目录
1、ConcurrentHashMap
在JDK1.4之前只有vector和HashTable是线程安全集合,在JDK 1.5时开始增加了安全的Map接口ConcurrentHashMap和线程安全的队列BlockingQueue
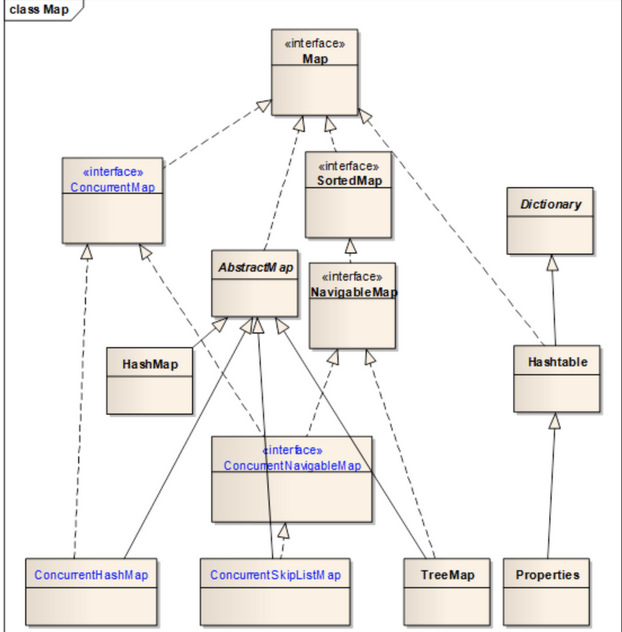
通过继承关系图可知:
ConcurrentHashMap是HashMap的安全版本
2、ConcurrentMap
也是键值对形式来存储数据
public interface ConcurrentMap<K, V> extends Map<K, V> {
实现自Map接口,及Map中所有的接口ConcurrentMap同样具有

特有方法说明:
//如果指定键已经不在和某个值关联,则他和给定值关联
V putIfAbsent(K key, V value);
//只有目前将键映射到给定的value时,才移除该键值对 返回值Boolean类型, true:成功 false:失败
boolean remove(Object key, Object value);
//只有当key和oldValue同时存在时,才会将oldValue替换为newValue
boolean replace(K key, V oldValue, V newValue);
//只有在集合中存在该key,才完成替换
V replace(K key, V value);提供的原子操作方法
3、ConcurrentHashMap
线程安全的?如何体现出线程安全?
总结ConcurrentHashMap的特点?
继承结构、默认值和属性、构造函数、底层数据结构、扩容机制、常见方法
说明线程安全性如何体现?
//用来存储数据 是一个Segment数组
final Segment<K,V>[] segments;
//segment是继承自ReentrantLock,实现了锁机制
static final class Segment<K,V> extends ReentrantLock implements Serializable {
//重入次数 加锁操作发送冲突需要考虑重入问题
static final int MAX_SCAN_RETRIES =
Runtime.getRuntime().availableProcessors() > 1 ? 64 : 1;
//数据存放在table中,是volatile修饰
transient volatile HashEntry<K,V>[] table;
Segment(float lf, int threshold, HashEntry<K,V>[] tab) {
this.loadFactor = lf;
this.threshold = threshold;
this.table = tab;
}
}
static final class HashEntry<K,V> {
final int hash;
final K key;
volatile V value;
volatile HashEntry<K,V> next;
HashEntry(int hash, K key, V value, HashEntry<K,V> next) {
this.hash = hash;
this.key = key;
this.value = value;
this.next = next;
}
}
ConcurrentHashMap是segment数组+链表,即哈希表结构。
通过源码可知:Segment类继承自ReentrantLock类,其本质是一把锁,称之为分段锁
构造函数中concurrencyLevel称之为并发度,该参数是用来实例化segment数组的大小,默认的大小是16个,即同一时刻并发的线程量至少是16个,在ConcurrentHashMap中变更操作(put,remove,replace)加锁处理,针对get读操作是可以共享操作,读操作可以同时有多个线程操作。
并发度concurrencyLevel默认是16,也可以自行指定,指定的并发度需要满足2的倍数形式,目的方法快速的进行key哈希找到对应存储位置,并发度一旦确定之后是不再改变的,在ConcurrentHashMap使用过程中数量超过扩容阈值时,也只是对segment下的哈希表进行扩容。
分段锁将数据分成一段一段的存储,然后给每一段数据进行加锁,当一个线程占用锁访问其中一段数据时,其他段的数据也会被其他线程访问。

在每个线程操作是只会锁住其中一个segment,不同的线程在操作ConcurrentHashMap时只要所操作的数据在不同的segment中,线程之间是互不干扰的。
ConcurrentHashMap的高并发主要来源于:
1、采用分段锁实现多个线程间的共享访问。
2、用HashEntry对象的不变性来降低执行读操作的线程,在遍历链表期间对加锁的要求。
3、对于同一个volatile变量的读/写操作,协调不同线程间的读写内存的可见性问题。
1.8之后底层换成了CAS,把锁分段机制放弃了,CAS基本上是可以达到无锁境界
CAS + volatile 无锁编程
ConcurrentHashMap的put流程-jdk1.7为例
public V put(K key, V value) {
//key,value不能为null
Segment<K,V> s;
if (value == null)
throw new NullPointerException();
//通过key进行哈希到对应segment位置
int hash = hash(key);
int j = (hash >>> segmentShift) & segmentMask;
//通过位置j获取当前的对应segment起始位置
if ((s = (Segment<K,V>)UNSAFE.getObject // nonvolatile; recheck
(segments, (j << SSHIFT) + SBASE)) == null) // in ensureSegment
s = ensureSegment(j);
return s.put(key, hash, value, false);
}
#内部类Segment下的put方法
final V put(K key, int hash, V value, boolean onlyIfAbsent) {
//尝试性加锁
HashEntry<K,V> node = tryLock() ? null :
scanAndLockForPut(key, hash, value);
V oldValue;
try {
//当前segment下的table
HashEntry<K,V>[] tab = table;
//通过key的哈希值进行哈希找到对应table位置
int index = (tab.length - 1) & hash;
HashEntry<K,V> first = entryAt(tab, index);
for (HashEntry<K,V> e = first;;) {
if (e != null) {
K k;
if ((k = e.key) == key ||(e.hash == hash && key.equals(k))) {
oldValue = e.value;
if (!onlyIfAbsent) {
//put方法处理:将新value替换oldvalue
e.value = value;
++modCount;
}
break;
}
e = e.next;
} else {
if (node != null)
node.setNext(first);
else
node = new HashEntry<K,V>(hash, key, value, first);
int c = count + 1;
if (c > threshold && tab.length < MAXIMUM_CAPACITY)
//超过扩容阈值
rehash(node);
else
setEntryAt(tab, index, node);
++modCount;
count = c;
oldValue = null;
break;
}
}
} finally {
//释放锁
unlock();
}
return oldValue;
}
//扩容仅针对某个segment进行扩容,而不是对整个ConcurrentHashMap进行扩容
private void rehash(HashEntry<K,V> node) {
//在segment下的table
HashEntry<K,V>[] oldTable = table;
int oldCapacity = oldTable.length;
//按照原大小2倍关系进行扩容
int newCapacity = oldCapacity << 1;
threshold = (int)(newCapacity * loadFactor);
HashEntry<K,V>[] newTable =(HashEntry<K,V>[]) new HashEntry[newCapacity];
int sizeMask = newCapacity - 1;
//将原有table上的所有hashentry节点进行重新哈希到新table上
for (int i = 0; i < oldCapacity ; i++) {
HashEntry<K,V> e = oldTable[i];
if (e != null) {
HashEntry<K,V> next = e.next;
int idx = e.hash & sizeMask;
if (next == null) // Single node on list
newTable[idx] = e;
else { // Reuse consecutive sequence at same slot
HashEntry<K,V> lastRun = e;
int lastIdx = idx;
for (HashEntry<K,V> last = next;
last != null;
last = last.next) {
int k = last.hash & sizeMask;
if (k != lastIdx) {
lastIdx = k;
lastRun = last;
}
}
newTable[lastIdx] = lastRun;
// Clone remaining nodes
for (HashEntry<K,V> p = e; p != lastRun; p = p.next) {
V v = p.value;
int h = p.hash;
int k = h & sizeMask;
HashEntry<K,V> n = newTable[k];
newTable[k] = new HashEntry<K,V>(h, p.key, v, n);
}
}
}
}
int nodeIndex = node.hash & sizeMask; // add the new node
node.setNext(newTable[nodeIndex]);
newTable[nodeIndex] = node;
table = newTable;
}
