӹ�ϣ����,
�����ǵIJ�¡������������λͼ����n����ϣ�������ɵ�,��ô��������һ��λͼ,ʲô��λͼ?��λͼ���ĵ�λ�����ǵ�
��,��������,
��һ������λһ������λ��
�Կ��Խ���洢,�����ǵIJ��ܹ���������Ҫ�Բ�֧��ɾ��������
��,����֧֧��ɾ����������������ȱ��,���ԵĹ����о������ʵ���������֧��ɾ������,��ô�����ܲ���
�����Ծ��Ǹ�����,����֧��ɾ��������?��һ�������ں���ĺ����Դ�뽲���Ĺ������ػ����ҽ��⡣
��,��ô��������һ��,
����λͼ����n����ϣ����,n����ϣ����,��ô��������������һ��λͼ���������ɵ�,�����������λͼ��ʵ��λͼ?
��c�Ӽӵ��������ǿ���ʹ������bite��
����˵���������������Ҿٸ�����,�����Dz��ǿ���ʹ��on sine
�������������ǵ��������,�Բ���?������������Dz�����8���Dz�����8������?
��8�����ضԲ���?��8������,��ô�����ô���8��8�Dz����ܹ�����һ��64λ64���ص�λͼ?
�����������ʵ��λ�����λ��?
��,�����������Ӧ�ú�������������������?��,��ô����Ҫ��������λ��,�ؼ����������ڵĹ�ϣ����
������һ��stringͨ����ϣ����������173,��ô������ô��173��ϣ���������λͼ������?������ô��173��ϣ���������λͼ����?��
�����Dz�������Ҫ������������������λͼ�ij���88 64�Բ���?��ô������Ҫ��64ȡ��,ȡ��֮�����ǵó����Ľ����
��,���Ƕ�64ȡ����൱�ڶ�63����ȡ&����,ȡ&������ͱ��һ��λ����ĶԲ���?λ������ȻҪ��һЩ�Բ���?
��ôλ�����һЩ,��ô����������������45,
��ô45������ô���ҵ���������λ��,���ҵ������λ��,����� I��j��������?�����ǵĺ������������,
���� I�Dz������ǵ�������?���ǵ�j�Dz������ǵĺ�����?��ô���ǵ�������ͺ�������ô�����������?�������Dz��ǿ��Զ�ȡ���ؾ��ҵ������ǵĺ����������,����λ����5,��ô����������
I��Ҳ��5,��ô���Ǿ��ҵ�55,��ô���ǽ����λ������Ϊһ,����ؾ������ǵ�һ����ϣ��������λͼ���������ϣ��?
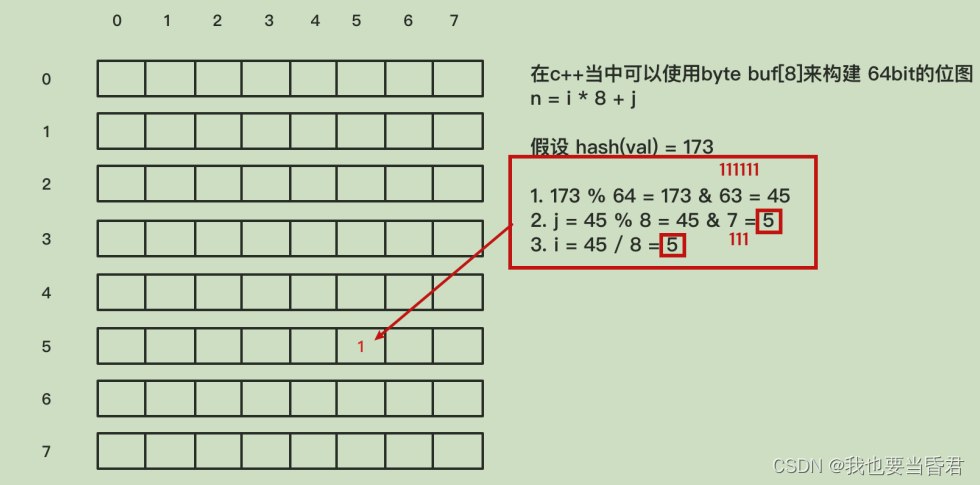
���ǵ����ͼ��������λͼ������������ڶ����ؾ���������ôȥ
ȥ��λ,�����ǵ�λͼ���ֵ��λ,����˵���ǽ���� Valueӳ�䵽�������λͼ����,��ô���ǾͿ�����5��5���λ���ذ�����Ϊһ
�Ϳ����ˡ�
��,��������һ������ԭ��,���ǵ�һ��Ԫ�ؼ���λͼʱ,k����ϣ�����ػὫ���Ԫ��ӳ�䵽����λͼ�е�k����,
λλ������λͼ���е�k����,����������Ϊһ,����������Ϊһ,Ҳ���ǵ����Ǽ�����ʱ��,����ͨ��k����ϣ����������ʱ��,�������Dz�ѯ��ʱ��,
��������Dz����ʱ������Dz����ʱ��,��������Dz�ѯ��ʱ��,���Dz�ѯ��ʱ����Ҳ��ͨ����k���������,��k������ij��γ��,
����в�Ψһ�ĵ���ôһ��������,
����˵���ǵ�����һ,�������λ�����λ�ø����λ����һ,�������Dz���һ���Ծ�,������һ��λ�������ǵ�
�������Ѿ����ڵ����λ������,��ô�����ٿ��ڶ�����ϣ����,�ڶ�����ϣ��������������ԭ�����������㵱��,��ô������Ϊsting���϶�������string1
����������QQ�����ض�ͨ��������ϣ���������е��������λ�õ��еIJ�ͬ�ĵ�,��ͬ�ĵ�,��ô����ȥ��ѯ��ʱ�������Ǿ�ȥ
һҲ��ͨ����������ϣ������ϣ��������,��������λͼ���е�λ���Dz��Ƕ�Ψһ,�����Ψһ,��ô˵�������ܴ���,�����һ����Ψһ��һ����Ψһ,��ô��˵����
�϶�������,һ�������ڡ�
����ؾ������ǵ�ԭ��ͼ,��������ԭ��ͼ,��ô
����λͼ��ÿ����λ��ֻ������״̬,����0����1,
�Բ���?��������ͼһ��,���ǵ�stringһ��string�������λ��,�����λ�����б�����
ӳ�䵽,��������ӳ�䵽�Բ���?���ﱻ�����ط�������4G1��4G2��ӳ�䵽���λ����,
��ô���ǾͲ�֪������ӳ���˼���,��֪�����һ�������˼��ζԲ���?Ҳ��֪�������ٸ�string����ϣӳ����,�Լ��DZ��ĸ���ϣ����ӳ�������,���Dz�ȷ���ǹ�ϣһӳ�������,���ǹ�ϣ��ӳ�������,�Բ���?
������,���Dz��ܹ�֧��ɾ��������
Ϊʲô���Dz��ܹ�����,����֧��ɾ������,��Ϊ
��������ÿ����λֻ������״̬,���Dz�֪�����������˼���,ͬʱ����Ҳ��֪�����ĸ�
��ϣ����ӳ�������,����������ɾ����ʱ����ܻ�����ܶͬ,�Բ���?
��,����֪�������֧��ɾ������֮��,��������һ��������ʵ��Ӧ�ù��̵���,�����ǵIJ�¡������Ӧ�������ʹ��?
������������������ϣ����,��ô���ǵ���Ҫѡ����ٸ���ϣ����?��,��ȷ���ԱȽϴ�,
��ô����Ӧ��ѡ����ٸ���ϣ����?�����ǵ��ո�����ǰ����������Ѿ�����,���ǵ�������ٿռ��λͼ��?
�����ܹ����λ�õ����ܹ��洢���ٸ�Ԫ��,����Ϊ��Ҷ�֪������������һ��
��һ��������һ����������,���������Ǿ�����Ϊ�˼��ٳ�ͻ,��Ӧ�������ǵ����鳤��Ҫ�������ǵĴ洢Ԫ�صĸ���,��ô������Ҳ��һ��,**�����Dz������λͼ�Ĵ�СҪ��������
Ҫ��������ַ����ĸ���Ҫ��һЩ,**�����������Ҫ���������������������һ��������������,���ǵ����鳤�Ⱥܴ�,�Բ���?
����������鳤����Ҫ����������,
��ô������������ܲ��ܹ����Ƽ�������?
�����ܲ��ܿ��Ƽ�����?ʲô�м�����?���Dz��ܹ������ܹ���ȷһ��һ��������,���ܹ���ȷһ������,��ô�����ж��������ġ�
**Ҳ����˵���Ǵ����жϴ��ڵĸ��ʾͽм�����,**����
������ж�����������ڵĸ��ʽ����ٵ���,���DZ���˵���ǵ�����һ��������,
��,������ٸ�����,Ϊʲô��ѡ���ֹ���?�������ʡ�����������
���Ƶ���������Ҫѡ��Ҫѡȡ���ٸ�Ԫ��,
Ȼ������Ҫѡȡ���ٸ�λͼ,��������ռ�λͼ�ֶοռ��Լ������������,��ô���������й���
��ʽ,�����������Ӧ��ѡ������⼸����ֵ�Ƕ��١�
��,������������ܹ��������˲���,�����������Ļ�,��ô��,��ô�����������ظ���ҽ���һ��,
�����ǵ�ʵ��Ӧ�ù��̵���,������һ������ȷ������,
��������Ҫ�����ܹ������д����Ԫ��,�����������ǰ����д�õ�,�����Լ����,������Ϊ��ġ�
��ô�ڶ���Ҫ����������ܹ����ܵļ�����,
���������ʾ��������ܹ����ܵ�,����˵0.000,��������0.1�м���04��01��һ�Բ���?�Dz���һҹ
1/1�ڶԲ���?��ô����1�ڸ�����ֻ��һ������,�����������?����1�ڴ��жϵ���ֻ��һ���жϳ���,
����������� P����ֵ��ʲôֵ,���Ǿ��������ֵ��
��,��ô����һ�����Ǹ���������ֵȥ��m��km�ؾ��Ǹ������ǵ�ǰ
���������ִ��ڵ�Ԫ�ظ����ǵļ�ҩ��,������������ǵ�λ��Ӧ��ҪҪ�ж���,���ǵĹ�ϣ�����ĸ���Ҫ�ж���?
��,��ô����������ǵ�ʵ��Ӧ�ó���,����ֻ���г�һ����ʽ,�����ֱ�Ӵ�����������,����Ƶ��Ĺ������Ǿͽ�����ѧ���������Ƶ�,����ֱ���ý��۾�����,
����ֱ���ý��۾�����,����֪����ô�þ�����,��ô�����Ǿ�֪����Ҫ������ֵ,��һ�������Dz��ܹ���ЩԪ�صĸ���,�Լ������ܹ����ܵļ����ʾ��������ʡ�
��,��ô���Ǿ���ѡ����4��ֵ,Ȼ������һ�������,���ǵ�������Ҳ����1��
����һ����վ,���ذ����ǵ����������Ѿ�д����,���Ƿ������,�����и���վ��ҿ���n��һ��ǵ����ĸ���,�ɾ�������
��ǰҪ���,���������ܹ���������Ҫ�������������,�������Dz���4000������,��ô��������������
��ǧǧ��/1,��ô���ǵļ��������ܽ��ܵ���ǧ��/1,Ҳ��������1,000����жϵĵ�����һ�γ���,��ô���������ֵ��
��ô���������������ĸ������ؾ�������������,������������,�����ύһ�������������㡣
��ô���������ֵ�ؾ������������Ҫ�õĿռ������,�Լ���������ǵ�k��ֵ�Ƕ��١�
���ǿ��Ը����������ļ���������������� m��k��ֵ,
�������ǵ���Ҫʹ�ö���,���λ�õĵ����Ƕ���,�Լ����������ϣ�����ĸ����Ƕ���,��ô�����ǾͿ���ͨ�������վ������ǰ��Ԥ�ݡ�
ͬʱ������Ҳ���Կ������ǵĹ���,��������
������ֵ������,����˵����Ҫ��p�� n�Ĺ�ϵp��n�Ĺ�ϵ,���ǰ�mk
��ֵ����,Ҳ�������ǵĴ洢�ռ�λͼ�Ĵ�С����,�Լ�����party�����IJ���
��,��������һ�����ǵĹ�ϵ,��������ǵĹ�ϵ,��������Ĺ�ϵ��
������������ֵ����,������ֵ���䡣��������һ��n��p�Ĺ�ϵ,p�������ǵļ����ʵĹ�ϵ,��ôn�ؾ������ǵ�
��¡���������еĸ����Ĺ�ϵ����������һ��,������������������,Ҳ�������������ܹ��������ӵ���������,
�Ǹ�Ȩ��һ��Ҫ����,���ļ�����Խ��Խ������n��b�Ĺ�ϵ�ؾ�������İ�������,���ǵ�p����Խ��Խ��
��ôͬ������������һ�µڶ���,���ǹ̶�סn��k���ǹ̶�סn��k���ǹ̶�סn��k
��������һ��p��m�Ĺ�ϵ,�������ǵ��ڲ����,��������λͼ�ڲ����,���ǵļ�����Խ��Խ��,
��������?����ضԵ�,���Ҳ�����������ǵ������λͼ�Ĵ�С�ܴ�Ļ�,��ô�����ʿ϶���С,�Բ���?�����ʿ϶���С��
��ô���ǽ��������������Ĺ�ϵ,��ô���ǵ�����p
p��k��ô�����Ǿ��ǽ����ǵ�m��n����
�̶�ס,�����Ȱ����̶�����������,���ǵ�
m�������ǵĴ洢�ռ�����ǵ�����,����,��������һ��p��k�Ĺ�ϵ,��ô�����ϵ��
��ҿ��Կ�����,�������23������һ����͵�,��������һ�ֺ�,��
������Ȼ�������ϵ�������һ������,Ҳ����˵����23��ʱ��������һ�����λ�õ�,
�����23��ʱ������һ����ѵ�λ�õ�,�������λ�á�
����������ʦ�����ʽͼû����,
��ô���������λ���������������ŵ�,��������������һ�����ŵ㡣
ѡ���
����23�������ֻ�������,���ǵļ�ѹ���ֻ�������,�������ǵĺ�������������,���Ҳ��������õ����ǵ�k
��ϣ������ϣ����Խ��Ļ�,��ϣ����Խ��Ļ�,��ô����Ҫ��λͼ�������õĵ�Ҳ��Խ��,���������?�������ǵĹ�ϣ����Խ��,��ô�����������ͼ���еĵ�Ҳ����Խ��,
���Խ���Dz���?�ڴ�ռ��Խ�డ,�γ�ռ��Խ��,�����Ǹ�����Ϊһ�ĵ�Խ��,�����ڴ�ռ���ڴ�Խ��,������
Ψһ��Ҳ�ǵö�,��ô��Ӧ�����ļ�����Ҳ������,�������������Բ���?
��,���������֮���������Ѿ���������4������֮��,��������
���������ǿ��һ��,����ʵ�ʹ������̵���,����ʹ�ò��ܹ�������ʱ��,��������������������,
n��pָ��n��pȥ�����m��k��,��ô��������һ��,���ǵ�����������һ��,����������Դ��,
�������������ѡ��k����ϣ����?
����k����ϣ���������ǵĿ���ѡַ���е�˫��,���˫�ع�ϣ��һ����,
˫�ع�ϣ��һ����,˫�ع�ϣ��ҿ�һ��,����ؾ�������ѡȡk��������ô��ѡȡ,���Dz��õ���mama�� c��me m��ϣ��,���ǽ�
��� p���뵽���ǵ���������ϣ��,Ȼ����ָ��һ������ƫ��������ƫ����,Ȼ�������ǽ������ϣһ��ֵ�ش��뵽���ǵ����
��ϣ����,����ͬ�����Dz��õĹ�ϣ����,Ȼ���ذ����ŵ����������,
����������ͨ����ϣһ����ϣ��ģ�������k��k�����ǹ�ϣ�����ĸ���,k�ǹ�ϣ�����ĸ���,
�����ǵ�m�ؾ������ǵ�λͼ�Ĵ�С,�Բ���?
M����λͼ�Ĵ�С��
��,
���������ͨ����ϣһ����I�������ǵĹ�ϣ��,�ٶ����ǵĻ�ͼ����ȡ��,��
���������Ҫ����Щλͼ��Щ����и�������������Ϊһ,����һ,
ͨ������K���ϣ��������������ģ��k����ϣ�����Dz��Ǹ����ǵ�˫��
˫�ع�ϣ��һģһ����,���ǵ�˫�ع�ϣ�Dz��Ǹո�������ʦ����Ҳ�����,���Dz�����ʵ����
����ǰ��Ŀ�����������ϣһ,Ȼ�����һ��k����k���ĺ�������Dz�����,��������Dz�����,����
������һ�翴�����ǵĹ�ϣ������������,����ͨ������˫�ع�ϣȥ̽��û����ɫ�ĵ�,��ô����ͬ����
ʹ��˫�ع�ϣ���ܹ����һ��,���DZ���˵����������������,���Dz�������������������������һ����,��
������������������ҵ�һ����,��ô��û�������ˡ�
����˵������������ϣ�������ҵ�������в���?����Ȼ����,�Բ���?�����Dz���
����ǰ��ķ����������Ǹ�̽����˫ͷ����̽��,�������ٲ����Լ�
��Ǯ��֮ǰ�ij�ͻ,��������?��,�����������û��?��Markˢ���ʻ�����?����Ϊʲô�������������˫��˫�ػ���?��������ʹ��
˫�ֻ��ε�������ȫ��������һ������,��Ϊ�����Ǹ��Ƶ�,˫�ֻ���һ��������߿�һ������
��������,�����ڵڶ�������Ҫȥ̽��һ��,������ȥ̽������һ��,
�����Ǽ��ٳ�ͻ,����������k������֮����ٳ��,�Բ���?
�������k������֮�䶼�г�ͻ��,������������ܹ������϶�Ч�ʺܵ���,�Բ���?
�����ص�,���ǵĸ�˹�ٵ�������˵�ĺܶ�,���������ǾͿ��Ա����⼸�������ص���,���������ؾ��Dz��õ�˫ͷ����,
���������ǵ�˫�ع�ϣ��Ҳ�ܹ����,�����Ǹ��ۼ��ۼ���ϣ����ͬ��ۼ���ϣҲ��һ���ĵ�����
��ô������ô�����ش�ҾͲ��ÿ�����,��ô����ֻ֪�����ǵ�˫�ع�ϣ�ܹ�������ֳ�ͻ�����ˡ�
�ܹ������ͻ������
��,��ô����������һ�����Դ��,k����2k1���ǵ���2,kһ������
�������ֵ,����˵��������Ҫ����4000������,Ҫ����4000��������,������1/ǧ��ļ�����,
��ô�������������Ҫ��23������,���ǵ��������������,������������,��������ͨ�������ʽ������ġ�
��,���ǵ�k�Ǹ���n���ǵ�n��p�������,����ǰ��һ��һ���������,��ô23
��ʵ����ֻ����һ����ϣ����,��������?���ǵ���ʵ����ֻ����һ������,�������Ƕ����õ�mama�����,����û��?��23��������ͨ����������
˫�ط�Ϣ,�����Ǹ�����һ������IȻ�����ǰ���������ϣ����֮��Ĺ�ϵ,
лл
����������Dz��Ǹ�����ǰ����������,����32λ�����ǵĵ������������Dz��ġ���,�����˰�?
�������ͨ��������������ȥ�������,��32��k��23����
��������,�ԶԶ����ǵ��·���������Ҫ��������,
���������,�������ﲢ������23����ϣ����,����ֻ����һ����ϣ������ͨ������ƫ�Ƶķ�ʽ������α�����
32�����溯��,��������?��,�����������������ĵ�˼��,�������ǵIJ�¡��������ĵ�˼��,��ô��������������ʹ����
������������ʹ�����̫���Ժ��ڹ�����Ҫʹ�ò�¡�����������ѵ�,����ֱ���ù���ʹ�þ����ˡ�
��,��������һ��,������������������һ���������ʹ�õġ�
��������Ҫ��ʼ�����ǵIJ��ܹ�����,��ҿ�һ�����dz�ʼ��¡�����������Щ����,��һ���ص�Ȼ����������ṹ��,�ڶ�������������һ��,
�ڶ��������ǵ���� C��,�������ǵ�kһ����ʼ����g�ĸ��Ǹ� k����kһ��,��ô������������Ϊ��,
�����������Ҫ�������4000��Ԫ��,��������?
����Ҫ����4000��Ԫ��,����������������ٵ�������һ����,����Ҫ����4000��Ԫ��,
Ȼ�����ǵļ������Ƕ���?��������
Ҳ��ǧ��/1,�Բ���?Ҳ��ǧ��/1,���ǰ������ü���������1/ǧ��,��ô���Ǹ�����������һ��������ô���,����ͨ�����
�����ʸ�Ҫ�����Ԫ��ȥ�������λͼҪռ���ٿռ�,�Լ�����Ҫ�ö��ٸ���ϣ����,��ô�������
�������������ǵ�λͼ�Ŀռ�Ĵ�С�Ƕ���,��ͨ������������ǾͿ����������������������������,�������ٰ������������ô����ڴ�����ˡ�
������Ƿ�������ǵ�λ���ɵ����ǵ�λͼ,����������ǵ�λͼ��ͼ�Ĵ�С,��ͼ���Ǹ��ڴ��Բ���?����������ǵ�λͼ,����ؾ������ǵ�
�ռ��,���������k�Ĵ�Сk�ĸ���,���ǵ�k�ĸ�������һ�¾��������ϣ��ʽ��
��,��ҿ�һ�����ǵĹ�ϣ��ʽ,
�������ҿ�һ��,�����Dz�����������Ȼ�������Ϊһ,
�൱��������������������������൱�������ġ���,���Ƕ���ϲ��дc���Ĵ���,��,���ǿ�һ�¶���,��,��������һ��,
Ȼ���������ٰ����������������,Ȼ���ٰ����ӵ�������Ǽ���Ԫ�ص�ʱ��,�������������������Ԫ��,���Ǹ� key key��
֪��û��?
��,��������ǽ�t�����Ž�ȥ,Ȼ���ذ������õ�ַ,���ǰ��Ǹ�����Ϊһ����Ϊһ�Ժ�,���ǾͰ���
ÿ���ȥ,������dz������ǵ��������,���ﻹ����1���������,�����������Dz��������������?������,������ѡ���ľ����Ǹ�4����
�����4000,��������������4000��,�Ǿ͵����������4000��,�ҾͰ�����֮Ϊһ,
��ûʲô����ûʲô����,��Ȼ��Ϊ�����,������һ��Ҫ����ʵ����Ŀ����������һ��ʱ������,��һ��ʱ������,�������������һ��ֵ��
��,����������һ�����������������һ��������롣���ȱ���һ��,
����Ҫָ��ͷ�ļ��������ǵ�main CPDȻ������,Ȼ�����뵽���ǵ�test����,�����ǵ�������һ�¡�
��,��ҿ�һ�����ǵĹ������ǵĹ��ܾ��������������art item,����1000��������1000���ַ���,��ҿ��������Dz�����1000���ַ���,
���Dz�����1000���ֲ���,��ô���Ŀ�ͷ����0words,���Ǹ����ǵ�URL�Բ���?Ȼ�����������һ�����0��10,001�Ƿ�������?
���ǵ�0��10,001�Ƿ������ǵ����������,�����ǵIJ��ܹ���������,��ô������ͨ�������ҿ��Կ�����,���ǵ�0�����Ǵ��ڵ�,�������ǵ��ַ�������,
���ǵ�10,001�����Dz����ڵ�,��Ϊ��������������1000������1000������,��ô������������Dz���1000��html,������Ӧ���ܹ������?
��Ӧ��д���ܴ��ڵ�,��Ϊ���ǵ����������ǧ��/1,��ҿ�������д�������1/ǧ��
��,�����¡����������ʵ�DZȽϼ�,�ؼ���������Ҫ��������ѧ��֪ʶ�ܹ���������,�ܹ���������ѧ��֪ʶ��������,���ǵ�set map�Լ����ǰ�unordered_mapΪʲô���Dz���,�Լ����ǵ�ϸ����ʲô����,
Ϊʲô���ǵIJ�¡����������,�����ǵIJ�¡��������û�д洢��� String,û�д洢��� key,
������ͨ�����ָ����͵���ͨ�������͵�Ȼ����ӳ�������,ͨ���������ü����ʵķ�ʽ,���������ܹ����ܶ�������ʡ�
����
#ifndef __MICRO_BLOOMFILTER_H__
#define __MICRO_BLOOMFILTER_H__
/**
*
* ����Cassandra�е�BloomFilterʵ��,Hashѡ��MurmurHash2,ͨ��˫��ɢ�й�ʽ����ɢ�к���,�ο�:http://hur.st/bloomfilter
* Hash(key, i) = (H1(key) + i * H2(key)) % m
*
**/
#include <stdio.h>
#include <stdlib.h>
#include <stdint.h>
#include <string.h>
#include <math.h>
#define __BLOOMFILTER_VERSION__ "1.1"
#define __MGAIC_CODE__ (0x01464C42)
/**
* BloomFilterʹ������:
* static BaseBloomFilter stBloomFilter = {0};
*
* ��ʼ��BloomFilter(���100000Ԫ��,������0.00001�Ĵ�����):
* InitBloomFilter(&stBloomFilter, 0, 100000, 0.00001);
* ����BloomFilter:
* ResetBloomFilter(&stBloomFilter);
* �ͷ�BloomFilter:
* FreeBloomFilter(&stBloomFilter);
*
* ��BloomFilter������һ����ֵ(0-����,1-������ֵ����):
* uint32_t dwValue;
* iRet = BloomFilter_Add(&stBloomFilter, &dwValue, sizeof(uint32_t));
* �����ֵ�Ƿ���BloomFilter��(0-����,1-������):
* iRet = BloomFilter_Check(&stBloomFilter, &dwValue, sizeof(uint32_t));
*
* (1.1����) �����ɺõ�BloomFilterд���ļ�:
* iRet = SaveBloomFilterToFile(&stBloomFilter, "dump.bin")
* (1.1����) ���ļ���ȡ���ɺõ�BloomFilter:
* iRet = LoadBloomFilterFromFile(&stBloomFilter, "dump.bin")
**/
// ע��,Ҫ��Add/Check��������,����ʹ�� -O2 �����ϵ��Ż��ȼ�
#define FORCE_INLINE __attribute__((always_inline))
#define BYTE_BITS (8)
#define MIX_UINT64(v) ((uint32_t)((v>>32)^(v)))
#define SETBIT(filter, n) (filter->pstFilter[n/BYTE_BITS] |= (1 << (n%BYTE_BITS)))
#define GETBIT(filter, n) (filter->pstFilter[n/BYTE_BITS] & (1 << (n%BYTE_BITS)))
#pragma pack(1)
// BloomFilter�ṹ����
typedef struct
{
uint8_t cInitFlag; // ��ʼ����־,Ϊ0ʱ�ĵ�һ��Add()���stFilter[]����ʼ��
uint8_t cResv[3];
uint32_t dwMaxItems; // n - BloomFilter�����Ԫ�ظ��� (������)
double dProbFalse; // p - �������� (������,�������֮һ:0.00001)
uint32_t dwFilterBits; // m = ceil((n * log(p)) / log(1.0 / (pow(2.0, log(2.0))))); - BloomFilter�ı�����
uint32_t dwHashFuncs; // k = round(log(2.0) * m / n); - ��ϣ��������
uint32_t dwSeed; // MurmurHash������ƫ����
uint32_t dwCount; // Add()�ļ���,����MAX_BLOOMFILTER_N��ʧ��
uint32_t dwFilterSize; // dwFilterBits / BYTE_BITS
unsigned char *pstFilter; // BloomFilter�洢ָ��,ʹ��malloc����
uint32_t *pdwHashPos; // �洢�ϴ�hash�õ���K��bitλ������(��bloom_hash���)
} BaseBloomFilter;
// BloomFilter�ļ�ͷ������
typedef struct
{
uint32_t dwMagicCode; // �ļ�ͷ����ʶ,��� __MGAIC_CODE__
uint32_t dwSeed;
uint32_t dwCount;
uint32_t dwMaxItems; // n - BloomFilter�����Ԫ�ظ��� (������)
double dProbFalse; // p - �������� (������,�������֮һ:0.00001)
uint32_t dwFilterBits; // m = ceil((n * log(p)) / log(1.0 / (pow(2.0, log(2.0))))); - BloomFilter�ı�����
uint32_t dwHashFuncs; // k = round(log(2.0) * m / n); - ��ϣ��������
uint32_t dwResv[6];
uint32_t dwFileCrc; // (δʹ��)�����ļ���У���
uint32_t dwFilterSize; // ����Filter��Buffer����
} BloomFileHead;
#pragma pack()
// ����BloomFilter�IJ���m,k
static inline void _CalcBloomFilterParam(uint32_t n, double p, uint32_t *pm, uint32_t *pk)
{
/**
* n - Number of items in the filter
* p - Probability of false positives, float between 0 and 1 or a number indicating 1-in-p
* m - Number of bits in the filter
* k - Number of hash functions
*
* f = ln(2) �� ln(1/2) �� m / n = (0.6185) ^ (m/n)
* m = -1 * ln(p) �� n / 0.6185 , �������
* k = ln(2) �� m / n = 0.6931 * m / n
* darren����:
* m = -1*n*ln(p)/((ln(2))^2) = -1*n*ln(p)/(ln(2)*ln(2)) = -1*n*ln(p)/(0.69314718055995*0.69314718055995))
* = -1*n*ln(p)/0.4804530139182079271955440025
* k = ln(2)*m/n
**/
uint32_t m, k, m2;
// printf("ln(2):%lf, ln(p):%lf\n", log(2), log(p)); // ������֤������ȷ��
// ����ָ������(���)��������Ҫ�ı�����
m =(uint32_t) ceil(-1.0 * n * log(p) / 0.480453); //darren ����
m = (m - m % 64) + 64; // 8�ֽڶ���
// �����ϣ��������
double double_k = (0.69314 * m / n); // ln(2)*m/n // ����ֻ��Ϊ��debug������������ĸ�����ֵ
k = round(double_k); // ����x��������������ֵ��
printf("orig_k:%lf, k:%u\n", double_k, k);
*pm = m;
*pk = k;
return;
}
// ����Ŀ�꾫�Ⱥ����ݸ���,��ʼ��BloomFilter�ṹ
/**
* @brief ��ʼ����¡������
* @param pstBloomfilter ��¡������ʵ��
* @param dwSeed hash����
* @param dwMaxItems �洢����
* @param dProbFalse ������������
* @return ����ֵ
* -1 ����IJ�¡������Ϊ��
* -2 hash���Ӵ�������>=1
*/
inline int InitBloomFilter(BaseBloomFilter *pstBloomfilter, uint32_t dwSeed, uint32_t dwMaxItems,
double dProbFalse)
{
if (pstBloomfilter == NULL)
return -1;
if ((dProbFalse <= 0) || (dProbFalse >= 1))
return -2;
// �ȼ���Ƿ��ظ�Init,�ͷ��ڴ�
if (pstBloomfilter->pstFilter != NULL)
free(pstBloomfilter->pstFilter);
if (pstBloomfilter->pdwHashPos != NULL)
free(pstBloomfilter->pdwHashPos);
memset(pstBloomfilter, 0, sizeof(BaseBloomFilter));
// ��ʼ���ڴ�ṹ,������BloomFilter��Ҫ�Ŀռ�
pstBloomfilter->dwMaxItems = dwMaxItems; // ���洢
pstBloomfilter->dProbFalse = dProbFalse; // ���
pstBloomfilter->dwSeed = dwSeed; // hash����
// ���� m, k
_CalcBloomFilterParam(pstBloomfilter->dwMaxItems, pstBloomfilter->dProbFalse,
&pstBloomfilter->dwFilterBits, &pstBloomfilter->dwHashFuncs);
// ����BloomFilter�Ĵ洢�ռ�
pstBloomfilter->dwFilterSize = pstBloomfilter->dwFilterBits / BYTE_BITS;
pstBloomfilter->pstFilter = (unsigned char *) malloc(pstBloomfilter->dwFilterSize);
if (NULL == pstBloomfilter->pstFilter)
return -100;
// ��ϣ�������,ÿ����ϣ����һ��
pstBloomfilter->pdwHashPos = (uint32_t*) malloc(pstBloomfilter->dwHashFuncs * sizeof(uint32_t));
if (NULL == pstBloomfilter->pdwHashPos)
return -200;
printf(">>> Init BloomFilter(n=%u, p=%e, m=%u, k=%d), malloc() size=%.2fMB, items:bits=1:%0.1lf\n",
pstBloomfilter->dwMaxItems, pstBloomfilter->dProbFalse, pstBloomfilter->dwFilterBits,
pstBloomfilter->dwHashFuncs, (double)pstBloomfilter->dwFilterSize/1024/1024,
pstBloomfilter->dwFilterBits*1.0/pstBloomfilter->dwMaxItems);
// ��ʼ��BloomFilter���ڴ�
memset(pstBloomfilter->pstFilter, 0, pstBloomfilter->dwFilterSize);
pstBloomfilter->cInitFlag = 1;
return 0;
}
// �ͷ�BloomFilter
inline int FreeBloomFilter(BaseBloomFilter *pstBloomfilter)
{
if (pstBloomfilter == NULL)
return -1;
pstBloomfilter->cInitFlag = 0;
pstBloomfilter->dwCount = 0;
free(pstBloomfilter->pstFilter);
pstBloomfilter->pstFilter = NULL;
free(pstBloomfilter->pdwHashPos);
pstBloomfilter->pdwHashPos = NULL;
return 0;
}
// ����BloomFilter
// ע��: Reset()��������������ʼ��stFilter,���ǵ�һ��Add()ʱȥmemset
inline int ResetBloomFilter(BaseBloomFilter *pstBloomfilter)
{
if (pstBloomfilter == NULL)
return -1;
pstBloomfilter->cInitFlag = 0;
pstBloomfilter->dwCount = 0;
return 0;
}
// ��ResetBloomFilter��ͬ,���ú�����memset�ڴ�
inline int RealResetBloomFilter(BaseBloomFilter *pstBloomfilter)
{
if (pstBloomfilter == NULL)
return -1;
memset(pstBloomfilter->pstFilter, 0, pstBloomfilter->dwFilterSize);
pstBloomfilter->cInitFlag = 1;
pstBloomfilter->dwCount = 0;
return 0;
}
///
/// ����FORCE_INLINE,����ִ��
///
// MurmurHash2, 64-bit versions, by Austin Appleby
// https://sites.google.com/site/murmurhash/
FORCE_INLINE uint64_t MurmurHash2_x64 ( const void * key, int len, uint32_t seed )
{
const uint64_t m = 0xc6a4a7935bd1e995;
const int r = 47;
uint64_t h = seed ^ (len * m);
const uint64_t * data = (const uint64_t *)key;
const uint64_t * end = data + (len/8);
while(data != end)
{
uint64_t k = *data++;
k *= m;
k ^= k >> r;
k *= m;
h ^= k;
h *= m;
}
const uint8_t * data2 = (const uint8_t*)data;
switch(len & 7)
{
case 7: h ^= ((uint64_t)data2[6]) << 48;
case 6: h ^= ((uint64_t)data2[5]) << 40;
case 5: h ^= ((uint64_t)data2[4]) << 32;
case 4: h ^= ((uint64_t)data2[3]) << 24;
case 3: h ^= ((uint64_t)data2[2]) << 16;
case 2: h ^= ((uint64_t)data2[1]) << 8;
case 1: h ^= ((uint64_t)data2[0]);
h *= m;
};
h ^= h >> r;
h *= m;
h ^= h >> r;
return h;
}
// ˫��ɢ�з�װ
FORCE_INLINE void bloom_hash(BaseBloomFilter *pstBloomfilter, const void * key, int len)
{
//if (pstBloomfilter == NULL) return;
int i;
uint32_t dwFilterBits = pstBloomfilter->dwFilterBits;
uint64_t hash1 = MurmurHash2_x64(key, len, pstBloomfilter->dwSeed);
uint64_t hash2 = MurmurHash2_x64(key, len, MIX_UINT64(hash1));
for (i = 0; i < (int)pstBloomfilter->dwHashFuncs; i++)
{
pstBloomfilter->pdwHashPos[i] = (hash1 + i*hash2) % dwFilterBits;
}
return;
}
// ��BloomFilter������һ��Ԫ��
// �ɹ�����0,���������ݳ�������ֵʱ����1��ʾ�û�
FORCE_INLINE int BloomFilter_Add(BaseBloomFilter *pstBloomfilter, const void * key, int len)
{
if ((pstBloomfilter == NULL) || (key == NULL) || (len <= 0))
return -1;
int i;
if (pstBloomfilter->cInitFlag != 1)
{
// Reset��û�г�ʼ��,ʹ��ǰ��Ҫmemset
memset(pstBloomfilter->pstFilter, 0, pstBloomfilter->dwFilterSize);
pstBloomfilter->cInitFlag = 1;
}
// hash key��bloomfilter��
bloom_hash(pstBloomfilter, key, len);
for (i = 0; i < (int)pstBloomfilter->dwHashFuncs; i++)
{
SETBIT(pstBloomfilter, pstBloomfilter->pdwHashPos[i]);
}
// ����count��
pstBloomfilter->dwCount++;
if (pstBloomfilter->dwCount <= pstBloomfilter->dwMaxItems)
return 0;
else
return 1; // ����N���ֵ,���ܳ���ȷ���½������
}
// ���һ��Ԫ���Ƿ���bloomfilter��
// ����:0-����,1-������,������ʾʧ��
FORCE_INLINE int BloomFilter_Check(BaseBloomFilter *pstBloomfilter, const void * key, int len)
{
if ((pstBloomfilter == NULL) || (key == NULL) || (len <= 0))
return -1;
int i;
bloom_hash(pstBloomfilter, key, len);
for (i = 0; i < (int)pstBloomfilter->dwHashFuncs; i++)
{
// ���������bit��Ϊ1,˵��key����bloomfilter��
// ע��: GETBIT()���ز���0|1,��λ���ܳ���128֮������
if (GETBIT(pstBloomfilter, pstBloomfilter->pdwHashPos[i]) == 0)
return 1;
}
return 0;
}
/* �ļ���ط�װ */
// �����ɺõ�BloomFilterд���ļ�
inline int SaveBloomFilterToFile(BaseBloomFilter *pstBloomfilter, char *szFileName)
{
if ((pstBloomfilter == NULL) || (szFileName == NULL))
return -1;
int iRet;
FILE *pFile;
static BloomFileHead stFileHeader = {0};
pFile = fopen(szFileName, "wb");
if (pFile == NULL)
{
perror("fopen");
return -11;
}
// ��д���ļ�ͷ
stFileHeader.dwMagicCode = __MGAIC_CODE__;
stFileHeader.dwSeed = pstBloomfilter->dwSeed;
stFileHeader.dwCount = pstBloomfilter->dwCount;
stFileHeader.dwMaxItems = pstBloomfilter->dwMaxItems;
stFileHeader.dProbFalse = pstBloomfilter->dProbFalse;
stFileHeader.dwFilterBits = pstBloomfilter->dwFilterBits;
stFileHeader.dwHashFuncs = pstBloomfilter->dwHashFuncs;
stFileHeader.dwFilterSize = pstBloomfilter->dwFilterSize;
iRet = fwrite((const void*)&stFileHeader, sizeof(stFileHeader), 1, pFile);
if (iRet != 1)
{
perror("fwrite(head)");
return -21;
}
// �����BloomFilter������
iRet = fwrite(pstBloomfilter->pstFilter, 1, pstBloomfilter->dwFilterSize, pFile);
if ((uint32_t)iRet != pstBloomfilter->dwFilterSize)
{
perror("fwrite(data)");
return -31;
}
fclose(pFile);
return 0;
}
// ���ļ���ȡ���ɺõ�BloomFilter
inline int LoadBloomFilterFromFile(BaseBloomFilter *pstBloomfilter, char *szFileName)
{
if ((pstBloomfilter == NULL) || (szFileName == NULL))
return -1;
int iRet;
FILE *pFile;
static BloomFileHead stFileHeader = {0};
if (pstBloomfilter->pstFilter != NULL)
free(pstBloomfilter->pstFilter);
if (pstBloomfilter->pdwHashPos != NULL)
free(pstBloomfilter->pdwHashPos);
//
pFile = fopen(szFileName, "rb");
if (pFile == NULL)
{
perror("fopen");
return -11;
}
// ��ȡ������ļ�ͷ
iRet = fread((void*)&stFileHeader, sizeof(stFileHeader), 1, pFile);
if (iRet != 1)
{
perror("fread(head)");
return -21;
}
if ((stFileHeader.dwMagicCode != __MGAIC_CODE__)
|| (stFileHeader.dwFilterBits != stFileHeader.dwFilterSize*BYTE_BITS))
return -50;
// ��ʼ������� BaseBloomFilter �ṹ
pstBloomfilter->dwMaxItems = stFileHeader.dwMaxItems;
pstBloomfilter->dProbFalse = stFileHeader.dProbFalse;
pstBloomfilter->dwFilterBits = stFileHeader.dwFilterBits;
pstBloomfilter->dwHashFuncs = stFileHeader.dwHashFuncs;
pstBloomfilter->dwSeed = stFileHeader.dwSeed;
pstBloomfilter->dwCount = stFileHeader.dwCount;
pstBloomfilter->dwFilterSize = stFileHeader.dwFilterSize;
pstBloomfilter->pstFilter = (unsigned char *) malloc(pstBloomfilter->dwFilterSize);
if (NULL == pstBloomfilter->pstFilter)
return -100;
pstBloomfilter->pdwHashPos = (uint32_t*) malloc(pstBloomfilter->dwHashFuncs * sizeof(uint32_t));
if (NULL == pstBloomfilter->pdwHashPos)
return -200;
// �������Data���ֶ��� pstFilter
iRet = fread((void*)(pstBloomfilter->pstFilter), 1, pstBloomfilter->dwFilterSize, pFile);
if ((uint32_t)iRet != pstBloomfilter->dwFilterSize)
{
perror("fread(data)");
return -31;
}
pstBloomfilter->cInitFlag = 1;
printf(">>> Load BloomFilter(n=%u, p=%f, m=%u, k=%d), malloc() size=%.2fMB\n",
pstBloomfilter->dwMaxItems, pstBloomfilter->dProbFalse, pstBloomfilter->dwFilterBits,
pstBloomfilter->dwHashFuncs, (double)pstBloomfilter->dwFilterSize/1024/1024);
fclose(pFile);
return 0;
}
#endif
#include "bloomfilter.h"
#include <stdio.h>
#define MAX_ITEMS 4000 // �������Ԫ��
#define ADD_ITEMS 1000 // ���Ӳ���Ԫ��
#define P_ERROR 0.0000001 // �������
int main(int argc, char** argv)
{
printf(" test bloomfilter\n");
// 1. ����BaseBloomFilter
static BaseBloomFilter stBloomFilter = {0};
// 2. ��ʼ��stBloomFilter,����ʱ����hash����,�洢����,�Լ�������������
InitBloomFilter(&stBloomFilter, 0, MAX_ITEMS, P_ERROR);
// 3. ��BloomFilter��������ֵ
char url[128] = {0};
for(int i = 0; i < ADD_ITEMS; i++){
sprintf(url, "https://0voice.com/%d.html", i);
if(0 == BloomFilter_Add(&stBloomFilter, (const void*)url, strlen(url))){
// printf("add %s success", url);
}else{
printf("add %s failed", url);
}
memset(url, 0, sizeof(url));
}
// 4. check url exist or not
const char* str = "https://0voice.com/0.html";
if (0 == BloomFilter_Check(&stBloomFilter, str, strlen(str)) ){
printf("https://0voice.com/0.html exist\n");
}
const char* str2 = "https://0voice.com/10001.html";
if (0 != BloomFilter_Check(&stBloomFilter, str2, strlen(str2)) ){
printf("https://0voice.com/10001.html not exist\n");
}
// 5. free bloomfilter
FreeBloomFilter(&stBloomFilter);
getchar();
return 0;
}