声明:内容非原创,是学习内容的总结,版权所属姜老师
逻辑回归
# 虽然叫回归,但是本质上是一个分类算法,可以解决多分类的问题,也可以输出回归的概率性结果
from sklearn.linear_model import LogisticRegression
from sklearn.datasets import make_blobs
X, y = make_blobs(n_samples=150, n_features=2, centers=3)
X.shape
(150, 2)
y.shape
(150,)
y
array([0, 1, 0, 1, 2, 1, 0, 1, 1, 2, 2, 2, 1, 2, 0, 1, 2, 0, 2, 2, 1, 2,
0, 1, 1, 0, 1, 2, 0, 0, 2, 0, 0, 2, 1, 0, 1, 2, 1, 1, 2, 2, 0, 2,
2, 2, 0, 0, 0, 0, 1, 0, 0, 0, 1, 1, 1, 1, 2, 2, 0, 0, 0, 2, 0, 2,
2, 2, 0, 1, 2, 1, 0, 0, 0, 0, 0, 1, 0, 2, 1, 0, 0, 1, 2, 2, 2, 2,
2, 2, 2, 0, 0, 0, 1, 1, 2, 2, 0, 0, 0, 1, 1, 0, 1, 1, 2, 2, 0, 1,
1, 2, 2, 1, 2, 1, 0, 2, 0, 1, 0, 0, 2, 2, 2, 0, 1, 2, 1, 0, 1, 0,
2, 1, 1, 0, 1, 1, 2, 1, 1, 2, 2, 1, 1, 1, 0, 2, 1, 1])
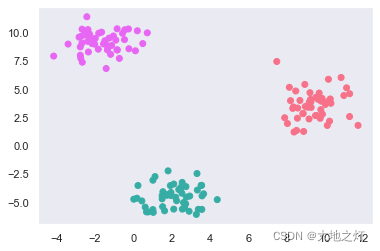
import seaborn as sns
sns.countplot(y)
D:\software\anaconda\lib\site-packages\seaborn\_decorators.py:36: FutureWarning: Pass the following variable as a keyword arg: x. From version 0.12, the only valid positional argument will be `data`, and passing other arguments without an explicit keyword will result in an error or misinterpretation.
warnings.warn(
<AxesSubplot:ylabel='count'>

import matplotlib.pyplot as plt
%matplotlib inline
sns.set(palette='cubehelix',style = 'dark')
from matplotlib.colors import ListedColormap
colors = sns.color_palette('husl')
cmp = ListedColormap(colors)
plt.scatter(X[:,0],X[:,1],c=y,cmap=cmp)
<matplotlib.collections.PathCollection at 0x253b8d81430>
# 使用逻辑斯蒂回归 来进行分类
# 1.实例化逻辑斯蒂回归算法
lr = LogisticRegression()
# 2.训练模型
lr.fit(X,y)
LogisticRegression()
import numpy as np
# 绘制分类的边界
xmin, xmax = X[:,0].min(),X[:,0].max()
ymin, ymax = X[:,1].min(),X[:,1].max()
a = np.linspace(xmin, xmax, 200)
b = np.linspace(ymin, ymax, 200)
xx, yy = np.meshgrid(a, b)
X_test = np.concatenate((xx.reshape(-1,1),yy.reshape(-1,1)),axis=1)
X_test.shape
(40000, 2)
# 3.预测
y_ = lr.predict(X_test)
plt.scatter(X_test[:,0],X_test[:,1],c=y_)
plt.scatter(X[:,0],X[:,1],c=y,cmap=cmp)
<matplotlib.collections.PathCollection at 0x253b9f5c430>
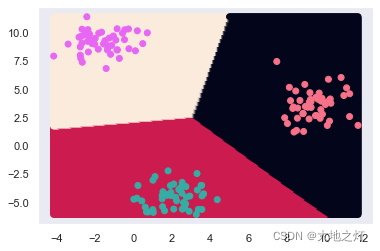
# 逻辑斯蒂回归只能对线性可分的数据进行更好的划分
# 但是由于我们的逻辑斯蒂是一个概率估计模型 并且 它具备线性回归的所有优点(高效 缩减) 所以是一个非常流行的算法
逻辑斯蒂回归的概率预测
# 生成随机数据:10个样本 每个样本5个特征
X = np.random.random(size=(10,5))
X
array([[0.76319326, 0.80687777, 0.03787185, 0.04125638, 0.24176662],
[0.49108586, 0.86212156, 0.58924449, 0.63014179, 0.58616281],
[0.47409458, 0.07739679, 0.57434414, 0.87367993, 0.23624037],
[0.83504226, 0.15709413, 0.70954111, 0.66084017, 0.94787926],
[0.51833235, 0.0205479 , 0.36886036, 0.68425598, 0.89572644],
[0.21072669, 0.75949519, 0.28850424, 0.05028508, 0.26778145],
[0.62106076, 0.31755045, 0.09641944, 0.83162441, 0.64964526],
[0.77423254, 0.49471209, 0.18916518, 0.9511086 , 0.30883323],
[0.15912683, 0.47671285, 0.54351492, 0.63198269, 0.0259659 ],
[0.22599968, 0.70621492, 0.95491154, 0.9921246 , 0.76667328]])
# 10个样本 对应着 10个标签
y = np.random.randint(0,2,size=10)
y
array([1, 1, 0, 1, 0, 0, 0, 1, 1, 0])
# 1.实例化逻辑斯蒂
lr = LogisticRegression()
# 2.训练
lr.fit(X,y)
LogisticRegression()
# 3.预测
lr.predict(X)
array([1, 1, 0, 0, 0, 1, 0, 1, 0, 0])
# 获取系数
lr.coef_
array([[ 0.45474797, 0.36116252, -0.03061392, -0.15813758, -0.27354745]])
# 查看准确度评分
lr.score(X,y)
0.7
# 查看正负样本的概率
# 第一列就是P(y=0)的概率 第二列就是P(y=1)概率
# 如果P(y=0) > P(y=1) 预测结果为0 反之亦然
# 隐藏的逻辑是: 逻辑斯蒂回归默认的是看哪个分类的概率值高于0.5 (阈值)
# 如果把阈值调整,就可以影响到我们对正负样本的预测结果
# 举个例子:如果把P(y=0) >0.5 条件改为P(y=0)> 0.4 那么就意味着我们更加倾向于y=0的结果
lr.predict_proba(X)
array([[0.39799317, 0.60200683],
[0.47356658, 0.52643342],
[0.53186764, 0.46813236],
[0.52494617, 0.47505383],
[0.56763617, 0.43236383],
[0.46772714, 0.53227286],
[0.5164642 , 0.4835358 ],
[0.46524313, 0.53475687],
[0.50749225, 0.49250775],
[0.54706982, 0.45293018]])
lr.predict(X)
array([1, 1, 0, 0, 0, 1, 0, 1, 0, 0])
# 调整阈值
(lr.predict_proba(X)[:,0] > 0.6)*1
array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0])
(lr.predict_proba(X)[:,0] < 0.52)*1
array([1, 1, 0, 0, 0, 1, 1, 1, 1, 0])
lr.predict_proba(X)[:,1]
array([0.60200683, 0.52643342, 0.46813236, 0.47505383, 0.43236383,
0.53227286, 0.4835358 , 0.53475687, 0.49250775, 0.45293018])
梯度下降
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
%matplotlib inline
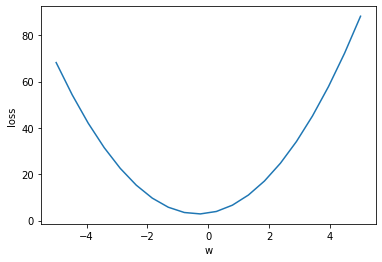
线性回归的损失函数 Loss = ((y-y_)**2).sum()
# 假设当前有损失函数
# f(x) = 3*x**2 + 2*x + 3.2
f = lambda x: 3*x**2 + 2*x + 3.2
x = np.linspace(-5, 5,20)
y = f(x)
plt.plot(x,y)
plt.xlabel('w')
plt.ylabel('loss')
Text(0, 0.5, 'loss')
# 使用梯度下降来找到loss的最小值的w的值
# f(x) = 3*x**2 + 2*x + 3.2
# 对上述的函数求导: g(x) = f'(x) = 6*x + 2
g = lambda x: 6*x + 2
# 梯度下降公式
w1 = w0 - step*g(w0)
h = np.abs(w0 - w1)
# w0 表示梯度下降的起始点
# w1 表示下降之后的点
# step 表示步长(学习率)
# g(x)函数 是对损失函数f(x)求导的函数
w0 = np.random.randint(-5,5,1)[0]
print('梯度下降的起始点:%d'%(w0))
# 下降之后的点 先随便初始化一个在w0附近的值
w1 = w0 +1
# 学习率(步长)
# 不能太长 容易跳过最优解 容易梯度震荡 梯度爆炸
# 不能太小 找不到最优解
step = 0.01
# 我们还需要设置一个精度 用来限制下降的水平
# 如果两次位移 所产生的的下降幅度很小 小到可以忽略 则停止下降
precision = 0.001
# 下降次数 最大迭代次数
max_count = 3000
# 记录当前下降的次数
current_count = 1
# 记录所有下降的位置
points = []
while 1:
if current_count> max_count:
break
# 如果上一次和当前下降的距离 < 预设的精度
if np.abs(w0-w1) <= precision:
break
# 更新上次的点
w0 = w1
# 重新计算下降的点
w1 = w0 - step*g(w0)
points.append(w1)
current_count += 1
print('当前第%d次下降的位置:%.4f'%(current_count,w1))
梯度下降的起始点:-5
当前第2次下降的位置:-3.7800
当前第3次下降的位置:-3.5732
当前第4次下降的位置:-3.3788
。。。。。。
当前第87次下降的位置:-0.3513
当前第88次下降的位置:-0.3502
当前第89次下降的位置:-0.3492
当前第90次下降的位置:-0.3482
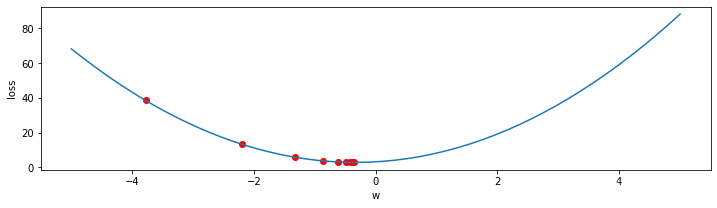
w = np.array(points)[::10]
value = f(w)
x = np.linspace(-5,5,50)
y = f(x)
plt.figure(figsize=(12,3))
plt.plot(x,y)
plt.xlabel('w')
plt.ylabel('loss')
plt.scatter(w,value,color = 'red')
<matplotlib.collections.PathCollection at 0x154b5a16400>