����Ŀ¼
ʲô��ǿ��ѧϰ?(����������)
3.����������(Bellman equation)
���������̱�ʾ����״̬��ֵ������״̬-��Ϊ��ֵ����֮��Ĺ�ϵ�������������б������������̺ͱ�������ѷ��̡�
3.1��������������(Bellman expectation equation)
�����������̿ɽ�״̬��ֵ������״̬-��Ϊ��ֵ������ʾΪ����ֵ
E
E
E��״̬��ֵ�����ı������������̱�ʾ����:
V
��
(
s
)
=
E
[
R
t
+
1
+
��
V
��
(
S
t
+
1
)
�O
S
t
=
s
]
V_{\pi}(s)=\mathbb{E}\left[R_{t+1}+\gamma V_{\pi}\left(S_{t+1}\right) \mid S_{t}=s\right]
V��?(s)=E[Rt+1?+��V��?(St+1?)�OSt?=s]��ǰ״̬
S
t
S_t
St? �ļ�ֵ���۵���һ״̬
S
t
+
1
S_{t+1}
St+1?�ļ�ֵ
��
\gamma
�� ���Ե�����ֵ��
״̬-��Ϊ��ֵ�����ı�����������������:
Q
��
(
s
,
a
)
=
E
[
R
t
+
1
+
��
Q
��
(
S
t
+
1
,
A
t
+
1
)
�O
S
t
=
s
,
A
t
=
a
]
Q_{\pi}(s, a)=\mathbb{E}\left[R_{t+1}+\gamma Q_{\pi}\left(S_{t+1}, A_{t+1}\right) \mid S_{t}=s, A_{t}=a\right]
Q��?(s,a)=E[Rt+1?+��Q��?(St+1?,At+1?)�OSt?=s,At?=a]�ڵ�ǰ״̬
S
t
S_t
St?��ִ�ж���
A
t
A_t
At?,�������������
R
t
+
1
R_{t+1}
Rt+1?������һ��״̬
S
t
+
1
S_{t+1}
St+1? �Ͷ���
A
t
+
1
A_{t+1}
At+1?��״̬-������ֵ�����ۿ��ʡ�
��״̬��ֵ������,���Խ�������ֵת��Ϊ��ѭ����
��
��
�� ��״̬-��Ϊ��ֵ����,������ʾ:
V
��
(
s
)
=
��
a
��
A
��
(
a
�O
s
)
Q
��
(
s
,
a
)
V_{\pi}(s)=\sum_{a \in A} \pi(a \mid s) Q_{\pi}(s, a)
V��?(s)=a��A��?��(a�Os)Q��?(s,a)״̬
s
s
s ���ݲ���
��
��
�� ѡ����Ϊ
a
a
a �ĸ��ʳ���״̬
s
s
s ����
��
��
�� ִ����Ϊ
a
a
a �ļ�ֵ���ڴ˹�ʽ��,״̬-��Ϊ��ֵ����Ҳ������״̬��ֵ����������⡣
Q
��
(
s
,
a
)
=
R
s
a
+
��
��
s
��
��
S
P
s
,
s
��
a
V
��
(
s
��
)
Q_{\pi}(s, a)=R_{s}^{a}+\gamma \sum_{s^{\prime} \in S} P_{s, s^{\prime}}^{a} V_{\pi}\left(s^{\prime}\right)
Q��?(s,a)=Rsa?+��s����S��?Ps,s��a?V��?(s��)�ڵ�ǰ״̬
s
s
s ��ִ����Ϊ
a
a
a ʱ,���������Ͷ���һ״̬
s
s
s ������ֵ����״̬ת�Ƹ���,�����ϼ����ۿۡ�
���˹�ʽ���������״ֵ̬����:
V
��
(
s
)
=
��
a
��
A
��
(
a
�O
s
)
(
R
s
a
+
��
��
s
��
��
S
P
s
,
s
��
a
V
��
(
s
��
)
)
V_{\pi}(s)=\sum_{a \in A} \pi(a \mid s)\left(R_{s}^{a}+\gamma \sum_{s^{\prime} \in S} P_{s, s^{\prime}}^{a} V_{\pi}\left(s^{\prime}\right)\right)
V��?(s)=a��A��?��(a�Os)(Rsa?+��s����S��?Ps,s��a?V��?(s��))����,�ڼ�ֵ��������ʽ��,ģ������ֵ����ʽ
E
E
E ����ȥ���ݹ�ر�ʾ��
���Ƶ�,״̬-��Ϊ��ֵ����Ҳ���Եݹ�ر�ʾ:
Q
��
(
s
,
a
)
=
R
s
a
+
��
��
s
��
��
S
P
s
,
s
��
a
��
a
��
��
A
��
(
a
��
�O
s
��
)
Q
��
(
s
��
,
a
��
)
Q_{\pi}(s, a)=R_{s}^{a}+\gamma \sum_{s^{\prime} \in S} P_{s, s^{\prime}}^{a} \sum_{a^{\prime} \in A} \pi\left(a^{\prime} \mid s^{\prime}\right) Q_{\pi}\left(s^{\prime}, a^{\prime}\right)
Q��?(s,a)=Rsa?+��s����S��?Ps,s��a?a����A��?��(a���Os��)Q��?(s��,a��)
����ͨ�����������̶�״̬��ֵ������״̬-��Ϊ��ֵ���������˵ݹ���⡣
3.2 ���������ŷ���(Bellman optimality equation)
���״̬��ֵ�����״̬-�ж���ֵ���Ա���Ϊ:��Ѽ�ֵ��ָ����ѭ�ɻ������ܻر�������ʱ����õļ�ֵ��
V
?
(
s
)
=
max
?
��
V
��
(
s
)
Q
?
(
s
,
a
)
=
max
?
��
Q
��
(
s
,
a
)
\begin{aligned} V_{*}(s) &=\max _{\pi} V_{\pi}(s) \\ Q_{*}(s, a) &=\max _{\pi} Q_{\pi}(s, a) \end{aligned}
V??(s)Q??(s,a)?=��max?V��?(s)=��max?Q��?(s,a)?��
V
V
V ��
Q
Q
Q �ϼ�������(*)��ʾ��Ѽ�ֵ��
�ñ�������ѷ��̱�ʾ��Ѽ�ֵ������ж���ֵ:
V
?
(
s
)
=
max
?
a
R
s
a
+
��
��
s
��
��
S
P
s
,
s
��
a
V
?
(
s
��
)
Q
?
(
s
,
a
)
=
R
s
a
+
��
��
s
��
��
S
P
s
,
s
��
a
V
?
(
s
��
)
\begin{gathered} V_{*}(s)=\max _{a} R_{s}^{a}+\gamma \sum_{s^{\prime} \in S} P_{s, s^{\prime}}^{a} V_{*}\left(s^{\prime}\right) \\ Q_{*}(s, a)=R_{s}^{a}+\gamma \sum_{s^{\prime} \in S} P_{s, s^{\prime}}^{a} V_{*}\left(s^{\prime}\right) \end{gathered}
V??(s)=amax?Rsa?+��s����S��?Ps,s��a?V??(s��)Q??(s,a)=Rsa?+��s����S��?Ps,s��a?V??(s��)?
4. M D P MDP MDP �Ķ�̬���(dynamic programming)
4.1 M D P MDP MDP
�����ǿ�һ��ʹ�ô��ױ������������
M
D
P
MDP
MDP �Ķ�̬��̡���̬���(Dynamic Programming,DP)��һ�ֽ���ݹ��Ż�����ķ���,DP�ɲ��Ե����ͼ�ֵ������ɡ�
�ظ�����(policy iteration)
�ظ����Խ��ظ�ˢ��״̬��ֵ����,������ʾ:
V
k
+
1
(
s
)
=
��
a
��
A
��
(
a
�O
s
)
(
R
s
a
+
��
��
s
��
��
S
P
s
,
s
��
a
V
k
(
s
��
)
)
V_{k+1}(s)=\sum_{a \in A} \pi(a \mid s)\left(R_{s}^{a}+\gamma \sum_{s^{\prime} \in S} P_{s, s^{\prime}}^{a} V_{k}\left(s^{\prime}\right)\right)
Vk+1?(s)=a��A��?��(a�Os)(Rsa?+��s����S��?Ps,s��a?Vk?(s��))
����
k
k
k ��ʾ�ظ����̡��ظ�
N
N
N �θ��¼�ֵ����V�Դ���
V
1
��
V
2
��
��
��
V
N
V_1��V_2������V_N
V1?��V2?������VN?�����뱴�����������̵���ʽ��ͬ��
���ǽ����µ��������
M
D
P
MDP
MDP ʾ����������3x3���������еIJ���
 ���,��������������״̬������ͬ��0.25����ִ�����в�����δӦ���ۿۡ���,��
��
\gamma
��=1��
���,��������������״̬������ͬ��0.25����ִ�����в�����δӦ���ۿۡ���,��
��
\gamma
��=1��
��������ʱ-0.1,����Ŀ�ĵ�ʱ����1������,�����ǿ�һ���ظ�ˢ��״̬��ֵ�����ᷢ��ʲô��
������ʾ��״̬��ֵ�����ڲ����ظ������еı仯
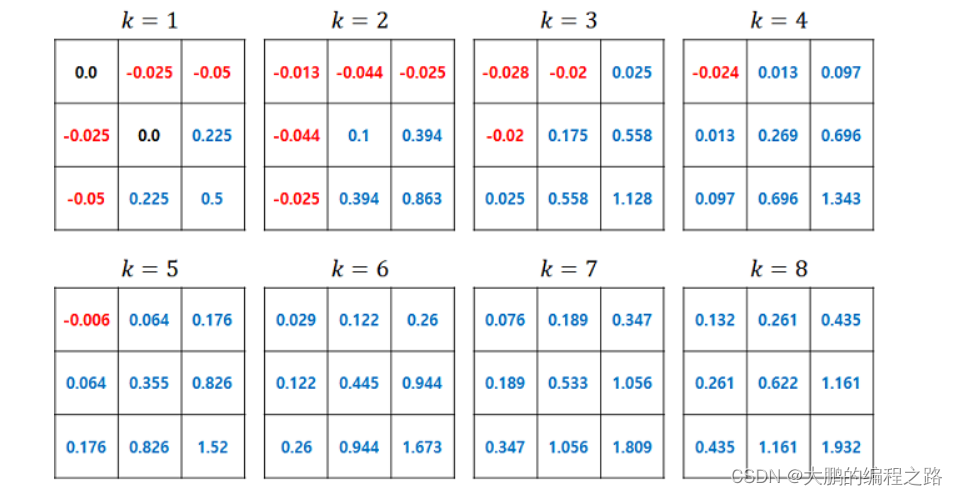
���Ե����е�״ֵ̬�����仯���� k=8 ʱ,���Կ��Ը���Ϊ
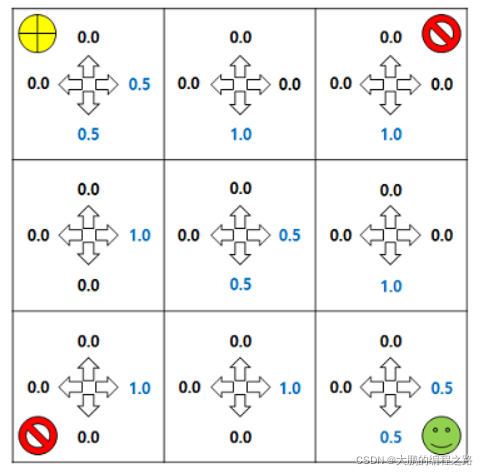
����״̬��ֵ�����IJ��Ը���
�����һ��״̬���������״̬��ֵ�����IJ��Ը�����ͬ�ļ�ֵ,����Ը�����ͬ�ĸ���,ʹ���ƶ����������ֵ��״̬����ֵ�ظ�(value iteration)��ֵ�ظ������ڲ����ظ�����������,������������һ�¼�ֵ�ظ��Ĺ�ʽ
V
k
+
1
(
s
)
=
max
?
a
��
A
R
s
a
+
��
��
s
��
��
S
P
s
,
s
��
a
V
k
(
s
��
)
V_{k+1}(s)=\max a \in A R_{s}^{a}+\gamma \sum_{s^{\prime} \in S} P_{s, s^{\prime}}^{a} V_{k}\left(s^{\prime}\right)
Vk+1?(s)=maxa��ARsa?+��s����S��?Ps,s��a?Vk?(s��)�ڲ����ظ���,���ǽ�����״̬�ļ�ֵ���Բ��Ժ����ĸ������,���ڲ����ظ���,����̰����ѡ��������һ����ֵ���ӹ�ʽ���Կ���,ֻ�б�������ѷ��̡��ڲ����ظ���,���Ǹ�����״̬��ֵ����,����ָ����˲���;���ڼ�ֵ�ظ���,����û�е������²��ԵIJ��衣��ֵѭ���ٶ���ǰ�IJ�������ѵ�,��������IJ�����
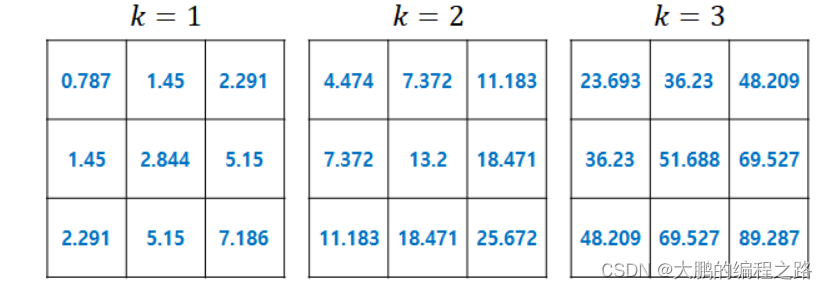
�����ʾ����ʾ���ظ�ֵ״̬��ֵ������������ͬʾ���еı仯���:
4.2.��̬�滮�ľ������Լ�Ϊʲô��Ҫǿ��ѧϰ
��̬�滮����Ӧ���ڴ������ʵ���������,����״̬ת�Ƹ��ʺͽ�����������ʵ������ǰ֪��,��Ϊ������� MDP ��״̬ת�Ƹ��ʺͽ���������
������ⶨ��÷dz���,��ʹ״̬ת�Ƹ��ʺͽ�����������֪��,����״̬����������,Ҳ����ʵ����ⱴ�������̡�
��ʹ�ú��ѽ���̬�滮Ӧ���ڴ����ʵ������,����״̬ת�Ƹ��ʺͽ����������Ȳ�֪������״̬�����ġ���Щȱ�����ͨ������ǿ��ѧϰ���������˷���