背景
常听有人说,Mysql数据库单张表的数据,最多不要超过千万级别,否则需要分表处理。那这个结论是如何来的呢,是否正确呢?今天来探讨一番。
一、页的结构
前面讲过,Mysql在读取数据时,是一页一页的读数据,称之为预读。那页的结构到底是怎样的呢?
Mysql表中的数据,在硬盘上存成了.ibd文件,这个文件,专业名词叫表空间。在.ibd文件的内部,把表数据分成了很多份的数据页,每份大小16k。类似于下图所示:
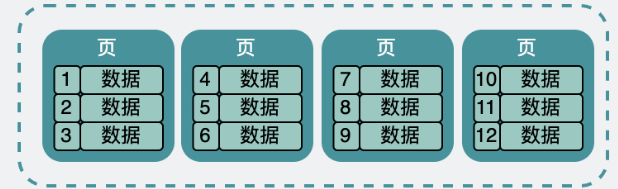
每页中,不仅只有表数据,还有一些其他信息,具体如下:
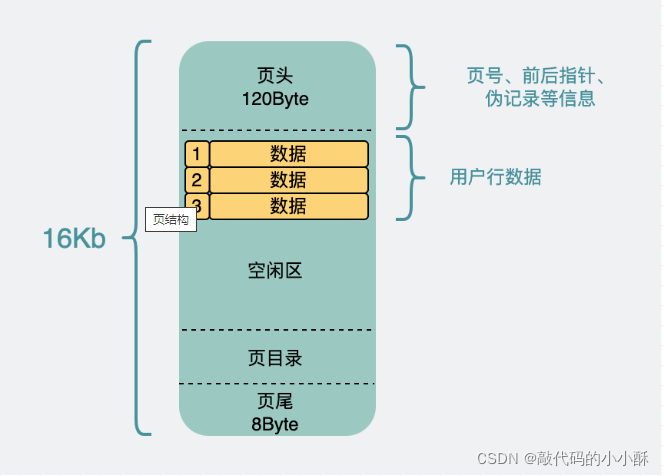
页头:页头占120字节大小,里面包括页号(ibd文件里的偏移量),指针(指向前一页和后一页)等信息。
页尾:页尾占8字节,包含校验码等信息。
页目录:行数据太多的话,进入每页中,挨个遍历,效率也不高,页目录是提高页内数据搜索的效率。
剩下的就是表数据的区域。
二、B+tree索引与页
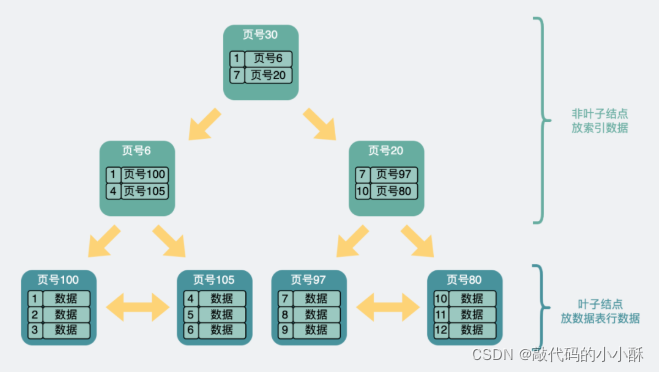
Mysql索引也是一个文件,在索引文件的内部,也会按页,进行数据的切分。每页的大小固定都是16k。以主键索引为例,在主键索引中,非叶子节点,只存放了数据的主键id,不存放数据的其他信息。因此,在非叶子节点的每个页中,就能存放更多的索引信息。
因为索引是树形结构,所以在非叶子节点的页中,还会有指向下级节点的指针,专业名词叫扇出。B+tree索引每个非叶子都扇出到下一级节点,直到叶子节点的页中。
叶子节点的页里,存放的就是完整的行数据了(仅针对主键索引,二级索引叶子节点是索引列+id)。
如下图所示:
三、单表最多行数的计算
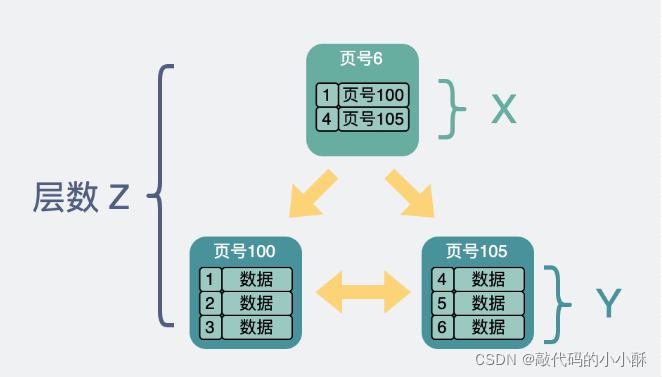
上图中,x表示非叶子节点,每页中的数据行数。
y表示叶子节点,每页中的数据行数。
z表示B+tree树的高度。
那么,这个B+tree的行数总量就是:(x ^ (z-1)) * y。
x的计算:
页16k,页头120b,页尾8b,剩余大约15k的空间来存索引数据。主键索引包括主键列和页号两部分组成。主键假设是bigint类型,占8b,页号专业名词是FIL_PAGE_OFFSET,占4b,也就是索引数据大约12b。
剩余的15k里,每条索引数据12b,那么就可以放1280条索引数据,即每个非叶子节点有1280个扇出。
y的计算
叶子节点与非叶子节点页的结构一样,所以也有15k的空间存放数据,在主键索引中,叶子节点存放的是整条记录,这里假设整条记录是1kb,所以叶子节点每个页就能存放15条完整数据,即y=15。
z的计算
z代表树的高度,树越高,查询效率就越低,所以,一般维持树在三层高度。这样,查询数据时,最多进行3次IO,就可以查询到数据。即z=3。
x=1280,y=15,z=3,套入上述公式,得:(x ^ (z-1)) * y=(1280 ^ (3-1)) * 15 ≈ 2.5kw。
所以,单表最多可以存放2.5kw数据。
计算y时,我们假设的一条数据1kb。而单条数据达到1kb,算是比较大的数据了。一般一条数据也就300b左右。如果按300b一条计算,则y=45。那么总行数就是:2.5kw*3=7.5kw。即单表可以存七八千万条数据。
四、联合索引的情况考虑
上面的计算方式,是按照主键索引来计算的。而真实生产中,肯定会涉及到多条件查询。大数据量的情况下,肯定要创建联合索引。那么考虑到联合索引,如何计算单表最大行数呢?
假设一条多条件查询sql命中了索引,则首先是在联合索引中查询数据,分两种情况讨论:
索引覆盖情况:
即通过联合索引,就可以返回sql所需的字段,无需回表查询。
x的计算:
索引数据的空间还是剩余15k大小,但是,与主键索引不同的是,联合索引每个非叶子节点,会把索引列所有的字段都存起来,其大小肯定比主键索引的id要大。我们假设联合索引有三个字段,每个字段都是varchar类型,且每个字段的值都是5个字(utf8编码),那么每个字段就是15b,三个字段就是45b。
所以,一条数据的索引大小为45b,那么15k,能存300条数据,也就是300个扇出。
y的计算
联合索引的叶子节点,存放的还是那几个联合索引列+id列。这里看成和x值相等,45b,一个页也能存300条数据。
z还按3计算。那么总数是:(x ^ (z-1)) * y=300^2*300=2.7kw。
这是按照联合索引3个字段,每个字段5个汉字计算的。如果按照3个索引列,每个字段10个汉字计算,10个utf8编码的汉字占用字节为:103=30b。三个字段就是90b。15k就能存150条数据,即x=y=150。
z还按3计算,则总条数为:150^2150=330w。
由此可见,在索引覆盖的情况下,一张表能存多少数据,跟索引列大小有直接关系。索引列小时,千万级别数据没问题,索引列大时,能存百万级别数据。
索引回表情况:
在联合索引需要回表的情况下,需要先联合索引需要几次回表,然后主键索引需要几次回表。这些确定了,才能计算有多少数据量,这里情况复杂,不再详细计算。
五、buffer_pool_size参数考虑
关于Innodb_buffer_pool_size:《深入浅出MySQL》一文中这样描述Innodb_buffer_pool_size:
该参数定义了 InnoDB 存储引擎的表数据和索引数据的最大内存缓冲区大小。和 MyISAM 存储引擎不同, MyISAM 的
key_buffer_size只缓存索引键, 而 innodb_buffer_pool_size 却是同时为数据块和索引块做缓存,
这个特性和 Oracle 是一样的。这个值设得越高,访问 表中数据需要的磁盘 I/O 就越少。在一个专用的数据库
服务器上,可以设置这个参数达机器 物理内存大小的 80%。尽管如此,还是建议用户不要把它设置得太大, 因为对物理内存的竞
争可能在操作系统上导致内存调度。
可见,Mysql的索引,是可以在bufferpool中缓存的,所以,并不是每个节点,都需要进行一次IO的。这也是为何上面的联合索引,需要回表的情况,我没有进一步讨论的原因。考虑到缓存等,情况很复杂。
六、总结
综上所述,对于单条数据量小,涉及字段少的表,存千万级别的数据,是没问题的,多者可以达到七八千万条数据。而对于单条数据量大,字段多的表,百万级别的量,是可以承受的,至于能不能存放千万级别的数据,能存放几千万的数据,这就需要根据实际情况,进行性能的判断和判别了。无法通过理论的计算,来获得一个很准确的值。
参考文章:https://mp.weixin.qq.com/s/mLosK11gCTFEzQlUjSPgtA

