Redis 键值对结构
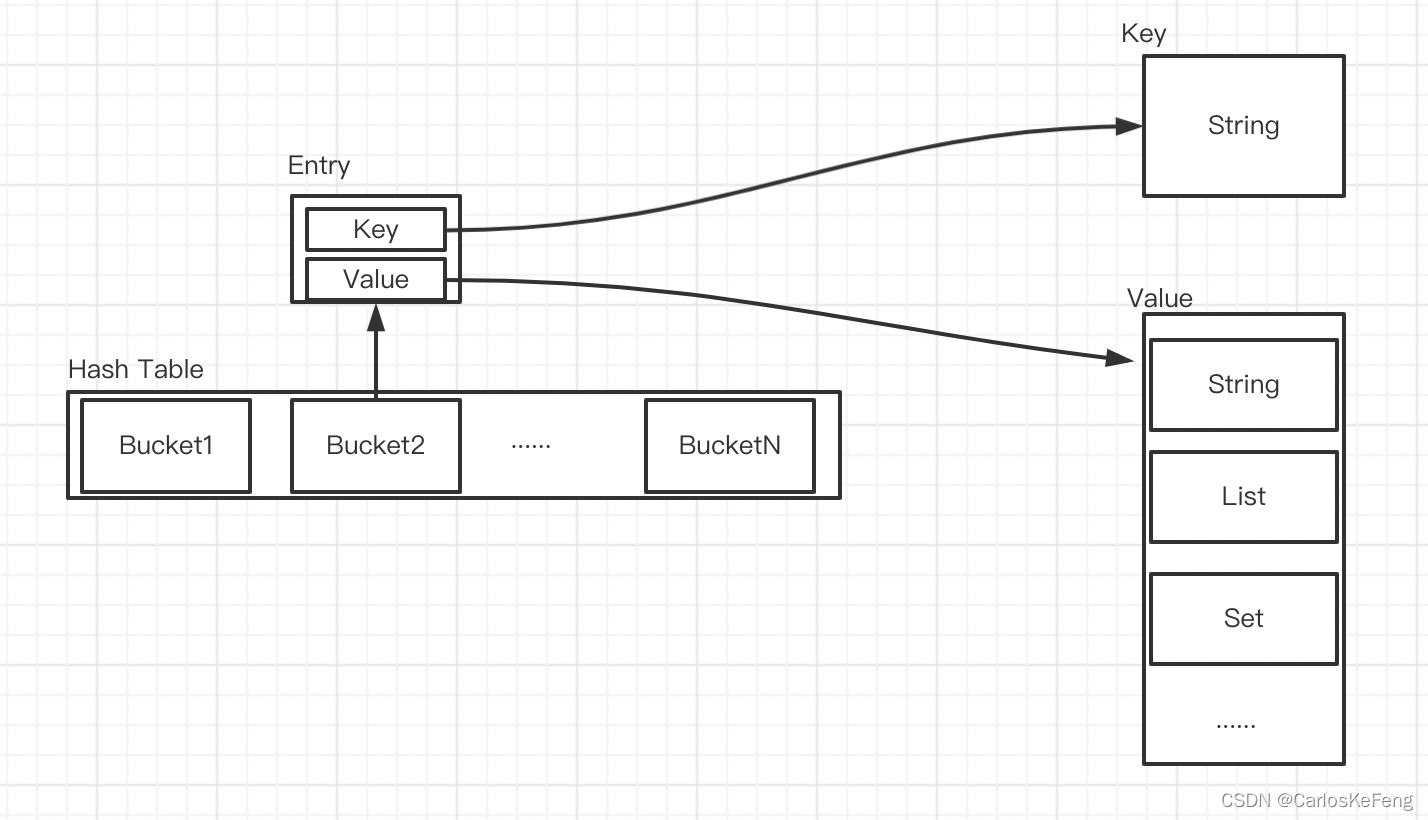
- HashTable
Redis中有一个「全局哈希表」,该哈希表中保存锁所有的键值对。对于Hash表的查找操作时间复杂度为O(1)
- Bucket
哈希表中的每一个元素称为哈希桶(Bucket),哈希桶中保存了键值对数据
- Entry
保存键值对数据
如上图:其实Entry中保存的是Key,Value的指针值,通过对应的指针能够对Key,Value进行查找
举个🌰:
假设你现在要往Redis中写入一个String类型的数据,其中Key=username_1 ,Value=小明
那么Redis将调用Hash函数计算Key的哈希值,根据哈希值选择哈希表中对应的哈希桶,然后将Key,Value进行存储。并将Key,Value的指针存入哈希桶的Enrty中
Rehash
哈希冲突
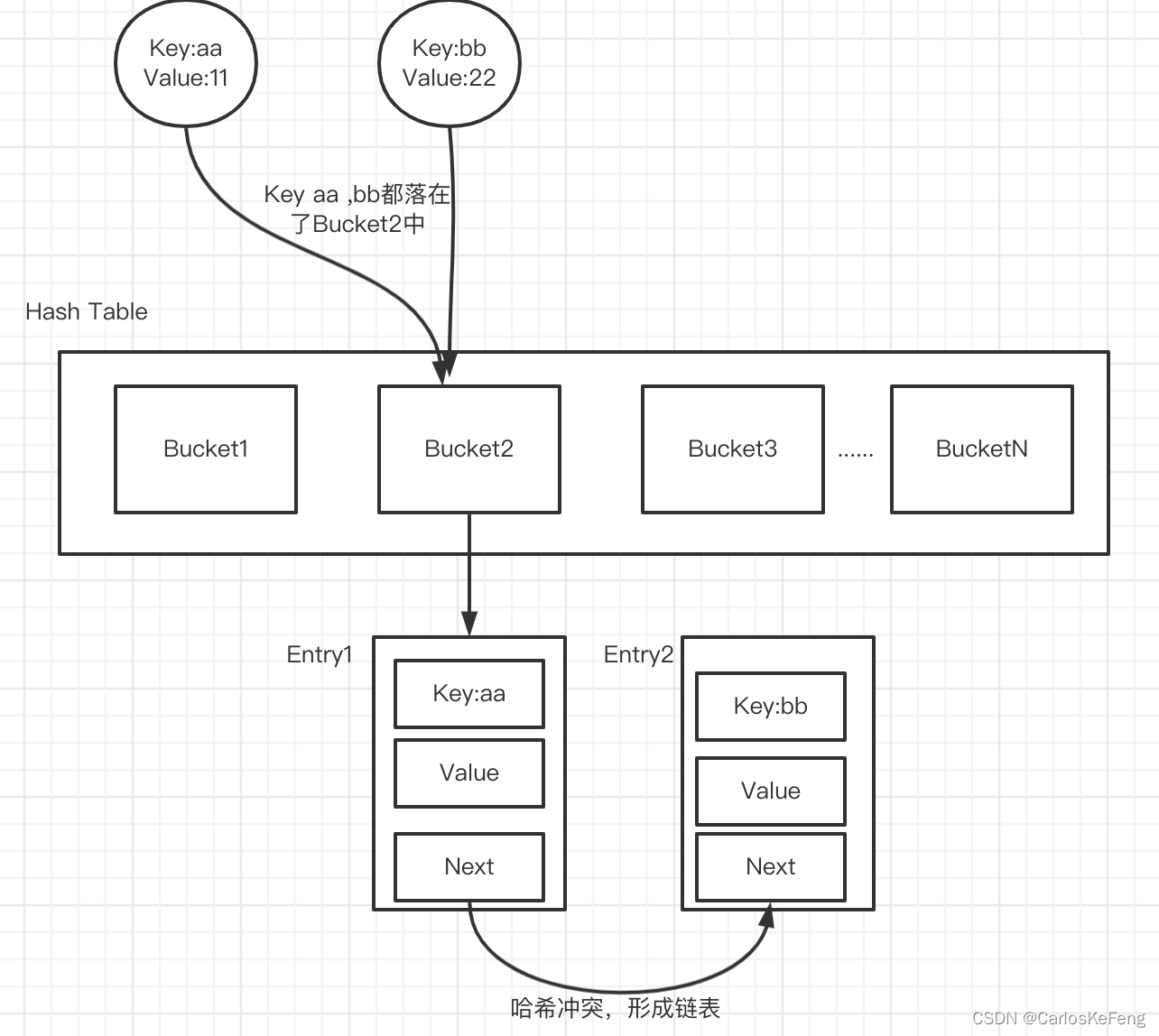
哈希表中桶的数量是有限的,当Key的数量较大时自然避免不了哈希冲突(多个Key落在了同一个哈希桶中)。当哈希桶中存在哈希冲突时那么多个Entry就形成了链表,每个链表中有一个Next指针指向了下一个元素。当哈希桶中的链表过长时,那么查询性能会显著降低(链表的查找时间复杂度为O(N)),Redis为了避免类似的问题从而会进行Rehash操作
Rehash

为了能够减少哈希冲突,其实最直接的做法是增加哈希桶数量从而让元素能够更加均匀的分布在哈希表中。而Redis中的Rehash操作的原理其实也是如此,只不过他的设计更加巧妙。
Redis中其实有两个「全局哈希表」,一开始时默认使用的Hash Table1来存储数据,而Hash Table2并没有分配内存空间。随着Hash Table1中的元素越来越多时,Redis会进行Rehash操作。首先会给Hash Table2分配一定的内存空间(肯定比哈希表一大),然后将Hash Table1中的元素重新映射至Hash Table2中,最后会释放Hash Table1。这样来看的话,Redis的Rehash操作的确能减少哈希冲突,但是你有没有想过如果Hash Table1中的元素特别多时,如果这么粗暴的将数据往Hash Table2中搬,那势必会阻塞Redis的主线程进而影响Redis的性能。其实Redis也考虑到了这个问题,那么接下来我们看看Redis是如何解决这种问题的
渐进式Rehash
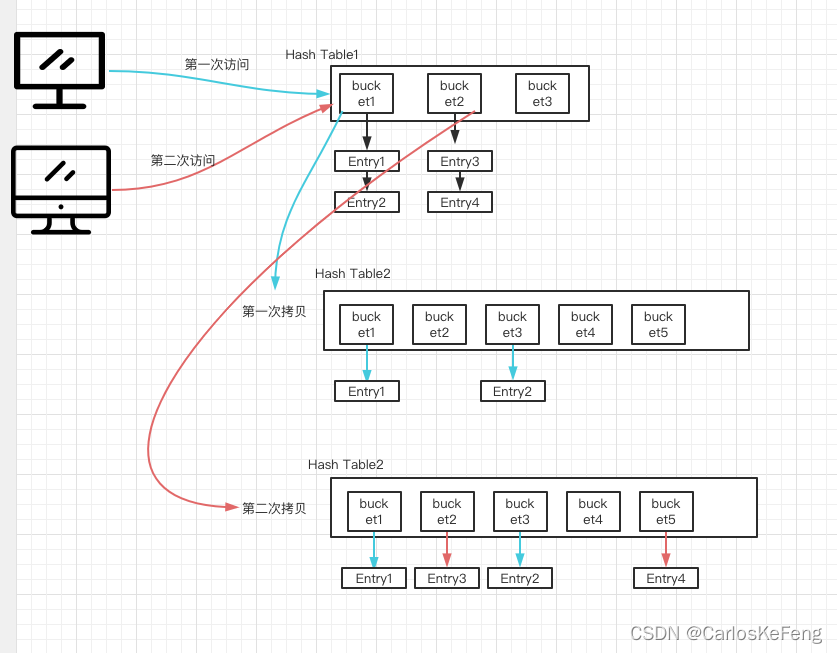
如上图所示,渐进式Rehash采用的做法是:
在将数据拷贝至Hash Table2时,Hash Table1仍然对客户端提供服务。
当客户端访问Hash Table1时,Hash Table1 将索引位置为1的Bucket1中的Entery全部拷贝至Hash Table2,同理当客户端再一次访问Hash Table1时,Hash Table1 将索引位置为2的Bucket2中的Entery全部拷贝至Hash Table2。再拷贝数据进Hash Table2的同时会对数据做重新的Bucket分配,从而减少Hash冲突。
如此往复下去,当Hash Table1的元素都拷贝Hash Table2时,Hash Table2对顶替Hash Table1 与客户端进行交互,此时Hash Table1会被释放,等待下一次Rehash使用。
总结
上文中我们描述了Redis是通过Hash Table的方式来组织所有的键值对,Hash Table中的元素为Bucket(哈希桶)。Bucket中存储着键值对的指针。
当Hash Table中的元素逐渐增多时,会在Bucket中形成链表,一旦链表过长则会严重影响Redis的查询性能,这对以速度著称的Redis是不能接受的。所以Redis采用了增加Hash Table的容量来解决这个问题,也就是所谓的Rehash机制,而Redis为了减轻Rehash时数据大量拷贝锁带来的压力,从而采用了渐进式Rehash来分批次的进行数据拷贝。
如果你对文章内容有疑问,欢迎留言区交流