Ŀ¼
�����Ͳο��鼮:scikit-learn����ѧϰ�C�����㷨ԭ�������ʵս
�㷨ԭ��
һ���мල�Ļ���ѧϰ�㷨,�����ڽ������ͻع�����
**����˼��:**һ��Ϊ����ǵ���������ɾ����������k���ھӾ���
ʹ��һ���Ѿ���ǵ�������������ѵ��,������������ǩ
�������ǵ��������������ݼ���ÿ�������ľ���,ȡ���������k������,�۲���K���������������,���������Ǹ����Ϊ��������������ڵ����
�㷨��ȱ��
| �ŵ� | ȷ�Ը�,�쳣ֵ�������Խ��Ӱ����Խ�С |
| ȱ�� | ���ڴ�����ϴ�,ÿ��һ���������з����Ҫ������ȫ������һ�� |
�㷨����
Knn�㷨��һ�������������ھӵ��Ȩ��,���ǿ��Ը����������㲻ͬ�����������ָ����ͬ��Ȩ��,����Խ��Ȩ��Խ��,����㷨���ֿ���ͨ��KNeighborsClassifier���е�weight����ָ��
sklearn.KNeighborsClassifier
sklearn.neighbors.KNeighborsClassifier(n_neighbors=5, *, weights='uniform', algorithm='auto', leaf_size=30, p=2, metric='minkowski', metric_params=None, n_jobs=None)
��Ҫ����
n_neighbors
�������������������ھӸ��� ��
ֵԽ��,�����������ھ�Խ��,ģ�͵�ƫ��Ҳ��Խ��,����������Ҳ���ò�����;ֵ������ܻ����ģ��Ƿ���,ֵ��С������෴��Ч��
weights
| ����ȡֵ | ���� |
|---|---|
| uniform | ƽ��Ȩ��,���������㲻ͬ���ھӾ�����ͬ��Ȩ�� |
| distance | Ȩ��ȡ�����ھӾ���������ľ��� |
| [callable] | �Զ���Ȩ�ط��䷽�� |
algorithm
���ڼ�������ھӵ��㷨
| ����ȡֵ | ���� |
|---|---|
| ��ball_tree�� | BallTree�㷨 |
| ��kd_tree�� | KDTree�㷨 |
| ��brute�� | ǿ������ |
| ��auto�� | ���Ը�������Ѱ������ʵķ����㷨���ݸ�fit() |
���
fit(x,y)
ʹ��ѵ�����ݼ����k���ڷ�����
x,y�ֱ��ʾѵ�����ݼ����Ӧ�ı�ǩ
keighbors()
keighbors([X, n_neighbors, return_distance])
Ѱ���������k������ھ�
��Ҫ����
x
array-like
��Ҫ��ѯ�ĵ�(һ������)
n_neighbors
int,None
�ھӸ���,Ĭ��ֵΪģ���е�n_neighbors
return_distance
bool,True
�Ƿ�ÿ���ھӾ���������ľ���
����ֵ
����������������ھ��Ǿ���������ľ���(��return_distanceΪTrueʱ����),��������:ndarray of (x.shape,n_neighbors)
����������������ھ�����ԭѵ�����ݼ��е�������������:ndarray of (x.shape,n_neighbors)
ʵ��:
predict(x)
������x����Ԥ��
ʹ��knn���з��������
����һ������50��������(3����Ⱥ)�����ݼ���Ϊѵ������,ʹ�ø����ݼ���knnģ�ͽ������,Ȼ��ʹ����Ϻ��ģ�Ͷ�ѵ�����ݽ���Ԥ��
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.neighbors import KNeighborsClassifier
x,y=make_blobs(n_samples=50,cluster_std=0.6)
clf=KNeighborsClassifier(n_neighbors=2)
clf.fit(x,y)
x_sample=[[2,-2],[0,0],[3,0]] # �������������
y_sample=clf.predict(x_sample) # ʹ����Ϲ���knnģ�ͽ���Ԥ��
y_sample
>>> array([0, 1, 1])
neighbors=clf.kneighbors(x_sample) # �鿴����������������ھ���Ϣ
>>> (array([[3.81072592, 3.87193455],
[1.81365177, 1.85249566],
[2.49118958, 2.56258328]]),
array([[45, 5],
[44, 35],
[19, 5]], dtype=int64))
'''����ĵ�һ��array�����е�Ԫ�طֱ��ʾ����(3��)��������������2���ھӵľ���
�ڶ���array�����е�Ԫ�طֱ��ʾ����(3��)��������������2����������ԭѵ�����ݼ��е�����
'''
sklearn.KNeighborsRegressor
���������Ԥ��ֵ����ɢ��,����ʹ��KNN�㷨�����������ڶ���ֵ����Ԥ��,���ع����
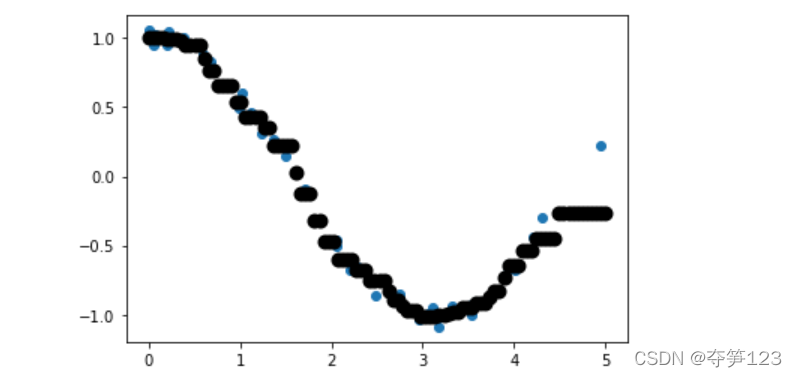
ʹ��knn���лع���ϵ�����
import numpy as np
import matplotlib.pyplot as plt
from sklearn.datasets import make_blobs
from sklearn.neighbors import KNeighborsRegressor
x=5*np.random.rand(40,1) # ����ѵ�����ݼ�
y=np.cos(x).ravel() # ravel()������y��ά����(40,1)ת��Ϊ(40,)
knn=KNeighborsRegressor(5)
knn.fit(x,y)
x_sample=np.linspace(0,5,100).reshape(-1,1) # ���ɲ�������
y_sample=knn.predict(x_sample) # ʹ��knn�ع����
plt.figure()
plt.scatter(x,y)
plt.scatter(x_sample,y_sample,c='k',lw=4)
plt.show()
������,���Կ���ģ������˴������