Redis ЪЧгУCгябдаДЕФ,ЫљвдЖдгкЪ§ОнНсЙЙЖјбд,дНЧхГўдРэ,дНФмЙЛУїАзredisЕФРїКІжЎДІЁЃ
МИИіУћДЪЯШМЧзЁ: RedisDB RedisObject dict sds dictEntry
ДцДЂжЕ вЊжЊЕР ДцЕФНсЙЙЮЊЪВУД жЇГж string hash listетУДЖрЪ§ОнНсЙЙ
ЖјЧвжЊЕРНсЙЙжЎКѓ,ЛЙвЊеыЖдВЛЭЌЕФНсЙЙВЛЭЌЕФБрТы,РДЬсЩ§аЇТЪЁЃ
вРРЕ
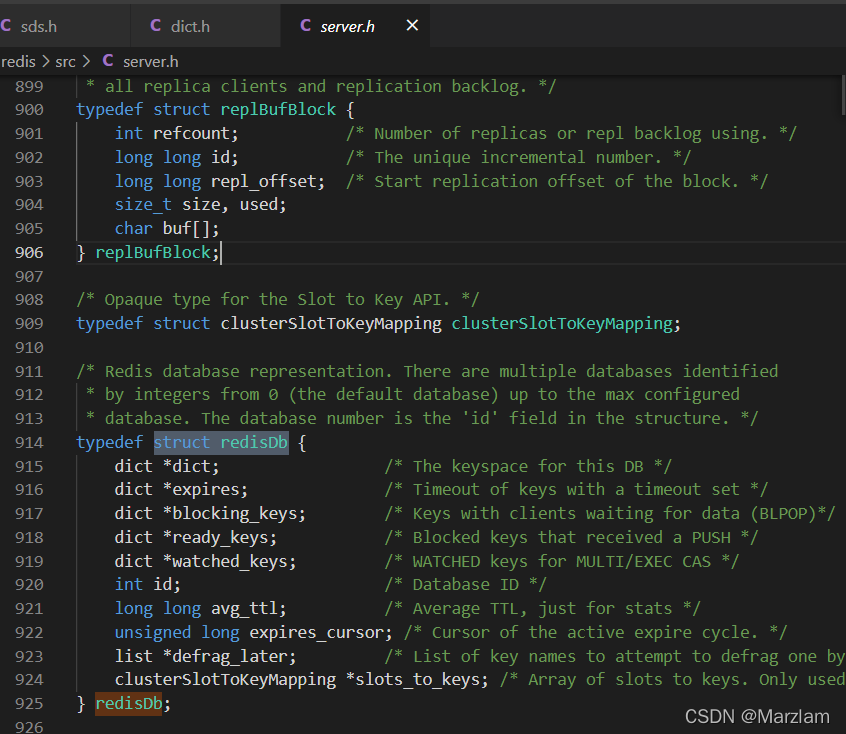
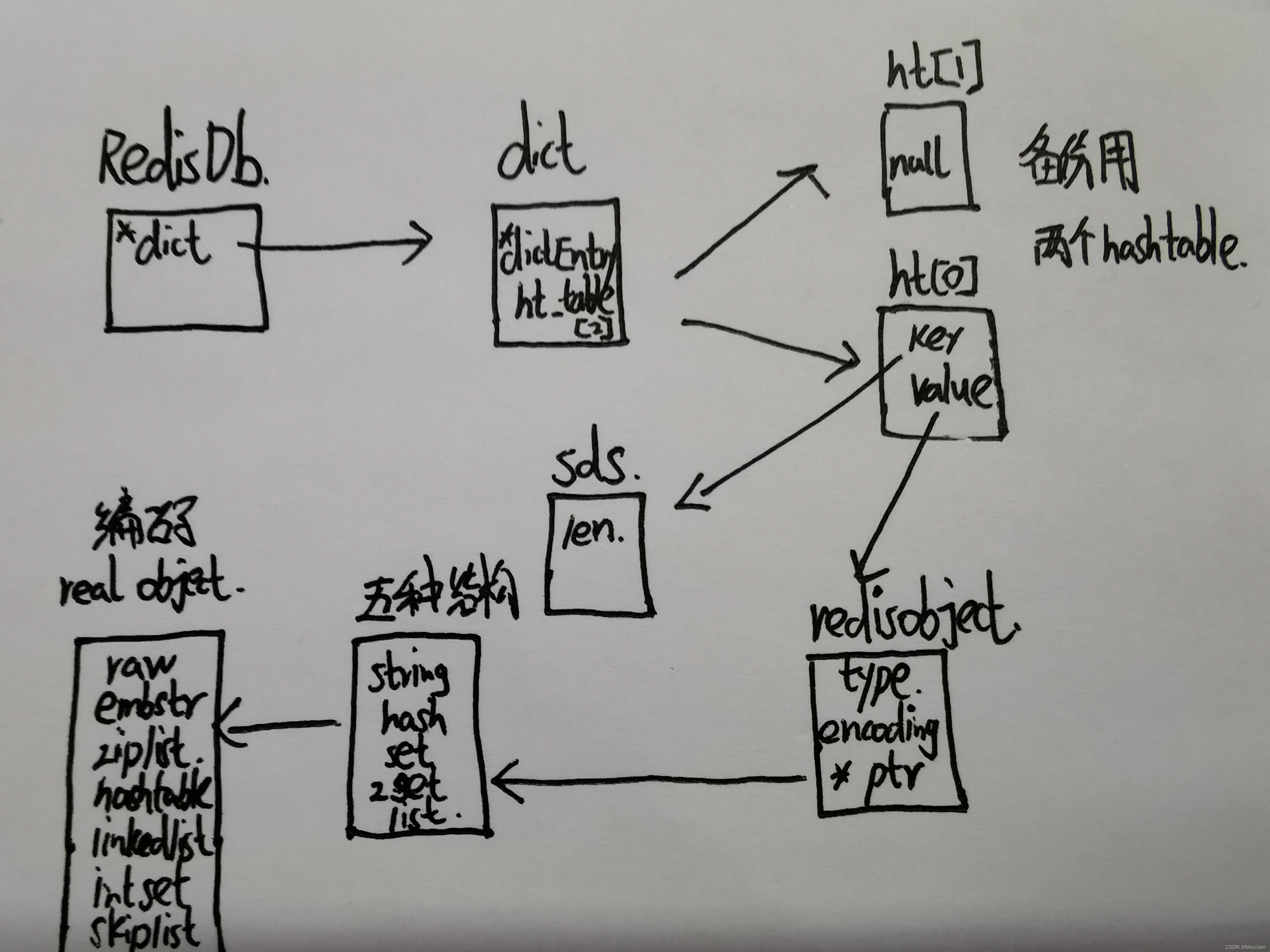
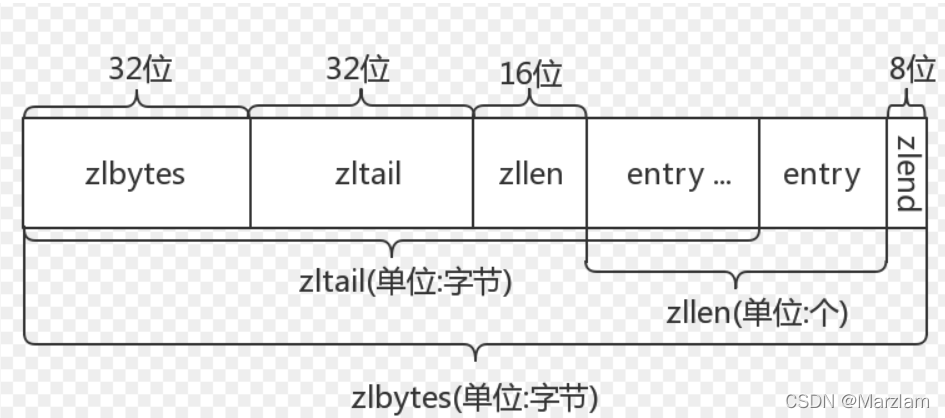
1.RedisDB вВОЭЪЧ Ъ§ОнПт ЫќДг0ЕН15 вЛЙВ16Иі етЪЧЕквЛВНШыПкЪ§ОндкФФИіПт
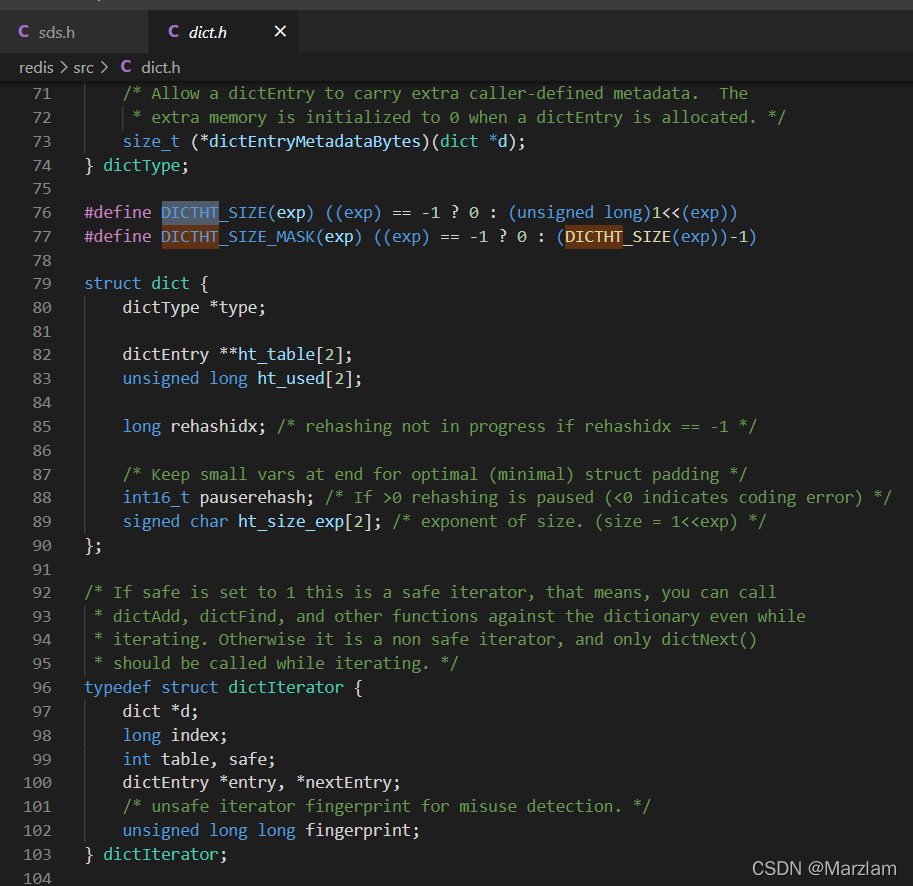
2. RedisDB РяУцга dict вВОЭЪЧзжЕфдиЬхвВОЭЪЧДцЪ§ОнЕФдиЬх
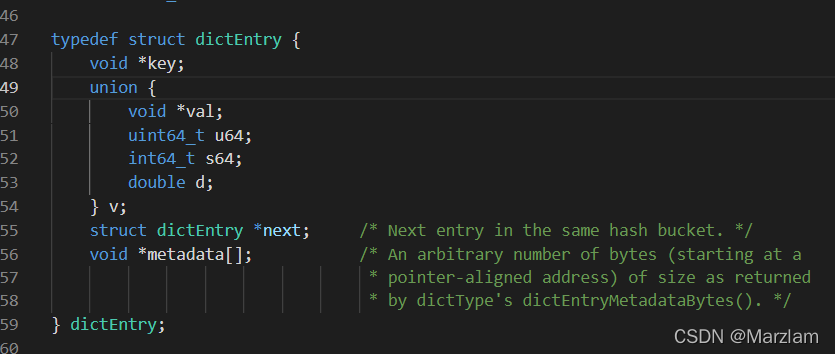
3. dict РяУцга dictEntry вВОЭЪЧДцЕФКЫаФНкЕуЧјгђСЫЙўЯЃаЮЪНЕФБэЯжаЮЪН
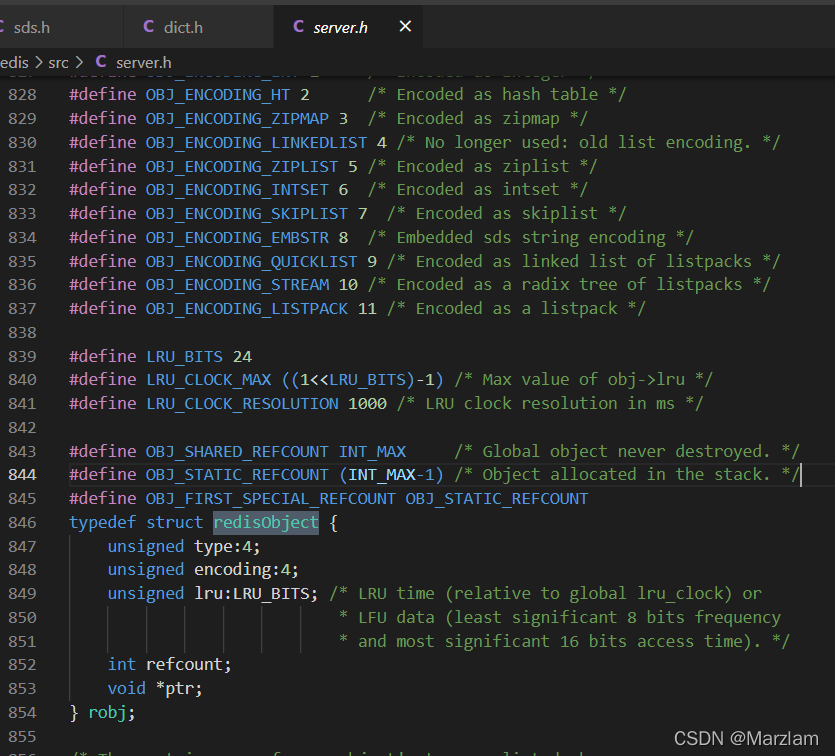
4. dictEntryРяУцkey ЪЧ sds valueЪЧ RedisObject вВОЭЪЧЩцМАБрТыЯрЙиДцЖдЯѓ вВОЭЪЧ5жжЛљДЁНсЙЙЕФЬхЯж
НсЙЙСїГЬЪсРэ:дДТыЮФМў server.h - dict.h -sds.h - server.h
SDS

зжЗћДЎstringЛљгкSDSЪЕЯж
гУгкМЦЪ§:ЗлЫПЪ§
ЛЙПЩгУгкБЃДцгУЛЇЕФsession,ЧАЬсЪЧБЃжЄredisЕФИпПЩгУ
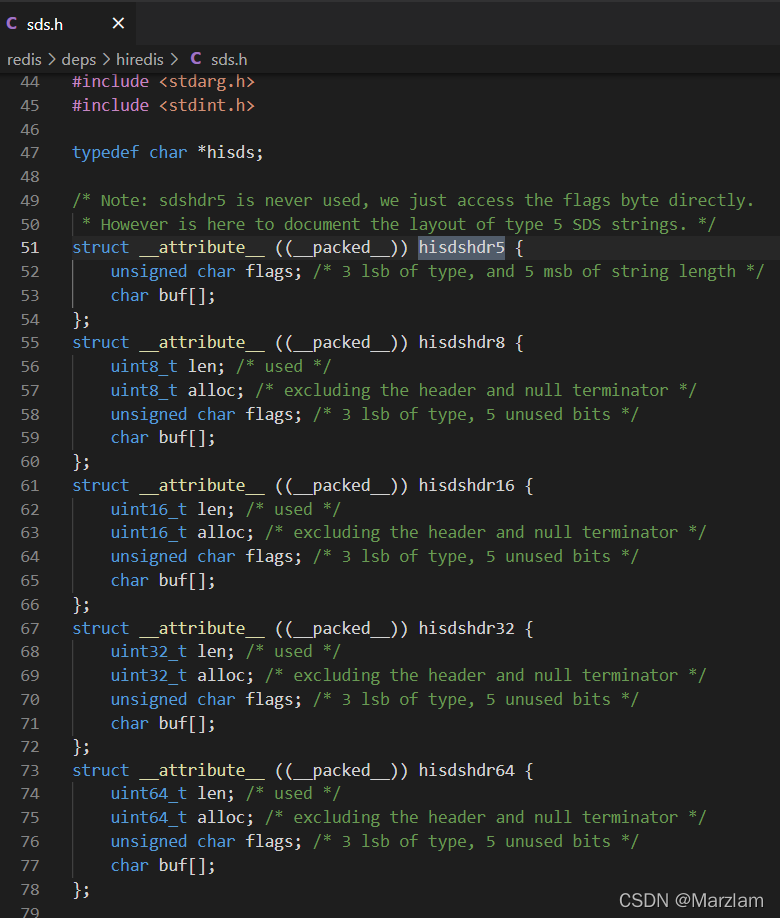
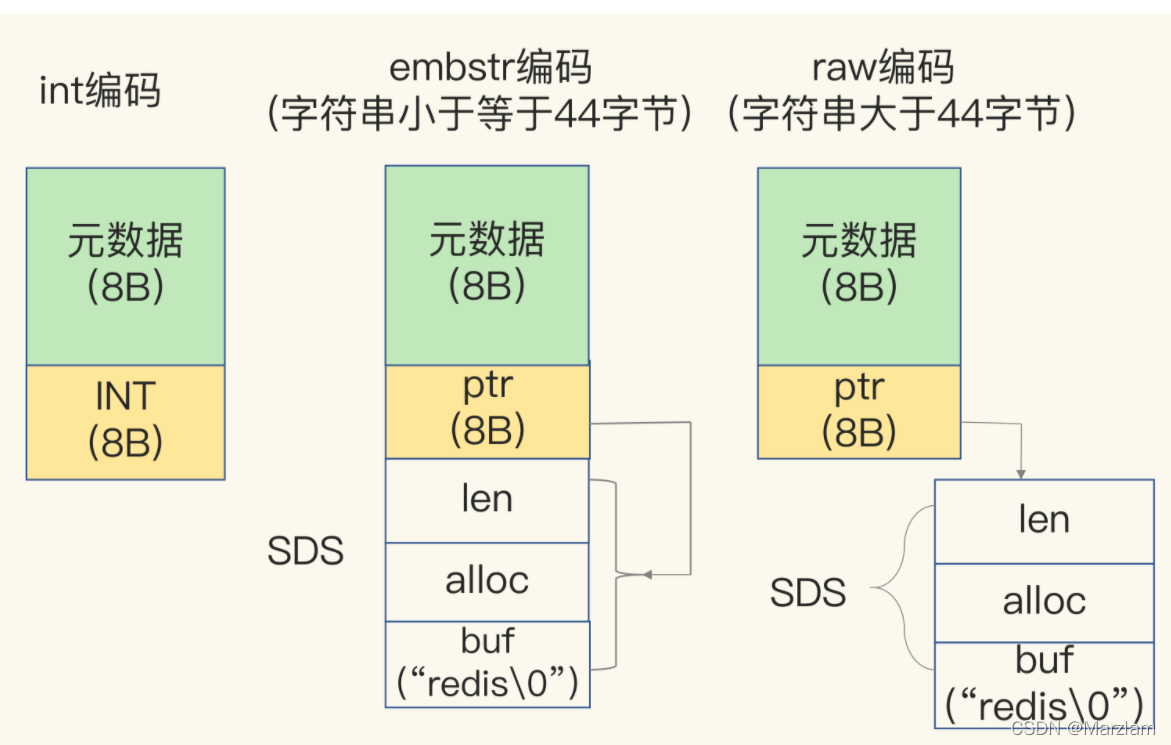
2жжБрТы raw embstr
raw ПЊБйСНДЮПеМф Дѓгк44зжНкЕФЪБКђ
embstr аЁгк44зжНкЕФЪБКђ ПЊБйвЛДЮПеМф,дЄСєвЛДЮПеМф ЛсдьГЩПеМфШпгр
ЮЊЪВУДЪЧ44,дРДЪЧ39,вђЮЊ sds КѓајгХЛЏ гаСЫ5ажЕм sdshdr5 sdshdr8 sdshdr16 sdshdr32 sdshdr64
БОЩэОЭЪЧеыЖдЖЬзжЗћДЎЕФembstrздШЛЛсЪЙгУзюаЁЕФsdshdr8,Жјsdshdr8гыжЎЧАЕФsdshdrЯрБШе§КУМѕЩйСЫ5ИізжНк(sdsdr8 = uint8_t * 2 + char = 1*2+1 = 3, sdshdr = unsigned int * 2 = 4 * 2 = 8),ЫљвдЦфФмШнФЩЕФзжЗћДЎГЄЖШдіМгСЫ5ИізжНкБфГЩСЫ44.
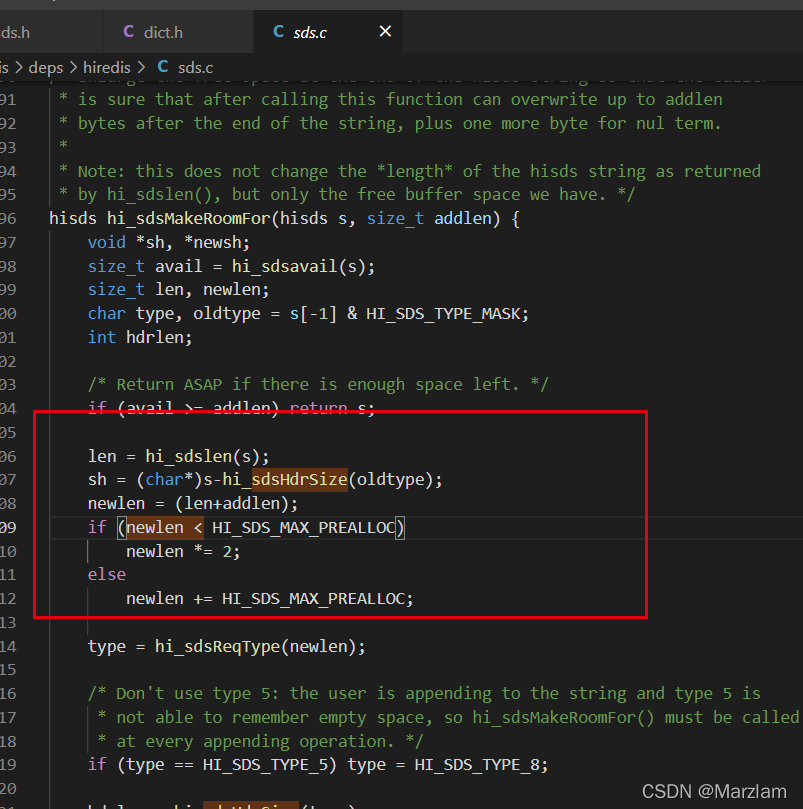
sdsФкВПbufЕФРЉШнЛњжЦ:аТbufГЄЖШ = (дbufГЄЖШ + ЬэМгbufГЄЖШ)*2ЁЃШчЙћbufГЄЖШДѓгк1MКѓ,УПДЮРЉШнвВжЛЛсдіДѓ1M
Ыљвд вЛАуЭЦМігУhash
ЙўЯЃhash ЛљгкзжЕфЪЕЯж
ЪЪгУгкДцДЂЖдЯѓ,ЧАЬсЪЧетИіЖдЯѓУЛгаЧЖЬзЦфЫќЖдЯѓ
2жжБрТы hashtable ziplist
ziplist: аЁkeyЕФИіЪ§ВЛГЌЙ§512ЖјЧвГЄЖШЖМВЛДѓгк64ИізжНк
hashtable:ГЌЙ§512 Дѓгк64ИізжНк ЪБМфИДдгЖШ o(1) ЙўЯЃЫуЗЈ
ziplist ЯрЕБгкбЙЫѕаЭЕФМЏКЯ,ЕЋЪЧВщевЪБМфИДдгЖШ o(n),ЫљвдгжЯожЦ512
ЖјЧвПЊБйПеМфЪЧвдзюДѓдЊЫизжНкПЊБйЕФ,ЫљвдШчЙћЪЧ1,2,3,100ОЭЛсПЊБй4Иі100,ЫљвдгжЯожЦВЛДѓгк64
ЫљвдвЊhashtable ЪБМфИДдгЖШo(1)ЭЈЙ§ЙўЯЃЫуЗЈ УПИідЊЫиШЗЖЈвЛИіЯргІбАжЗ,евЕФЪБКђОЭжБНгИљОнЯТБъОЭевЕНСЫЁЃ
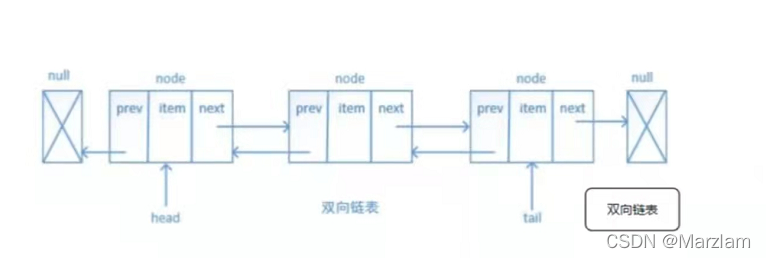
СаБэlist ЛљгкЫЋЯђСДБэЪЕЯж
аоИФlistжаМфЕФЪ§ОнЪБ,ЪБМфИДдгЖШНЯИп
ЪЪгУгкЗлЫПСаБэ ЯћЯЂСаБэ
2жжБрТы linkedlist ziplist
3.0жЎКѓlistМќвбОВЛжБНггУziplistКЭlinkedlistзїЮЊЕзВуЪЕЯжСЫ,ШЁЖјДњжЎЕФЪЧquicklist
ЕЅЯђСДБэ,КУВюШыВщбЏ,ЕЋВЛКУЩОГ§ ЗДзХРД
ЫЋЯђСДБэ ПЩвдЕБЖгСавВПЩвдЕБеЛ ЪЙгУ
hash-max-ziplist-entries 512
hash-max-ziplist-value 64
МЏКЯset ЛљгкзжЕфЪЕЯж
ЙІФмгыlistРрЫЦ,ЕЋПЩвдздЖЏШЅжи ,ЕЋЮоађ
ПЩвдгУsetРДЧѓНЛМЏ,ШчЙВЭЌЙизЂЁЂЙВЭЌЗлЫПЁЂЙВЭЌЯВКУ
ЪЙгУsrandommemberРДЛёШЁЫцЛњЪ§
2жжБрТы hashtable intset
intset :ЖМЪЧЪ§зж ЖјЧвЖдгІДѓаЁ БрТыint16 32 64 ЖјЧвбАев ЖўЗжВщев гаЫГађЕФ
hashtable : ДцдкВЛЪЧЪ§зжЕФжЕ/Ъ§зжГЌЙ§2ЕФ64ДЮЗН/ГЄЖШГЌЙ§512
гаађМЏКЯzset ЛљгкЬјБэЪЕЯж
2жжБрТы skiplist ziplist
ziplist: МЏКЯЪ§СПаЁгк128Иі ЖјЧв дЊЫиЕФДѓаЁЖМаЁгк 64зжНк
skiplist: ЗжЪ§ЙВЯэФкДцЁЂЬјдОБэ
