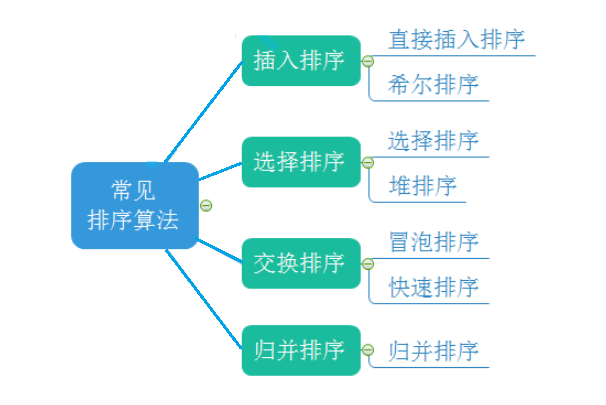
���������ߴ�����
1.����ĸ��������
1.1����ĸ���
����:��ν����,����ʹһ����¼,�������е�ij����ijЩ�ؼ��ֵĴ�С,������ݼ������������IJ�����
�ȶ���:�ٶ��ڴ�����ļ�¼������,���ڶ��������ͬ�Ĺؼ��ֵļ�¼,����������,��Щ��¼����Դ� �ֲ���,����ԭ������,r[i]=r[j],��r[i]��r[j]֮ǰ,����������������,r[i]����r[j]֮ǰ,��������� ���㷨���ȶ���;�����Ϊ���ȶ��ġ�
�ȶ��Ե�����:�ڸ��ݶ������Խ�������ʱ���о�����塣���������ȶ�ѧ������ѧ�Ž���������,�ٶ�ѧ�������˰��ճɼ���������,��ʱѧ�źͳɼ���Ϊ�����־�������,��������ڰ��ճɼ���������ʱ,��ʹ�õ��㷨�Dz������ȶ��Ե�,��ô�ڶԳɼ������,֮ǰ����ѧ�Ž��е������û��������,��ʱ�ͻ������ͬ�ɼ�,����ѧ�ſ������ǰ��,��֮,�������ѡ�����������ȶ���,��ô�ɼ���ͬ,ѧ�ſ�ǰ��Ӧ����ǰ�档
�ڲ�����:����Ԫ��ȫ�������ڴ��е�����
�ⲿ����:����Ԫ��̫���ͬʱ�����ڴ���,����������̵�Ҫ�����������֮���ƶ����ݵ�����һ�������Ǵ洢�ڴ����еġ�
������������:
| �������� | ���ݴ洢 | �����ٶ� | ֧�ֵķ�����ʽ |
|---|---|---|---|
| ������ | �������ڴ���(����) | �� | �±�������� |
| ������ | �����ڴ�����,�������ܴ� | �� | ���з��� |
1.2 ���������
������ǰ��۸���ֻ���������:
�����Ǹ����ۺϵ÷ֶԴ�ѧ��������:
1.3 �����������㷨
2. ���������㷨��ʵ��
2.1 ��������
2.1.1 ����˼��
ֱ�Ӳ���������һ�ּIJ�������,�����˼����:
�Ѵ�����ļ�¼����ؼ���ֵ�Ĵ�С������뵽һ���Ѿ��ź��������������,ֱ�����еļ�¼������Ϊֹ,�õ�һ���µ��������� ��
����˵����:��һ����������,����һ������,���ɱ���������
2.1.2ֱ�Ӳ�������
�������i(i>=1)��Ԫ��ʱ,ǰ���array[0],array[1],��,array[i-1]�Ѿ��ź���,��ʱ��array[i]���������� array[i-1],array[i-2],����������˳����бȽ�,�ҵ�����λ�ü���array[i]����,ԭ��λ���ϵ�Ԫ��˳����ơ�
��ͼչʾ:
����ʵ��:(�˴��ŵ�������)
void InsertSort(int *a,int n)
{
for (int i = 0; i < n-1;i++)//end:[0:n-2] end+1:[1:n-1]
{
int end = i;
//[0,end]���� ��[end+1]�����ȥ,��������������
int tmp = a[end + 1];
while (end >= 0)
{
if (tmp < a[end])//������ǰ� < ��Ϊ >
{
a[end + 1] = a[end];
--end;
}
else
{
break;
}
}
a[end + 1] = tmp;
//�˴����������,��һ�־������ݵ���Ӧ�ò����λ��(��a[0]),��һ�־�������Ҫ���뵽a[0]��λ��
}
}
ֱ�Ӳ�������������ܽ�:
- Ԫ�ؼ���Խ�ӽ�����,ֱ�Ӳ��������㷨��ʱ��Ч��Խ��
- ʱ�临�Ӷ�:O(N^2) ������(����):1 + 2 + ������������ + N ʱ�临�Ӷ�:O(N2) ���:(����)O(N)
- �ռ临�Ӷ�:O(1),����һ���ȶ��������㷨
- �ȶ���:�ȶ�
2.1.3 ϣ������
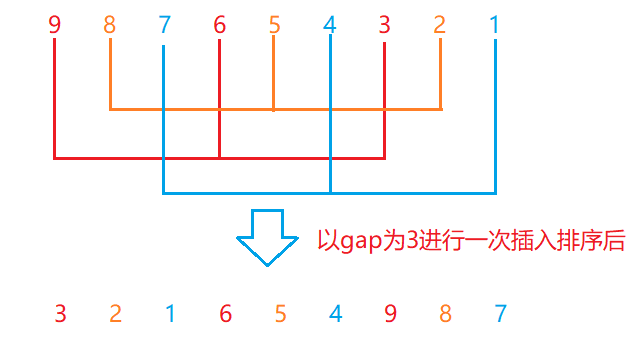
ϣ������(ShellSort)�ֳ�Ϊ����С����������1959����D.L.Shell������ġ��÷����Ļ���˼����:�Ƚ���������Ԫ�����зָ�����ɸ�������(�����ij������������Ԫ����ɵ�)�ֱ����ֱ�Ӳ�������,Ȼ���������������ٽ�������,�����������е�Ԫ�ػ�������(�����㹻С)ʱ,�ٶ�ȫ��Ԫ�ؽ���һ��ֱ�Ӳ�����������Ϊֱ�Ӳ���������Ԫ�ػ�������������(�ӽ�������),Ч���Ǻܸߵ�,���ϣ��������ʱ��Ч���ϱ�ǰ���ַ����нϴ���ߡ�
��������:����ȷ��һ������d0,d1,d2,d3,��,dt-1()����n>d0>d1>��>dt-1=1),����i=0,1,2,��,t-1,���ν�������ĸ��˴���:���ݵ�ǰ����di��n��Ԫ�طֳ�di����,ÿ����Ԫ�ص��±����Ϊdi;�ٶԸ�����Ԫ�ؽ���ֱ�Ӳ�������.
��ͼչʾ:
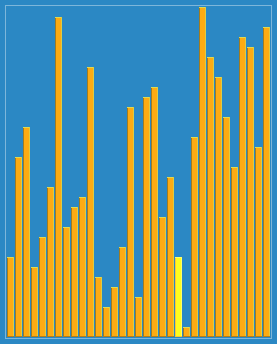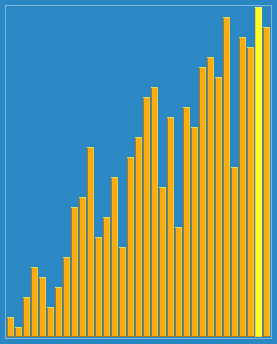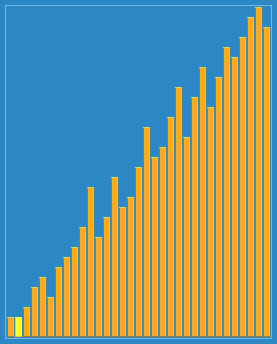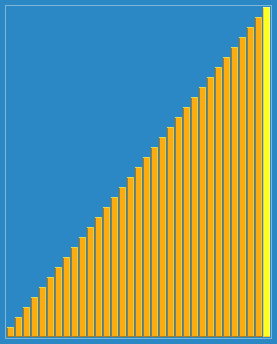
1��Ԥ����:���������ĵ�����ȥ,С��������ĵ�ǰ��ȥ,�����ܵؽӽ�����
����:
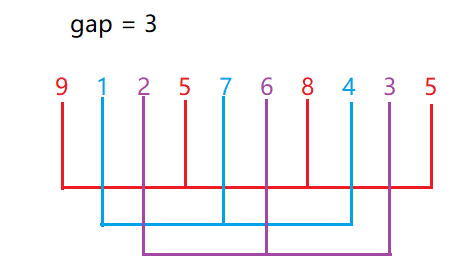
gapΪ��,�ͽ����ֻ���Ϊ��������,Ȼ��ֱ���⼸�����ݽ��в�������,�����������������,���ȶ�9��5��8��5���в�������,Ȼ���1��7��4���в�������,Ȼ���ٶ�2��6��3���в������������Ԥ����
��:gap�Ĵ�С��Ԥ������������ʲô��ϵ?
��:���gapԽС,������ԾԽ��,����Ԥ���������ݾ�Խ�ӽ�����;���gapԽ��,������ݿ��Ը���ĵ������,С�����ݿ��Ը���ĵ���ǰ��,����Խ���ӽ�����,ֻ��˵���������
��:ϣ�������һ����ֱ�Ӳ����������?
��:��һ��,���������鱾������������߽ӽ������ʱ��,���е�Ԥ������൱�������ù�,�൱���ǰ�����,��ʱ��Ч�ʾͲ���ֱ�Ӳ��������ˡ���Ȼ,��������Ǻ��ٵ�,һ�����������ݶ���������߽ӽ������,�����������һ�㲻ȥ���ǡ�
2��ֱ�Ӳ�������
ֱ�Ӳ����������gapΪ1ʱ�������,����ֱ�Ӳ�������,���ڴ�ʱ�������Ѿ��ӽ�����,���Բ�������������Ϊ���ס�
��:���������������������?
��:�ڼ��gap�����ݽ��в�������ʱ,�൱��һ�ο�Խgap�����ݽ����ƶ�,�����ӱ��������������ֱ�Ӳ��������ʡ�˺ܶ��ѭ�������ѵ�ʱ��,����ٸ���������:
�ھ���һ��gapΪ3�IJ��������,��С����������3��2��1�Ѿ��ŵ�����ǰ��,�м����������6��5��4�Ѿ������м�,�ϴ����������9��8��7�Ѿ��������,���������ڽ���ֱ�Ӳ��������ʱ��,1ֻ��Ҫ�ƶ����ξ��ܵ�����ǰ��,�����û�н���gapΪ3���Ǵ�Ԥ����Ļ�,1��Ҫ�ƶ�8�ν���8��ѭ�����ܵ�������Ҫ�����λ��,�����ϣ��������ߵ�Ч�����ڡ�
����:
//ϣ������:��ͳд��
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)//����ط�������>=1,��Ϊ��������Ŀ��ƺ�,gapʼ�մ���1,�����>=1,�ͻ�������ѭ��
{
gap = gap / 3 + 1;//��֤���һ��һ����1,�������һ��ֱ�Ӳ�������
for (int k = 0; k < gap; k++)
{
for (int i = k; i < n - gap; i += gap)//Ϊʲô��n - gap?��Ϊ���һ��end��n-1-gap,end+gapһ��С��n
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
break;
}
a[end + gap] = tmp;
}
}
}
}
������ϣ��������Ż�д��:
���IJ�ѭ����Ϊ3��ѭ��,��Ȼ,Ч�ʲ�û������,ֻ�ǽ������ѭ������������һ��,����ʱ�临�Ӷ���ʵ��û��̫�������
//ϣ������:�Ż�д��
void ShellSort(int* a, int n)
{
int gap = n;
while (gap > 1)//����ط�������>=1,��Ϊ��������Ŀ��ƺ�,gapʼ�մ���1,�����>=1,�ͻ�������ѭ��
{
gap =gap/3 + 1;//��֤���һ��һ����1,�������һ��ֱ�Ӳ�������
for (int i = 0; i < n - gap; ++i)//Ϊʲô��n - gap?��Ϊ���һ��end��n-1-gap,end+gapһ��С��n
{
int end = i;
int tmp = a[end + gap];
while (end >= 0)
{
if (tmp < a[end])
{
a[end + gap] = a[end];
end -= gap;
}
else
break;
}
a[end + gap] = tmp;
}
}
}
ϣ������������ܽ�:
ϣ�������Ƕ�ֱ�Ӳ���������Ż���
��gap > 1ʱ����Ԥ����,Ŀ������������ӽ�������gap == 1ʱ,�����Ѿ��ӽ��������,������ ��ܿ졣�����������,���Դﵽ�Ż���Ч��������ʵ�ֺ���Խ������ܲ��ԵĶԱȡ�
ϣ�������ʱ�临�ӶȲ��ü���,��Ϊgap��ȡֵ�����ܶ�,���º���ȥ����,����ں�Щ���и����� ϣ�������ʱ�临�Ӷȶ����̶�:
�����ݽṹ(C����)���� ��ε��
�����ݽṹ-�����������C++�������� ������
��Ϊ���ǵ�gap�ǰ���Knuth����ķ�ʽȡֵ��,����Knuth�����˴�����ʵ��ͳ��,���Ǿ���ʱ����:==O(n1.25)��O(1.6*n1.25)==����
�ȶ���:���ȶ�


��������Լ���ϣ�������ʱ�临�ӶȵĻ�:
Ԥ����:
gap�ܴ�ʱ,�������ĺܿ�,�����O(N),�ڲ�ѭ���������Բ���,��Ծ�ĺܿ�(ÿ����Ծgap��)��
gap��Сʱ,���ݺܽӽ�����,��������ҪŲ��,��ʱ���Ҳ��O(N)��
�����ѭ��:
�ܹ�ѭ��log3N��
�������Ǵ��Խ��м����ʱ��ʱ�临�Ӷ�:O(N*log3N)
2.2 ѡ������
2.2.1 ����˼��
ÿһ�δӴ����������Ԫ����ѡ����С(�����)��һ��Ԫ��,��������е���ʼλ��,ֱ��ȫ�������������Ԫ������ ��
2.2.2 ֱ��ѡ������
- ��Ԫ�ؼ���array[i]�Carray[n-1]��ѡ��ؼ������(С)������Ԫ��
- ������������Ԫ���е����һ��(��һ��)Ԫ��,����������Ԫ���е����һ��(��һ��)Ԫ�ؽ���
- ��ʣ���array[i]�Carray[n-2](array[i+1]�Carray[n-1])������,�ظ���������,ֱ������ʣ��1��Ԫ��
��̬ͼ:
ֱ��ѡ������������ܽ�:
- ֱ��ѡ������˼���dz�������,����Ч�ʲ��Ǻܺá�ʵ���к���ʹ��
- ʱ�临�Ӷ�:O(N^2)
- �ռ临�Ӷ�:O(1)
- �ȶ���:���ȶ�
ѡ���������ʵ��:
void SelectSort(int* a, int n)
{
int left = 0;
int right = n - 1;
while (left < right)
{
int maxi = left;
int mini = left;
//����Ϊʲô�����ұ�����?��Ϊmaxi��mini�Ѿ�����left����С������������,���Բ����ٰ���left��,����rightb
for (int i = left + 1; i <= right; i++)
{
if (a[i] < a[mini])
{
mini = i;
}
if (a[i] > a[maxi])
{
maxi = i;
}
}
Swap(&a[left], &a[mini]);
//���left��maxi�ص�,�ڽ�mini��left����֮��,mini��ʱ�͵���maxi
if (left == maxi)
{
maxi = mini;
}
Swap(&a[right], &a[maxi]);
left++;
right--;
}
}
2.2.3 ������
������(Heapsort)��ָ���öѻ���(��)�������ݽṹ����Ƶ�һ�������㷨,����ѡ�������һ�֡����� ͨ����������ѡ�����ݡ���Ҫע�����������Ҫ�����,�Ž���С�ѡ�
2.3 ��������
����˼��:��ν����,���Ǹ���������������¼��ֵ�ıȽϽ�����Ի���������¼�������е�λ��,����������ص���:����ֵ�ϴ�ļ�¼�����е�β���ƶ�,��ֵ��С�ļ�¼�����е�ǰ���ƶ���
2.3.1����
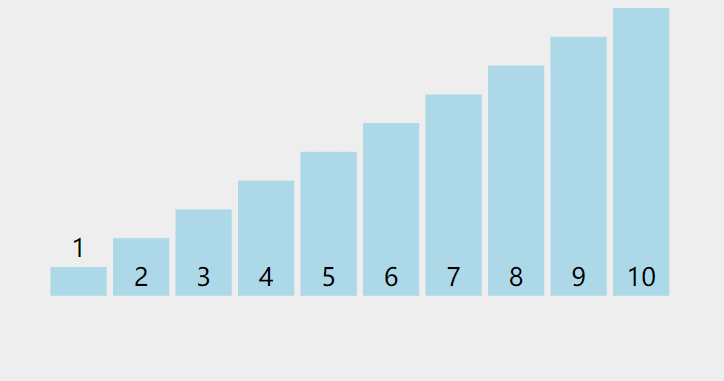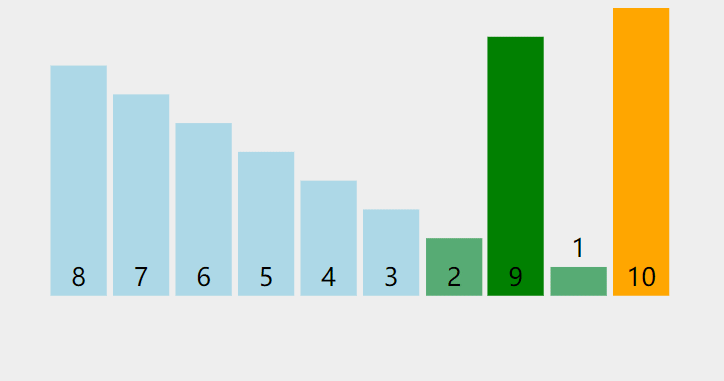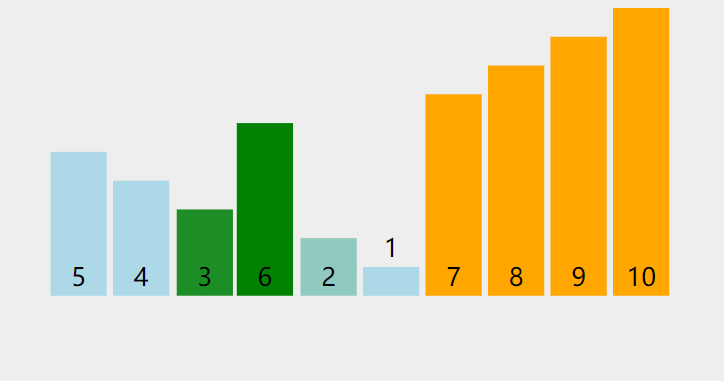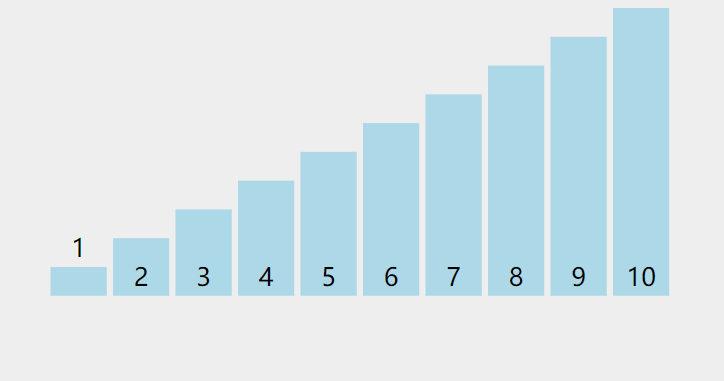
����:
void BubbleSort(int* a, int n)
{
for (int i = 0; i < n; i++)
{
int exange = 0;
for (int j = 0; j < n - i - 1; j++)
{
if (a[j] > a[j + 1])
{
Swap(&a[j], &a[j + 1]);
exange = 1;
}
}
if(exange == 0)//�������ʱ��ֱ���˳�
break;
}
}
ð������������ܽ�:
1. ð��������һ�ַdz��������������
2. ʱ�临�Ӷ�:O(N^2) ������:˳������:O(N)(���ٵ�ִ��һ���ڲ�ѭ��)
3. �ռ临�Ӷ�:O(1)
4. �ȶ���:�ȶ�
ð���������������ıȽ�
���֮��,������������һЩ,����������������:
1 2 3 4 5 6 8 7
��������²�������Ҫ�Ƚ�8��,����ð������Ҫ�Ƚ�7 + 6 = 13�Ρ���Ȼ����ʱ��ʱ�临�Ӷȶ���O(N)��
�����ھֲ�����������:
3 4 2 8 7 9 5 9
ð��������Ż������������ֳ�ʲô��ֵ,���Dz�������ȴ�ܳ�����þֲ���������,ʹ�Ƚϴ������١�
�ܽ�:�����˳����������,��ô�����ð����һ����;��������Ǿֲ�����,���߽ӽ�����,��ô�������Ӧ�Ը���,�Ƚϴ������١�
2.3.2 ��������
2.3.2.1 ��������Ĵ���ʵ��(����˼·)
����������Hoare��1962�������һ�ֶ������ṹ�Ľ�������,�����˼��Ϊ:��ȡ������Ԫ�������е�ijԪ����Ϊ��ֵ,���ո������뽫�����Ϸָ����������,��������������Ԫ�ؾ�С�ڻ�ֵ,��������������Ԫ�ؾ����ڻ�ֵ,Ȼ���������������ظ��ù���,ֱ������Ԫ�ض���������Ӧλ����Ϊֹ��
// ���谴�������array������[left, right)�����е�Ԫ�ؽ�������
void QuickSort(int array[], int left, int right)
{
if (right - left <= 1)
return;
// ���ջ�ֵ��array����� [left, right)�����е�Ԫ�ؽ��л���
int div = partion(array, left, right);
// ���ֳɹ�����divΪ�߽��γ������������� [left, div) �� [div+1, right)
// �ݹ���[left, div)
QuickSort(array, left, div);
// �ݹ���[div+1, right)
QuickSort(array, div + 1, right);
}
����Ϊ��������ݹ�ʵ�ֵ������,�����������ǰ���������dz���,������д�ݹ���ʱ�����������ǰ��������ɿ���д����,����ֻ�������ΰ��ջ�ֵ�������������ݽ��л��ֵķ�ʽ���ɡ�
�����䰴�ջ�ֵ����Ϊ�������벿�ֵij�����ʽ��:
-
hoare�汾
��������:ѡ��һ��key,һ���ǵ�һ�����������һ����
Ҫ��:��ߵ�ֵ����keyҪС,�ұߵ�ֵ����keyҪ��
��ͼչʾ:
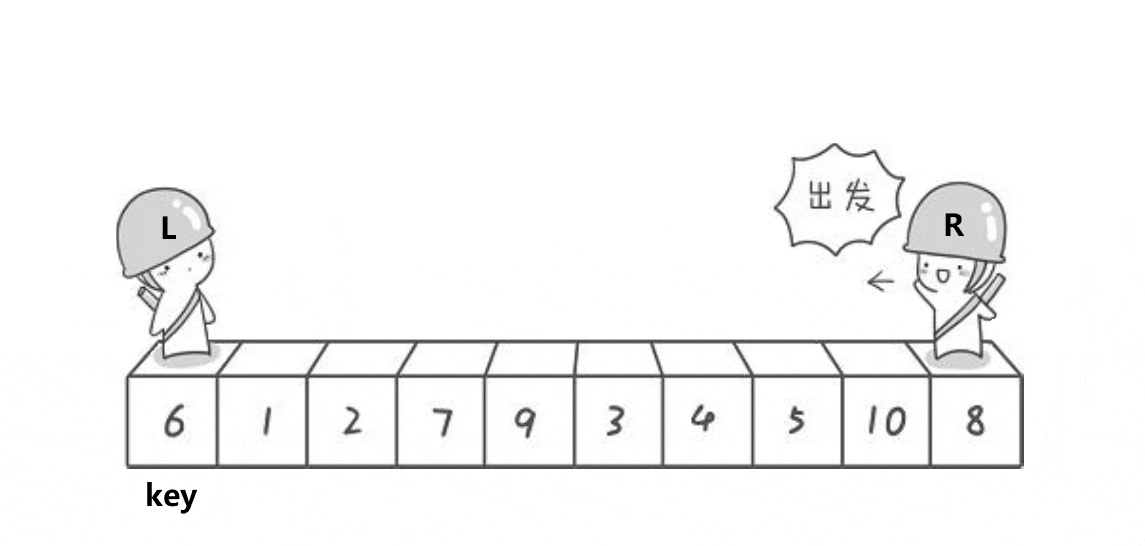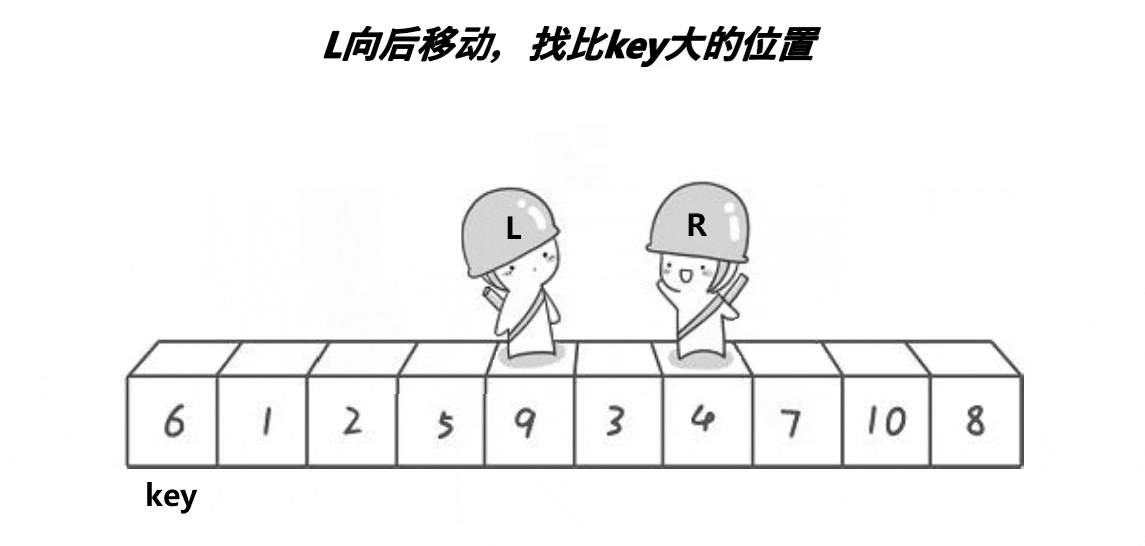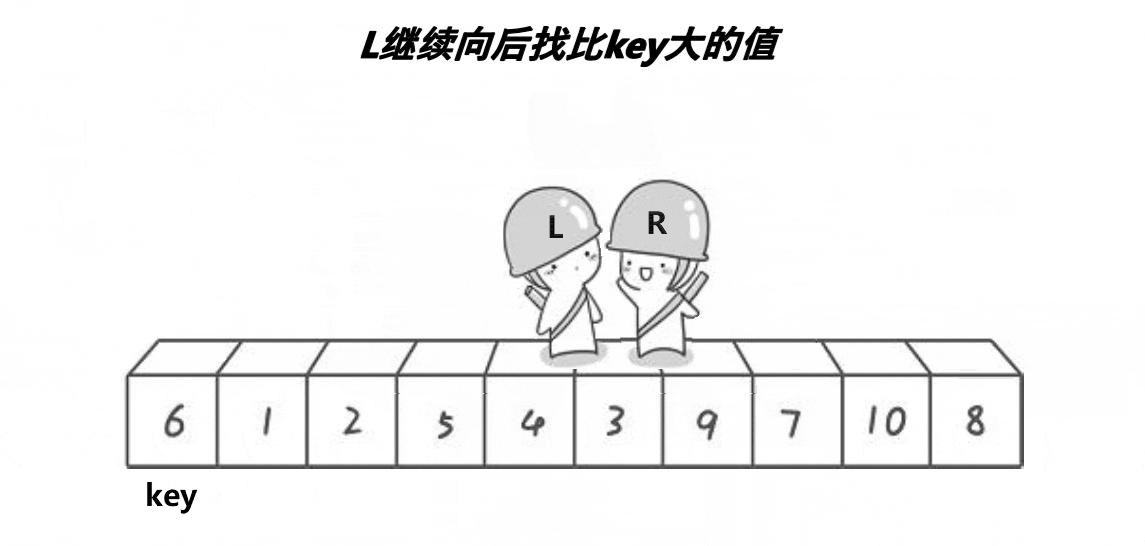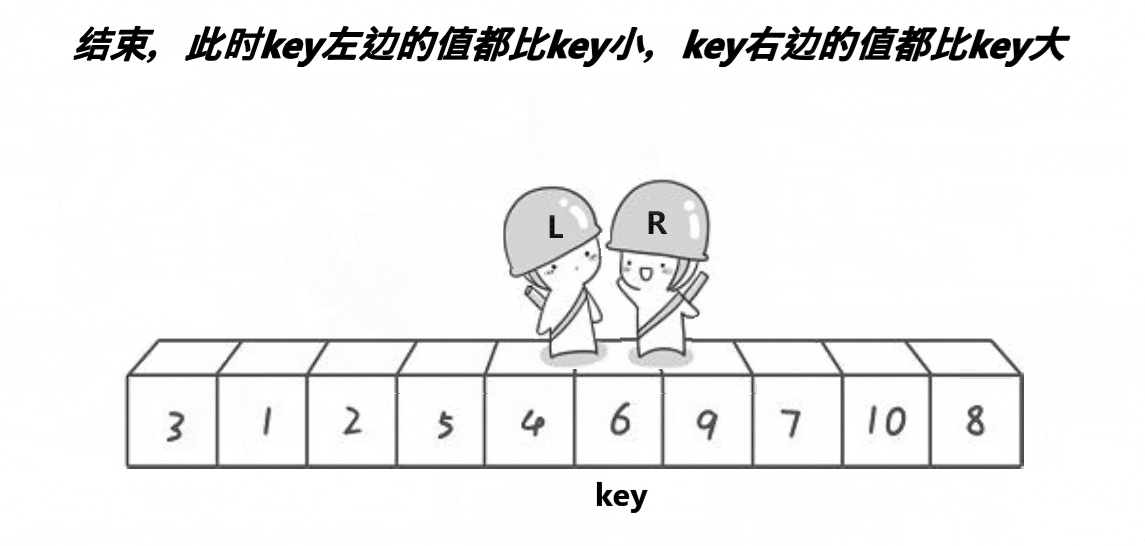
ͼ��չʾ:

�ܽ�:R�ұ�keyС��ֵ,L�ұ�key���ֵ,�ҵ���,���ظ���������,����֮��,������λ�õ�ֵ��key������
��:��������ĿΪż����ʱ��,�Ƿ����ֲ����������������α�֤����λ�õ�ֵһ����keyС��?
��:����,��ΪR��������L�ƶ�,�ܻ��ҵ�һ����keyС��λ��,��ʹL�ĺ��治��һ��С��key������,��ʱ��RҲ�ᵽ��L������λ��,��Ϊ֮ǰ��������,��ʱһ����һ����keyС�����֡������վ���ֻ���������:Rȥ��L,����Lȥ��R,������һ��,���������ĵط�����һ����keyС��λ�á�
��:����ұ���key,��ô��һ����������ʲô���ӵ�?
��:��һ���������ͼ��ʾ:
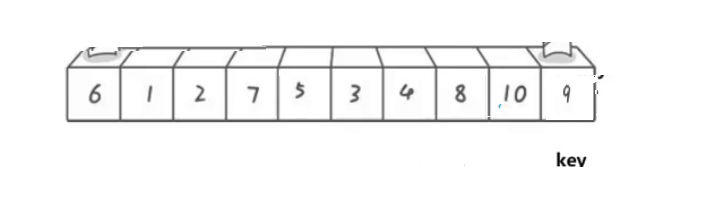
��ʱҪע��������������,Ϊ�˱�֤������һ����һ����key������ݡ�
��������������д��˼·:
��ʼ����:
int PartSort(int *a,int left,int right)//�������������� { int keyi = left; while (left < right) { //�ұ���С while (a[right] > a[keyi]) { right--; } //����Ҵ� while (a[left] < a[keyi]) { left++; } Swap(&a[left], &a[right]); } Swap(&a[keyi], &a[left]); return left;//����������λ�� }������,����Ĵ��벢������,�������������,��������������:
1 2 3 4 55 5 2 3 5����������¾ͻ�������ѭ��,��Ϊ5������5,rightʼ�������ШC����,leftҲͬ��������++����,��ʱ�ͻ�������ѭ������ʱ�����Ż�,����ȵ�ʱ��ҲҪ���ШC����:
int PartSort(int *a,int left,int right)//�������������� { int keyi = left; while (left < right) { //�ұ���С while (a[right] >= a[keyi]) { right--; } //����Ҵ� while (a[left] <= a[keyi]) { left++; } Swap(&a[left], &a[right]); } Swap(&a[keyi], &a[left]); return left;//����������λ�� }��ʱ�ֳ������µ�����:���right�Ҳ�����keyС��,�ͻ����Խ��ķ���,�����ڽ���
a[right]>=a[keyi]�����жϵ�ǰ�滹Ҫ����һ������,�����Ǵ���Ľ�һ���Ż�:(���հ�)int PartSort(int *a,int left,int right)//�������������� { int keyi = left; while (left < right) { //�ұ���С while (left<right && a[right] >= a[keyi]) { right--; } //����Ҵ� while (left < right && a[left] <= a[keyi]) { left++; } Swap(&a[left], &a[right]); } Swap(&a[keyi], &a[left]); return left;//����������λ�� }��ʱ���н������ķ���������:
��ʱkeyi���ڵ����ݾͲ���Ҫ�ٽ����ƶ���,�Ѿ���������ȷ��λ�á����keyi���������,�ұ�������,��ô����������������ʱ����Ҫ����������˼��,��ʱ�ֱ���ұ߽��е�������ĵݹ�,ֱ���������ݶ�����,Ȼ���ظ����������,ֱ��ֻ��һ������ʱΪֹ,��ʱ�˳��ݹ�,�����������ġ�
������������������:
void QuickSort(int* a,int begin,int end) { //�����ִ�λ���߶�����ȵ�ʱ���ֹͣ if (begin >= end) return; int keyi = PartSort(a, begin, end); //�ָ��������������:[begin,keyi-1]keyi[keyi+1,end] QuickSort(a, begin, keyi - 1); QuickSort(a, keyi+1, end); }��:return�������ж�Ϊʲô��
begin >= end?������ֻ��һ��==��?��:���統�����������ʱ,begin = 0,end = 2,keyi = 1,��ʱ�ͻ������������,����[0,0]��[2,1],���ֻ����ȵĻ�,�ж�ǰ���������Ȼû��ʲô����,�����жϺ���IJ����ڵ�����ʱ�Ͳ����ˡ�
-
�ڿӷ�
��ͼչʾ:
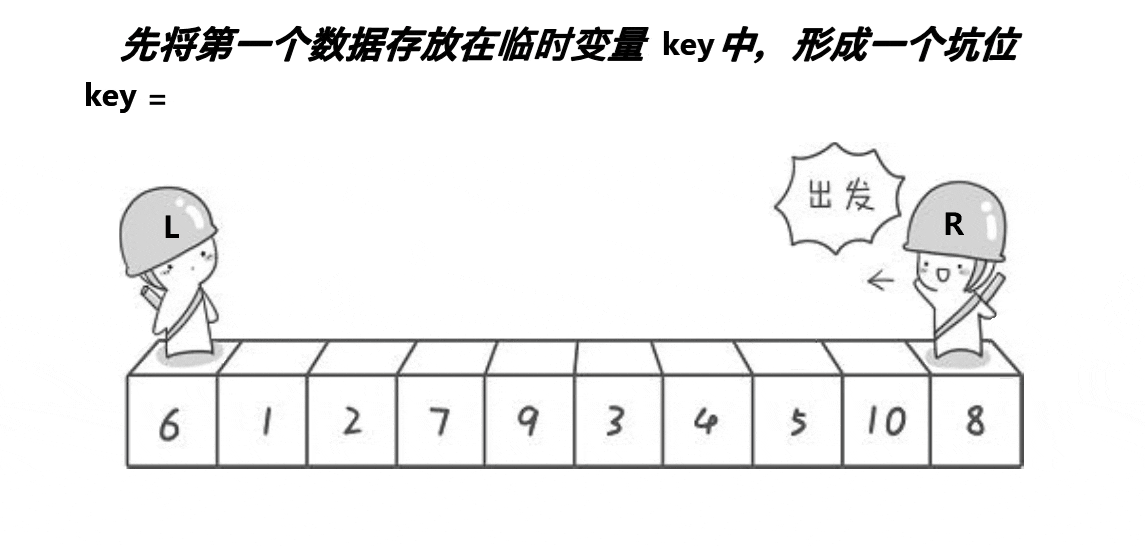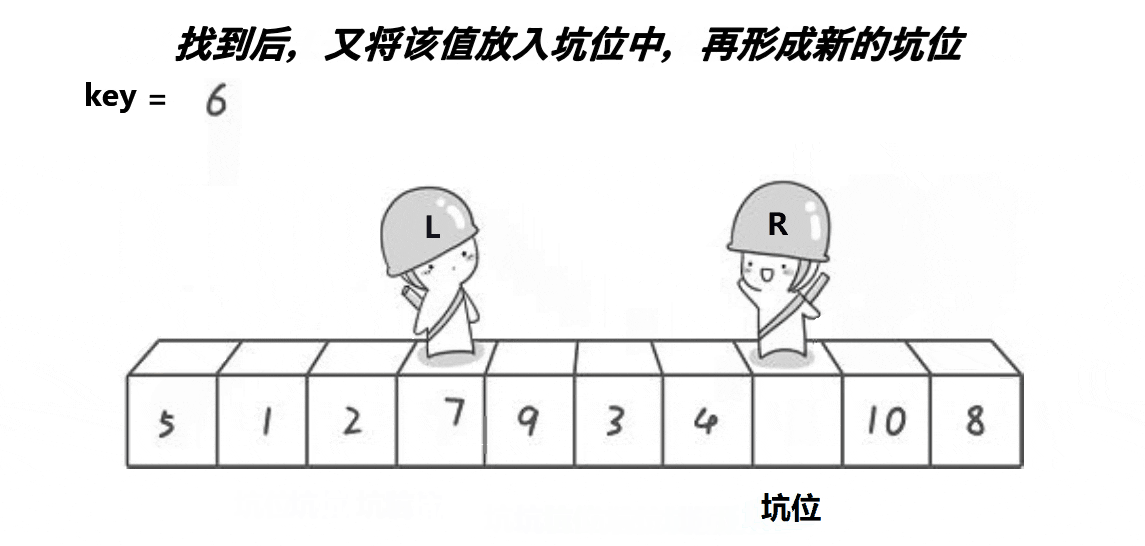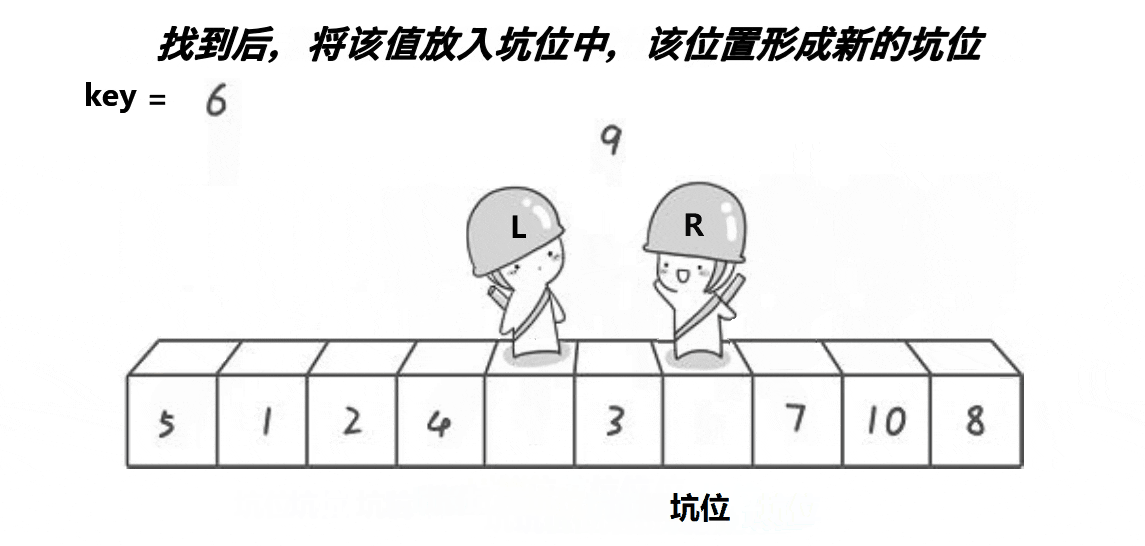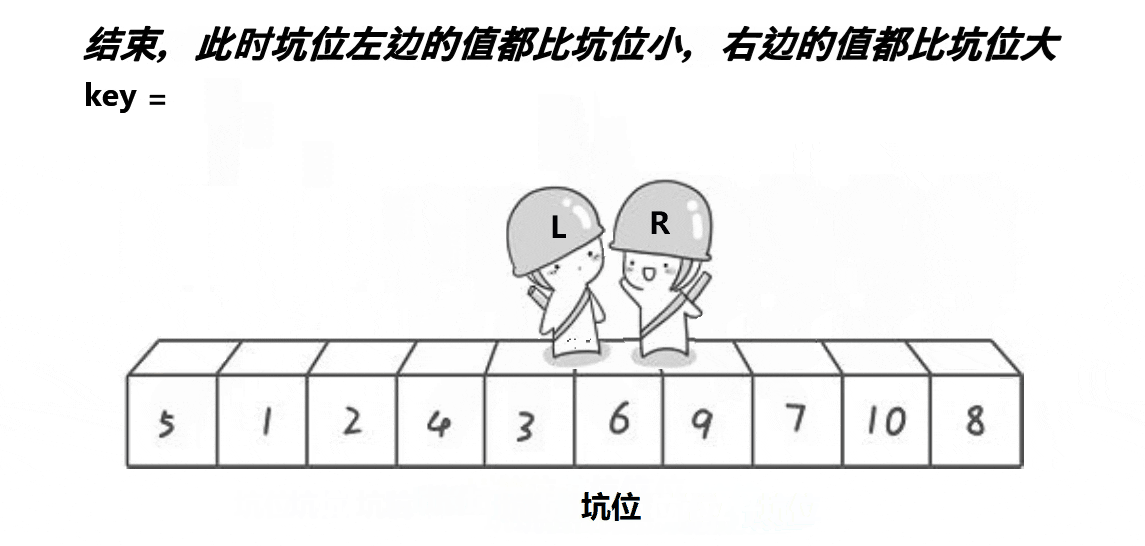
����:
int PartSort2(int* a, int left, int right) { int key = a[left]; int hole = left;//��¼�ӵ��±� while (left < right) { while (left<right&& a[right] >= key)//���ұ���С��key�� { right--; } a[hole] = a[right];//���ҵ���ֵ�ŵ���λ��ȥ hole = right;//�γ��µĿ� while (left<right&&a[left] <= key)//������Ҵ���key�� { left++; } a[hole] = a[left];//���ҵ���ֵ�ŵ���λ��ȥ hole = left;//�γ��µĿ� } a[left] = key;//��key�ŵ�������λ����ȥ(������λ��һ���ǿ�) return left;//��������λ�õ��±� }��:�ڿӷ���hoare��ʲô������?������Ч���Ƿ�һ��?�ڿӷ��Ƿ��һ����hoare��������?
��:�ڿӷ���hoare����û�б��ʵ�����,������ʱ�临�Ӷ�Ҳ����һ����,������˭��˭�ӵ�����,���ߵĺû���û���ϸ����,�ڿӷ����hoare������˵,����������,hoare�������ڳ���,��Щ��̫�����⡣��Ҫע�����:��ʹ�����ַ���������һ��������γɵĽ������һ������ͬ��,����˵���ߴ��������¶��Dz���ͬ��,ֻ����������²�����ͬ�ġ�
-
ǰ��ָ�뷨
��ͼչʾ:
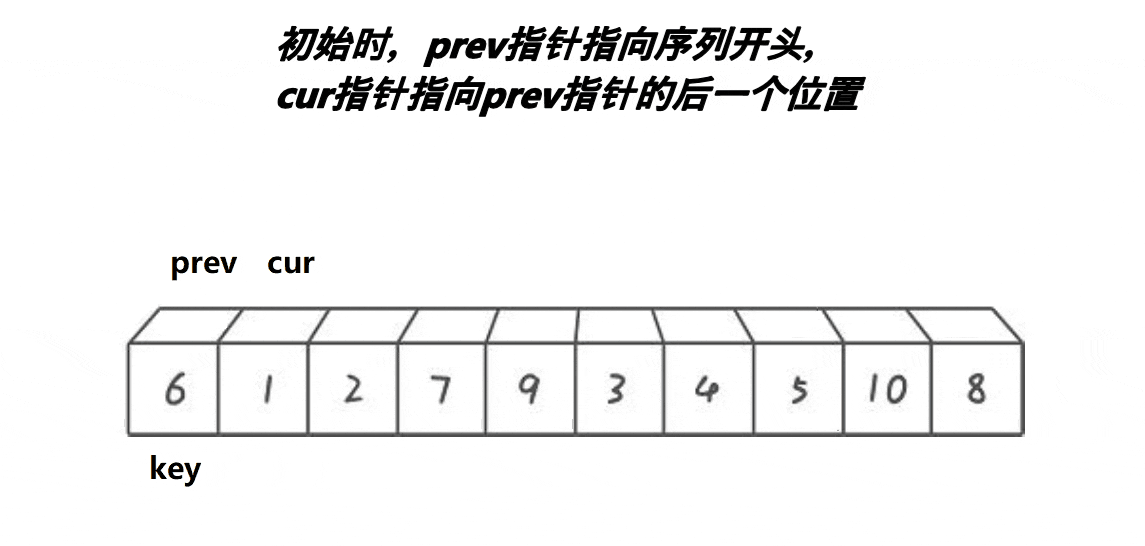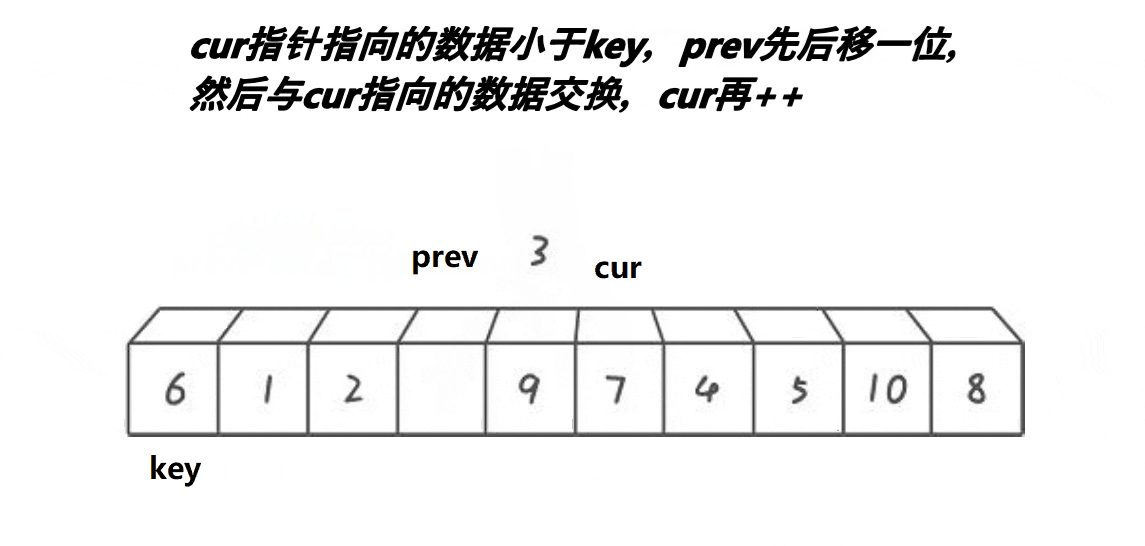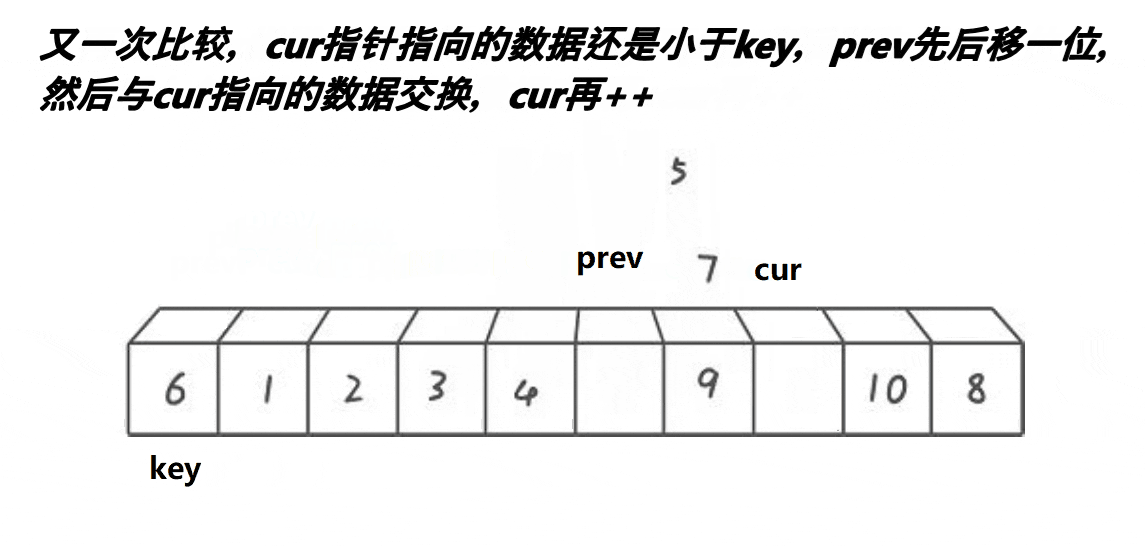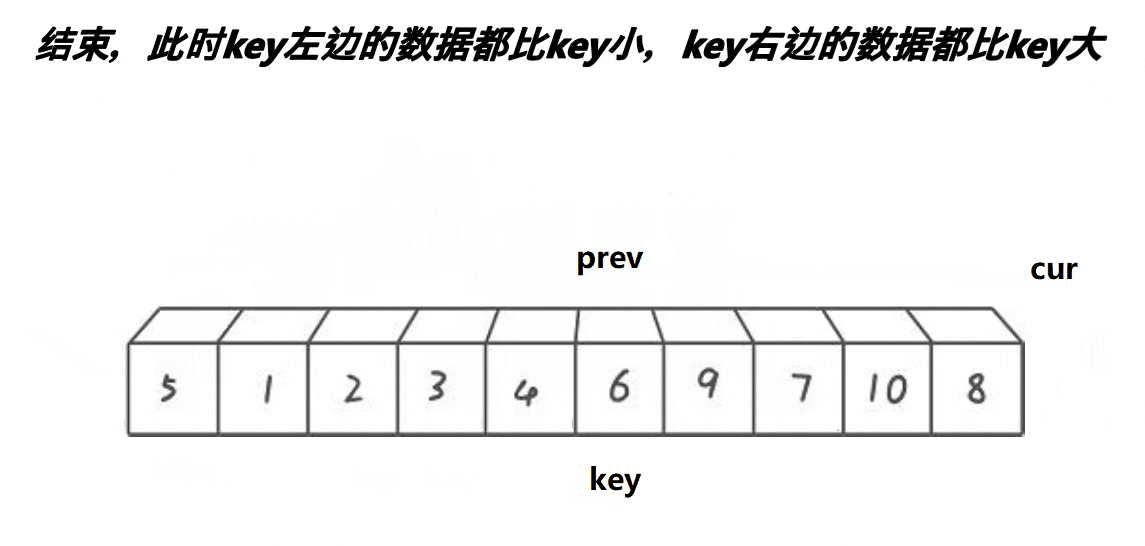
����:
//left��keyi int PartSort3(int* a, int left, int right) { int keyi = left; int prev = left; int cur = left + 1; while (cur <= right) { //������һ�д��������:��cur������a[keyi]С��ֵ��++prev,���ҷ�ֹ�Լ����Լ����н��� if (a[cur] < a[keyi] && a[++prev]!= a[cur]) Swap(&a[cur], &a[prev]); cur++; } Swap(&a[prev], &a[keyi]);//��a[prev]��a[keyi]���н��� return prev; } //right��keyi int PartSort3(int* a, int left, int right) { int keyi = right; int cur = left; int prev = left - 1; while (cur<right) { if (a[cur] < a[keyi] && a[++prev] != a[cur]) { Swap(&a[cur], &a[prev]); } cur++; } Swap(&a[++prev], &a[keyi]); return prev; }prev��cur�Ĺ�ϵ:
1��cur��û������key���ֵʱ,prev������cur,һǰһ��
2��cur������key���ֵʱ,prev��cur֮������һ�α�key���ֵ�����䡣
2.3.2.2 ʱ�临�Ӷ�
���������ʱ�临�Ӷ�:
������:ÿ��ѡ�Ķ�����λ��O(N*log2N)
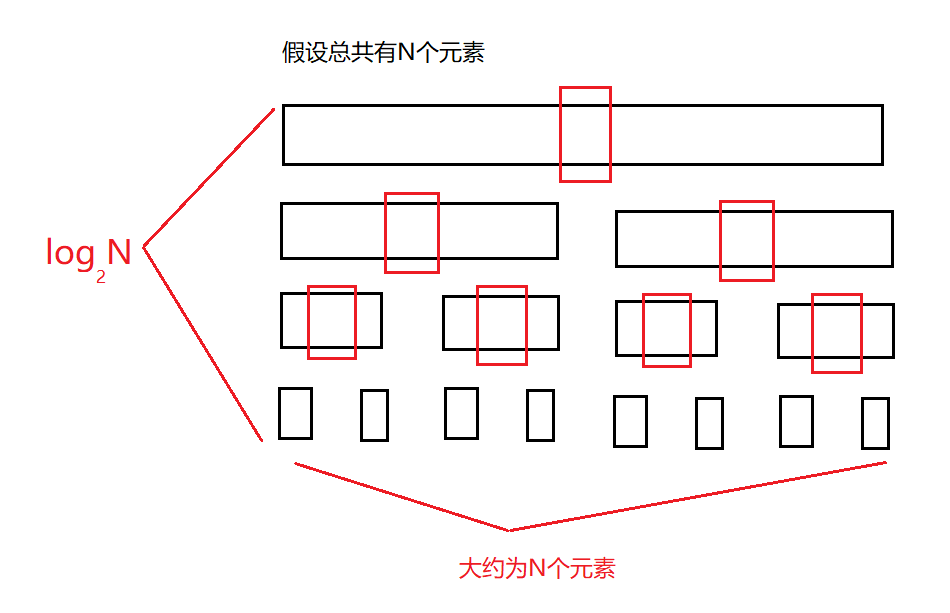
����:ÿ��ѡ��key����С�Ļ�����O(N2)
2.3.2.3 ����������Ż�
1.���ѡkey
2.����ѡ��
int GetMidIndex(int*a,int left,int right)
{
int mid = left + (right- left) / 2;
if (a[left] < a[mid])// left mid
{
if (a[mid] < a[right])//left mid right
{
return mid;
}
else if (a[left] > a[right])//right left mid
{
return left;
}
else//left right mid
{
return right;
}
}
else//mid left
{
if (a[right] > a[left])//mid left right
{
return left;
}
else if (a[mid] < a[right])//mid right left
{
return right;
}
else//right mid left
{
return mid;
}
}
}
//left��keyi
int PartSort3(int* a, int left, int right)
{
int midi = GetMidIndex(a, left, right);
Swap(&a[midi], &a[left]);
int keyi = left;
int prev = left;
int cur = left + 1;
while (cur <= right)
{
//������һ�д��������:��cur������a[keyi]С��ֵ��++prev,���ҷ�ֹ�Լ����Լ����н���
if (a[cur] < a[keyi] && a[++prev]!= a[cur])
Swap(&a[cur], &a[prev]);
cur++;
}
Swap(&a[prev], &a[keyi]);//��a[prev]��a[keyi]�����
return prev;
}
ע��:����ȡ�з���Ȼ����ȫ������ij������������и��Ӷȱ�ΪO(n2)�������
3.С�����Ż�
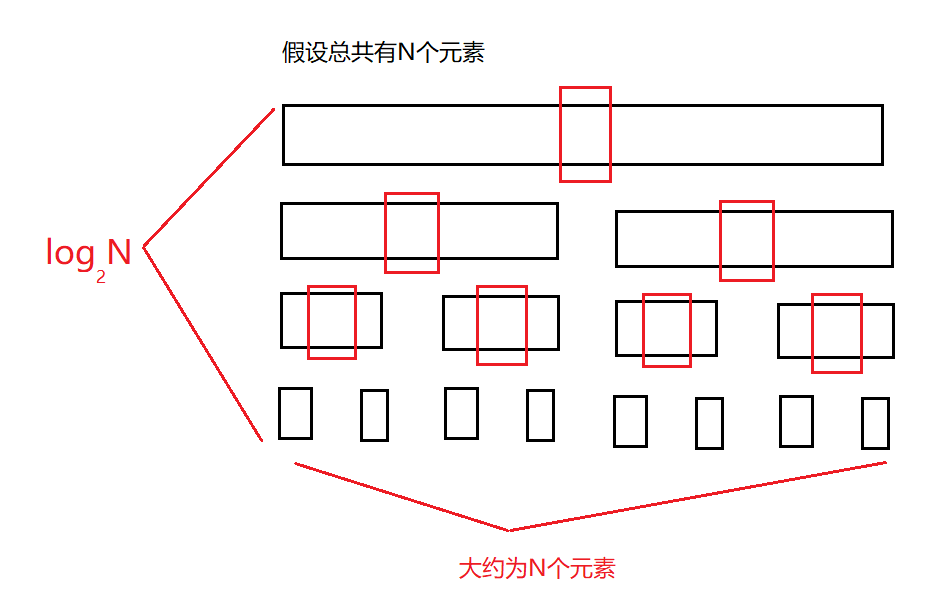
���ŵݹ���þ���չ����ͼ����һ��������,���Ǵ���ͼ�п��Կ���,�����������Ҫ���������ݱȽ��ٵ�ʱ��,����begin��end֮������Ƚ��ٻ���begin��end��ȵ�ʱ��,���ʱ��ĵݹ�����൱��,���ǿ��������ֱȽ��ٵ�ʱ��ȥ����������������,�Դ����ﵽ�Ż������ŵ�Ŀ�ġ�
�����֮:�����Сʱ,����ʹ�õݹ黮�ֵ�˼·��������,����ֱ��ʹ�ò��������С��������,���ٵݹ���á�
����:
void QuickSort(int* a,int begin,int end)
{
//�����ִ�λ���߶�����ȵ�ʱ���ֹͣ
if (begin >= end)
return;
//С����ֱ��ʹ�ò��������������
if (end - begin <= 10)
{
InsertSort(a + begin, end - begin + 1);
}
int keyi = PartSort3(a, begin, end);
//�ָ��������������:[begin,keyi-1]keyi[keyi+1,end]
QuickSort(a, begin, keyi - 1);
QuickSort(a, keyi+1, end);
}
2.3.2.3 ��������ǵݹ�
����˼·����ʵ��:
2.3.2.3.1 ջģ��ݹ�ʵ��
˼·:
����Ҫʹ�õ����±�ŵ�ջ����ʱ�洢(Ϊʲôֻ���±�?��ΪPartSort()����ֻ��Ҫ�õ����������±�),Ȼ��ʹ��ջ������,ÿ���ó�һ���±�ʱ,���õ������±�����ѹ��ջ��,����,ʼ�ն����ȶ��ұߵ��±��������,ģ���˵ݹ�����ʡ�

����ʵ��:
//��������ķǵݹ���ʽ1:ͨ��ջ��ʵ��
void QuickSort3(int* a, int begin, int end)
{
ST st;
StackInit(&st);
StackPush(&st, begin);
StackPush(&st, end);
while (!StackEmpty(&st))
{
int end = StackTop(&st);
StackPop(&st);
int begin = StackTop(&st);
StackPop(&st);
int keyi = PartSort(a, begin, end);
//[begin , keyi - 1] [keyi+1,end]
if (begin < keyi - 1)
{
StackPush(&st, begin);
StackPush(&st, keyi - 1);
}
if (keyi + 1 < end)
{
StackPush(&st, keyi + 1);
StackPush(&st, end);
}
}
StackDestory(&st);
}
2.2.2.3.2 ����ģ�����������ʵ��
˼·:
����Ҫʹ�õ����±�ŵ���������������ʱ�洢,ÿ�δӶ������ó�һ���±�ʱ,�ֽ����γɵ��±���뵽������ȥ,ֱ������Ϊ��ʱֹͣ��
ͼʾ:

����:
//��������ķǵݹ���ʽ1:ͨ��������ʵ��
void QuickSort3(int* a, int begin, int end)
{
Queue q;
QueueInit(&q);
QueuePush(&q, begin);
QueuePush(&q, end);
while (!QueueEmpty(&q))
{
int left = QueueFront(&q);
QueuePop(&q);
int right = QueueFront(&q);
QueuePop(&q);
int keyi = PartSort(a, left, end);//[left,keyi-1][keyi+1,right]
if (left < keyi - 1)
{
QueuePush(&q, left);
QueuePush(&q, keyi - 1);
}
if (keyi + 1 < right)
{
QueuePush(&q, keyi + 1);
QueuePush(&q, right);
}
}
QueueDestory(&q);
}
2.4 �鲢����
2.4.1 ����˼��
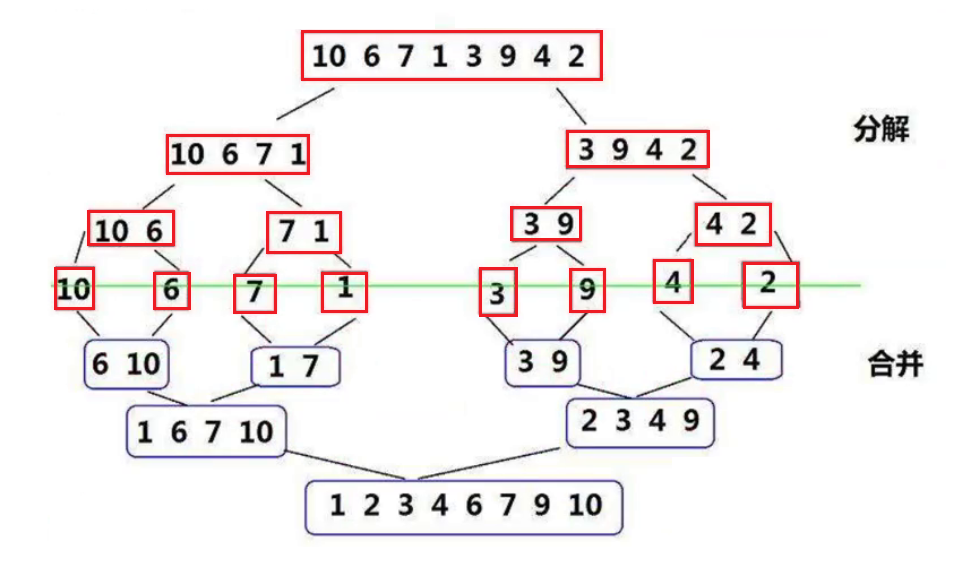
�鲢����(MERGE-SORT)�ǽ����ڹ鲢�����ϵ�һ����Ч�������㷨,���㷨�Dz��÷��η�(Divide and Conquer)��һ���dz����͵�Ӧ�á���������������кϲ�,�õ���ȫ���������;����ʹÿ���������� ��,��ʹ�����жμ�������������������ϲ���һ�������,��Ϊ��·�鲢�� �鲢����
���IJ���:
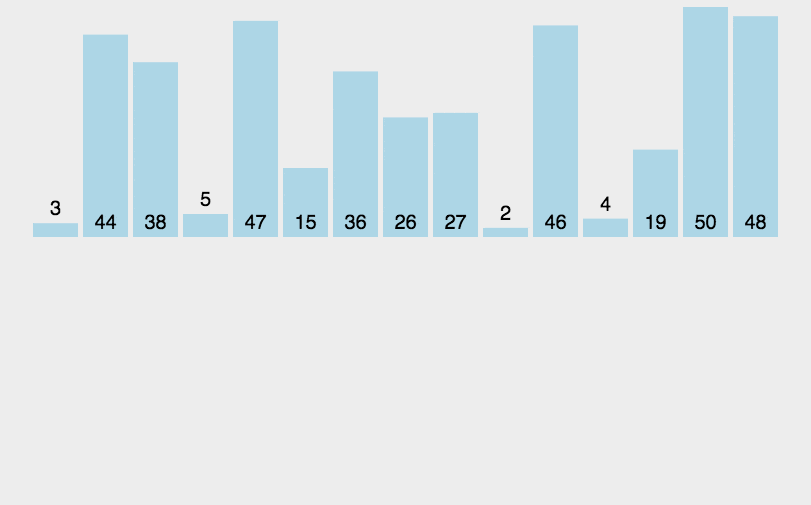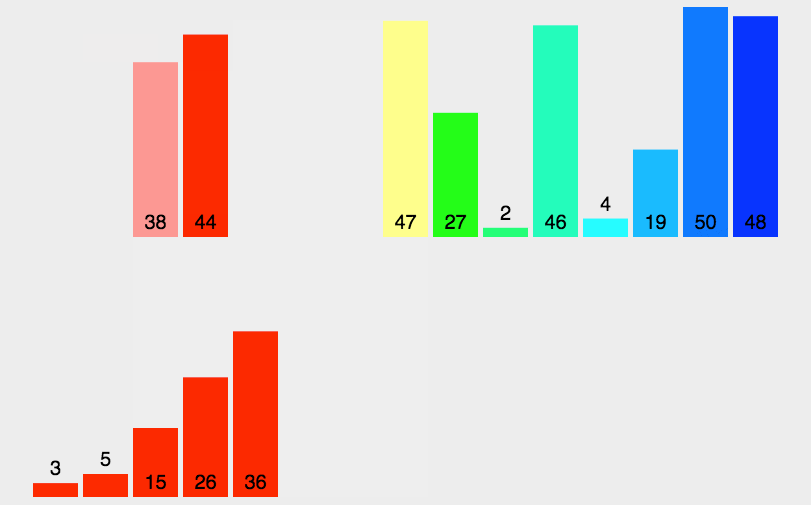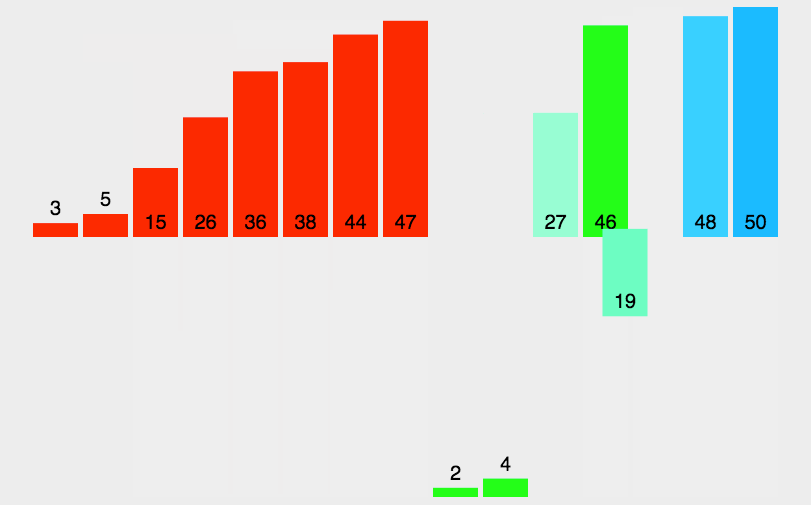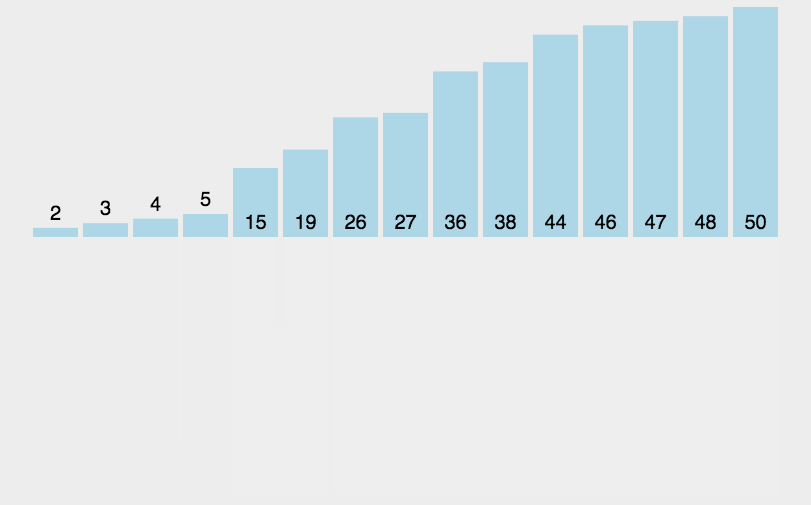
2.4.2 �鲢�����ʵ��
2.4.2.1 ����һ:�ݹ��
�ֽ�˼·:
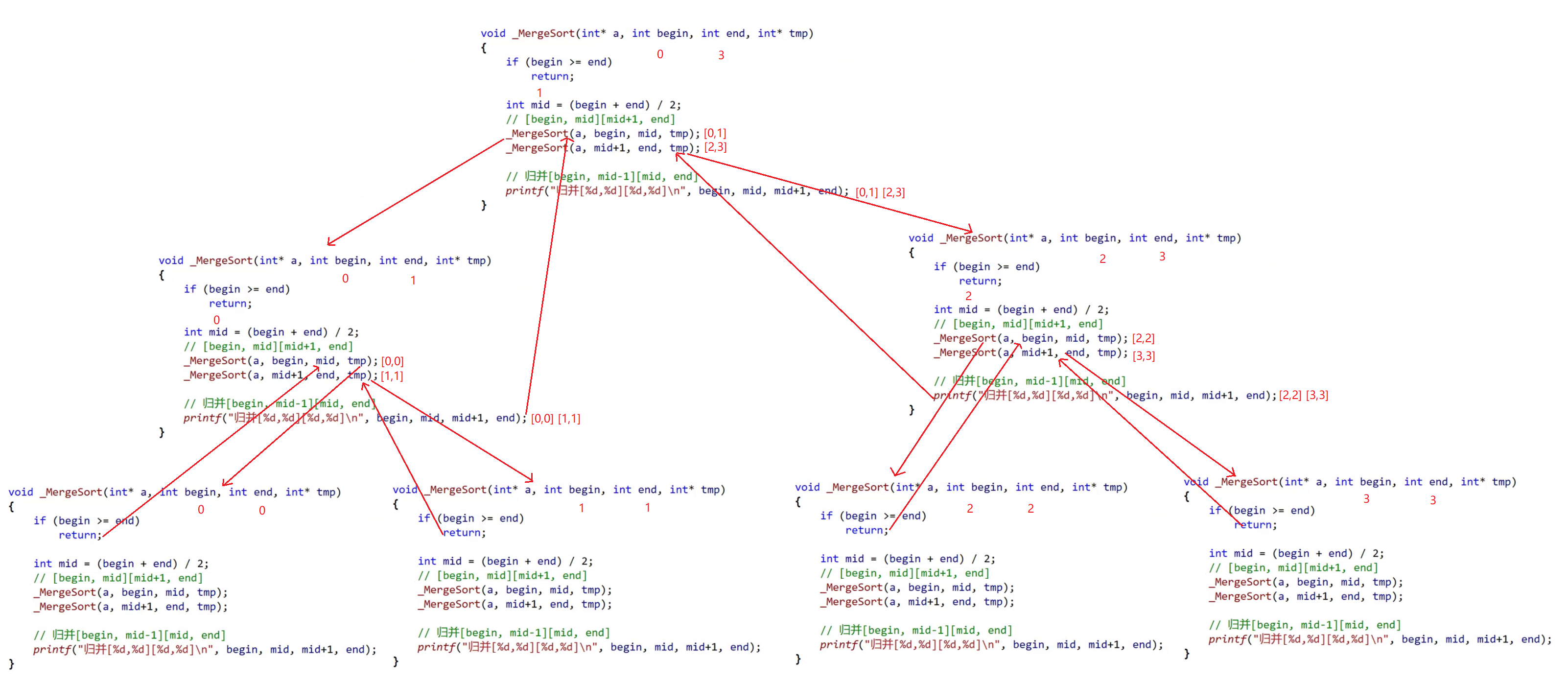
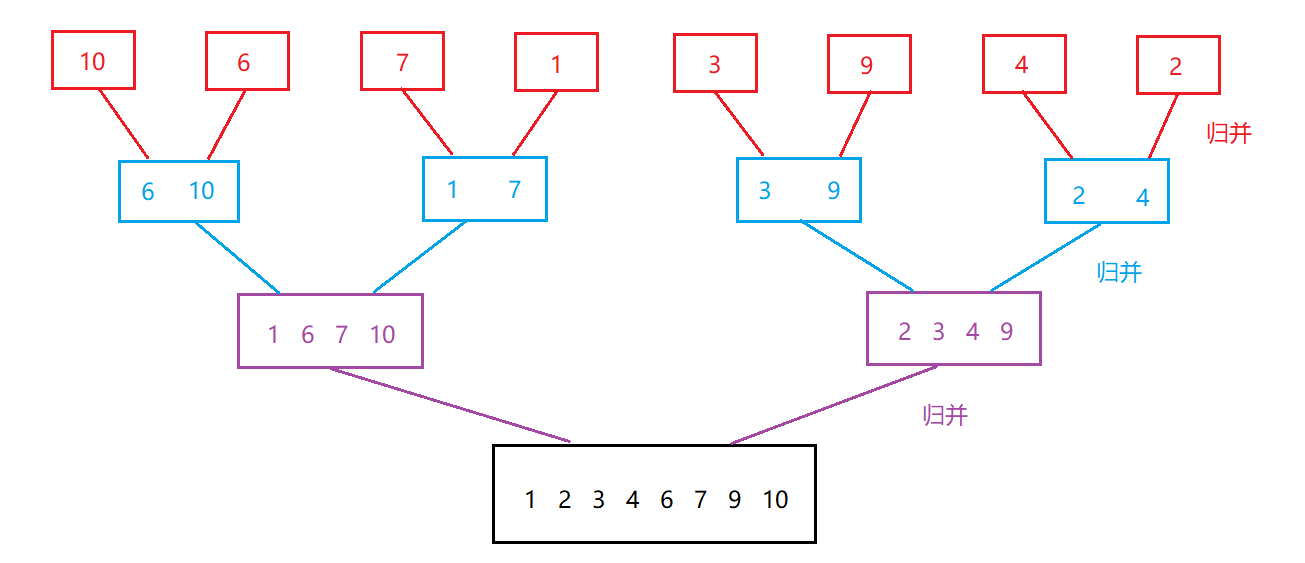
�鲢˼·:
����:
//�鲢����
void _MergeSort(int* a, int begin, int end,int*tmp)//��������
{
if (begin >= end)
{
return;
}
int mid = (begin + end) / 2;
//[begin,mid][mid+1,end]
_MergeSort(a, begin, mid, tmp);
_MergeSort(a, mid + 1, end, tmp);
//�˴�����������������,�������Ϊ[begin,mid-1][mid,end]ʱ�ͻ������ѭ��������,����[1,2]
//�鲢
int begin1 = begin, end1 = mid;//begin1��end1�������Ƶ�һ������
int begin2 = mid + 1, end2 = end;//begin2��end2�������Ƶڶ�������
int index = begin;//�±�ÿ�ζ���beginλ�ÿ�ʼ
while (begin1 <= end1 && begin2 <= end2)//������������һ�����䵽�����ʱ��ֹͣ
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)//�����һ������û�н����ʹӵ�һ���������Ų������
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)//����ڶ�������û�н����ʹӵڶ������������Ų������
{
tmp[index++] = a[begin2++];
}
memcpy(a+begin, tmp+begin, (end - begin + 1) * sizeof(int));//�����ڴ濽������
}
void MergeSort(int* a,int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);//������ʱ����ռ�
assert(tmp);//��ֹ����ʧ��
_MergeSort(a, 0, n - 1,tmp);
free(tmp);
}
2.4.2.2 ������:�ǵݹ��
��һ���汾:
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
assert(tmp);
int gap = 1;
while (gap<n)
{
for (int i = 0;i<n;i+=2*gap)//Ϊʲô��gapǰ����һ��2,��Ϊ���������ݽ��й鲢
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i+gap, end2 = i + 2 * gap - 1;
int index = i;
//printf("[%d,%d] [%d,%d]\n", begin1 , end1 , begin2 , end2);
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
}
memcpy(a, tmp, n*sizeof(int));
gap *= 2;
}
free(tmp);
}
����Ĵ��뾭����ӡ,�ڲ��Է�2���ݴη�����Ŀ������ʱ����ͻ��������,���統���Dz���10����ʱ��һ�´�ӡ���±�:
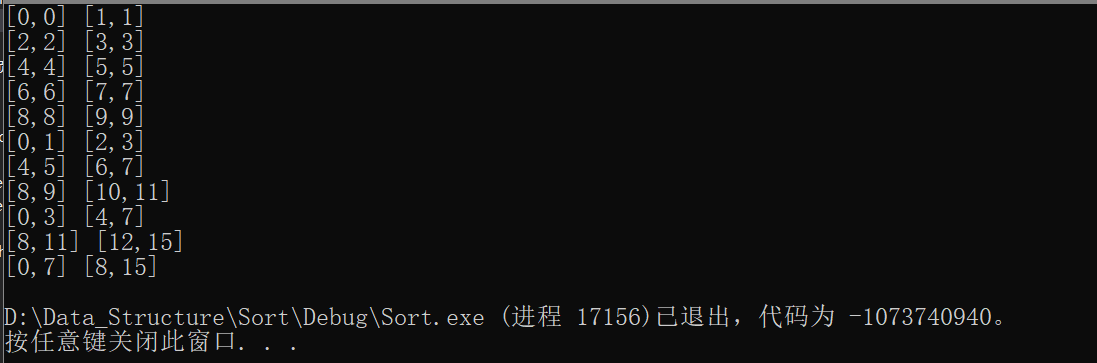
������Խ��(�ܹ���10������,�±����Ϊ9,���Գ������������)
���潫����һ������,��Խ����±�����ǿ����Ϊn-1,�������ֵĴ���������ʾ:
if (end1 >= n)
{
end1 = n - 1;
}
if (begin2 >= n)
{
begin2 = n - 1;
}
if (end2 >= n)
{
end2 = n - 1;
}
�������ӡ���Ϊ:
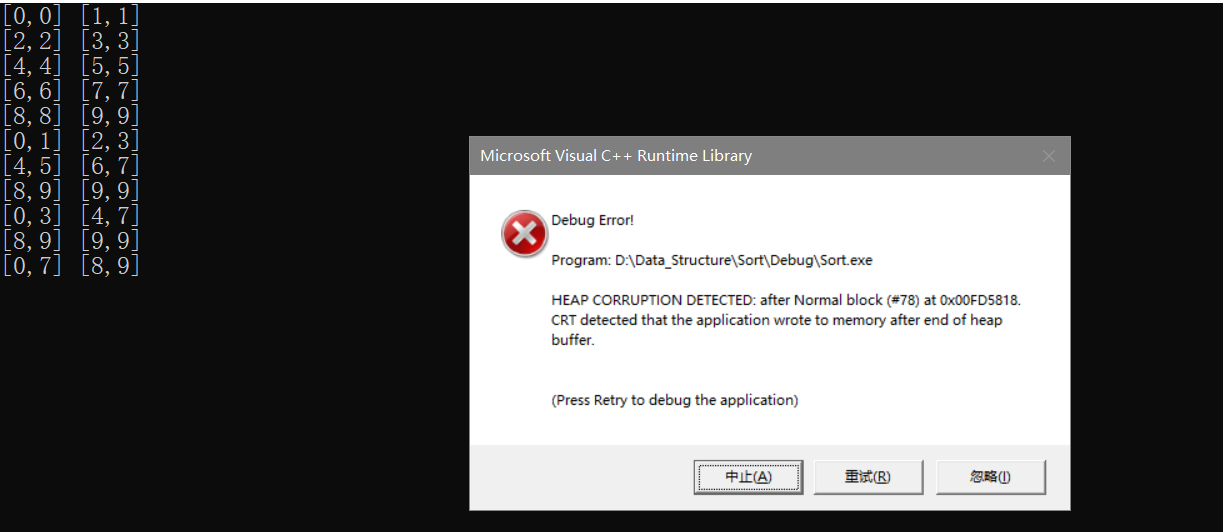
��ʱ�������ɲ���,Ϊʲô?��Ϊindex�ᷢ��Խ��,���±�Ϊ[8,9]��[9,9]��ʱ��,�������while(begin1 <= end1 && begin2 <= end2)���λ�ý���ѭ������,Ȼ���ʱindex����10(�ʼ��indexΪ8),Ȼ�������Ϊbegin2==end2���ٴν���ѭ��,��ʱ��index�ͻ����Խ����ʵ�����
�˴����з���:���end1Խ��,�����ǿ���������,���end2Խ��,begin2û��Խ��,����Ҳ�ǿ�������end2��,���begin2Խ����,��ô�ڶ�������ͻ�ֱ�Ӳ�����,��ʱ��Ҫ�ٶ�����Ĵ�������ġ�
if (end1 >= n)
{
end1 = n - 1;
}
if (begin2 >= n)
{
begin2 = n;
end2 = n - 1;
}
if (end2 >= n)
{
end2 = n - 1;
}
�ĵIJ��־���:���begin2Խ��,ֱ����[begin2,end2]������䲻���ڼ��ɡ�
��������������ʾ:
void MergeSort(int* a, int n)
{
int* tmp = (int*)malloc(sizeof(int) * n);
assert(tmp);
int gap = 1;
while (gap<n)
{
for (int i = 0;i<n;i+=2*gap)//Ϊʲô��gapǰ����һ��2,��Ϊ���������ݽ��й鲢
{
int begin1 = i, end1 = i + gap - 1;
int begin2 = i+gap, end2 = i + 2 * gap - 1;
//end1Խ��
if (end1 >= n)
{
end1 = n - 1;
}
//begin2Խ��
if (begin2 >= n)
{
begin2 = n;
end2 = n - 1;
}
//ֻ��end2Խ��
if (end2 >= n)
{
end2 = n - 1;
}
int index = i;
while (begin1 <= end1 && begin2 <= end2)
{
if (a[begin1] < a[begin2])
{
tmp[index++] = a[begin1++];
}
else
{
tmp[index++] = a[begin2++];
}
}
while (begin1 <= end1)
{
tmp[index++] = a[begin1++];
}
while (begin2 <= end2)
{
tmp[index++] = a[begin2++];
}
}
memcpy(a, tmp, n*sizeof(int));
gap *= 2;
}
free(tmp);
}
2.4.3 �鲢�����������
2.4.3.1 �鲢�������˼��
˼��:����Ҫ����ĵ�������̫������ļ�̫��,��ֱ�����ڴ�������,����Ҫ�����ⲿ�豸ʱ,�ͻ�ʹ�õ��ⲿ����
�㷨����:
����Ҫ������ļ�ƽ���ָ�����ɸ����Լ��ص��ڴ��е�С�ļ�
��ÿ��С�ļ��е����ݼ��ص��ڴ���,ʹ�ÿ�������������������ÿ��С�ļ��е������ų�����
���ڴ����������������д�ص��ļ���,��ʱ�ﵽ���ļ��й鲢���Ⱦ�����
-
�鲢˼·����ͼ��ʾ:
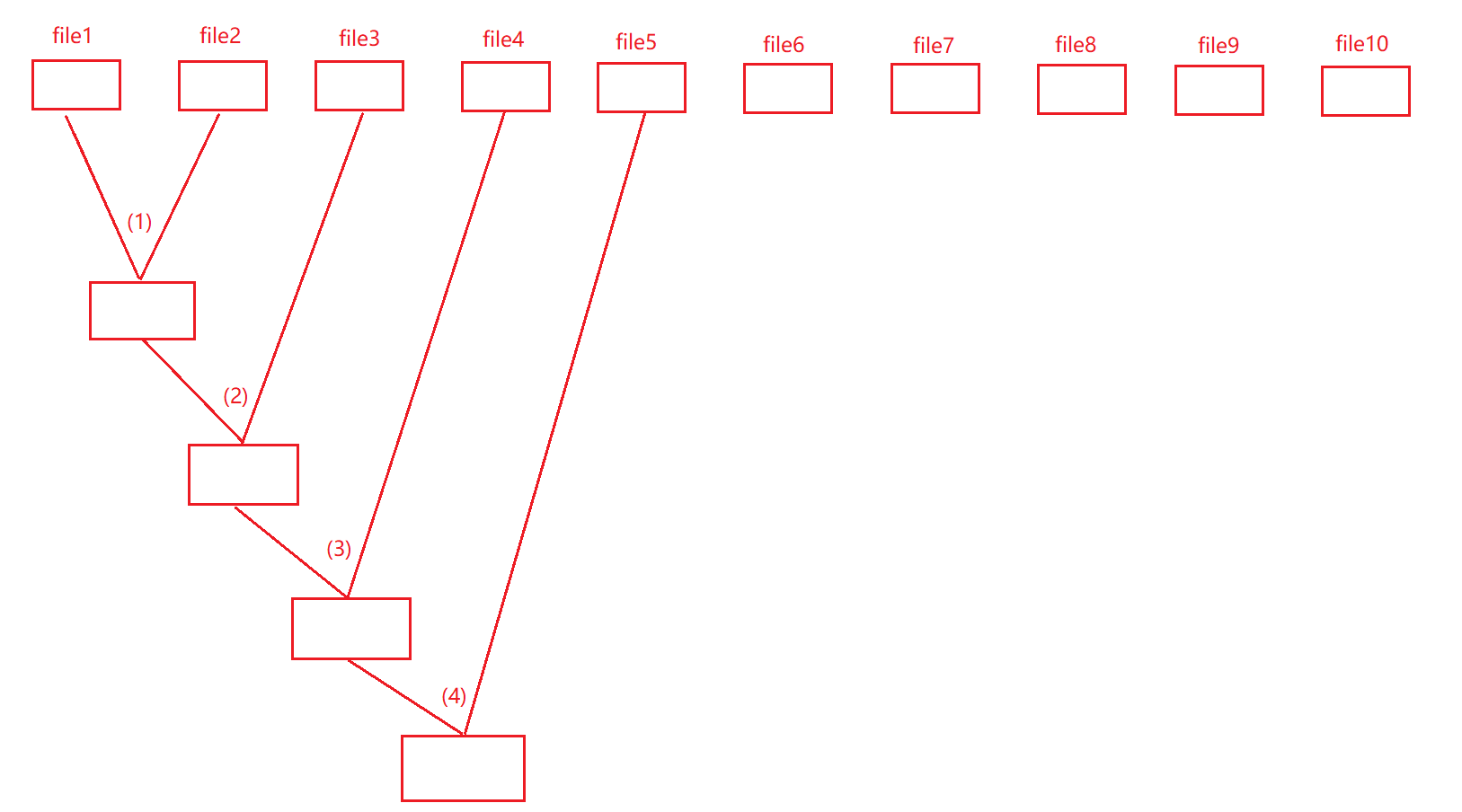
��ͼ�е�(1)��(2)��(3)��(4)�ֱ��ǵ�һ�ι鲢���ڶ��ι鲢�������ι鲢�͵��Ĵι鲢,�����û�����оٳ�����
ע��:ʵ���еĹ鲢˼·�кܶ���,������ֻ����һ��,�˴������˼·�оٳ���ֻ��Ϊ�˺����Ӧ�þ�����
2.4.3.2 �鲢�������ʵ��
�鲢����������������:
//�鲢������ļ�����
//file1��file2��Ҫ���鲢���ļ�,mfile�Ǵ�Ź鲢������ݵ��ļ�
void _MergeFile(const char*file1, const char*file2,const char* mfile)
{
//�������ļ���
FILE* fout1 = fopen(file1, "r");
if (fout1 == NULL)
{
printf("���ļ�ʧ��!\n");
exit(-1);
}
FILE* fout2 = fopen(file2, "r");
if (fout2 == NULL)
{
printf("���ļ�ʧ��!\n");
exit(-1);
}
FILE* fin = fopen(mfile, "w");
if (fin == NULL)
{
printf("���ļ�ʧ��!\n");
exit(-1);
}
//��ʼ�鲢
int num1, num2;//�洢file1��file2�ж�ȡ������
//�ȴ��ļ��ж�ȡ��һ������,ret1��Ϊ���ж��Ƿ��ȡ����,�������EOF��˵���Ѿ���ȡ����
int ret1 = fscanf(fout1, "%d\n", &num1);
int ret2 = fscanf(fout2, "%d\n", &num2);
//����µ�����
while (ret1!= EOF && ret2 != EOF)//����һ���ļ���ȡ����ʱ��ȡ�ͽ���
{
//�˴�����ΪҪ������,���Խ�С�����ݶ����µ��ļ���
if (num1 < num2)
{
fprintf(fin, "%d\n", num1);//��С������num1�����µ��ļ���
ret1 = fscanf(fout1, "%d\n", &num1);//���¶����µ�����
}
else
{
fprintf(fin, "%d\n", num2);//ͬ��
ret2 = fscanf(fout2, "%d\n", &num2);
}
}
//�������δ��ȡ����ļ�,��ʣ������ݶ�ȡ���µ��ļ�mfile��
while (ret1!=EOF)
{
fprintf(fin, "%d\n", num1);
ret1 = fscanf(fout1, "%d\n", &num1);
}
while (ret2!=EOF)
{
fprintf(fin, "%d\n", num2);
ret2 = fscanf(fout1, "%d\n", &num2);
}
fclose(fout1);
fclose(fout2);
fclose(fin);
}
2.4.3.3 �鲢������ʹ�þ���
������������ļ�file,���ļ����ܹ�����100������,������Ҫ�����ֳ�10��,ÿ��������10������,ÿ�����ݷ���һ���ļ���,�ļ�����1��10,Ȼ�������ļ��������ʼ��12,��ʾ����ļ�Ҫ����ļ�1��2�鲢�������,ͬ��,�����123���Ǵ���ļ�12��3�鲢������ݡ�
����ʵ��:
void MergeSortFile(const char* file)//�˴���file��Ҫ��������ļ�
{
FILE* fout = fopen(file, "r");
if (fout == NULL)
{
printf("���ļ�ʧ��!\n");
exit(-1);
}
//�ָ��һ��һ������,�ڴ������д��С�ļ�
int n = 10;
int a[10];
int i = 0;
int num = 0;
char subfile[20] = { 0 };
int filei = 1;
while (fscanf(fout, "%d\n", &num) != EOF)
{
if (i < n-1)//ǰ9�����ݽ�ȥ
{
a[i++] = num;
}
else
{
a[i] = num;//���ǵ�10������
QuickSort(a, 0, n - 1);
sprintf(subfile, "%d", filei++);
FILE* fin = fopen(subfile, "w");
if (fin == NULL)
{
printf("���ļ�ʧ��\n");
exit(-1);
}
for (int i = 0; i < n; i++)
{
fprintf(fin, "%d\n", a[i]);
}
fclose(fin);
i = 0;
memset(a, 0, sizeof(int)*n);
}
}
//���û���鲢���ļ�,ʵ����������
//��������
char mfile[100] = "12";
char file1[100] = "1";
char file2[100] = "2";
for (int i = 2; i <= n; i++)
{
//��ȡfile1��file2,���й鲢��mfile
_MergeFile(file1, file2, mfile);//��file1��file2���й鲢��mfile��
strcpy(file1, mfile);//�˴���mfile�����ָ��Ƹ�file1
sprintf(file2, "%d", i+1);
sprintf(mfile, "%s%d", mfile,i + 1);
}
fclose(fout);
}
2.4.4 �鲢����������ܽ�
- �鲢��ȱ��������ҪO(N)�Ŀռ临�Ӷ�,�鲢�����˼��������ǽ���ڴ����е����������⡣
- ʱ�临�Ӷ�:O(N*logN)
�������鲢�����ʱ�临�Ӷ�?
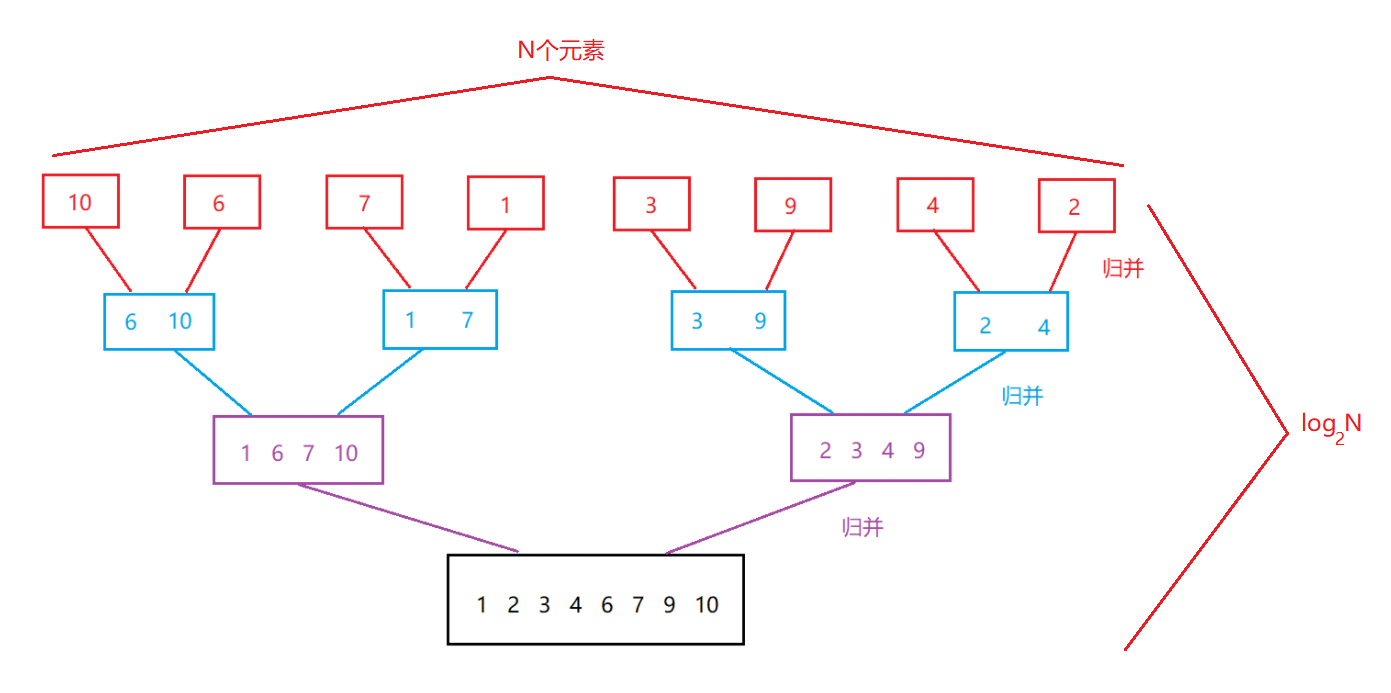
- �ռ临�Ӷ�:O(N)
ע��:ʵ����Ӧ����O(N + log2N)(N�ǿ��ٵ�����Ŀռ�,log2N�ǿ���ջ֡�IJ���(�ݹ�汾,�ǵݹ��û��),log2N̫С,���Կ����dz���,�������Բ���,���Ծ���O(N)) - �ȶ���:�ȶ�
2.5 �ߴ��������ܲ��ԱȽ�
2.5.1 ���ԱȽϴ���
����:
// ������������ܶԱ�
void TestOP()
{
srand((unsigned)time(0));
const int N = 100000;
int* a1 = (int*)malloc(sizeof(int) * N);
int* a2 = (int*)malloc(sizeof(int) * N);
int* a3 = (int*)malloc(sizeof(int) * N);
int* a4 = (int*)malloc(sizeof(int) * N);
int* a5 = (int*)malloc(sizeof(int) * N);
int* a6 = (int*)malloc(sizeof(int) * N);
int* a7 = (int*)malloc(sizeof(int) * N);
assert(a1);
assert(a2);
assert(a3);
assert(a4);
assert(a5);
assert(a6);
assert(a7);
for (int i = 0; i<N; i++)
{
a1[i] = rand();
a1[i] = N-i;
a2[i] = a1[i];
a3[i] = a1[i];
a4[i] = a1[i];
a5[i] = a1[i];
a6[i] = a1[i];
a7[i] = a1[i];
}
int begin1 = clock();
InsertSort(a1, N);
int end1 = clock();
int begin2 = clock();
ShellSort(a2, N);
int end2 = clock();
int begin3 = clock();
SelectSort(a3, N);
int end3 = clock();
int begin4 = clock();
HeapSort(a4, N);
int end4 = clock();
int begin5 = clock();
QuickSort(a5, 0, N - 1);
int end5 = clock();
int begin6 = clock();
MergeSort(a6, N);
int end6 = clock();
int begin7 = clock();
BubbleSort(a7, N);
int end7 = clock();
printf("InsertSort:%d\n", end1 - begin1);
printf("ShellSort:%d\n", end2 - begin2);
printf("SelectSort:%d\n", end3 - begin3);
printf("HeapSort:%d\n", end4 - begin4);
printf("QuickSort:%d\n", end5 - begin5);
printf("MergeSort:%d\n", end6 - begin6);
printf("BubbleSort:%d\n", end7 - begin7);
free(a1);
free(a2);
free(a3);
free(a4);
free(a5);
free(a6);
free(a7);
}
2.5.2 ���ԱȽϽ��
ע��:��VS2019release�汾�½��в���,��ʱ������������һϵ���Ż���
��NΪ10000ʱ:
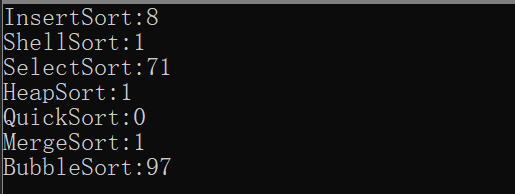
��NΪ100000ʱ:
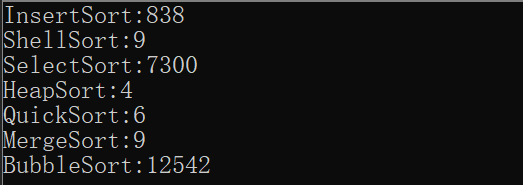
��ʱ�������в��Կ�����������ϣ�����鲢����:
��NΪ1000000:

��NΪ10000000:

��NΪ20000000:

2.6 �DZȽ�����
2.6.1 ��������
2.6.1.1 ���������˼��
˼��:���������ֳ�Ϊ�볲ԭ��,�ǶԹ�ϣֱ�Ӷ�ַ���ı���Ӧ�á� ��������:
- ͳ����ͬԪ�س��ִ���
- ����ͳ�ƵĽ�������л��յ�ԭ����������
ͼʾ: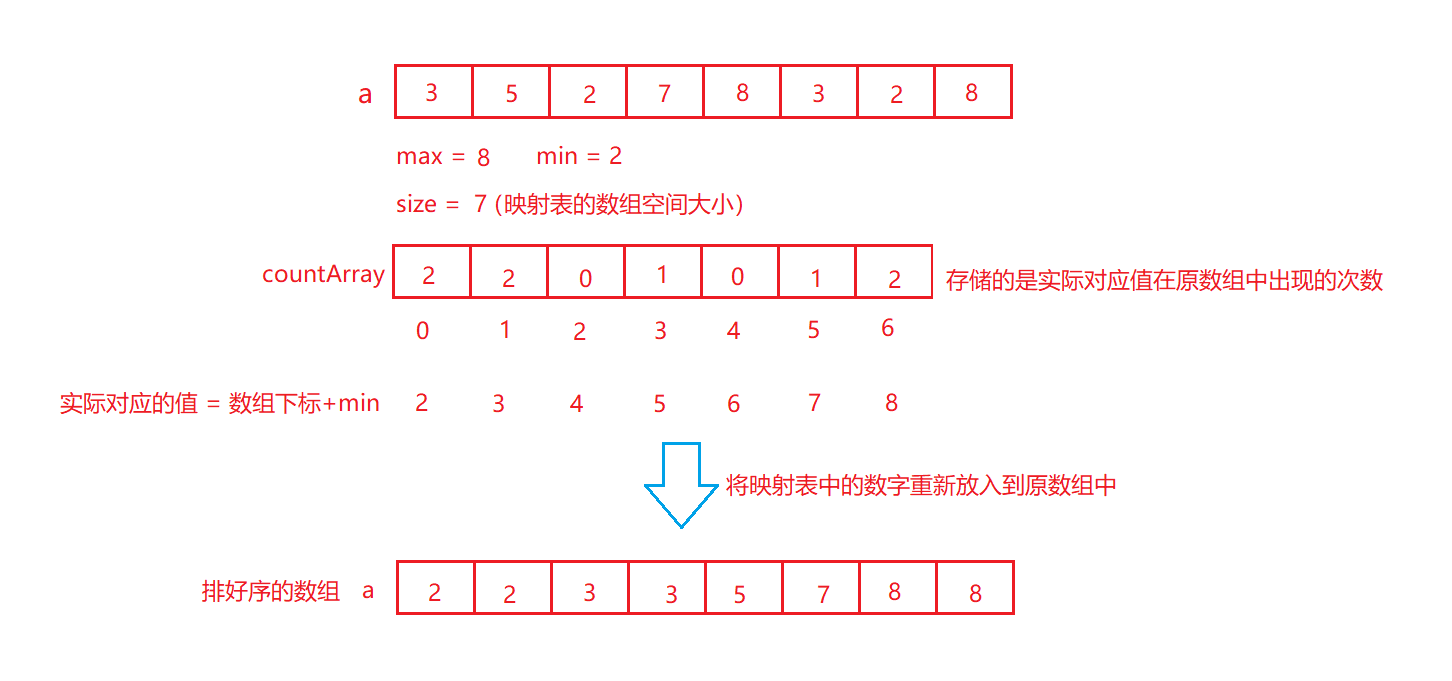
����:
void CountSort(int* a,int n)
{
//������ֵ����Сֵ
int max = a[0];
int min = a[0];
for (int i = 1; i < n; i++)
{
if (a[i] > max)
{
max = a[i];
}
if (a[i] < min)
{
min = a[i];
}
}
int size = max - min + 1;//ӳ�������Ĵ�С
//����ӳ������
int* countArray = (int*)calloc(size,sizeof(int));
assert(countArray);
//����
for (int i = 0; i < n; i++)
{
countArray[a[i] - min]++;
}
//�Żص�ԭ����������:����
int j = 0;//j������¼ԭ��������±�
for (int i = 0; i < size; i++)//i������¼ӳ�������Ԫ�ص�С��
{
while(countArray[i]--)
{
a[j++] = i + min;
}
}
}
2.6.1.2 ��������ĸ��Ӷ�
ʱ�临�Ӷ�:O(N + range)
�ռ临�Ӷ�:O(range)
ע��:range = max - min +1
˵��:�������������ڷ�Χ���е�����
ע��:��������֧�ָ������Dz�֧�ָ��������ַ����ȡ�
3.�����㷨���Ӷȼ��ȶ��Է���
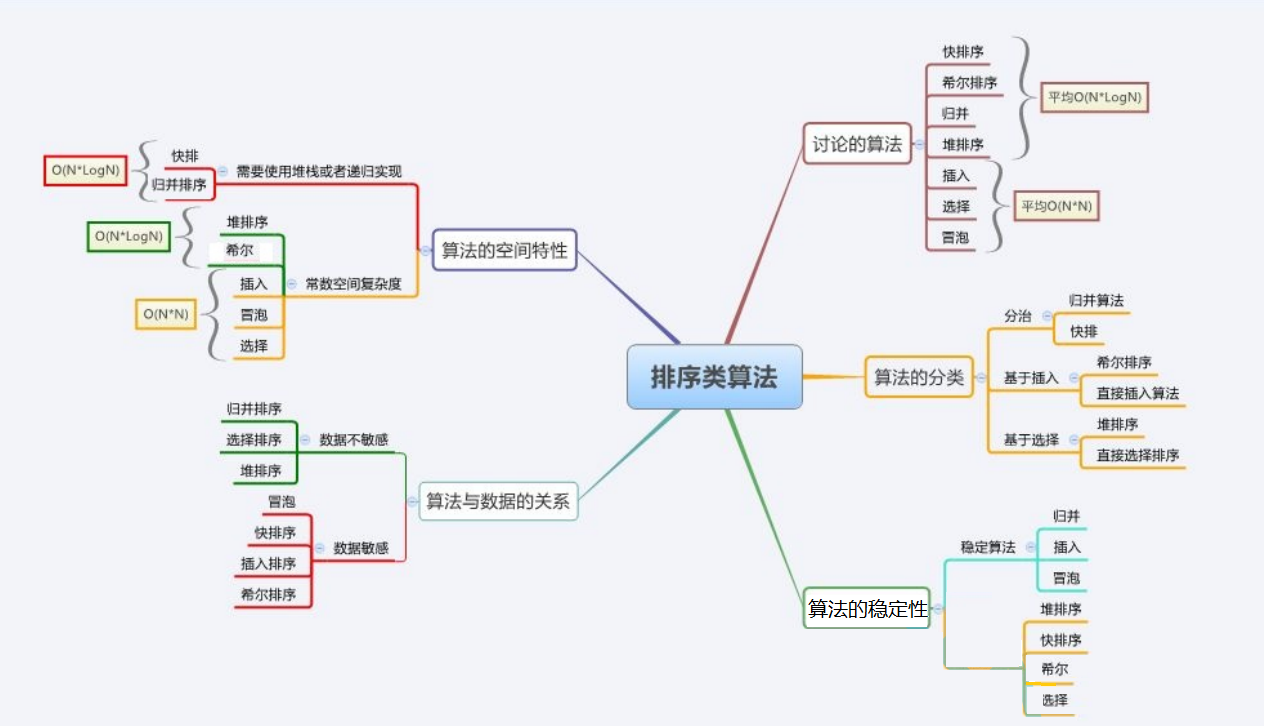
�ȶ��Է���:
ֱ�Ӳ�������:�ȶ���
ϣ������:���ȶ�����ͬ�������ܱ����䵽��ͬ��gap���С�
ѡ������:���ȶ�������ͼ��ʾ:

����ͼ��,ѡ����С������1,��ǰ���3����֮������3�����λ�þͷ����˽���,˵��ѡ�������Dz��ȶ��ġ�
������:���ȶ�������ͼ��ʾ:

��ʱ��һ�����,������Ҫ�õ��������������,��ʱ�����8��4���н�����,��ʱ����8�����λ�þͷ����˸ı�,���Զ��������ȶ��ԡ�
ð������:�ȶ���
��������:���ȶ�����Ϊ����keyiҪ�ŵ��м�ȥ��
�鲢����:�ȶ�����Ϊ�ڹ鲢��ʱ��,��ߵ����¾�ʼ�����ȶ��ġ�
ͼ���ܽ�:
| ���� | ƽ����� | ������ | ���� | �����ռ� | �ȶ��� |
|---|---|---|---|---|---|
| ð������ | O(n2) | O(n2) | O(n2) | O(1) | �ȶ� |
| ��ѡ������ | O(n2) | O(n2) | O(n2) | O(1) | ���ȶ� |
| ֱ�Ӳ������� | O(n2) | O(n) | O(n2) | O(1) | �ȶ� |
| ϣ������ | O(nlog2n)~O(n2) | O(n1.3) | O(n2) | O(1) | ���ȶ� |
| ������ | O(nlog2n) | O(nlog2n) | O(nlog2n) | O(1) | ���ȶ� |
| �鲢���� | O(nlog2n) | O(nlog2n) | O(nlog2n) | O(n) | �ȶ� |
| �������� | O(nlog2n) | O(nlog2n) | O(n2) | O(log2n)~O(n) | ���ȶ� |

