ЮФеТФПТМ
ЧАбд
ЮвУЧЕФМЦЫуЛњФмЙЛНјааЪ§жЕдЫЫу,ЕЋЪЧгЩгкВЛЭЌЪ§ОнжЎМфЕФСЊЯЕКмЩй,гаЕФЪ§ОнжЎМфЭъШЋУЛгаШЮКЮСЊЯЕ,ЫљвдЮвУЧКмФбРћгУетаЉЕЅвЛЕФЪ§ОнШЅДІРэЪЕМЪЩњЛюжаЕФИДдгЮЪЬтЁЃВЛЙ§ШчЙћЮвУЧШЫЮЊЕиШУетаЉЪ§ОнДцдкЬиЖЈЕФСЊЯЕ,ФЧЮвУЧОЭгаСЫвЛжжДІРэЮЪЬтЕФЙЄОпКЭВФСЯЁЃ
етОЭКЭЁАЧЩИОФбЮЊЮоУзжЎДЖЁБвЛИіЕРРэ,ЮвУЧашвЊВФСЯЁЊЪ§ОнНсЙЙ,ВХФмНјааКмЖрЬиЪтЕФГЬађЩшМЦЁЃ
ЯжЪЕЩњЛюжа,КмЖрДѓаЭГЬађЖМгІгУСЫЪ§ОнНсЙЙЁЃ
етвЛИізЈРИЛсДјДѓМвШЯЪЖВЂЧвЩюШыСЫНтЪ§ОнНсЙЙЁЃ
ГѕЪЖЪ§ОнНсЙЙ
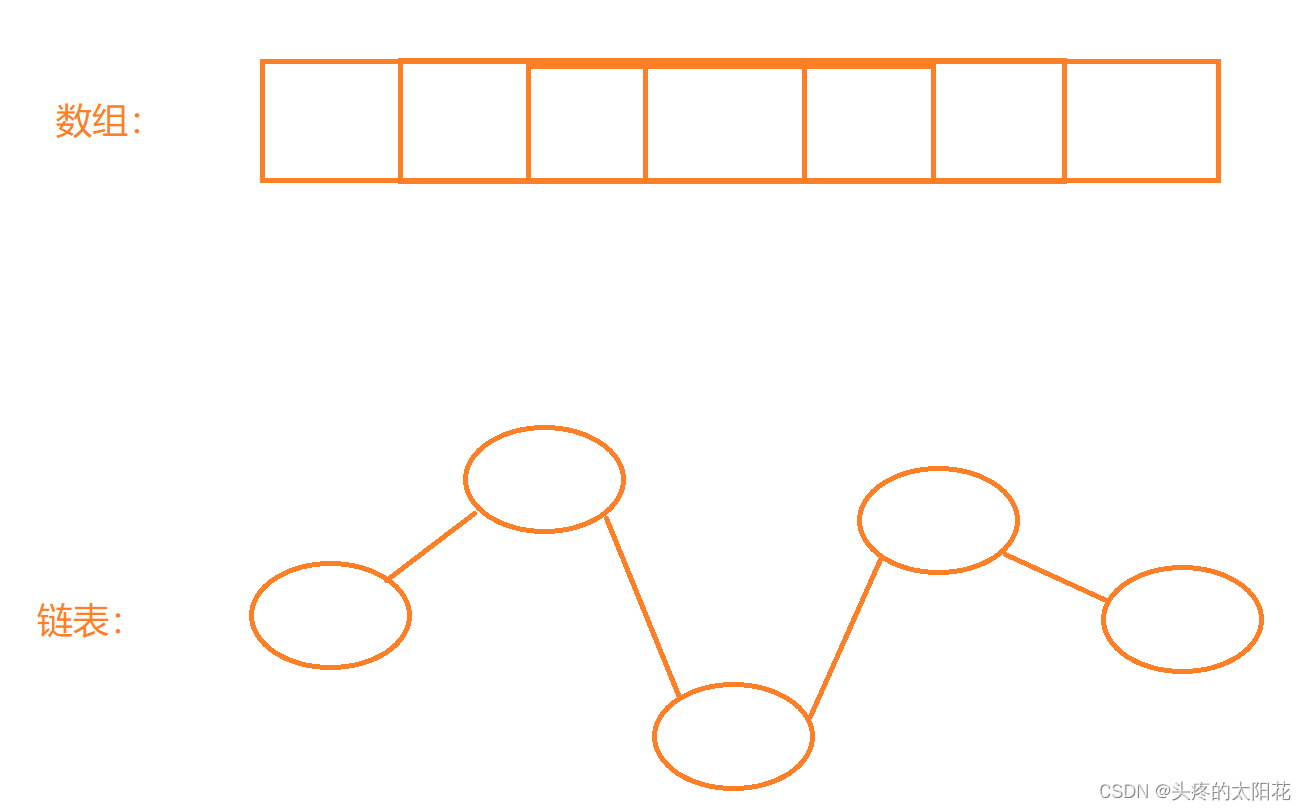
Ъ§ОнНсЙЙ:ЪЧЯрЛЅжЎМфДцдквЛжжЛђепЖржжЬиЖЈЙиЯЕЕФЪ§ОндЊЫиЕФМЏКЯ
ЮвУЧПЩвдЭЈЙ§етжжЬиЪтЕФЙиЯЕЖдвЛзщЪ§ОнНјааПьЫйЕФдіМг,ЩОГ§,аоИФЁЃ
ЪЧВЛЪЧИаОѕетаДЙІФмдкЮвУЧвдЧАбЇЙ§ЕФФГИіЪ§ОнРраЭКмЯрЫЦ?
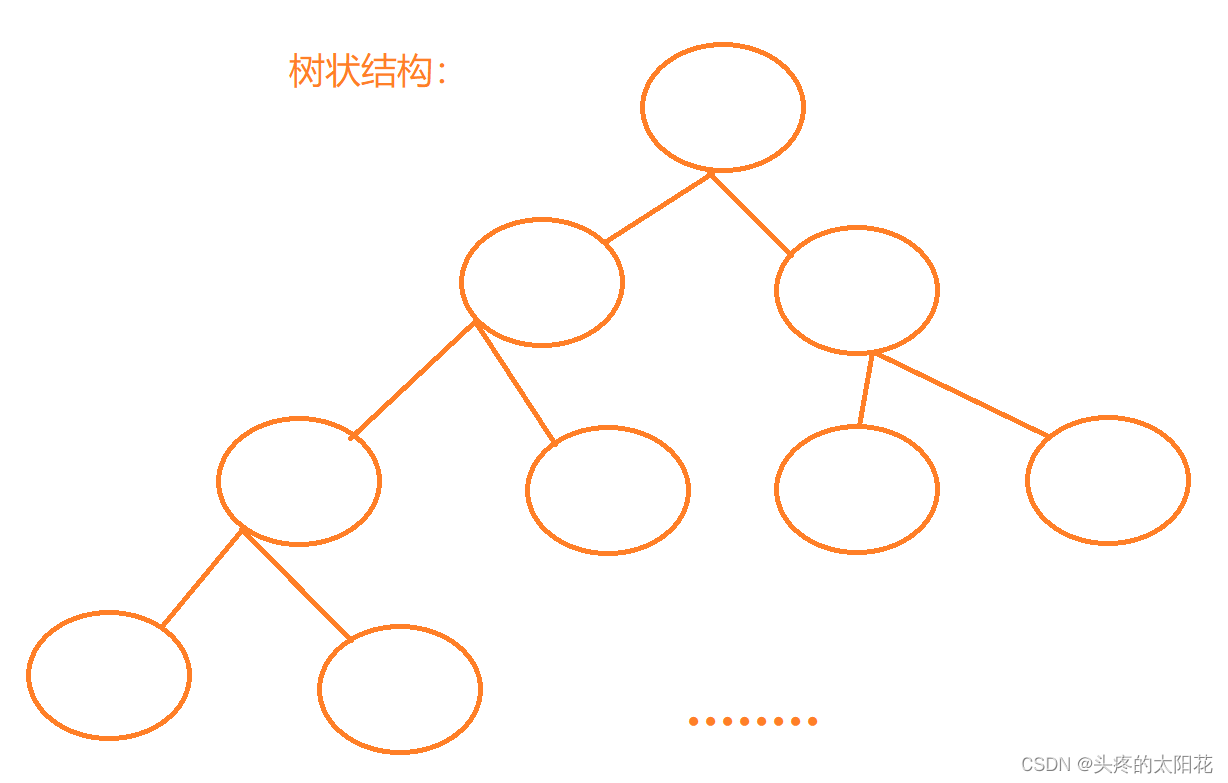
УЛДэ,ЦфЪЕЮвУЧдкКмОУвдЧАОЭНгДЅЙ§вЛжжзюМђЕЅЕФЪ§ОнНсЙЙ------Ъ§зщ,Ъ§зщжаЕФУПвЛИідЊЫиЖМЪЧгаЙиСЊЕФ,ЮвУЧПЩвдЭЈЙ§ЯТБъШЅЯђЪ§зщжаЕФШЮвтЮЛжУаДШыЪ§Он,вВПЩвдДгЪ§зщжаЖСШЁШЮвтвЛИіЯТБъЕФЪ§ОнЁЃ
Ъ§ОнНсЙЙЕФЗжРр
Ъ§ОнНсЙЙЗжЮЊетМИжжРраЭ:

зЂвт:дкCгябджаЪ§ОнНсЙЙЕФЖдгІЗНЪНЪЧЭЈЙ§жИеыРДЪЕЯжЕФЁЃ
Ъ§ОнНсЙЙгыЫуЗЈ
ЭЌбљФУХытПзіР§зг:
ЮвУЧгаСЫХытПЕФВФСЯКЭЙЄОп(Ъ§ОнНсЙЙ),ЕЋЪЧШчЙћЮвУЧУЛгаСщЧЩЕФММЪѕ(ЫуЗЈ),ФЧУДЮвУЧЛЙЪЧКмФбзіГігХауЕФзїЦЗ
Ъ§ОнНсЙЙКЭЫуЗЈЕФЙиЯЕ:
дкЯжЪЕжаУцЖдЕФДѓЖрЪ§ЮЪЬтЖМашвЊЪ§ОнНсЙЙКЭЫуЗЈЙВЭЌРДНтОі,
ЮвУЧРћгУИпаЇЕФЫуЗЈРДНтОіЮЪЬт,ЕЋЪЧИпаЇЕФЫуЗЈгжвРРЕгкЬиЪтЕФЪ§ОнНсЙЙВХФмзїгУЁЃ
ЫуЗЈЕФаЇТЪ:
ЮвУЧРћгУИпаЇЕФЫуЗЈРДЬсИпЮвУЧДњТыЕФаЇТЪ,ЖјЮвУЧгждѕбљШЅХаЖЯвЛИіЫуЗЈЪЧЗёИпаЇФи?
ЮвУЧРћгУЪБМфИДдгЖШКЭПеМфИДдгЖШШЅКтСПвЛИіДњТыЕФадФм,ИДдгЖШдНЕЭЕФДњТыгЕгадНИпЕФаЇТЪЁЃ
ЪБМфИДдгЖШ
ЪБМфИДдгЖШЕФИХФю
ЪБМфИДдгЖШжївЊКтСПвЛИіЫуЗЈЕФГЬађПьТ§ЁЃетИіПьТ§ВЛЪЧЮвУЧЦНЪБРэНтЕФвЛИіГЬађдЫааСЫЖрГЄЪБМф,етЪЧВЛзМШЗЕФЗНЗЈ------етИіЪБМфЛсгЩгкВЛЭЌЕФдЫааЛЗОГВњЩњВЛЭЌЕФдЫааЪБМфЁЃ
ВЛЭЌЕФЛЗОГАќРЈ:гВМўВЛЭЌ,ЪфШыЕФЪ§ОнВЛЭЌЕШЁЃ
вђЮЊвЛИіЫуЗЈЫљЛЈЗбЕФЪБМфгыЦфжагяОфжДааДЮЪ§е§е§БШ,ЫљвдЮвУЧПЩвдгУЫуЗЈжагяОфЕФЛљБОВйзїДЮЪ§РДзїЮЊЫуЗЈЕФЪБМфИДдгЖШ,
дкМЦЫуЛњПЦбЇжа:ЫуЗЈЕФЪБМфИДдгЖШЪЧвЛИіКЏЪ§(Ъ§бЇРяУцЕФКЏЪ§)ЁЃЛљБОВйзїдЫааДЮЪ§ = F(N)етЪЧвЛИівдNЮЊЮДжЊЪ§ЕФКЏЪ§ЁЃ
ДѓOЕФНЅНјБэЪО
етЪЧвЛжжИДдгЖШЕФБэЪОЗНЗЈ,ЮвУЧМЦЫуЪБМфИДдгЖШЪБ,ЮвУЧЦфЪЕВЂВЛвЛЖЈвЊМЦЫуОЋШЗЕФжДааДЮЪ§,ЖјжЛашвЊДѓИХжДааДЮЪ§ ЁЃ
ДѓOЗћКХ(Big O notation):ЪЧгУгкУшЪіКЏЪ§НЅНјааЮЊЕФЪ§бЇЗћКХЁЃ
вЛАугУO()РДБэЪОИДдгЖШР§Шч:O(1)ЁЂO(N)ЁЂO(N^2)ЕШ
ЮЊЪВУДПЩвдНЅНјБэЪО
ЮвУЧРДПДЯТУцетИіБэИё
| ВЮЪ§N \ жДааДЮЪ§ | F(1) | F(N) | F(N^2) | F(N^2+N) |
|---|---|---|---|---|
| 10 | ЮогАЯь | 10 | 100 | 110 |
| 100 | ЮогАЯь | 100 | 10000 | 10100 |
| 1000 | ЮогАЯь | 1000 | 1000000 | 1001000 |
| 10000 | ЮогАЯь | 10000 | 100000000 | 100010000 |
ЮвУЧПЩвдПДГіЕБЮвУЧЕФВЮЪ§дНДѓЪБ,ЕЭНзгАЯьЕФВйзїДЮЪ§дкШЋВПДЮЪ§жаеМБШдНРДдНЕЭЁЃ
ЮЊСЫПЩвдЗНБуЕиБэЪОГіЪБМфИДдгЖШ,ЮвУЧОЭВЩгУНЅНјБэЪОЗНЗЈ(НЋВйзїДЮЪ§гыЮДжЊЪ§ЕФЙиЯЕДѓжТБэЪОГіРД)ЁЃ
вЛАуЮвУЧВЩгУДѓOНзНЅНјБэЪО,ЯТУцЪЧЭЦЕМЗНЗЈ:
ДѓOНзЭЦЕМЗНЗЈ
- гУГЃЪ§1ШЁДњдЫааЪБМфжаЕФЫљгаМгЗЈГЃЪ§ЁЃ
Р§зг:
void Func(int N) { int i = 0; for(i = 0; i< 10;i++) { printf("%d",i); } }
ЮвУЧРДМЦЫуетИіГЬађЕФЪБМфИДдгЖШВЂЧвЪЙгУДѓOБэЪОЗЂНЋИДдгЖШБэЪОГіРД:
ЗжЮі:
етИіГЬађЕФжДааДЮЪ§КЭБфСПNУЛгаШЮКЮЙиЯЕ,МДЮоТлЮвУЧДЋВЮЙ§ШЅЕФжЕЪЧЖрЩй,ЮвУЧЕФЛљДЁВйзїжДааДЮЪ§ЖМЪЧвЛЖЈЕФ,етбљЕФДњТыЪБМфИДдгЖШЪЧзюЕЭЕФ,ЪБМфИДдгЖШ = ГЃЪ§,ЖјЮвУЧЕФЕквЛЬѕЭЦЕМЗНЗЈОЭЪЧ:гУГЃЪ§1ШЁДњдЫааЪБМфжаЕФЫљгаМгЗЈГЃЪ§ЁЃ
ЫљвдЮвУЧетИіГЬађЕФЪБМфИДдгЖШЪЧ**O(1)**
-
дкаоИФКѓЕФдЫааДЮЪ§КЏЪ§жа,жЛБЃСєзюИпНзЯюЁЃ
Р§зг1:
void Func(int N) { int i = 0; for(i = 0; i< 10;i++) { printf("%d",i); } while(N--) { i++; } }
ЗжЮі:
етЖЮДњТыЕФжДааДЮЪ§гыВЮЪ§NгаЙиЯЕ,ЪБМфИДдгЖШ = N+ГЃЪ§,ИљОнЮвУЧЕФЕкЖўИіЭЦЕМЗНЪН:ЮвУЧБЃСєзюИпНзЯюЪ§НсЙћЪЧO(N)ЁЃ
ЫљвдетвЛИіЫуЗЈЕФЪБМфИДдгЖШЪЧO(N)ЁЃ
ШчЙћЪЧетбљЕФДњТыФи?
Р§зг2:
void Func1(int N)
{
int count = 0;
int num = N*N;
//бЛЗ1:
while(num--)
{
++count;
}
//бЛЗ2:
for (int k = 0; k < N ; ++ k)
{
++count;
}
int M = 10;
printf("%d",count);
}
ЗжЮі:
ЯждкЮвУЧжЊЕР:дкМЦЫуЪБМфИДдгЖШЕФЪБКђ,жЛашвЊШЅЙизЂКЭВЮЪ§гаЙиЕФВйзїЁЃ
дкетЖЮДњТыжа,ВЮЪ§ЪЧN,бЛЗ1жаЛсбЛЗN*NДЮ,бЛЗ2ЛсбЛЗNДЮЁЃ
ЫљвдИУЫуЗЈжажДааЕФЛљДЁВйзїДЮЪ§=N*N+N,ВЛЙ§гЩгкЮвУЧжЛЛсБЃСєзюИпНз
ЫљвдИУЫуЗЈЕФЪБМфИДдгЖШЪЧO(N)
- ШчЙћзюИпНзЯюДцдкЧвВЛЪЧ1,дђШЅГ§гыетИіЯюФПЯрГЫЕФГЃЪ§ЁЃЕУЕНЕФНсЙћОЭЪЧДѓOНз
Р§зг:
//МЦЫуИУДњТыЖЮжа++countгяОфжДааСЫЖрЩйДЮ?
void Func1(int N)
{
int count = 0;
for (int i = 0; i < 2*N; ++i)
{
for (int j = 0; j < N; ++j)
{
++count;
}
}
for (int k = 0; k < 2 * N; ++k)
{
++count;
}
int M = 10;
while (M--)
{
++count;
}
printf("%d\n", count);
return 0;
}
ЗжЮі:
ЯждкЮвУЧжЊЕРжЛашвЊШЅМЦЫузюИпНзЯю,етИіР§згжазюИпНзЯюЪЧ
2*N*N,дкЕкШ§ЬѕЙцдђжа,ЮвУЧЛсНЋзюИпНзЯюЕФЯЕЪ§БфЮЊ1,ЪЃЯТЕФОЭЪЧИУЫуЗЈЕФЪБМфИДдгЖШЁЃ
ЫљвдИУР§ЕФЪБМфИДдгЖШЪЧO(N^2);
ЪБМфИДдгЖШЕФМЦЫу
ЩЯУцЮвУЧдкНщЩмДѓOНЅНјБэЪОЗЈЕФЪБКђвбОбЇЛсСЫМђЕЅЕФЪБМфИДдгЖШМЦЫуСЫ,ЮЊСЫПЩвдЖдЪБМфИДдгЖШгаИќЧхЮњЕФШЯЪЖ,етРяОйСЫМИИіНЯЮЊИДдгЕФР§зг:
Р§зг1:
void Func3(int N, int M)
{
int count = 0;
for (int k = 0; k < M; ++k)
{
++count;
}
for (int k = 0; k < N; ++k)
{
++count;
}
printf("%d\n", count);
}
етЪЧгаСНИіВЮЪ§ЕФКЏЪ§,ИУЫуЗЈЕФЛљБОВйзїжДааДЮЪ§ЛсЫцMЁЂNСНИіжЕЕФБфЛЏЖјБфЛЏ,ЮвУЧХХГ§СЫЖдЪБМфИДдгЖШгАЯьВЛДѓЕФДЮЪ§,ЫљвдИУЫуЗЈЕФЪБМфИДдгЖШЪЧO(M+N)
зЂвт:ШчЙћВЮЪ§жаM>>N,ФЧУДИУЫуЗЈЕФЪБМфИДдгЖШПЩвдБэЪОЮЊO(M);
ШчЙћВЮЪ§жаN>>M,ФЧУДИУЫуЗЈЕФЪБМфИДдгЖШПЩвдБэЪОЮЊO(N);
ШчЙћВЮЪ§жаNдМЕШгкM,ФЧУДИУЫуЗЈЕФЪБМфИДдгЖШПЩвдБэЪОЮЊO(M)ЛђепO(N);
двђ:ЮвУЧдкМЦЫуЪБМфИДдгЖШЕФЪБКђ,ВЛашвЊМЦЫуГіЪЎЗжОЋШЗЕФЪ§,ЮвУЧПЩвдХХГ§ЕєЖдНсЙћгАЯьВЛДѓЕФВйзїЁЃ
ЪБМфИДдгЖШЕФБэЪО:дкРЈКХРяУцЕФзжЗћВЛвЛЖЈЪЧN,вВПЩвдЪЧO(M)ЁЃжЛашвЊТњзуИУзжЗћЪЧЮДжЊЪ§МДПЩЁЃ
Р§зг2:
// МЦЫуstrchrЕФЪБМфИДдгЖШ
const char * strchr ( const char * str, int character );
ИУКЏЪ§ЛсдквЛИізжЗћДЎжавРДЮбАев
characterзжЗћ,ШчЙћевЕНОЭОЭЗЕЛиИУДІЕФЕижЗ,ШчЙћећИізжЗћДЎжаЖМУЛгаевЕН,ОЭЛсЗЕЛиПежИеыЁЃ
зЂвт:
гааЉЫуЗЈЕФЪБМфИДдгЖШДцдкзюКУЁЂЦНОљКЭзюЛЕЧщПі:
- зюЛЕЧщПі:ШЮвтЪфШыЙцФЃЕФзюДѓдЫааДЮЪ§(ЩЯНч) ЁЃ
- зюКУЧщПі:ШЮвтЪфШыЙцФЃЕФзюаЁдЫааДЮЪ§(ЯТНч) ЁЃ
- ЦфЫћЁЃ

**дкЪЕМЪжавЛАуЧщПіЙизЂЕФЪЧЫуЗЈЕФзюЛЕдЫааЧщПі,ЫљвдЪ§зщжаЫбЫїЪ§ОнЪБМфИДдгЖШЮЊ**O(N)
ЫљвдИУР§згЕФЪБМфИДдгЖШЪЧO(N)ЁЃ
Р§зг3:
//етЪЧвЛИіУАХнХХађ,ЫќЕФЪБМфИДдгЖШЪЧЖрЩйФи?
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i - 1] > a[i])
{
Swap(&a[i - 1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}
зЂвт:ВЂВЛЪЧДцдкСНВубЛЗОЭЫЕУїЪБМфИДдгЖШЪЧO(N^2)

УАХнХХађЕФПеМфИДдгЖШМЦЫу:ЮвУЧАДеезюЛЕЕФЧщПіДђЫу:F(N) = (N-1)*N/2,НЅНјБэЪОЗЈЪЧO(N^2)
Р§зг4:ЖдвЛИівбОгаађЕФЪ§зщНјааЖўЗжВщев:
//ЖўЗжВщевЕФЪБМфИДдгЖШ
int BinarySearch(int* a, int n, int x)
{
assert(a);
int begin = 0;
int end = n;
while (begin < end)
{
int mid = begin + ((end - begin) >> 1);
if (a[mid] < x)
{
begin = mid + 1;
}
else if (a[mid] > x)
{
end = mid;
}
else
{
return mid;
}
}
return -1;
}
ЮвУЧМЦЫуетИіЫуЗЈЕФЪБМфИДдгЖШ,вВЪЧвдвЛжжзюЛЕЕФЧщПіРДМЦЫуЕФ------дкзюКѓВХевЕНЮвУЧашвЊЕФдЊЫи,ЛђепИУЪ§зщжаУЛгаЮвУЧашвЊевЕФдЊЫиЁЃ

ЫљвдИУЫуЗЈЕФЪБМфИДдгЖШЮЊO(logN)
зЂвт:ШчЙћЪБМфИДдгЖШЮЊ
O(log 2 N),ФЧУДЮвУЧПЩвдМђаДЮЊO(logN)ЁЃ
Р§зг4:вЛИіЕнЙщГЬађЕФЪБМфИДдгЖШМЦЫу
long long Fac(size_t N)
{
if(0 == N)
{
return 1;
}
return Fac(N-1)*N;
}
ИУЫуЗЈвЛЙВОЙ§СЫNДЮКЏЪ§ЕїгУ,УПвЛДЮКЏЪ§ЕїгУЖМЫувдДЫЛљБОВйзї

ЕнЙщЫуЗЈЪБМфИДдгЖШМЦЫу:
-
ШчЙћУПДЮЕїгУЕФКЏЪ§ЕФЪБМфИДдгЖШЪЧO(1),ФЧУДећИіЫуЗЈЕФЪБМфИДдгЖШОЭПДЫќЕФЕнЙщДЮЪ§ЁЃ
-
ШчЙћУПДЮЕїгУЕФКЏЪ§ЕФЪБМфИДдгЖШВЛЪЧO(1),ФЧУДећИіЫуЗЈЕФЪБМфИДдгЖШЪЧУПДЮЕнЙщжаВйзїДЮЪ§ЕФРлМгКЭЁЃ
Р§Шч
long long Func(int n,int count) { int i = 0; for( i = 0; i< n;i++) { count++; } if(0 == n) { return 0; } return Func(n-1,count); }етИіЫуЗЈжаУПвЛДЮЕїгУЕФКЏЪ§ЪБМфИДдгЖШЖМЪЧO(N),ФЧУДећИіЫуЗЈЕФЪБМфИДдгЖШОЭЪЧO(N^2);
Р§зг5:МЦЫуьГВЈФЧЦѕЪ§СаЪ§СаЫуЗЈЕФЪБМфИДдгЖШ
long long Fib(size_t N)
{
if(N < 3)
{
return 1;
}
return Fib(N-1) + Fib(N-2);
}
етИіР§згвВЪЧЕнЙщКЏЪ§,УПвЛДЮЕїгУЪБЖМжЛЪЧНјааСЫГЃЪ§ДЮВйзї,ЫљвдЮвУЧдкМЦЫуЪБМфИДдгЖШЕФЪБКђжЛашвЊМЦЫуИУЫуЗЈЕнЙщЕФзмДЮЪ§:
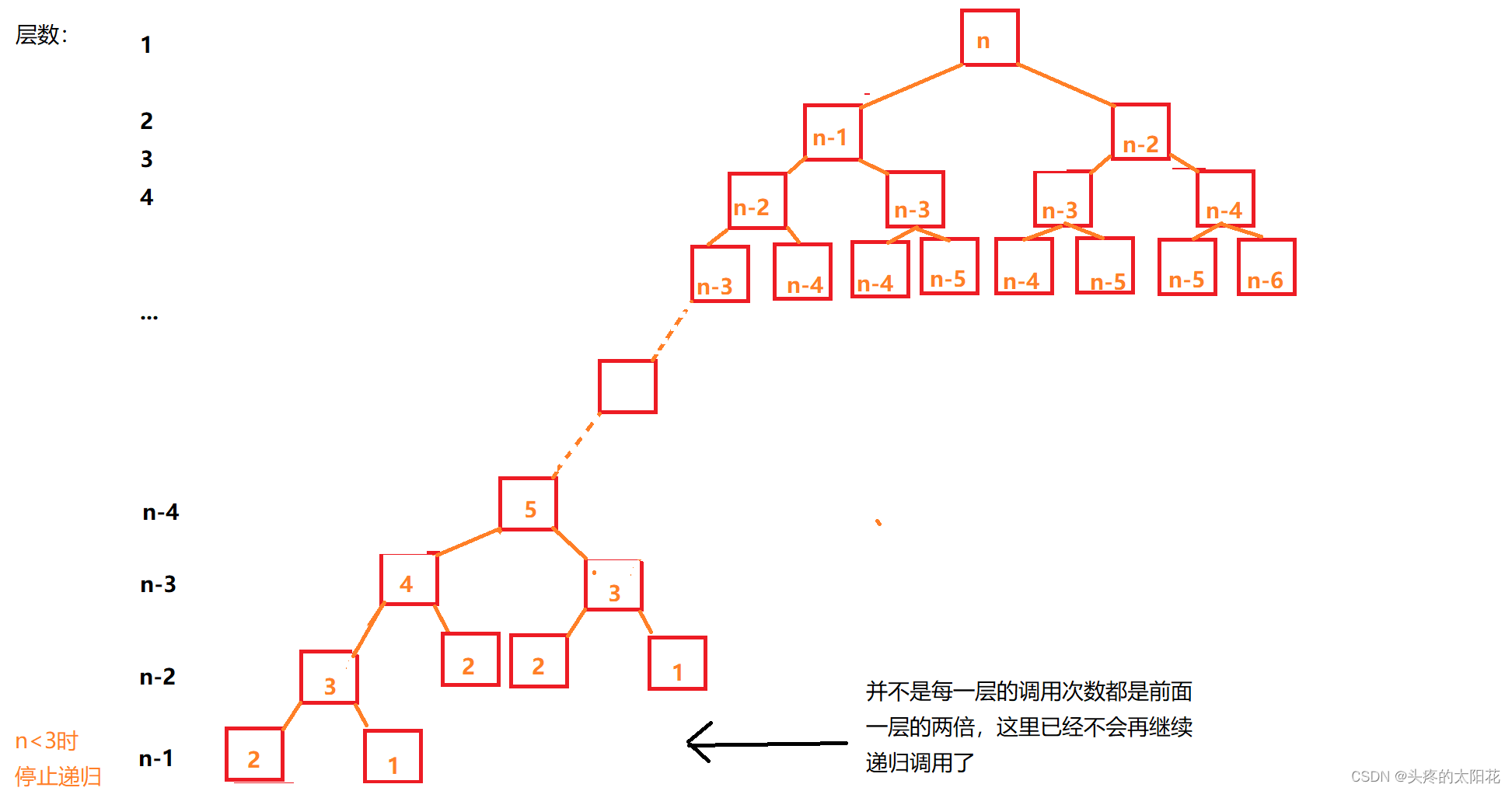
етгывЛИіЕШБШЪ§СаЯрЫЦ

гЩгкЮвУЧВЛашвЊМЦЫуГіКмОЋШЗЕФжДааДЮЪ§,ЫљвдЮвУЧШдШЛПЩвдНЋетИіЕШБШЪ§СаЧѓКЭ,ЫљЕУЕФКЭзїЮЊИУЫуЗЈЕФЪБМфИДдгЖШ:
F(N) = 1 + 2 + 4 +Ё+2^(N-1)
НЅНјБэЪОЗЈЕФЪБМфИДдгЖШЮЊ:O(2^N)
ШчЙћвЛИіЫуЗЈЕФЪБМфИДдгЖШЪЧO(2^N),ФЧУДетИіЫуЗЈЪЧдуИтЕФ,вђЮЊЕБЮвУЧЕФЮДжЊЪ§НіНіЮЊ30ЪБ,ГЬађОЭЛсНјаа1073741824ДЮВйзїЁЃЕБЮДжЊЪ§КмДѓЪБ,ГЬађЛсБМРЃЁЃ
ПеМфИДдгЖШ
ЮвУЧКтСПвЛИіЫуЗЈЕФаЇТЪЕФЪБКђЛЙашвЊПППеМфаЇТЪ
ПеМфИДдгЖШЕФИХФю
-
ПеМфИДдгЖШвВЪЧвЛИіЪ§бЇКЏЪ§БэДяЪН,ЪЧЖдвЛИіЫуЗЈдкдЫааЙ§ГЬжаСйЪБеМгУПеМфДѓаЁЕФСПЖШ
-
ПеМфИДдгЖШВЛЪЧжИГЬађеМгУСЫЖрЩйзжНкЕФПеМф,ПеМфИДдгЖШМЦЫуЕФЪЧБфСПЕФИіЪ§
ПеМфИДдгЖШжївЊЭЈЙ§КЏЪ§дйдЫааЪБЯдЪОЩъЧыЕФЖюЭтПеМфРДШЗЖЈЕФ(КЏЪ§дЫааЪБЕФеМПеМфвбОдйБрвыЦкМфОЭвбОШЗЖЈКУСЫ)
ПеМфИДдгЖШвВЪЧгУДѓOБэЪОЗЈРДБэЪО
ПеМфИДдгЖШЕФМЦЫу
ЭЌбљетРяОйГіМИИіР§згРДШУЮвУЧШЅЩюШыРэНтПеМфИДдгЖШ:
Р§зг1:УАХнХХађЕФПеМфИДдгЖШ
void BubbleSort(int* a, int n)
{
assert(a);
for (size_t end = n; end > 0; --end)
{
int exchange = 0;
for (size_t i = 1; i < end; ++i)
{
if (a[i - 1] > a[i])
{
Swap(&a[i - 1], &a[i]);
exchange = 1;
}
}
if (exchange == 0)
break;
}
}
етИіХХађЫуЗЈзюЖрПЊБйСЫШ§ИіаТЕФПеМф
size_t end
int exchange
size_t iЮЈвЛгавЩЛѓЕФПЩФмЪЧБфСПexchange:вђЮЊетЪЧвЛИіОжВПБфСП,дйУПДЮДІРэзїгУгыКѓ,етИіПеМфОЭЯњЛйСЫ,ЕЋЪЧЕкЖўДЮНјШыбЛЗКѓгаашвЊПЊБйвЛИіПеМф,УПДЮПЊБйПеМфЖМдйФкДцжаЕФЭЌвЛИіЮЛжУ,ЫљвдЮвУЧМЦЫуЖюЭтЕФПеМфЕФЪБКђжЛашНЋИУБфСПЪгЮЊвЛИіЖюЭтПеМф
ШчЯТЭМ:УПвЛДЮбЛЗНсЪј,БфСПiЕФПеМфЖМЛсБЛЯњЛй,УПвЛДЮНјШыбЛЗ,ОЭЛсЮЊБфСПiПЊБйвЛИіПеМф,ЕЋЪЧУПДЮПЊБйЕФЦфЪЕЪЧЭЌвЛПщПеМф:
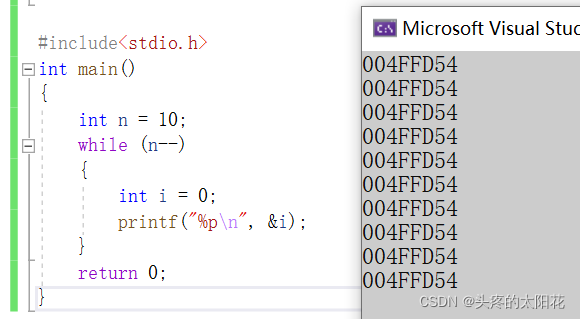
ПеМфЪ§СПВЛЛсЫцВЮЪ§ЕФБфЛЏЖјБфЛЏ,ЫљвдИУЫуЗЈЕФПеМфИДдгЖШЪЧO(1)
ФФжжЧщПіЯТЕФПеМфИДдгЖШЪЧO(N)Фи?
ЯТУцЪЧМИИіЪЎЗжОЕфЕФР§зг:
Р§зг2:ЯћЪЇЕФЪ§зж
етРяЮвУЧгаleetcodeЩЯУцЕФвЛЕРЬтРДНтЪЭ:

етЕРЬтЮвУЧВЩгУвЛжжгГЩфЕФЗНЗЈ:
ЪзЯШЖЏЬЌПЊБйвЛИіЪ§зщ:
int* arr = (int*)malloc(sizeof(int)*(numsSize+1));

етРяЮвУЧЖюЭтПЊБйЕФПеМфИіЪ§гЩВЮЪ§ДЋЕнЕНЙ§РДЕФЪ§зщЕФдЊЫиИіЪ§РДОіЖЈ
ВЮЪ§Ъ§зщдЊЫиИіЪ§ ДДНЈЕФаТЪ§зщдЊЫиИіЪ§ 20 21 50 51 10000 10001 N N+1
ЫљвдетИіЫуЗЈЕФПеМфИДдгЖШЪЧO(N)
ШчЙћЮвУЧНЋЖЏЬЌПЊБйПеМфЕФДњТыИФЮЊ:
int* arr = (int*)malloc(sizeof(int)*10000)
етРяЮвУЧДДНЈСЫвЛИіга10000ИіintРраЭ дЊЫиЕФЖЏЬЌЪ§зщ,гЩгкетИіПЊБйГіРДЕФПеМфЕФДѓаЁВЛЛсвђЮЊВЮЪ§ЕФИФБфЖјИФБф,УПвЛДЮЖМЪЧВЛБфЕФДѓаЁ,ЫљвдДЫЪБИУЫуЗЈЕФПеМфИДдгЖШЮЊO(1)ЁЃ
Р§зг3:ьГВЈФЧЦѕЪ§СаЕФПеМфИДдгЖШ
//етЪЧМЦЫуьГВЈФЧЦѕЪ§СаЕФСэвЛжжЪЕЯжЗНЗЈ
//РДМЦЫуИУЫуЗЈЕФПеМфИДдгЖШ
long long* Fibonacci(size_t n)
{
if (n == 0)
return NULL;
long long* fibArray = (long long*)malloc((n + 1) * sizeof(long long));
fibArray[0] = 0;
fibArray[1] = 1;
for (int i = 2; i <= n; ++i)
{
fibArray[i] = fibArray[i - 1] + fibArray[i - 2];
}
return fibArray;
}
ЗжЮі:ИУЫуЗЈвВЪЧдйЖЏЬЌПЊБйПеМфЕФЪБКђПЊБйГіСЫ(n+1)ИіПеМф,гЩгкЮвУЧЕФИДдгЖШБэЪОЗЈЪЧМЦЫуЕФДѓИХжЕ,ВЛашвЊЪЎЗжОЋШЗЁЃ
ИУЫуЗЈЕФПеМфИДдгЖШЪЧO(N)ЁЃ
Р§зг4:ЕнЙщКЏЪ§ЕФПеМфИДдгЖШ
// МЦЫуНзГЫЕнЙщFacЕФПеМфИДдгЖШ?
long long Fac(size_t N)
{
if (N == 0)
return 1;
return Fac(N - 1) * N;
}
ЖдгкЕнЙщКЏЪ§,ПеМфИДдгЖШВЛЛсЪЧO(1)
ЗжЮі:
ЕнЙщКЏЪ§УПвЛДЮЕїгУЖМЛсДДНЈКЏЪ§еЛжЁ
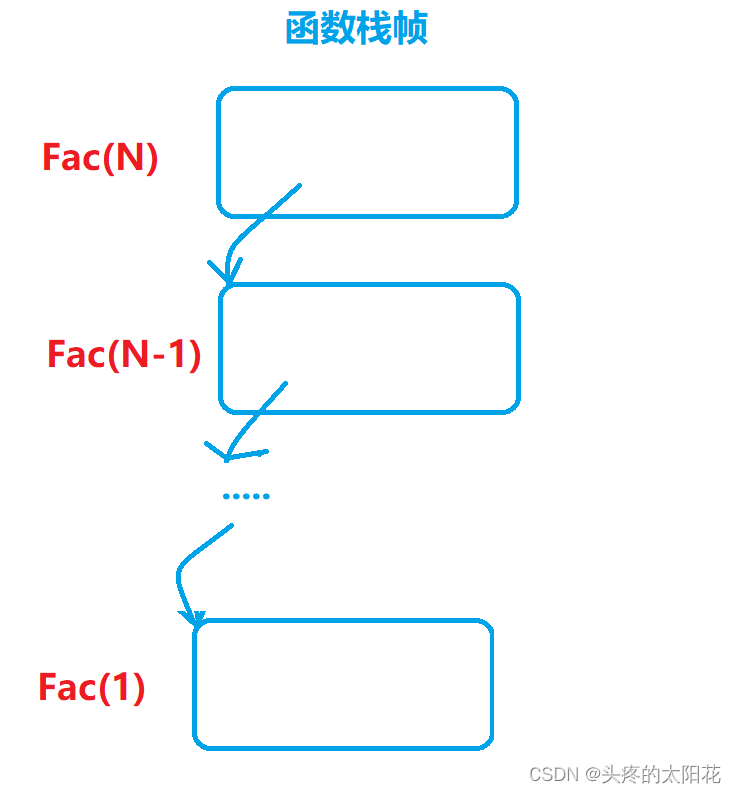
етРяЕїгУСЫNДЫКЏЪ§,ВЂЧвУПДЮКЏЪ§ЖМДДНЈСЫвЛИіБфСП,ЫљвдетРяЕФПеМфИДдгЖШЪЧO(N)
жиЕу:ЪБМфЪЧРлЛ§ЕФ,ЮоЗЈжиИДРћгУЕФ,ПеМфЪЧПЩвджиИДРћгУЕФ
Р§зг5:ьГВЈФЧЦѕЪ§СаЕФПеМфИДдгЖШ
етЪЧвЛИіьГВЈФЧЦѕЖюЪ§Са,МЦЫуЫќЕФПеМфИДдгЖШ:
long long Fib(size_t N)
{
if (N < 3)
return 1;
return Fib(N - 1) + Fib(N - 2);
}
ЪзЯШЮвУЧСЫНтетбљвЛИіИХФю:
ЕБвЛИіКЏЪ§дкЕїгУЕФЪБКђ,ЛсДДНЈИУКЏЪ§ЕФКЏЪ§еЛжЁ,ЕБетИіКЏЪ§ЕїгУНсЪјЕФЪБКђ,ЫќЫљЖдгІЕФКЏЪ§еЛжЁЛсЯњЛйЁЃ

ДгетРяПЩвдПДГі,СНДЮВЛЭЌЕФКЏЪ§ЕїгУжаДДНЈ СЫВЛЭЌЕФБфСПaКЭb,ЕЋЪЧa,bШДгаЯрЭЌЕФЕижЗ,жЄУїСЫСНДЮКЏЪ§ЕїгУВСЛЦНЁЕФКЏЪ§еЛжЁЪБЭЌвЛПщЁЃ
ЖдгкИеВХЕФьГВЈФЧЦѕЪ§СаЫуЗЈвВФмгУетИідРэНтЪЭГіРДЁЃ
ЗжЮі:
ЪзЯШЮвУЧРћгУвЛИізМШЗЕФЪ§жЕРДДњЬцВЮЪ§N,Р§ШчЮвУЧНЋВЮЪ§NИГЮЊ4,ЮвУЧ РДЙлВьИУЫуЗЈжаКЏЪ§еЛжЁЕФДДНЈКЭЯњЛй:
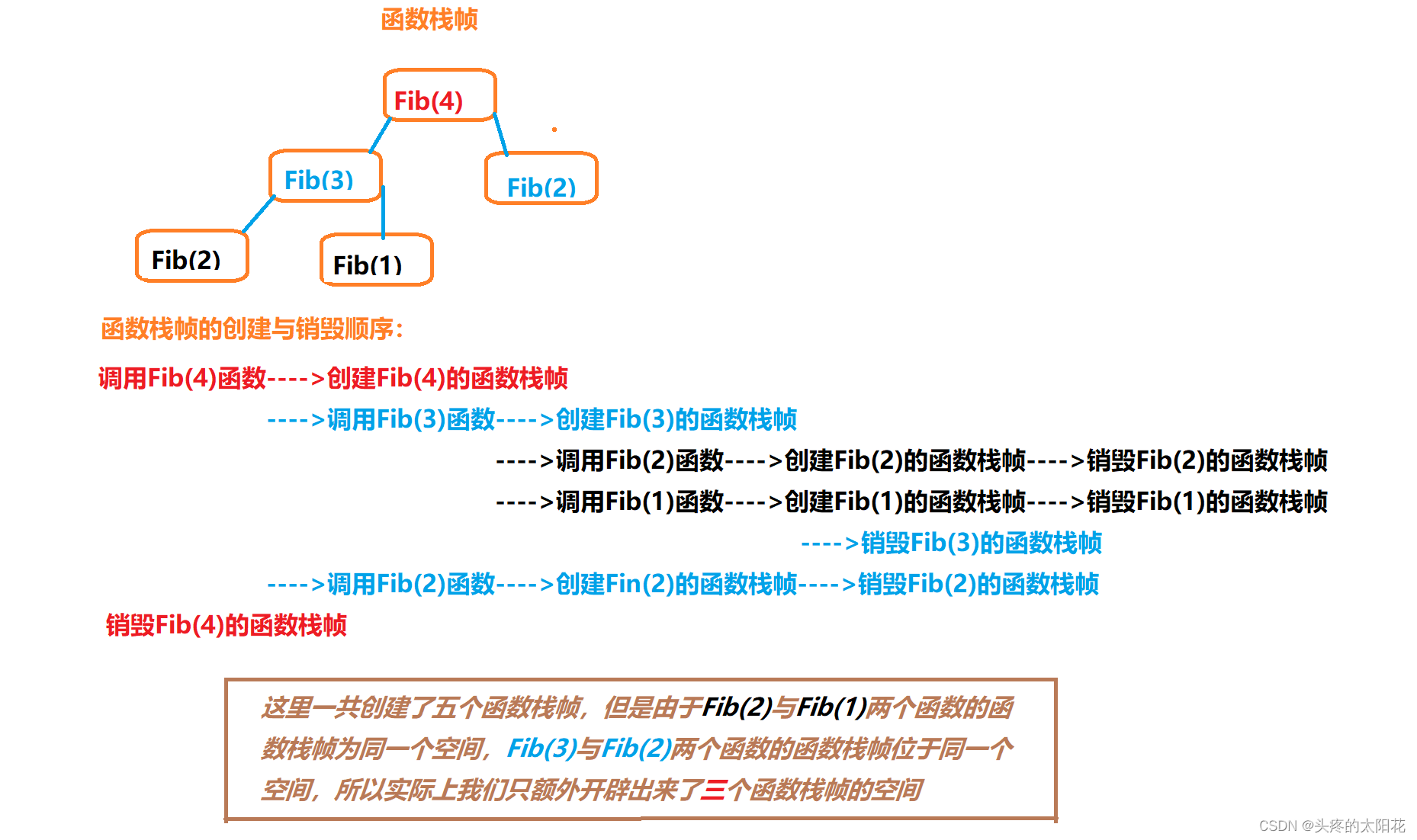
вдДЫ,ЮвУЧПЩвдХаЖЯГіИУЫуЗЈЛсЖюЭтДДНЈГіN-1ИіКЏЪ§еЛжЁ,РћгУДѓOНЅНјБэЪОЗЈ:ИУЫуЗЈЕФПеМфИДдгЖШЪЧ:O(N)
ЪБМфгыПеМфЕФШЁЩс
ШЫУЧжЎЫљвдЛЈДѓСІЦјШЅЦРЙРЫуЗЈЕФЪБМфИДдгЖШКЭПеМфИДдгЖШ, ЦфИљ
БОдвђЪЧМЦЫуЛњЕФдЫЫуЫйЖШКЭПеМфзЪдДЪЧгаЯоЕФ
ЮвУЧЖМЯывЊШЅевЕНвЛИіЪБМфИДдгЖШКЭПеМфИДдгЖШЖМКмЕЭЕФЗНЗЈШЅНтОіЮЪЬт,ЕЋЪЧДѓЖрЪ§ЪБКђ,етЪЧГЪЯжГігуКЭамеЦВЛПЩМцЕУЕФзДЬЌ,ЮвУЧВЛЕУВЛдкПеМфИДдгЖШКЭЪБМфИДдгЖШжЎМфНјааШЁЩс
дкМЦЫуЛњЗЂеЙЕФдчЦк,гЩгкМЦЫуЛњЕФШнСПКмаЁ,ЫљвдКмдквтПеМфИДдгЖШЁЃЕЋЪЧЯждкЕФМЦЫуЛњДЂДцШнСПвбОЪЎЗжИп,ЫљвдЮвУЧВЛашвЊдйЬиБ№ЙизЂПеМфИДдгЖШЁЃ
дкОјДѓЖрЪ§ЪБКђ,ЪБМфИДдгЖШБШПеМфИДдгЖШИќЮЊживЊвЛаЉ,ЮвУЧФўдИЖрЛЈвЛЕуФкДцПеМф,вВЯЃЭћЬсЩ§ГЬађЕФжДааЫйЖШЁЃ