前言:讲一些平常挺少用的但是也挺重要的东西
map
rbegin&rend
反向迭代器,可以反向遍历map。
ps:反向迭代器的迭代器类型是reverse_iterator,别写错了
demo:
int main()
{
string a[] = { "apple", "banana", "watermelon" };
map<string, int> m;
for (auto e : a)
{
m[e]++;
}
for (map<string, int>::reverse_iterator rit = m.rbegin(); rit != m.rend(); rit++)
{
cout << rit->first << ':' << rit->second << endl;
}
}
范围for
众所周知,返回for里面的e代表的就是容器中的元素。由于map的元素是pair,如果写成这种形式:for(auto e : m){},就会涉及到要调用拷贝构造,影响效率。
因此尽量写成for(const auto& e : m),就不会涉及拷贝构造了。
demo
这样就不用深拷贝string了
int main()
{
string a[] = { "apple", "banana", "watermelon" };
map<string, int> m;
for (const auto& e : a)
{
m[e]++;
}
for (const auto& e : m)
{
cout << e.first << ':' << e.second << endl;
}
}
insert与[]
insert平时其实没啥用,我习惯都是用[]进行插入。但是[]本质就是用insert实现的。
insert的函数签名
pair<iterator,bool> insert (const value_type& val);
注意到它的返回值是一个pair,重要的是pair的first是iterator,这是用来实现[]的重点内容。
operator[]的函数签名
返回值是val的引用,因此可以用于修改val。
mapped_type是val的类型
mapped_type& operator[] (const K& k);
operator[]的实现代码如下:
(*((this->insert(make_pair(k,mapped_type()))).first)).second
解释一下:
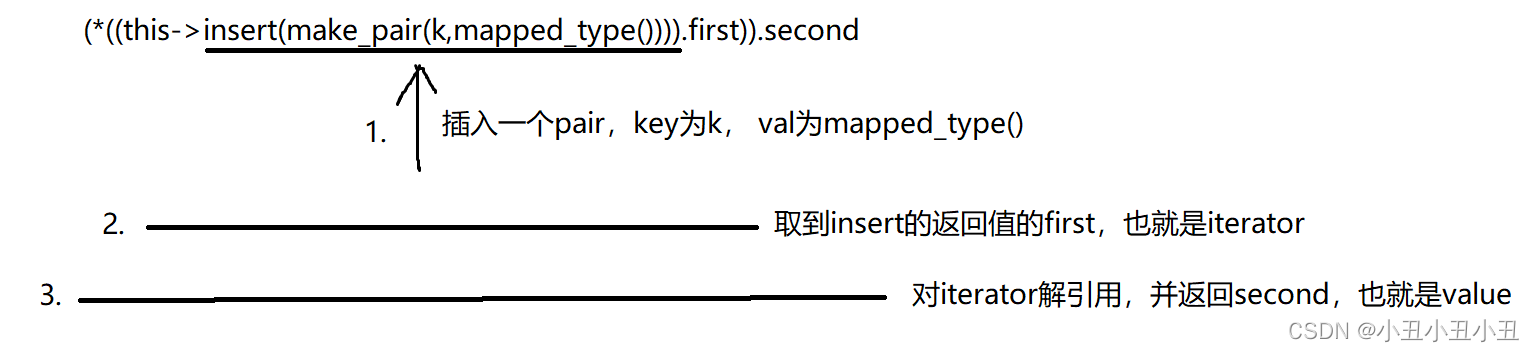
拆开来写也就是:
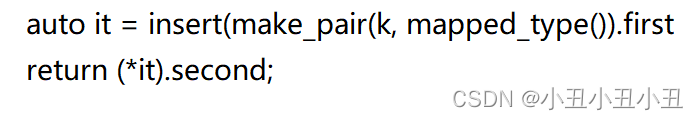
find&count
find是用来找map里面是否有这个key的。返回值是迭代器。
demo:
一定要判断res是否等于end迭代器,如果等于证明找不到,就不要去访问了。
int main()
{
string a[] = { "apple", "banana", "watermelon" };
map<string, int> m;
for (const auto& e : a) m[e]++;
auto res = m.find("apple");
if (res != m.end()) cout << m[res] << endl;
}
实际写算法题的时候,基本不用find。都是用count。count是返回key对应的val的。
一般用来判断这个key是否在map里面出现,出现了,返回值>0,没有出现,返回值==0
demo
int main()
{
string a[] = { "apple", "banana", "watermelon" };
map<string, int> m;
for (const auto& e : a) m[e]++;
if (m.count("apple")) cout << "有苹果" << endl;
if (m.count("pineapple") == 0) cout << "没有菠萝" << endl;
}
ps:千万不要用[]来判断一个key是否在map中出现过.如果没有出现且使用了[],就会自动插入了。
就把[]当成插入就好了,即使[]也可以返回一个已经存在的key的val值。
仿函数
这是仿函数的定义:
仿函数(Functor)又称为函数对象(Function Object)是一个能行使函数功能的类。仿函数的语法几乎和我们普通的函数调用一样,不过作为仿函数的类,都必须重载operator()运算符。因为调用仿函数,实际上就是通过类对象调用重载后的operator()运算符。
我总结几点:
- 仿函数是一个类
- 仿函数就是为了取代函数指针的写法才涉及出来的,传参传仿函数相当于传函数指针
- 仿函数必须重载operator()
这个仿函数在map,heap, set,都可以用到,因为它们都可以选择排序的规则。
甚至sort里面也可以用到仿函数,只不过由于sort可以重载<来排序,我们就很少在sort上面用仿函数。
demo
注意:重载operator()的时候,只能重载要排序的类型,比如这里要排序的是key,只能写key的类型。
struct cmp
{
bool operator()(string x, string y) const//这里不能写pair,只能写key的类型
{
//按字典序降序来排序(只能对key排序)
return x > y;
}
};
int main()
{
string a[] = { "apple", "banana", "watermelon" };
map<string, int, cmp> m;
for (const auto& e : a) m[e]++;
for (const auto& e : m) cout << e.first << ' ' << e.second << endl;
}
ps:
仿函数在模板参数的时候传类型,在函数参数的时候参对象。因此在map模板参数上传的是cmp类型。
在sort上的demo,由于sort是函数,传参要传cmp()对象
struct cmp
{
bool operator()(string x, string y) const//这里不能写pair,只能写key的类型
{
//按字典序降序来排序(只能对key排序)
return x > y;
}
};
int main()
{
string a[] = { "apple", "banana", "watermelon" };
sort(a, a + 3, cmp());
}
在heap上也可以使用,用一道leetcode的题做例子
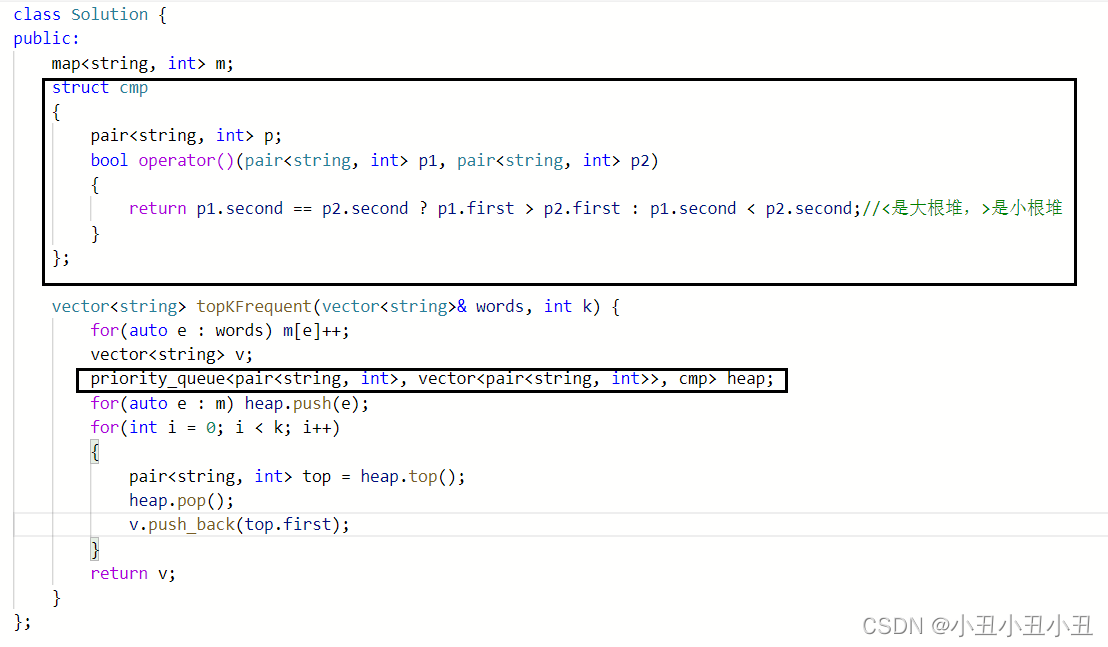
multimap
multimap就是允许key相同的map,实际用的不多。
set和multiset
这两个没什么讲的,和map使用差不多。但是有一点要强调的:
请问set是不是kv模型的容器?
答案:是的!!!虽然set和multiset只能传key,但是底层结构它们都是<value, value>模型的。
列一下set的常用接口
- count
- insert
demo
int main()
{
string a[] = { "apple", "banana", "watermelon" };
set<string> s;
for (const auto& e : a) s.insert(e);
if (s.count("apple")) cout << "existed" << endl;
else cout << "not existed" << endl;
}
multiset是允许key冗余的set。
其实当我们不需要存value的时候,都可以用set或者multiset,不一定每次都用map

