索引是帮助MySQL高效获取数据的排好序的数据结构
- 索引的数据结构:
1.二叉树
通过一个简单的插入你可以看到,二叉树的插入会根据每个节点进行判断,每一个节点右边的数据一定是大于等于这个节点数据,而他的左边数据一定是小于这个节点的数据。
他的插入,删除,查找都是根据这个特性来的。
这里我们可以看到如果我们的数据是排序依次插入,就会是一条链表,这样查询的速度可以说是超级慢,所以二叉树不适合mysql的存储

2.红黑树
红黑树又叫做平衡二叉树,在二叉树的基础上进行了平衡的算法,他平衡的原理就依靠红和黑两个颜色的约束决定的
1.结点是红色或者黑色
2.根节点是黑色
3.所有叶子都是黑色
4.每个红色结点的两个子结点都是黑色。(从每个叶子到根的所有路径上不能有两个连续的红色结点)
5.从任一节结点到其每个叶子的所有路径都包含相同数目的黑色结点。
虽然红黑树做了平衡处理,但我们可以看到,如果我们的数据量特别大,达到千万,亿万级别的时候,红黑树的高度会特别的大,这样我们查询的时候其实跟链表差不多了
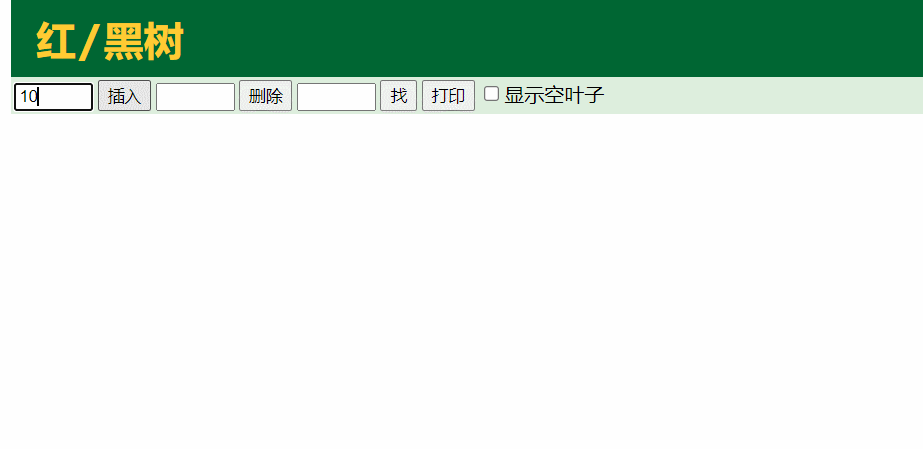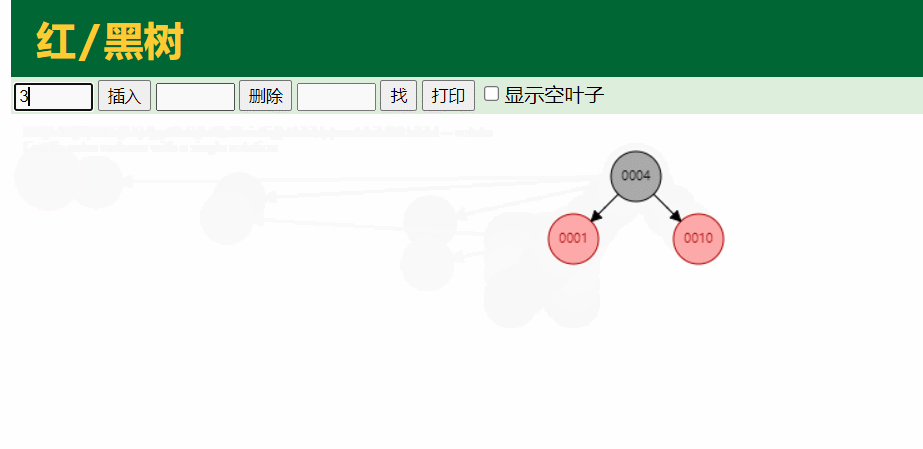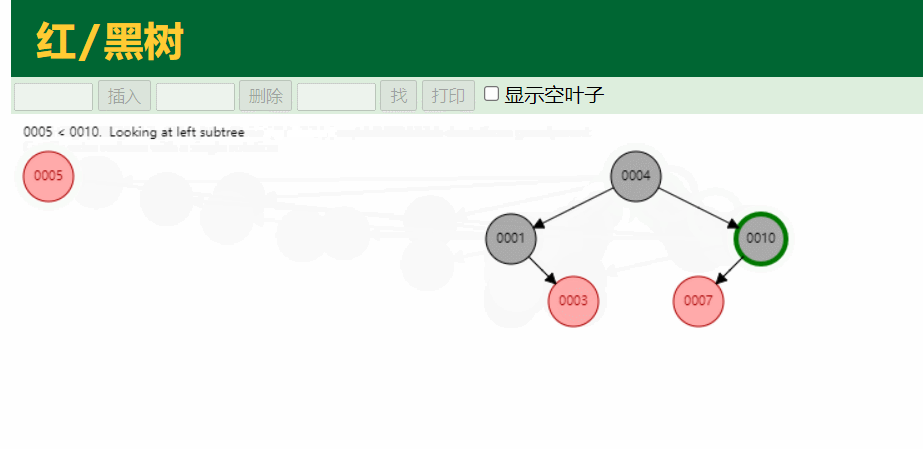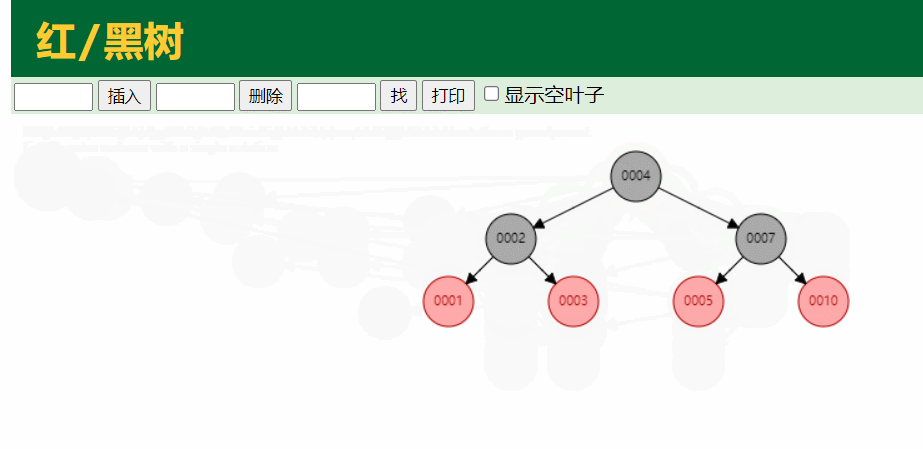
3.B-tree
通过B树的插入演示,B树的度就是每个结点存储的个数,当子节点存储满足了度,就会将处于中间的那个数据往父节点存储,有以下几个特点:
叶节点具有相同的深度
叶节点的指针为空
节点中的数据key从左到右递增排列
对于B树而言,相同的一个节点可以存储多个数据,这样的话,它的高度就会得到控制。但是mysql也没有用到B树作为存储结构,我们可以看到B树他的每一个节点都存有数据,而mysql底层存储使用的是B+树,则是把这个数据都放在了叶子结点
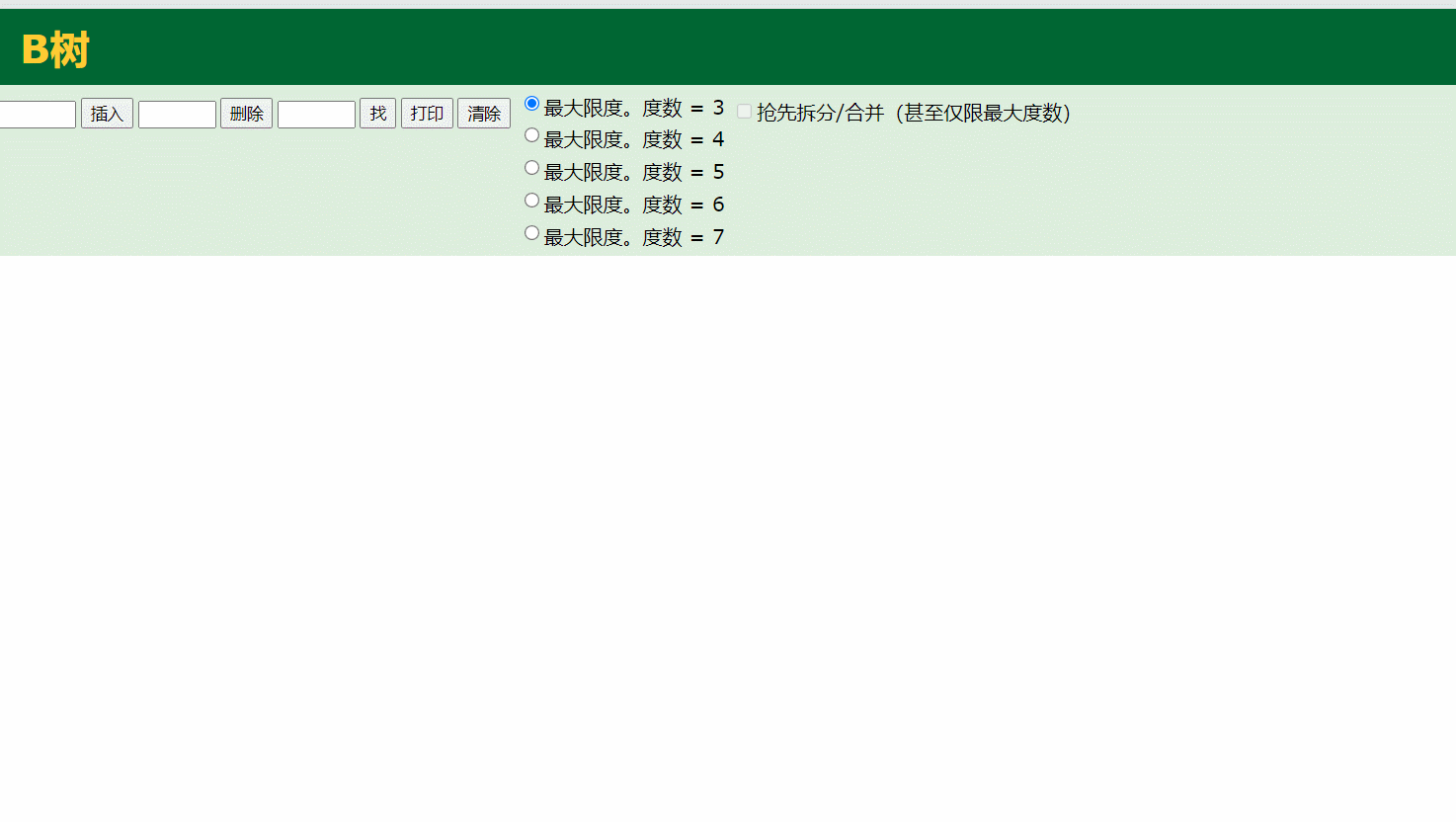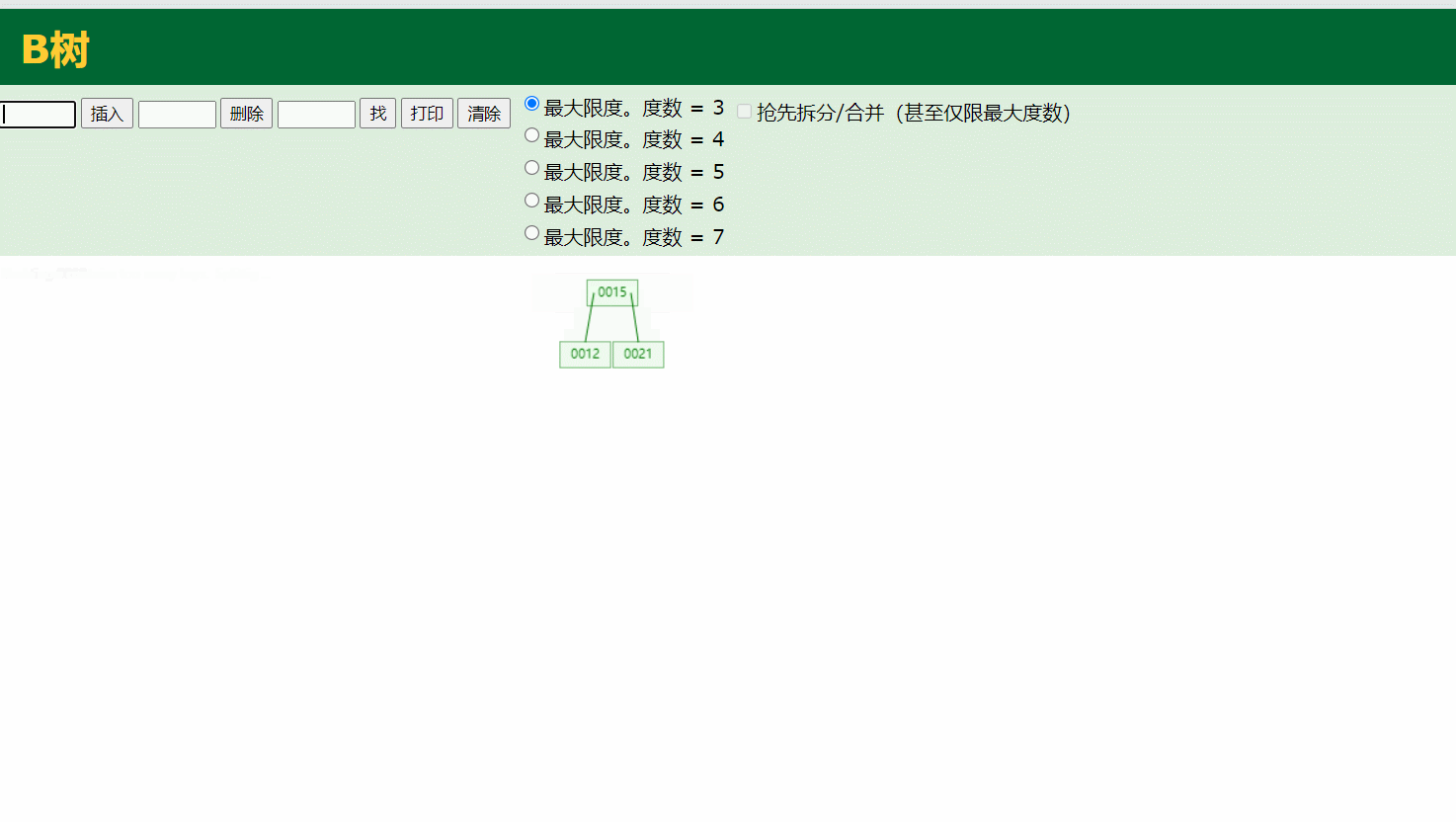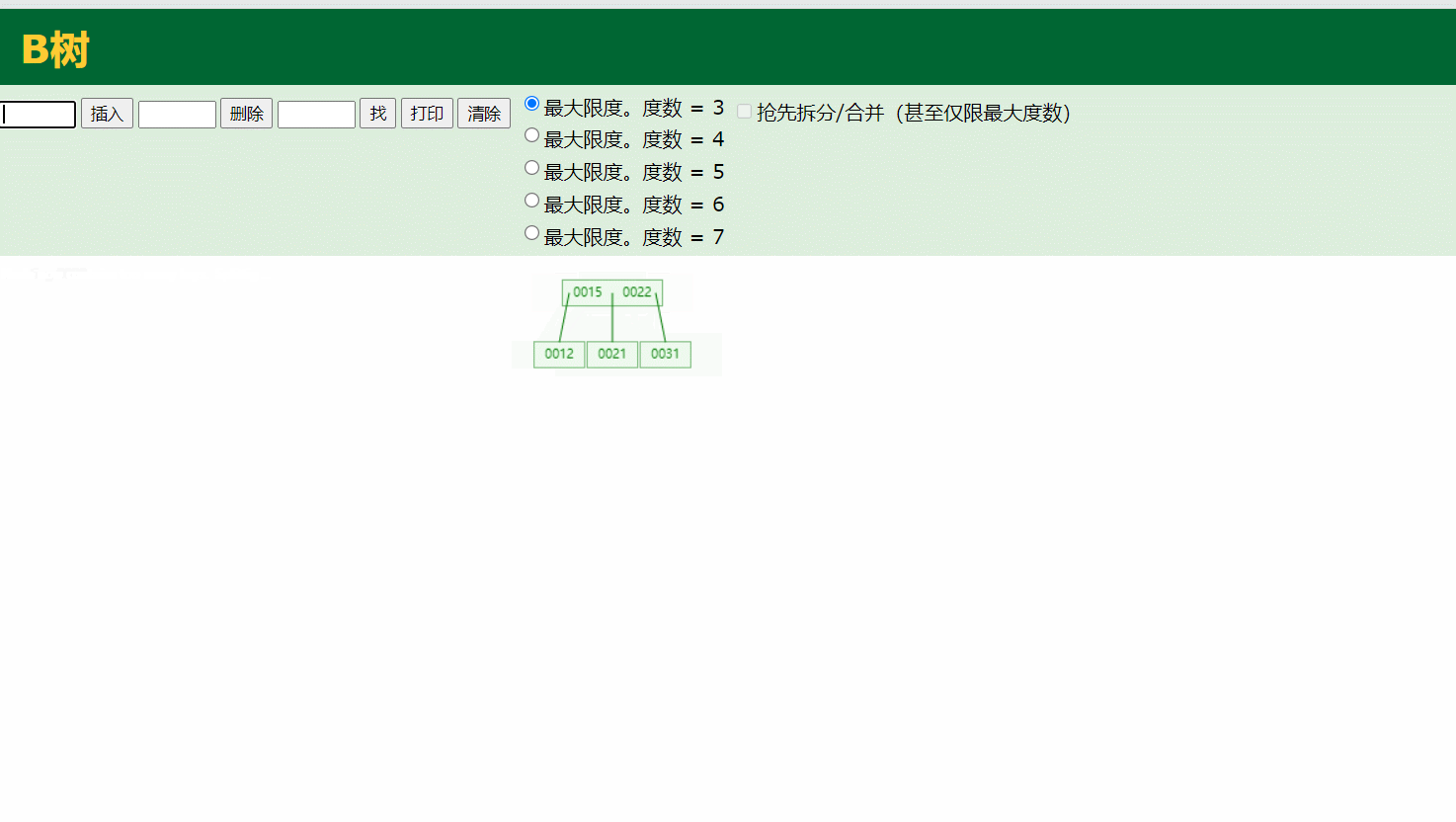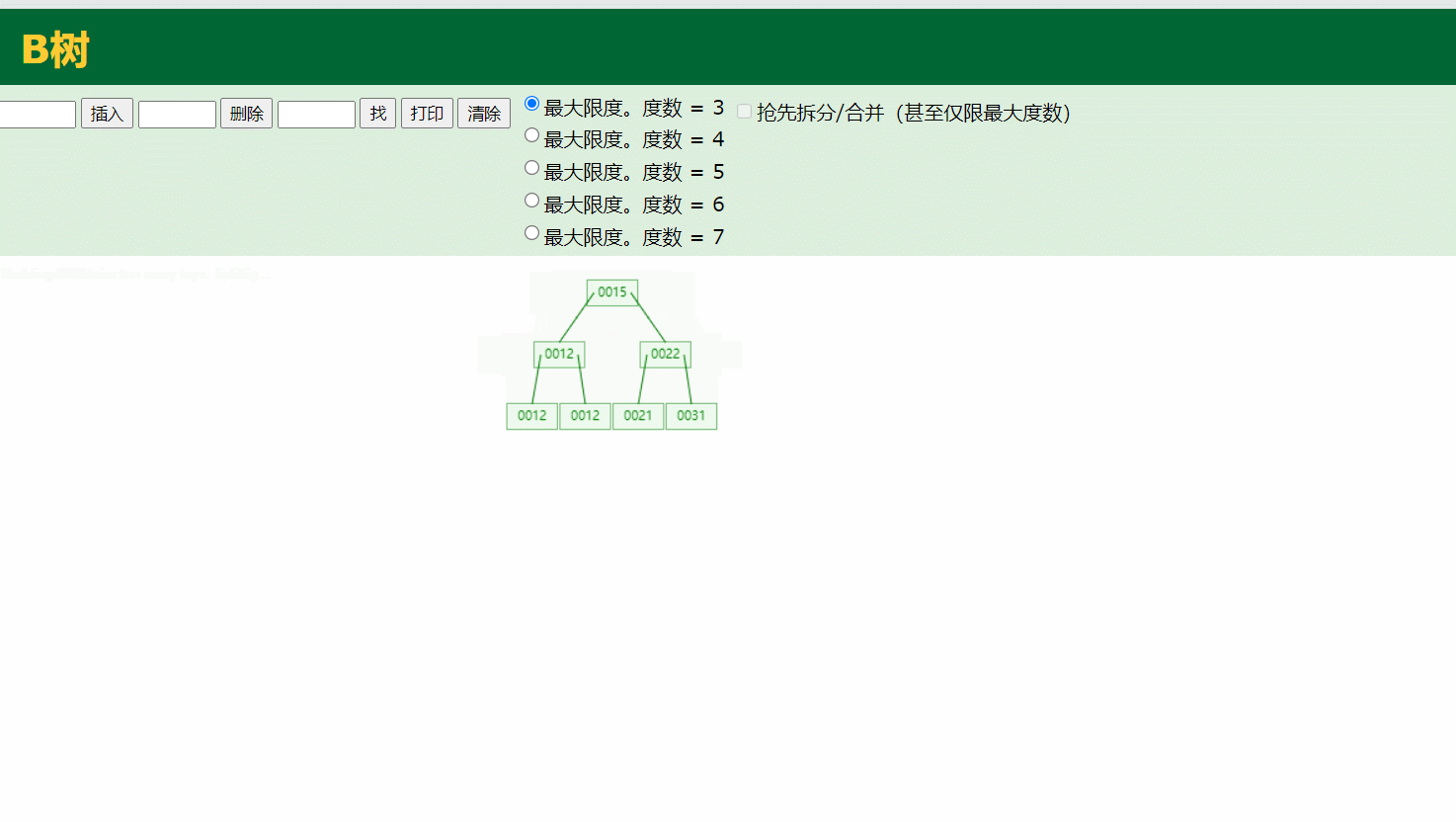
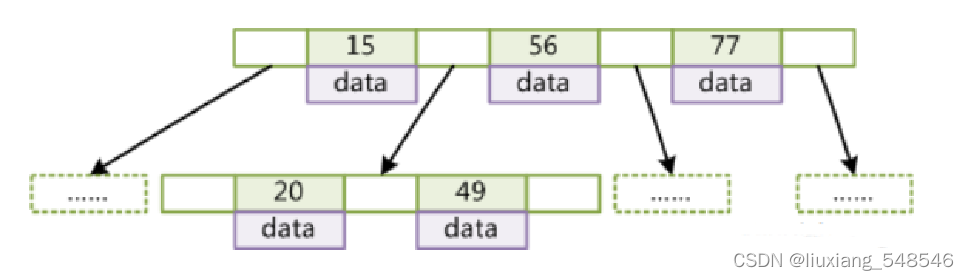
B+tree
B+树对于B树而言又进行了优化,可以看到他的叶子结点是有一个指针指向下一份叶子结点,里面存储了下一个节点的位置信息,是为了叶子结点之间能够快速地查找,而mysql内部就是使用的这种存储模式

MySQL底层的数据结构:
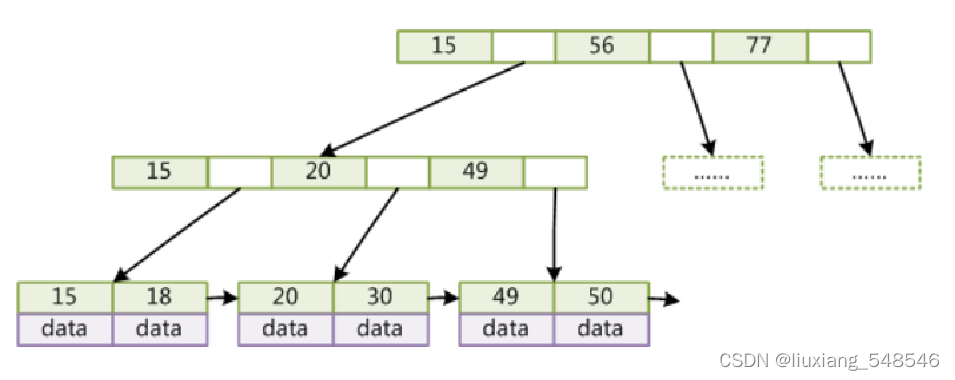
MySQL将所有的数据都放到了叶子节点中,而根节点和非叶子节点中放的都是冗余的索引Key,可以理解为我们所有的数据都是key-value的形式存放的,这些数据都是放在叶子节中(最后一行数据),而他们的父节点都是所有数据的key用算法算出中间的平衡值作为父节点,这样做有两个好处,一个是增加非叶子节点的度,还有就是减少io的磁盘消耗,下面会讲到。
MySQL查找的实现顺序:
1.将根节点磁盘页数据(第一行数据)load到内存中进行比较,找到要查找数据的在那个区间
2.然后再将第二行磁盘页load到内存中,执行上面的操作,找到区间
3. 1,2步骤的查找是相当快的, 因为他都是排好序的,消耗的内存也很少,因为他只存了key值,这就是要将数据放在叶子节点的好处,最后在叶子节点找到要查找的key,在把value一起拿出来,就查找到了我们的结果
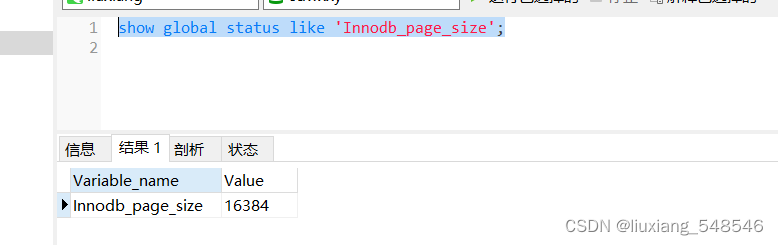
MySQL是怎么限制树的高度?
MySQL底层将每一个磁盘页的大小设置为16k,可以使用 sql语句:show global status like ‘Innodb_page_size’; 这个值是mysql经过多次测试设置的,可以修改,但不建议修改,
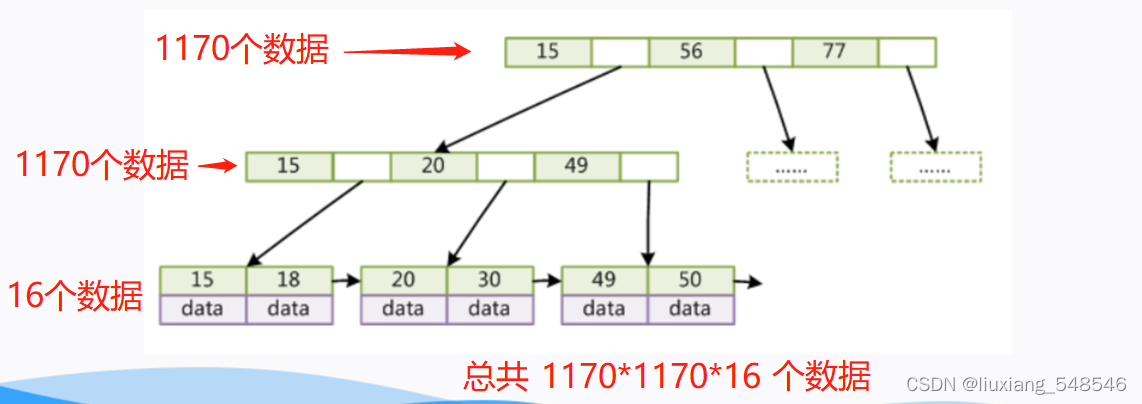
比如我们索引使用的ID,bigint类型占用八个字节加上一个地址大约6个字节,就是16kb/8+6kb=1170个节点,最后叶子结点存放了数据就算是1k,存储的数据达到了两千多万的数据,而他的树高度只有3,就是说我们只需要三次磁盘的io就可以完成查找,还可以将根节点放到磁盘中,这样就只需要两次,速度也是相当于快。
总结一下:
MySQL底层使用的是B+tree存储结构
非叶子节点存储索引和下一个子节点的地址
叶子结点存储所有的索引和数据