����Ŀ¼
ѧϰ��Ƶ:
���˲˵Ļ���ѧϰsklearn���á�_��������_bilibili
������
1.����
1.1��������������
������(Decision Tree)��һ���Dz���(���Դ������ָ���������)���мලѧϰ(���DZ���Ҫ�б�ǩ)����,���ܹ���һϵ���������ͱ�ǩ���������ܽ�����߹���,������״ͼ�Ľṹ��������Щ����,�Խ������ͻع����⡣
�������㷨��������,���ø�������,�ڽ����������ʱ�������ñ���,����������ģ��Ϊ���ĵĸ��ּ����㷨,�ڸ�����ҵ�������й㷺��Ӧ�á�
��������߹�����,һֱ�ڶԼ�¼�������������ʡ�������������ڵĵط��������ڵ�,�ڵõ�����ǰ��ÿһ�����ⶼ���м�ڵ�,���õ���ÿһ������(��������)������Ҷ�ӽڵ���
- ���ڵ�:û�н���,�г��ߡ����������,�������������;
- �м�ڵ�:���н���Ҳ�г���,����ֻ��һ��,���߿����кܶ����������������������;
- Ҷ�ӽڵ�:�н���,û�г���,ÿ��Ҷ�ӽڵ㶼��һ������ǩ��
- �ӽڵ���ڵ�:�����������Ľڵ���,���ӽ����ڵ���Ǹ��ڵ�,��һ�����ӽڵ㡣
���ھ������㷨��˵,����ľ��ǽ��������������:
- ��δ����ݱ����ҳ���ѽڵ����ѷ�֦?
- ����þ�����ֹͣ����,��ֹ�����?
1.2 sklearn�еľ�����
- ģ��sklearn.tree
sklearn�еľ������ġ��ࡰ���ǡ�tree�����ģ����,���ģ���ܹ�����5����
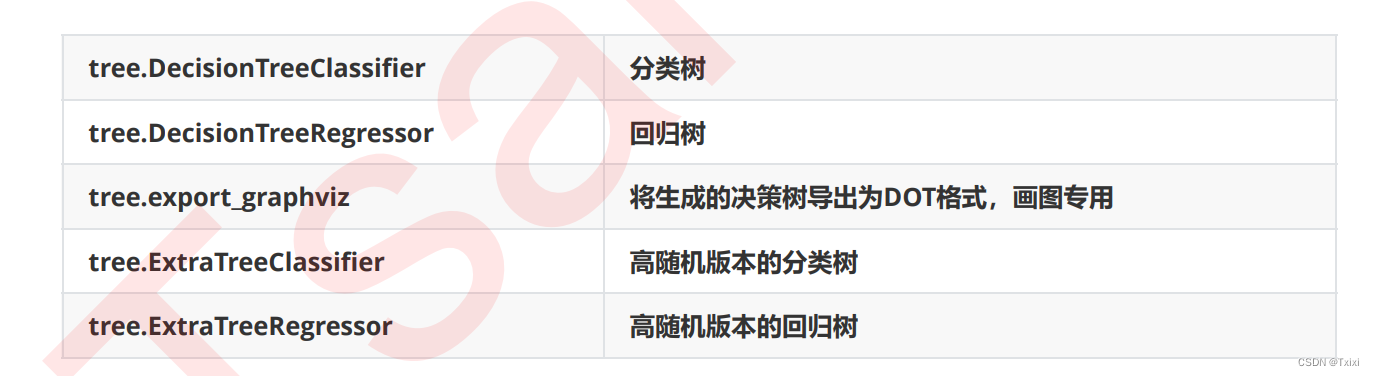
- sklearn�Ļ�����ģ����
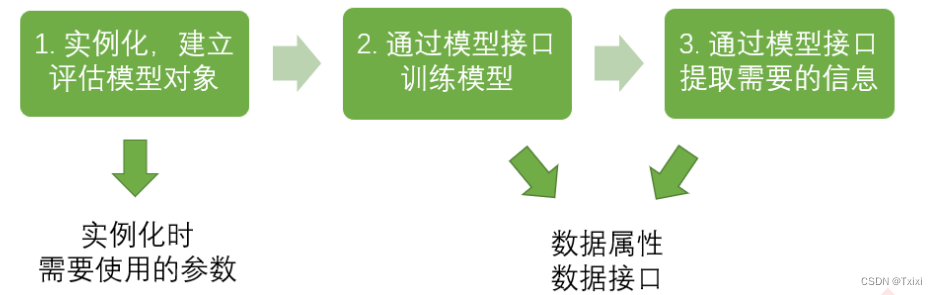
�����ʺϵ���,Ȼ��ȷ������,ѵ��ģ������fit�ӿ�,��ȡ���õ���Ϣ,����score���ǶԷ���ģ�ͽ��д�ֵġ��ڴ�������,��������Ӧ�Ĵ���:
from sklearn import tree #������Ҫ��ģ��
clf = tree.DecisionTreeClassifier() #ʵ����
clf = clf.fit(X_train,y_train) #��ѵ��������ѵ��ģ��
result = clf.score(X_test,y_test) #������Լ�,�ӽӿ��е�����Ҫ����Ϣ
2.DecisionTreeclassifier�������ݼ�
2.1��Ҫ����
2.1.1 criterion
Ϊ��Ҫ������ת��Ϊһ����,��������Ҫ�ҳ���ѽڵ����ѵķ�֦����,�Է�������˵,�����������ѡ���ָ�����==�������ȡ�==��ͨ����˵,������Խ��,��������ѵ���������Խ�á�����ʹ�õľ������㷨�ڷ�֦�����ϵĺ��Ĵ����Χ���ڶ�ij�����������ָ������Ż��ϡ�
�����Ȼ��ڽڵ�������,���е�ÿ���ڵ㶼����һ��������,�����ӽڵ�IJ�����һ���ǵ��ڸ��ڵ��,Ҳ����˵,��ͬһ�þ�������,Ҷ�ӽڵ�IJ�����һ������͵ġ�
Criterion������������������������ȵļ��㷽���ġ�sklearn�ṩ������ѡ��:
(1)����"entropy",ʹ����Ϣ(Entropy)
E
n
t
r
o
p
y
(
t
)
=
?
��
i
=
0
c
?
1
p
(
i
�O
t
)
log
?
2
p
(
i
�O
t
)
Entropy\left( t \right) =-\sum_{i=0}^{c-1}{p\left( i|t \right) \log _2p\left( i|t \right)}
Entropy(t)=?i=0��c?1?p(i�Ot)log2?p(i�Ot)
(2)����"gini",ʹ�û���ϵ��(Gini Impurity)
G
i
n
i
=
1
?
��
i
=
0
c
?
1
p
(
i
�O
t
)
2
Gini=1-\sum_{i=0}^{c-1}{p\left( i|t \right) ^2}
Gini=1?i=0��c?1?p(i�Ot)2
����t�DZ�ʾ�ĸ����ڵ�,i��ʾ���DZ�ǩ���������,
p
(
i
�O
t
)
2
p\left(i|t\right)^2
p(i�Ot)2��ʾ���DZ�ǩ����i�ڽڵ�t����ռ�ı�����
��sklearn�м�����Ϣ��ʱ,�ǻ�����Ϣ�ص���Ϣ����(Information Gain),Ҳ���Ǹ��ڵ����Ϣ�غ��ӽڵ���Ϣ�صIJ����ڻ���ϵ����˵,��Ϣ�ضԲ����ȸ�������,�Բ����ȵijͷ���ǿ,������ʵ��ʹ�ù�����,��Ϣ�غͻ���ϵ����Ч������һ������Ϣ�εļ���Ȼ���ϵ������һЩ,��Ϊ����ϵ���ļ��㲻�漰����������,��Ϊ��Ϣ�ζԲ����ȸ�������,������Ϣ����Ϊָ��ʱ,����������������ӡ���ϸ��,��˶��ڸ�ά���ݻ��������ܶ������,��Ϣժ���������,����ϵ�������������Ч�������ȽϺá���ģ����ϳ̶Ȳ����ʱ��,����ģ����ѵ�����Ͳ��Լ��϶����ֲ�̫�õ�ʱ��,ʹ����Ϣ�Ρ���Ȼ,��Щ���Ǿ��Եġ�
����criterion����
- ȷ�������ȵļ��㷽��,��æ�ҳ���ѽڵ����ѷ�֦,������Խ��,��������ѵ���������Խ��;
- �IJ���������ѡ��:gini��entropy,Ĭ��״̬����gini;
- ͨ�������ʹ�û���ϵ��,����ά�Ⱥܴ�,�����ܴ�ʱʹ�û���ϵ��;ά�ȵ�,���ݱȽ�������ʱ��,��Ϣ�κͻ���ϵ��û������������ϳ̶Ȳ�����ʱ��,ʹ����Ϣ������������,���þͻ�����һ����
���ھ������Ļ������̿��Լĸſ�Ϊ:

ֱ��û�и������������,������IJ�����ָ���Ѿ�����,�������ͻ�ֹͣ������
���˽��˵�һ��������,����Python���Դ��ĺ�����ݽ���һ����
(1)����ģ��
from sklearn import tree #�����������ģ��
from sklearn.datasets import 1oad_wine #����������,datasets��sklearn�Դ���,�и��ָ���������
from sklearn.model_selection import train_test_split#���뻮�ֲ��Լ���ѵ������ģ��
(2)̽������
wine = load_wine()
wine.data#���ݵ�����
win.target#���ݱ�ǩ
#��wine����ת����һ�ű�
import pandas as pd
pd.concat([pd.DataFrame (wine.data) , pd.DataFrame(wine.target)],axis=1)
wine.feature_names #��������
wine.target_names #��ǩ����
(3)����ѵ�����Ͳ��Լ�
Xtrain, Xtest, Ytrain, Ytest = train_test_split(wine.data,wine.target,test_size=0.3)
Xtrain.shape
Xtest.shape
(4)����ģ��
������������Ĵ������ֲ�ͬ�Ľ��,
clf = tree.DecisionTreeClassifier(criterion="entropy")
clf = clf.fit(Xtrain, Ytrain) #fit����ѵ���Ľӿ�
score = clf.score(Xtest, Ytest) #����Ԥ���ȷ��
score
(5)����һ����
feature_name=['�ƾ�','ƻ����','��','�ҵļ���','þ','�ܷ�','���ͪ','�ǻ��������','������','��ɫǿ��','ɫ��','od280/od315ϡ�����Ѿ�','������']
import graphviz #��Ҫ��װ�����Դ���
dot_data = tree.export_graphviz(clf #����ѵ���õ�ģ��
,feature_names= feature_name #��������
,class_names=["�پ�","ѩ��","����Ħ��"]#��ǩ��
,filled=True #�����ɫ
,rounded=True#�����״
)
graph = graphviz.Source(dot_data)
graph
(6)̽��������
#������Ҫ��
clf.feature_importances_
[*zip(feature_name,clf.feature_importances_)]
��ֻ�˽�һ�������������,������һ�������ľ����������ǻص�����4����ģ��,score����ij��ֵ��������,������5�л�������ÿһ��������һ������Ϊʲô��ȶ���?���ʹ���������ݼ�,������ȶ���?����֮ǰ�ᵽ��,���۾�����ģ����ν���,�ڷ�֦�ϵı��ʶ�������ij����������ص�ָ����Ż�,�����������ᵽ��,�������ǻ��ڽڵ��������,Ҳ����˵,�������ڽ���ʱ,�ǿ��Ż��ڵ�����һ���Ż�����,�����ŵĽڵ��ܹ���֤���ŵ�����?�����㷨����������������:sklearn��ʾ,��Ȼһ�������ܱ�֤����,�Ǿͽ�����IJ�ͬ����,Ȼ�����ȡ��õġ�������һ�����ݼ��н���ͬ����?��ÿ�η�֦ʱ,����ʹ��ȫ������,�������ѡȡһ��������,����ѡȡ���������ָ�����ŵ���Ϊ��֦�õĽڵ㡣����,ÿ�����ɵ���Ҳ�Ͳ�ͬ�ˡ�
ʹ��random_state������������Ե�
2.1.2 random_state &splitter
random_state�������÷�֦�е����ģʽ�IJ���,Ĭ��None,�ڸ�ά��ʱ����Ի���ָ�����,��ά�ȵ�����
(�����β�����ݼ�),����Լ�������������������������,��һֱ����ͬһ����,��ģ���ȶ�������
splitterҲ���������ƾ������е����ѡ���,����������ֵ,����"best",�������ڷ�֦ʱ��Ȼ���,���ǻ��ǻ�����ѡ�����Ҫ���������з�֦(��Ҫ�Կ���ͨ������feature_importances_�鿴),����"random",�������ڷ�֦ʱ��������,������Ϊ���и���IJ���Ҫ��Ϣ���������,������Щ����Ҫ��Ϣ�����Ͷ�ѵ��������ϡ���Ҳ�Ƿ�ֹ����ϵ�һ�ַ�ʽ������Ԥ����ģ�ͻ�����,�������������������㽵��������֮�����ϵĿ����ԡ���Ȼ,��һ������,������Ȼ��ʹ�ü�֦��������ֹ����ϡ�
clf = tree.DecisionTreeClassifier(criterion="entropy"
,random_state=30
,splitter="random"
)
clf = clf.fit(Xtrain, Ytrain) #fit����ѵ���Ľӿ�
score = clf.score(Xtest, Ytest) #����Ԥ���ȷ��
score
import graphviz #��Ҫ��װ�����Դ���
dot_data = tree.export_graphviz(clf #����ѵ���õ�ģ��
,feature_names= feature_name #��������
,class_names=["�پ�","ѩ��","����Ħ��"]#��ǩ��
,filled=True #�����ɫ
,rounded=True#�����״
)
graph = graphviz.Source(dot_data)
graph
2.1.3��֦����
�ڲ������Ƶ������,һ�þ����������������������ȵ�ָ������,����û�и������������Ϊֹ�������ľ���������������,�����˵,������ѵ�����ϱ��ֺܺ�,�ڲ��Լ���ȴ��������������ռ����������ݲ����ܺ������״����ȫһ��,��˵�һ�þ�������ѵ���������˹�������Ľ�����,���ҳ��Ĺ����Ȼ������ѵ�������е�����,��ʹ����δ֪���ݵ���ϳ̶Ȳ��㡣
#���ǵ�����ѵ��������ϳ̶����?
sore_train = clf.sore(Xtrain,Ytrain)
sore_train
Ϊ���þ������и��õķ�����,����Ҫ�Ծ�����������֦����֦���ԶԾ�������Ӱ���,��ȷ�ļ�֦�������Ż��������㷨�ĺ�����sklearnΪ�����ṩ�˲�ͬ�ļ�֦����:
- max_depth
(1)�˲�������������������,�����趨��ȵ���֦ȫ������;
(2)�˲������õ���㷺�ļ�֦����,���ڷ�����ά�ȵ������������зdz���Ч����Ϊ������������һ��,�������������������һ��,��������������ܹ���Ч�����ƹ����;
(3)�˲������ڼ����㷨��Ҳ�dz�ʵ�á�ʵ��ʹ��ʱ,�����3��ʼ����,������ϵ�Ч���پ����Ƿ������趨��ȡ�
- min_samples_leaf (Ҷ�ӽڵ����Ҫ����) min_samples_split
(1)�˲�������һ���ڵ��ڷ�֦���ÿ���ӽڵ㶼�����������min_samples_leaf��ѵ������,�����֦�Ͳ��ᷢ��;
(2)һ���max_depth��������ʹ��,�˲����ڶ��ڻع�������ʹ��ģ�ͱ�ø���ƽ��;
(3)�˲������������õ�̫С����������,���õ�̫��ͻ���ֹģ��ѧϰ����,���˷����ݡ�һ����˵,�����5��ʼʹ�á����Ҷ�ڵ��к��е��������仯�ܴ�,�������븡������Ϊ�������İٷֱ���ʹ�á�ͬʱ,����������Ա�֤ÿ��Ҷ�ӵ���С�ߴ�,�����ڻع������б���ͷ���,����ϵ�Ҷ�ӽڵ���֡��������ķ�������,1ͨ���������ѡ��
- min_samples_split
�˲�����Ҫ��һ���ڵ����Ҫ��������min_samples_split��ѵ������,����ڵ����������֦,�����֦�Ͳ��ᷢ����
clf = tree.DecisionTreeClassifier(criterion='entropy'
,random_state=30
,splitter='random'
,max_depth=3
,min_samples_leaf=10
,min_samples_split=10
)
clf = clf.fit(Xtrain, Ytrain) #fit����ѵ���Ľӿ�
score = clf.score(Xtest, Ytest) #����Ԥ���ȷ��
score
import graphviz #��Ҫ��װ�����Դ���
dot_data = tree.export_graphviz(clf #����ѵ���õ�ģ��
,feature_names= feature_name #��������
,class_names=["�پ�","ѩ��","����Ħ��"]#��ǩ��
,filled=True #�����ɫ
,rounded=True#�����״
)
graph = graphviz.Source(dot_data)
graph
clf.score(xtrain, Ytrain)
clf.score(xtest, Ytest)
- max_features & min_impurity_decrease
(1)max_features���������Ʒ�֦ʱ���ǵ���������,�������Ƹ������������ᱻ��������max_depth����ͬ��,max_features���������Ƹ�ά�����ݵĹ���ϵļ�֦����,���䷽���Ƚϱ���,��ֱ�����ƿ���ʹ�õ�����������ǿ��ʹ������ͣ�µIJ���,�ڲ�֪���������еĸ�����������Ҫ�Ե������,ǿ���趨����������ܻᵼ��ģ��ѧϰ���㡣���ϣ��ͨ����ά�ķ�ʽ��ֹ�����,����ʹ��PCA,ICA��������ѡ��ģ���еĽ�ά�㷨��
(2)min_impurity_decrease������������Ϣ����Ĵ�С,��Ϣ����С���趨��ֵ�ķ�֦���ᷢ����������0.19�汾�и��µĹ���,��0.19�汾֮ǰʱʹ��min_impurity_split��
- ȷ�����Ų���
֪������֦������,��ô����ȷ�����ŵ���֦������?��ʱ����Ҫ���ݳ��������������ж�������֦������
��������ѧϰ����,��һ���Գ�������ȡֵΪ������,ģ�͵Ķ���ָ��Ϊ�����������,��������������ͬ������ȡֵ��ģ�͵ı��ֵ��ߡ������ǽ��õľ�������,���ǵ�ģ�Ͷ���ָ�����score��
import matplotlib.pyplot as plt #���뻭ͼģ��
#����һ��forѭ��,��max_depth������1-10ѭ��,�ֱ�����ڲ��Լ��ı���,����ѧϰ����
test = []
for i in range(10):
clf = tree.DecisionTreeClassifier(max_depth=i+1
,criterion="entropy"
,random_state=30
,splitter="random"
)
clf = clf.fit(Xtrain, Ytrain)
score = clf.score(Xtest, Ytest)
test.append(score)
plt.plot(range(1,11),test,color="red",label="max_depth")
plt.legend()
plt.show()
�ܽ�:���β�һ��������ģ���ڲ��Լ��ϵı���,û�о��ԵĴ�,�ⶼ����Ҫ�������ݱ�����ȷ����,���ڼ�֦������˵Ĭ��ֵ����������������Щ����ijЩ���ݼ��Ͽ��ܷdz���,���ڴ������Ҳ�dz���������������е����ݼ��dz���,���Ѿ�Ԥ���������㶼��Ҫ��֦��,����ǰ�趨��Щ�������������ĸ����Ժʹ�С��ȽϺá�������һ�еĵ��ζ�����Ҫ�����ݱ���������
2.1.4Ŀ��Ȩ�ز���
- class_weight & min_weight_fraction_leaf
���������������������ǩƽ��IJ�����
������ƽ����ָ��һ�����ݼ���,��ǩ��һ������ռ�кܴ�ı���������˵,������Ҫ�жϡ�һ���������ÿ������Ƿ��ΥԼ��,������vs��(1%:99%)�ı��������ַ���״����,����ģ��ʲôҲ����,ȫ�ѽ��Ԥ���"��",��ȷ��Ҳ����99%��
���ڲ����������Ҫʹ��class_weight������������ǩ����һ���ľ���,��ԭ�����Ǹ������ı�ǩ�����Ȩ��,��ģ��ƫ��������,��������ķ���ģ���ò���Ĭ��None,��ģʽ��ʾ�Զ��������ݼ��е����б�ǩ��ͬ��Ȩ����
����Ȩ��֮��,�������Ͳ����ǵ����ؼ�¼��Ŀ,�����������Ȩ��Ӱ����,�����ʱ���֦,����Ҫ����min_
weight_fraction_leaf�������Ȩ�صļ�֦������ʹ�á�����ע��,����Ȩ�صļ�֦����(����min_weight_
fraction_leaf)���Ȳ�֪������Ȩ�صı�(����min_samples_leaf)����ƫ�������ࡣ��������Ǽ�Ȩ��,��ʹ�û���Ȩ�ص�Ԥ�������������Ż����ṹ,��ȷ��Ҷ�ڵ����ٰ�������Ȩ�ص��ܺ͵�һС���֡�
2.2��Ҫ���Ժͽӿ�
����:����ָģ��ѵ��֮��,�ܹ����ò鿴��ģ�͵ĸ������ʡ����ھ�������˵,������Ҫ�����Ծ���feature_importances_,�����Կ��Բ鿴����������ģ�͵���Ҫ�ԡ�
����sklearnģ��,�ܶ��㷨�Ľӿڶ������Ƶ�,����fit��score������ÿ���㷨������ʹ�á������������ӿ�֮��,��������õĽӿڻ���apply��predict��
apply:�˽ӿ���������Լ�����ÿ�������������ڵ�Ҷ�ӽڵ������;
predict:�˽ӿ���������Լ�����ÿ�����������ı�ǩ��
ֵ��ע�����,���нӿ���Ҫ������X_train��X_test�IJ���,����������������������һ����ά������
sklearn�������κ�һά������Ϊ�����������롣���������ݵ�ȷֻ��һ������,�DZ�����reshape(-1,1)����������ά;����������ֻ��һ��������һ������,ʹ��reshape(1,-1)�������������ά��
#apply����ÿ�������������ڵ�Ҷ�ӽڵ������
clf.apply(Xtest)
#predict����ÿ�����������ķ���/�ع���
clf.predict(Xtest)
���������ܽ�
����,�����˷�����DecisionTreeClassifier���þ�������ͼ(export_graphviz)�����л���,�˽��˾������Ļ�������,�������İ˸�����,һ������,�ĸ��ӿ�,�Լ���ͼ���õĴ��롣
�˸�����:Criterion,�����������صIJ���(random_state,splitter),�����֦����(max_depth,min_samples_split,min_samples_leaf,max_feature,min_impurity_decrease)
һ������:feature_importances_
�ĸ��ӿ�:fit,score,apply,predict
3.�ع���
�ع����������в��������ԡ��ӿںͷ�����һ��,ֻ���ڻع�����û�б�ǩ�ֲ��Ƿ���������,���û��class_weight�����IJ�����
�ع����õ���DecisionTreeRegressor��
3.1��Ҫ����,���Լ��ӿ�
criterion
�ع�û�в����ȵĶ���,�ع����к�����֦������ָ��������:
(1)mse:�������mean squared error(MSE),���ڵ��Ҷ�ӽڵ�֮����������IJ������������Ϊ����ѡ��ı�,���ַ���ͨ��ʹ��Ҷ�ӽڵ�ľ�ֵ����С��L2��ʧ;
M
S
E
=
1
N
��
i
=
1
N
(
f
i
?
y
i
)
2
MSE=\frac{1}{N}\sum_{i=1}^N{\left( f_i-y_i \right) ^2}
MSE=N1?i=1��N?(fi??yi?)2
����N����������,i��ÿ����������,
f
i
f_i
fi?�ǻع�������Ľ��,
y
i
y_i
yi?��������i��ʵ��ֵ,���MSE�ı��ʾ�����ʵֵ�ͻع����IJ���;
(2)friedman_mse:�Ѷ������������,����ָ��ʹ�ø���������DZ�ڷ�֦�е�����Ľ���ľ������;
(3)mae:����ƽ�����MAE(mean absolute error),����ָ��ʹ��Ҷ�ڵ����ֵ����С��L1��ʧ����������Ҫ����Ȼ��feature_importances_,�ӿ���Ȼ��apply,fit,predict,score����ġ�
�ڻع�����MSE��ֻ�����ǵķ�֦��������ָ��,Ҳ��������õĺ����ع����ع�������ָ��,��������ʹ�ý�����֤,����������ʽ��ȡ�ع����Ľ��ʱ,��������ѡ����������Ϊ���ǵ�����(�ڷ����������ָ����score������Ԥ��ȷ��)���ڻع���,���������,MSEԽСԽ�á�����,�ع�ӿ�score���ص���
R
2
R^2
R2,
R
2
=
1
?
u
v
,
u
=
��
i
=
1
N
(
f
i
?
y
i
)
2
??
v
=
��
i
=
1
N
(
y
i
?
y
^
)
2
R^2=1-\frac{u}{v}\text{,}u=\sum_{i=1}^N{\left( f_i-y_i \right) ^2}\ \ v=\sum_{i=1}^N{\left( y_i-\widehat{y} \right) ^2}
R2=1?vu?,u=i=1��N?(fi??yi?)2??v=i=1��N?(yi??y
?)2
����,u�Dzв�ƽ����,v����ƽ����,N����������,i��ÿ����������,
f
i
f_i
fi?�ǻع�������Ľ��,
y
i
y_i
yi?��������i��ʵ��ֵ,
y
^
\widehat{y}
y
?����ʵֵ��ƽ��ֵ��
R
2
R^2
R2�ǿ����ɸ���(��СΪ������,���Ϊ1),��ģ�͵IJв�ƽ����ԶԶ����ģ�͵���ƽ����,ģ�ͷdz����,
R
2
R^2
R2�ͻ�Ϊ��,�����������ԶΪ����
ע:��Ȼ���������ԶΪ��,����sklearn����ʹ�þ��������Ϊ���б�ʱ,ȴ�Ǽ���"���������"(neg_mean_squared_error)��������Ϊsklearn�ڼ���ģ������ָ���ʱ��,�ῼ��ָ�걾��������,����������һ�����,���Ա�sklearn����Ϊģ�͵�һ����ʧ(loss),�����sklearn����,���Ը�����ʾ�������ľ������MSE����ֵ,��ʵ����neg_mean_squared_errorȥ�����ŵ����֡�
������֤�������۲�ģ�͵��ȶ��Ե�һ�ַ���,���ǽ����ݻ���Ϊn��,����ʹ������һ����Ϊ���Լ�,����n-1����Ϊѵ����,��μ���ģ�͵ľ�ȷ��������ģ�͵�ƽ��ȷ�̶ȡ�ѵ�����Ͳ��Լ��Ļ��ֻ����ģ�͵Ľ��,����ý�����֤n�εĽ�������ƽ��ֵ,�Ƕ�ģ��Ч����һ�����õĶ�����
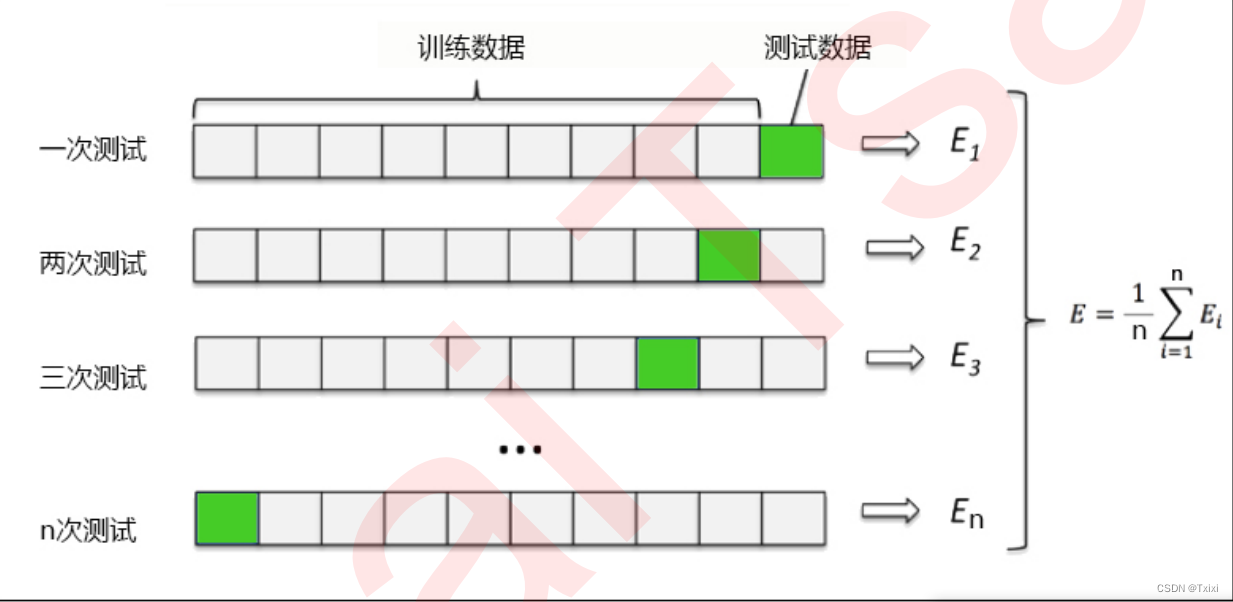
from sklearn.datasets import load_boston
from sklearn.model_selection import cross_val_score
from sklearn.tree import DecisiontreeRegressor
boston = 1oad_boston()
regressor = DecisionTreeRegressor(random_state=0)
cross_val_score(regressor, boston.data, boston.target, cV=10
#,scoring = "neg_mean_squared_error"
)
#������֤cross_val_score���÷�,��һ��������ʵ������ģ��,�ڶ��������Dz���Ҫ����ѵ�����Ͳ��Լ�������X,�ڶ��������Dz���Ҫ����ѵ�����Ͳ��Լ�������Y,���ĸ�������ȷ�������۽���,
3.2 ʵ��:һά�ع��ͼ�����
�ûع����������������,������һЩ�������۲�ع����ı��֡�
(1)������Ҫ�Ŀ�
import numpy as np
from sklearn.tree import DecisionTreeRegressor
import matplotlib.pyplot as plt
(2)����һ��������������������
����һ��,���ǵĻ���˼·��,�ȴ���һ�������,�ֲ���0-5�ϵĺ��������ȡֵ(x),Ȼ����һ��ֵ�ŵ�sin������ȥ�����������ֵ(y),�����ٵ�y��ȥ����������ȫ�����ǻ�ʹ��numpy����Ϊ������������������ߡ�
rng = np.random.RandomState(1)#����һ�����������
X = np.sort(5 * rng.rand(80,1), axis=0)#����0-5֮��������ɵ�X
y = np.sin(X).ravel()#������������
y[::5] += 3 * (0.5 - rng.rand(16))#�����������ϼ�����
#np.random.rand(����ṹ),�����������ĺ���
#�˽⽵ά����ravel()���÷�
np.random.random((2,1))
np.random.random((2,1)).ravel()
np.random.random((2,1)).ravel().shape
(3)ʵ����&ѵ��ģ��
regr_1 = DecisionTreeRegressor(max_depth=2)
regr_2 = DecisionTreeRegressor (max_depth=5)
regr_1. fit(X, y) regr_2. fit(x, y)
(4)���Լ�����ģ��,Ԥ����
X_test = np.arange(0.0,5.0,0.01)[:,np.newaxis]
y_l = regr_1.predict(X_test)
y_2 = regr_2.predict(X_test)
#np.arrange(��ʼ��,������,����)������������ĺ���
#�˽���ά��Ƭnp.newaxis���÷�
l = np.array([1,2,3,4])
l
l.shape
l[:,np.newaxis]
l[:,np.newaxis].shape
l[np.newaxis,:].shape
(5)����ͼ��
plt.figure()
plt.scatter(X, y, s=20, edgecolor="black",c="darkorange", label="data")
plt.plot(X_test, y_1, color="cornflowerblue",label="max_depth=2", linewidth=2)
plt.plot(X_test, y_2, color="yellowgreen", label="max_depth=5", linewidth=2)
plt.xlabel("data")
plt.ylabel("target")
plt.title("Decision Tree Regression")
plt.legend()#��ʾͼ��
plt.show()
�ɼ�,�ع���ѧϰ�˽����������ߵľֲ����Իع顣���ǿ��Կ���,�������������(��max_depth��������)���õ�̫��,�������ѧϰ��̫��ϸ,����ѵ��������ѧ�˺ܶ�ϸ��,���������ó���,�Ӷ�ʹģ��ƫ����ʵ����������,�γɹ���ϡ�
4.ʵ��:̩̹��˺��Ҵ��ߵ�Ԥ��
̩̹��˺ŵij�û�������������صĺ����¹�֮һ,����ͨ��������ģ����Ԥ��һ����Щ�˿��ܳ�Ϊ�Ҵ��ߡ� ���ݼ�����https://www.kaggle.com/c/titanic,���ݼ���������csv��ʽ�ļ�,dataΪ���ǽ�����Ҫʹ�õ�����,testΪkaggle�ṩ�IJ��Լ�,test�������Dz����õ�,û�б�ǩ��,Ҳ����û�н����
(1)��������Ŀ�
import pandas as pd
from sklearn.tree import DecisionTreeClassifier
from sklearn.model_selection import train_test_split
from sklearn.model_selection import GridSearchCV
from sklearn.model_selection import cross_val_score
import matplotlib.pyplot as plt
(2)�������ݼ�,̽������
data = pd.read_csv(r"C:\work\learnbetter\micro-class\week 1 DT\data\data.csv",index_col
= 0)
data.head()
data.info()
(3)����Ԥ����
#ɾ��ȱʧֵ�������,�۲��ж���˵��Ԥ���yû�й�ϵ����,inplace=True��ʾ����ɾ����ı�����ԭ��,Ĭ�ϵ���false,axis=1��ʾ���н��в�����
data.drop(["Cabin","Name","Ticket"],inplace=True,axis=1)
#����ȱʧֵ,��ȱʧֵ�϶���н����,��һЩ����ֻȷʵһ����ֵ,���Բ�ȡֱ��ɾ����¼�ķ���
data["Age"] = data["Age"].fillna(data["Age"].mean())
data = data.dropna()
#���������ܴ�������
#�����������ת��Ϊ��ֵ�ͱ���
#astype�ܹ���һ��pandas����ת��Ϊij������,��apply(int(x))��ͬ,astype���Խ��ı���ת��Ϊ����,�������ʽ���Ժܱ�ݵؽ�����������ת��Ϊ0~1
data.loc[:,"Sex"] = (data["Sex"]== "male").astype("int")
#�����������ת��Ϊ��ֵ�ͱ���
labels = data["Embarked"].unique().tolist()
data["Embarked"] = data["Embarked"].apply(lambda x: labels.index(x))
#�鿴����������ݼ�
data.head()
(4)��ȡ��ǩ����������,�ֲ��Լ���ѵ����
X = data.iloc[:,data.columns != "Survived"] #ȡ�����е��кͳ�Survived����
y = data.iloc[:,data.columns == "Survived"]
from sklearn.model_selection import train_test_split
Xtrain, Xtest, Ytrain, Ytest = train_test_split(X,y,test_size=0.3)
#���������,��������������
#�������Լ���ѵ����������,
for i in [Xtrain, Xtest, Ytrain, Ytest]:
i.index = range(i.shape[0])
#�鿴�ֺõ�ѵ�����Ͳ��Լ�
Xtrain.head()
(5)����ģ��
clf = DecisionTreeClassifier(random_state=25)
clf = clf.fit(Xtrain, Ytrain)
score_ = clf.score(Xtest, Ytest)
score_
score = cross_val_score(clf,X,y,cv=10).mean()
score
(6)��max_depth����
tr = []
te = []
for i in range(10):
clf = DecisionTreeClassifier(random_state=25
,max_depth=i+1
,criterion="entropy"
)
clf = clf.fit(Xtrain, Ytrain)
score_tr = clf.score(Xtrain,Ytrain)
score_te = cross_val_score(clf,X,y,cv=10).mean()
tr.append(score_tr)
te.append(score_te)
print(max(te))
plt.plot(range(1,11),tr,color="red",label="train")
plt.plot(range(1,11),te,color="blue",label="test")
plt.xticks(range(1,11))
plt.legend()
plt.show()
#����Ϊʲôʹ�á�entropy��?��Ϊ����ע�,��������=3��ʱ��,ģ����ϲ���,��ѵ�����Ͳ��Լ��ϵı��ֽӽ�,��ȴ�����Ƿdz�����,ֻ�ܹ��ﵽ83%����,��������Ҫʹ��entropy��
(7)������������������
�ܹ���������ͬʱ������������ļ���(ö�ټ���),��ȱ���ʱ��
import numpy as np
gini_thresholds = np.linspace(0,0.5,20)
#һ����������Щ������Ӧ��,����ϣ�����������������IJ�����ȡֵ��Χ
parameters = {'splitter':('best','random')
,'criterion':("gini","entropy")
,"max_depth":[*range(1,10)]
,'min_samples_leaf':[*range(1,50,5)]
,'min_impurity_decrease':[*np.linspace(0,0.5,20)]
}
clf = DecisionTreeClassifier(random_state=25)
GS = GridSearchCV(clf, parameters, cv=10)
GS.fit(Xtrain,Ytrain)
GS.best_params_ #����������IJ����Ͳ���ȡֵ���б���,����������
GS.best_score_ #�����������ģ�͵����б�
5.����������ȱ��
5.1�������ŵ�
-
��������ͽ���,��Ϊ��ľ���Ի�����������;
-
��Ҫ���ٵ��������������ܶ��㷨ͨ������Ҫ���ݹ淶��,��Ҫ�������������ɾ����ֵ�ȡ�����ע��,sklearn�еľ�����ģ����֧�ֶ�ȱʧֵ�Ĵ���;
-
ʹ�����ijɱ�(����˵,��Ԥ�����ݵ�ʱ��)������ѵ���������ݵ�������Ķ���,����������㷨,����һ���ܵ͵ijɱ�;
-
�ܹ����ع��ֿ���������,��������ͨ��ר�����ڷ���������һ�ֱ������͵����ݼ�;
-
�ܹ��������������,�����ж����ǩ������,ע����һ����ǩ�к��ж��ֱ�ǩ�������������;
-
��һ����ģ��,����������ܹ������͡������ģ���п��Թ۲쵽���������,�����ͨ�����������ɽ����������෴,�ںں�ģ����(����,���˹���������),������ܸ����Խ���;
-
����ʹ��ͳ�Ʋ�����֤ģ��,�������ǿ��Կ���ģ�͵Ŀɿ���;
-
��ʹ�������ij�̶ֳ���Υ�����������ݵ���ʵģ��,Ҳ�ܹ��������á�
5.2������ȱ��
- ������ѧϰ�߿��ܴ������ڸ��ӵ���,��Щ�����ܺܺõ��ƹ����ݡ����Ϊ������ϡ���,����Ҷ�ڵ��������С���������������������ȵȻ����DZ���������������,����Щ���������Ϻ͵����Գ�ѧ����˵��Ƚϻ�ɬ;
- ���������ܲ��ȶ�,������С�ı仯���ܵ���������ȫ��ͬ����,���������Ҫͨ�������㷨�����;
- ��������ѧϰ�ǻ���̰���㷨,�����Ż��ֲ�����(ÿ���ڵ������)����ͼ�ﵽ���������,�������������ܱ�֤����ȫ�����ž��������������Ҳ�����ɼ����㷨�����,�����ɭ����,�������������ڷ�֦�����б��������;
- ��Щ�������ѧϰ,��Ϊ�����������ױ�������,����XOR,��żУ����·����������;
- �����ǩ�е�ijЩ��ռ������λ,������ѧϰ�ᴴ��ƫ����������������,��������Ͼ�����֮ǰƽ�����ݼ���

