1.第一次分治
kafka通过topic给用户提供数据的读写,对于不同的业务来说,可以定义不同的topic来达到数据分治的目的,不同的业务写入或者读取不同的topic,且不同的topic会尽可能分散在不同的broker中,提高数据的IO效率。
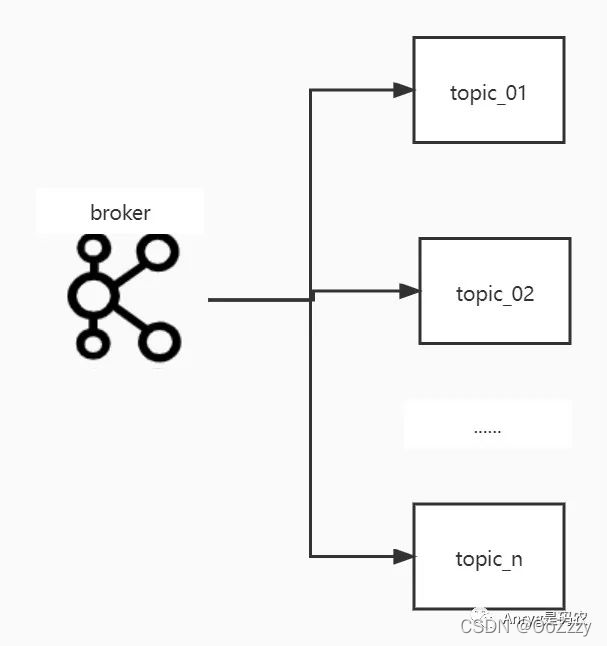
虽然kafka没有限制topic的个数,但是也不要盲目多建,因为越多的topic,代表着越多的数据存储单元,容易导致同一个topic的数据在磁盘存储位置的不连续,从而降低数据读写的IO。
2.第二次分治
对于kafka的topic,我们在创建之初可以设置多个partition来存放数据,对于同一个topic的数据,每条数据的key通过哈希取模被路由到不同的partition中(如果没有设置key,则根据消息本身取模),以此达到分治的目的。
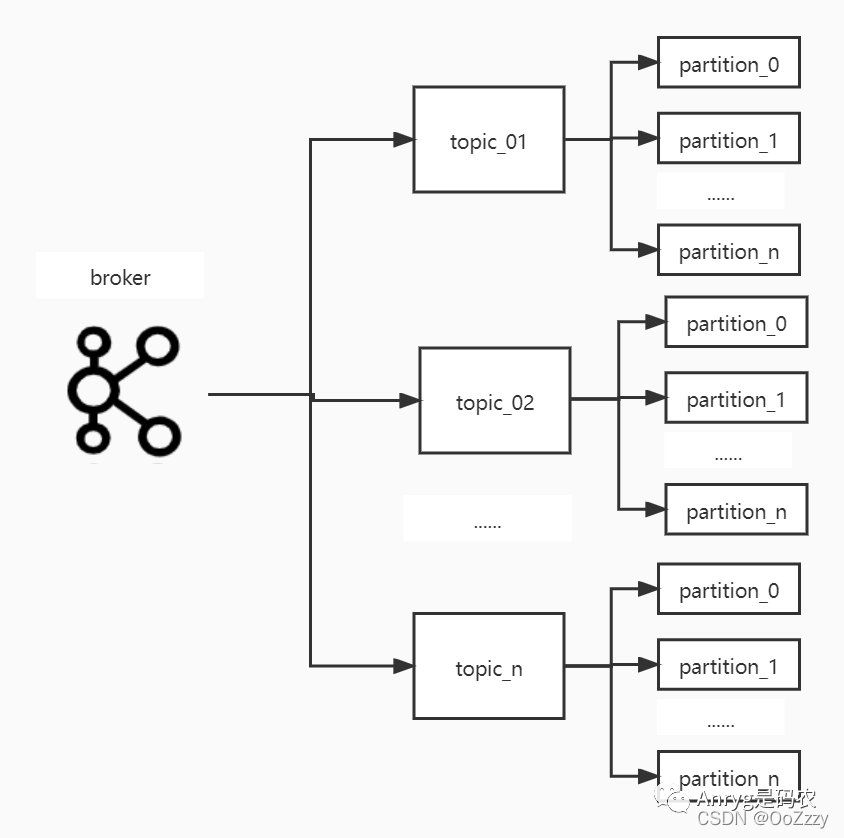
同样,对于每个topic的partition数量来说,也不宜过多,因为partition是kafka管理数据的基本逻辑组织单元,越多的partition意味着越多的数据存储文件(一个partition对应至少3个数据文件),同样容易隔断磁盘数据的连续性,影响数据读写的IO性能。
另外,过多的partition还会导致broker的操作系统内存OOM,即每一个partition文件至少对应2个索引文件(至少1个.index文件和1个.indextime文件),而索引文件是需要常驻内存的,因此partition数量不宜过多。
3.第三次分治
索引+分治:
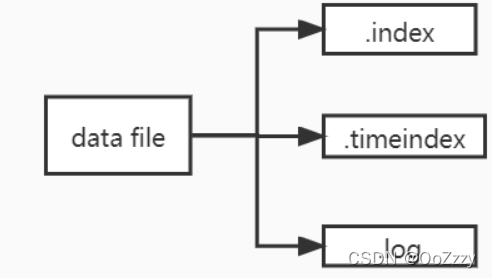
即原本一个partition对应一个文件的情况,变成了一个partition对应多个不同类型的文件,kafka将文件根据不同的功能分成了3大类:
-
.index文件:offset索引文件,用来记录log文件中真实消息的相对偏移量和物理位置,为了减少索引文件的大小,这里用了一种比较聪明的做法,叫稀疏索引,即只记录相对offset的范围段(后文详细说明),可用于快速定位目标offset的消息;
-
.timeindex文件:时间索引文件,类比.index文件,用来记录log文件中真实消息写入的时间情况,跟offset索引文件功能一样,只不过这个以时间作为索引,用来快速定位目标时间点的数据;
-
.log文件:用来记录producer写入的真实消息,即消息体本身;
4.第四次分治
随着数据的不断写入,这3个文件就会越来越大,会导致它们的读写IO也会越来越高,负荷越来越重。
kafka对单个.index文件、.timeindex文件、.log文件的大小都有限定(通过不同参数配置),且这3个文件互为一组,当.log文件的大小达到阈值则会自动拆分形成一组新的文件。如图所示:

这种将数据拆分成多个的小文件叫做segment,一个log文件代表一个segment。
分治的作用只是将大份数据进行打散成多份小数据,而如果想要快速定位到其中的某条数据,还必须要有索引或者路由策略才可以。否则,查找效率一样不佳。
5.查询逻辑
分治思想解决了数据集中的问题,将原本一份很大的数据进行了多个层次的拆分,让数据分散到多台服务器(多个broker)的多个不同目录,以及同个目录下的多个文件中。
offset: 对于消费者来说,想要消费哪个topic的数据,kafka先通过topic名字找到其topic,其时间复杂度为O(1),然后到每个partition中定位具体的offset。利用二分查找方法。并利用.index文件进一步精确定位消息位置。
.index文件和.log文件对应关系:
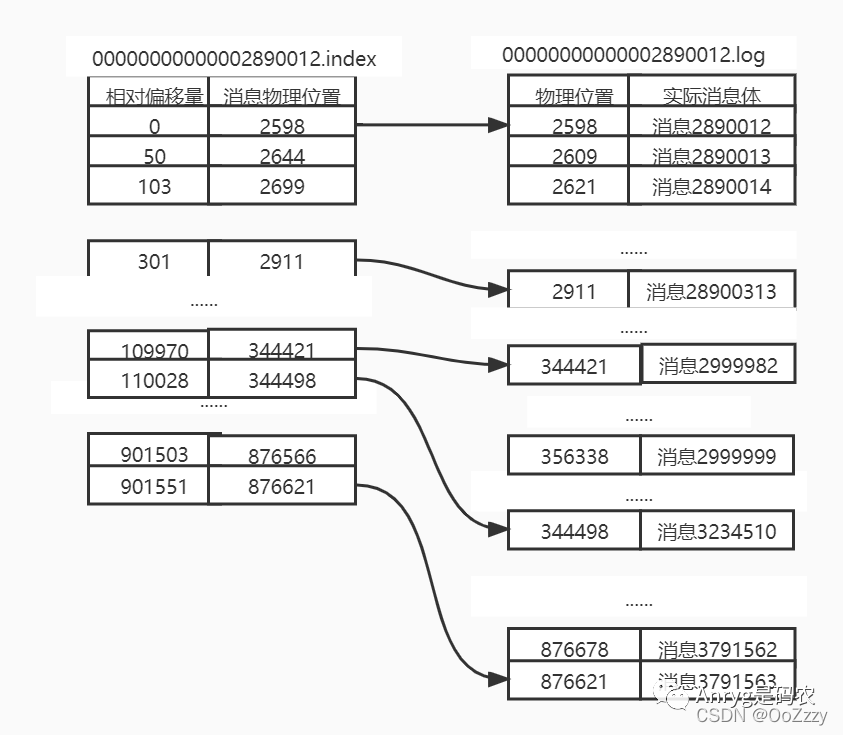
二分查找,通过O(logN)的查找复杂度,在.index文件中定位到其物理位置在相对偏移量为109970(109970+2890012=2999982为小于2999999的最大偏移量)和110028(110028+2890012=3000040 为大于2999999最小的偏移量)这两个索引中间。
即定位到offset为2999999这条消息的具体物理位置在位置244421和位置344498之间。
kafka是顺序存储的, 再二分找找,最终定位到位置为344486的消息即为目标消息。
查询通过3次分治查找。第一次根据offset找到目标index文件 第二次通过index文件找到属于哪个offset段 第三次具体找到对应的目标消息。
6.总结
Kafka通过4次分治和3次二分查找的算法定位到消息目标。
查询通过3次分治查找。第一次根据offset找到目标index文件 第二次通过index文件找到属于哪个offset段 第三次具体找到对应的目标消息。