概览
Redis 本质是 K-V 键值对数据库,底层通过字典 dict 存储键值映射关系,除此之外,dict 还作为 Redis hash 结构底层的实现之一。
讨论 Redis 的数据结构,可以从两个层面出发。
第一个层面从使用者角度出发,即 Redis 暴露给外部调用的 Api:
- string
- list
- hash
- set
- sorted set
第二个层面是 Redis 的内部实现角度出发,是更为底层的数据结构实现:
- dict
- sds
- ziplist
- quicklist
- skiplist
Redis 这么做的目的还是基于高性能的考虑,在不同的场景下使用不同的底层数据结构实现,最大程度提升内存操作的效率。
例如当 sorted set,hash 存储的数据规模较小时,底层都是通过 ziplist 实现,而当数据规模达到一定量时,sorted set 会转换成 dict + skiplist 的底层实现,hash 会转换成 dict 的底层实现。
本文主要讨论是 Redis 关于 dict 这一底层数据结构的实现原理。
实现
dict 的实现与 java jdk 中 hashmap 的实现有许多相似之处:
- 关于哈希映射,key 的索引计算公式为 hash & (n - 1),其中 hash 为 key 对应的 hash 值(Redis 通过 MurmurHash 算法计算得出),n 为哈希数组的大小
- 关于哈希冲突,Redis 同样也是采用链地址法解决冲突
dict 在扩缩容的情况下,采用的是渐进式的 rehash 方式,这是它的特殊之处,下文会主要讲到。
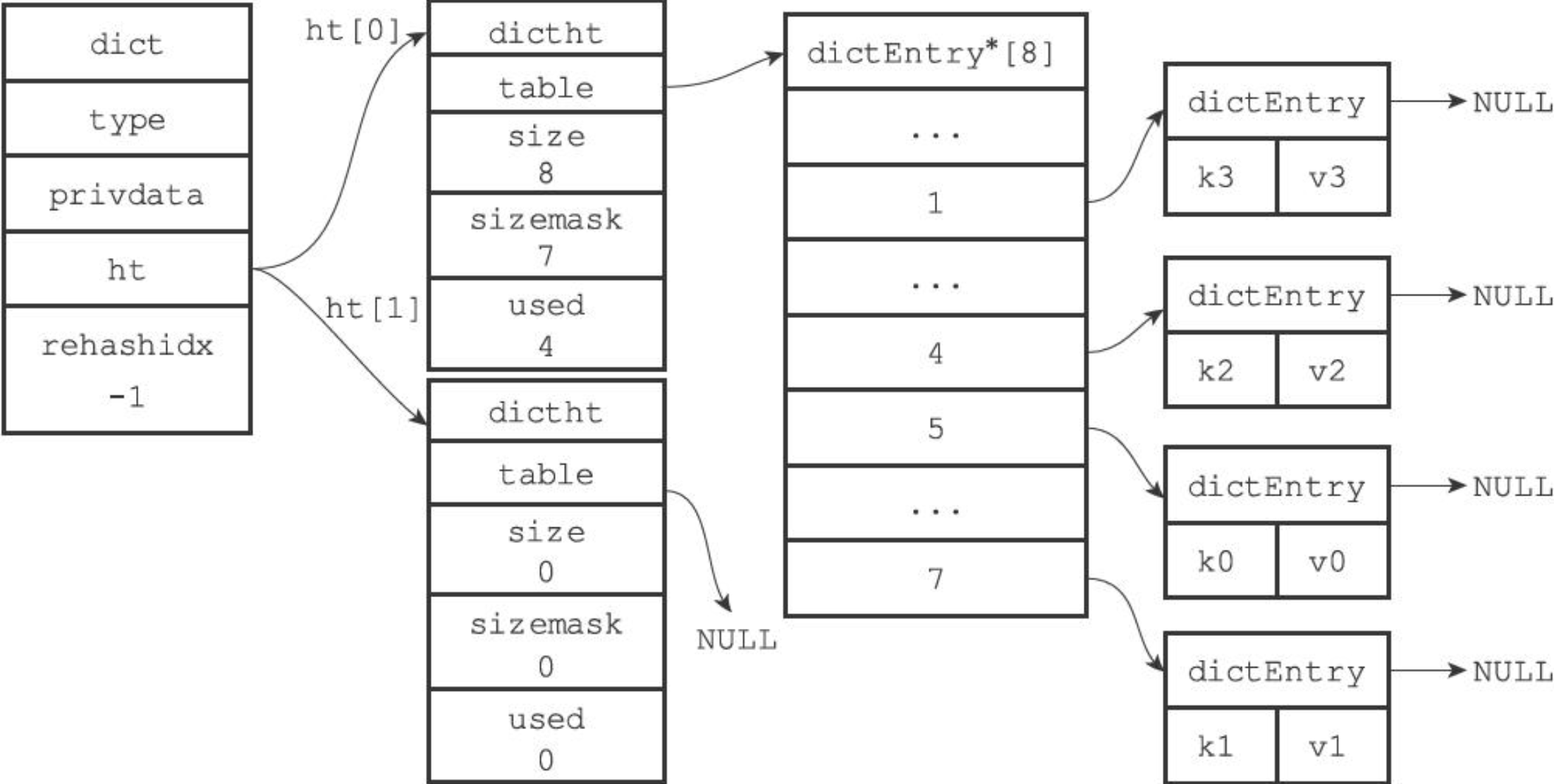
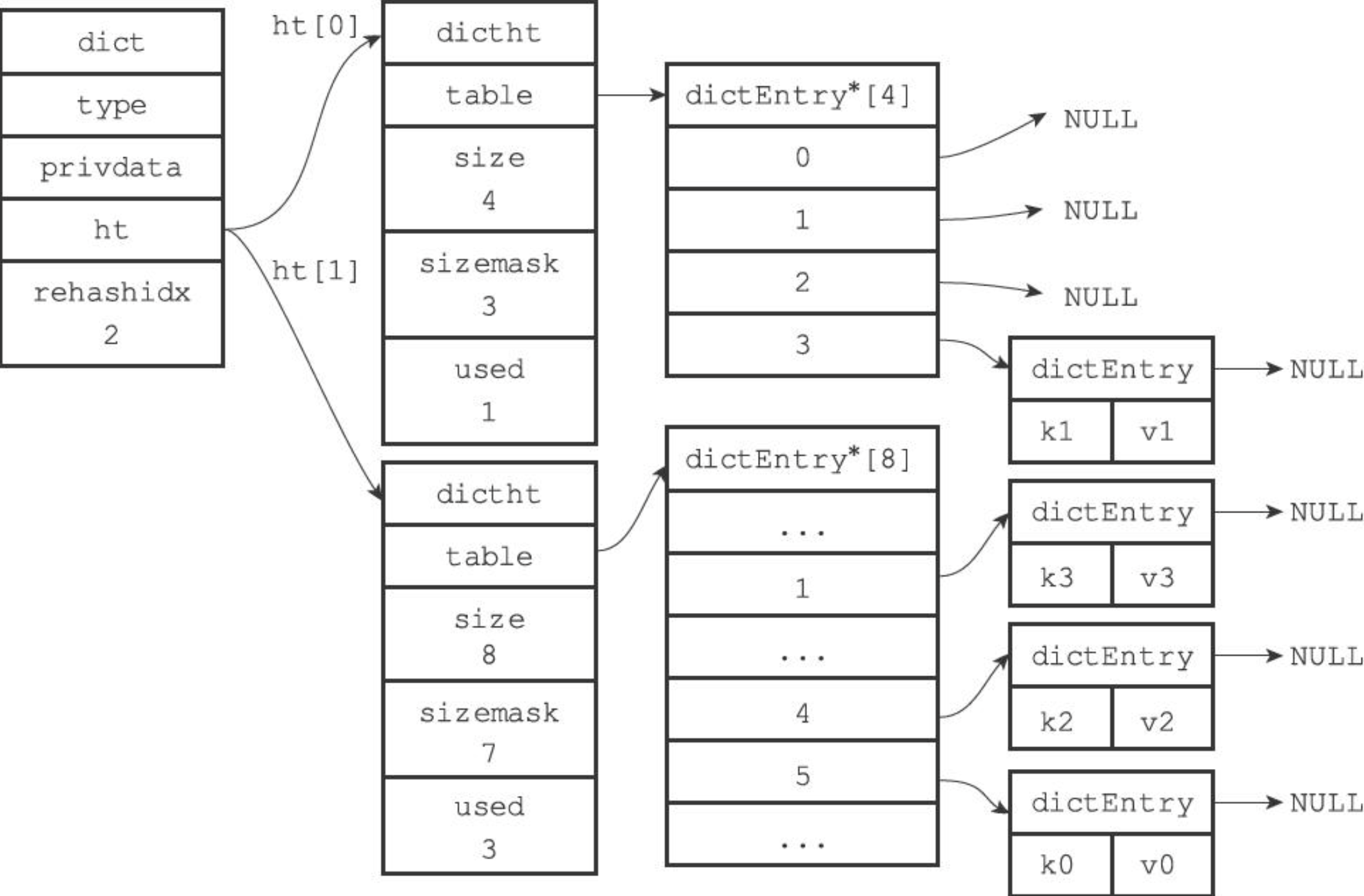
dict 的数据结构如下:
- type属性是一个指向dictType结构的指针,每个dictType结构保存了一簇用于操作特定类型键值对的函数,Redis会为用途不同的字典设置不同的类型特定函数
- privdata属性则保存了需要传给那些类型特定函数的可选参数
- ht[2] 数组中存放了两张哈希表,只有在 rehash 的过程中,ht[0] ht[1] 才都有效;正常情况下只有 ht[0] 有效,ht[1] 中没有任何数据
- rehashidx 用来表示 rehash 过程到了哪一个索引位置,正常情况下 rehashidx = -1,表示当前没有进行 rehash

dictht 的数据结构如下:
- dictEntry 数组,用来存放键值对
- size 表示当前 dictEntry 数组的大小
- sizemask,值为 size - 1,在计算 key 的索引位置时用到, index = hash & sizemask
- used 记录现有 dict 的数据个数

正常情况下,dict 整体的数据结构如下图所示:
rehash
随着操作不断执行,哈希表中的键值对会逐渐增加或减少,为了让哈希表的负载因子(负载因子 = 已保存节点数量/哈希表大小)维持在一个合理的范围内,当哈希表中节点数量过多或者过少时,Redis 会对哈希表进行相应的扩容或缩容,这一过程称为 rehash。
在 rehash 操作开始前,首先要为哈希表 ht[1] 分配内存,ht[1] 之前一直是空闲状态,终于要派上用场了,具体内存分配策略如下:
- 如果是扩容操作,ht[1]的大小为第一个大于等于ht[0].used*2的2^n(2的n次方幂),举个例子 ht[0].used = 5,触发了扩容操作,即 ht[1].size = 5 * 2 = 10,但 10 不符合 2^n 要求,则继续往下找到第一个符合要求的数 16,即 ht[1].size = 16
- 如果是缩容操作,ht[1]的大小为第一个大于等于ht[0].used的2^n(2的n次方幂),举个例子 ht[0].used = 5,触发了缩容操作,则 ht[1].size = 8
ht[1] 分配完内存之后,接着进行如下操作:
- 将 ht[0] 的中的节点重新计算哈希值和索引值,映射到 ht[1] 上
- 当ht[0]包含的所有键值对都迁移到了ht[1]之后(ht[0]变为空表),释放ht[0],将ht[1]设置为ht[0],并在ht[1]新创建一个空白哈希表,为下一次rehash做准备
哈希表触发扩容的时机如下:
- 服务器目前没有在执行BGSAVE命令或者BGREWRITEAOF命令,并且哈希表的负载因子大于等于1
- 服务器目前正在执行BGSAVE命令或者BGREWRITEAOF命令,并且哈希表的负载因子大于等于5,这么做的原因是避免在子进程存在期间进行哈希表扩容操作,从而避免不必要的内存写入操作,最大限度节省内存
负载因子的计算公式:

当负载因子小于 0.1 时,触发缩容操作。
渐进式rehash
值得注意的是 rehash 的过程,Redis 并不是一次性将所有元素集中式地 rehash 到 ht[1] 中,而是分多次,渐进式地完成。
这么做的原因是如果当哈希表中存放的键值对数量如果是千万级,甚至亿级,一次性完成所有键值的 rehash 操作,可能会导致 Redis 一段时间内对外不可用。
以下是渐进式 rehash 的具体步骤:
- 为ht[1]分配空间,让字典同时持有ht[0]和ht[1]两个哈希表
- 在字典中维持一个索引计数器变量rehashidx,并将它的值设置为0,表示rehash工作正式开始
- 在rehash进行期间,每次对字典执行添删改查操作时,程序除了执行指定的操作以外,还会顺带将ht[0]哈希表在rehashidx索引上的所有键值对rehash到ht[1],当rehash工作完成之后,程序将rehashidx属性的值增一
- 随着字典操作的不断执行,最终在某个时间点上,ht[0]的所有键值对都会被rehash至ht[1],这时程序将rehashidx属性的值设为-1,表示此次rehash操作已完成
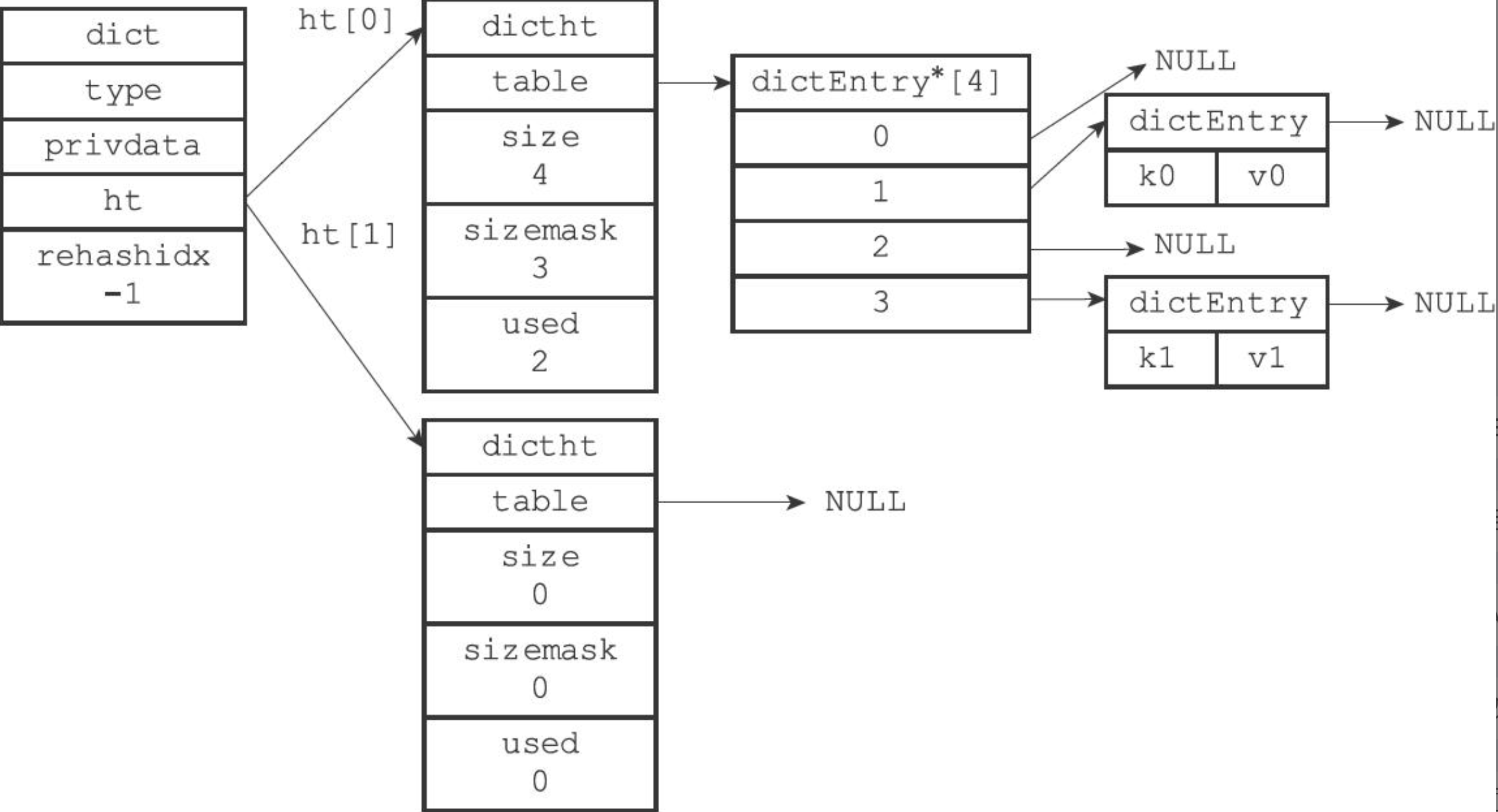
下面展示一次完整 rehash 的过程,首先初始化 dict,准备开始 rehash;

rehashidx = 0,rehash 索引0对应的键值对,rehashidx + 1;
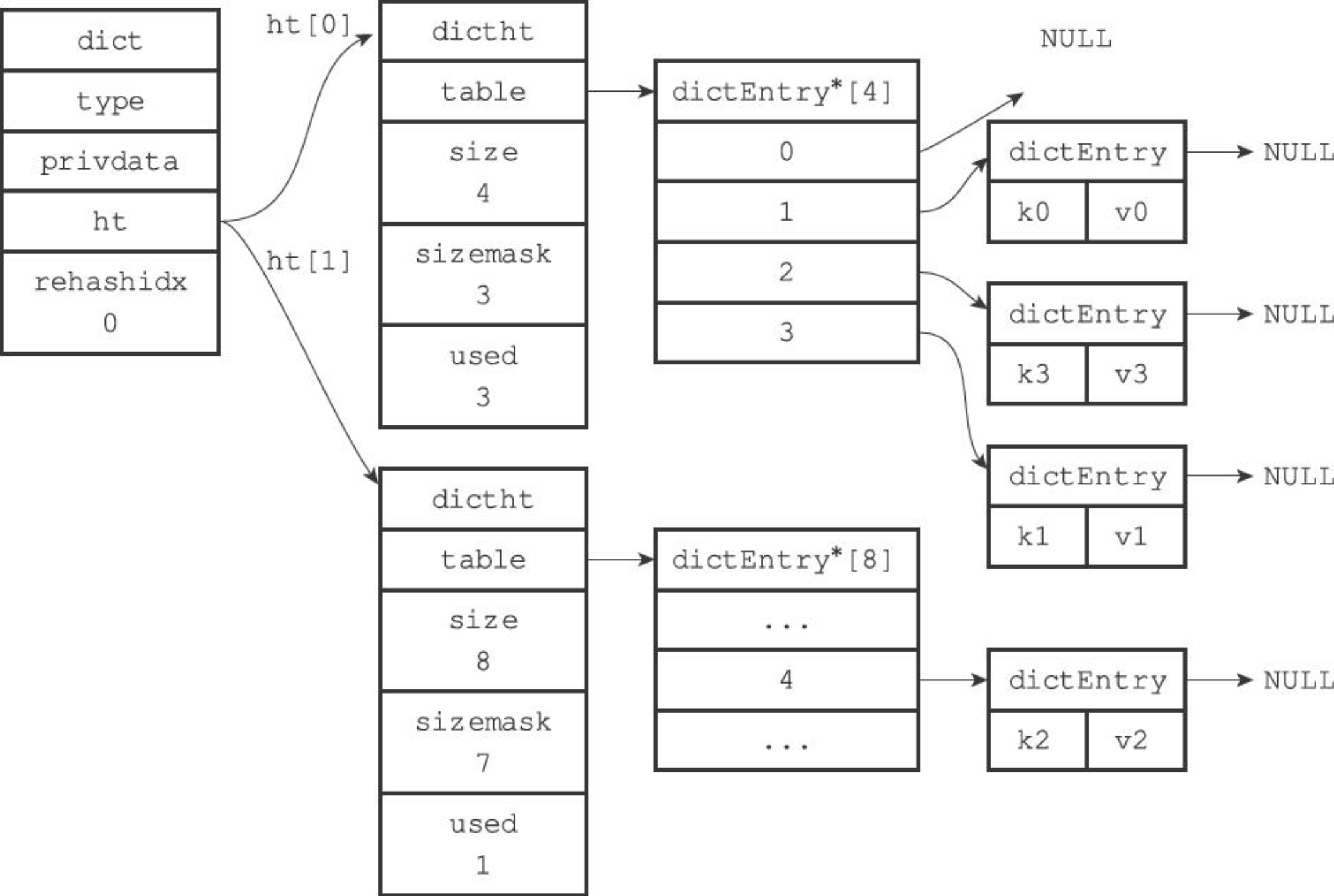
rehashidx = 1,rehash 索引1对应的键值对,rehashidx + 1;
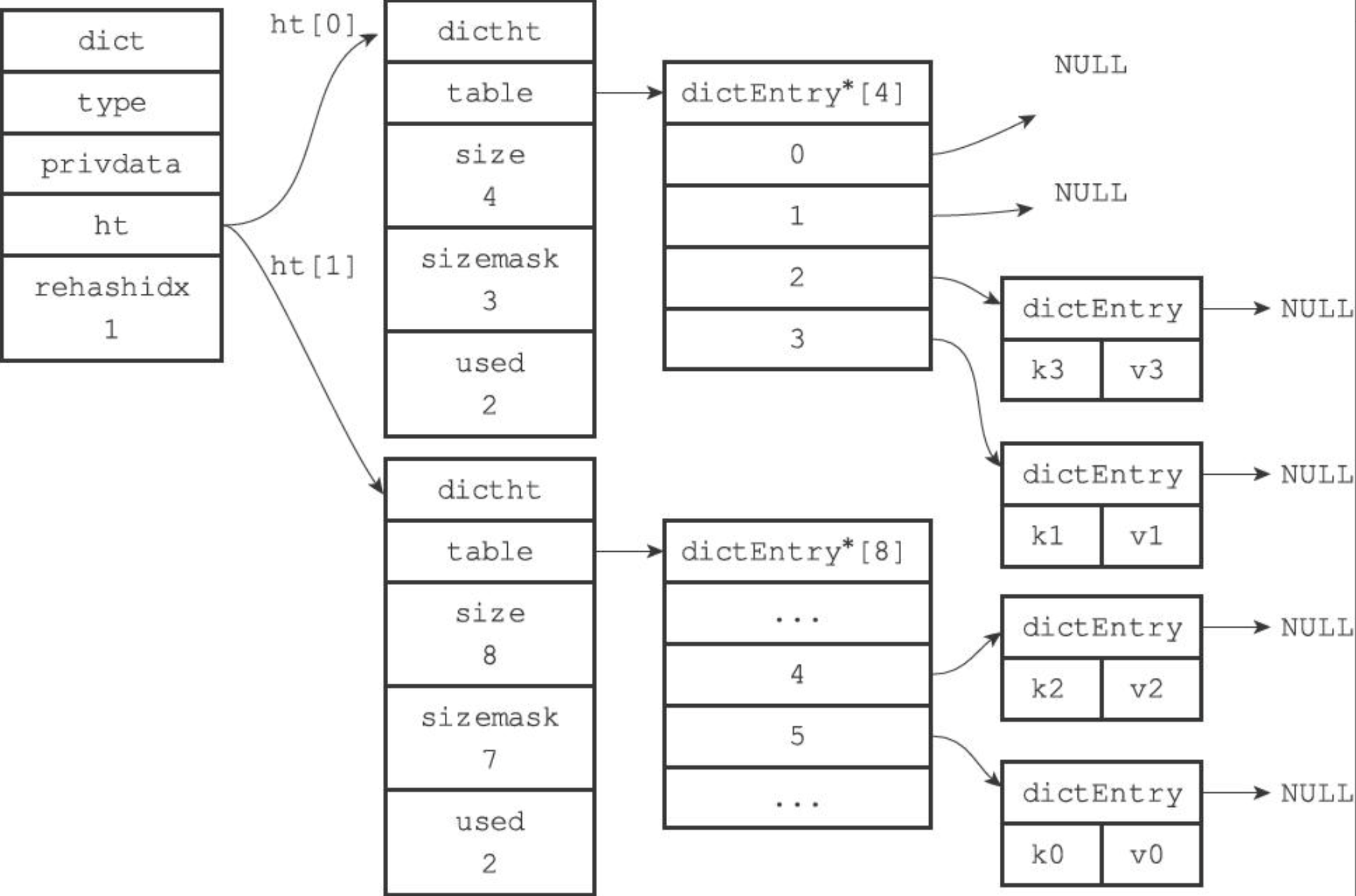
rehashidx = 2,rehash 索引2对应的键值对,rehashidx + 1;
最终完成 rehash 过程。