1.什么叫快速排序?
快速排序是对冒泡排序的改进,其实质是给基准数据找其正确索引位置的过程。
2.快速排序的实现步骤?
快排的主要思想是分治思想,将大问题分成小问题解决,主要有三步:
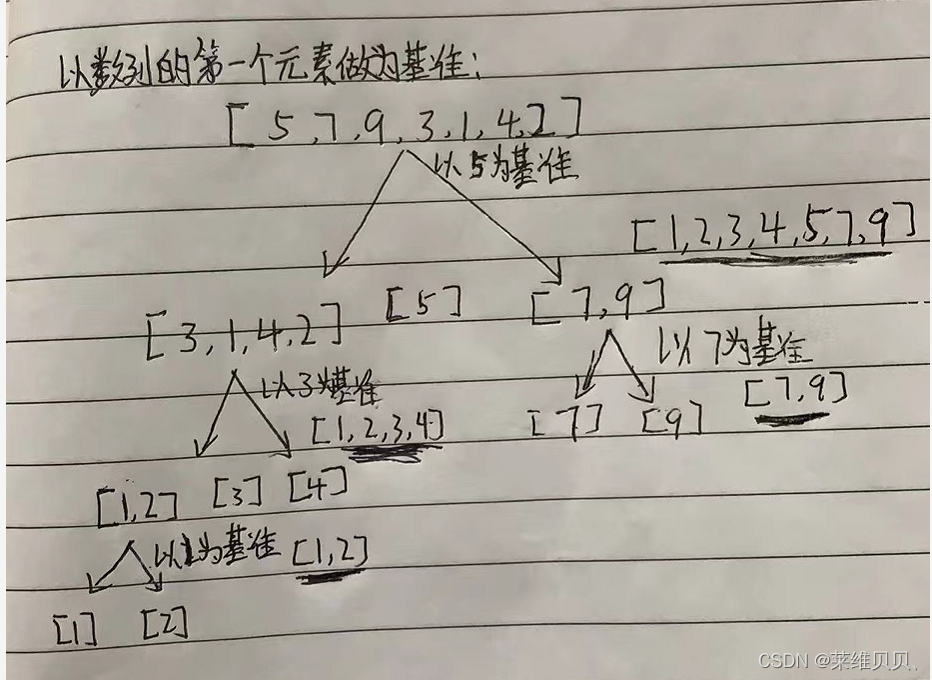
- 在数列中,选择一个元素作为基准(pivot),或者叫比较值:
- 将数列中所有元素与基准进行比较,比基准小的放基准的左边,比基准大的放基准的右边。
- 以基准值左右两边的子列作为新数列,不断重复第一步和第二步,直到所有子集只剩下一个元素为止。
如下图所示:
3.快速排序是所有排序里面性能最好的吗?
答:在数据规模越大快速排序的性能越优。快排在极端情况下会变成O(n2)复杂度的算法,如果每次选第一个数作为基准值,但每次这个数又是最小值,那么序列本身就是有序的,但时间复杂度是最高的。
4.归并排序与快速排序那个更高效:
答:归并排序与快速排序都是分为之治思想,但是它们分解和合并的策略不一样:归并是从中间直接将数列分为两个,而快排是比较后将小的放在左边,大的放在右边;归并排序在合并的时候需要将两个数列再次进行对比排序,而快排则直接合并不再需要排序;所以快排比归并排序更高效一些。
5.快速排序有什么优点,有什么缺点?
答:快速排序的思想是分治思想,在处理大数据集时效果比较好,但是小数据集时候性能差些。当数据量较少时,比如数据量为10的时候,插入排序的速度比快速排序快,因为数据量较少时交换所消耗的资源占比大。
6.快排优化方案成立
答:对于大数据集排序先使用快排,使数据集达到基本有序,然后当分区达到一定小的时候使用插入排序,因为插入排序对少量的基本有序数据集性能由于快排!
快速排序的原始代码:
def quick_sort(s, l, r):
if l >= r:
return
# 列表的最后一个元素,s[l]作为基准值
pivot = s[l]
left = l
right = r
# 一轮循环,有可能,不能将所有的大数都放到基准值的右边,小数放到基准值的左边,所以直到left>right 跳出循环;
while left < right:
# 找寻右边数列比基准值小的数的位置
while left < right and s[right] >= pivot:
right -= 1
# 此时有两种情况,第一种:left=right,下面操作可以说无意义;
# 第二种:找到了s[right] >= pivot 且 left<right,意义将较大或相等的值放到左边的坑位
s[left] = s[right]
# 找寻左边数列比基准值大的数的位置
while left < right and s[left] < pivot:
left += 1
# 此时有两种情况,第一种:left=right,下面操作可以说无意义;
# 第二种:找到了s[right] < pivot 且 left<right,意义将较小的值放到右边的坑位
s[right] = s[left]
# 将大的数放在基准值的右边,小的数放在基准值的左边
# while结束时候,left=right ,将基准值放到中间
s[left] = pivot
quick_sort(s, l, left-1)
quick_sort(s, left+1, r)
if __name__ == '__main__':
s = [9,8,6,7,4,3,99,5,3]
quick_sort(s,0,len(s)-1)
print(s)
# 稳定性:不稳定
# 最优时间复杂度:O(nlogn)
# 最坏时间复杂度:O(n^2)
参考:
https://zhuanlan.zhihu.com/p/60731708
https://www.cnblogs.com/skywang12345/p/3596746.html
https://www.cnblogs.com/tianyadream/p/12456545.html
https://zhuanlan.zhihu.com/p/61800461
https://www.cnblogs.com/sfencs-hcy/p/10602598.html
https://blog.csdn.net/liangkaiping0525/article/details/82558188