本文是自己写来用于回顾2d检测中易混淆的关键知识点
总结:
1.yolov1,yolov2,yolov3的bbox中心点坐标的损失计算方法和faster rcnn系列不一样,yolo计算损失时是直接坐标相减,而faster rcnn计算损失时是用的gd和anchor的偏移量与预测的和anchor的偏移量作差。 我们其实可以通过看出网络预测输出的是什么,从而判断是上面哪种损失计算方式,因为计算损失时一般都是直接取网络的输出来计算,而不会对网络的输出进行变换后再去和gd算损失,都是对标签进行处理来迎合网络输出的形式。
2.相对(局部)坐标的计算思想:比如要算a点的相对于b这个网格的坐标,就是通过计算 a这一点的绝对坐标(这个例子就是相对于图像坐标系的,如果点云就是相对于雷达坐标系的) 减去 b这个网格的中心(选格子的左上角为中心)的绝对坐标,但除不除以对应的边长(就是gridsize),也就是是否标准化就看具体的代码或者论文实现。
Yolo v1:
直接看这位大佬的链接,讲得非常透彻!:https://blog.csdn.net/weixin_41424926/article/details/105382858?ops_request_misc=&request_id=&biz_id=&utm_medium=distribute.pc_search_result.none-task-blog-2alles_rank~default-1-105382858.es_vector_control_group&utm_term=googlenet+yolov1&spm=1018.2226.3001.4187
这是我唯一看到对训练样本的标签进行讲解的文章,更能深刻理解bbox的坐标回归损失。
网络是直接回归bbox的中心坐标(x,y)。标签的制作过程:将标签的bbox的中心绝对坐标xc(基于原始图像的像素坐标)除以7(因为输出特征图为7×7,要分成7×7个格子)然后向下取整得到g,来判断该点属于哪个格子(g数过来在哪个格子的左上角就是哪个格子负责),g×gridsize得到xg,然后用(xc-xg)/gridsize就得到了用于损失计算的中心坐标(yolov1-yolov3都是采用这种方式)。
不足:
1.YOLO对相互靠近的物体,会导致许多的 object 的中心点其实在一个 cell 中,那么就会出现漏检。这是因为一个网格只预测了2个框,并且都只属于同一类,因为每个网格只预测一个类别C,而且每个网格的感受野比较大(7*7的输出,一个点的对应到原图的感受野就是64),那么相对来说对大物体的检测就比较理想,而对小物体的检测就比较棘手。
2.由于损失函数的问题,定位误差是影响检测效果的主要原因。尤其是大小物体的处理上,还有待加强。(因为对于小的bounding boxes,小误差的影响会很大)
3.宽高比方面泛化率低,就是无法定位不寻常比例的物体。
Yolov2:
改进点可以看这个链接,具体容易混淆的细节我下面有解析:https://blog.csdn.net/u014380165/article/details/77961414?ops_request_misc=&request_id=&biz_id=102&utm_term=yolov2&utm_medium=distribute.pc_search_result.none-task-blog-2allsobaiduweb~default-2-77961414.nonecase&spm=1018.2226.3001.4187
提升点:
- 引入 Batch Normalization
- 将YOLOv1网络的FC层和最后一个Pooling层去掉,最后输出1313125,其中125=5个anchor*(20+4+1) ,Yolov2网络结果参考链接:
https://blog.csdn.net/zhw864680355/article/details/103119156 - 引入 Anchor Box:yolov1是直接和gd做的损失,没有anchor box
- 利用尺寸聚类(Kmeans,IOU作为距离度量)自动得到anchor box尺寸而不是手选
- 采用anchor box,但中心点坐标的损失计算没有沿用rpn提出来的那个损失计算方法,即网络直接预测偏移(faster rcnn系列的bbox损失都是这个计算思想),而是仍然沿用yolov1的损失计算思想方法,网络直接预测中心点坐标(yolo系列bbox中心点坐标损失计算都是这个思想)
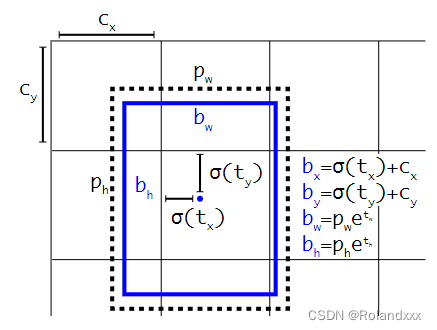
具体解释:如上图所示,pw,ph是先验框的宽,高。cx,cy是基于原图划分为H*W(H,W由输出特征图决定)个格子后,bbox中心点坐标相对于左上角点x方向和y方向的格子数(不足的舍去)。举个具体的例子(以yolov3为例,因为yolov3和yolov2这里的计算方法一样),假设原图输入是256,对于输出的一个head的特征图16 × 16 × 3 × 85(3是预测3个box,85=80类+1+4)中的第[5,4,2]维(即第5行第4列的预测的第2个box对应的值),上图中的cx为5, cy为4,输出特征图对应的先验框为(30×61),(62×45),(59× 119),prior_box的index为2,那么取最后一个59,119作为先验w、先验h。这样计算之后的bx,by还需要乘以每个gridsize(这里为256/16=16),才得到真实的检测框x,y。(这一点很多博客根本没提!!!)
Yolov3
1.特征提取网络加入残差
2.多尺度预测(3个head,3种不同尺度的网络输出Y1、Y2、Y3)
3.多标签分类:用于分类的softmax层修改为逻辑回归分类器(sigmoid)。因为在一些复杂的场景中,单一目标可能从属于多个类别。