1.Information Retrieval
����:
Information retrieval (IR) is finding material (usually documents) of an unstructured nature (usually text) that satisfies an information need from within large collections (usually stored on computers).
web search
- �����Ӵ�
- ��Ҫ����
- ����թ
- ������
personal information retrieval:
- eg:Email
- ����
- �����ʼ�����
- �洢�������
- �����
- ���̿ռ�
enterprise,institutional, and domain-specific search
- stored on centralized file systems
���Բ���:grep
- ���ı��в�ij�����㹻��,������������
��������:
- �����������,���ٴ���
- flexible matching operations
- ����
����ģ��
- query:��������ʽ
����:
- ad hoc retrieval task.
- ����query,���doc�б�(�����)
����
- precision
- recall
- ��
ר������
- term:�����ĵ�Ԫ,��ʡ����顢DZ�ڴʵ�
- document:�����ĵ�λ,����վ�б�,Ҳ������ijһ�½�
- collection����corpus:doc�ļ���
- information need
- �û����������ݵ�����
- ���ܲ�����ȷ
- relevant:����û���Ϊ�������������Ϣ������ص���Ϣ
1.1 term-document matrix

�ʴ�->doc����:ÿ��һ��doc����,ÿ��һ��term����
query:Brutus AND Caesar AND NOT Calpurnia,
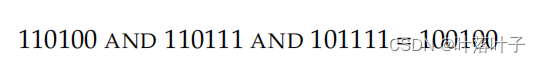
��:Antony and Cleopatra and Hamlet
����
- ϡ��,�ʱ������Դ洢�C>��������
1.2 ��������
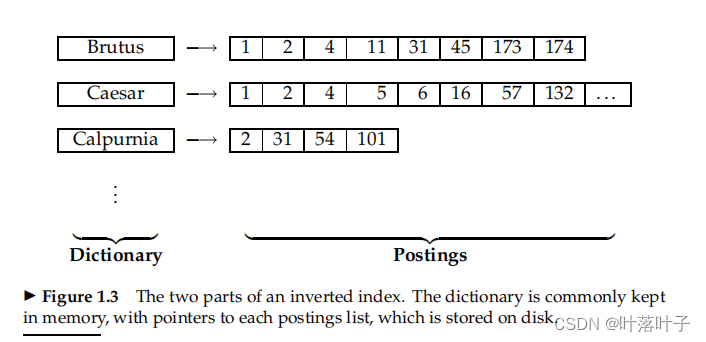
INVERTED INDEX
- dictionary(vacabulary):
- �ڴ�
- key:term�б�,Ҳ������,Ҳ���¼postings�ij���(doc freq)
- value:postings list/postings:�ź����,��doc id,������شʵ�freq,��
- postings
- posting��¼:docid,term��doc�г��ֵ�λ�á�freq,��
- �洢:disk
- �̶�����:����,�˷�
- linked list:����,
- ���ڲ���,
- ������չ��advanced indexing strategies
- skip list,��Ҫ�µ�ָ��
- ����:Ҫ�洢ָ��
- �ɱ�����
- ˳��洢,������
- ����洢ָ��,ָ�������offset
- ���
- �������������
����:
- Collect the documents to be indexed:
- �ִ�
- normalized
- index
- merge:��ͬterm����ͬdoc�ϲ�
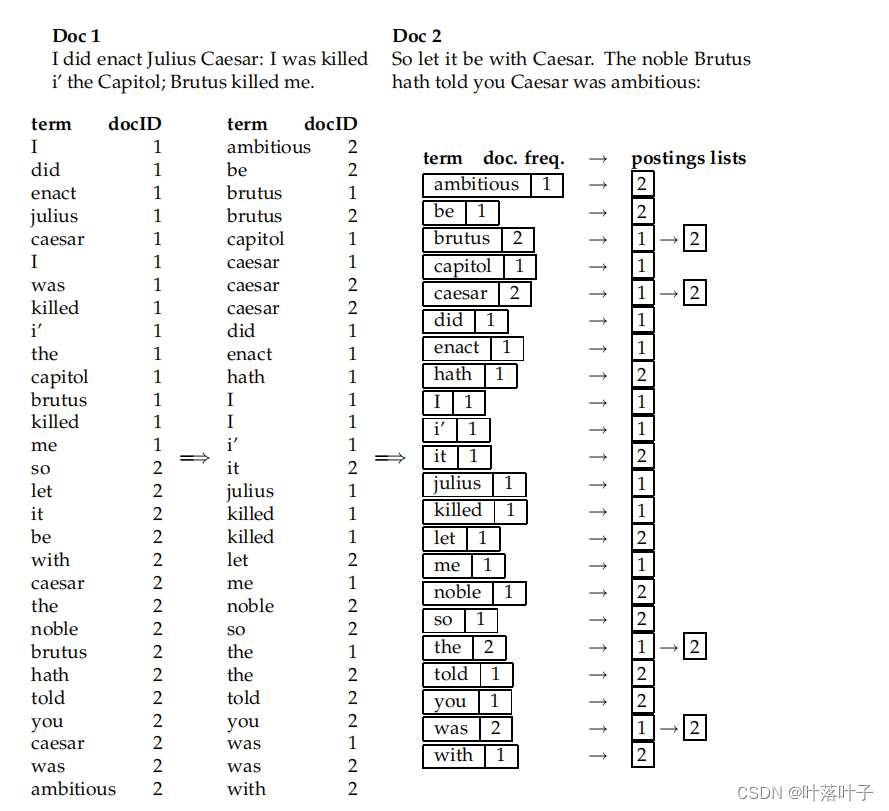
- merge:��ͬterm����ͬdoc�ϲ�
1.3 Processing Boolean queries
- �õ�ÿ��term��postings
- OR:���������ں�,ȡ����,AND:ȡ����,ת��ΪAND���ӵ���ʽ
ȡ����:(������)

����:ȡ����ʱ,�������Ӷ�,����������ܴ�
���:
- �Ȱ�doc freq����(posting�ij���),�Ⱥϲ��̵�
- ���ս���ij��Ȳ��ᳬ����̵��б�
- ���DZ���doc freq.��ԭ��
- ����OR,����AND

- ����̵�,Ȼ�浽�м���
- ÿ����һ���������м�����
- ����:���Գ�
- �м���:�ڴ�;��һ������:disk
- ����һ��������ܱ��м�����ö�(����������?)
- ���ٺϲ�����
- �м�����doc�ڳ�positng���������Һϲ�
- ��postings���ù�ϣ�洢
- ����������ѹ�����positngs
- ���dz�����,�Կ����ñ���
���������:

1.4 �Ի���������������չ���������
�����������������(�������ģ��)��Ӧ
��������:
- query:��ȷ��������ʽ
- ���:����
- ��������������չ
- �ڽ�������:term�ľ������ĵ��нӽ�(�м京�м�����,�������ӽ��ij̶�
- רҵ��ʿ��ϲ����������:��ѯ��ȷ,������������
- ����:��ʱ�䡣����
�������
- query:����������ʽ��ô��ȷ,����һ�������ʹ���(�����ı���ѯ)
- ���:����
Ҫ��
- term:�ṩ,����ƴд����,������ﲻһ��(������ͬ)
- ���ϴʺͶ���:(Gates Near Microsoft)
- ���ƶ�:������ѯ����¼�������,����������Ҫ�õ��ĵ���صĿɿ��̶�
- ����Ƶ��:term��doc�е�Ƶ�ʸ�,Ȩ�ظ�
- ����
ad hoc search:
- ���ѡ���������������
- ����֧�ֲ�������,רҵ��ʿϲ��,������õ���

