зЂ:БОЦЊВЉПЭВЮПМ bеО:ЛњЦїбЇЯАОЕфЫуЗЈ(2)ЁЊЁЊОіВпЪїгыЫцЛњЩСж
ЮФеТФПТМ
ОіВпЪїгаШ§жжЫуЗЈ:

вЛЁЂьигыЛљФсЯЕЪ§
ьи:вЛМўЪТЧщЕФЛьТвГЬЖШ

- ШчЙћвЛИіМЏКЯФкВПЕФЪєадКмЖр,ЛьТвГЬЖШОЭКмДѓ,дђьижЕвВНЯДѓ
- ШчЙћвЛИіМЏКЯФкВПЕФЪєадКмЩй,ЛьТвГЬЖШОЭКмаЁ,дђьижЕвВНЯаЁ
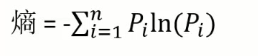

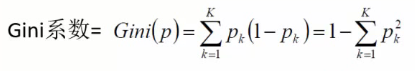
ЛљФсЯЕЪ§КЭьидкЙЋЪНЩЯУцВЛЭЌ,ЕЋЪЧБэДяЕФНсЙћЪЧЯрЭЌЕФЁЃ
- ьиКЭЛљФсЯЕЪ§дНДѓ,ЫЕУїЕБЧАЗжРраЇЙћдНВЛКУ
- ьиКЭЛљФсЯЕЪ§дНаЁ,ЫЕУїЕБЧАЗжРраЇЙћдНКУ
ЖўЁЂОіВпЪїЙЙдьЪЕР§
ЙЙдьЪїЕФЛљБОЯыЗЈЪЧЫцзХЪїЩюЖШЕФдіМг,НкЕуЕФьибИЫйЕиНЕЕЭЁЃьиНЕЕЭЕФЫйЖШдНПьдНКУ,етбљЮвУЧгаЭћЕУЕНвЛПУИпЖШзюАЋЕФОіВпЪїЁЃ
ьиНЕЕЭЕФЫйЖШдНПьдНКУ:ФмгаШ§ВНЙЙдьОіВпЪї,ОЭВЛЪЙгУЮхВНЙЙдьОіВпЪїЁЃвЊЪЙОіВпЪїЕФЗжРрВуДЮЩйЁЃ
вдДђЧђЮЊР§:
ДЫЪБЕФьиЪЧЕЅДПИљОнвдЭљЪЧЗёДђЧђРДМЦЫуЕФИХТЪ,УЛгаПМТЧЬьЦјЕШЦфЫћвђЫи:

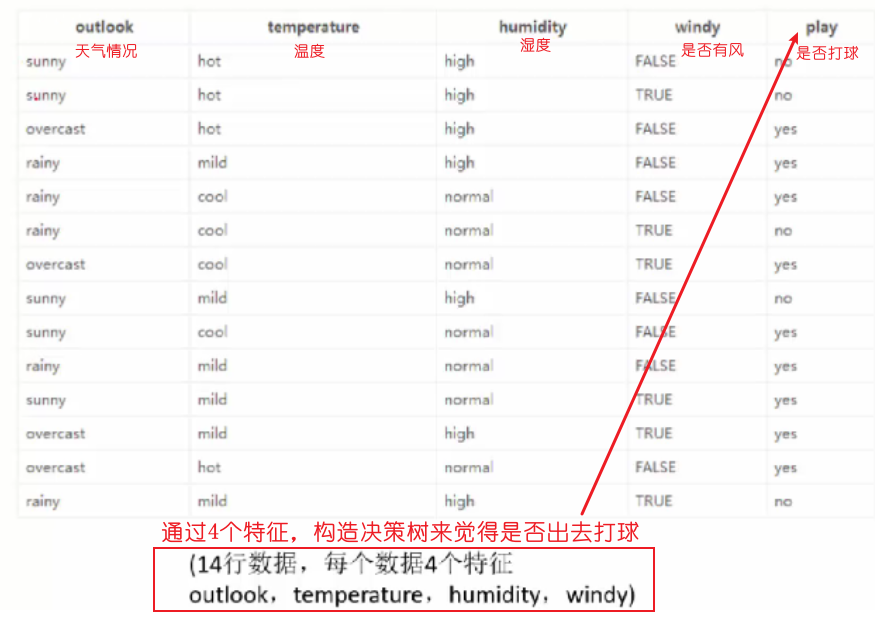

Ш§ЁЂаХЯЂдівц(ID3ЫуЗЈ)
ID3ЫуЗЈ(аХЯЂдівц):НЯЮЊДЋЭГЕФЫуЗЈ,ЪЙгУаХЯЂдівцЙЙНЈОіВпЪїЁЃ
аХЯЂдівцОЭЪЧНЋдЪМЕФьиМѕШЅгУФГИіжИБъЕБИљНкЕужЎКѓЕФьиЁЃ
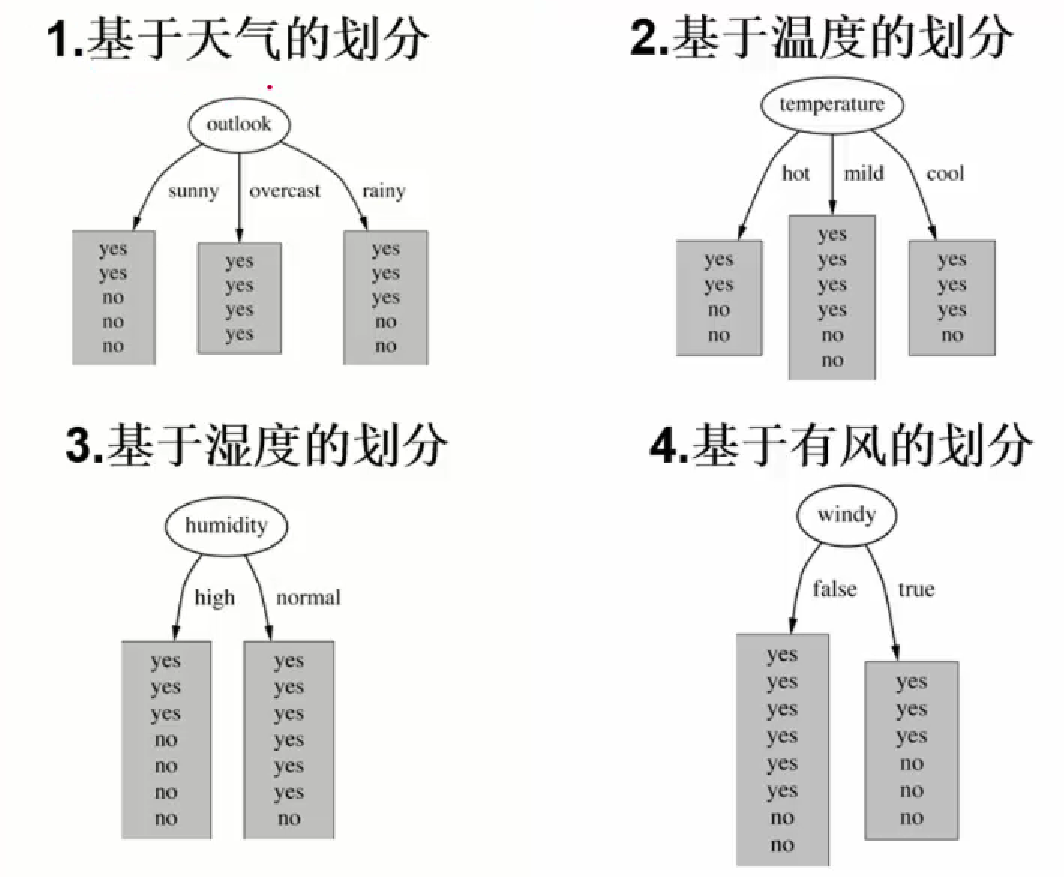
дкБОР§жаОЭЪЧШчЯТЫљЪОЕФgain(outlook)
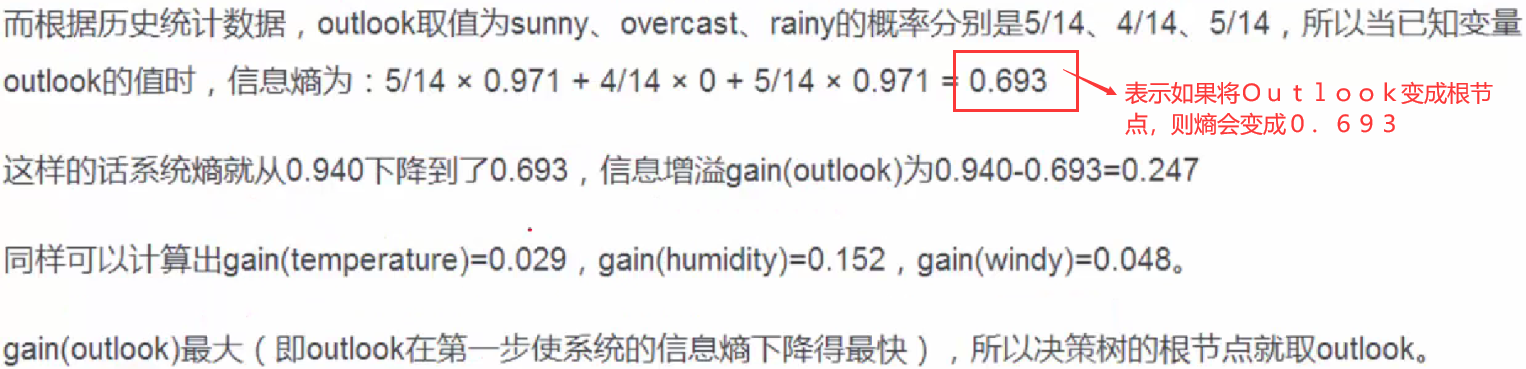
аХЯЂдівцдНДѓ,ФЧУДОіВпЪїОЭЛсдНМђНрЁЃетРяаХЯЂдівцЕФГЬЖШгУаХЯЂьиЕФБфЛЏГЬЖШРДКтСПЁЃ
вђДЫНЋЫФИіВЮЪ§ЕФаХЯЂдівцжЕМЦЫуГіРД,аХЯЂдівцзюДѓЕФОЭЪЧИљНкЕуЁЃ
ЦфгрЕФНкЕувВЪЧвЛбљЕФ,РрЫЦгквЛИіЕнЙщЕФВйзї,УПДЮЖМбЁдёЭЌРраЭЕБжааХЯЂдівцДѓЕФзїЮЊНкЕуЁЃ
ЫФЁЂаХЯЂдівцТЪ(C4.5ЫуЗЈ)
ЭЈГЃНіЪЙгУаХЯЂдівцРДЛцжЦОіВпЪїЪЧВЛППЦзЕФ,ШчЙћФГИіЬиеїДцдкЕФЪєадКмЖр,ЕЋЪЧЪєадЖдгІбљБОЕФИіЪ§КмЩй,етжжЧщПіЯТаХЯЂдівцКмДѓ,ЕЋШДЮоЗЈЕУЕНЮвУЧЯывЊЕФаЇЙћЁЃ
БШШчНЋIDвВЕБГЩвЛИіЬиеї,ФЧУДУПИібљБОЕФIDЖМЪЧВЛЭЌЕФ,ЧвУПИібљБОЗжРрЕБжажЛгаздЩэ,вђДЫДПЖШКмИп,ьиЮЊ0,аХЯЂдівцзюДѓЁЃЕЋетНЋЕМжТУПИібљБОЖМЗжГЩвЛРр,ВЛЪЧЮвУЧЦкЭћЕФЁЃ
вђДЫв§ШыаХЯЂдівцТЪЁЃ
аХЯЂдівцТЪ=аХЯЂдівц / здЩэЕФьижЕ
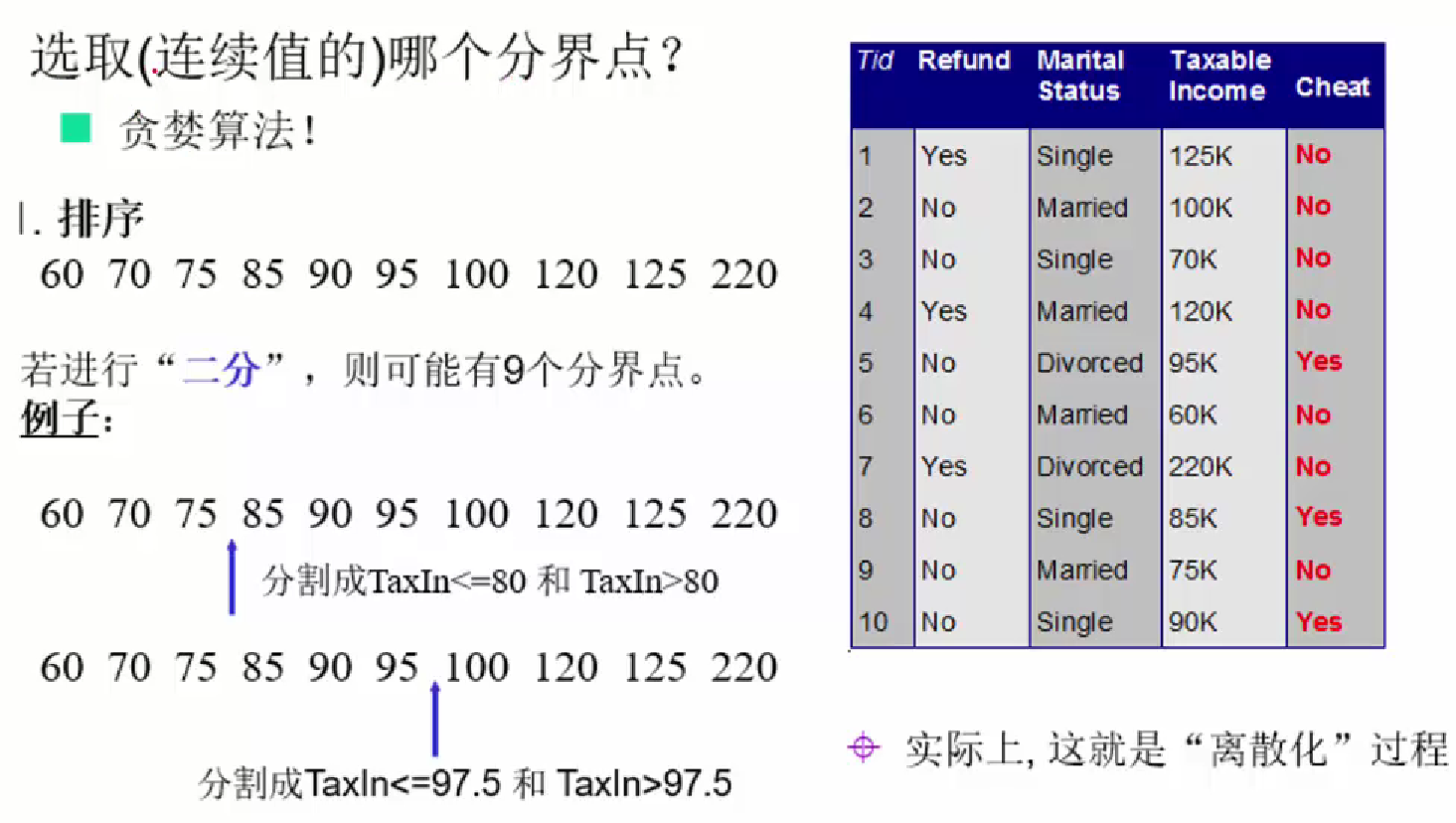
ШчКЮКтСПзюжеОіВпЪїЕФаЇЙћФи,ПЩвдЪЙгУЦРМлКЏЪ§:

етРяЪЙгУH(t)БэЪОУПИівЖзгНкЕуЫуГіЕФЛљФсЯЕЪ§ЛђепьижЕ,зюжеФПЕФЯЃЭћУПИівЖзгНкЕуЕФДПЖШКмДѓ,вђДЫЯЃЭћH(t)КмаЁЁЃ
вђДЫЦРМлКЏЪ§дНаЁдНКУЁЃ
C4.5ЫуЗЈЪЧID3ЫуЗЈЕФРЉеЙ
ФмЙЛДІРэСЌајаЭЕФЪєадЁЃЪзЯШНЋСЌајаЭЪєадРыЩЂЛЏ,АбСЌајаЭЪєадЕФжЕЗжГЩВЛЭЌЕФЧјМф,вРОнЪЧБШНЯИїИіЗжСбЕуGianжЕЕФДѓаЁЁЃ
ШБЪЇЪ§ОнЕФПМТЧ:дкЙЙНЈОіВпЪїЪБ,ПЩвдМђЕЅЕиКіТдШБЪЇЪ§Он,МДдкМЦЫудівцЪБ,НіПМТЧОпгаЪєаджЕЕФМЧТМЁЃ
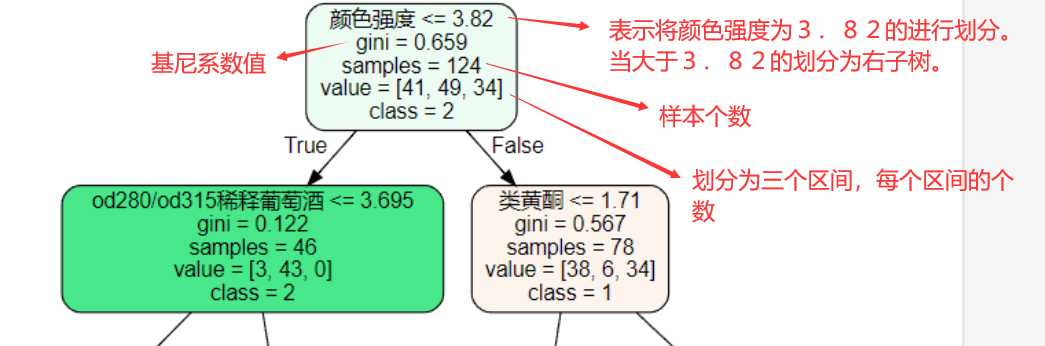

ЮхЁЂЖўЗжбЁжЕ
СљЁЂОіВпЪїМѕжІ
МДШУОіВпЪїЕФВуЪ§НЯаЁ,ИпЖШНЯАЋЁЃвђЮЊШчЙћОіВпЪїКмИпЕФЛА,зюжедкбЕСЗМЏЩЯЖМФмДяЕН100%ЕФДПЖШ,ЕЋЪЧЖдгкВтЪдМЏ,ОЭПЩФмдьГЩЮѓВю,ВњЩњЙ§ФтКЯ,вђДЫашвЊШУОіВпЪїЕФВуЪ§НЯаЁ,ИпЖШНЯАЋЁЃ
- дЄМєжІ:дкЙЙНЈОіВпЪїЕФЙ§ГЬЪБ,ЬсЧАЭЃжЙЁЃ
МДжИЖЈОіВпЪїЕФЩюЖШ,БШШчжИЖЈЮЊ3,дђЗжЕНЕкШ§ВужЎКѓОЭЭЃжЙМЬајЗжВуСЫЁЃ
ЛђепжИЖЈmin_sample,ОЭЪЧЕБбљБОаЁгк50ИіЕФЪБКђ,ОЭЭЃжЙМЬајЗжжІЁЃ

ЮЊЪВУДвЊНјаадЄМѕжІ?ЮЊСЫЗРжЙЙ§ФтКЯЕФЗчЯеЁЃ
- КѓМєжІ:ОіВпЪїЙЙНЈКУКѓ,ШЛКѓВХПЊЪМВУМєЁЃ
 вђЮЊвЖзгНкЕуИіЪ§дНЖр,дНЫіЫщ,дђдНШнвздьГЩЙ§ФтКЯЁЃ
вђЮЊвЖзгНкЕуИіЪ§дНЖр,дНЫіЫщ,дђдНШнвздьГЩЙ§ФтКЯЁЃ
зюжевЊЪЙЕУЩЯЭМЕФЙЋЪНжЕзюаЁЁЃ
ЩЯУцЙЋЪНжаЕФaжЕПЩвдЪжЙЄжИЖЈЕФ:
ШчЙћaНЯДѓ,дђвЖзгНкЕуИіЪ§вЊЩй
ШчЙћaНЯаЁ,дђвЖзгНкЕуИіЪ§ПЩвдНЯЖр
ЦпЁЂЫцЛњЩСж
ЩСж:ЖрПХОіВпЪїОЭЙЙдьСЫвЛЦЌЩСжЁЃ
ЫцЛњЩСж:ЙЙдьГіРДвЛЦЌОіВпЪї,гУвЛЦЌОіВпЪїЖМЭъГЩОіВпЕФВйзї,УПИіОіВпЪїЖМЕЅЖРжДааОіВпЕФВйзї,зюжеЕФНсЙћШЅЫљгаОіВпЪїЕФжкЪ§ЁЃ
ЫцЛњ: гЩгкбљБОПЩФмгавьГЃжЕ,вђДЫвЊНјааЫцЛњЕФбЁдёЁЃвЛЙВгаСНжиЕФЫцЛњад:
-
Ъ§ОнЕФбЁдёЫцЛњад
ЫцЛњЩШЅЕФбљБОЪЧгаЗХЛиЕФ(ОЭЪЧПЩвдгаЭъШЋЯрЭЌЕФбљБО),ЖјЧвБШР§ЪЧЫцЛњЕФ,ЖМЪЧдкдЪМЕФбЕСЗМЏНјааЫцЛњЕФбЁдёЁЃ -
ЬиеїбЁдёЕФЫцЛњад
-
BootstrapingгаЗХЛиВЩбљ
-
Bagging:гаЗХЛиВЩбљnИібљБОвЛЙВНЈСЂ.ЗжРрЦї
ОіВпЪїЕФВЮЪ§:етаЉВЮЪ§жївЊЪЧОѕЕУОіВпЪїдѕУДдЄМѕжІКЭКѓМѕжІЕФЮЪЬт,ЗРжЙЙ§ФтКЯЕФЮЪЬтЁЃ
1ЁЂ criterion: ЬиеїбЁШЁЗНЗЈ,ПЩвдЪЧgini(ЛљФсЯЕЪ§),entropy(аХЯЂдівц),ЭЈГЃбЁдёgini,МДCARTЫуЗЈ,ШчЙћбЁдёКѓеп,дђЪЧID3КЭC4,.5
2ЁЂ splitter: ЬиеїЛЎЗжЕубЁдёЗНЗЈ,ПЩвдЪЧbestЛђrandom,ЧАепЪЧдкЬиеїЕФШЋВПЛЎЗжЕужаевЕНзюгХЕФЛЎЗжЕу,КѓепЪЧдкЫцЛњбЁдёЕФВПЗжЛЎЗжЕуевЕНОжВПзюгХЕФЛЎЗжЕу,вЛАудкбљБОСПВЛДѓЕФЪБКђ,бЁдёbest,бљБОСПЙ§Дѓ,ПЩвдгУrandom
3ЁЂ max_depth: ЪїЕФзюДѓЩюЖШ,ФЌШЯПЩвдВЛЪфШы,ФЧУДВЛЛсЯожЦзгЪїЕФЩюЖШ,вЛАудкбљБОЩйЬиеївВЩйЕФЧщПіЯТ,ПЩвдВЛзіЯожЦ,ЕЋЪЧбљБОЙ§ЖрЛђепЬиеїЙ§ЖрЕФЧщПіЯТ,ПЩвдЩшЖЈвЛИіЩЯЯо,вЛАуШЁ10~100
4ЁЂ min_samples_split:НкЕудйЛЎЗжЫљашзюЩйбљБОЪ§,ШчЙћНкЕуЩЯЕФбљБОЪївбОЕЭгкетИіжЕ,дђВЛЛсдйбАевзюгХЕФЛЎЗжЕуНјааЛЎЗж,ЧввдНсЕузїЮЊвЖзгНкЕу,ФЌШЯЪЧ2,ШчЙћбљБОЙ§ЖрЕФЧщПіЯТ,ПЩвдЩшЖЈвЛИіуажЕ,ОпЬхПЩИљОнвЕЮёашЧѓКЭЪ§ОнСПРДЖЈ
5ЁЂ min_samples_leaf: вЖзгНкЕуЫљашзюЩйбљБОЪ§,ШчЙћДяВЛЕНетИіуажЕ,дђЭЌвЛИИНкЕуЕФЫљгавЖзгНкЕуОљБЛМєжІ,етЪЧвЛИіЗРжЙЙ§ФтКЯЕФВЮЪ§,ПЩвдЪфШывЛИіОпЬхЕФжЕ,ЛђаЁгк1ЕФЪ§(ЛсИљОнбљБОСПМЦЫуАйЗжБШ)
6ЁЂ min_weight_fraction_leaf: вЖзгНкЕуЫљгабљБОШЈжиКЭ,ШчЙћЕЭгкуажЕ,дђЛсКЭажЕмНкЕувЛЦ№БЛМєжІ,ФЌШЯЪЧ0,ОЭЪЧВЛПМТЧШЈжиЮЪЬтЁЃетИівЛАудкбљБОРрБ№ЦЋВюНЯДѓЛђгаНЯЖрШБЪЇжЕЕФЧщПіЯТЛсПМТЧ
7ЁЂ max_features: ЛЎЗжПМТЧзюДѓЬиеїЪ§,ВЛЪфШыдђФЌШЯШЋВПЬиеї,ПЩвдбЁ log2N,sqrt(N),autoЛђепЪЧаЁгк1ЕФИЁЕуЪ§(АйЗжБШ)ЛђећЪ§(ОпЬхЪ§СПЕФЬиеї)ЁЃШчЙћЬиеїЬиБ№ЖрЪБШчДѓгк50,ПЩвдПМТЧбЁдёautoРДПижЦОіВпЪїЕФЩњГЩЪБМф
8ЁЂ max_leaf_nodes:зюДѓвЖзгНкЕуЪ§,ЗРжЙЙ§ФтКЯ,ФЌШЯВЛЯожЦ,ШчЙћЩшЖЈСЫуажЕ,ФЧУДЛсдкуажЕЗЖЮЇФкЕУЕНзюгХЕФОіВпЪї,бљБОСПЙ§ЖрЪБПЩвдЩшЖЈ
9ЁЂmin_impurity_decrease/min_impurity_split: ЛЎЗжзюашзюаЁВЛДПЖШ,ЧАепЪЧЬиеїбЁдёЪБЕЭгкОЭВЛПМТЧетИіЬиеї,КѓепЪЧШчЙћбЁШЁЕФзюгХЬиеїЛЎЗжКѓДяВЛЕНетИіуажЕ,дђВЛдйЛЎЗж,НкЕуБфГЩвЖзгНкЕу
10ЁЂclass_weight: РрБ№ШЈжи,дкбљБОгаНЯДѓШБЪЇжЕЛђРрБ№ЦЋВюНЯДѓЪБПЩбЁ,ЗРжЙОіВпЪїЯђРрБ№Й§ДѓЕФбљБОЧуаБЁЃПЩЩшЖЈЛђепbalanced,КѓепЛсздЖЏИљОнбљБОЕФЪ§СПЗжВММЦЫуШЈжи,бљБОЪ§ЩйдђШЈжиИп,гыmin_weight_fraction_leafЖдгІ
11ЁЂpresort: ЪЧЗёХХађ,ЛљБОВЛгУЙм

