| 不同点 | 顺序表 | 链表 |
| 存储空间 | 物理上一定连续 | 逻辑上连续,但物理上不一定连续 |
| 随机访问 | 支持O(1) | 不支持:O(N) |
| 任意位置插入或者删除元素 | 可能需要搬移元素,效率低O(N) | 只需修改指针指向 |
| 插入 | 动态顺序表,空间不够时需要扩容 | 没有容量的概念 |
| 应用场景 | 元素高效存储+频繁访问 | 任意位置插入和删除频繁 |
| 缓存利用率 | 高 | 低 |
由上表可总结出:
顺序表优点:
1. 物理空间是连续的,方便用下标随机访问。
2. CPU高速缓存命中率更高
顺序表缺点:
1. 由于需要物理空间连续,空间不够需要扩容。扩容有性能消耗。每次扩容还存在一定的空间浪费
2. 头部或者中部插入删除,挪动数据,效率低。O(N)
链表优点:
1. 任意位置插入删除数据效率高。O(1)
2. 按需申请和释放空间
链表缺点:
不支持下标的随机访问。有些算法不适合在它上面进行。如:二分查找、排序等。
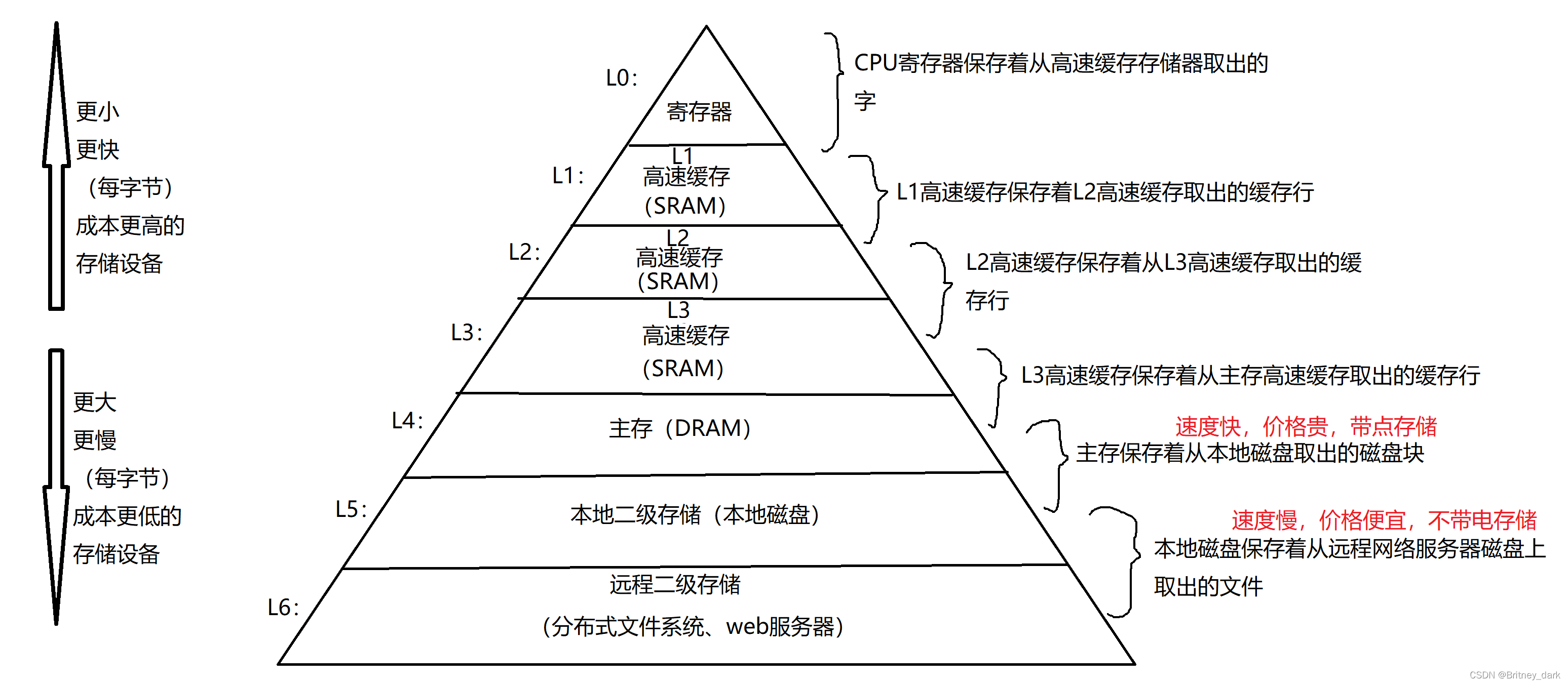
注:缓存利用率指的的是高速缓存的命中率
CPU在读取数据时,CPU是不会直接访问内存,因为它嫌弃内存的速度太慢了,所以会把数据加载到三级缓存或者寄存器上,4/8byte小数据就放到寄存器上,大数据就放到缓存
高速缓存的命中率是指:CPU会看数据是否在缓存,在就叫命中,直接访问;不在就叫不命中,先把数据从内存加载到缓存,再进行访问
CPU认为你有可能除了访问当前这块内存的数据以外,还会访问当前这块内存的后面的内存的数据,所以在读取时,还会预读取后面那块内存的数据,而在数组中由于物理空间和逻辑空间都是连续的,所以命中率会更高,链表是逻辑空间是连续的,物理空间不一定是连续的,所以命中率更低。
? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? ? 存储器的层次结构
更多的CPU缓存知识:与程序员相关的CPU缓存知识

