PythonЪ§ОнНсЙЙгыЫуЗЈ(3.2)ЁЊЁЊеЛЯрЙигІгУгыЯАЬт
0. бЇЯАФПБъ
ЮвУЧвбОбЇЯАСЫеЛЕФЯрЙиИХФювдМАЦфЪЕЯж,ЭЌЪБвВСЫНтСЫеЛдкЪЕМЪЮЪЬтжаЕФЙуЗКгІгУ,БОНкЕФжївЊФПЕФЪЧЭЈЙ§еЛЕФЯрЙиЯАЬтРДНјвЛВНМгЩюЖдеЛЕФРэНт,ЭЌЪБФмЙЛРћгУеЛНЕЕЭвЛаЉИДдгЮЪЬтНтОіЗНАИЕФЪБМфИДдгЖШЁЃ
1. ЛиЮФађСаХаЖЯ
[ЮЪЬт] ИјЖЈвЛзжЗћДЎ string (Шч:abamaba),МьВщЦфЪЧЗёЮЊЛиЮФЁЃ
[ЫМТЗ] гЩгк string ЮЊзжЗћДЎ,вђДЫзюМђЕЅЕФЗНЗЈЪЧЪЙгУЫЋЫїв§ЗЈ,ЦфжавЛИіЫїв§ЮЛгкзжЗћДЎЕФПЊЭЗ,СэвЛИіЮЛгкзжЗћДЎЕФФЉЮВ;УПДЮБШНЯСНИіЫїв§ДІЕФжЕЪЧЗёЯрЭЌЁЃШчЙћжЕЯрЭЌ,дђдіМгзѓЫїв§ЁЂМѕЩйгвЫїв§,ЗёдђИјЖЈЕФзжЗћДЎВЛЪЧЛиЮФађСа;ГжајЩЯЪіЙ§ГЬ,жБЕНСНИіЫїв§дкжаМфЯргіЁЃ
ЮвУЧвВПЩвдРћгУеЛРДПьЫйНтОіДЫЮЪЬт,ШчЯТЪі[ЫуЗЈ]ЫљЪОЁЃ
[ЫуЗЈ]
?БщРњзжЗћДЎ,НЋЫљгадЊЫи push ЕНеЛжа
?БщРњзжЗћДЎ,НЋУПИідЊЫигыеЛЖЅдЊЫиНјааБШНЯ
?ШчЙћЯрЭЌ,дђеЛЖЅдЊЫиГіеЛВЂМЬајЖдБШзжЗћжаЕФЯТвЛдЊЫи
?ШчЙћВЛЯрЭЌ,дђИјЖЈзжЗћДЎВЂЗЧЛиЮФ,ЬјГібЛЗ
[ДњТы]
def ispalindrome(string):
string_stack = Stack()
flag = True
for c in string:
string_stack.push(c)
for c in string:
if c != string_stack.pop():
flag = False
break
return flag
[ЪБПеИДдгЖШ] ЪБМфИДдгЖШЮЊ O ( n ) O(n) O(n),ПеМфИДдгЖШЮЊ O ( n ) O(n) O(n)ЁЃ
2. ЗДзЊеЛжадЊЫи
[ЮЪЬт] ИјЖЈвЛеЛ stack,НіЪЙгУеЛЕФВйзїЗДзЊеЛжадЊЫиЁЃ
[ЫМТЗ] гЩгкеЛЕФЯШНјКѓГіЬиад,ПЩвдЙЙНЈаТеЛ new_stack,ВЂНЋдРДеЛ stack жаЕФдЊЫиАДГіеЛЫГађбЙШы new_stack жаЁЃ
[ЫуЗЈ]
?ЪЕР§ЛЏаТеЛ new_stack
?ШчЙћеЛ stack ЗЧПе:
???еЛЖЅдЊЫиГіеЛ
???ГіеЛдЊЫи push НјаТеЛ new_stack жа
[ДњТы]
def reverse_stack(stack):
new_stack = Stack()
if not stack.isempty():
new_stack.push(stack.pop())
return new_stack
[ЪБПеИДдгЖШ] ЪБМфИДдгЖШЮЊ O ( n ) O(n) O(n),ПеМфИДдгЖШЮЊ O ( n ) O(n) O(n)ЁЃ
3. зюДѓПчЖШЮЪЬт
[ЮЪЬт3-1] ИјЖЈвЛСаБэ L,ЮвУЧЖЈвх L[i] ЕФПчЖШ S[i] ЮЊНєСк L[i]жЎЧА,ВЂТњзу L[j] <= L[i] ЕФСЌајдЊЫиИіЪ§,МД i - jЁЃР§Шч:
| i | L[i] | S[i] |
|---|---|---|
| 0 | 7 | 1 |
| 1 | 2 | 1 |
| 2 | 5 | 2 |
| 3 | 6 | 3 |
| 4 | 1 | 1 |
етвЛЮЪЬтЕФвЛИіГЃМћЪЕгУГЁОАЭЈГЃЮЊбАевЗхжЕ,Р§ШчВщевЕЭгкЕБЧАЙЩЦБМлИёЕФзюДѓСЌајЬьЪ§:
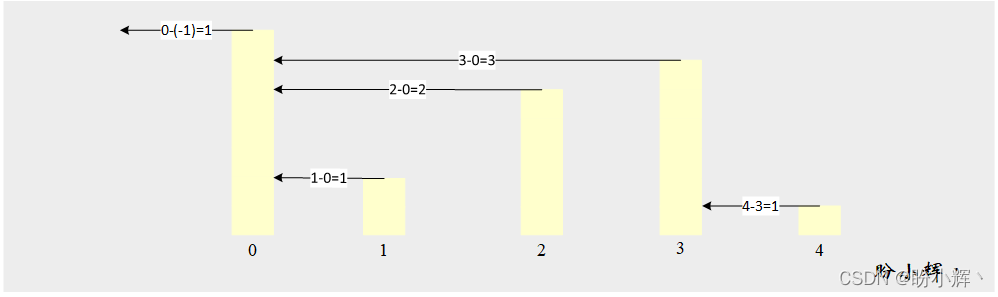
[ЫМТЗ3-1] ЮЊСЫЖдДЫЮЪЬтгавЛИіЧхЮњЕФШЯЪЖ,ЮвУЧЪзЯШПМТЧВЩгУБщРњЕФЗНЗЈ,МьВщгаЖрЩйСЌајдЊЫижЕЕЭгкЕБЧАдЊЫиЁЃ
[ДњТы3-1]
def finding_spans(L):
s = [None] * len(L)
for i in range(len(L)):
j = i - 1
while j >= 0 and L[i] > L[j]:
j -= 1
s[i] = i - j
return s
[ЪБПеИДдгЖШ3-1] ЪБМфИДдгЖШ O ( n 2 ) O(n^2) O(n2),ПеМфИДдгЖШ O ( 1 ) O(1) O(1)ЁЃ
[ЮЪЬт3-2] РћгУеЛНЕЕЭ [ЮЪЬт3-2] ЕФЪБМфИДдгЖШЁЃ
[ЫМТЗ3-2] Дг [ЫуЗЈ3-1] ПЩвдПДГі,ШчЙћЮвУЧжЊЕРСЫЕк i ИідЊЫиЧАЕФЕквЛИіДѓгк L[i] ЕФдЊЫиЫїв§,ОЭПЩвдКмШнвзМЦЫуГіЕк i ЬьЕФПчЖШ S[i],МйЩшИУЫїв§ЮЊ p,ФЧУД S[i] = i - p,вђДЫЮвУЧЪЙгУеЛРДБЃДцДѓгкЕБЧАдЊЫиЕФЕквЛИідЊЫиЕФЫїв§,ГѕЪМЪБЫїв§ p=-1ЁЃ
[ЫуЗЈ3-2]
?ЪЕР§ЛЏаТеЛ d,ВЂГѕЪМЛЏПчЖШСаБэ s
?БщРњСаБэ L:
???ШчЙћеЛ d ВЛЮЊПе,ЧвЕБЧАдЊЫиДѓгкеЛЖЅдЊЫи:
?????d ГіеЛ
???Зёдђ:
?????p=еЛЖЅдЊЫижЕ
???МЦЫу s[i],ВЂНЋСаБэЕБЧАЫїв§ШыеЛ
[ДњТы3-2]
def finding_spans(L):
d = Stack()
s = [None] * len(L)
for i in range(len(L)):
# stack.peek()ЗНЗЈгУгкЗЕЛиеЛЖЅдЊЫи,ВЂВЛГіеЛ
while not d.isempty() and L[i] > L[d.peek()]:
d.pop()
if d.isempty():
p = -1
else:
p = d.peek()
s[i] = i - p
d.push(i)
return s
[ЪБПеИДдгЖШ3-2] гЩгкСаБэжаЕФЫїв§зюЖрШыеЛ 1 ДЮ,ЧвзюЖрГіеЛ 1 ДЮ,ЫфШЛгаФкбЛЗ,ЕЋЦфзмЕФжДааДЮЪ§ЮЊ n n n,вђДЫЫуЗЈЕФЪБМфИДдгЖШЮЊ O ( n ) O(n) O(n),ПеМфИДдгЖШЮЊ O ( n ) O(n) O(n)ЁЃ
4. ЪЙгУвЛИіСаБэЪЕЯжСНИіеЛ
[ЮЪЬт] НіЪЙгУвЛИіЖЈГЄСаБэЪЕЯжСНИіеЛ,жБЕНСаБэжаУЛгаПеЯаПеМфЁЃ
[ЫМТЗ] вЛжжПЩааЕФЗНЗЈШчЯТЭМЫљЪО:

[ЫуЗЈ]
?ЪЙгУЫЋЫїв§,вЛИідкСаБэзѓЖЫ,СэвЛИідкгвЖЫ
?ЪЙгУзѓВрЫїв§ФЃФтЕквЛИіеЛ,гвВрЫїв§ФЃФтЕкЖўИіеЛ
?ЕквЛИіеЛЯђгвдіГЄ,ЕкЖўИіеЛЯђзѓдіГЄ
[ДњТы]
class TwoStack:
def __init__(self, size=10):
self.items = [None] * size
self.size = size
self.top_1 = -1
self.top_2 = size
def stack_1_push(self, data):
if self.top_2 - self.top_1 > 1:
self.top_1 += 1
self.items[self.top_1] = data
else:
raise("Stack Overflow!")
def stack_2_push(self, data):
if self.top_2 - self.top_1 > 1:
self.top_2 -= 1
self.items[self.top_2] = data
else:
raise("Stack Overflow!")
def stack_1_pop(self):
if self.top_1 < 0:
raise("Stack Underflow!")
else:
result = self.items[self.top_1]
self.top_1 -= 1
return result
def stack_2_pop(self):
if self.top_2 >= self.size:
raise("Stack Underflow!")
else:
result = self.items[self.top_2]
self.top_2 += 1
return result
[ЪБПеИДдгЖШ] СНИіеЛЕФ push КЭ pop ВйзїЕФЪБМфИДдгЖШОљЮЊ
O
(
1
)
O(1)
O(1),ПеМфИДдгЖШЮЊ
O
(
1
)
O(1)
O(1)ЁЃ
5. ЩОГ§ЫљгаЯрСкЕФжиИДдЊЫи
[ЮЪЬт] ИјЖЈвЛзжЗћДЎ string,ДгзжЗћДЎжаЩОГ§ЯрСкЕФжиИДзжЗћ,ЪЙЪфГізжЗћДЎжаВЛАќКЌЯрСкЕФжиИДЯюЁЃШч:ЪфШызжЗћДЎ cennection,ЪфГіЮЊ tionЁЃ
[ЫМТЗ] гЩгкдк python жазжЗћДЎЪєгкВЛПЩБфађСа,вђДЫЮЊСЫЪЕЯждЕиаоИФ,ЪзЯШНЋзжЗћДЎ string БфЮЊСаБэЁЃШЛКѓжБНгНЋДЫСаБэзїЮЊеЛ,ЕБеЛЖЅЕФзжЗћгыЕБЧАзжЗћВЛЭЌЪБ,НЋЦфЬэМгЕНеЛжа;Зёдђ,ЬјЙ§ЕБЧАзжЗћ,жБЕНИУзжЗћгыеЛЖЅВЛЯрЭЌ,ШЛКѓДгеЛжавЦГ§ИУдЊЫи,зюжееЛжаЕФдЊЫиМДЮЊЫљЧѓНсЙћЁЃ
[ЫуЗЈ]
?НЋзжЗћДЎ string БфЮЊађСа,ВЂГѕЪМЛЏеЛЖЅ ptr КЭЫїв§ i
?БщРњађСа string:
???ШчЙћеЛЖЅЕФзжЗћгыЕБЧАзжЗћВЛЭЌ:
?????ЕБЧАзжЗћШыеЛ
???Зёдђ:
?????ЬјЙ§ЕБЧАзжЗћ,жБЕНЕБЧАзжЗћгыеЛЖЅВЛЯрЭЌ
???еЛЖЅдЊЫиГіеЛ
[ДњТы]
def remove_duplicates(string):
string = list(string)
ptr = -1
i = 0
size = len(string)
while i < size:
if ptr == -1 or string[ptr] != string[i]:
ptr += 1
string[ptr] = string[i]
i += 1
else:
while i < size and string[ptr] == string[i]:
i += 1
ptr -= 1
ptr += 1
string = ''.join(string[0:ptr])
return string
[ЪБПеИДдгЖШ] ЪБМфИДдгЖШЮЊ O ( n ) O(n) O(n),ПеМфИДдгЖШЮЊ O ( 1 ) O(1) O(1)ЁЃ
ЯрЙиСДНг
ЯпадБэЛљБОИХФю
ЫГађБэМАЦфВйзїЪЕЯж
ЕЅСДБэМАЦфВйзїЪЕЯж
еЛМАЦфЪЕЯж